
Heim >Technologie-Peripheriegeräte >KI >Lösen Sie die ChatGPT-Amnesie vollständig! Durchbrechen der Transformer-Eingabegrenze: Gemessen zur Unterstützung von 2 Millionen gültigen Token
Lösen Sie die ChatGPT-Amnesie vollständig! Durchbrechen der Transformer-Eingabegrenze: Gemessen zur Unterstützung von 2 Millionen gültigen Token

- 王林nach vorne
- 2023-05-13 14:07:062140Durchsuche
ChatGPT oder das Transformer-Klassenmodell weist einen schwerwiegenden Fehler auf, der zu leicht vergessen wird. Sobald das Token der Eingabesequenz den Schwellenwert des Kontextfensters überschreitet, stimmt der nachfolgende Ausgabeinhalt nicht mit der vorherigen Logik überein .
ChatGPT kann nur die Eingabe von 4000 Token (ca. 3000 Wörter) unterstützen. Selbst das neu veröffentlichte GPT-4 unterstützt nur ein maximales Token-Fenster von 32000. Wenn Sie die Länge der Eingabesequenz weiter erhöhen, wird die Die Berechnung wird auch komplizierter.
Kürzlich haben Forscher von DeepPavlov, AIRI und dem London Mathematical Sciences Institute einen technischen Bericht veröffentlicht, in dem sie den Recurrent Memory Transformer (RMT) verwenden, um die effektive Kontextlänge von BERT auf „beispiellose 2 Millionen Token“ zu erhöhen. , unter Beibehaltung einer hohen Speicherabrufgenauigkeit.
Papierlink: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
Diese Methode kann lokale und globale Informationen speichern und verarbeiten und Schleifen verwenden, um die Informationen zu behalten im Fluss zwischen Segmenten der Eingabesequenz.
Der experimentelle Abschnitt demonstriert die Wirksamkeit dieses Ansatzes, der ein außerordentliches Potenzial zur Verbesserung der langfristigen Abhängigkeitsverarbeitung bei Aufgaben zum Verstehen und Generieren natürlicher Sprache hat und eine groß angelegte Kontextverarbeitung für speicherintensive Anwendungen ermöglicht.
Obwohl RMT den Speicherverbrauch nicht erhöhen kann und auf nahezu unbegrenzte Sequenzlängen erweitert werden kann, besteht immer noch das Problem des Speicherverfalls in RNN und einer längeren Inferenzzeit ist erforderlich.

Aber einige Internetnutzer haben eine Lösung vorgeschlagen: RMT wird für das Langzeitgedächtnis verwendet, großer Kontext wird für das Kurzzeitgedächtnis verwendet und dann modelliert Das Training wird nachts/während der Wartung durchgeführt.
Cyclic Memory Transformer
Im Jahr 2022 schlug das Team das Cyclic Memory Transformer (RMT)-Modell vor, indem der Eingabe- oder Ausgabesequenz ein spezielles Speichertoken hinzugefügt und dann geändert wurde Das Modelltraining zur Steuerung von Speicheroperationen und zur Verarbeitung von Sequenzdarstellungen kann einen neuen Speichermechanismus implementieren, ohne das ursprüngliche Transformer-Modell zu ändern.

Papierlink: https://arxiv.org/abs/2207.06881
Publikationskonferenz: NeurIPS 2022#🎜🎜 #
Im Vergleich zu Transformer-XL benötigt RMT weniger Speicher und kann längere Aufgabensequenzen bewältigen.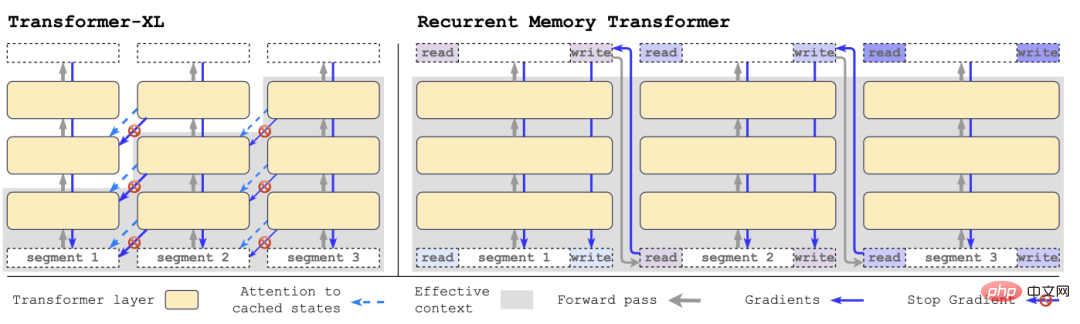
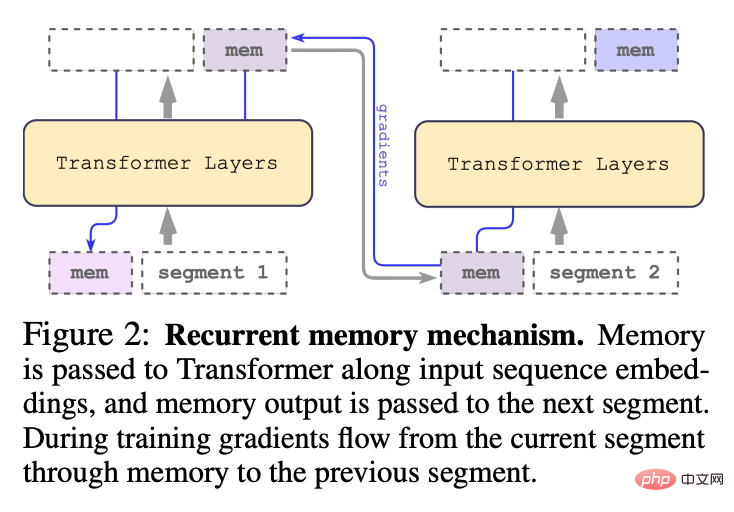
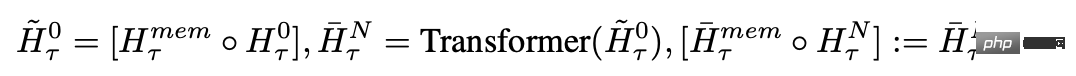 Nachdem der Forscher die Segmente der Eingabesequenz der Reihe nach verarbeitet hat, um eine rekursive Verbindung zu erreichen, übergibt der Forscher die Ausgabe des Speichertokens des aktuellen Segments an die Eingabe des nächsten Segments: #🎜 🎜#
Nachdem der Forscher die Segmente der Eingabesequenz der Reihe nach verarbeitet hat, um eine rekursive Verbindung zu erreichen, übergibt der Forscher die Ausgabe des Speichertokens des aktuellen Segments an die Eingabe des nächsten Segments: #🎜 🎜#
Der Speicher und die Schleife in RMT basieren nur auf globalen Speichertokens, die das Backbone-Transformer-Modell unverändert lassen können, wodurch die Speichererweiterungsfunktion von RMT mit jedem Transformer kompatibel ist Modell. 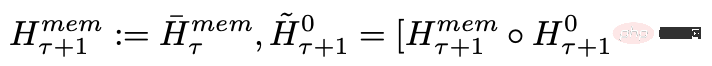
Die lineare Expansion wird erreicht, indem eine Eingabesequenz in mehrere Segmente unterteilt wird und alle Aufmerksamkeitsmatrizen nur innerhalb der Grenzen der Segmente berechnet werden. Die Ergebnisse sind sichtbar Wenn also die Segmentlänge fest ist, steigt die Inferenzgeschwindigkeit von RMT für jede Modellgröße linear an. 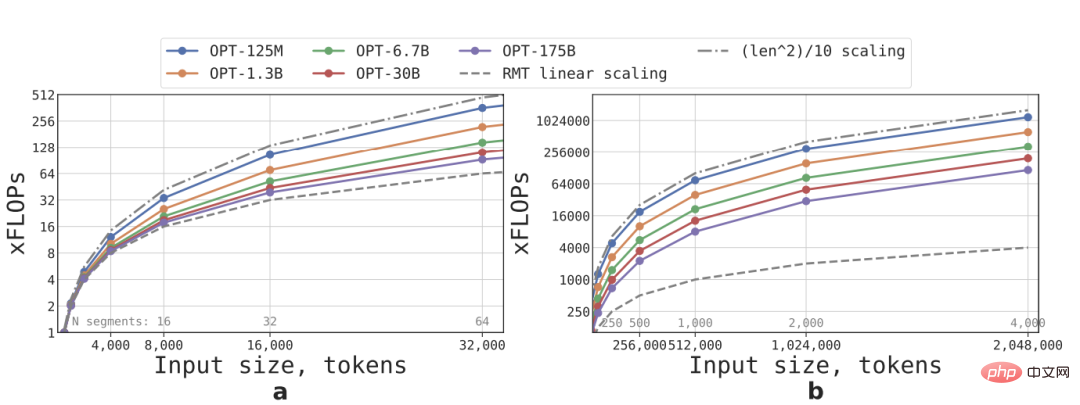
Aufgrund des großen Rechenaufwands der FFN-Schicht zeigen größere Transformer-Modelle tendenziell eine langsamere quadratische Wachstumsrate im Verhältnis zur Sequenzlänge. Bei extrem langen Sequenzen mit einer Länge von mehr als 32.000 kehren FLOPs jedoch zum quadratischen Wachstum zurück .
