
So implementieren Sie die Suchschnittstelle mit Redis

- 王林nach vorne
- 2023-06-02 21:31:211120Durchsuche
Für Back-End-Entwickler kann eine einzelne SQL zum Implementieren der Listenabfrageschnittstelle verwendet werden. Wenn die Abfragebedingungen komplex und das Design der Tabellendatenbank unzumutbar sind, wird die Abfrage schwierig um die Suchschnittstelle zu implementieren.
Beginnen wir mit einem Beispiel: Wenn Sie gebeten würden, eine solche Suchoberfläche zu implementieren
Natürlich haben Sie das mit Hilfe von Suchmaschinen implementiert Elasticsearch, Sie können es auf jeden Fall schaffen. Aber was ich hier sagen möchte ist: Was ist, wenn Sie es selbst implementieren möchten?

Wie Sie auf dem Bild oben sehen können, ist die Suche in 6 Hauptkategorien unterteilt, und jede Hauptkategorie ist in Unterkategorien unterteilt.
In diesem Fall berücksichtigt der Filterprozess die Schnittmenge verschiedener Hauptkategorien von Bedingungen und berücksichtigt Einzelauswahl, Mehrfachauswahl und Anpassung in jeder Unterkategorie, um einen Ergebnissatz auszugeben, der die Bedingungen erfüllt.
Okay, jetzt, da die Anforderungen klar sind, beginnen wir mit der Umsetzung.
Implementierung 1
Als erster erscheint Student A. Er ist ein „Experte“ im Schreiben von SQL. Little A sagte zuversichtlich: „Ist es nicht nur eine Abfrageschnittstelle? Es gibt viele Bedingungen, aber mit meiner reichen SQL-Erfahrung ist das für mich kein Problem.“
Also habe ich das folgende Code-Snippet geschrieben (wobei MySQL als Beispiel hier):
select ... from table_1 left join table_2 left join table_3 left join (select ... from table_x where ...) tmp_1 ... where ... order by ... limit m,n
Der Code wurde in der Testumgebung ausgeführt und die Ergebnisse schienen übereinzustimmen, sodass er für die Vorabveröffentlichung bereit war. Mit diesem Vorabstart begannen Probleme aufzutauchen.
Die Vorabversion soll die Online-Umgebung so realistisch wie möglich gestalten, daher ist die Datenmenge natürlich viel größer als die des Tests. Für ein so komplexes SQL kann man sich also dessen Ausführungseffizienz vorstellen. Der Testklassenkamerad tippte entschlossen den Code von Little A ein.
Implementierung 2
Fasst die Lehren aus dem Scheitern von Little A zusammen. Little B begann mit der Optimierung von SQL. Zuerst wurde das Schlüsselwort EXPLAIN übergeben, um eine SQL-Leistungsanalyse durchzuführen, und an den Stellen, an denen Indizes hinzugefügt wurden, wurden Indizes hinzugefügt.
Teilen Sie eine komplexe SQL gleichzeitig in mehrere SQLs auf, und die Berechnungsergebnisse werden im Programmspeicher berechnet.
Der Pseudocode lautet wie folgt:
$result_1 = query('select ... from table_1 where ...');
$result_2 = query('select ... from table_2 where ...');
$result_3 = query('select ... from table_3 where ...');
...
$result = array_intersect($result_1, $result_2, $result_3, ...);
Diese Lösung ist in Bezug auf die Leistung offensichtlich viel besser als die erste, aber während der Funktionsabnahme hatte der Produktmanager immer noch das Gefühl, dass die Abfragegeschwindigkeit nicht schnell genug war.
Little B selbst weiß auch, dass jede Abfrage die Datenbank mehrmals abfragt. Aus historischen Gründen kann eine Einzeltabellenabfrage unter bestimmten Bedingungen nicht durchgeführt werden, sodass die Wartezeit für Abfragen unvermeidlich ist.
Implementierung 3
Little C sieht Optimierungspotenzial in der oben genannten Lösung. Er stellte fest, dass Little B kein Problem mit seinem Denken hatte. Er teilte die komplexen Bedingungen auf, berechnete die Ergebnismengen jeder Unterdimension und fasste schließlich alle Unterergebnismengen zusammen und führte sie zusammen, um das endgültige gewünschte Ergebnis zu erhalten.
Also überlegte er plötzlich, ob er die Ergebnismengen jeder Unterdimension im Voraus zwischenspeichern könnte. Dies würde es ihm ermöglichen, bei der Abfrage direkt die gewünschte Teilmenge abzurufen, ohne jedes Mal die Datenbank auf Berechnung überprüfen zu müssen.
Little C verwendet hier Redis zum Speichern von Cache-Daten. Der Hauptgrund für die Verwendung besteht darin, dass es eine Vielzahl von Datenstrukturen bereitstellt und es sehr einfach ist, Schnitt- und Vereinigungsoperationen für Mengen in Redis durchzuführen.
Der spezifische Plan ist wie in der Abbildung dargestellt:
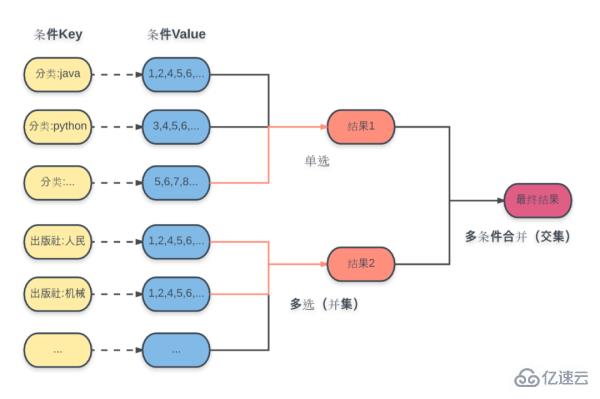
Für jede Bedingung wird hier die berechnete Ergebnissatz-ID im Voraus im entsprechenden Schlüssel gespeichert und die ausgewählte Datenstruktur festgelegt.
Abfrageoperationen umfassen:
Funkauswahl für Unterkategorien: Erhalten Sie direkt die entsprechende Ergebnismenge basierend auf dem Bedingungsschlüssel.
Mehrfachauswahl für Unterkategorien: Führen Sie eine Vereinigungsoperation basierend auf mehreren Bedingungsschlüsseln durch, um die entsprechende Ergebnismenge zu erhalten.
Endergebnis: Führen Sie eine Schnittoperation für alle erhaltenen Unterkategorie-Ergebnissätze durch, um das Endergebnis zu erhalten.
Das ist eigentlich der sogenannte Reverse-Index. Hier werden Sie feststellen, dass eine Preisbedingung fehlt. Aus der Nachfrage ist ersichtlich, dass die Preisbedingung eine Spanne ist und unendlich ist.
Daher ist die Schlüsselwertmethode mit den oben genannten erschöpfenden Bedingungen nicht möglich. Hier verwenden wir zur Implementierung die Datenstruktur des geordneten Satzes (Sorted Set) von Redis.
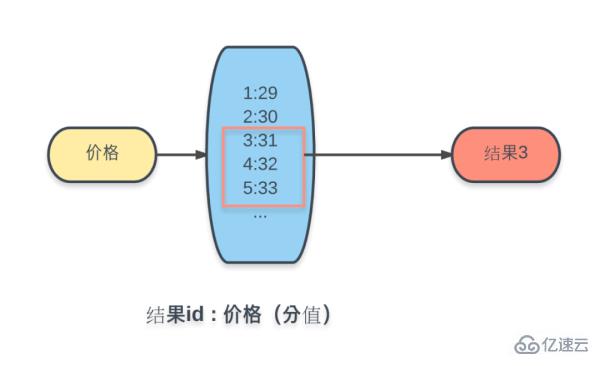
Fügen Sie alle Produkte zum geordneten Satz hinzu, deren Schlüssel der Preis, der Wert die Produkt-ID und jeder Wert entspricht Die Punktzahl ist der numerische Wert des Produktpreises.
Auf diese Weise können Sie im geordneten Satz von Redis den Befehl ZRANGEBYSCORE verwenden, um den entsprechenden Ergebnissatz basierend auf dem Bewertungsbereich (Preisbereich) zu erhalten.
Zu diesem Zeitpunkt ist die Optimierung von Plan 3 abgeschlossen und die Datenabfrage und -berechnung wurden durch Caching getrennt.
Bei jeder Suche müssen Sie Redis nur ein paar Mal durchsuchen, um das Ergebnis zu erhalten. Die Abfragegeschwindigkeit entspricht den Akzeptanzanforderungen.
Erweiterung
①Paging
Möglicherweise haben Sie hier einen schwerwiegenden Funktionsfehler entdeckt, wie kann Listenabfrage kein Paging haben? Ja, schauen wir uns gleich an, wie Redis Paging implementiert.
Bei der Paginierung geht es hauptsächlich um das Sortieren. Nehmen wir der Einfachheit halber die Erstellungszeit als Beispiel. Wie in der Abbildung gezeigt:
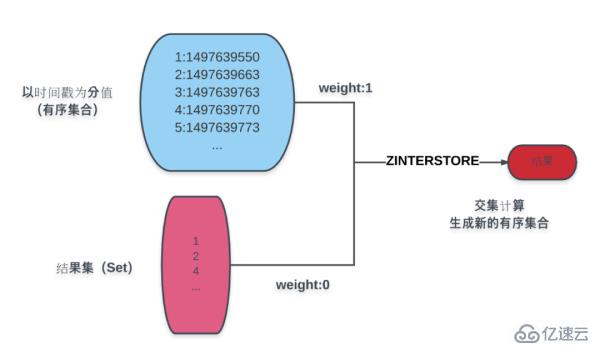
Der blaue Teil in der Abbildung ist eine geordnete Sammlung von Produkten basierend auf der Erstellungszeit. Der Ergebnissatz unter dem Blau ist das Ergebnis der bedingten Berechnung. Der Ergebnissatz wird über den Befehl ZINTERSTORE zugewiesen Das Gewicht ist 0, das Produktzeitergebnis ist 1 und die durch Schnittmenge erhaltene Ergebnismenge wird angegeben, um eine neue geordnete Menge von Zeitbewertungen zu erstellen.
Durch die Operation des neuen Ergebnissatzes können die verschiedenen für das Paging erforderlichen Daten abgerufen werden:
Die Gesamtzahl der Seiten beträgt: ZCOUNT-Befehl.
Aktueller Seiteninhalt: ZRANGE-Befehl.
Bei umgekehrter Anordnung: ZREVRANGE-Befehl.
②Datenaktualisierung
Bezüglich der Frage der Indexdatenaktualisierung gibt es zwei Möglichkeiten, vorzugehen. Eine besteht darin, den Aktualisierungsvorgang sofort durch die Änderung der Produktdaten auszulösen, und die andere darin, Stapelaktualisierungen über geplante Skripte durchzuführen.
Hier ist zu beachten, dass bei der Aktualisierung des Indexinhalts der Schlüssel zurückgesetzt werden muss, wenn er gewaltsam gelöscht wird.
Da die beiden Vorgänge in Redis nicht atomar ausgeführt werden, kann es zu Lücken dazwischen kommen. Es wird empfohlen, nur die ungültigen Elemente in der Sammlung zu entfernen und neue Elemente hinzuzufügen.
③Leistungsoptimierung
Redis ist eine Operation auf Speicherebene, sodass eine einzelne Abfrage sehr schnell erfolgt. Wenn in unserer Implementierung jedoch mehrere Redis-Vorgänge ausgeführt werden, kann es sein, dass die mehreren Redis-Verbindungszeiten unnötig viel Zeit in Anspruch nehmen.
Starten Sie mithilfe des MULTI-Befehls eine Transaktion, fügen Sie mehrere Redis-Vorgänge in einer Transaktion zusammen und führen Sie schließlich eine atomare Ausführung über EXEC durch.
Hinweis: Die sogenannte Transaktion führt hier nur mehrere Vorgänge in einer Verbindung aus. Wenn während der Ausführung ein Fehler auftritt, wird dieser nicht zurückgesetzt.
Zusammenfassung
Dies ist nur eine einfache Demo mit Redis zur Optimierung der Abfragesuche. Im Vergleich zu bestehenden Open-Source-Suchmaschinen ist es einfacher und die Lernkosten sind entsprechend geringer.
Zweitens ähneln einige seiner Ideen Open-Source-Suchmaschinen. Wenn die Wortanalyse hinzugefügt wird, können auch Funktionen erreicht werden, die der Volltextsuche ähneln.
Das obige ist der detaillierte Inhalt vonSo implementieren Sie die Suchschnittstelle mit Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!