
Heim >Technologie-Peripheriegeräte >KI >Was tun, wenn das große Modellwissen nicht mehr vorhanden ist? Das Team der Zhejiang-Universität erforscht Methoden zur Aktualisierung von Parametern großer Modelle – Modellbearbeitung
Was tun, wenn das große Modellwissen nicht mehr vorhanden ist? Das Team der Zhejiang-Universität erforscht Methoden zur Aktualisierung von Parametern großer Modelle – Modellbearbeitung

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-30 22:11:091408Durchsuche
Xi Xiaoyao Science and Technology Talk Originalautor |. Xiaoxi, Python
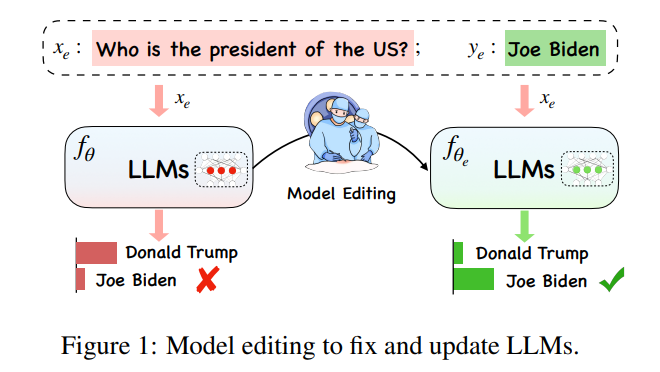
Hinter der enormen Größe großer Modelle steckt eine intuitive Frage: „Wie sollten große Modelle aktualisiert werden?“
Unter dem extrem großen Rechenaufwand großer Modelle Modelle Das Aktualisieren des Modellwissens ist keine einfache „Lernaufgabe“. Angesichts der komplexen Veränderungen in verschiedenen Situationen auf der Welt sollten große Modelle jederzeit und überall mit der Zeit Schritt halten, aber die Berechnung des Trainings eines neuen großen Modells ist eine Belastung Daher wurde ein neues Konzept „Modellbearbeitung“ entwickelt, um in bestimmten Bereichen wirksame Änderungen an Modelldaten zu erzielen, ohne dass sich dies negativ auf andere Eingaben auswirkt.

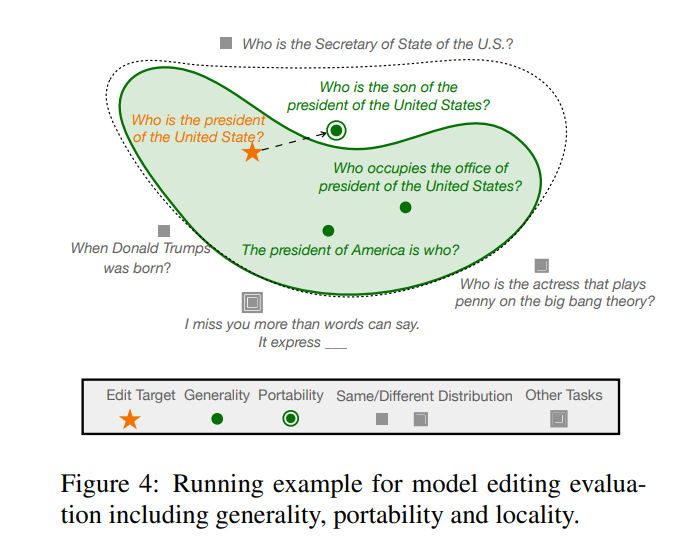
Darunter stellt es den „effektiven Nachbarn“ von dar, der den Bereich außerhalb des Geltungsbereichs von darstellt. Ein bearbeitetes Modell sollte die folgenden drei Punkte erfüllen, nämlich Zuverlässigkeit, Universalität und Lokalität. Zuverlässigkeit bedeutet, dass das bearbeitete Modell in der Lage sein sollte, Fehlerbeispiele im vorbearbeiteten Modell korrekt auszugeben, was durch die durchschnittliche Genauigkeit des bearbeiteten Modells bestimmt werden kann In einigen Fällen bedeutet Universalität, dass das Modell in der Lage sein sollte, eine korrekte Ausgabe für die „effektiven Nachbarn“ zu liefern. Das Modell sollte dennoch die Vorbearbeitungsgenauigkeit in Beispielen außerhalb des Bearbeitungsbereichs beibehalten. Die Lokalität kann durch separate Messung des Durchschnitts charakterisiert werden Genauigkeit vor und nach der Bearbeitung, wie in der folgenden Abbildung dargestellt, an der Bearbeitungsposition „Trump“, einige andere öffentliche Merkmale sollten nicht geändert werden. Gleichzeitig sollten andere Einheiten, wie etwa der „Secretary of State“, trotz ähnlicher Merkmale wie der „President“ nicht betroffen sein.
Der heute vorgestellte Artikel der Zhejiang-Universität beschreibt detailliert die Probleme, Methoden und die Zukunft der Modellbearbeitung im Zeitalter großer Modelle und stellt einen neuen Maßstab dar Bewertungsindikatoren helfen dabei, bestehende Technologien umfassender zu bewerten und liefern der Community aussagekräftige Entscheidungsvorschläge und Erkenntnisse zur Methodenauswahl:
Papiertitel: Bearbeiten großer Sprachmodelle: Probleme, Methoden und Chancen
Papierlink: https://arxiv .org/pdf/2305.13172.pdf
Mainstream-Methoden
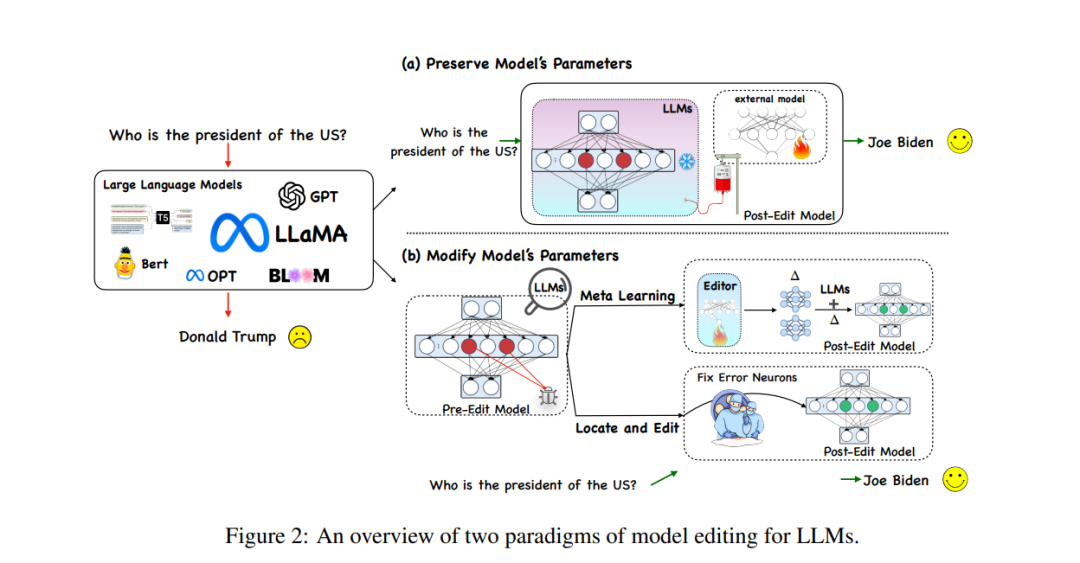
Die aktuellen Modellbearbeitungsmethoden für große Sprachmodelle (LLMs) sind hauptsächlich in zwei Arten von Paradigmen unterteilt, wie in der folgenden Abbildung dargestellt, nämlich Wie in Abbildung (a) dargestellt ) unten werden zusätzliche Parameter verwendet, während die ursprünglichen Modellparameter unverändert bleiben, und die internen Parameter des Modells werden geändert, wie in Abbildung (b) unten gezeigt.
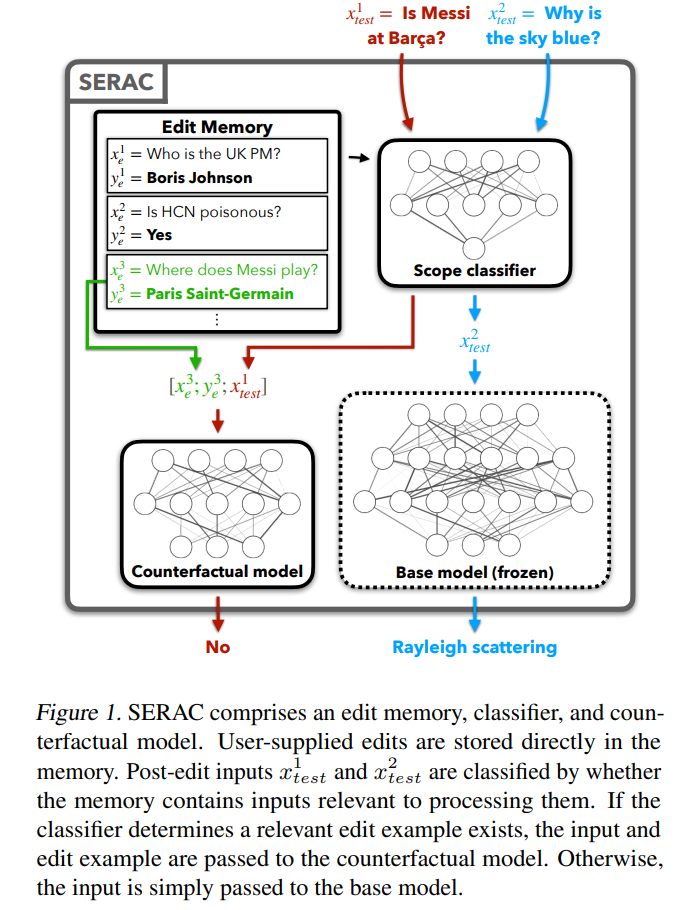
Schauen wir uns zunächst die relativ einfache Methode zum Hinzufügen zusätzlicher Parameter an. Diese Methode wird auch als Speicher- oder speicherbasierte Modellbearbeitungsmethode bezeichnet. Die repräsentative Methode SERAC erschien erstmals in Mitchells Artikel, in dem sie „Modellbearbeitung“ vorschlug Die Kernidee besteht darin, die ursprünglichen Parameter des Modells unverändert zu lassen und die geänderten Fakten über einen unabhängigen Parametersatz erneut zu verarbeiten. Insbesondere fügt diese Art von Methode im Allgemeinen zunächst einen „Bereichsklassifikator“ hinzu, um zu bestimmen, ob die neue Eingabe innerhalb des „überarbeiteten“ Bereichs liegt. Innerhalb des Faktenbereichs wird die Eingabe mit einem unabhängigen Parametersatz verarbeitet, was eine höhere Auswahlwahrscheinlichkeit für die „richtige Antwort“ im Cache ergibt. Basierend auf SERAC führen T-Patcher und CaliNET zusätzliche trainierbare Parameter in das Feedforward-Modul von PLMs ein (anstatt ein zusätzliches Modell einzustecken). Diese Parameter werden auf den geänderten Faktendatensatz trainiert, um den Effekt der Modellbearbeitung zu erzielen.
Eine weitere Hauptkategorie von Methoden, die Methode zum Ändern der Parameter im Originalmodell, verwendet hauptsächlich eine Δ-Matrix, um einige Parameter im Modell zu aktualisieren. Insbesondere kann die Methode zum Ändern von Parametern in „Lokalisieren-Dann-“ unterteilt werden. Bearbeiten“ Es gibt zwei Arten von Methoden: Meta-Lernen und Meta-Lernen. Wie aus dem Namen hervorgeht, lokalisiert die Locate-Then-Edit-Methode zunächst die wichtigsten Einflussparameter im Modell und ändert dann die gefundenen Modellparameter Die wichtigsten Methoden sind die Knowledge Neuron-Methode (KN), die die wichtigsten Einflussparameter durch die Identifizierung von „Wissensneuronen“ bestimmt und das Modell durch Aktualisierung dieser Neuronen aktualisiert zu KN und lokalisiert den Bearbeitungsbereich durch kausale Zwischenanalyse. Darüber hinaus gibt es eine MEMIT-Methode, die eine Reihe von Bearbeitungsbeschreibungen aktualisieren kann. Das größte Problem bei dieser Art von Methode besteht darin, dass sie im Allgemeinen auf der Annahme der Lokalität des Faktenwissens beruht, diese Annahme jedoch nicht umfassend überprüft wurde und die Bearbeitung vieler Parameter zu unerwarteten Ergebnissen führen kann.
Die Meta-Lernmethode unterscheidet sich von der Locate-Then-Edit-Methode. Die Meta-Lernmethode verwendet die Hypernetzwerkmethode und verwendet ein Hypernetzwerk, um Gewichte für ein anderes Netzwerk zu generieren Wissenseditor Bei dieser Methode verwendet der Autor ein bidirektionales LSTM, um die Aktualisierung vorherzusagen, die jeder Datenpunkt zum Modellgewicht bringt, und erreicht so eine eingeschränkte Optimierung des Bearbeitungszielwissens. Diese Art der Wissensbearbeitung ist aufgrund der großen Anzahl von Parametern in LLMs schwierig. Daher haben Mitchell et al. vorgeschlagen, dass eine einzige Bearbeitungsbeschreibung LLMs effektiv aktualisieren kann Die Aktualisierungsmethode verwendet hauptsächlich die Zerlegung von Gradienten mit niedrigem Rang, um die Gradienten großer Modelle zu optimieren und so minimale Ressourcenaktualisierungen für LLMs zu ermöglichen. Im Gegensatz zur Locate-Then-Edit-Methode dauern Meta-Learning-Methoden normalerweise länger und verbrauchen höhere Speicherkosten.
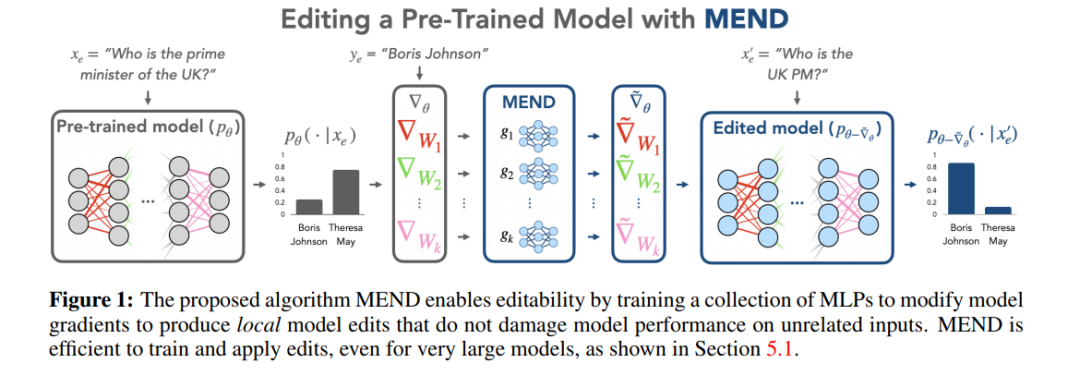
Methodenbewertung
Diese unterschiedlichen Methoden werden in den beiden Mainstream-Datensätzen der Modellbearbeitung, ZsRE (Frage- und Antwortdatensatz), verwendet Mithilfe von Reverse-Experimenten wurden zwei LLMs durchgeführt, die größer waren als die zuvor untersuchten (Neuformulierung des durch die Übersetzung erzeugten Problems als effektive Domäne) und COUNTERFACT (kontrafaktischer Datensatz, bei dem die Subjektentität durch eine synonyme Entität als effektive Domäne ersetzt wurde). Als Grundmodelle werden T5-XL (3B) und GPT-J (6B) verwendet. Ein effizienter Modelleditor sollte ein Gleichgewicht zwischen Modellleistung, Inferenzgeschwindigkeit und Speicherplatz herstellen.
Wenn man die Ergebnisse der Feinabstimmung (FT) in der ersten Spalte vergleicht, kann man feststellen, dass SERAC und ROME bei den ZsRE- und COUNTERFACT-Datensätzen eine gute Leistung erbringen, insbesondere SERAC, das mehr als 90 erreicht Mehrere Bewertungsindikatoren. Obwohl MEMIT nicht so vielseitig ist wie SERAC und ROME, schneidet es in Bezug auf Zuverlässigkeit und Lokalität gut ab. Die T-Patcher-Methode weist eine gute Zuverlässigkeit und Lokalität im COUNTERFACT-Datensatz auf, es mangelt ihr jedoch an Allgemeingültigkeit, die Leistung ist jedoch schlecht. Es ist erwähnenswert, dass die Leistung von KE, CaliNET und KN im Vergleich zur guten Leistung dieser Modelle in „kleinen Modellen“ schlecht ist. Die Experimente könnten beweisen, dass diese Methoden nicht gut an die Umgebung großer Modelle angepasst sind.
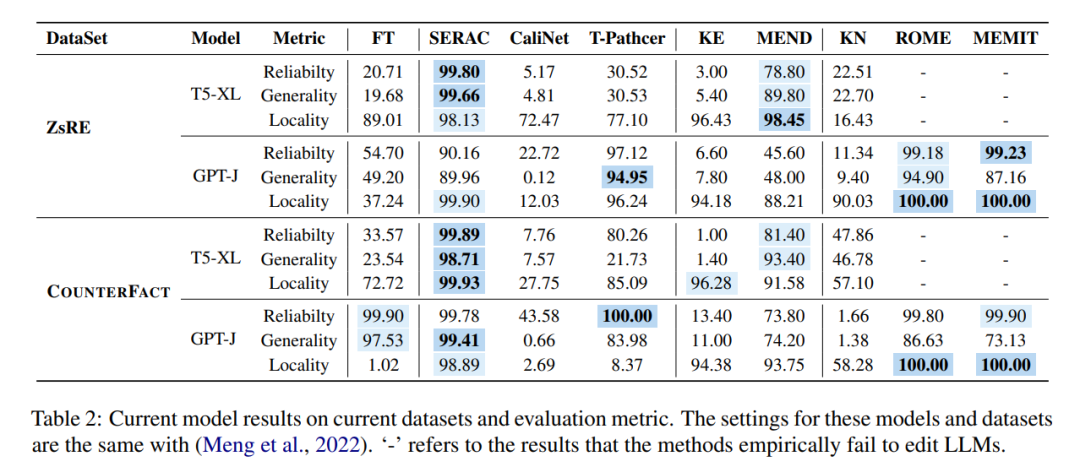
Aus zeitlicher Sicht funktionieren KE und MEND nach dem Training des Netzwerks sehr gut, während Methoden wie T-Patcher zeitaufwändig sind ist zu ernst:
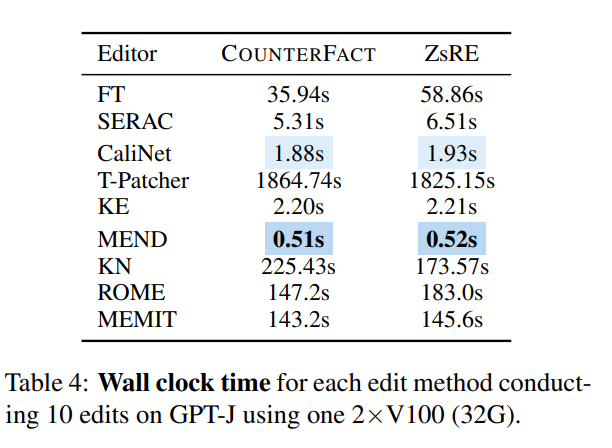
Aus Sicht des Speicherverbrauchs verbrauchen die meisten Methoden Speicher in der gleichen Größenordnung, aber Methoden, die zusätzliche Parameter einführen, tragen dazu bei die Belastung Zusätzlicher Speicheraufwand:
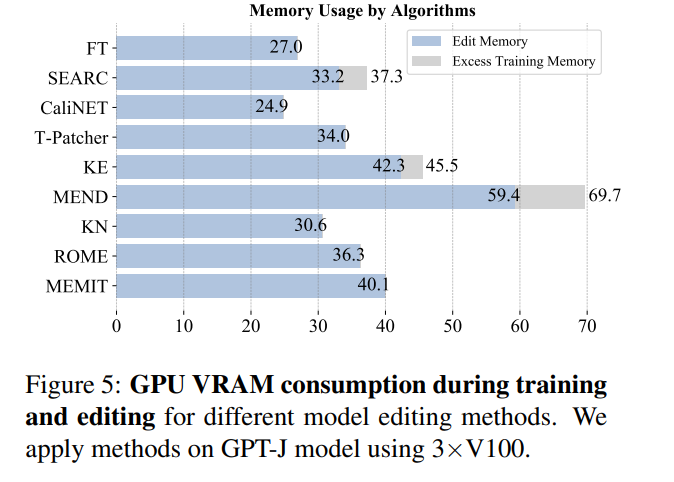
Gleichzeitig muss der Modellbearbeitungsvorgang normalerweise auch Batch-Input-Bearbeitungsinformationen und sequentielle Eingabebearbeitungsinformationen berücksichtigen. Das heißt, eine Aktualisierung mehrerer Fakteninformationen und die sequentielle Aktualisierung mehrerer Fakteninformationen. Der Gesamtmodelleffekt der Batch-Eingabebearbeitungsinformationen ist in der folgenden Abbildung dargestellt. Sie können sehen, dass MEMIT die gleichzeitige Bearbeitung von mehr als 10.000 Informationen unterstützen kann Zeit und kann auch sicherstellen, dass die Leistung beider Metriken stabil bleibt, während MEND und SERAC schlecht abschneiden:
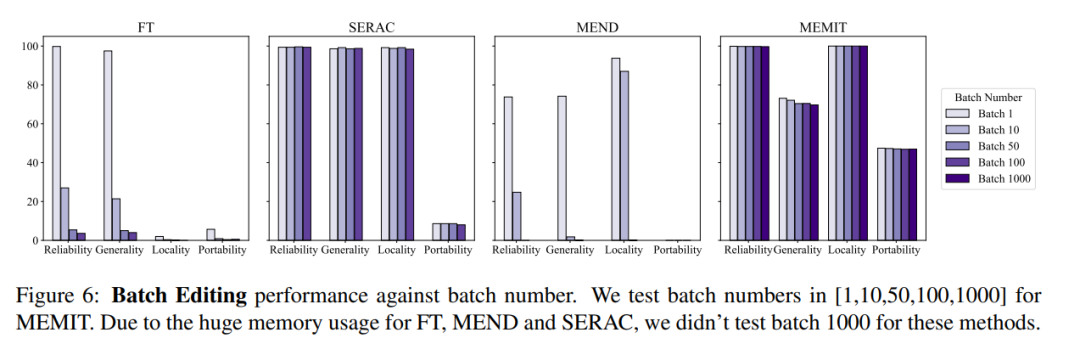
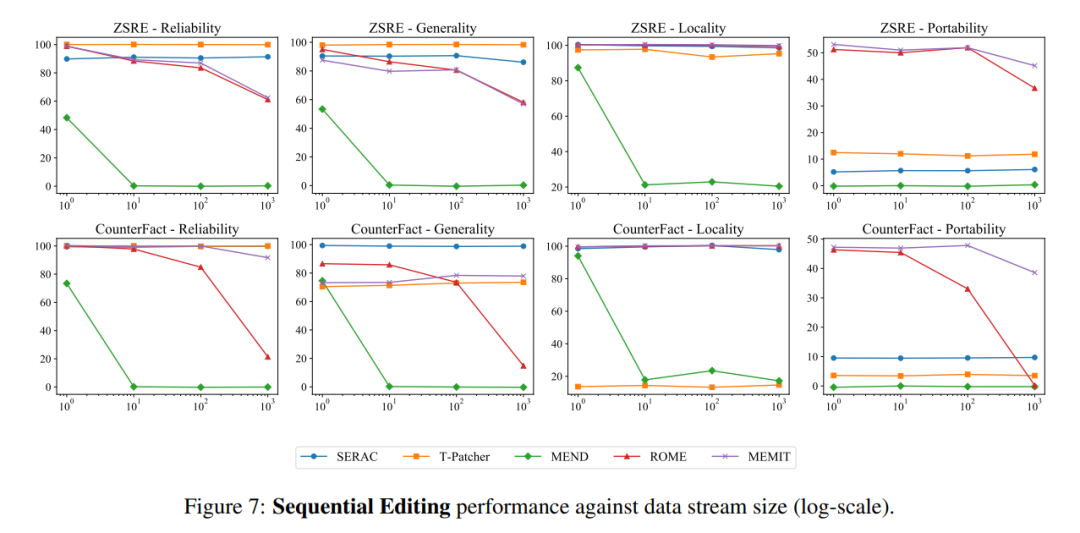
In Bezug auf die sequentielle Eingabe verzeichneten SERAC und T-Patcher nach einer bestimmten Anzahl von Fällen eine gute und stabile Leistung Eingaben. Phänomen:
Schließlich stellte der Autor in der Forschung fest, dass sich die aktuellen Konstruktions- und Bewertungsindikatoren dieser Datensätze größtenteils nur auf die Formulierung von Sätzen konzentrieren. Änderungen, die jedoch nicht so weit gehen wie die Änderungen des Modelleditors an vielen relevanten logischen Fakten. Wenn beispielsweise die Antwort auf „Watts Humphrey besuchte das College“ von Trinity College in die University of Michigan geändert wird, natürlich, wenn wir das Modell fragen: „ Watts Humphrey besuchte das College. „In welcher Stadt leben Sie?“ sollte das ideale Modell Ann Arbor anstelle von Hartford beantworten. Daher führten die Autoren des Papiers einen „Portabilitäts“-Indikator ein, der auf den ersten drei Bewertungsindikatoren basiert, um das Wissen zu messen des bearbeiteten Modells.
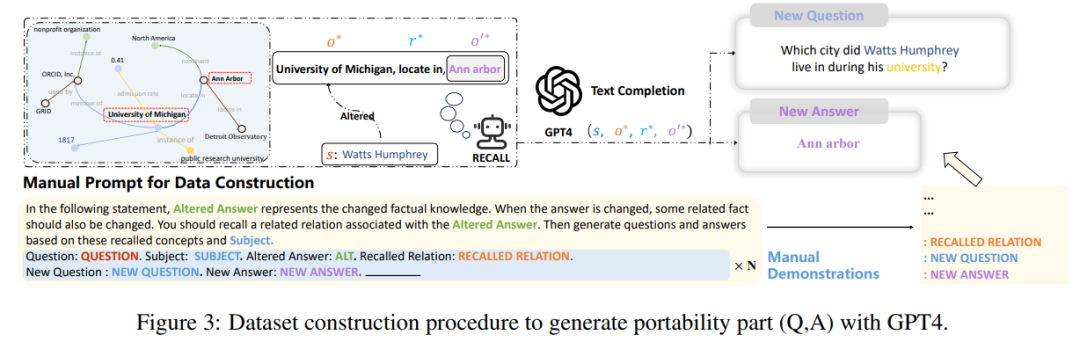
Zu diesem Zweck erstellte der Autor einen neuen Datensatz mit GPT-4, indem er die Antwort auf die ursprüngliche Frage von in änderte und weitere Fragen erstellte Wenn die korrekte Antwort aus Tripeln besteht und das bearbeitete Modell korrekt ausgegeben werden kann, beweist dies, dass das bearbeitete Modell „tragbar“ ist Der Portabilitätswert ist in der folgenden Abbildung dargestellt:
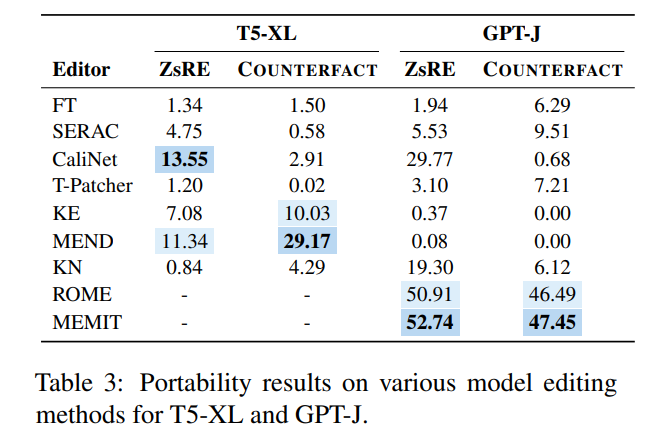
Es ist ersichtlich, dass fast die überwiegende Mehrheit der Modellbearbeitungsmethoden im Hinblick auf die Portabilität nicht ideal sind. Die herausragende Portabilitätsgenauigkeit von SERAC beträgt weniger als 10 %, und die relativ besten ROME und MEMIT haben ein Maximum von nur etwa 50 %. Dies zeigt, dass es mit der aktuellen Modellbearbeitungsmethode nahezu schwierig ist, eine Erweiterung und Förderung des bearbeiteten Modells zu erreichen Bearbeitung Es liegt noch ein langer Weg vor uns.
Diskussion und Zukunft
Egal in welchem Sinne, das Problem der Model-Editing-Presets hat in der sogenannten „Big-Model-Ära“ in der Zukunft großes Potenzial besser untersucht werden, wie zum Beispiel „In welchen Parametern wird das Modellwissen gespeichert?“ und „Wie können Modellbearbeitungsvorgänge die Ausgabe anderer Module nicht beeinflussen?“ Um das Problem zu lösen, dass das Modell „veraltet“ ist, besteht eine weitere Idee darin, das Modell „lebenslang lernen“ zu lassen und sensibles Wissen „vergessen“ zu lassen, unabhängig davon, ob es sich um eine Modellbearbeitung handelt oder nicht Modell für lebenslanges Lernen. Solche Forschung wird einen sinnvollen Beitrag zu den Sicherheits- und Datenschutzproblemen von LLMs leisten.
Das obige ist der detaillierte Inhalt vonWas tun, wenn das große Modellwissen nicht mehr vorhanden ist? Das Team der Zhejiang-Universität erforscht Methoden zur Aktualisierung von Parametern großer Modelle – Modellbearbeitung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr