
Heim >Technologie-Peripheriegeräte >KI >Erforschung und Praxis der Suchrelevanztechnologie von Dianping
Erforschung und Praxis der Suchrelevanztechnologie von Dianping

- 王林nach vorne
- 2023-05-19 19:04:041028Durchsuche
Autor: Xiaoya Shen Yuan Zhudi et al Die #Dianping-Suche ist einer der Haupteingänge der Dianping-App. Benutzer verwenden die Suche, um ihre Bedürfnisse bei der Suche nach Geschäften für Life-Service-Händler in verschiedenen Szenarien zu erfüllen. Das langfristige Ziel der Suche besteht darin, das Sucherlebnis kontinuierlich zu optimieren und die Suchzufriedenheit der Benutzer zu verbessern. Dazu müssen wir die Suchabsichten der Benutzer verstehen, die Korrelation zwischen Suchbegriffen und Händlern genau messen, relevante Händler so weit wie möglich anzeigen und ein höheres Ranking erzielen relevante Händler basierend auf Forward. Daher ist die Berechnung der Korrelation zwischen Suchbegriffen und Händlern ein wichtiger Bestandteil der Bewertungssuche.
Die Relevanzprobleme, mit denen Dianping-Suchszenarien konfrontiert sind, sind komplex und vielfältig. Die Suchbegriffe der Benutzer sind sehr unterschiedlich, z. B. die Suche nach Firmennamen, Gerichten, Adressen, Kategorien usw. und die Beziehungen zwischen ihnen. Verschiedene komplexe Kombinationen von Informationen, und Händler verfügen auch über mehrere Arten von Informationen, einschließlich Händlernamen, Adressinformationen, Gruppenbestellinformationen, Gerichtinformationen und verschiedenen anderen Einrichtungen und Etiketteninformationen usw., was zu einem extremen Ergebnis führt Komplexes Übereinstimmungsmuster zwischen Abfrage und Händlern, das leicht zu erzeugen ist. Es treten verschiedene Korrelationsprobleme auf. Insbesondere kann es in die folgenden Typen unterteilt werden:
Textkonflikt
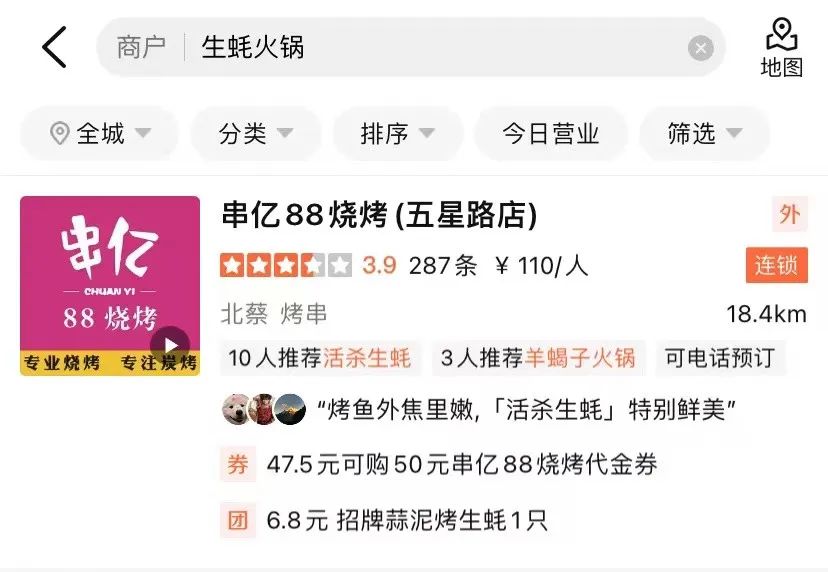
: Bei der Suche sicherstellen, dass mehr Händler verfügbar sind abgerufen und offengelegt werden, wird die Abfrage zum Abruf möglicherweise in feinere Wörter aufgeteilt, was zu dem Problem führt, dass die Abfrage nicht mit verschiedenen Feldern des Händlers übereinstimmt. Wie in Abbildung 1(a) gezeigt, sucht der Benutzer nach „Austern“. „Hot Pot“ sollte nach einem Hot Pot suchen, dessen Suppenbasis Austern enthält, und „Austern“ und „Hot Pot“ entsprechen jeweils zwei verschiedenen Gerichten des Händlers.
- Semantischer Offset: Die Abfrage stimmt buchstäblich mit dem Händler überein, aber der Händler hat keinen semantischen Bezug zur Hauptabsicht der Abfrage, z. B. „ Milchtee“ – „Brauner Zuckerperlen-Milchteebeutel“, wie in Abbildung 1(b) dargestellt.
- Kategorie-Offset: Die Abfrage stimmt wörtlich mit dem Händler überein und ist semantisch verwandt, aber die Hauptkategorie entspricht beispielsweise nicht den Bedürfnissen des Benutzers , Der Benutzer Bei der Suche nach „Obst“ ist ein KTV-Händler, der „Obstteller“ anbietet, offensichtlich nicht für die Bedürfnisse des Benutzers relevant.
- (a) Beispiel für Textkonflikte #🎜 🎜 Nr Beispiel
Die auf wörtlichem Matching basierende Korrelationsmethode kann die oben genannten Probleme nicht effektiv lösen, um die verschiedenen Arten von Inkonsistenzen in der Suchliste zu lösen entsprechen nicht der Absicht des Nutzers. Verwandte Probleme erfordern eine genauere Darstellung der tiefen semantischen Korrelation zwischen Suchbegriffen und Händlern. Dieser Artikel basiert auf dem MT-BERT-Vortrainingsmodell, das auf dem umfangreichen Geschäftskorpus von Meituan trainiert wurde, und optimiert die Abfrage und den Händler (POI, entsprechend Doc in allgemeinen Suchmaschinen) im Dianping-Suchszenario . Tiefes semantisches Korrelationsmodell und wendet die Korrelationsinformationen zwischen Abfrage und POI in jedem Link des Suchlinks an.
2. Suchkorrelation vorhandene Technologie
Suchkorrelation zielt darauf ab, den Grad der Korrelation zwischen Abfrage und zurückgegebenem Dokument zu berechnen, d. h. Bestimmen Sie, ob die Der Inhalt im Dokument entspricht den Abfrageanforderungen des Benutzers und entspricht der semantischen Matching-Aufgabe in NLP (Semantic Matching). Im Suchszenario von Dianping besteht die Suchrelevanz darin, die Korrelation zwischen der Suchanfrage des Benutzers und dem POI des Händlers zu berechnen.
Textabgleichsmethode: Frühe Textabgleichsaufgaben berücksichtigten nur den wörtlichen Übereinstimmungsgrad zwischen Abfrage und Dokument über TF-IDF und BM25 Calculate Die Korrelation basiert auf den übereinstimmenden Merkmalen von Term. Die Online-Berechnungseffizienz der Wortübereinstimmungskorrelation ist hoch, aber die Generalisierungsleistung der begriffsbasierten Schlüsselwortübereinstimmung ist schlecht, es fehlen Semantik- und Wortreihenfolgeinformationen und das Problem der Mehrfachbedeutungen eines Wortes oder mehrerer Wörter mit einer Bedeutung kann daher nicht gelöst werden Fehlende Übereinstimmungen und Missverständnisse Das Matching-Phänomen ist ernst.
Traditionelles semantisches Matching-Modell: Um die Mängel des wörtlichen Matchings auszugleichen, wird das semantische Matching-Modell vorgeschlagen, um die semantische Korrelation zwischen Abfrage und Dokument besser zu verstehen. Herkömmliche semantische Matching-Modelle umfassen hauptsächlich Matching basierend auf implizitem Raum: Zuordnung von Query und Doc zu Vektoren im selben Raum und anschließende Verwendung von Vektorabstand oder -ähnlichkeit als Matching-Scores, wie z. B. Partial Least Square (PLS)[1 ] ; und Abgleich basierend auf dem Übersetzungsmodell: Ordnen Sie das Dokument zu, nachdem Sie es dem Abfrageraum zugeordnet haben, oder berechnen Sie die Wahrscheinlichkeit, dass das Dokument in die Abfrage übersetzt wird[2].
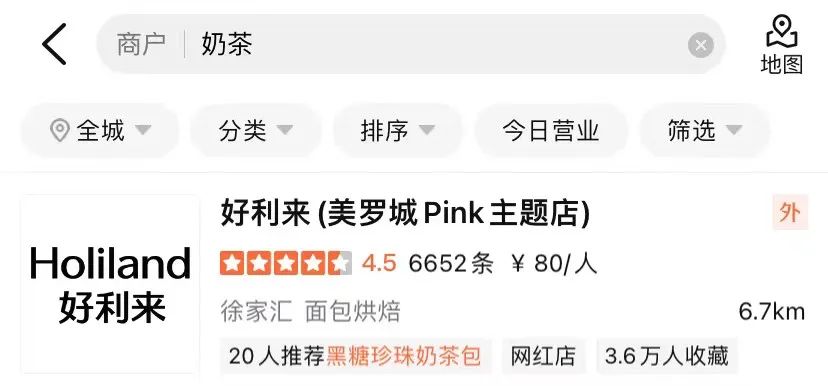
Mit der Entwicklung von Deep-Learning- und Pre-Training-Modellen werden auch Deep-Semantic-Matching-Modelle in der Branche häufig eingesetzt. Hinsichtlich der Implementierungsmethoden werden tiefe semantische Matching-Modelle in darstellungsbasierte (Repräsentationsbasierte) Methoden und interaktionsbasierte (Interaktionsbasierte) Methoden unterteilt. Als effektive Methode im Bereich der Verarbeitung natürlicher Sprache werden vorab trainierte Modelle auch häufig bei semantischen Matching-Aufgaben eingesetzt. (a) Darstellungsbasiertes Multidomänen-Korrelationsmodell
Repräsentationsbasiertes tiefes semantisches Matching-Modell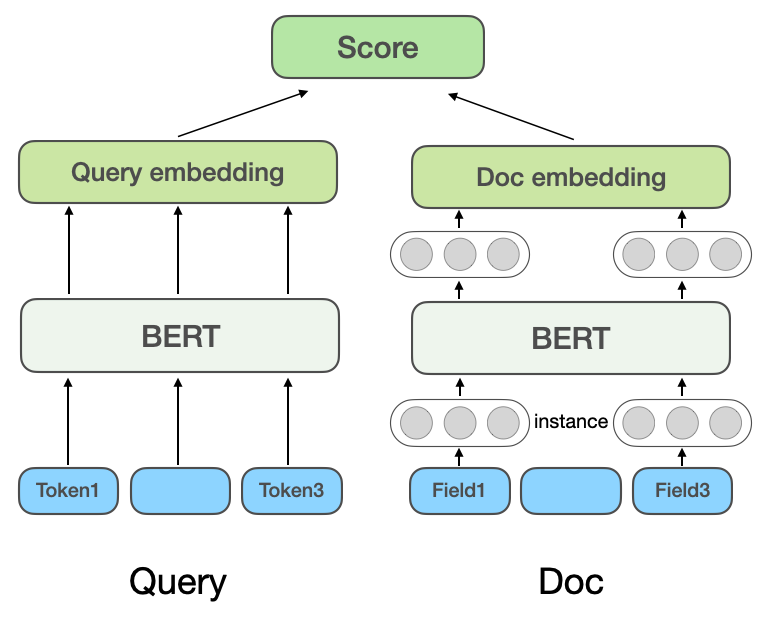 : Die repräsentationsbasierte Methode lernt die semantischen Vektordarstellungen von Query bzw. Doc und berechnet dann die Ähnlichkeit basierend auf den beiden Vektoren. Das DSSM-Modell von Microsoft
: Die repräsentationsbasierte Methode lernt die semantischen Vektordarstellungen von Query bzw. Doc und berechnet dann die Ähnlichkeit basierend auf den beiden Vektoren. Das DSSM-Modell von Microsoft
schlägt ein klassisches Textanpassungsmodell mit Doppelturmstruktur vor, das zwei unabhängige Netzwerke verwendet, um Vektordarstellungen von Query und Doc zu erstellen, und Kosinusähnlichkeit verwendet, um die Korrelation zwischen den beiden Vektoren zu messen. Das NRM von Microsoft Bing Search [4]Zielt auf das Problem der Dokumentdarstellung ab. Zusätzlich zum grundlegenden Dokumenttitel und -inhalt berücksichtigt es auch andere Informationen aus mehreren Quellen (
Jeder Informationstyp wird als Feldfeld bezeichnet), z Bedenken Sie, dass es bei externen Links und Benutzerklicks auf Abfragen usw. mehrere Felder in einem Dokument gibt und dass in jedem Feld mehrere Instanzen (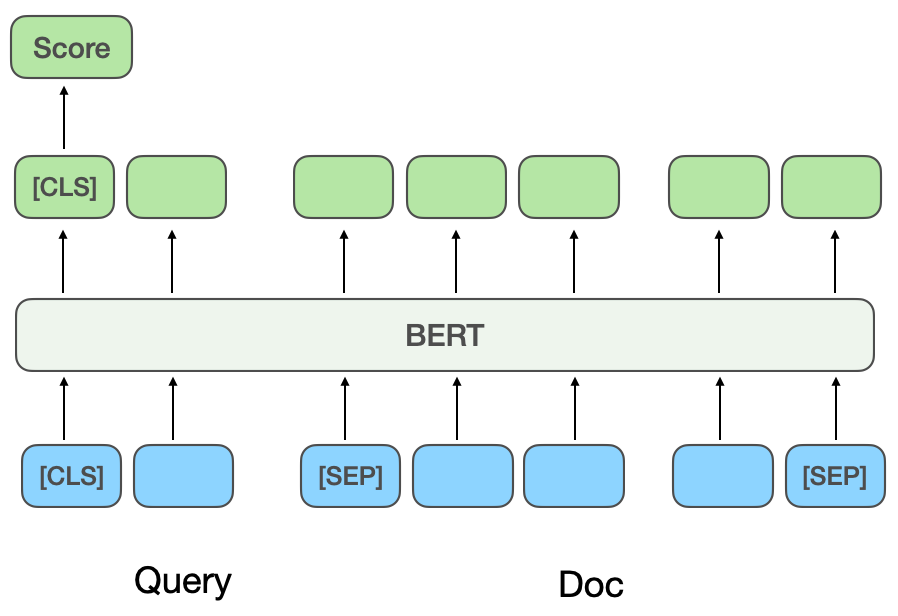 Instanz
Instanz
[5]Führt das vorab trainierte Modell BERT in die Codierungsschicht von Query und Doc von Twin Towers ein, verwendet verschiedene Pooling-Methoden, um die Satzvektoren von Twin Towers zu erhalten, und interagiert mit Query und Doc durch Punktmultiplikation, Spleißen, usw.
Dianpings frühes Modell der Suchrelevanz stützte sich auf die Ideen von NRM und SentenceBERT und übernahm die in Abbildung 2(a) dargestellte repräsentationsbasierte Multidomänen-Relevanzmodellstruktur. Die repräsentationsbasierte Methode kann den POI-Vektor konvertieren Es wird im Voraus berechnet und im Cache gespeichert. Nur der interaktive Teil des Abfragevektors und der POI-Vektor werden online berechnet, sodass die Berechnungsgeschwindigkeit bei Online-Nutzung schneller ist.
Interaktionsbasiertes tiefes semantisches Matching-Modell: Die interaktionsbasierte Methode lernt die semantischen Darstellungsvektoren von Query und Doc nicht direkt, ermöglicht aber die Interaktion von Query und Doc in der zugrunde liegenden Eingabephase, um einige grundlegende Matching-Signale zu ermitteln Die grundlegenden Matching-Signale werden dann zu einem Matching-Score verschmolzen. ESIM[6] ist ein klassisches Modell, das in der Branche vor der Einführung von Pre-Training-Modellen weit verbreitet war. Zuerst werden Query und Doc codiert, um den Anfangsvektor zu erhalten, und dann wird der Aufmerksamkeitsmechanismus zur interaktiven Gewichtung verwendet und dann gespleißt mit dem Anfangsvektor und schließlich wird die Korrelation durch Klassifizierung ermittelt. Bei der Einführung des vorab trainierten Modells BERT für interaktive Berechnungen werden Query und Doc normalerweise als Eingabe der BERT-Inter-Satz-Beziehungsaufgabe zusammengefügt, und der endgültige Korrelationswert wird über das MLP-Netzwerk erhalten [7 ], wie in Abbildung 2(b) gezeigt. CEDR[8]Nachdem die Abfrage- und Doc-Vektoren aus der BERT-Aufgabe zur Beziehung zwischen Sätzen erhalten wurden, werden die Abfrage- und Doc-Vektoren aufgeteilt und die Kosinus-Ähnlichkeitsmatrix von Query und Doc weiter berechnet. Das Meituan-Suchteam[9] führte interaktionsbasierte Methoden in das Meituan-Suchkorrelationsmodell ein, führte Händlerkategorieinformationen für das Vortraining ein und führte Entitätserkennungsaufgaben für das Lernen mit mehreren Aufgaben ein. Das Meituan-Team für In-Store-Suchwerbung [10]
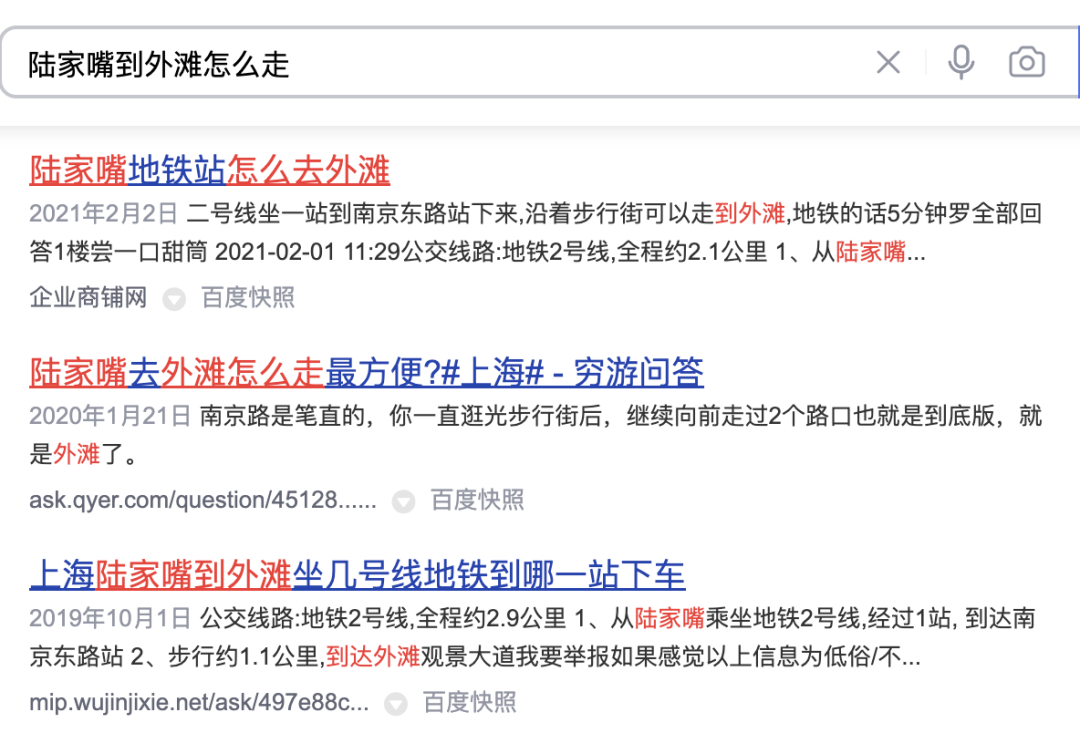
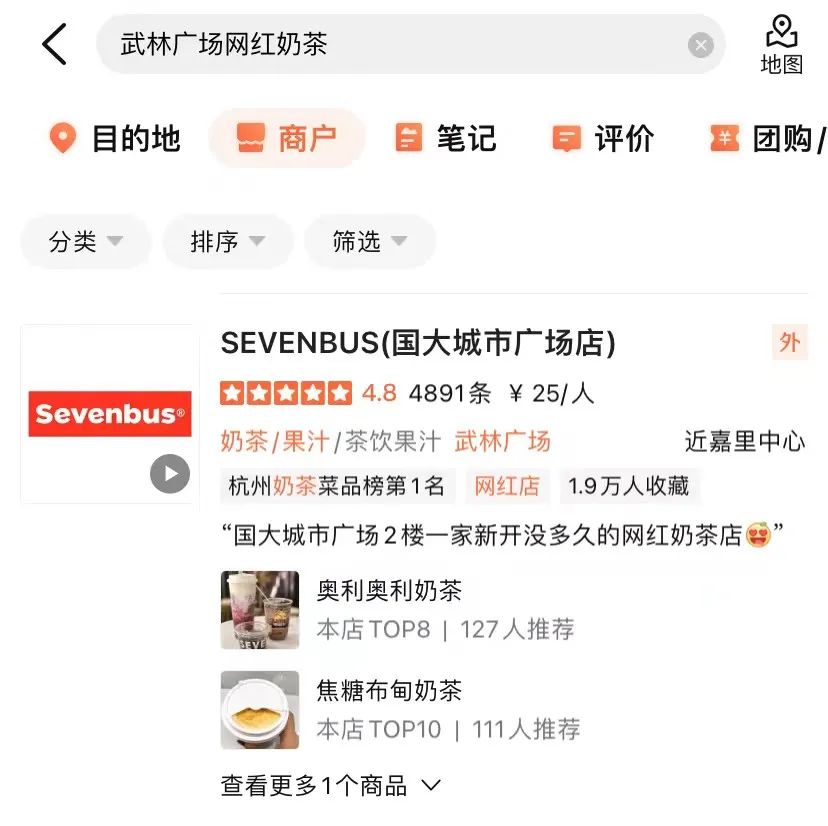
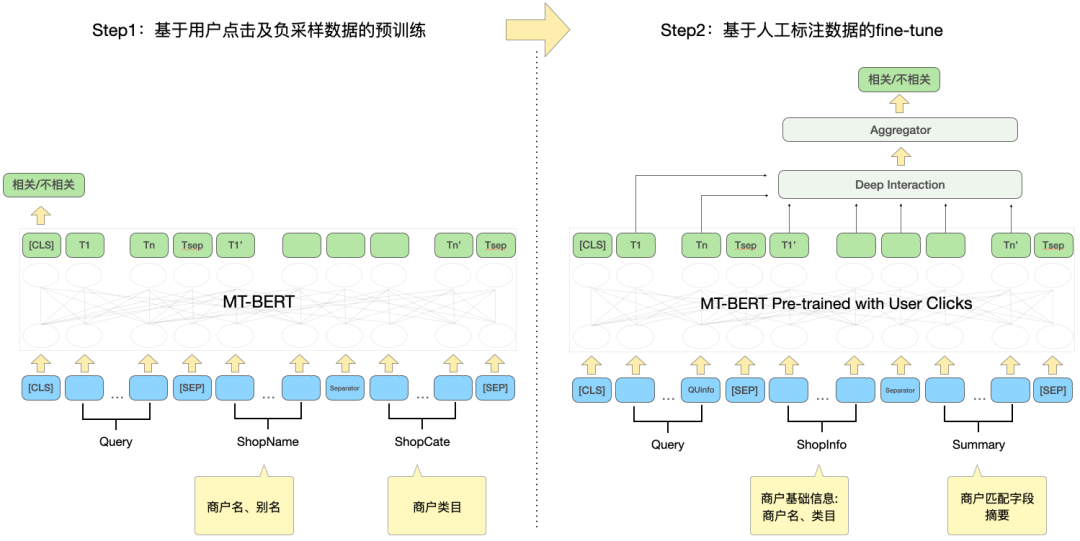
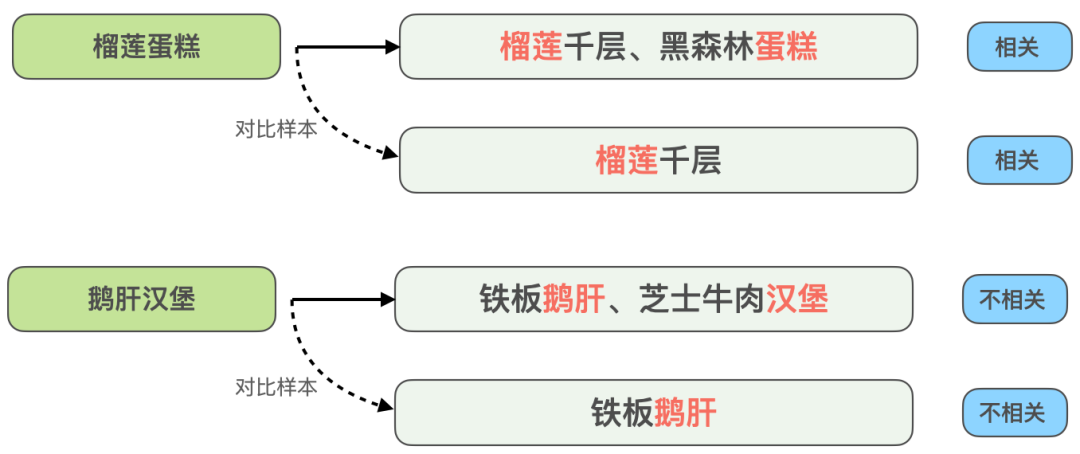
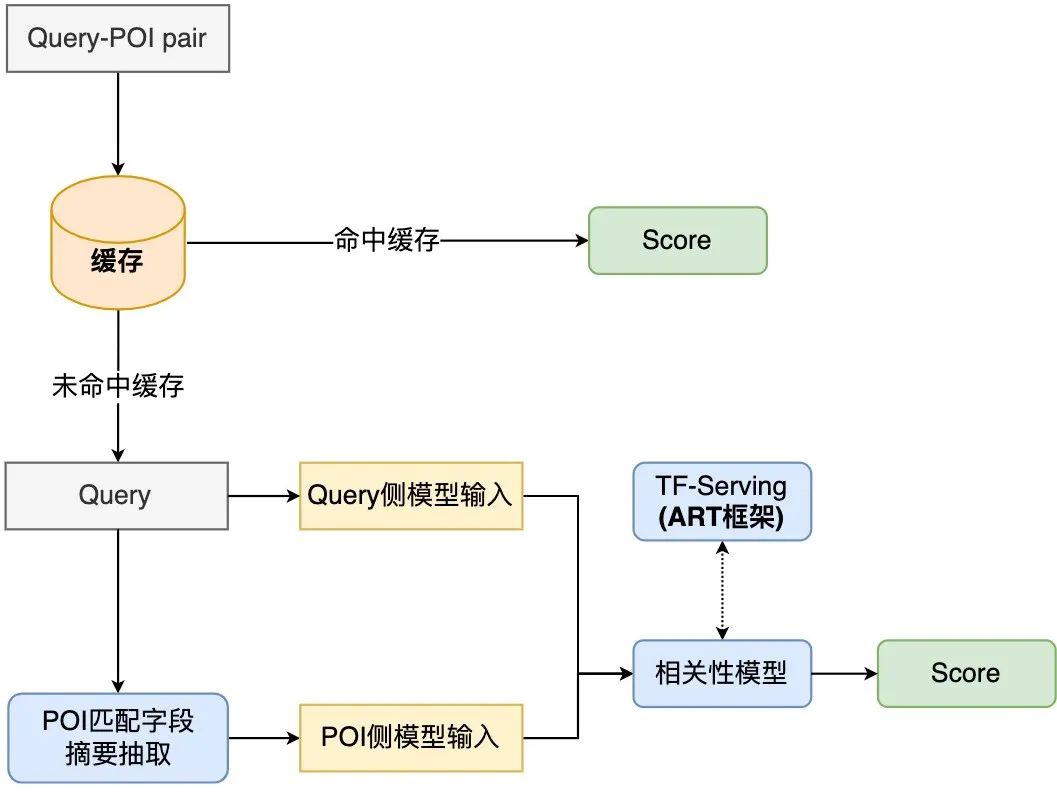
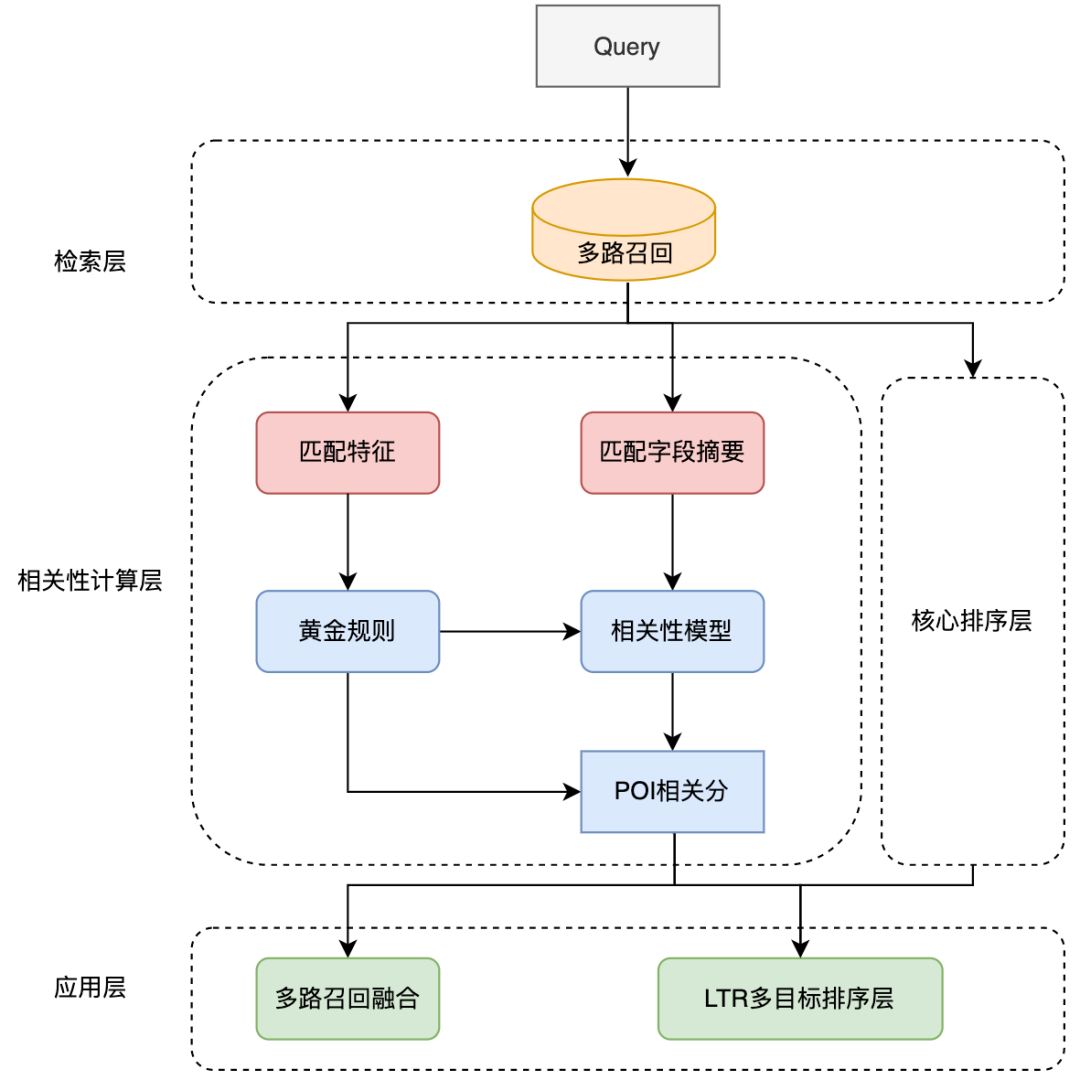
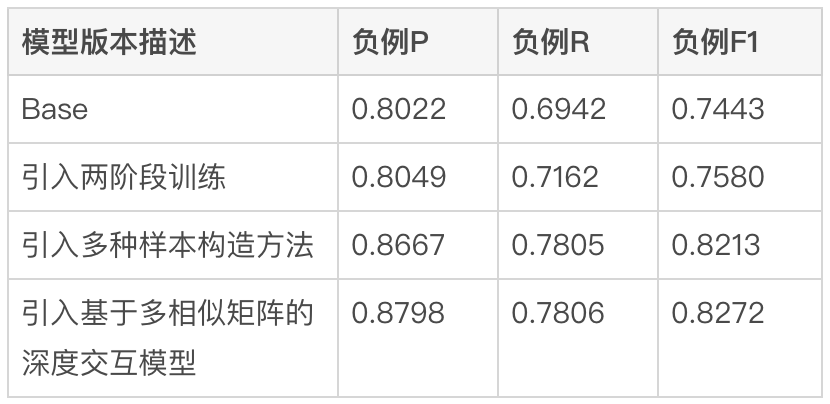
schlug eine Methode vor, das interaktionsbasierte Modell in ein darstellungsbasiertes Modell zu destillieren, um eine virtuelle Interaktion des Twin-Tower-Modells zu erreichen und die Interaktion zwischen Abfrage und POI zu erhöhen und gleichzeitig die Leistung sicherzustellen .Das darstellungsbasierte Modell konzentriert sich auf die Darstellung der globalen Merkmale von POI und es fehlen die passenden Informationen zwischen Online-Abfrage und POI. Die interaktionsbasierte Methode kann die Mängel der Darstellung ausgleichen -basierte Methode und Verbesserung der Abfrage- und POI-Interaktion, um die Ausdrucksfähigkeit des Modells zu verbessern. Gleichzeitig wurde angesichts der starken Leistung des vorab trainierten Modells bei Textsemantik-Matching-Aufgaben eine interaktive Suchkorrelationsberechnung ermittelt Lösung basierend auf dem vorab trainierten Meituan-Modell MT-BERT[11]. Bei der Anwendung von interaktivem BERT basierend auf vorab trainierten Modellen auf die Relevanzaufgabe der Überprüfung von Suchszenarien gibt es immer noch viele Herausforderungen: Nach kontinuierlicher Erkundung und Experimentierung haben wir eine POI-Textzusammenfassung erstellt, die an das Bewertungssuchszenario für die komplexen Informationen aus mehreren Quellen auf der POI-Seite angepasst ist, damit sich das Modell besser an die Berechnung der Bewertungssuchrelevanz anpassen kann. Zwei Methoden wurden verwendet, um die Modellstruktur entsprechend den Merkmalen der Korrelationsberechnung umzuwandeln und schließlich den Berechnungsprozess zu optimieren, Caching und andere Maßnahmen einzuführen, wodurch die Echtzeitberechnung des Modells und die Gesamtanwendung zeitaufwändiger werden Die Verknüpfung wurde erfolgreich reduziert und erfüllte die Anforderungen der Online-Echtzeitberechnung. Bei der Bestimmung der Korrelation zwischen Abfrage und POI sind mehr als ein Dutzend Felder an der Berechnung auf der POI-Seite beteiligt, und es gibt viele Inhalte darunter Einige Felder (Zum Beispiel kann ein Händler Hunderte von empfohlenen Gerichten haben), daher müssen sie eine geeignete Möglichkeit finden, POI-Nebeninformationen zu extrahieren, zu organisieren und in das Korrelationsmodell einzugeben. Allgemeine Suchmaschinen (wie Baidu) oder gängige vertikale Suchmaschinen (wie Taobao) verfügen über eine große Menge an Informationen im Webseitentitel oder Produkttitel ihres Dokuments, der normalerweise die Hauptinhaltseingabe für das Dokument darstellt Dokumentseitiges Modell im Relevanzbestimmungsprozess. Wie in Abbildung 3(a) dargestellt, sind in einer allgemeinen Suchmaschine die Schlüsselinformationen der entsprechenden Website und ob sie mit der Suchanfrage in Zusammenhang stehen, auf einen Blick durch den Titel der Suchergebnisse erkennbar, während in Abbildung 3 (b) In den Suchergebnissen der Dianping-App können nicht nur über das Feld „Händlername“ ausreichende Händlerinformationen abgerufen werden. Es ist erforderlich, die Händlerkategorie (Milchteesaft) und die vom Benutzer empfohlenen Gerichte (Oli-Milchtee) zu kombinieren. Tags (Internet Celebrity Store), Adresse ( Wulin Plaza) Mehrere Felder können verwendet werden, um die Relevanz des Händlers für die Abfrage „Wulin Plaza Internet Celebrity Milk Tea“ zu bestimmen. (a) Beispiel für ein allgemeines Suchergebnis einer Suchmaschine Die Tag-Extraktion ist eine relativ gängige Methode zum Extrahieren von Themeninformationen in der Branche. Daher haben wir zunächst versucht, die Eingabemethode für das POI-Seitenmodell mithilfe von Händler-Tags und basierend auf den Kommentaren des Händlers, grundlegenden Informationen, Gerichten und entsprechenden Kopfsuchklicks zu erstellen an den Händler Wörter usw. werden verwendet, um repräsentative Händlerschlüsselwörter als Händler-Tags zu extrahieren. Bei der Online-Nutzung werden die extrahierten Händler-Tags, der Händlername und die grundlegenden Informationen zur Kategorie als Eingabeinformationen auf der POI-Seite des Modells verwendet und mit Query werden interaktive Berechnungen durchgeführt. Die Abdeckung der Händlerinformationen durch Händler-Tags ist jedoch immer noch nicht umfassend genug. Wenn ein Benutzer beispielsweise nach dem Gericht „Eiercreme“ sucht, verkauft ein koreanisches Restaurant in der Nähe des Benutzers Eiercreme, aber das charakteristische Gericht des Geschäfts, Kopfklick Wörter haben nichts mit „Eiercreme“ zu tun, was dazu führt, dass die vom Geschäft extrahierten Tag-Wörter auch eine geringe Korrelation mit „Eiercreme“ aufweisen, sodass das Modell das Geschäft als irrelevant beurteilt, was zu einer Beeinträchtigung der Benutzererfahrung führt. Um eine möglichst umfassende POI-Darstellung zu erhalten, besteht eine Lösung darin, alle Felder des Händlers direkt in die Modelleingabe einzubinden, ohne Schlüsselwörter zu extrahieren. Diese Methode beeinträchtigt jedoch die Online-Leistung erheblich, da die Modelleingabelänge zu lang ist. , und eine große Menge redundanter Informationen wirkt sich auch auf die Modellleistung aus. vorgeschlagen, die die Online-Abfrage-Matching-Situation kombiniert, um den passenden Feldtext des POI in Echtzeit zu extrahieren Konstruieren Sie die Übereinstimmung. Die Feldzusammenfassung wird als Eingabeinformationen für das POI-seitige Modell verwendet. Der Extraktionsprozess der POI-Übereinstimmungsfeldzusammenfassung ist in Abbildung 4 dargestellt. Basierend auf einigen Textähnlichkeitsmerkmalen extrahieren wir die Textfelder, die für die Abfrage am relevantesten und informativsten sind, und integrieren die Feldtypinformationen, um eine Übereinstimmungsfeldzusammenfassung zu erstellen. Bei der Online-Nutzung werden die extrahierte POI-Übereinstimmungsfeldzusammenfassung, der Händlername und die grundlegenden Kategorieinformationen als POI-Seitenmodell eingegeben. Abbildung 4 Prozess zum Extrahieren der POI-Übereinstimmungsfeldzusammenfassung 3.2 So optimieren Sie das Modell, um es besser an die Relevanzberechnung für die Bewertungssuche anzupassen Damit sich das Modell besser an die Berechnung der Relevanzberechnung für die Bewertungssuche anpassen kann, enthält es zwei Bedeutungen: Textinformationen im Dianping-Suchszenario und MT- Es gibt bestimmte Unterschiede in der Verteilung des vom BERT-Vortrainingsmodell verwendeten Korpus; die Inter-Satz-Beziehungsaufgaben des Vortrainingsmodells unterscheiden sich ebenfalls geringfügig von den Korrelationsaufgaben von Abfrage und POI, und die Modellstruktur muss geändert werden. Nach kontinuierlicher Erkundung haben wir ein zweistufiges Trainingsschema basierend auf Domänendaten in Kombination mit der Konstruktion von Trainingsbeispielen eingeführt, um das Vortrainingsmodell für die Korrelationsaufgabe von Überprüfungssuchszenarien besser geeignet zu machen, und eine tiefe interaktive Korrelation basierend auf mehreren vorgeschlagen Ähnlichkeitsmatrizen Das Modell stärkt die Interaktion zwischen Abfrage und POI, verbessert die Fähigkeit des Modells, komplexe Abfrage- und POI-Informationen auszudrücken, und optimiert den Korrelationsberechnungseffekt. Um Benutzerklickdaten effektiv zu nutzen und das vorab trainierte Modell MT-BERT besser für Überprüfungssuchrelevanzaufgaben geeignet zu machen, ziehen wir Lehren aus der Baidu-Suchrelevanz[ 12] Die Idee besteht darin, eine mehrstufige Trainingsmethode einzuführen, die Benutzerklicks und negative Stichprobendaten für die erste Stufe des Domänenanpassungs-Vortrainings (Kontinuierliches domänenadaptives Vortraining) verwendet und manuelle Annotationsdaten für verwendet In der zweiten Trainingsphase (Fine-Tune) ist die Modellstruktur in Abbildung 5 unten dargestellt: Abbildung 5 Zweistufige Trainingsmodellstruktur basierend auf Klick- und manuellen Anmerkungsdaten Die erste Stufe des Trainings basierend auf Klickdaten Der direkte Grund für die Einführung von Klickdaten als Trainingsaufgabe der ersten Stufe besteht darin, dass es im Bewertungssuchszenario einige einzigartige Probleme gibt. Zum Beispiel die Wörter „glücklich“ und „. „Happy“ sind in gängigen Szenarien fast vollständig synonym, aber im Bewertungssuchszenario sind „Happy BBQ“ und „Happy BBQ“ zwei völlig unterschiedliche Markenhändler, sodass die Einführung von Klickdaten dem Modell dabei helfen kann, bei der Suche einzigartiges Wissen zu erlernen Szenario. Bei der direkten Verwendung von Klickproben zur Korrelationsbeurteilung entsteht jedoch viel Lärm, da der Benutzer möglicherweise aufgrund eines höheren Rankings versehentlich auf einen Händler klickt und der Benutzer möglicherweise nicht auf einen Händler klickt, nur weil der Händler weit entfernt ist Da dies nicht auf das Korrelationsproblem zurückzuführen ist, haben wir verschiedene Funktionen und Regeln eingeführt, um die Genauigkeit der automatischen Annotation von Trainingsbeispielen zu verbessern. Bei der Erstellung der Stichprobe werden Kandidatenstichproben überprüft, indem gezählt wird, ob ein Klick vorliegt, die Klickposition, der Abstand zwischen dem Händler mit dem größten Klick und dem Benutzer usw. sowie die Abfrage-POI-Paare, deren Belichtungsklickrate beträgt Werte über einem bestimmten Schwellenwert gelten als positive Beispiele und basieren auf den Geschäftsfunktionen: Passen Sie unterschiedliche Schwellenwerte für verschiedene Arten von Händlern an. Hinsichtlich der Struktur der Negativbeispiele werden bei der Skip-Above-Sampling-Strategie Händler als Negativbeispiele herangezogen, die vor dem angeklickten Händler liegen und deren Klickrate unter dem Schwellenwert liegt. Darüber hinaus können zufällige negative Stichproben einfache negative Beispiele für Trainingsstichproben ergänzen. Bei der Betrachtung zufälliger negativer Stichproben werden jedoch auch einige Rauschdaten eingeführt. Daher verwenden wir künstlich entworfene Regeln, um die Trainingsdaten zu entrauschen: Wenn die Kategorieabsicht der Abfrage besteht anders als Wenn das Kategoriensystem eines POI relativ konsistent ist oder stark mit dem POI-Namen übereinstimmt, wird es aus den negativen Stichproben entfernt. Die zweite Trainingsstufe basiert auf manuellen Anmerkungsdaten Nach der ersten Trainingsstufe ist es angesichts der Tatsache, dass das Rauschen in den Klickdaten nicht vollständig entfernt werden kann, und den Merkmalen der Korrelationsaufgabe erforderlich zur Einführung künstlicher Die zweite Stufe des Trainings markierter Proben wird zur Korrektur des Modells verwendet. Um die Fähigkeiten des Modells so weit wie möglich zu verbessern, führen wir nicht nur zufällige Stichproben aus einem Teil der Daten durch und übergeben sie der manuellen Annotation, sondern produzieren auch eine große Anzahl hochwertiger Stichproben durch schwieriges Beispiel-Mining und vergleichende Stichprobenverbesserung und Hand sie zur manuellen Annotation übergeben. Die Details sind wie folgt: 1) Schwieriges Fall-Mining 2) Kontrastprobenverbesserung: Basierend auf der Idee des kontrastiven Lernens generieren wir Kontrastproben zur Datenverbesserung für einige gut übereinstimmende Proben und führen manuelle Anmerkungen durch, um die Genauigkeit der Probenetiketten sicherzustellen. Durch den Vergleich der Unterschiede zwischen Stichproben kann sich das Modell auf wirklich nützliche Informationen konzentrieren und seine Generalisierungsfähigkeit für Synonyme verbessern, wodurch bessere Ergebnisse erzielt werden. # 🎜🎜##🎜 🎜# Unterliegt CEDR [8]#🎜🎜 Inspiriert von # teilen wir die von MT-BERT codierten Abfrage- und POI-Vektoren auf, um die detaillierte Interaktionsbeziehung zwischen den beiden Teilen zu berechnen Einerseits können wir die Korrelation zwischen Abfrage und POI gezielt erlernen, andererseits kann die erhöhte Anzahl von Parametern die Anpassungsfähigkeit des Modells verbessern. -Modell berechnet das tiefe Kreuzkorrelationsmodell vier verschiedene Query-Doc-Ähnlichkeitsmatrizen und führt sie zusammen , einschließlich Indikator, Skalarprodukt, Kosinusdistanz und euklidischer Distanz, und werden mit der Ausgabe des POI-Teils aufmerksamkeitsgewichtet. Die Indikatormatrix wird verwendet, um zu beschreiben, ob das Token der Abfrage und der POI konsistent sind. Die Berechnungsmethode ist wie folgt: , das die passende Matrix darstellt. Das der Zeile und Spalte entsprechende Element stellt das Abfrage-Token und das POI-Token dar. Da es sich bei der Indikatormatrix um eine Matrix handelt, die angibt, ob die Abfrage und der POI buchstäblich übereinstimmen, und das Eingabeformat der anderen drei semantischen Übereinstimmungsmatrizen unterschiedlich ist, stehen die drei Übereinstimmungsmatrizen Skalarprodukt, Kosinusabstand und euklidischer Abstand an erster Stelle fusioniert, und dann werden die erhaltenen Ergebnisse mit der Indikatormatrix kombiniert. Die Matrizen werden weiter fusioniert, bevor der endgültige Korrelationswert berechnet wird. Die Indikatormatrix kann die Übereinstimmungsbeziehung zwischen Abfrage und POI besser beschreiben. Die Einführung dieser Matrix berücksichtigt hauptsächlich die Schwierigkeit, den Grad der Korrelation zwischen Abfrage und POI zu bestimmen: manchmal sogar, wenn der Text vorhanden ist sehr ähnlich, die beiden sind nicht verwandt. Die interaktionsbasierte BERT-Modellstruktur erleichtert die Ermittlung der Relevanz von Suchanfragen und POIs mit einem hohen Grad an Textübereinstimmung. Im Szenario der Rezensionssuche ist dies jedoch in einigen schwierigen Fällen möglicherweise nicht der Fall. Obwohl beispielsweise „Bohnensaft“ und „Mungbohnensaft“ sehr gut zusammenpassen, sind sie nicht miteinander verwandt. Obwohl „Maokong“ und „Cat’s Sky Castle“ getrennte Übereinstimmungen sind, sind sie verwandt, da Ersteres die Abkürzung für Letzteres ist. Daher werden unterschiedliche Textübereinstimmungssituationen über die Indikatormatrix direkt in das Modell eingegeben, sodass das Modell explizit Textübereinstimmungssituationen wie „enthält“ und „Split-Übereinstimmung“ empfangen kann, was nicht nur dazu beiträgt, dass das Modell seine Fähigkeit zur Unterscheidung schwieriger Fälle verbessert , aber es wird auch die Leistung der meisten normalen Fälle beeinträchtigen. Das tiefe interaktive Korrelationsmodell, das auf mehreren Ähnlichkeitsmatrizen basiert, teilt Abfrage und POI auf und berechnet die Ähnlichkeitsmatrix, was der expliziten Interaktion des Modells mit Abfrage und POI entspricht. Machen Sie das Modell besser für Korrelationsaufgaben geeignet. Mehrere Ähnlichkeitsmatrizen erhöhen die Darstellungsfähigkeit des Modells bei der Berechnung der Korrelation zwischen Abfrage und POI, während die Indikatormatrix speziell für komplexe Textübereinstimmungssituationen bei Korrelationsaufgaben entwickelt wurde, wodurch die Beurteilung irrelevanter Ergebnisse durch das Modell genauer wird. Bei der Online-Bereitstellung von Korrelationsberechnungen sind vorhandene Lösungen normalerweise dual -Turmstruktur der Wissensdestillation [10,14] wird verwendet, um die Effizienz der Online-Berechnung sicherzustellen, aber diese Verarbeitungsmethode ist mehr oder weniger schädlich für die Wirkung des Modells. Überprüfen Sie die Suchkorrelationsberechnung. Um den Modelleffekt sicherzustellen, wird online ein vorab trainiertes 12-Schicht-BERT-Korrelationsmodell basierend auf Interaktion verwendet, das erfordert, dass Hunderte von POIs unter jeder Abfrage vom 12-Schicht-BERT-Modell vorhergesagt werden. Um die Effizienz des Online-Computing sicherzustellen, haben wir von den beiden Perspektiven Modell-Echtzeit-Computing-Prozess und Anwendungsverknüpfung ausgegangen und diese durch die Einführung eines Caching-Mechanismus, die Beschleunigung der Modellvorhersage, die Einführung einer vorgoldenen Regelschicht, die Parallelisierung der Korrelationsberechnung und der Kernsortierung optimiert. usw. Der Leistungsengpass des Korrelationsmodells bei der Online-Bereitstellung ermöglicht eine stabile und effiziente Online-Ausführung des 12-schichtigen interaktionsbasierten BERT-Korrelationsmodells und stellt sicher, dass es Korrelationsberechnungen zwischen Hunderten von Händlern und Query unterstützen kann. Abbildung 8 Korrelationsmodell online Berechnungsflussdiagramm Der Online-Berechnungsprozess des Kommentarsuchkorrelationsmodells ist in Abbildung 8 dargestellt, das durch den Caching-Mechanismus und die Vorhersagebeschleunigung des TF-Serving-Modells optimiert wird Leistung der Modell-Echtzeitberechnung. Um Rechenressourcen effektiv zu nutzen, führt die Online-Bereitstellung des Modells einen Caching-Mechanismus ein, um die Korrelationswerte von Hochfrequenzabfragen in den Cache zu schreiben. Bei nachfolgenden Aufrufen wird zuerst der Cache gelesen, wenn der Cache erreicht wird, wird die Punktzahl direkt ausgegeben. Wenn der Cache nicht erreicht wird, wird die Punktzahl online in Echtzeit berechnet. Der Caching-Mechanismus spart erheblich Rechenressourcen und verringert effektiv den Leistungsdruck beim Online-Computing. Für eine Abfrage, bei der der Cache fehlt, verarbeiten Sie sie als abfrageseitige Modelleingabe, rufen Sie die passende Feldzusammenfassung jedes POI über den in Abbildung 4 beschriebenen Prozess ab und verarbeiten Sie sie Geben Sie das Format für das POI-Seitenmodell ein und rufen Sie dann das Online-Korrelationsmodell auf, um den Korrelationswert auszugeben. Das Korrelationsmodell wird auf TF-Serving eingesetzt. Bei der Vorhersage des Modells wird das Modelloptimierungstool ART-Framework der Meituan-Plattform für maschinelles Lernen verwendet (basierend auf Faster-Transformer[15] Improvement#🎜 🎜#) für die Beschleunigung, was die Geschwindigkeit der Modellvorhersage erheblich verbessert und gleichzeitig die Genauigkeit gewährleistet. Abbildung 9 Korrelationsmodell in Anwendung in Überprüfen Sie den Suchlink Die Anwendung des Korrelationsmodells im Suchlink ist in Abbildung 9 oben dargestellt. Durch Einführung der vorgoldenen Regel wird die Korrelation berechnet die Kernsortierschicht, um die Leistung in der gesamten Suchkette zu optimieren. Um die Korrelationsaufrufverknüpfung weiter zu beschleunigen, haben wir die vorgoldene Regel zum Umleiten von Abfragen eingeführt und dadurch den Korrelationsscore direkt über Regeln für einige Abfragen ausgegeben Entlastung des Modells. Berechnen Sie den Druck. In der Golden-Rule-Schicht werden Textabgleichsfunktionen verwendet, um Abfrage und POI zu beurteilen. Wenn der Suchbegriff beispielsweise genau mit dem Händlernamen übereinstimmt, wird die „relevante“ Beurteilung direkt über die Golden-Rule-Schicht ausgegeben, ohne die Korrelation zu berechnen Bewertung durch das Korrelationsmodell. Im Gesamtberechnungslink werden der Korrelationsberechnungsprozess und die Kernsortierschicht gleichzeitig ausgeführt, um sicherzustellen, dass die Korrelationsberechnung grundsätzlich keinen Einfluss auf den Gesamtzeitaufwand des Suchlinks hat. Auf der Anwendungsebene werden Korrelationsberechnungen in vielen Aspekten verwendet, beispielsweise beim Abrufen und Sortieren von Suchlinks. Um den Anteil irrelevanter Händler auf dem ersten Bildschirm der Suchliste zu reduzieren, haben wir die Relevanzbewertung in die LTR-Mehrziel-Fusionssortierung eingeführt, um die Listenseiten zu sortieren, und eine Multi-Way-Recall-Fusion-Strategie übernommen des Korrelationsmodells wird nur der ergänzende Rückrufpfad Verwandte Händler in der Liste zusammengeführt. Um den Offline-Effekt der Modelliteration genau wiederzugeben Wir bestehen mehrere Runden manueller Anmerkungen, um einen Stapel von Benchmarks zu erstellen. Da das Hauptziel bei der tatsächlichen Online-Nutzung darin besteht, den BadCase-Indikator zu reduzieren, d. und F1-Wert von Negativbeispielen als Messwerte. Die Vorteile, die das zweistufige Training, die Beispielkonstruktion und die Modelliteration mit sich bringen, sind in der folgenden Tabelle 1 aufgeführt: Überprüfen Sie den Offline-Index der Modelliteration für die Suchrelevanz #Base) verwendet Abfrage, um zusammenfassende POI-Übereinstimmungsfeldinformationen für die Klassifizierung von BERT-Satzpaaren zu verbinden. In der Aufgabe verwendet die Modelleingabe auf der Abfrageseite die ursprüngliche Abfrageeingabe des Benutzers und die POI-Seite den Händlernamen und die Händlerkategorie und Methode zum Zusammenfügen von zusammenfassendem Text in passenden Feldern. Nach der Einführung des zweistufigen Trainings basierend auf Klickdaten stieg der F1-Index für negative Beispiele im Vergleich zur Basismethode um 1,84 % durch die Einführung von Vergleichsproben und schwierigen Beispielproben, um Trainingsproben kontinuierlich zu iterieren und mit der Eingabestruktur des Modells der zweiten Stufe zusammenzuarbeiten , der Negativbeispiel-F1-Index im Vergleich zur Basismethode Eine signifikante Verbesserung von 10,35 % Nach der Einführung der Tiefeninteraktionsmethode basierend auf mehreren Ähnlichkeitsmatrizen verbesserte sich der Negativbeispiel-F1 im Vergleich zur Basis um 11,14 %. Die Gesamtindikatoren des Modells im Benchmark erreichten ebenfalls hohe Werte von AUC von 0,96 und F1 von 0,97. Um die Suchzufriedenheit der Benutzer effektiv zu messen, prüft Dianping Search jeden Tag den tatsächlichen Online-Verkehr und beschriftet ihn manuell. Die BadCase-Rate auf dem ersten Bildschirm der Listenseite wird als Kernindikator für die Bewertung der Wirksamkeit des Korrelationsmodells verwendet. Nach der Einführung des Korrelationsmodells sank der monatliche durchschnittliche BadCase-Rate-Indikator der Dianping-Suche deutlich um 2,9 Prozentpunkte (Prozentpunkt, Prozentsatz absoluter Punkt Abbildung 10 unten listet einige Beispiele für Online-BadCase-Lösungen auf. Der Untertitel ist die Abfrage, die dem Beispiel entspricht. Die linke Seite ist die experimentelle Gruppe, die das Korrelationsmodell angewendet hat. und die rechte Seite ist die Kontrollgruppe. Wenn in Abbildung 10(a) der Suchbegriff „Pei Jie“ lautet, bestimmt das Korrelationsmodell, dass der Händler „Pei Jie Famous Products“, dessen Kernwort „Pei Jie“ enthält, relevant ist, und wählt hochwertige Artikel aus, die der Benutzer verwenden kann Möglicherweise möchten Sie den Qualitätszielhändler „Pei Jie Lao Hotpot“ finden. Gleichzeitig werden durch die Eingabe der Adressfeldkennung die Händler angezeigt, die sich neben „Pei Jie“ in der Adresse befinden Als irrelevant beurteilt; in Abbildung 10(b) übergibt der Benutzer die Abfrage „Youzi Ri „Selbstbedienungslebensmittel“ möchte einen japanischen Lebensmittel-Selbstbedienungsladen namens „Yuzu“ finden. Das Korrelationsmodell gleicht die geteilten Wörter mit dem ab Der japanische Lebensmittel-Selbstbedienungsladen „Takewako Tuna“, der Yuzu-bezogene Produkte verkauft, beurteilt diese korrekt als irrelevant und ordnet sie entsprechend ein. Schließlich ist garantiert, dass die oben angezeigten Händler Händler sind, die eher mit den Hauptprodukten des Benutzers übereinstimmen Bedürfnisse. (a) Schwester Pei # 🎜🎜#(b) Pomelo Japanese Food BuffetAbbildung 10 Online-BadCase-Lösungsbeispiel Dieser Artikel stellt die technische Lösung und praktische Anwendung des Dianping-Suchkorrelationsmodells vor. Um die Eingabeinformationen des händlerseitigen Modells besser zu konstruieren, haben wir eine Methode zum Extrahieren des zusammenfassenden Texts der Händler-Übereinstimmungsfelder in Echtzeit eingeführt, um Händlerdarstellungen als Modelleingabe zu erstellen und das Modell so zu optimieren, dass es sich besser an die Überprüfung von Suchkorrelationsberechnungen anpassen kann. Es wurde ein zweistufiger Prozess verwendet. Die Trainingsmethode verwendet ein zweistufiges Trainingsschema, das auf Klicks und manuellen Anmerkungsdaten basiert, um die Benutzerklickdaten von Dianping effektiv zu nutzen. Gemäß den Merkmalen der Korrelationsberechnung entsteht eine tiefe Interaktionsstruktur, die auf mehreren Ähnlichkeiten basiert Um den Online-Rechnerdruck des Korrelationsmodells zu verringern, werden Matrizen während der Online-Bereitstellung eingeführt. Die goldene Regelschicht wird eingeführt, um Abfragen auszulagern. und die Korrelationsberechnung wird mit der Kernsortierschicht parallelisiert, wodurch die Online-Leistungsanforderungen für die Echtzeitberechnung von BERT erfüllt werden. Durch die Anwendung des Korrelationsmodells auf jeden Link des Suchlinks wird der Anteil irrelevanter Fragen deutlich reduziert und das Sucherlebnis des Benutzers effektiv verbessert. Derzeit besteht beim Bewertungssuchkorrelationsmodell noch Raum für Verbesserungen in der Modellleistung und bei Online-Anwendungen. In Bezug auf die Modellstruktur werden wir weitere Domänenvorkenntnisse untersuchen und Methoden einführen B. Multitasking-Lernen zur Identifizierung von Entitätstypen in Abfragen, Integration von Eingaben aus externen Wissensoptimierungsmodellen usw. im Hinblick auf praktische Anwendungen. Es wird weiter auf weitere Ebenen verfeinert, um den Anforderungen der Benutzer an eine verfeinerte Geschäftssuche gerecht zu werden. Wir werden auch versuchen, die Relevanzfähigkeit auf Nicht-Merchant-Module anzuwenden, um das Sucherlebnis der gesamten Suchliste zu optimieren. xiaoya*, Shen Yuan *, Judy, Tang Biao, Zhang Gong usw. sind alle vom Search Technology Center der Meituan/Dianping Division. * ist Co-Autor dieses Artikels. 3. Überprüfen Sie die Suchkorrelationsberechnung
3.1 So erstellen Sie die Eingabeinformationen des POI-seitigen Modells besser
 Um aussagekräftigere POI-Seiteninformationen als Modelleingabe zu erstellen, haben wir die Methode
Um aussagekräftigere POI-Seiteninformationen als Modelleingabe zu erstellen, haben wir die Methode 3.2.1 Zweistufiges Training basierend auf Domänendaten
Unter Bezugnahme auf das MatchPyramid
[13]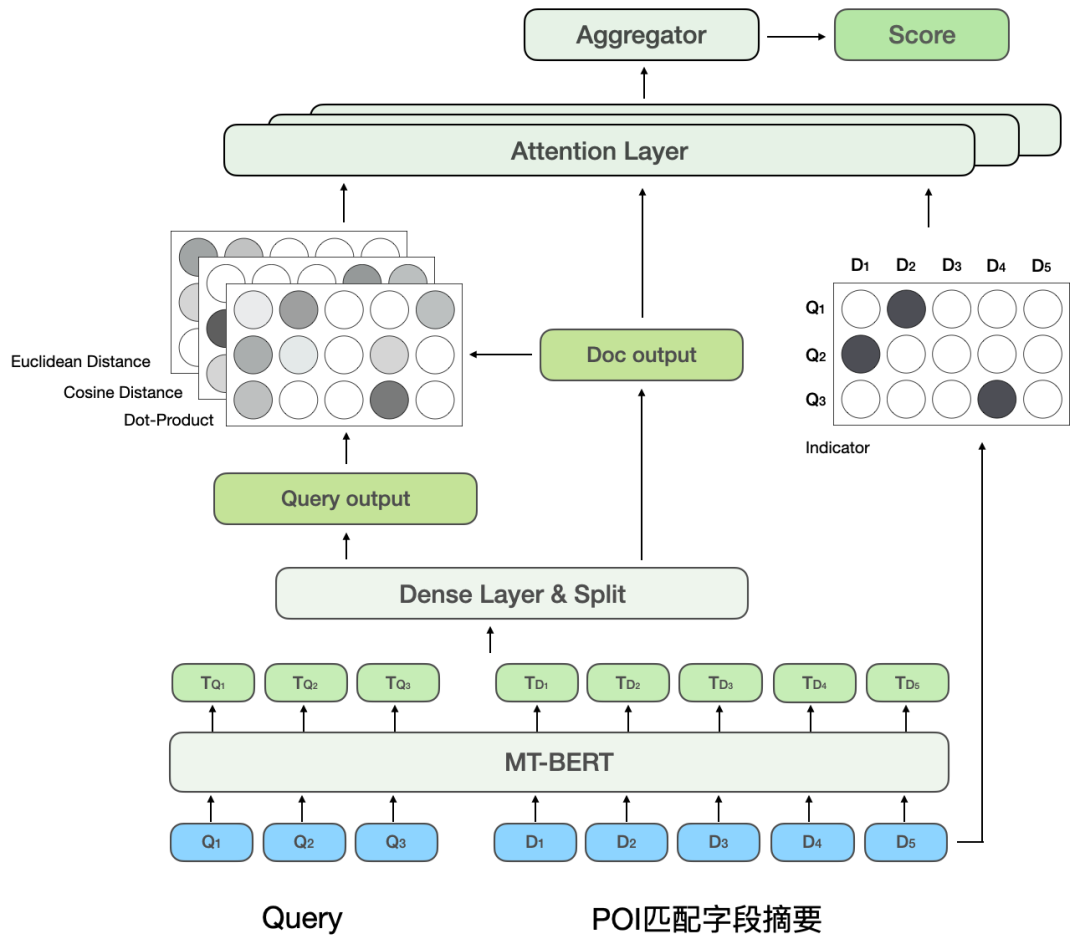
3.3 So lösen Sie den Online-Leistungsengpass des vorab trainierten Korrelationsmodells
3.3.1 Leistungsoptimierung des Korrelationsmodellberechnungsprozesses
4. Praktische Anwendung
4.1 Offline-Effekt
 4.2 Online-Effekt
4.2 Online-Effekt 5. Zusammenfassung und Ausblick
6. Über den Autor
Das obige ist der detaillierte Inhalt vonErforschung und Praxis der Suchrelevanztechnologie von Dianping. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr