
Heim >Technologie-Peripheriegeräte >KI >Die Shanghai University of Science and Technology und andere haben DreamFace veröffentlicht: Nur Text kann einen „hyperrealistischen 3D-Digitalmenschen' erzeugen.
Die Shanghai University of Science and Technology und andere haben DreamFace veröffentlicht: Nur Text kann einen „hyperrealistischen 3D-Digitalmenschen' erzeugen.

- 王林nach vorne
- 2023-05-17 08:02:081768Durchsuche
Mit der Entwicklung von Large Language Model (LLM), Diffusion (Diffusion) und anderen Technologien hat die Geburt von Produkten wie ChatGPT und Midjourney eine neue Welle der KI-Begeisterung ausgelöst, und auch die generative KI hat begonnen erregte auch viel Aufmerksamkeit.
Im Gegensatz zu Text und Bildern befindet sich die 3D-Generierung noch im Stadium der technologischen Erforschung.
Ende 2022 starteten Google, NVIDIA und Microsoft nacheinander ihre eigene 3D-Generierungsarbeit, die meisten davon basierten jedoch implizit auf dem Advanced Neural Radiation Field (NeRF). Ausdruck und Die Rendering-Pipelines industrieller 3D-Software wie Unity, Unreal Engine und Maya sind nicht kompatibel.
Selbst wenn es mit herkömmlichen Lösungen in durch Mesh ausgedrückte geometrische und Farbkarten umgewandelt wird, führt dies zu unzureichender Genauigkeit und verringerter visueller Qualität und kann nicht direkt auf Film angewendet werden und Fernsehproduktion und Spieleproduktion.

Projektwebsite: https://sites.google .com/view/dreamface
Papieradresse: https://arxiv.org/abs/2304.03117#🎜 🎜#
Web-Demo: https://hyperhuman.top
#🎜 🎜#HuggingFace Space: https://huggingface.co/spaces/DEEMOSTECH/ChatAvatar
Um diese Probleme zu lösen, haben Shadow Eye Technology und Shanghai Technology Das Forschungs- und Entwicklungsteam der Universität schlägt ein textgesteuertes, progressives 3D-Generierungsframework vor.Dieses Framework führt externe Datensätze (einschließlich Geometrie und PBR-Materialien) ein, die den CG-Produktionsstandards entsprechen, und kann basierend auf Text direkt 3D-Assets generieren, die diesem Standard entsprechen Es ist das erste A-Framework, das die Generierung produktionsbereiter 3D-Assets unterstützt.
Um textgenerierte hyperrealistische digitale 3D-Menschen zu erreichen, kombinierte das Team dieses Framework mit einem digitalen 3D-Menschendatensatz in Produktionsqualität. Diese Arbeit wurde von Transactions on Graphics, der führenden internationalen Fachzeitschrift im Bereich Computergrafik, angenommen und wird auf der SIGGRAPH 2023, der führenden internationalen Computergrafikkonferenz, vorgestellt.
DreamFace umfasst hauptsächlich drei Module: Geometriegenerierung, physikbasierte Materialdiffusion und Animationsfähigkeitsgenerierung.
Im Vergleich zu früheren Arbeiten zur 3D-Generierung umfassen die Hauptbeiträge dieser Arbeit:
#🎜 🎜 #·
schlägt DreamFace vor, eine neuartige Generierungslösung, die aktuelle visuelle Sprachmodelle mit animierbaren und physisch materialisierbaren Gesichtselementen kombiniert und dabei progressives Lernen nutzt, um Geometrie, Aussehen und Animationsfunktionen zu trennen.
·führt ein zweikanaliges Erscheinungsbildgenerierungsdesign ein, das ein neuartiges Materialdiffusionsmodell mit einem vorab trainierten Modell kombiniert, während zwei- Die Bühnenoptimierung wird im Latentraum und im Bildraum durchgeführt.
·Gesichtsassets mit BlendShapes oder generierten personalisierten BlendShapes werden animiert und demonstrieren die Kompetenz von DreamFace in der Anwendung natürlicher Charakterdesigns. Geometriegenerierung
Das Geometriegenerierungsmodul kann ein konsistentes geometrisches Modell basierend auf Textaufforderungen generieren. Wenn es jedoch um die Gesichtergenerierung geht, kann es schwierig sein, diese zu überwachen und zu konvergieren.
Daher schlägt DreamFace ein auf CLIP (Contrastive Language-Image Pre-Training) basierendes Auswahlframework vor, bei dem zunächst zufällig Kandidaten aus dem geometrischen Parameterraum des Gesichts ausgewählt werden, um die besten auszuwählen Wählen Sie aus den Optionen ein grobes Geometriemodell aus und formen Sie dann die geometrischen Details, um das Kopfmodell besser mit der Textaufforderung in Einklang zu bringen.
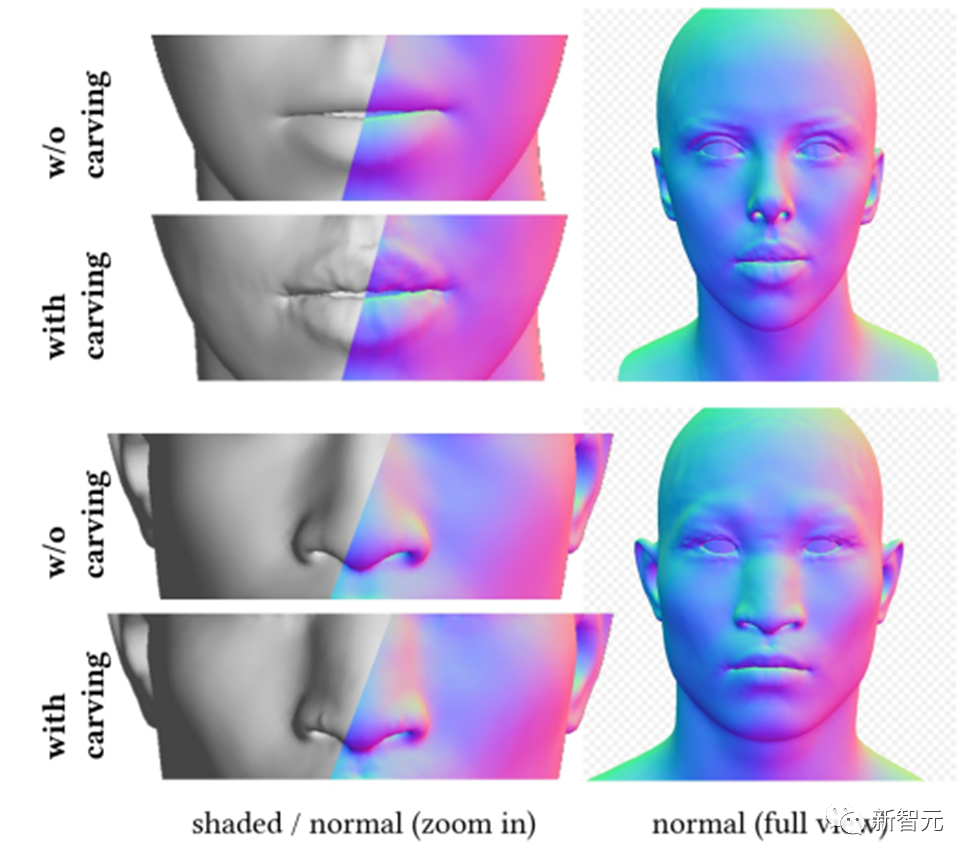
Dadurch kann DreamFace durch Scheitelpunktverschiebung und detaillierte Normalkarten Gesichtsdetails zu groben Geometriemodellen hinzufügen, was zu einer hochdetaillierten Geometrie führt.
Ähnlich wie beim Kopfmodell trifft auch DreamFace auf diesem Rahmen basierende Frisuren- und Farbauswahlen.
Physikalisch basierte Materialdiffusionsgenerierung
Das physikalisch basierte Materialdiffusionsmodul ist darauf ausgelegt, Gesichtstexturen vorherzusagen, die mit vorhergesagten Geometrie- und Texthinweisen übereinstimmen.
Zuerst hat DreamFace das vorab trainierte LDM anhand des groß angelegten UV-Materialdatensatzes verfeinert, um zwei LDM-Diffusionsmodelle zu erhalten.

DreamFace verwendet ein gemeinsames Trainingsschema, das zwei Diffusionsprozesse koordiniert, einen zum direkten Entrauschen von UV-Texturkarten und einen zur Überwachung des gerenderten Bildes, um sicherzustellen, dass die Gesichts-UV-Karte und das gerenderte Bild die richtige Formation haben von stimmt mit der Textaufforderung überein.
Um die Generierungszeit zu verkürzen, verwendet DreamFace eine Phase der potenziellen Diffusion grober Texturen, um a priori Potenzial für die Generierung detaillierter Texturen bereitzustellen.
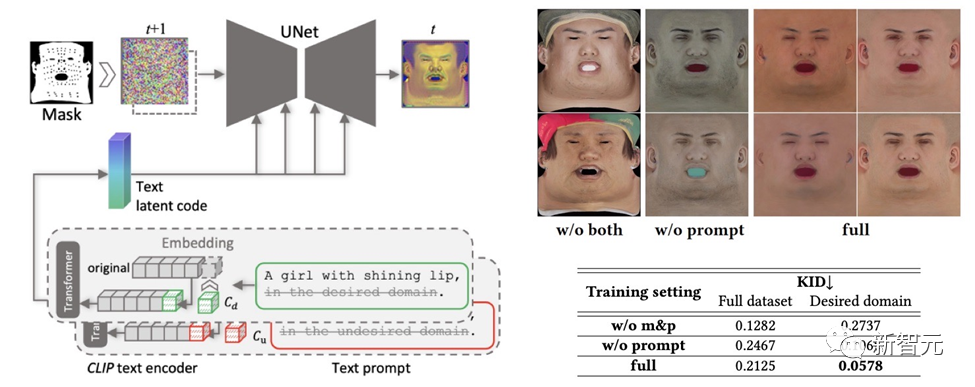
Um sicherzustellen, dass die erstellten Texturkarten keine unerwünschten Merkmale oder Beleuchtungssituationen enthalten und dennoch die Vielfalt gewahrt bleibt, wurde eine Hinweis-Lernstrategie entwickelt.
Das Team verwendet zwei Methoden, um hochwertige diffuse Karten zu generieren:
(1) Prompt Tuning. Im Gegensatz zu handgefertigten domänenspezifischen Texthinweisen kombiniert DreamFace die beiden domänenspezifischen kontinuierlichen Texthinweise Cd und Cu mit entsprechenden Texthinweisen, die während des U-Net-Denoiser-Trainings optimiert werden, um Instabilität und zeitaufwändiges manuelles Schreiben von Eingabeaufforderungen zu vermeiden.
(2) Maskierung von Nicht-Gesichtsbereichen. Der LDM-Rauschunterdrückungsprozess wird zusätzlich durch Nicht-Gesichtsbereichsmasken eingeschränkt, um sicherzustellen, dass die resultierende diffuse Karte keine unerwünschten Elemente enthält.
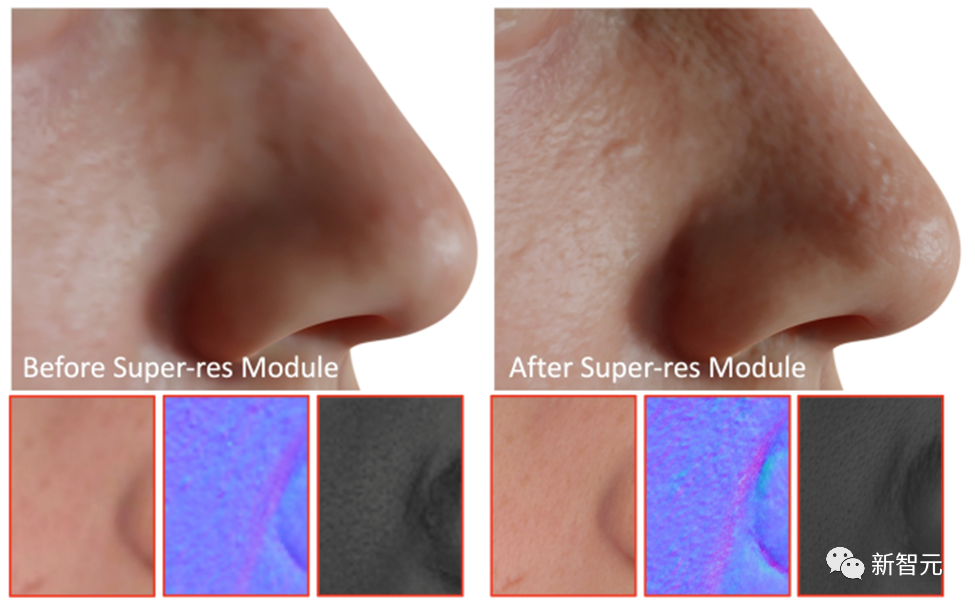
Als letzten Schritt wendet DreamFace das Super-Resolution-Modul an, um physikalisch basierte 4K-Texturen für ein hochwertiges Rendering zu generieren.

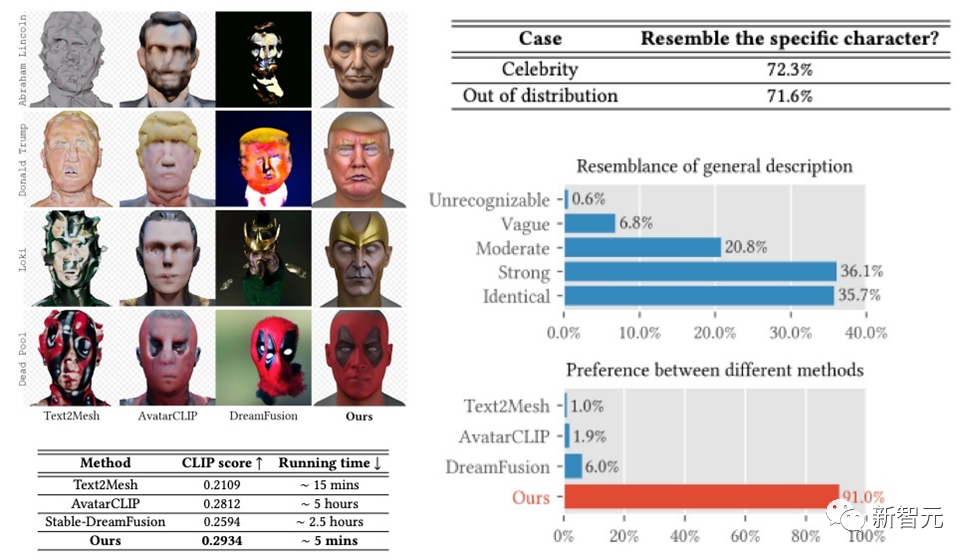
Das DreamFace-Framework hat sehr gute Ergebnisse bei der Generierung von Prominenten und Charakteren auf der Grundlage von Beschreibungen erzielt und Ergebnisse erzielt, die frühere Arbeiten bei Benutzerstudien weit übertreffen. Im Vergleich zu früheren Arbeiten weist es auch offensichtliche Vorteile bei der Laufzeit auf.
Darüber hinaus unterstützt DreamFace auch die Texturbearbeitung mithilfe von Tipps und Skizzen. Globale Bearbeitungseffekte wie Alterung und Make-up können durch die direkte Verwendung fein abgestimmter Textur-LDMs und Cues erzielt werden. Durch die weitere Kombination von Masken oder Skizzen können verschiedene Effekte wie Tätowierungen, Bärte und Muttermale erzeugt werden.

Animationsfunktionsgenerierung
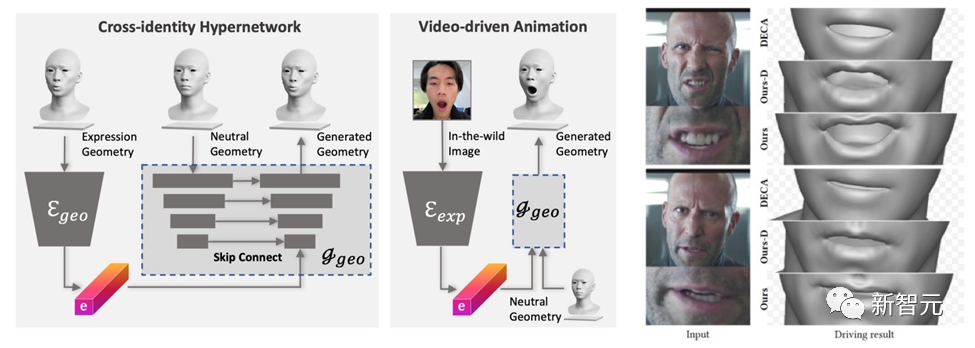
Das von DreamFace generierte Modell verfügt über Animationsfunktionen. Im Gegensatz zu BlendShapes-basierten Methoden erzeugt die neuronale Gesichtsanimationsmethode von DreamFace personalisierte Animationen, indem sie einzigartige Verformungen vorhersagt, um das resultierende neutrale Modell zu animieren.
Zuerst wird ein Geometriegenerator trainiert, um den latenten Raum von Ausdrücken zu lernen, wobei der Decoder erweitert wird, um auf neutrale Geometrien konditioniert zu werden. Anschließend wird der Ausdrucksencoder weiter trainiert, um Ausdrucksmerkmale aus RGB-Bildern zu extrahieren. Daher ist DreamFace in der Lage, mithilfe monokularer RGB-Bilder personalisierte Animationen zu generieren, die auf neutralen geometrischen Formen basieren.
Im Vergleich zu DECA, das generische BlendShapes zur Ausdruckssteuerung verwendet, bietet das Framework von DreamFace feine Ausdrucksdetails und ist in der Lage, Darbietungen mit feinen Details zu erfassen.
Fazit
In diesem Artikel wird DreamFace vorgestellt, ein textgesteuertes progressives 3D-Generierungsframework, das die neuesten visuellen Sprachmodelle, implizite Diffusionsmodelle und physikalisch basierte Materialdiffusionstechnologie kombiniert.
Zu den wichtigsten Innovationen von DreamFace gehören die Geometriegenerierung, die physikalisch basierte Materialdiffusionsgenerierung und die Generierung von Animationsmöglichkeiten. Im Vergleich zu herkömmlichen 3D-Generierungsmethoden bietet DreamFace eine höhere Genauigkeit, eine schnellere Laufgeschwindigkeit und eine bessere CG-Pipeline-Kompatibilität.
Das progressive Generierungsframework von DreamFace bietet eine effektive Lösung für die Lösung komplexer 3D-Generierungsaufgaben und dürfte weitere ähnliche Forschungs- und Technologieentwicklungen fördern.
Darüber hinaus wird die physikalisch basierte Materialdiffusionsgenerierung und die Generierung von Animationsfähigkeiten die Anwendung der 3D-Generierungstechnologie in der Film- und Fernsehproduktion, der Spieleentwicklung und anderen verwandten Branchen fördern.
Das obige ist der detaillierte Inhalt vonDie Shanghai University of Science and Technology und andere haben DreamFace veröffentlicht: Nur Text kann einen „hyperrealistischen 3D-Digitalmenschen' erzeugen.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr