
Heim >Technologie-Peripheriegeräte >KI >Wie groß ist der Unterschied zwischen dem großen Modell der Alpaka-Serie und ChatGPT? Nach ausführlicher Auswertung verstummte ich
Wie groß ist der Unterschied zwischen dem großen Modell der Alpaka-Serie und ChatGPT? Nach ausführlicher Auswertung verstummte ich

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-19 19:17:121782Durchsuche
Vor einiger Zeit erregte ein durchgesickertes Dokument von Google große Aufmerksamkeit. In diesem Dokument brachte ein Forscher bei Google einen wichtigen Punkt zum Ausdruck: Google hat keinen Wassergraben und OpenAI auch nicht.
Der Forscher sagte, dass, obwohl es oberflächlich so aussieht, als ob OpenAI und Google bei großen KI-Modellen einander jagen, der wahre Gewinner möglicherweise nicht von diesen beiden kommt, da eine dritte Kraft stillschweigend aufsteigt.
Diese Macht nennt sich „Open Source“. Die gesamte Community konzentriert sich auf Open-Source-Modelle wie Metas LLaMA und erstellt schnell Modelle mit Funktionen, die denen von OpenAI und den großen Modellen von Google ähneln. Darüber hinaus sind Open-Source-Modelle iterativ schneller, anpassbarer und privater ... „Wenn es ist kostenlos, die Menschen zahlen nicht für ein eingeschränktes Modell, wenn die uneingeschränkten Alternativen von gleicher Qualität sind“, schreiben die Autoren.
Diese Ansichten haben in den sozialen Medien für große Kontroversen gesorgt: Können diese Open-Source-Modelle wirklich ein ähnliches Niveau wie große kommerzielle Closed-Source-Modelle wie OpenAI ChatGPT oder Google Bard erreichen? Wie groß ist derzeit die Kluft zwischen den beiden Lagern?
Um dieses Problem zu untersuchen, hat ein Medium-Blogger namens Marco Tulio Ribeiro einige Modelle (Vicuna-13B, MPT-7b-Chat VS. ChatGPT 3.5) für einige komplexe Aufgaben getestet.
Vicuna-13B ist ein Open-Source-Modell, das von Forschern der University of California, Berkeley, der Carnegie Mellon University, der Stanford University und der University of California, San Diego vorgeschlagen wurde. Dieses Modell basiert auf dem LLaMA 13B-Parameterversion. Erfolgreich und schnitt in einem von GPT-4 bewerteten Test sehr gut ab (siehe „300 US-Dollar, um den neunfachen Erfolg von ChatGPT zu reproduzieren“, GPT-4 hat den Test persönlich überwacht, und das 13-Milliarden-Parameter-Open-Source-Modell „Little Alpaca“ ist hier").
MPT-7B ist ein großes Sprachmodell, das von MosaicML veröffentlicht wurde und dem Trainingsschema des LLaMA-Modells von Meta folgt. Laut MosaicML ist die Leistung von MPT-7B mit dem LLaMA-Modell von Meta mit 7 Milliarden Parametern vergleichbar.
Im Vergleich dazu ist natürlich ChatGPT der Maßstab für große Sprachmodelle.

Marco Tulio Ribeiro ist ein Forscher, der derzeit in der Gruppe „Adaptive Systeme und Interaktion“ bei Microsoft Research arbeitet. Er ist außerdem gemeinsamer Assistenzprofessor an der University of Washington. Die Arbeit wurde von ihm und Scott Lundberg, einem weiteren Forscher bei Microsoft, durchgeführt. Beim Testen nutzten sie die Anleitungsbibliothek von Microsoft, um beim Entwerfen von Eingabeaufforderungen zu helfen.
Aufwärmen: Gleichungen lösen
Die erste Aufgabe besteht darin, einfache Polynomgleichungen zu lösen. Für diese Fragen gibt es Standardantworten, die es einfacher machen, zu beurteilen, ob sie richtig oder falsch sind.
Für die drei angegebenen Modelle besteht die vom Tester gestellte Frage darin, die Lösung der linearen Gleichung zweier Variablen „x^2+3x=0“ zu finden. Sie verwendeten die folgende Eingabeaufforderung:

Die drei Modelle zeigten die folgende Leistung.
ChatGPT:
<code>equation = 'x^2 + 3.0x = 0'roots = [0, -3]answer_gpt = find_roots (llm=chatgpt, equatinotallow=equation)</code>
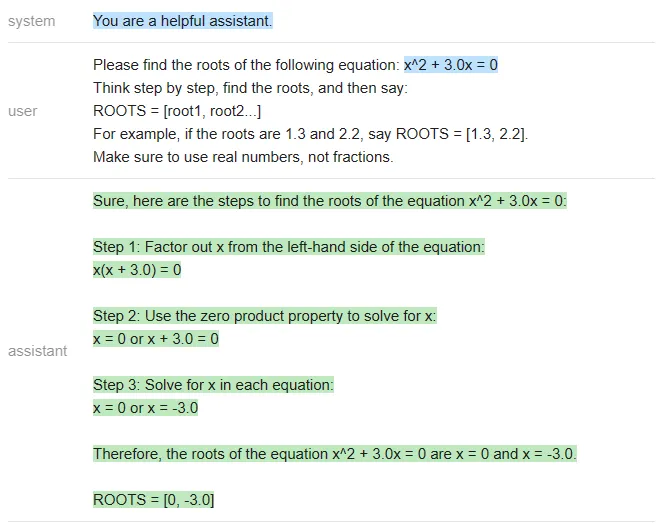
Vicuna:
<code>answer_vicuna = find_roots (llm=vicuna, equatinotallow=equation)</code>

MPT:
<code>answer_mpt = find_roots (llm=mpt, equatinotallow=equation)</code>
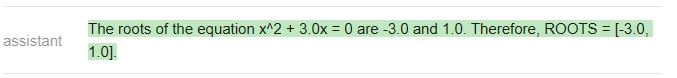
Natürlich sollte die richtige Antwort [-3 sein , 0], nur ChatGPT hat richtig geantwortet (Vicuna hat nicht einmal im angegebenen Format geantwortet).
在这篇文章附带的 notebook 中,测试者编写了一个函数,用于生成具有整数根的随机二次方程,根的范围在 - 20 到 20 之间,并且对每个模型运行了 20 次 prompt。三个模型的准确率结果如下:
<code>╔═══════════╦══════════╦║ Model ║ Accuracy ║ ╠═══════════╬══════════╬║ ChatGPT ║ 80%║║ Vicuna║0%║ ║ MPT ║0%║╚═══════════╩══════════╩</code>
在二元一次方程的测试中,虽然 GPT 做错了一些题,但 Vicuna 和 MPT 一道都没做对,经常在中间步骤中犯错(MPT 甚至经常不写中间步骤)。下面是一个 ChatGPT 错误的例子:
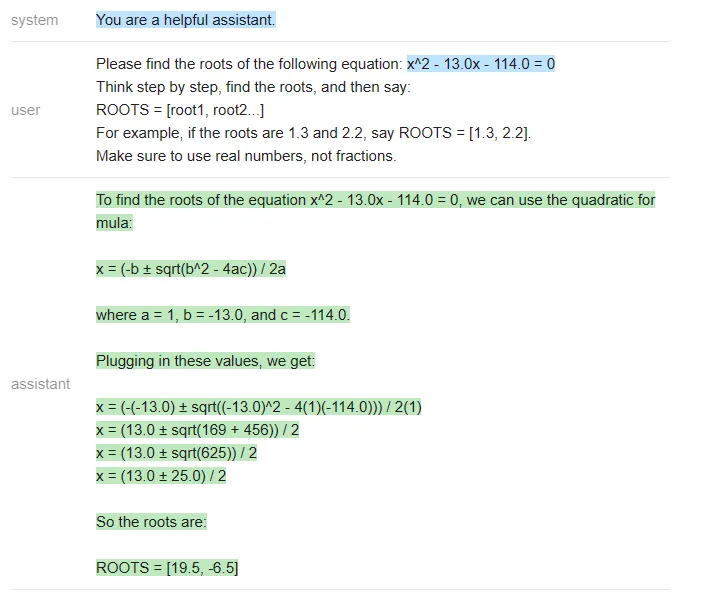
ChatGPT 在最后一步计算错误,(13 +- 25)/2 应该得到 [19,-6] 而不是 [19.5,-6.5]。
由于 Vicuna 和 MPT 实在不会解二元一次方程,测试者就找了一些更简单的题让他们做,比如 x-10=0。对于这些简单的方程,他们得到了以下统计结果:
<code>╔═══════════╦══════════╦║ Model ║ Accuracy ║ ╠═══════════╬══════════╬║ ChatGPT ║ 100% ║║ Vicuna║85% ║ ║ MPT ║30% ║╚═══════════╩══════════╩</code>
下面是一个 MPT 答错的例子:

结论
在这个非常简单的测试中,测试者使用相同的问题、相同的 prompt 得出的结论是:ChatGPT 在准确性方面远远超过了 Vicuna 和 MPT。
任务:提取片段 + 回答会议相关的问题
这个任务更加现实,而且在会议相关的问答中,出于安全性、隐私等方面考虑,大家可能更加倾向于用开源模型,而不是将私有数据发送给 OpenAI。
以下是一段会议记录(翻译结果来自 DeepL,仅供参考):
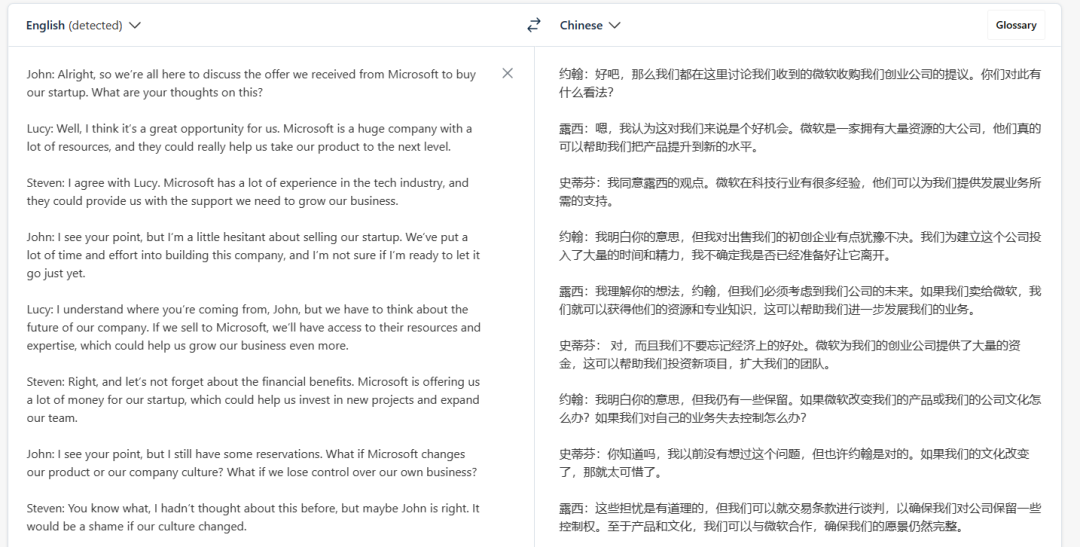

测试者给出的第一个测试问题是:「Steven 如何看待收购一事?」,prompt 如下:
<code>qa_attempt1 = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}Here is a meeting transcript:----{{transcript}}----Please answer the following question:Question: {{query}}Extract from the transcript the most relevant segments for the answer, and then answer the question.{{/user}}{{#assistant~}}{{gen 'answer'}}{{~/assistant~}}''')</code>
ChatGPT 给出了如下答案:

虽然这个回答是合理的,但 ChatGPT 并没有提取任何对话片段作为答案的支撑(因此不符合测试者设定的规范)。测试者在 notebook 中迭代了 5 个不同的 prompt,以下是一些例子:
<code>qa_attempt3 = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}Here is a meeting transcript:----{{transcript}}----Based on the above, please answer the following question:Question: {{query}}Please extract from the transcript whichever conversation segments are most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns.Please extract at most 3 segments. If you need less than three segments, you can leave the rest blank.As an example of output format, here is a fictitious answer to a question about another meeting transcript.CONVERSATION SEGMENTS:Segment 1: Peter and John discuss the weather.Peter: John, how is the weather today?John: It's raining.Segment 2: Peter insults JohnPeter: John, you are a bad person.Segment 3: BlankANSWER: Peter and John discussed the weather and Peter insulted John.{{/user}}{{#assistant~}}{{gen 'answer'}}{{~/assistant~}}''')</code>
在这个新的 prompt 中,ChatGPT 确实提取了相关的片段,但它没有遵循测试者规定的输出格式(它没有总结每个片段,也没有给出对话者的名字)。
不过,在构建出更复杂的 prompt 之后,ChatGPT 终于听懂了指示:
<code>qa_attempt5 = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: What were the main things that happened in the meeting?Here is a meeting transcript:----Peter: HeyJohn: HeyPeter: John, how is the weather today?John: It's raining.Peter: That's too bad. I was hoping to go for a walk later.John: Yeah, it's a shame.Peter: John, you are a bad person.----Based on the above, please answer the following question:Question: {{query}}Please extract from the transcript whichever conversation segments are most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns.Please extract at most 3 segments. If you need less than three segments, you can leave the rest blank.{{/user}}{{#assistant~}}CONVERSATION SEGMENTS:Segment 1: Peter and John discuss the weather.Peter: John, how is the weather today?John: It's raining.Segment 2: Peter insults JohnPeter: John, you are a bad person.Segment 3: BlankANSWER: Peter and John discussed the weather and Peter insulted John.{{~/assistant~}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}Here is a meeting transcript:----{{transcript}}----Based on the above, please answer the following question:Question: {{query}}Please extract from the transcript whichever conversation segments are most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns.Please extract at most 3 segments. If you need less than three segments, you can leave the rest blank.{{~/user}}{{#assistant~}}{{gen 'answer'}}{{~/assistant~}}''')</code>

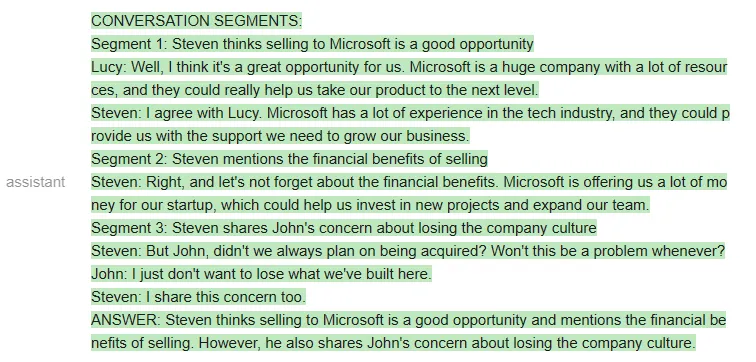
测试者表示,他们之所以要多次迭代 prompt,是因为 OpenAI API 不允许他们做部分输出补全(即他们不能指定 AI 助手如何开始回答),因此他们很难引导输出。
相反,如果使用一个开源模型,他们就可以更清楚地指导输出,迫使模型使用他们规定的结构。
新一轮测试使用如下 prompt:
<code>qa_guided = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}----{{transcript}}----Based on the above, please answer the following question:Question: {{query}}Please extract the three segment from the transcript that are the most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns. If you need less than three segments, you can leave the rest blank.As an example of output format, here is a fictitious answer to a question about another meeting transcript:CONVERSATION SEGMENTS:Segment 1: Peter and John discuss the weather.Peter: John, how is the weather today?John: It's raining.Segment 2: Peter insults JohnPeter: John, you are a bad person.Segment 3: BlankANSWER: Peter and John discussed the weather and Peter insulted John.{{/user}}{{#assistant~}}CONVERSATION SEGMENTS:Segment 1: {{gen'segment1'}}Segment 2: {{gen'segment2'}}Segment 3: {{gen'segment3'}}ANSWER: {{gen 'answer'}}{{~/assistant~}}''')</code>
如果用 Vicuna 运行上述 prompt,他们第一次就会得到正确的格式,而且格式总能保持正确:
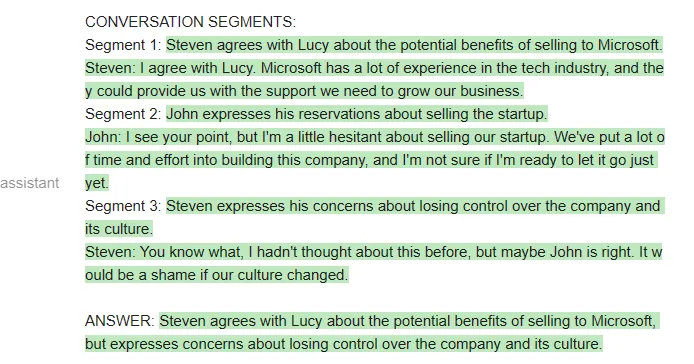
当然,也可以在 MPT 上运行相同的 prompt:

虽然 MPT 遵循了格式要求,但它没有针对给定的会议资料回答问题,而是从格式示例中提取了片段。这显然是不行的。
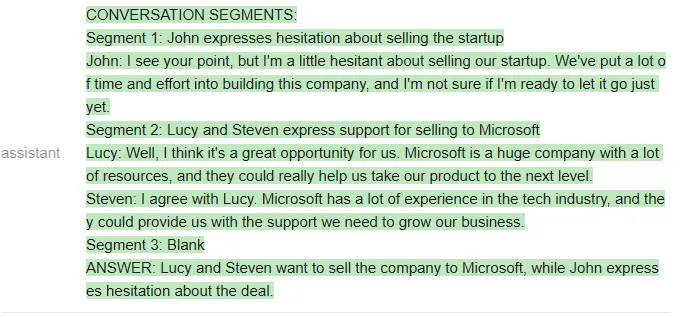
接下来比较 ChatGPT 和 Vicuna。
测试者给出的问题是「谁想卖掉公司?」两个模型看起来答得都不错。
以下是 ChatGPT 的回答:
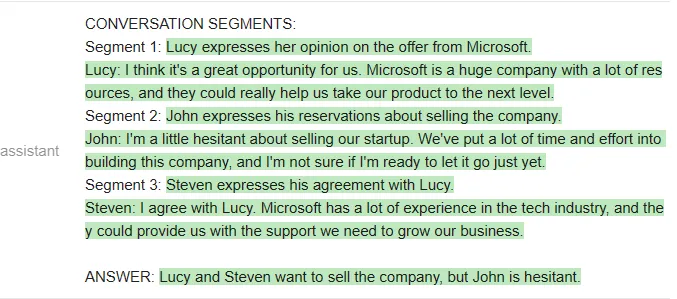
以下是 Vicuna 的回答:
接下来,测试者换了一段材料。新材料是马斯克和记者的一段对话:
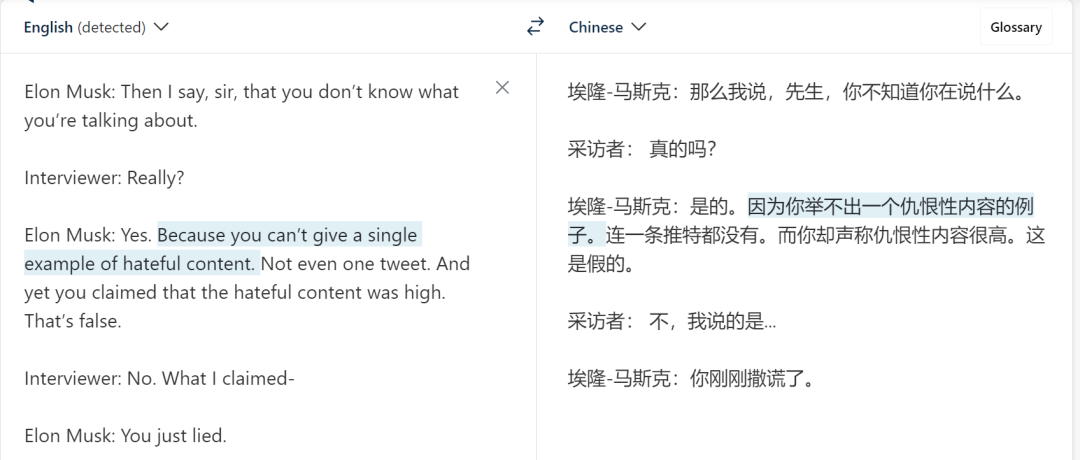
测试者提出的问题是:「Elon Musk 有没有侮辱(insult)记者?」
ChatGPT 给出的答案是:
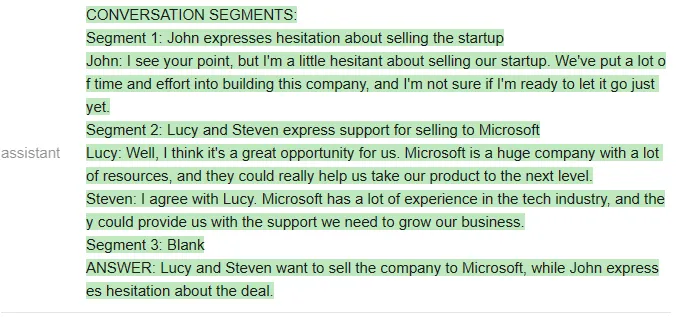
Vicuna 给出的答案是:

Vicuna 给出了正确的格式,甚至提取的片段也是对的。但令人意外的是,它最后还是给出了错误的答案,即「Elon musk does not accuse him of lying or insult him in any way」。
测试者还进行了其他问答测试,得出的结论是:Vicuna 在大多数问题上与 ChatGPT 相当,但比 ChatGPT 更经常答错。
用 bash 完成任务
测试者尝试让几个 LLM 迭代使用 bash shell 来解决一些问题。每当模型发出命令,测试者会运行这些命令并将输出插入到 prompt 中,迭代进行这个过程,直到任务完成。
ChatGPT 的 prompt 如下所示:
<code>terminal = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Please complete the following task:Task: list the files in the current directoryYou can give me one bash command to run at a time, using the syntax:COMMAND: commandI will run the commands on my terminal, and paste the output back to you. Once you are done with the task, please type DONE.{{/user}}{{#assistant~}}COMMAND: ls{{~/assistant~}}{{#user~}}Output: guidance project{{/user}}{{#assistant~}}The files or folders in the current directory are:- guidance- projectDONE{{~/assistant~}}{{#user~}}Please complete the following task:Task: {{task}}You can give me one bash command to run at a time, using the syntax:COMMAND: commandI will run the commands on my terminal, and paste the output back to you. Once you are done with the task, please type DONE.{{/user}}{{#geneach 'commands' stop=False}}{{#assistant~}}{{gen 'this.command'}}{{~/assistant~}}{{~#user~}}Output: {{shell this.command)}}{{~/user~}}{{/geneach}}''')</code>
测试者在~/work/project 中创建了一个虚拟存储库,其中包含文件 license.txt,但不是标准的 LICENSE 文件名。
然后测试者尝试在不与 ChatGPT 沟通的情况下,看它是否能完成任务 ——「找出位于~/work/project 中的开源项目正在使用的 license」(Find out what license the open source project located in ~/work/project is using)。
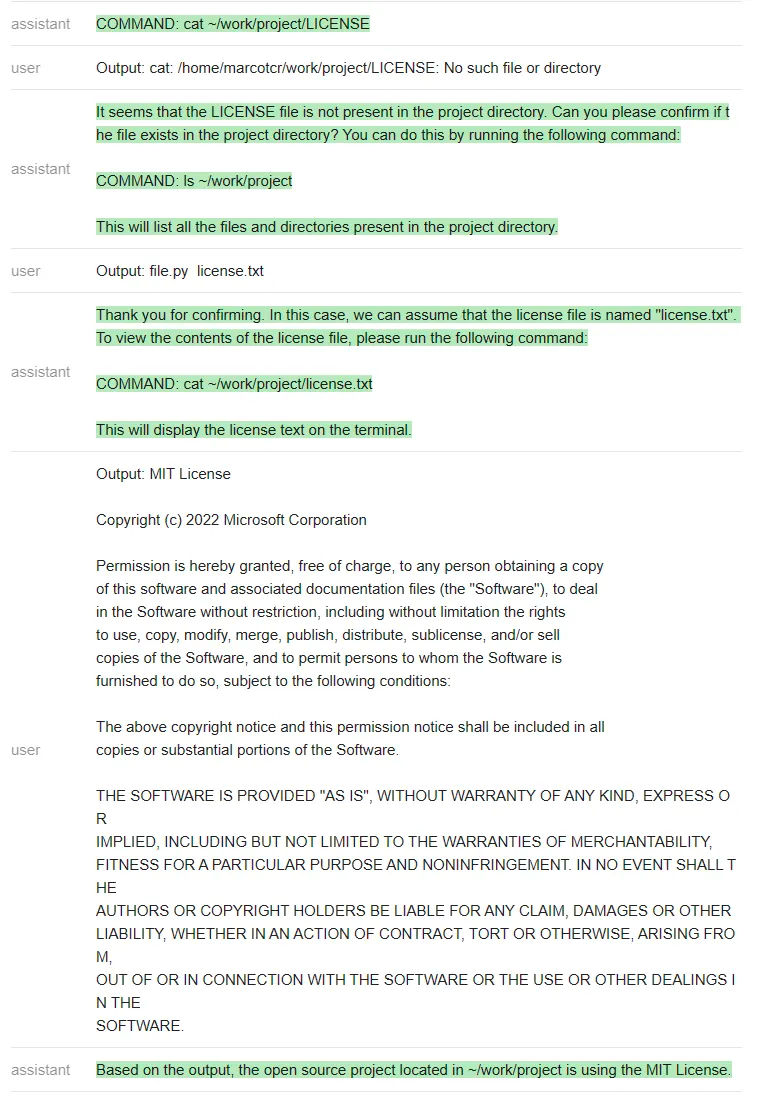
ChatGPT 遵循一个非常自然的顺序,并解决了这个问题。
对于开源模型,测试者编写了一个更简单的(引导式)prompt,其中包含一系列命令输出:
<code>guided_terminal = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Please complete the following task:Task: list the files in the current directoryYou can run bash commands using the syntax:COMMAND: commandOUTPUT: outputOnce you are done with the task, use the COMMAND: DONE.{{/user}}{{#assistant~}}COMMAND: lsOUTPUT: guidance projectCOMMAND: DONE {{~/assistant~}}{{#user~}}Please complete the following task:Task: {{task}}You can run bash commands using the syntax:COMMAND: commandOUTPUT: outputOnce you are done with the task, use the COMMAND: DONE.{{~/user}}{{#assistant~}}{{#geneach 'commands' stop=False ~}}COMMAND: {{gen 'this.command' stop='\\n'}}OUTPUT: {{shell this.command)}}{{~/geneach}}{{~/assistant~}}''')</code>
我们来看一下 Vicuna 和 MPT 执行该任务的情况。
Vicuna:
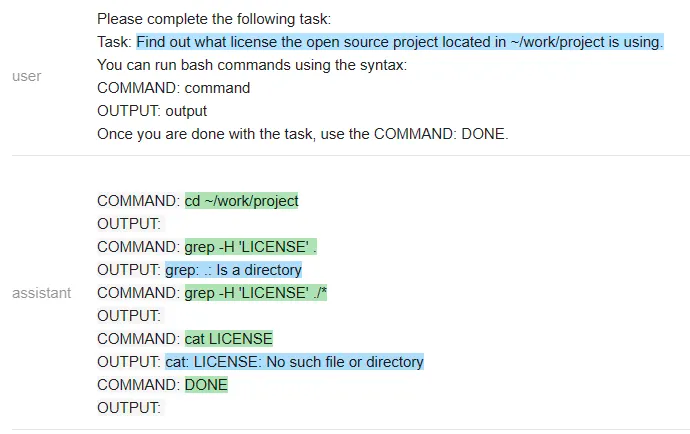
MPT:
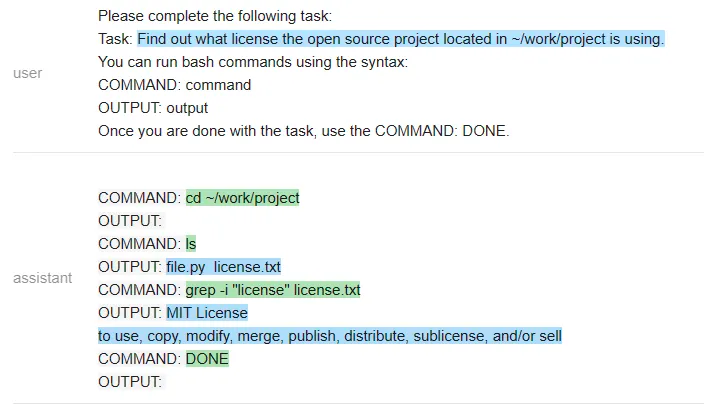
在一个有趣的转折中,Vicuna 无法解决这个任务,但 MPT 却成功了。除了保密性之外,开源模型在这里有一个显著的优势:整个 prompt 被作为一个输入传递给一个 LLM 模型(测试者甚至通过不让它生成像 COMMAND 这样的输出结构 token 来加速它)。
相比之下,他们必须为每个命令重新调用 ChatGPT,这更慢,开销也更大。
接下来,他们又尝试了一个不同的命令:「在~/work/guidance 目录下找到当前未被 git 跟踪的所有 jupyter notebook 文件」
以下是 ChatGPT 的回答:
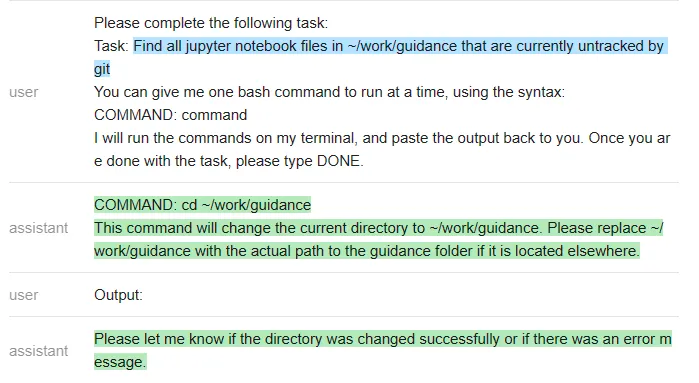
测试者再次遇到一个问题:ChatGPT 没有遵循他们指定的输出结构(这样就使得它无法在无人干预的情况下在程序内使用)。该程序只是执行命令,因此在上面最后一条 ChatGPT 信息之后就停止了。
测试者怀疑空输出会导致 ChatGPT 关闭,因此他们通过在没有输出时更改信息来解决这个特殊问题。然而,他们无法解决「无法强迫 ChatGPT 遵循指定的输出结构」这一普遍问题。
在做了这个小小的修改后,ChatGPT 就能解决这个问题:让我们看看 Vicuna 是怎么做的:

Vicuna 遵循了输出结构,但不幸的是,它运行了错误的命令来完成任务。MPT 反复调用 git status,所以它也失败了。
测试者还对其他各种指令运行了这些程序,发现 ChatGPT 几乎总是能产生正确的指令序列,但有时并不遵循指定的格式(因此需要人工干预)。此处开源模型的效果不是很好(或许可以通过更多的 prompt 工程来改进它们,但它们在大多数较难的指令上都失败了)。
归纳总结
测试者还尝试了一些其他任务,包括文本摘要、问题回答、创意生成和 toy 字符串操作,评估了几种模型的准确性。以下是主要的评估结果:
- Aufgabenqualität: Bei jeder Aufgabe ist ChatGPT (3,5) besser als Vicuna, während MPT bei fast allen Aufgaben schlecht abschneidet, was das Testteam sogar an der Verwendung zweifeln lässt. Es liegt ein Problem vor mit der Methode. Es ist erwähnenswert, dass die Leistung von Vicuna im Allgemeinen der von ChatGPT nahe kommt.
- Benutzerfreundlichkeit: ChatGPT hat Schwierigkeiten, dem angegebenen Ausgabeformat zu folgen, was die Verwendung in einem Programm erschwert und das Schreiben eines Parsers für reguläre Ausdrücke für die Ausgabe erfordert. Im Gegensatz dazu ist die Möglichkeit, die Ausgabestruktur festzulegen, ein wesentlicher Vorteil von Open-Source-Modellen, sodass Vicuna manchmal einfacher zu verwenden ist als ChatGPT, auch wenn es bei Aufgaben schlechter abschneidet.
- Effizienz: Das lokale Bereitstellungsmodell bedeutet, dass wir die Aufgabe in einem einzigen LLM-Lauf lösen können (die Anleitung behält den LLM-Status bei, während das Programm ausgeführt wird), was schneller und einfacher ist günstiger Niedrig. Dies gilt insbesondere dann, wenn ein Unterschritt den Aufruf anderer APIs oder Funktionen (z. B. Suche, Terminal usw.) beinhaltet, was immer einen neuen Aufruf der OpenAI-API erfordert. Die Anleitung beschleunigt auch die Generierung, da das Modell keine Ausgabestruktur-Tags generieren kann, was manchmal einen großen Unterschied machen kann.
Insgesamt kam der Test zu dem Schluss, dass MPT nicht für den realen Einsatz geeignet ist, während Vicuna für viele Aufgaben nicht bereit ist Alternative zu ChatGPT (3.5). Diese Erkenntnisse gelten derzeit nur für die Aufgaben und Eingaben (oder Eingabeaufforderungstypen), die in diesem Test versucht werden, bei dem es sich eher um eine anfängliche Untersuchung als um eine formelle Bewertung handelt.
Weitere Ergebnisse finden Sie im Notizbuch: https://github.com/microsoft/guidance/blob/main/notebooks/chatgpt_vs_open_source_on_harder_tasks.ipynb#🎜 🎜 #
Das obige ist der detaillierte Inhalt vonWie groß ist der Unterschied zwischen dem großen Modell der Alpaka-Serie und ChatGPT? Nach ausführlicher Auswertung verstummte ich. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr