
Heim >Technologie-Peripheriegeräte >KI >Kann maschinelles Lernen wirklich zu intelligenten Entscheidungen führen?
Kann maschinelles Lernen wirklich zu intelligenten Entscheidungen führen?

- 王林nach vorne
- 2023-05-17 08:16:05731Durchsuche
Nach drei Jahren haben wir im Jahr 2022 Judea Pearl, Gewinnerin des Turing Award, Professorin für Informatik an der UCLA, Akademikerin der National Academy of Sciences und bekannt als „Vater der Bayesianischen Netzwerke“, fertiggestellt. Das Meisterwerk „Causation: Models“. , Argumentation und Schlussfolgerung“.
Die ursprüngliche Erstausgabe dieses Buches wurde im Jahr 2000 geschrieben. Es war der Wegbereiter für neue Ideen und Methoden der Kausalanalyse und Schlussfolgerung. Es erhielt großes Lob, sobald es veröffentlicht wurde, und förderte Datenwissenschaft, künstliche Intelligenz, maschinelles Lernen und Kausalität Neue Revolutionen in Bereichen wie der Analyse hatten große Auswirkungen auf die Wissenschaft.
Später wurde die zweite Auflage im Jahr 2009 überarbeitet. Der Inhalt wurde aufgrund der neuen Entwicklungen in der Ursachenforschung zu dieser Zeit erheblich geändert. Die englische Originalversion des Buches, das wir derzeit übersetzen, wurde 2009 veröffentlicht, ist also mehr als zehn Jahre her.
Die Veröffentlichung der chinesischen Version dieses Buches wird chinesischen Wissenschaftlern, Studenten und Praktikern in verschiedenen Bereichen helfen, Inhalte im Zusammenhang mit Kausalmodellen, Argumentation und Schlussfolgerungen zu verstehen und zu beherrschen. Wie kann insbesondere in der heutigen Zeit, in der Statistiken und maschinelles Lernen beliebt sind, der Wandel von „Datenanpassung“ zu „Datenverständnis“ erreicht werden? Wie kann man im nächsten Jahrzehnt von der derzeit vorherrschenden Annahme, dass „alles Wissen aus den Daten selbst stammt“, zu einem völlig neuen Paradigma des maschinellen Lernens übergehen? Wird es eine „zweite Revolution der künstlichen Intelligenz“ auslösen?
Gerade als Pearl mit dem Turing Award ausgezeichnet wurde, wurde seine Arbeit als „ein grundlegender Beitrag auf dem Gebiet der künstlichen Intelligenz“ bewertet. Er schlug probabilistische und kausale Schlussfolgerungsalgorithmen vor, die die Richtung der ursprünglich auf Regeln basierenden künstlichen Intelligenz völlig veränderten und Logik.“ Wir erwarten, dass dieses Paradigma neue technische Richtungen und Impulse für maschinelles Lernen bringt und letztendlich eine Rolle in praktischen Anwendungen spielt.
正Wie Pearl sagte: „Die Datenanpassung dominiert derzeit fest die aktuellen Bereiche der Statistik und des maschinellen Lernens und ist das wichtigste Forschungsparadigma für die meisten Forscher des maschinellen Lernens, insbesondere für diejenigen, die sich mit den Themen „ISM“, „Deep Learning“ und „Join“ befassen Neuronale Netzwerktechnologie.“ Dieses Paradigma mit „Datenanpassung“ als Kern hat bemerkenswerte Erfolge in Anwendungsfeldern wie Computer Vision, Spracherkennung und autonomes Fahren erzielt. Viele Forscher auf dem Gebiet der Datenwissenschaft haben jedoch auch erkannt, dass maschinelles Lernen in der aktuellen Praxis nicht das Verständnis hervorbringen kann, das für eine intelligente Entscheidungsfindung erforderlich ist. Zu diesen Themen gehören: Robustheit, Übertragbarkeit, Interpretierbarkeit usw. Schauen wir uns unten ein Beispiel an.
1. Sind die Statistiken zuverlässig?
In den letzten Jahren denken viele Menschen in den Selbstmedien, dass sie Statistiker sind. Denn „Datenanpassung“ und „Alles Wissen kommt aus den Daten selbst“ liefern statistische Grundlagen für viele wichtige Entscheidungen. Allerdings müssen wir bei dieser Analyse vorsichtig sein. Schließlich sind die Dinge nicht immer so, wie sie auf den ersten Blick scheinen! Ein Fall, der eng mit unserem Leben verbunden ist. Vor zehn Jahren betrug der Hauspreis im Stadtzentrum 8.000 Yuan/Quadratmeter, bei einer Gesamtfläche von 10 Millionen Quadratmetern, in der High-Tech-Zone waren es 4.000 Yuan/Quadratmeter, bei einer Gesamtfläche von 1 Million Quadratmeter Insgesamt betrug der durchschnittliche Hauspreis der Stadt 7.636 Yuan/Quadratmeter. Jetzt beträgt der Preis im Stadtzentrum 10.000 Yuan/Quadratmeter, aber weil das Grundstücksangebot im Stadtzentrum geringer ist, wurden nur 2 Millionen Quadratmeter verkauft; die High-Tech-Zone beträgt 6.000 Yuan/Quadratmeter, aber weil es gibt mehr neu erschlossenes Land, insgesamt wurden 20 Millionen Quadratmeter verkauft; der durchschnittliche Hauspreis in der Stadt beträgt jetzt 6.363 Yuan/Quadratmeter. Betrachtet man also die verschiedenen Bereiche, sind die Immobilienpreise einzeln gestiegen, aber insgesamt gesehen werden Zweifel aufkommen: Warum sind die Immobilienpreise jetzt gesunken?
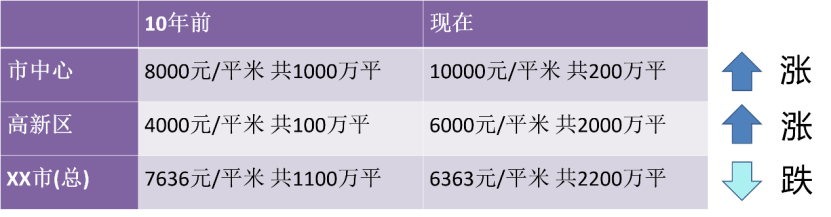
Abbildung 1 Die Immobilienpreisentwicklung ist in verschiedene Regionen unterteilt und widerspricht der Gesamtschlussfolgerung
Wir wissen, dass dieses Phänomen Simpson-Paradoxon genannt wird. Diese Fälle zeigen deutlich, wie wir aus statistischen Daten völlig falsche Modelle und Schlussfolgerungen ziehen können, wenn uns nicht genügend beobachtete Variablen zur Verfügung stehen. Im Falle dieser Pandemie erhalten wir typischerweise bundesweite Statistiken. Wenn wir nach Region, Stadt oder Landkreis gruppieren, könnten wir zu sehr unterschiedlichen Schlussfolgerungen kommen. Im ganzen Land können wir einen Rückgang der Zahl der COVID-19-Fälle beobachten, obwohl in einigen Gebieten ein Anstieg der Fälle zu verzeichnen ist (was den Beginn der nächsten Welle signalisieren könnte). Dies kann auch dann der Fall sein, wenn es sehr unterschiedliche Gruppen gibt, beispielsweise in Gebieten mit sehr unterschiedlicher Bevölkerung. In nationalen Daten können Anstiege in Fällen in weniger dicht besiedelten Gebieten durch Rückgänge in dichter besiedelten Gebieten in den Schatten gestellt werden.
Ähnliche statistische Probleme, die auf „Datenanpassung“ basieren, gibt es zuhauf. Nehmen Sie die folgenden zwei interessanten Beispiele.
Wenn wir Daten über die Anzahl der von Nicolas Cage gespielten Filme und die Anzahl der Ertrinkungen in den Vereinigten Staaten jedes Jahr sammeln, werden wir feststellen, dass diese beiden Variablen stark korrelieren und die Datenanpassung extrem hoch ist .
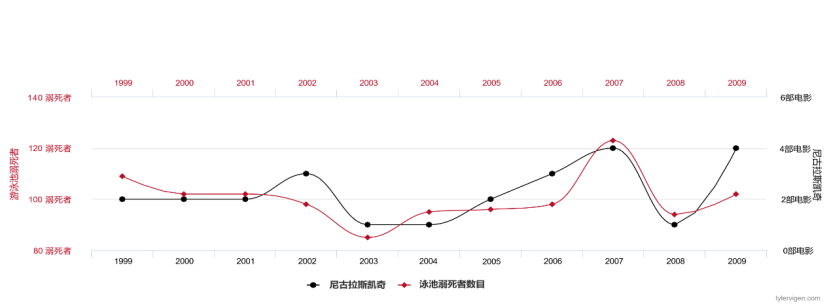
Abbildung 2 Die Anzahl der Filme, in denen Nicolas Cage jedes Jahr auftritt, und die Anzahl der Menschen, die in den Vereinigten Staaten ertrinken Staaten#🎜 🎜#
Wenn wir Daten zum Pro-Kopf-Milchverkauf und zur Anzahl der Nobelpreisträger in jedem Land sammeln, werden wir das herausfinden Diese beiden Variablen sind stark korreliert.
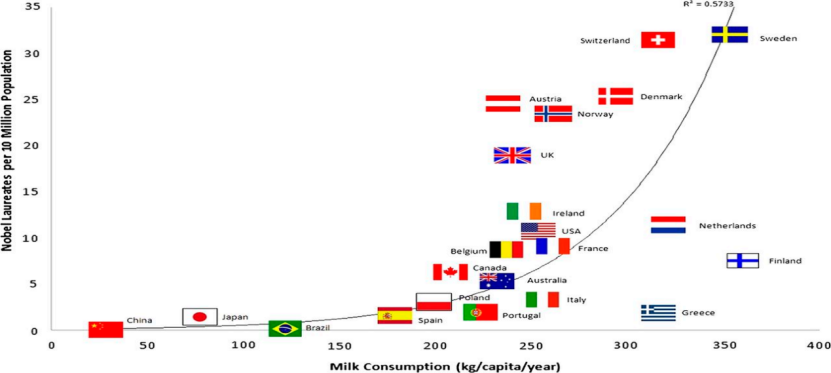
Abbildung 3 Pro-Kopf-Milchverbrauch und Anzahl der Nobelpreise#🎜🎜 #
Aus unserem gesunden Menschenverstand als Menschen sind dies Pseudokorrelationen oder sogar Paradoxien. Aber aus der Sicht der Mathematik und Wahrscheinlichkeitstheorie sind Fälle, die falsche Korrelationen oder Paradoxien aufweisen, sowohl aus statistischer als auch aus rechnerischer Sicht unproblematisch. Jeder, der eine kausale Grundlage hat, weiß, dass dies geschieht, weil in den Daten sogenannte lauernde Variablen, unbeobachtete Störfaktoren, verborgen sind.
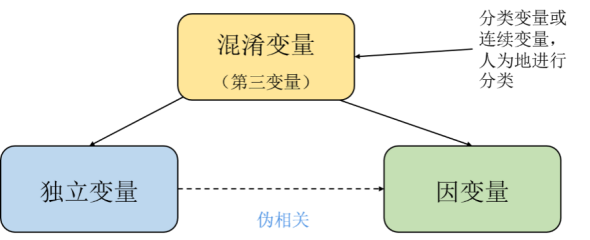
Perl gab in „Die Theorie von Ursache und Wirkung“ ein Lösungsparadigma an, analysierte und leitete die oben genannten Probleme im Detail ab und betonte den Zusammenhang zwischen Ursache und Wirkung und Statistik Der wesentliche Unterschied besteht darin, dass Kausalanalyse und Schlussfolgerung immer noch auf dem Kontext der Statistik basieren. Pearl schlug das grundlegende Berechnungsmodell für Interventionsoperationen (Operatoren) vor, einschließlich des Hintertürprinzips und spezifischer Berechnungsformeln. Dies ist derzeit die mathematischste Beschreibung der Kausalität. „Kausalität und verwandte Konzepte (wie Randomisierung, Confounding, Intervention usw.) sind keine statistischen Konzepte, die sich durch Pearls Kausalanalyse-Denken ziehen, das Pearl das erste Prinzip nennt.“
Die aktuellen datengesteuerten maschinellen Lernmethoden, insbesondere die Algorithmen, die stark auf statistischen Methoden basieren, enthalten also sehr wahrscheinlich die Hälfte der gelernten Modelle , irreführende oder gegenteilige Ergebnisse. Dies liegt daran, dass diese Modelle dazu neigen, auf der Grundlage der Verteilung der beobachteten Daten zu lernen und nicht auf dem Mechanismus, durch den die Daten generiert werden.
2. Drei Probleme, die maschinelles Lernen dringend lösen muss
Robustheit:Mit Die Popularität von Deep-Learning-Methoden, die Forschung in den Bereichen Computer Vision, Verarbeitung natürlicher Sprache und Spracherkennung haben dazu geführt, dass modernste tiefe neuronale Netzwerkstrukturen in großem Umfang genutzt werden. Es besteht jedoch immer noch ein langfristiges Problem darin, dass die Verteilung der von uns gesammelten Daten in der realen Welt normalerweise selten vollständig ist und möglicherweise nicht mit der Verteilung in der realen Welt übereinstimmt. Bei Computer-Vision-Anwendungen kann die Verteilung der Trainingssatz- und Testsatzdaten durch Faktoren wie Pixelunterschiede, Komprimierungsqualität oder Kameraverschiebung, -drehung oder -winkel beeinflusst werden. Bei diesen Variablen handelt es sich tatsächlich um „Interventionsthemen“ im Konzept von Ursache und Wirkung. Darauf aufbauend wurden einfache Algorithmen vorgeschlagen, um Eingriffe zu simulieren, um die Generalisierungsfähigkeit von Klassifizierungs- und Erkennungsmodellen gezielt zu testen, wie z. B. räumlicher Versatz, Unschärfe, Änderungen in Helligkeit oder Kontrast, Hintergrundsteuerung und -rotation sowie die Erfassung in mehreren Umgebungen. Obwohl wir mit Methoden wie Datenerweiterung, Vortraining und selbstüberwachtem Lernen einige Fortschritte bei der Robustheit erzielt haben, besteht bisher kein klarer Konsens darüber, wie diese Probleme gelöst werden können. Es wurde argumentiert, dass diese Korrekturen möglicherweise nicht ausreichen und dass eine Verallgemeinerung über die unabhängige und identisch verteilte Annahme hinaus das Erlernen nicht nur statistischer Zusammenhänge zwischen Variablen, sondern auch zugrunde liegender Kausalmodelle erfordert, die die Mechanismen verdeutlichen, durch die die Daten generiert wurden, und eine Simulation durch Eingriffe ermöglichen Konzepte Vertriebsänderungen.
Übertragbarkeit: Das Verständnis von Objekten durch Kleinkinder basiert auf der Verfolgung von Objekten, die sich im Laufe der Zeit konsistent verhalten. Ein solcher Ansatz ermöglicht es Kleinkindern, schnell neue Aufgaben zu erlernen, da ihr Wissen und ihr intuitives Verständnis von Objekten wiederverwendet werden können. Ebenso erfordert die effiziente Lösung realer Aufgaben die Wiederverwendung erlernter Kenntnisse und Fähigkeiten in neuen Szenarien. Untersuchungen haben gezeigt, dass maschinelle Lernsysteme, die Umweltwissen erlernen, effizienter und vielseitiger sind. Wenn wir die reale Welt modellieren, zeigen viele Module ein ähnliches Verhalten bei unterschiedlichen Aufgaben und Umgebungen. Daher müssen Menschen oder Maschinen möglicherweise nur wenige Module in ihrer internen Darstellung anpassen, wenn sie mit einer neuen Umgebung oder Aufgabe konfrontiert werden. Beim Erlernen eines Kausalmodells sind weniger Proben erforderlich, um sich an neue Umgebungen oder Aufgaben anzupassen, da der Großteil des Wissens (d. h. Module) ohne weiteres Training wiederverwendet werden kann.
Interpretierbarkeit: Interpretierbarkeit ist ein subtiles Konzept, das nicht vollständig mit der Sprache der Booleschen Logik oder der statistischen Wahrscheinlichkeit beschrieben werden kann. Es erfordert zusätzliche dazwischenliegende Konzepte, sogar das Konzept der Kontrafaktuale. Die Definition der Manipulierbarkeit in der Kausalität konzentriert sich auf die Tatsache, dass bedingte Wahrscheinlichkeiten („Menschen ihre Regenschirme öffnen zu sehen bedeutet, dass es regnet“) das Ergebnis einer aktiven Intervention nicht zuverlässig vorhersagen können („Das Weglegen der Regenschirme verhindert nicht, dass es regnet“). Kausalität wird als integraler Bestandteil der Argumentationskette angesehen, die Vorhersagen für Situationen liefern kann, die weit von der beobachteten Verteilung entfernt sind, und sogar Schlussfolgerungen für rein hypothetische Szenarien liefern kann. In diesem Sinne bedeutet die Entdeckung kausaler Zusammenhänge, verlässliches Wissen zu erlangen, das nicht durch die beobachtete Datenverteilung und Trainingsaufgaben eingeschränkt wird, und so eine eindeutige Spezifikation für interpretierbares Lernen bereitzustellen.
3. Drei Ebenen der kausalen Lernmodellierung
Konkret können Modelle des maschinellen Lernens, die auf statistischen Modellen basieren, nur Korrelationsbeziehungen modellieren, und Korrelationsbeziehungen neigen dazu, sich mit Änderungen in der Datenverteilung zu ändern. Das kausale Modell basiert auf der Modellierung kausaler Beziehungen , das die Essenz der Datengenerierung erfasst und die Beziehung zwischen Datengenerierungsmechanismen widerspiegelt. Eine solche Beziehung ist robuster und kann außerhalb der Verteilung verallgemeinert werden. In der Entscheidungstheorie beispielsweise ist die Unterscheidung zwischen Kausalität und Statistik klarer. In der Entscheidungstheorie gibt es zwei Arten von Problemen: Die eine besteht darin, die aktuelle Umgebung zu kennen, eine Intervention zu planen und das Ergebnis vorherzusagen. Der andere Typ besteht darin, die aktuelle Umgebung und die aktuellen Ergebnisse zu kennen und auf die Ursachen zu schließen. Ersteres wird als Folgeproblem und letzteres als Abduktionsproblem bezeichnet [3].
Vorhersagekraft unter unabhängigen und identisch verteilten Bedingungen
Statistische Modelle sind nur oberflächliche Beschreibungen der beobachteten realen Welt, da sie sich nur auf Korrelationen konzentrieren. Für Proben und Etiketten können wir Schätzungen verwenden, um Fragen zu beantworten wie: „Wie hoch ist die Wahrscheinlichkeit, dass auf diesem Foto ein Hund zu sehen ist?“ „Wie hoch ist die Wahrscheinlichkeit einer Herzinsuffizienz angesichts einiger Symptome?“ Solche Fragen können durch Beobachtung ausreichend generierter i.i.d.-Daten beantwortet werden. Obwohl maschinelle Lernalgorithmen diese Dinge gut können, reichen genaue Vorhersagen für unsere Entscheidungsfindung nicht aus, und kausales Lernen stellt eine nützliche Ergänzung dar. Was das vorherige Beispiel betrifft, korreliert die Häufigkeit, mit der Nicolas Cage in Filmen auftritt, positiv mit der Ertrinkungstodesrate in den Vereinigten Staaten. Wir können tatsächlich ein statistisches Lernmodell trainieren, um die Ertrinkungstodesrate in den Vereinigten Staaten basierend auf der Häufigkeit vorherzusagen Nicolas Cage spielt in Filmen mit, aber offensichtlich besteht kein direkter kausaler Zusammenhang zwischen den beiden. Statistische Modelle sind nur dann genau, wenn sie unabhängig und identisch verteilt sind. Wenn wir die Datenverteilung ändern, führt dies zu Fehlern im statistischen Lernmodell.
Vorhersagekraft bei Verteilungsverschiebung/Intervention
Wir diskutieren weiter das Interventionsproblem, das eine größere Herausforderung darstellt, da die Intervention (Operation) uns von der Annahme einer unabhängigen und identischen Verteilung beim statistischen Lernen befreit. Um mit dem Nicolas-Cage-Beispiel fortzufahren: „Wird die Erhöhung der Zahl der Nicolas-Cage-Filme in diesem Jahr die Ertrinkungsrate in den Vereinigten Staaten erhöhen?“ ist eine Interventionsfrage. Offensichtlich wird sich durch menschliches Eingreifen die Datenverteilung ändern und die Bedingungen für das Überleben des statistischen Lernens werden gebrochen, sodass es scheitern wird. Wenn wir andererseits in Gegenwart einer Intervention ein Vorhersagemodell erlernen können, können wir möglicherweise ein Modell erhalten, das robuster gegenüber Verteilungsänderungen in realen Umgebungen ist. Tatsächlich ist die sogenannte Intervention hier nichts Neues. Viele Dinge selbst ändern sich im Laufe der Zeit, beispielsweise die Interessenpräferenzen der Menschen, oder es besteht eine Diskrepanz in der Verteilung des Trainingssatzes und des Testsatzes selbst. Wie bereits erwähnt, erhält die Robustheit neuronaler Netze immer mehr Aufmerksamkeit und ist zu einem Forschungsthema geworden, das eng mit der kausalen Schlussfolgerung verbunden ist. Die Vorhersage im Falle einer Verteilungsverschiebung kann nicht auf das Erreichen einer hohen Genauigkeit des Testsatzes beschränkt werden. Wenn wir Algorithmen für maschinelles Lernen in praktischen Anwendungen einsetzen möchten, müssen wir davon ausgehen, dass sich die Vorhersageergebnisse des Modells auch ändern, wenn sich die Umgebungsbedingungen ändern. Genau. Die Kategorien der Verteilungsverschiebungen in praktischen Anwendungen können unterschiedlich sein. Wenn ein Modell nur bei einigen Testsätzen gute Ergebnisse erzielt, bedeutet dies nicht, dass wir diesem Modell in jeder Situation vertrauen können . Damit wir Vorhersagemodellen in möglichst vielen Situationen vertrauen können, müssen wir Modelle einsetzen, die in der Lage sind, Interventionsfragen zu beantworten, zumindest nicht nur mithilfe statistischer Lernmodelle.
Die Fähigkeit, kontrafaktische Fragen zu beantworten
Bei kontrafaktischen Fragen geht es darum, darüber nachzudenken, warum etwas passiert ist, sich die Konsequenzen verschiedener Aktionen vorzustellen und daraus zu entscheiden, welche Maßnahmen ergriffen werden müssen, um die gewünschten Ergebnisse zu erzielen. Die Beantwortung kontrafaktischer Fragen ist schwieriger als eine Intervention, stellt aber auch eine entscheidende Herausforderung für die KI dar. Wenn eine Interventionsfrage lautet: „Wie würde sich das Risiko einer Herzinsuffizienz ändern, wenn wir jetzt regelmäßig Sport treiben würden?“, lautet die entsprechende kontrafaktische Frage: „Was wäre, wenn dieser Patient, der bereits an Herzinsuffizienz litt, vor einem Jahr mit dem Sport beginnen würde?“ , wird er trotzdem Herzversagen bekommen?“ Offensichtlich ist die Beantwortung solcher kontrafaktischen Fragen für das verstärkende Lernen sehr wichtig. Sie können über ihre eigenen Entscheidungen nachdenken, kontrafaktische Hypothesen formulieren und diese dann durch die Praxis überprüfen, genau wie unsere Wissenschaft. Forschung ist das Gleiche.
4. Anwendung des Kausalen Lernens
Schließlich werfen wir einen Blick darauf, wie man Kausallernen in verschiedenen Bereichen anwenden kann. Der Nobelpreis für Wirtschaftswissenschaften 2021 wurde Joshua D. Angrist und Guido W. Imbens für ihre „methodischen Beiträge zur Analyse kausaler Zusammenhänge“ verliehen. Sie untersuchen die Anwendung kausaler Schlussfolgerungen in der empirischen Arbeitsökonomie. Das Auswahlkomitee für den Wirtschaftsnobelpreis ist davon überzeugt, dass „natürliche Experimente (randomisierte oder kontrollierte Experimente) zur Beantwortung wichtiger Fragen beitragen können“, aber die Frage, wie „Beobachtungsdaten zur Beantwortung kausaler Zusammenhänge genutzt werden können“, ist schwieriger. Eine wichtige Frage in der Ökonomie ist die Frage der Kausalität. Wie wirken sich Einwanderer beispielsweise auf die Arbeitsmarktaussichten der Einheimischen aus? Kann ein Studium an der Graduiertenschule das Einkommen steigern? Welchen Einfluss hat der Mindestlohn auf die Beschäftigungsaussichten von Fachkräften? Diese Fragen sind schwer zu beantworten, weil uns die richtigen Mittel zur Interpretation kontrafaktischer Aussagen fehlen.
Seit den 1970er Jahren haben Statistiker einen Rahmen zur Berechnung von „Kontrafaktualen“ erfunden, um den kausalen Effekt zwischen zwei Variablen aufzudecken. Auf dieser Grundlage haben Ökonomen Methoden wie die Diskontinuitätsregression, die Differenz-in-Differenzen und den Propensity Score weiterentwickelt und sie umfassend in der Ursachenforschung zu verschiedenen wirtschaftspolitischen Fragestellungen eingesetzt. Von religiösen Texten aus dem 6. Jahrhundert bis hin zum kausalen maschinellen Lernen im Jahr 2021, einschließlich der kausalen Verarbeitung natürlicher Sprache, können wir maschinelles Lernen, Statistik und Ökonometrie nutzen, um kausale Effekte zu modellieren. Bei der Analyse in den Wirtschaftswissenschaften und anderen Sozialwissenschaften geht es hauptsächlich um die Abschätzung kausaler Effekte, also der Interventionswirkung einer charakteristischen Variablen auf die Ergebnisvariable. Eigentlich interessiert uns in den meisten Fällen der sogenannte Interventionseffekt. Unter Interventionseffekt versteht man den kausalen Einfluss einer Intervention oder Behandlung auf die Ergebnisvariable. In den Wirtschaftswissenschaften beispielsweise ist einer der am häufigsten analysierten Interventionseffekte der kausale Einfluss von Subventionen an Unternehmen auf das Unternehmenseinkommen. Zu diesem Zweck schlug Rubin den potenziellen Ergebnisrahmen vor.
Obwohl Ökonomen und andere Sozialwissenschaftler kausale Effekte besser genau abschätzen als vorhersagen können, sind sie auch an den prädiktiven Vorteilen maschineller Lernmethoden interessiert. Zum Beispiel genaue Vorhersagefunktionen für Stichproben oder die Fähigkeit, eine große Anzahl von Merkmalen zu verarbeiten. Aber wie wir gesehen haben, sind klassische Modelle des maschinellen Lernens nicht darauf ausgelegt, kausale Effekte abzuschätzen, und die Verwendung handelsüblicher Vorhersagemethoden des maschinellen Lernens kann zu verzerrten Schätzungen der kausalen Effekte führen. Dann müssen wir bestehende Techniken des maschinellen Lernens verbessern, um die Vorteile des maschinellen Lernens zu nutzen, um kausale Effekte kontinuierlich und effektiv abzuschätzen, was zur Geburt des kausalen maschinellen Lernens führte!
Derzeit kann kausales maschinelles Lernen entsprechend der Art der abzuschätzenden kausalen Effekte grob in zwei Forschungsrichtungen unterteilt werden. Eine wichtige Richtung ist die Verbesserung maschineller Lernmethoden für unvoreingenommene und konsistente Schätzungen durchschnittlicher Interventionseffekte. Modelle in diesem Forschungsbereich versuchen, die folgenden Fragen zu beantworten: Wie ist die durchschnittliche Kundenreaktion auf eine Marketingkampagne? Welche durchschnittlichen Auswirkungen hat eine Preisänderung auf den Umsatz? Darüber hinaus konzentriert sich eine weitere Entwicklungslinie in der Forschung zum kausalen maschinellen Lernen auf die Verbesserung maschineller Lernmethoden, um die Spezifität von Interventionseffekten aufzudecken, d. h. die Identifizierung von Subpopulationen von Personen mit über- oder unterdurchschnittlichen Interventionseffekten. Diese Art von Modell zielt darauf ab, die folgende Frage zu beantworten: Welche Kunden reagieren am meisten auf eine Marketingkampagne? Wie unterschiedlich sind die Auswirkungen von Preisänderungen auf den Umsatz mit dem Alter der Kunden?
Zusätzlich zu diesen lebendigen Beispielen können wir auch spüren, dass ein tieferer Grund, warum kausales maschinelles Lernen das Interesse von Datenwissenschaftlern geweckt hat, die Generalisierungsfähigkeit des Modells ist. Modelle des maschinellen Lernens, die kausale Zusammenhänge zwischen Daten beschreiben, können auf neue Umgebungen verallgemeinert werden. Dies bleibt jedoch auch heute noch eine der größten Herausforderungen beim maschinellen Lernen.
Perl analysiert diese Probleme auf einer tieferen Ebene und glaubt, dass wir niemals echte künstliche Intelligenz auf menschlicher Ebene erreichen werden, wenn Maschinen nicht kausal argumentieren können, da Kausalität ein Schlüsselmechanismus ist durch die wir Menschen die komplexe Welt um uns herum verarbeiten und verstehen. Pearl schreibt im Vorwort der chinesischen Version von „On Causality“, dass „dieses Framework im Laufe des nächsten Jahrzehnts mit bestehenden maschinellen Lernsystemen kombiniert wird, was möglicherweise eine ‚zweite kausale Revolution‘ auslösen wird.“ Leser, sich aktiv an dieser kommenden Revolution zu beteiligen.“
Das obige ist der detaillierte Inhalt vonKann maschinelles Lernen wirklich zu intelligenten Entscheidungen führen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr