
Heim >Technologie-Peripheriegeräte >KI >In Anlehnung an die göttliche Zusammenfassung von Jeff Dean teilte ein ehemaliger Google-Ingenieur „LLM-Entwicklungsgeheimnisse' mit: Zahlen, die jeder Entwickler kennen sollte!
In Anlehnung an die göttliche Zusammenfassung von Jeff Dean teilte ein ehemaliger Google-Ingenieur „LLM-Entwicklungsgeheimnisse' mit: Zahlen, die jeder Entwickler kennen sollte!

- 王林nach vorne
- 2023-05-25 22:25:291479Durchsuche
Kürzlich hat ein Internetnutzer eine Liste mit „Zahlen, die jeder LLM-Entwickler kennen sollte“ zusammengestellt und erklärt, warum diese Zahlen wichtig sind und wie wir sie verwenden sollten.
Als er bei Google war, gab es ein vom legendären Ingenieur Jeff Dean zusammengestelltes Dokument mit dem Titel „Zahlen, die jeder Ingenieur kennen sollte“.

Jeff Dean: „Zahlen, die jeder Ingenieur kennen sollte“
Für LLM-Entwickler (Large Language Model) gibt es einen ähnlichen Satz grober Schätzungen. Auch Zahlen sind sehr nützlich.

Prompt
40-90%: Kosteneinsparungen nach dem Hinzufügen von „prägnant und prägnant“ zur Eingabeaufforderung
Sie müssen wissen, dass Sie sich auf das von LLM während der Ausgabe verwendete Token verlassen Bezahlt.
Das bedeutet, dass Sie viel Geld sparen können, indem Sie Ihr Modell prägnant gestalten.
Gleichzeitig kann dieses Konzept auf weitere Orte ausgeweitet werden.
Zum Beispiel wollten Sie ursprünglich GPT-4 verwenden, um 10 Alternativen zu generieren, aber jetzt können Sie es möglicherweise bitten, zuerst 5 bereitzustellen, und dann können Sie die andere Hälfte des Geldes behalten.
1.3: Die durchschnittliche Anzahl von Token pro Wort
LLM arbeitet in Token-Einheiten.
Und ein Token ist ein Wort oder ein Teil eines Wortes. Beispielsweise kann „essen“ in zwei Token zerlegt werden: „essen“ und „ing“.
Im Allgemeinen generieren 750 englische Wörter etwa 1000 Token.
Für andere Sprachen als Englisch wird die Anzahl der Token pro Wort erhöht, abhängig von ihrer Gemeinsamkeit im Einbettungskorpus von LLM.

Preis
Angesichts der Tatsache, dass die Kosten für die Nutzung von LLM sehr hoch sind, werden die preisbezogenen Zahlen besonders wichtig.
~50: Kostenverhältnis von GPT-4 vs. GPT-3.5 Turbo
Die Verwendung von GPT-3.5-Turbo ist etwa 50-mal günstiger als GPT-4. Ich sage „ungefähr“, weil GPT-4 für Eingabeaufforderungen und Generierung unterschiedliche Gebühren erhebt.
In der tatsächlichen Anwendung ist es also am besten, zu bestätigen, ob GPT-3.5-Turbo ausreicht, um Ihre Anforderungen zu erfüllen.
Für Aufgaben wie das Zusammenfassen ist beispielsweise GPT-3.5-Turbo mehr als ausreichend.


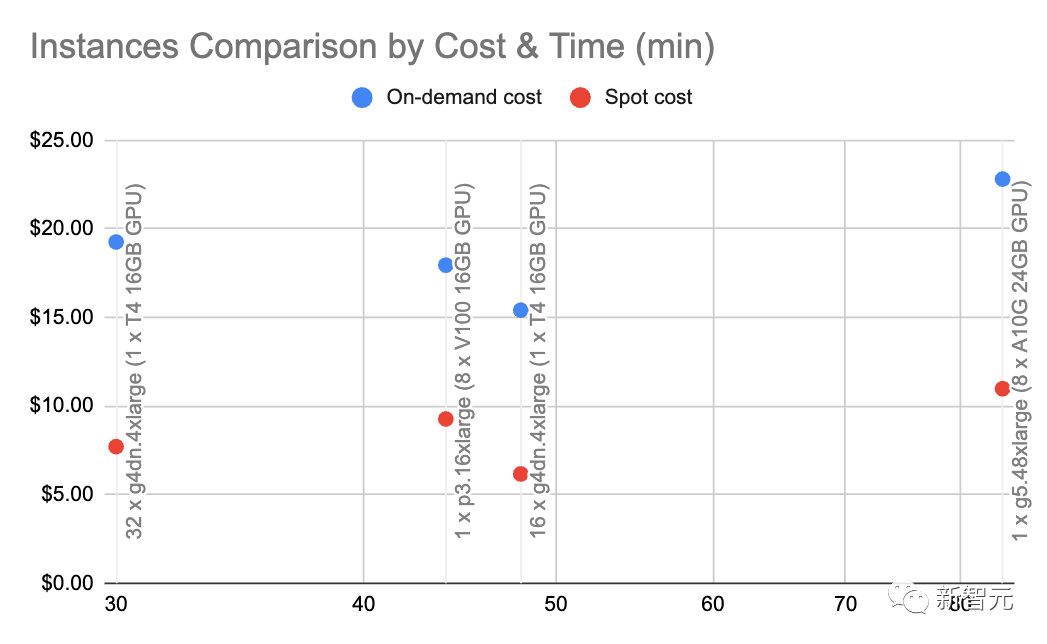
5 Es ist viel günstiger, die LLM-Generierung zu nutzen. Konkret kostet die Suche im neuronalen Informationsabrufsystem etwa fünfmal weniger als die Abfrage nach GPT-3.5-Turbo. Im Vergleich zu GPT-4 beträgt der Kostenunterschied das 250-fache! 10: Kostenverhältnis von OpenAI-Einbettung vs. selbstgehosteter Einbettung Hinweis: Diese Zahl hängt sehr stark von der Last und der eingebetteten Batchgröße ab. Betrachten Sie sie daher bitte als Näherungswert. Mit g4dn.4xlarge (On-Demand-Preis: 1,20 $/Stunde) können wir SentenceTransformers mit HuggingFace (vergleichbar mit den Einbettungen von OpenAI) nutzen, damit die Einbettung erfolgt mit einer Rate von etwa 9.000 Token pro Sekunde. Die Durchführung einiger grundlegender Berechnungen mit dieser Geschwindigkeit und diesem Knotentyp zeigt, dass selbst gehostete Einbettungen 10-mal günstiger sein können. 6: Kostenverhältnis von OpenAI-Basismodell und fein abgestimmter Modellabfrage Dies bedeutet auch, dass es kostengünstiger ist, die Spitzen des Basismodells anzupassen, als ein individuelles Modell zu verfeinern.
1: Kostenverhältnis des selbstgehosteten Basismodells im Vergleich zu fein abgestimmten Modellabfragen# 🎜🎜## 🎜🎜#Wenn Sie das Modell selbst hosten, sind die Kosten für das fein abgestimmte Modell fast die gleichen wie für das Basismodell: Die Anzahl der Parameter ist bei beiden Modellen gleich. Training und Feinabstimmung Papieradresse: https://arxiv.org/pdf/2302.13971.pdf #🎜 🎜#In der Arbeit von LLaMa wurde erwähnt, dass sie 21 Tage gebraucht und 2048 A100 80 GB GPUs verwendet haben, um das LLaMa-Modell zu trainieren. Angenommen, wir trainieren unser Modell auf dem Red Pajama-Trainingsset, alles ist in Ordnung, ohne Abstürze, und es gelingt beim ersten Mal, dann erhalten wir die oben genannten Zahlen . Darüber hinaus beinhaltet dieser Prozess auch die Koordination zwischen 2048 GPUs. Die meisten Unternehmen haben nicht die Voraussetzungen dafür. Die wichtigste Botschaft ist jedoch: Es ist möglich, unser eigenes LLM zu trainieren, aber der Prozess ist nicht billig. Und jedes Mal, wenn es läuft, dauert es mehrere Tage. Im Vergleich dazu ist die Verwendung eines vorab trainierten Modells viel günstiger. < 0,001: Kostensatz für Feinabstimmung und Schulung von Grund auf # 🎜🎜#Diese Zahl ist etwas allgemein gehalten und insgesamt sind die Kosten für die Feinabstimmung vernachlässigbar. Sogar zu den Preisen von OpenAI für sein teuerstes, fein abgestimmtes Modell, Davinci , es kostet nur 3 Cent pro 1.000 Token. # 🎜🎜 #
~1 Million US-Dollar: die Kosten für das Training eines 13-Milliarden-Parameter-Modells auf 1,4 Billionen Token
Feinabstimmung ist jedoch eine Sache, Training von Grund auf eine andere ...
#🎜 🎜#GPUVideoMemory
Wenn Sie das Modell selbst hosten, ist es sehr wichtig, den GPU-Videospeicher zu verstehen, da LLM den Videospeicher der GPU an seine Grenzen bringt.
Die folgenden Statistiken dienen speziell der Schlussfolgerung. Wenn Sie trainieren oder Feinabstimmungen durchführen möchten, benötigen Sie einiges an Videospeicher.
V100: 16 GB, A10G: 24 GB, A100: 40/80 GB: GPU-Speicherkapazität
Es ist wichtig, die Größe des Videospeichers für verschiedene GPU-Typen zu verstehen, da dies Ihr LLM einschränkt kann die Anzahl der Parameter haben.
Im Allgemeinen verwenden wir gerne A10G, da der On-Demand-Preis bei AWS 1,5 bis 2 US-Dollar pro Stunde mit 24 GB GPU-Speicher beträgt, während der Preis für jeden A100 etwa 5 US-Dollar pro Stunde beträgt.
2x Anzahl der Parameter: Typische GPU-Speicheranforderungen für LLM
Wenn Sie beispielsweise ein Modell mit 7 Milliarden Parametern haben, benötigen Sie etwa 14 GB GPU-Speicher.
Das liegt daran, dass jeder Parameter meistens einen 16-Bit-Float (oder 2 Bytes) erfordert.
Normalerweise sind nicht mehr als 16 Bit Genauigkeit erforderlich, aber meistens beginnt die Auflösung abzunehmen, wenn die Genauigkeit 8 Bit erreicht (in manchen Fällen ist dies auch akzeptabel).
Natürlich gibt es einige Projekte, die diese Situation verbessert haben. Beispielsweise hat llama.cpp ein Modell mit 13 Milliarden Parametern durch Quantisierung auf 4 Bit auf einer 6-GB-GPU durchlaufen (8 Bit sind ebenfalls akzeptabel), aber das ist nicht üblich.
~1 GB: Typischer GPU-Speicherbedarf für das Einbetten von Modellen
Wann immer Sie Anweisungen einbetten (was Sie häufig für Clustering-, semantische Such- und Klassifizierungsaufgaben tun), benötigen Sie so etwas wie einen Anweisungskonverter. So einen eingebetteten Modell. OpenAI verfügt auch über ein eigenes kommerzielles Einbettungsmodell.
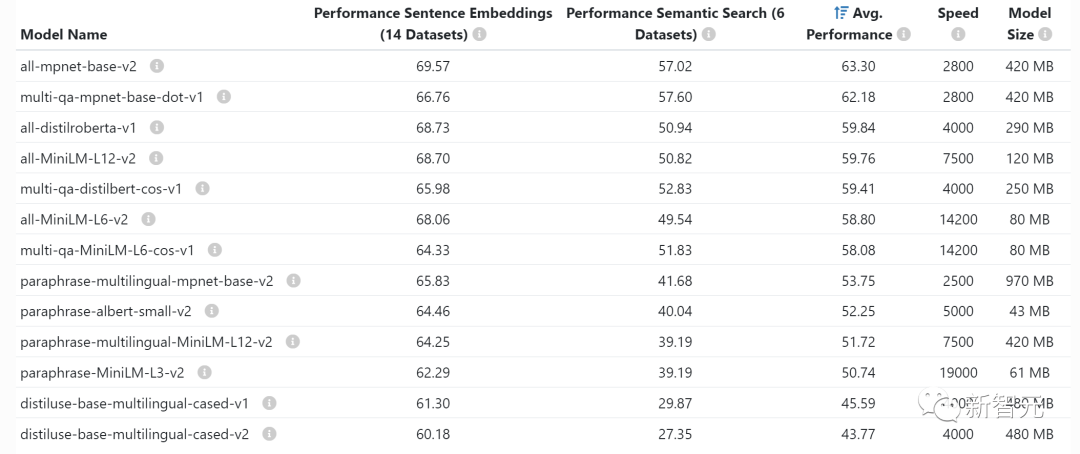
Normalerweise müssen Sie sich keine Gedanken darüber machen, wie viel Videospeicher die GPU einbettet, sie sind recht klein und Sie können LLM sogar auf derselben GPU einbetten.
>10x: Verbessern Sie den Durchsatz durch Stapeln von LLM-Anfragen
Die Latenz beim Ausführen von LLM-Abfragen über die GPU ist sehr hoch: Bei einem Durchsatz von 0,2 Abfragen pro Sekunde kann die Latenz 5 Sekunden dauern.
Interessanterweise beträgt die Latenz möglicherweise nur 5,2 Sekunden, wenn Sie zwei Aufgaben ausführen.
Das heißt, wenn Sie 25 Abfragen bündeln können, benötigen Sie etwa 10 Sekunden Latenz, während der Durchsatz auf 2,5 Abfragen pro Sekunde erhöht wurde.
Bitte lesen Sie jedoch weiter unten.
~1 MB: GPU-Speicher, der für ein Modell mit 13 Milliarden Parametern erforderlich ist, um 1 Token auszugeben
Der benötigte Speicher ist direkt proportional zur maximalen Anzahl von Token, die Sie generieren möchten.
Zum Beispiel erfordert die Generierung einer Ausgabe von bis zu 512 Token (ca. 380 Wörter) 512 MB Videospeicher.
Man könnte sagen, das ist keine große Sache – ich habe 24 GB Videospeicher, was sind 512 MB? Wenn Sie jedoch größere Chargen verarbeiten möchten, summiert sich diese Zahl.
Wenn Sie beispielsweise 16 Stapel ausführen möchten, wird der Videospeicher direkt auf 8 GB erhöht.
Das obige ist der detaillierte Inhalt vonIn Anlehnung an die göttliche Zusammenfassung von Jeff Dean teilte ein ehemaliger Google-Ingenieur „LLM-Entwicklungsgeheimnisse' mit: Zahlen, die jeder Entwickler kennen sollte!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr