
Heim >Technologie-Peripheriegeräte >KI >Das OpenAI-3D-Modell zur Textgenerierung wurde aktualisiert, um die Modellierung in Sekunden abzuschließen, was benutzerfreundlicher als Point·E ist
Das OpenAI-3D-Modell zur Textgenerierung wurde aktualisiert, um die Modellierung in Sekunden abzuschließen, was benutzerfreundlicher als Point·E ist

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-16 10:04:131653Durchsuche
Generative KI-Großmodelle stehen im Mittelpunkt der Bemühungen von OpenAI. Das Unternehmen hat bereits Anfang des Jahres die textgenerierten Bildmodelle DALL-E und DALL-E 2 sowie POINT-E auf den Markt gebracht, das 3D-Modelle basierend auf Text generiert.
Kürzlich hat das OpenAI-Forschungsteam das generative 3D-Modell aktualisiert und Shap・E neu eingeführt, ein bedingtes generatives Modell zur Synthese von 3D-Assets. Derzeit sind die relevanten Modellgewichte, der Inferenzcode und die Beispiele Open Source.

- Papieradresse: https://arxiv.org/abs/2305.02463
- Projektadresse: https://github. com /openai/shap -e
Werfen wir zunächst einen Blick auf den Generierungseffekt. Ähnlich wie beim Generieren von Bildern basierend auf Text konzentriert sich das von Shap・E generierte 3D-Objektmodell auf „uneingeschränkt“. Zum Beispiel ein Flugzeug, das wie eine Banane aussieht:

Ein Stuhl, der wie ein Baum aussieht:

Und das klassische Beispiel, ein Stuhl, der wie eine Avocado aussieht:

Natürlich können Sie auch dreidimensionale Modelle einiger gängiger Objekte erstellen, beispielsweise einer Schüssel Gemüse:

Donuts:

The Shap・E vorgeschlagen in Bei diesem Artikel handelt es sich um eine implizite Funktion im räumlichen Latentdiffusionsmodell in 3D, die in NeRF und texturierte Netze gerendert werden kann. Bei dem gleichen Datensatz, der gleichen Modellarchitektur und den gleichen Trainingsberechnungen übertrifft Shap・E ähnliche explizite generative Modelle. Die Forscher fanden heraus, dass das rein textbedingte Modell vielfältige und interessante Objekte generieren kann, was auch das Potenzial der Generierung impliziter Darstellungen zeigt.

Im Gegensatz zur Arbeit an generativen 3D-Modellen, die eine einzelne Ausgabedarstellung erzeugen, ist Shap-E in der Lage, die Parameter impliziter Funktionen direkt zu generieren. Das Training von Shap-E ist in zwei Phasen unterteilt: erstens Training des Encoders, der die 3D-Assets deterministisch auf die Parameter der impliziten Funktion abbildet, zweitens Training des bedingten Diffusionsmodells auf der Ausgabe des Encoders. Wenn das Modell auf einem großen Datensatz gepaarter 3D- und Textdaten trainiert wird, ist es in der Lage, in Sekundenschnelle komplexe und vielfältige 3D-Assets zu generieren. Im Vergleich zum expliziten Punktwolkengenerierungsmodell Point・E modelliert Shap-E einen hochdimensionalen Ausgaberaum mit mehreren Darstellungen, konvergiert schneller und erreicht eine gleichwertige oder bessere Probenqualität.
Forschungshintergrund
Dieser Artikel konzentriert sich auf zwei implizite neuronale Darstellungen (INR) für die 3D-Darstellung:
- NeRF ein INR, das eine 3D-Szene als Funktion darstellt, die Koordinaten und Ansichtsrichtungen der Dichte und der RGB-Farbe zuordnet;
- DMTet und seine Erweiterung GET3D stellen ein texturiertes 3D-Netz dar, das Koordinaten als Funktion der Farbe mit Vorzeichen zuordnet und Scheitelpunktversatz. Mit diesem INR können 3D-Dreiecksnetze auf differenzierbare Weise konstruiert und dann in eine differenzierbare Rasterisierungsbibliothek gerendert werden.
Obwohl INR flexibel und aussagekräftig ist, ist es teuer, INR für jede Probe im Datensatz zu ermitteln. Darüber hinaus kann jede INR viele numerische Parameter haben, was beim Training nachgelagerter generativer Modelle zu Schwierigkeiten führen kann. Durch die Lösung dieser Probleme mithilfe von Autoencodern mit impliziten Decodern können kleinere latente Darstellungen erhalten werden, die direkt mit vorhandenen generativen Techniken modelliert werden. Ein alternativer Ansatz besteht darin, mithilfe von Meta-Learning einen INR-Datensatz zu erstellen, der die meisten seiner Parameter gemeinsam hat, und dann ein Diffusionsmodell oder einen normalisierten Fluss auf den freien Parametern dieser INRs zu trainieren. Es wurde auch vorgeschlagen, dass Gradienten-basiertes Meta-Lernen möglicherweise nicht erforderlich ist und stattdessen der Transformer-Encoder direkt trainiert werden sollte, um NeRF-Parameter zu erzeugen, die von mehreren Ansichten eines 3D-Objekts abhängig sind.
Die Forscher kombinierten und erweiterten die oben genannten Methoden und erhielten schließlich Shap・E, das zu einem bedingten Generierungsmodell für verschiedene komplexe implizite 3D-Darstellungen wurde. Generieren Sie zunächst INR-Parameter für das 3D-Asset, indem Sie einen Transformer-basierten Encoder trainieren, und trainieren Sie dann ein Diffusionsmodell auf der Ausgabe des Encoders. Im Gegensatz zu früheren Ansätzen werden INRs generiert, die sowohl NeRF als auch Netze darstellen, sodass sie auf verschiedene Arten gerendert oder in nachgelagerte 3D-Anwendungen importiert werden können.
Wenn unser Modell anhand eines Datensatzes aus Millionen von 3D-Assets trainiert wird, ist es in der Lage, unter der Bedingung von Textaufforderungen eine Vielzahl identifizierbarer Proben zu erzeugen. Shap-E konvergiert schneller als Point·E, ein kürzlich vorgeschlagenes explizites generatives 3D-Modell. Mit derselben Modellarchitektur, demselben Datensatz und demselben Konditionierungsmechanismus können vergleichbare oder bessere Ergebnisse erzielt werden.
Übersicht über die Methode
Der Forscher trainiert zunächst den Encoder, um eine implizite Darstellung zu generieren, und trainiert dann das Diffusionsmodell auf der vom Encoder generierten latenten Darstellung. Dies wird hauptsächlich in den folgenden zwei Schritten abgeschlossen:
1 Trainieren Sie einen Encoder, um die Parameter einer impliziten Funktion anhand einer dichten expliziten Darstellung eines bekannten 3D-Assets zu ermitteln. Der Encoder erzeugt eine latente Darstellung des 3D-Assets, die dann linear projiziert wird, um die Gewichte des Multilayer-Perzeptrons (MLP) zu erhalten.
2 Wenden Sie den Encoder auf den Datensatz an und trainieren Sie dann eine Diffusion vor dem latenten Datensatz. Das Modell basiert auf Bildern oder Textbeschreibungen.
Die Forscher trainierten alle Modelle anhand eines großen Datensatzes von 3D-Assets unter Verwendung entsprechender Renderings, Punktwolken und Textbeschriftungen.
3D-Encoder
Die Encoder-Architektur ist in Abbildung 2 unten dargestellt.
Latente Diffusion
Das Generationsmodell übernimmt die transformatorbasierte Point・E-Diffusionsarchitektur, verwendet jedoch eine latente Vektorsequenz, um die Punktwolke zu ersetzen. Die Folge latenter Funktionsformen beträgt 1024×1024 und wird als Folge von 1024 Tokens in den Transformator eingegeben, wobei jedes Token einer anderen Zeile der MLP-Gewichtsmatrix entspricht. Daher ist dieses Modell rechnerisch in etwa äquivalent zum Basis-Point·E-Modell (d. h. hat die gleiche Kontextlänge und -breite). Auf dieser Basis werden Ein- und Ausgabekanäle hinzugefügt, um Samples in einem höherdimensionalen Raum zu generieren.
Experimentelle Ergebnisse
Encoder-Bewertung
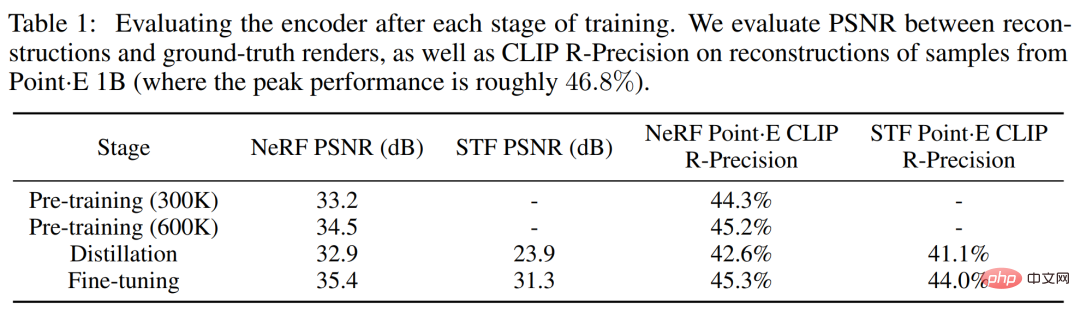
Die Forscher verfolgten während des Encoder-Trainingsprozesses zwei renderbasierte Metriken. Bewerten Sie zunächst das maximale Signal-Rausch-Verhältnis (PSNR) zwischen dem rekonstruierten Bild und dem real gerenderten Bild. Um außerdem die Fähigkeit des Encoders zu messen, semantisch relevante Details eines 3D-Assets zu erfassen, wurde die CLIP R-Präzision für rekonstruierte NeRF- und STF-Renderings neu bewertet, indem das vom größten Point·E-Modell erzeugte Netz codiert wurde.
Tabelle 1 unten zeigt die Ergebnisse dieser beiden Metriken in verschiedenen Trainingsphasen. Es zeigt sich, dass die Destillation die NeRF-Rekonstruktionsqualität beeinträchtigt, während die Feinabstimmung die NeRF-Qualität nicht nur wiederherstellt, sondern auch leicht verbessert und gleichzeitig die STF-Renderingqualität erheblich verbessert.
Vergleich mit Point・E
Das vom Forscher vorgeschlagene latente Diffusionsmodell hat die gleiche Architektur, den gleichen Trainingsdatensatz und das gleiche bedingte Muster wie Point・E. Der Vergleich mit Punkt·E ist nützlicher, um die Auswirkungen der Generierung impliziter neuronaler Darstellungen im Vergleich zu expliziten Darstellungen zu unterscheiden. Abbildung 4 unten vergleicht diese Methoden anhand stichprobenbasierter Bewertungsmetriken.
Qualitative Beispiele sind in Abbildung 5 unten dargestellt. Sie können sehen, dass diese Modelle häufig Beispiele unterschiedlicher Qualität für dieselbe Textaufforderung generieren. Vor dem Ende des Trainings beginnt sich der Textzustand Shap·E in der Auswertung zu verschlechtern. 
Die Forscher fanden heraus, dass Shap·E und Point·E tendenziell ähnliche Fehlerfälle aufweisen, wie in Abbildung 6 (a) unten dargestellt. Dies deutet darauf hin, dass Trainingsdaten, Modellarchitektur und konditionierte Bilder einen größeren Einfluss auf generierte Proben haben als der gewählte Darstellungsraum.
Wir können beobachten, dass es immer noch einige qualitative Unterschiede zwischen den beiden Bildzustandsmodellen gibt, zum Beispiel in der ersten Zeile von Abbildung 6(b) unten, Point・E ignoriert die kleine Lücke auf der Bank, während Shap・E Versuchen Sie, sie zu modellieren. In diesem Artikel wird die Hypothese aufgestellt, dass diese besondere Diskrepanz auftritt, weil Punktwolken dünne Merkmale oder Lücken nicht gut darstellen. In Tabelle 1 ist außerdem zu beobachten, dass der 3D-Encoder die CLIP-R-Präzision leicht verringert, wenn er auf Punkt·E-Proben angewendet wird.

Vergleich mit anderen Methoden
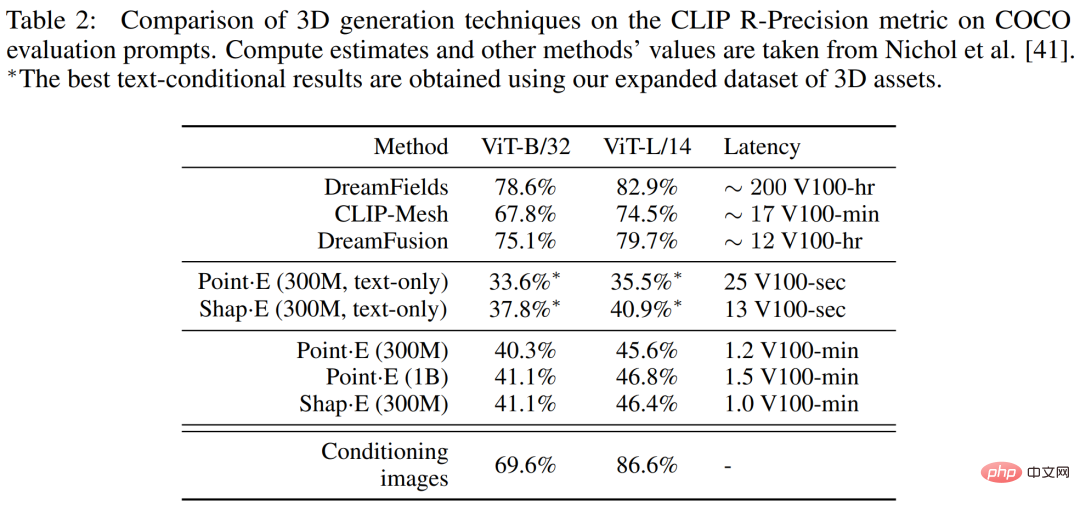
In Tabelle 2 unten verglichen die Forscher Shape・E mit einer breiteren Palette von 3D-Generierungstechniken auf der CLIP R-Precision-Metrik.
Einschränkungen und Ausblick
Während Shap-E viele einzelne Objektaufforderungen mit einfachen Eigenschaften verstehen kann, ist seine Fähigkeit, Konzepte zu kombinieren, begrenzt. Wie Sie in Abbildung 7 unten sehen können, erschwert dieses Modell die Bindung mehrerer Eigenschaften an verschiedene Objekte und generiert nicht effizient die richtige Anzahl von Objekten, wenn mehr als zwei Objekte angefordert werden. Dies kann auf unzureichende gepaarte Trainingsdaten zurückzuführen sein und kann durch das Sammeln oder Generieren eines größeren kommentierten 3D-Datensatzes behoben werden. 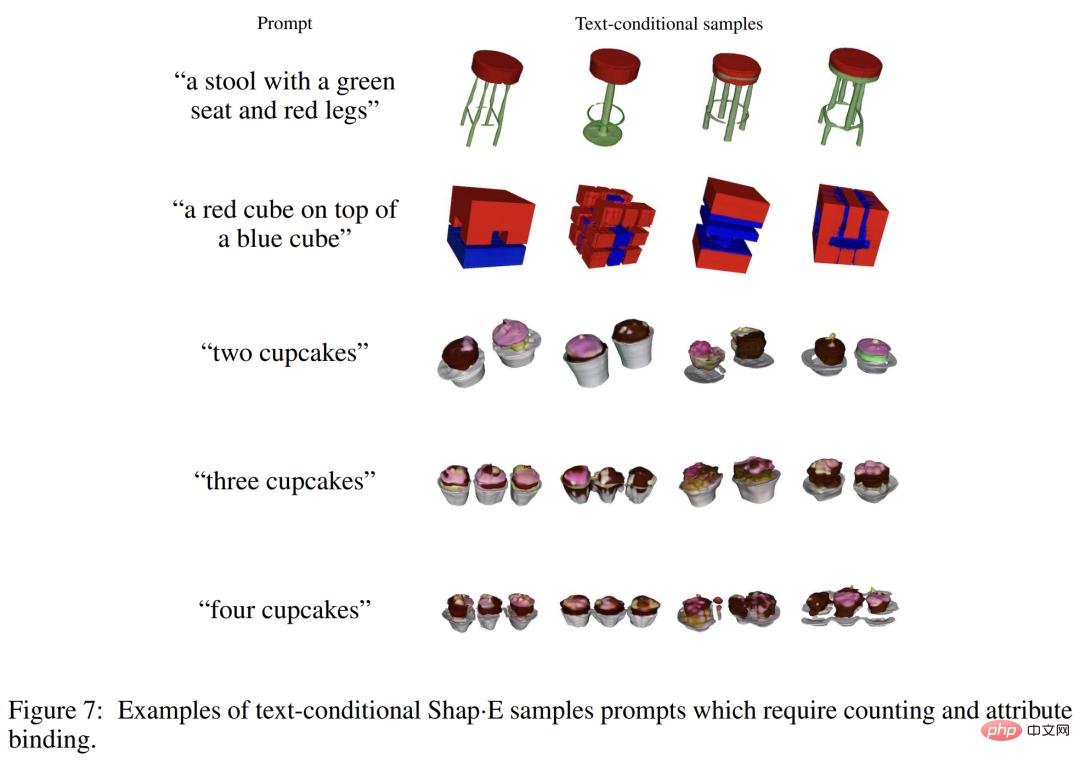
Darüber hinaus erzeugt Shap・E erkennbare 3D-Assets, die jedoch oft grob aussehen oder es an Details mangelt. Abbildung 3 unten zeigt, dass der Encoder manchmal detaillierte Texturen verliert (z. B. die Streifen auf einem Kaktus), was darauf hindeutet, dass ein verbesserter Encoder einen Teil der verlorenen Generierungsqualität wiederherstellen kann.

Weitere technische und experimentelle Details finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonDas OpenAI-3D-Modell zur Textgenerierung wurde aktualisiert, um die Modellierung in Sekunden abzuschließen, was benutzerfreundlicher als Point·E ist. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr