
Was sind die Fallstricke verteilter Redis-Sperren?

- PHPznach vorne
- 2023-06-03 12:03:241515Durchsuche
1 Nicht-atomare Operation
Bei Verwendung der verteilten Sperre von Redis denken wir möglicherweise als Erstes an den Befehl setNx. setNx命令。
if (jedis.setnx(lockKey, val) == 1) {
jedis.expire(lockKey, timeout);
}容易,三下五除二,我们就可以把代码写好。
这段代码确实可以加锁成功,但你有没有发现什么问题?
加锁操作和后面的设置超时时间是分开的,并非原子操作。
如果锁定成功,但无法设置超时时间,则lockKey将永远有效。假如在高并发场景中,有大量的lockKey加锁成功了,但不会失效,有可能直接导致redis内存空间不足。
那么,有没有保证原子性的加锁命令呢?
答案是:有,请看下面。
2 忘了释放锁
上面说到使用setNx命令加锁操作和设置超时时间是分开的,并非原子操作。
而在redis中还有set命令,该命令可以指定多个参数。
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;其中:
lockKey:锁的标识requestId:请求idNX:只在键不存在时,才对键进行设置操作。PX:设置键的过期时间为 millisecond 毫秒。expireTime:过期时间
set命令是原子操作,加锁和设置超时时间,一个命令就能轻松搞定。
使用set命令加锁,表面上看起来没有问题。但如果仔细想想,加锁之后,每次都要达到了超时时间才释放锁,会不会有点不合理?加锁后,如果不及时释放锁,会有很多问题。
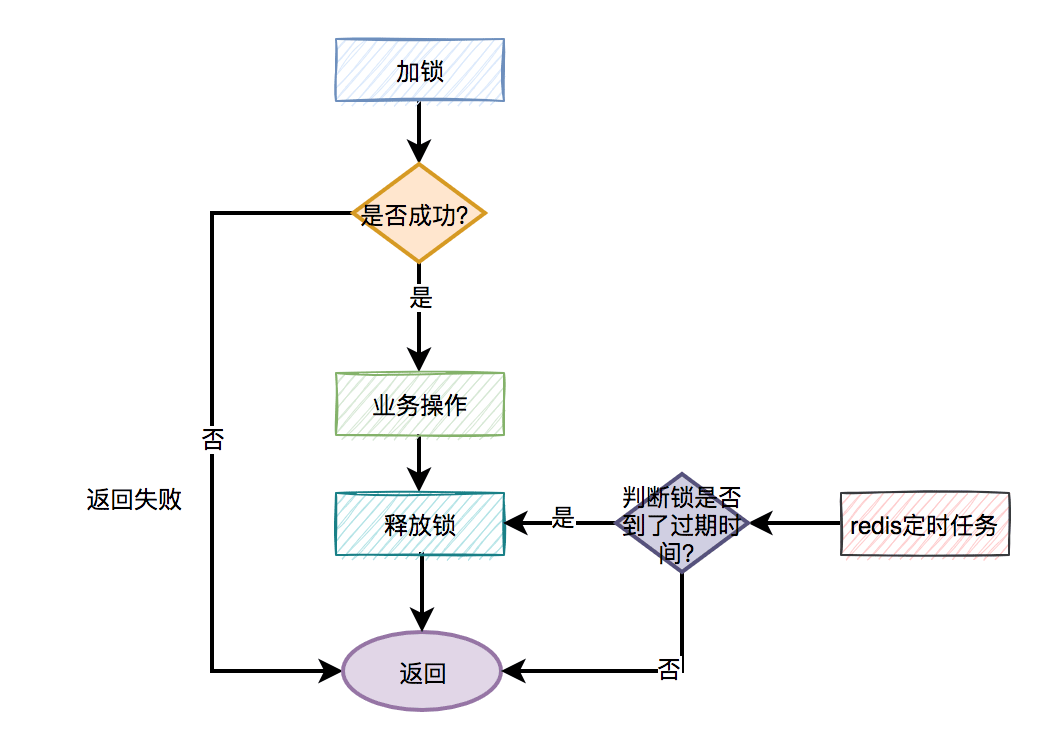
分布式锁更合理的用法是:
手动加锁
业务操作
手动释放锁
如果手动释放锁失败了,则达到超时时间,redis会自动释放锁。
大致流程图如下:
那么问题来了,如何释放锁呢?
伪代码如下:
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
} finally {
unlock(lockKey);
}需要捕获业务代码的异常,然后在finally中释放锁。换句话说就是:无论代码执行成功或失败了,都需要释放锁。
此时,有些朋友可能会问:假如刚好在释放锁的时候,系统被重启了,或者网络断线了,或者机房断点了,不也会导致释放锁失败?
这是一个好问题,因为这种小概率问题确实存在。
但还记得前面我们给锁设置过超时时间吗?即使出现异常情况造成释放锁失败,但到了我们设定的超时时间,锁还是会被redis自动释放。
但只在finally中释放锁,就够了吗?
3 释放了别人的锁
回答上一个问题是一个厚道的表现,但仅在finally中释放锁是不够的,因为锁的释放方式也很重要。
哪里不对?
答:在多线程场景中,可能会出现释放了别人的锁的情况。
有些朋友可能会反驳:假设在多线程场景中,线程A获取到了锁,但如果线程A没有释放锁,此时,线程B是获取不到锁的,何来释放了别人锁之说?
答:假如线程A和线程B,都使用lockKey加锁。尽管线程A成功地获取了锁,但是其业务功能的执行时间超过了超时时间的设定。这时候,redis会自动释放lockKey锁。此时,线程B就能给lockKey加锁成功了,接下来执行它的业务操作。恰好这个时候,线程A执行完了业务功能,接下来,在finally方法中释放了锁lockKey。这不就出问题了,线程B的锁,被线程A释放了。
我想这个时候,线程B肯定哭晕在厕所里,并且嘴里还振振有词。
那么,如何解决这个问题呢?
不知道你们注意到没?在使用set命令加锁时,除了使用lockKey锁标识,还多设置了一个参数:requestId
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
return true;
}
return false;Einfach, nur dreimal fünf und zwei, wir können den Code schreiben. Dieser Code kann zwar erfolgreich gesperrt werden, aber haben Sie irgendwelche Probleme festgestellt? Sperrvorgang und der folgende Zeitüberschreitungszeitraum festlegen sind separate und nicht-atomare Vorgänge.
2 Ich habe vergessen, die Sperre aufzuhebenWie oben erwähnt, sind der Sperrvorgang und das Festlegen des Timeouts mit dem BefehlDie Antwort lautet: Ja, siehe unten.
setNx getrennt und keine atomaren Vorgänge. Es gibt auch einen set-Befehl in Redis, der mehrere Parameter angeben kann. 🎜if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end🎜🎜Unter ihnen: 🎜🎜
- 🎜
lockKey: Die Identifikation des Schlosses🎜 - 🎜
requestId: Anforderungs-ID🎜 - 🎜
NX: Legen Sie den Schlüssel nur fest, wenn der Schlüssel nicht vorhanden ist. 🎜 - 🎜
PX: Legen Sie die Ablaufzeit des Schlüssels auf Millisekunden Millisekunden fest. 🎜 - 🎜
expireTime: Ablaufzeit🎜
set Der Befehl ist eine atomare Operation, die das Timeout sperrt und festlegt. Das geht ganz einfach mit einem Befehl. 🎜🎜Verwenden Sie zum Sperren den Befehl set, und an der Oberfläche scheint es kein Problem zu geben. Aber wenn Sie sorgfältig darüber nachdenken, wäre es nach dem Sperren etwas unangemessen, die Sperre jedes Mal nach Erreichen des Timeout-Zeitraums aufzuheben? Wenn die Sperre nach dem Sperren nicht rechtzeitig aufgehoben wird, treten viele Probleme auf. 🎜🎜🎜Eine sinnvollere Verwendung verteilter Sperren ist: 🎜🎜- 🎜Manuelle Sperre🎜
- 🎜Geschäftsbetrieb🎜 🎜Manuelle Freigabe der Sperre🎜
- 🎜Wenn die manuelle Freigabe der Sperre fehlschlägt, ist das Zeitlimit erreicht und Redis gibt die Sperre automatisch frei. 🎜
 🎜🎜Dann stellt sich die Frage, wie man die Sperre aufhebt? 🎜🎜🎜Der Pseudocode lautet wie folgt: 🎜🎜
🎜🎜Dann stellt sich die Frage, wie man die Sperre aufhebt? 🎜🎜🎜Der Pseudocode lautet wie folgt: 🎜🎜if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);🎜Sie müssen die Ausnahme des Geschäftscodes abfangen und dann die Sperre endlich aufheben. Mit anderen Worten: Unabhängig davon, ob die Codeausführung erfolgreich ist oder fehlschlägt, muss die Sperre aufgehoben werden. 🎜🎜Zu diesem Zeitpunkt fragen sich einige Freunde möglicherweise: Wenn das System gerade dann neu gestartet wird, wenn die Sperre aufgehoben wird, die Netzwerkverbindung getrennt wird oder der Computerraum über einen Haltepunkt verfügt, schlägt die Sperre dann auch fehl? 🎜🎜Das ist eine gute Frage, denn dieses kleine Wahrscheinlichkeitsproblem existiert tatsächlich. 🎜🎜Aber erinnerst du dich an die Zeitüberschreitung, die wir vorhin für die Sperre festgelegt haben? Selbst wenn eine ungewöhnliche Situation auftritt und die Sperrfreigabe fehlschlägt, wird die Sperre nach dem von uns festgelegten Zeitlimit von Redis automatisch freigegeben. 🎜🎜Aber reicht es, die Sperre nur endgültig zu lösen? 🎜🎜3 Die Sperre einer anderen Person aufheben🎜🎜Die Beantwortung der vorherigen Frage ist eine nette Geste, aber es reicht nicht aus, die Sperre endlich aufzuheben, denn auch die Art und Weise, wie die Sperre aufgehoben wird, ist wichtig. 🎜🎜Was ist los? 🎜🎜Antwort: In einem Multithread-Szenario kann die Sperre einer anderen Person aufgehoben werden. 🎜🎜Einige Freunde widerlegen möglicherweise: Angenommen, in einem Multithread-Szenario erhält Thread A die Sperre, aber wenn Thread A die Sperre nicht freigibt, kann Thread B die Sperre nicht erlangen sperren? 🎜🎜Antwort: Wenn Thread A und Thread B beide lockKey zum Sperren verwenden. Obwohl Thread A die Sperre erfolgreich erworben hat, hat die Ausführungszeit seiner Geschäftsfunktion die Timeout-Einstellung überschritten. Zu diesem Zeitpunkt gibt Redis die LockKey-Sperre automatisch frei. Zu diesem Zeitpunkt kann Thread B den LockKey erfolgreich sperren und dann seine Geschäftsvorgänge ausführen. Genau zu diesem Zeitpunkt hat Thread A die Ausführung der Geschäftsfunktion abgeschlossen und gibt dann den lockKey in der Methode „final“ frei. Ist das nicht ein Problem? Die Sperre von Thread B wird von Thread A aufgehoben. 🎜🎜Ich denke, zu diesem Zeitpunkt muss Thread B weinend auf der Toilette ohnmächtig geworden sein und immer noch plausibel gesprochen haben. 🎜🎜Also, wie kann man dieses Problem lösen? 🎜🎜Ich frage mich, ob es dir aufgefallen ist? Bei Verwendung des Befehls set zum Sperren wird zusätzlich zur Verwendung der Sperrkennung lockKey ein zusätzlicher Parameter festgelegt: requestId. Warum müssen wir die requestId aufzeichnen? 🎜🎜Antwort: requestId wird beim Aufheben der Sperre verwendet. 🎜🎜🎜Der Pseudocode lautet wie folgt: 🎜🎜try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;🎜Ermitteln Sie beim Aufheben der Sperre zunächst den Wert der Sperre (der zuvor festgelegte Wert ist requestId) und bestimmen Sie dann, ob er mit dem zuvor festgelegten Wert If übereinstimmt Es ist dasselbe, die Sperre darf gelöscht werden und der Erfolg wird zurückgegeben. Wenn sie unterschiedlich sind, wird der Fehler direkt zurückgegeben. 🎜🎜🎜Mit anderen Worten: Sie können nur die Sperren freigeben, die Sie hinzugefügt haben, und Sie dürfen die Sperren, die andere hinzugefügt haben, nicht freigeben. 🎜🎜🎜Warum müssen wir hier requestId verwenden? Können wir nicht userId verwenden? 🎜🎜Wenn Sie die Benutzer-ID verwenden, ist diese für die Anfrage nicht eindeutig. Es ist möglich, dass verschiedene Anfragen dieselbe Benutzer-ID verwenden. Die requestId ist global eindeutig und es gibt keine Verwirrung beim Sperren und Freigeben von Sperren. 🎜此外,使用lua脚本,也能解决释放了别人的锁的问题:
if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end
lua脚本能保证查询锁是否存在和删除锁是原子操作,用它来释放锁效果更好一些。
说到lua脚本,其实加锁操作也建议使用lua脚本:
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);这是redisson框架的加锁代码,写的不错,大家可以借鉴一下。
有趣,下面还有哪些好玩的东西?
4 大量失败请求
上面的加锁方法看起来好像没有问题,但如果你仔细想想,如果有1万的请求同时去竞争那把锁,可能只有一个请求是成功的,其余的9999个请求都会失败。
在秒杀场景下,会有什么问题?
答:每1万个请求,有1个成功。再1万个请求,有1个成功。如此下去,直到库存不足。这就变成均匀分布的秒杀了,跟我们想象中的不一样。
如何解决这个问题呢?
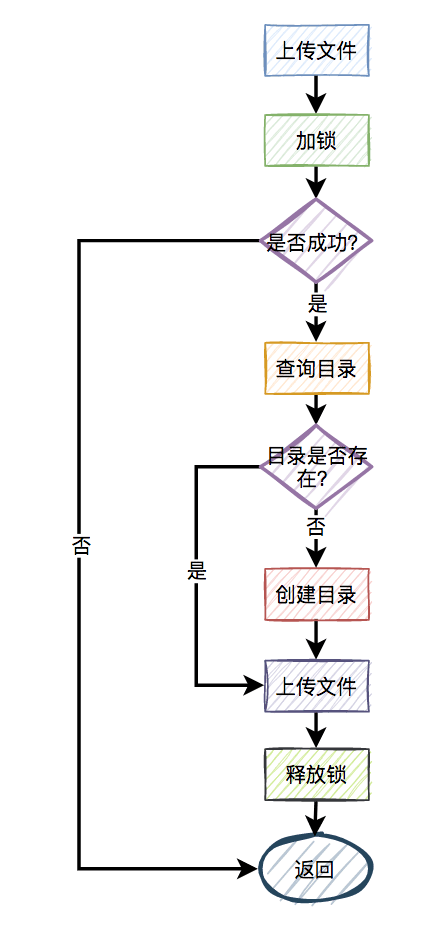
此外,还有一种场景:
比如,有两个线程同时上传文件到sftp,上传文件前先要创建目录。假设两个线程需要创建的目录名都是当天的日期,比如:20210920,如果不做任何控制,直接并发的创建目录,第二个线程必然会失败。
这时候有些朋友可能会说:这还不容易,加一个redis分布式锁就能解决问题了,此外再判断一下,如果目录已经存在就不创建,只有目录不存在才需要创建。
伪代码如下:
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;一切看似美好,但经不起仔细推敲。
来自灵魂的一问:第二个请求如果加锁失败了,接下来,是返回失败,还是返回成功呢?
主要流程图如下:
显然第二个请求,肯定是不能返回失败的,如果返回失败了,这个问题还是没有被解决。如果文件还没有上传成功,直接返回成功会有更大的问题。头疼,到底该如何解决呢?
答:使用自旋锁。
try {
Long start = System.currentTimeMillis();
while(true) {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
long time = System.currentTimeMillis() - start;
if (time>=timeout) {
return false;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} finally{
unlock(lockKey,requestId);
}
return false;在规定的时间,比如500毫秒内,自旋不断尝试加锁(说白了,就是在死循环中,不断尝试加锁),如果成功则直接返回。如果失败,则休眠50毫秒,再发起新一轮的尝试。如果到了超时时间,还未加锁成功,则直接返回失败。
好吧,学到一招了,还有吗?
5 锁重入问题
我们都知道redis分布式锁是互斥的。如果已经对一个key进行了加锁,并且该key对应的锁尚未失效,那么如果再次使用相同的key进行加锁,很可能会失败。
没错,大部分场景是没问题的。
为什么说是大部分场景呢?
因为还有这样的场景:
假设在某个请求中,需要获取一颗满足条件的菜单树或者分类树。我们以菜单为例,这就需要在接口中从根节点开始,递归遍历出所有满足条件的子节点,然后组装成一颗菜单树。
在后台系统中运营同学可以动态地添加、修改和删除菜单,因此需要注意菜单是可变的,不能一成不变。为了确保在并发情况下每次都可以获取到最新数据,可以使用Redis分布式锁。
加redis分布式锁的思路是对的。然而,随后出现了一个问题,即递归方法中进行多次递归遍历时,每次都需要获取同一把锁。当然,在递归的第一层可以成功加锁,但在第二、第三……第N层就会失败
递归方法中加锁的伪代码如下:
private int expireTime = 1000;
public void fun(int level,String lockKey,String requestId){
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(level<=10){
this.fun(++level,lockKey,requestId);
} else {
return;
}
}
return;
} finally {
unlock(lockKey,requestId);
}
}如果你直接这么用,看起来好像没有问题。但最终执行程序之后发现,等待你的结果只有一个:出现异常。
因为从根节点开始,第一层递归加锁成功,还没释放锁,就直接进入第二层递归。因为锁名为lockKey,并且值为requestId的锁已经存在,所以第二层递归大概率会加锁失败,然后返回到第一层。第一层接下来正常释放锁,然后整个递归方法直接返回了。
这下子,大家知道出现什么问题了吧?
没错,递归方法其实只执行了第一层递归就返回了,其他层递归由于加锁失败,根本没法执行。
那么这个问题该如何解决呢?
答:使用可重入锁。
我们以redisson框架为例,它的内部实现了可重入锁的功能。
古时候有句话说得好:为人不识陈近南,便称英雄也枉然。
我说:分布式锁不识redisson,便称好锁也枉然。哈哈哈,只是自娱自乐一下。
由此可见,redisson在redis分布式锁中的江湖地位很高。
伪代码如下:
private int expireTime = 1000;
public void run(String lockKey) {
RLock lock = redisson.getLock(lockKey);
this.fun(lock,1);
}
public void fun(RLock lock,int level){
try{
lock.lock(5, TimeUnit.SECONDS);
if(level<=10){
this.fun(lock,++level);
} else {
return;
}
} finally {
lock.unlock();
}
}上面的代码也许并不完美,这里只是给了一个大致的思路,如果大家有这方面需求的话,以上代码仅供参考。
接下来,聊聊redisson可重入锁的实现原理。
加锁主要是通过以下脚本实现的:
if (redis.call('exists', KEYS[1]) == 0) then redis.call('hset', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('hincrby', KEYS[1], ARGV[2], 1); redis.call('pexpire', KEYS[1], ARGV[1]); return nil; end; return redis.call('pttl', KEYS[1]);
其中:
KEYS[1]:锁名
ARGV[1]:过期时间
ARGV[2]:uuid + ":" + threadId,可认为是requestId
先判断如果锁名不存在,则加锁。
接下来,判断如果锁名和requestId值都存在,则使用hincrby命令给该锁名和requestId值计数,每次都加1。注意一下,这里就是重入锁的关键,锁重入一次值就加1。
如果锁名存在,但值不是requestId,则返回过期时间。
释放锁主要是通过以下脚本实现的:
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0)
then
return nil
end
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0)
then
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
return nil先判断如果锁名和requestId值不存在,则直接返回。
如果锁名和requestId值存在,则重入锁减1。
如果减1后,重入锁的value值还大于0,说明还有引用,则重试设置过期时间。
如果减1后,重入锁的value值还等于0,则可以删除锁,然后发消息通知等待线程抢锁。
再次强调一下,如果你们系统可以容忍数据暂时不一致,有些场景不加锁也行,我在这里只是举个例子,本节内容并不适用于所有场景。
6 锁竞争问题
如果有大量需要写入数据的业务场景,使用普通的redis分布式锁是没有问题的。
但如果有些业务场景,写入的操作比较少,反而有大量读取的操作。这样直接使用普通的redis分布式锁,会不会有点浪费性能?
我们都知道,锁的粒度越粗,多个线程抢锁时竞争就越激烈,造成多个线程锁等待的时间也就越长,性能也就越差。
所以,提升redis分布式锁性能的第一步,就是要把锁的粒度变细。
6.1 读写锁
众所周知,加锁的目的是为了保证,在并发环境中读写数据的安全性,即不会出现数据错误或者不一致的情况。
在大多数实际业务场景中,通常读取数据的频率远高于写入数据的频率。而线程间的并发读操作是并不涉及并发安全问题,我们没有必要给读操作加互斥锁,只要保证读写、写写并发操作上锁是互斥的就行,这样可以提升系统的性能。
我们以redisson框架为例,它内部已经实现了读写锁的功能。
读锁的伪代码如下:
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.readLock();
try {
rLock.lock();
//业务操作
} catch (Exception e) {
log.error(e);
} finally {
rLock.unlock();
}写锁的伪代码如下:
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.writeLock();
try {
rLock.lock();
//业务操作
} catch (InterruptedException e) {
log.error(e);
} finally {
rLock.unlock();
}将读锁和写锁分离的主要优点在于提高读取操作的性能,因为读取操作之间是共享的,而不存在互斥关系。而我们的实际业务场景中,绝大多数数据操作都是读操作。所以,如果提升了读操作的性能,也就会提升整个锁的性能。
下面总结一个读写锁的特点:
读与读是共享的,不互斥
读与写互斥
写与写互斥
6.2 锁分段
此外,为了减小锁的粒度,比较常见的做法是将大锁:分段。
在java中ConcurrentHashMap,就是将数据分为16段,每一段都有单独的锁,并且处于不同锁段的数据互不干扰,以此来提升锁的性能。
放在实际业务场景中,我们可以这样做:
比如在秒杀扣库存的场景中,现在的库存中有2000个商品,用户可以秒杀。为了防止出现超卖的情况,通常情况下,可以对库存加锁。如果有1W的用户竞争同一把锁,显然系统吞吐量会非常低。
为了提升系统性能,我们可以将库存分段,比如:分为100段,这样每段就有20个商品可以参与秒杀。
在秒杀过程中,先通过哈希函数获取用户ID的哈希值,然后对100取模。模为1的用户访问第1段库存,模为2的用户访问第2段库存,模为3的用户访问第3段库存,后面以此类推,到最后模为100的用户访问第100段库存。
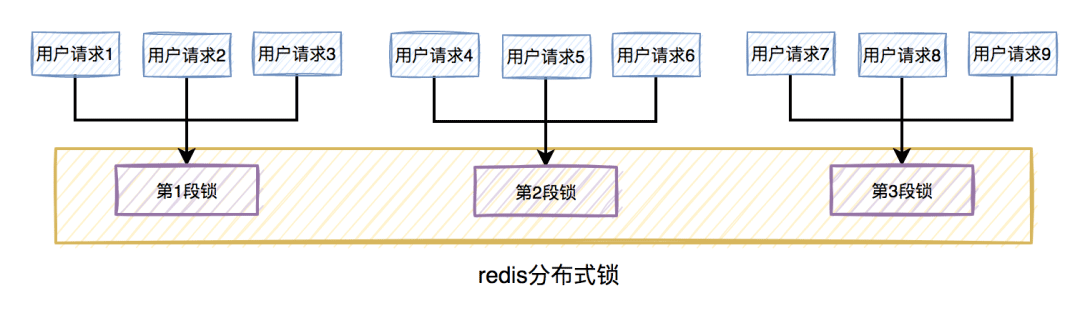
如此一来,在多线程环境中,可以大大的减少锁的冲突。以前多个线程只能同时竞争1把锁,尤其在秒杀的场景中,竞争太激烈了,简直可以用惨绝人寰来形容,其后果是导致绝大数线程在锁等待。由于多个线程同时竞争100把锁,等待线程数量减少,因此系统吞吐量提高了。
分段锁虽然能提高系统性能,但也会增加系统复杂度,需要注意。因为它需要引入额外的路由算法,跨段统计等功能。我们在实际业务场景中,需要综合考虑,不是说一定要将锁分段。
7 锁超时问题
我在前面提到过,如果线程A加锁成功了,但是由于业务功能耗时时间很长,超过了设置的超时时间,这时候redis会自动释放线程A加的锁。
有些朋友可能会说:到了超时时间,锁被释放了就释放了呗,对功能又没啥影响。
答:错,错,错。对功能其实有影响。
我们通常会对关键资源进行加锁,以避免在访问时产生数据异常。比如:线程A在修改数据C的值,线程B也在修改数据C的值,如果不做控制,在并发情况下,数据C的值会出问题。
为了保证某个方法,或者段代码的互斥性,即如果线程A执行了某段代码,是不允许其他线程在某一时刻同时执行的,我们可以用synchronized关键字加锁。
但这种锁有很大的局限性,只能保证单个节点的互斥性。如果需要在多个节点中保持互斥性,就需要用redis分布式锁。
做了这么多铺垫,现在回到正题。
假设线程A加redis分布式锁的代码,包含代码1和代码2两段代码。
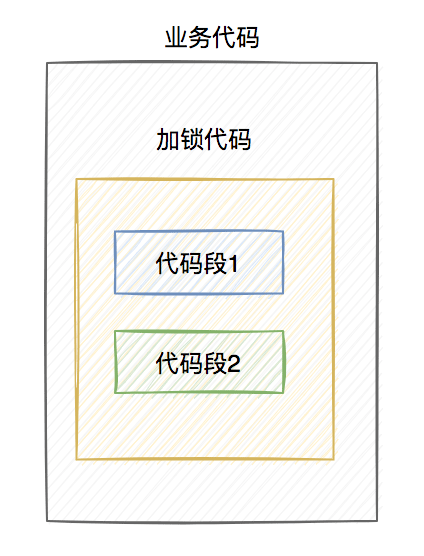
由于该线程要执行的业务操作非常耗时,程序在执行完代码1的时,已经到了设置的超时时间,redis自动释放了锁。而代码2还没来得及执行。
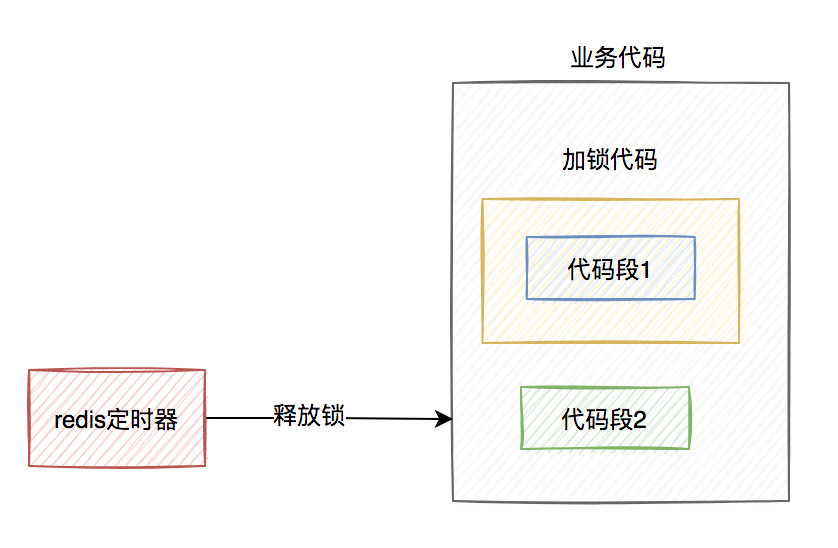
此时,代码2相当于裸奔的状态,无法保证互斥性。当多个线程访问同一临界资源时,如果存在并发访问,可能会导致数据异常。(PS:我说的访问临界资源,不单单指读取,还包含写入)
那么,如何解决这个问题呢?
答:如果达到了超时时间,但业务代码还没执行完,需要给锁自动续期。
我们可以使用TimerTask类,来实现自动续期的功能:
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//自动续期逻辑
}
}, 10000, TimeUnit.MILLISECONDS);获取锁之后,自动开启一个定时任务,每隔10秒钟,自动刷新一次过期时间。这种机制在redisson框架中,有个比较霸气的名字:watch dog,即传说中的看门狗。
当然自动续期功能,我们还是优先推荐使用lua脚本实现,比如:
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('pexpire', KEYS[1], ARGV[1]); return 1; end; return 0;
需要注意的地方是:在实现自动续期功能时,还需要设置一个总的过期时间,可以跟redisson保持一致,设置成30秒。自动续期将在总的过期时间到达后停止,即使业务代码未完成执行。
实现自动续期的功能需要在获得锁之后开启一个定时任务,每隔10秒检查一次锁是否存在,如果存在则更新过期时间。如果续期3次,也就是30秒之后,业务方法还是没有执行完,就不再续期了。
8 主从复制的问题
上面花了这么多篇幅介绍的内容,对单个redis实例是没有问题的。
but,如果redis存在多个实例。当使用主从复制或哨兵模式,并且基于Redis分布式锁功能进行操作时,可能会遇到问题。
具体是什么问题?
假定当前Redis采用主从复制模式,具有一个主节点和三个从节点。master节点负责写数据,slave节点负责读数据。
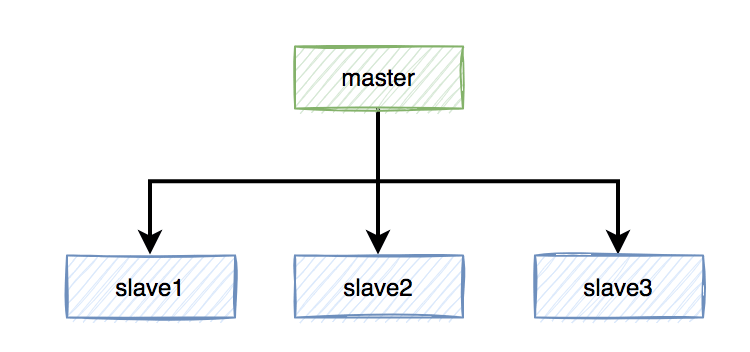
本来是和谐共处,相安无事的。在Redis中,加锁操作是在主节点上执行的,加锁成功后,会异步将锁同步到所有从节点。
突然有一天,master节点由于某些不可逆的原因,挂掉了。
这样需要找一个slave升级为新的master节点,假如slave1被选举出来了。
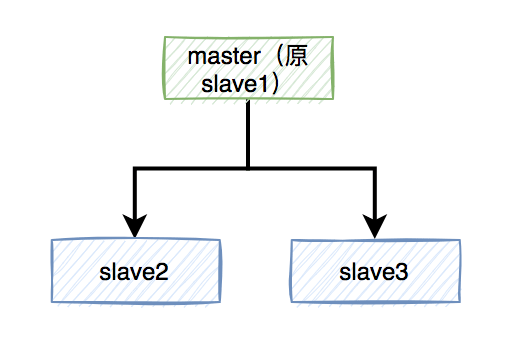
如果有个锁A比较悲催,刚加锁成功master就挂了,还没来得及同步到slave1。
这样会导致新master节点中的锁A丢失了。后面,如果有新的线程,使用锁A加锁,依然可以成功,分布式锁失效了。
那么,如何解决这个问题呢?
答:redisson框架为了解决这个问题,提供了一个专门的类:RedissonRedLock,使用了Redlock算法。
RedissonRedLock解决问题的思路如下:
需要搭建几套相互独立的redis环境,假如我们在这里搭建了5套。
每套环境都有一个redisson node节点。
Mehrere Redisson-Knoten bilden RedissonRedLock.
Die Umgebung umfasst: Standalone-, Master-Slave-, Sentinel- und Cluster-Modi, die einer oder eine Mischung aus mehreren sein können.
Hier nehmen wir das Master-Slave-Architekturdiagramm wie folgt:
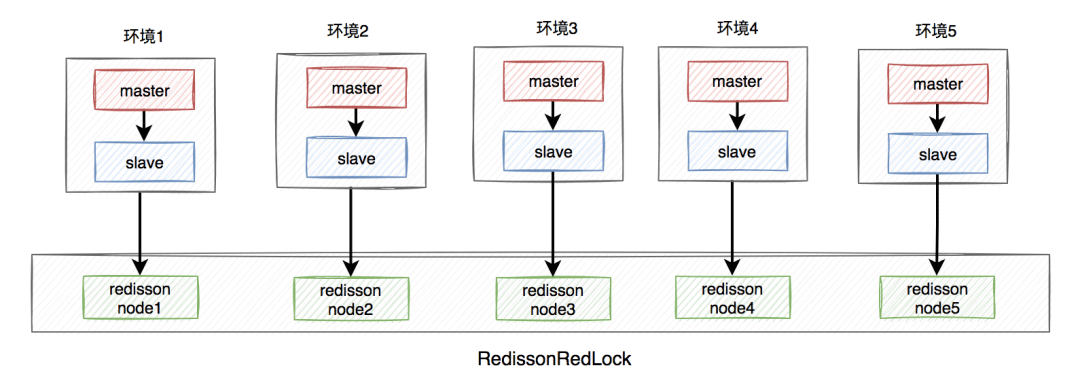
Der RedissonRedLock-Sperrprozess ist wie folgt:
Alle Redisson-Knoteninformationen abrufen und schleifen Für alle Redisson-Knoten ist die Knotensperre unter der Annahme, dass die Anzahl der Knoten N beträgt, im Beispiel N gleich 5.
Wenn unter N Knoten N/2 + 1 Knoten erfolgreich gesperrt sind, ist die gesamte RedissonRedLock-Sperre erfolgreich.
Wenn unter N Knoten weniger als N/2 + 1 Knoten erfolgreich gesperrt werden, schlägt die gesamte RedissonRedLock-Sperre fehl.
Wenn festgestellt wird, dass die Gesamtzeit, die für das Sperren jedes Knotens aufgewendet wurde, größer oder gleich der eingestellten maximalen Wartezeit ist, wird direkt ein Fehler zurückgegeben.
Wie aus dem Obigen ersichtlich ist, kann die Verwendung des Redlock-Algorithmus tatsächlich das Problem des Ausfalls verteilter Sperren in Szenarien mit mehreren Instanzen lösen, wenn der Masterknoten auflegt.
Aber es wirft auch einige neue Fragen auf, wie zum Beispiel:
Es ist notwendig, mehrere zusätzliche Umgebungen aufzubauen, mehr Ressourcen zu beantragen und das Kosten- und Preis-Leistungs-Verhältnis zu bewerten.
Wenn es N Redisson-Knoten gibt, muss es N-mal gesperrt werden, mindestens N/2+1-mal, um zu wissen, ob die Redlock-Sperre erfolgreich ist. Offensichtlich kommt noch der zusätzliche Zeitaufwand hinzu, der den Gewinn nicht wert ist.
Es ist ersichtlich, dass RedissonRedLock in tatsächlichen Geschäftsszenarien, insbesondere in Unternehmen mit hoher Parallelität, nicht häufig verwendet wird.
In einer verteilten Umgebung kann CAP nicht umgangen werden.
CAP bezieht sich in einem verteilten System auf:
Konsistenz
Verfügbarkeit
Partitionstoleranz
Jedes Element kann höchstens zwei Punkte gleichzeitig erreichen , und das ist es Es ist unmöglich, alle drei zu berücksichtigen.
In Ihrem tatsächlichen Geschäftsszenario ist die Gewährleistung der Datenkonsistenz wichtiger. Dann verwenden Sie bitte eine verteilte Sperre vom CP-Typ, z. B. zookeeper, die festplattenbasiert ist und die Leistung möglicherweise nicht so gut ist, aber im Allgemeinen gehen Daten nicht verloren.
In Ihrem tatsächlichen Geschäftsszenario ist es umso wichtiger, eine hohe Datenverfügbarkeit sicherzustellen. Es wird empfohlen, speicherbasierte verteilte Sperren zu verwenden, z. B. Sperren vom Typ AP in Redis. Obwohl die Leistung besser ist, besteht ein gewisses Risiko eines Datenverlusts.
Das obige ist der detaillierte Inhalt vonWas sind die Fallstricke verteilter Redis-Sperren?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!