
Wie Redis Spark beschleunigt

- PHPznach vorne
- 2023-06-03 11:45:361467Durchsuche
Apache Spark wird zunehmend zum Modell für Big-Data-Verarbeitungstools der nächsten Generation. Durch die Übernahme von Open-Source-Algorithmen und die Verteilung von Verarbeitungsaufgaben auf Cluster von Rechenknoten übertreffen Spark- und Hadoop-Generierungsframeworks sowohl die Art der Datenanalyse, die sie auf einer einzigen Plattform durchführen können, als auch die Geschwindigkeit, mit der sie diese Aufgaben ausführen können traditionelle Rahmenwerke. Spark nutzt Speicher zur Datenverarbeitung und ist damit deutlich schneller (bis zu 100-mal schneller) als festplattenbasiertes Hadoop.
Aber mit ein wenig Hilfe kann Spark noch schneller laufen. Wenn Sie Spark mit Redis (einer beliebten In-Memory-Datenstrukturspeichertechnologie) kombinieren, können Sie die Leistung bei der Verarbeitung von Analyseaufgaben noch einmal deutlich verbessern. Dies liegt an der optimierten Datenstruktur von Redis und seiner Fähigkeit, Komplexität und Overhead bei der Durchführung von Vorgängen zu minimieren. Die Verwendung von Konnektoren zur Verbindung mit Redis-Datenstrukturen und APIs kann Spark weiter beschleunigen.
Wie groß ist die Beschleunigung? Wenn Redis und Spark zusammen verwendet werden, stellt sich heraus, dass die Datenverarbeitung (zur Analyse der unten beschriebenen Zeitreihendaten) 45-mal schneller ist als Spark, der nur Prozessspeicher oder Off-Heap-Cache verwendet Daten speichern – Nicht 45 % schneller, aber ganze 45 Mal schneller!
Die Bedeutung der Analyse-Transaktionsgeschwindigkeit wächst von Tag zu Tag, da viele Unternehmen Analysen genauso schnell ermöglichen müssen wie Geschäftstransaktionen. Da immer mehr Entscheidungen automatisiert werden, sollten die für diese Entscheidungen erforderlichen Analysen in Echtzeit erfolgen. Apache Spark ist ein hervorragendes Allzweck-Datenverarbeitungsframework. Obwohl es nicht vollständig in Echtzeit funktioniert, ist es ein großer Schritt, um Daten zeitnah nutzbar zu machen.
Spark verwendet Resilient Distributed Datasets (RDDs), die im flüchtigen Speicher oder in einem persistenten Speichersystem wie HDFS gespeichert werden können. Alle über die Knoten des Spark-Clusters verteilten RDDs bleiben unverändert, es können jedoch durch Transformationsvorgänge andere RDDs erstellt werden.
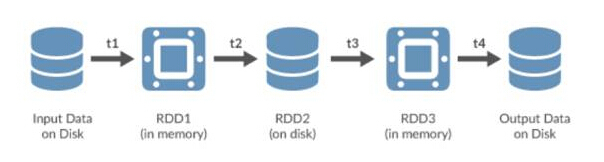
Spark RDD
RDD ist ein wichtiges abstraktes Objekt in Spark. Sie stellen eine fehlertolerante Methode zur effizienten Präsentation von Daten in einem iterativen Prozess dar. Durch die Verwendung der In-Memory-Verarbeitung wird die Verarbeitungszeit im Vergleich zur Verwendung von HDFS und MapReduce um Größenordnungen verkürzt.
Redis ist speziell für hohe Leistung konzipiert. Eine Latenzzeit von weniger als einer Millisekunde ist das Ergebnis optimierter Datenstrukturen, die die Effizienz verbessern, indem sie die Ausführung von Vorgängen in der Nähe des Speicherorts der Daten ermöglichen. Diese Datenstruktur nutzt nicht nur den Speicher effizient und reduziert die Anwendungskomplexität, sondern reduziert auch den Netzwerk-Overhead, den Bandbreitenverbrauch und die Verarbeitungszeit. Redis unterstützt mehrere Datenstrukturen, einschließlich Zeichenfolgen, Mengen, sortierte Mengen, Hashes, Bitmaps, Hyperloglogs und Geoindizes. Redis-Datenstrukturen sind wie Legosteine und bieten Entwicklern einfache Kanäle zur Implementierung komplexer Funktionen.
Um visuell zu zeigen, wie diese Datenstruktur die Verarbeitungszeit und Komplexität von Anwendungen vereinfachen kann, können wir genauso gut die Datenstruktur Sorted Set (Sorted Set) als Beispiel nehmen. Eine geordnete Menge ist im Grunde eine nach Punktzahl geordnete Menge von Mitgliedern.

Redis Sorted Collection
Hier können Sie viele Arten von Daten speichern, die automatisch nach Punktzahlen sortiert werden. Zu den gängigen Datentypen, die in geordneten Sammlungen gespeichert werden, gehören: Zeitreihendaten wie Artikel (nach Preis), Produktnamen (nach Menge), Aktienkurse und Sensormesswerte wie Zeitstempel.
Der Charme geordneter Mengen liegt in den integrierten Operationen von Redis, die es ermöglichen, Bereichsabfragen, Schnittmengen mehrerer geordneter Mengen, den Abruf nach Mitgliedsebene und -punktzahl sowie weitere Transaktionen einfach, mit extremer Geschwindigkeit und auf einem einfachen Weg auszuführen Großmaßstab umsetzen. Integrierte Vorgänge sparen nicht nur Code, der geschrieben werden muss, sondern die In-Memory-Ausführung reduziert auch die Netzwerklatenz und spart Bandbreite, was einen hohen Durchsatz mit Latenzen unter einer Millisekunde ermöglicht. Wenn Sie sortierte Sätze zur Analyse von Zeitreihendaten verwenden, können Sie im Vergleich zu anderen In-Memory-Schlüssel/Wert-Speichersystemen oder festplattenbasierten Datenbanken häufig Leistungsverbesserungen um mehrere Größenordnungen erzielen.
Der Spark-Redis-Connector wurde vom Redis-Team entwickelt, um die Analysefunktionen von Spark zu verbessern. Dieses Paket ermöglicht Spark die Verwendung von Redis als eine seiner Datenquellen. Über diesen Connector kann Spark direkt auf die Datenstruktur von Redis zugreifen und so die Leistung verschiedener Analysetypen erheblich verbessern.

Spark Redis Connector
Um die Vorteile von Spark zu demonstrieren, beschloss das Redis-Team, Zeitscheibenabfragen (Bereichsabfragen) in mehreren verschiedenen Szenarien durchzuführen, um die Zeitreihenanalyse in Spark horizontal zu vergleichen. Zu diesen Szenarien gehören: Spark speichert alle Daten im In-Heap-Speicher, Spark verwendet Tachyon als Off-Heap-Cache, Spark verwendet HDFS und eine Kombination aus Spark und Redis.
Das Redis-Team nutzte das Spark-Zeitreihenpaket von Cloudera, um ein Spark-Redis-Zeitreihenpaket zu erstellen, das die von Redis geordneten Sammlungen verwendet, um die Zeitreihenanalyse zu beschleunigen. Dieses Paket stellt nicht nur alle Datenstrukturen bereit, die Spark den Zugriff auf Redis ermöglichen, sondern führt auch zwei zusätzliche Aufgaben aus
Stellt automatisch sicher, dass Redis-Knoten mit dem Spark-Cluster konsistent sind, und stellt sicher, dass jeder Spark-Knoten lokale Redis-Daten verwendet, wodurch die Latenz optimiert wird.
Integration mit Spark-Datenrahmen- und Datenquellen-APIs, um Spark-SQL-Abfragen automatisch in den effizientesten Abrufmechanismus für Daten in Redis umzuwandeln.
Einfach ausgedrückt bedeutet dies, dass sich Benutzer keine Sorgen um die Betriebskonsistenz zwischen Spark und Redis machen müssen und weiterhin Spark SQL für Analysen verwenden können, während die Abfrageleistung erheblich verbessert wird.
Die in diesem direkten Vergleich verwendeten Zeitreihendaten umfassen: zufällig generierte Finanzdaten und 1024 Aktien pro Tag für 32 Jahre. Jede Aktie wird durch einen eigenen geordneten Satz dargestellt, der Score ist das Datum und die Datenelemente umfassen den Eröffnungspreis, den letzten Preis, den letzten Preis, den Schlusskurs, das Handelsvolumen und den angepassten Schlusskurs. Das folgende Bild zeigt die Datendarstellung in einem sortierten Redis-Satz, der für die Spark-Analyse verwendet wird:
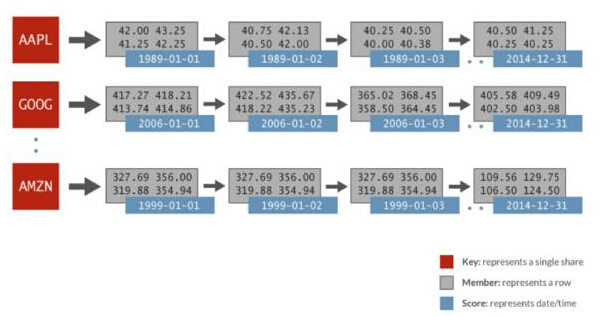
Spark Redis Time Series
Im obigen Beispiel gibt es in Bezug auf den sortierten Satz AAPL eine Darstellung jedes Tages ( 1989-01-01) und mehrere Werte im Laufe des Tages, dargestellt als eine zusammenhängende Zeile. Verwenden Sie dazu einfach einen einfachen ZRANGEBYSCORE-Befehl in Redis: Rufen Sie alle Werte für einen bestimmten Zeitabschnitt und damit alle Aktienkurse im angegebenen Datumsbereich ab. Redis kann diese Art von Abfragen schneller durchführen als andere Schlüssel-/Wertspeichersysteme, und zwar bis zu 100-mal schneller.
Dieser horizontale Vergleich bestätigt die Leistungsverbesserung. Es wurde festgestellt, dass Spark mit Redis Zeitscheibenabfragen 135-mal schneller durchführen kann als Spark mit HDFS und 45-mal schneller als Spark mit On-Heap-(Prozess-)Speicher oder Spark mit Tachyon als Off-Heap-Cache. Die folgende Abbildung zeigt die durchschnittliche Ausführungszeit im Vergleich für verschiedene Szenarien:
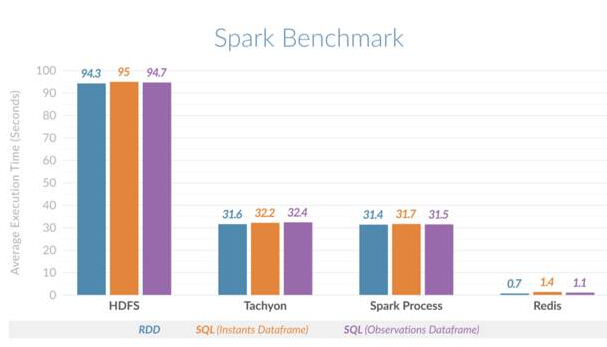
Spark Redis Horizontaler Vergleich
Diese Anleitung führt Sie Schritt für Schritt durch die Installation des Standard-Spark-Clusters und der Spark-Redis-Suite. Anhand eines einfachen Beispiels zum Zählen von Wörtern wird gezeigt, wie die Verwendung von Spark und Redis integriert werden kann. Nachdem Sie Spark und das Spark-Redis-Paket ausprobiert haben, können Sie weitere Szenarien erkunden, die andere Redis-Datenstrukturen nutzen.
Während geordnete Sätze gut für Zeitreihendaten geeignet sind, können die anderen Datenstrukturen von Redis wie Sätze, Listen und Geoindizes die Spark-Analyse weiter bereichern. Stellen Sie sich Folgendes vor: Ein Spark-Prozess versucht herauszufinden, welche Bereiche für die Einführung eines neuen Produkts geeignet sind, und berücksichtigt dabei Faktoren wie die Vorlieben des Publikums und die Entfernung vom Stadtzentrum, um den Einführungseffekt zu optimieren. Stellen Sie sich vor, wie Datenstrukturen wie Geoindizes und Sammlungen mit integrierten Analysefunktionen diesen Prozess erheblich beschleunigen könnten. Die Spark-Redis-Kombination bietet großartige Anwendungsaussichten.
Spark bietet eine breite Palette an Analysefunktionen, darunter SQL, maschinelles Lernen, Graph Computing und Spark Streaming. Mit den In-Memory-Verarbeitungsfunktionen von Spark erreichen Sie nur eine bestimmte Skalierung. Mit Redis können Sie jedoch noch einen Schritt weiter gehen: Durch die Verwendung der Datenstruktur von Redis können Sie nicht nur die Leistung verbessern, sondern Spark auch einfacher erweitern, indem Sie den von bereitgestellten Mechanismus zur gemeinsam genutzten verteilten Speicherdatenspeicherung vollständig nutzen Redis verarbeitet Hunderttausende Datensätze oder sogar Milliarden Datensätze.
Dieses Beispiel einer Zeitreihe ist nur der Anfang. Es wird erwartet, dass die Verwendung von Redis-Datenstrukturen für maschinelles Lernen und Diagrammanalyse auch erhebliche Zeitvorteile bei der Ausführung dieser Workloads mit sich bringt.
Das obige ist der detaillierte Inhalt vonWie Redis Spark beschleunigt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!