Für Sequenzen mit mehr als einem Segment (größer als 512 in dieser Studie) hat RMT niedrigere FLOPs als das azyklische Modell und kann die Effizienz von FLOPs bei kleineren Modellen um das bis zu 295-fache steigern Modelle Große Modelle wie OPT-175B können um das 29-fache verbessert werden.
Gedächtnisaufgabe
Um die Gedächtnisfähigkeiten zu testen, erstellten die Forscher einen synthetischen Datensatz, der vom Modell verlangte, sich einfache Fakten und grundlegende Überlegungen zu merken.
Aufgabeneingabe besteht aus einem oder mehreren Fakten und einer Frage, die nur mit all diesen Fakten beantwortet werden kann.
Um den Schwierigkeitsgrad der Aufgabe zu erhöhen, wird der Aufgabe auch Text in natürlicher Sprache hinzugefügt, der nicht mit der Frage oder Antwort zusammenhängt. Diese Texte können als Rauschen angesehen werden, sodass die Aufgabe des Modells tatsächlich darin besteht, die Fakten davon zu trennen den irrelevanten Text und verwenden Sie den Faktentext, um die Frage zu beantworten.

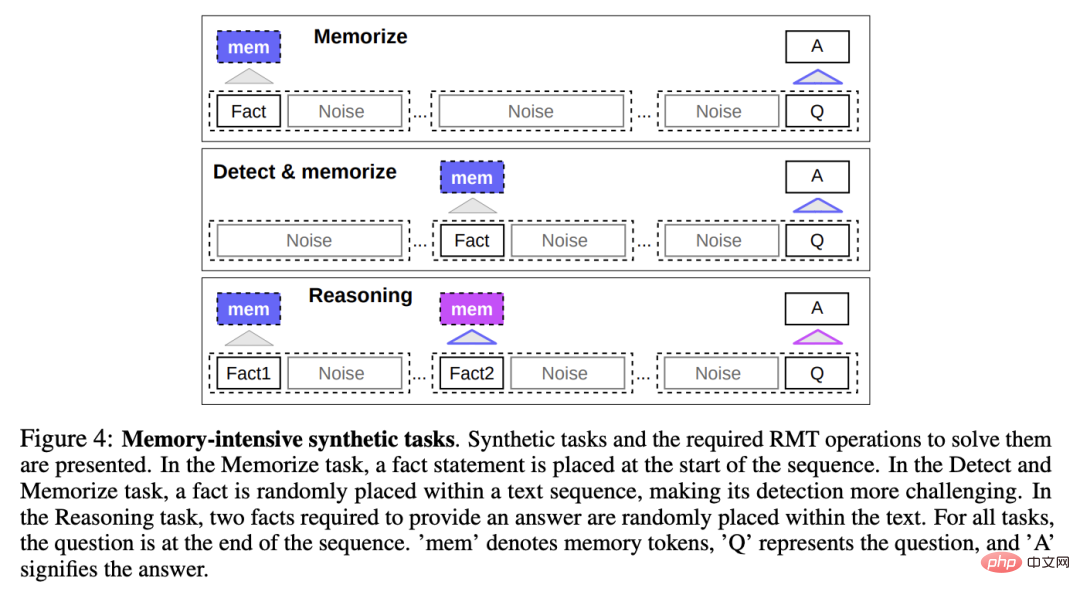
Faktengedächtnis
Testet RMTs Fähigkeit, Informationen über längere Zeiträume zu schreiben und im Gedächtnis zu speichern: Im einfachsten Fall stehen die Fakten am Anfang der Eingabe, die Fragen am Ende der Eingabe und schrittweise Erhöhen Sie die Menge an irrelevantem Text zwischen Fragen und Antworten, bis das Modell nicht mehr alle Eingaben auf einmal akzeptieren kann.

Faktenerkennung und Gedächtnis
Die Tatsachenerkennung erhöht die Schwierigkeit der Aufgabe, indem sie die Tatsache an eine zufällige Position in der Eingabe verschiebt, sodass das Modell die Tatsache zunächst von irrelevantem Text unterscheiden und in den Speicher schreiben muss. Beantworten Sie dann die Frage am Ende.
Argumentation auf der Grundlage von auswendig gelernten Fakten
Eine weitere wichtige Operation des Gedächtnisses besteht darin, auf der Grundlage von auswendig gelernten Fakten und dem aktuellen Kontext zu argumentieren.
Um diese Funktion zu bewerten, führten die Forscher eine komplexere Aufgabe ein, bei der zwei Fakten generiert und zufällig in der Eingabesequenz platziert werden. Eine am Ende der Sequenz gestellte Frage muss ausgewählt werden, um die Frage mit der richtigen Tatsache zu beantworten.

Experimentelle Ergebnisse
Die Forscher verwendeten in allen Experimenten das vorab trainierte Bert-Base-Case-Modell in HuggingFace Transformers als Rückgrat von RMT, und alle Modelle wurden mit einer Speichergröße von 10 erweitert.
Trainieren und evaluieren Sie auf 4–8 NVIDIA 1080Ti-GPUs für längere Sequenzen. Wechseln Sie zu einer einzelnen 40-GB-NVIDIA A100 für eine beschleunigte Evaluierung.
Curriculum Learning
Forscher beobachteten, dass der Einsatz von Trainingsplanung die Genauigkeit und Stabilität der Lösung deutlich verbessern kann.
Beginnen Sie das RMT-Training einfach mit einer kürzeren Version der Aufgabe. Erhöhen Sie nach der Konvergenz des Trainings die Aufgabenlänge, indem Sie ein Segment hinzufügen, und setzen Sie den Kurslernprozess fort, bis die ideale Eingabelänge erreicht ist.
Starten Sie das Experiment mit einer Sequenz, die zu einem einzelnen Segment passt. Die tatsächliche Segmentgröße beträgt 499, da 3 BERT-Spezialtoken und 10 Speicherplatzhalter aus der Modelleingabe beibehalten werden, was eine Gesamtgröße von 512 ergibt.
Es ist zu beobachten, dass RMT nach dem Training kürzerer Aufgaben längere Aufgaben leichter lösen kann, da es mit weniger Trainingsschritten zu einer perfekten Lösung konvergiert.
Extrapolationsfähigkeiten
Um die Generalisierungsfähigkeit von RMT auf unterschiedliche Sequenzlängen zu beobachten, bewerteten die Forscher Modelle, die auf einer unterschiedlichen Anzahl von Segmenten trainiert wurden, um Aufgaben größerer Länge zu lösen.
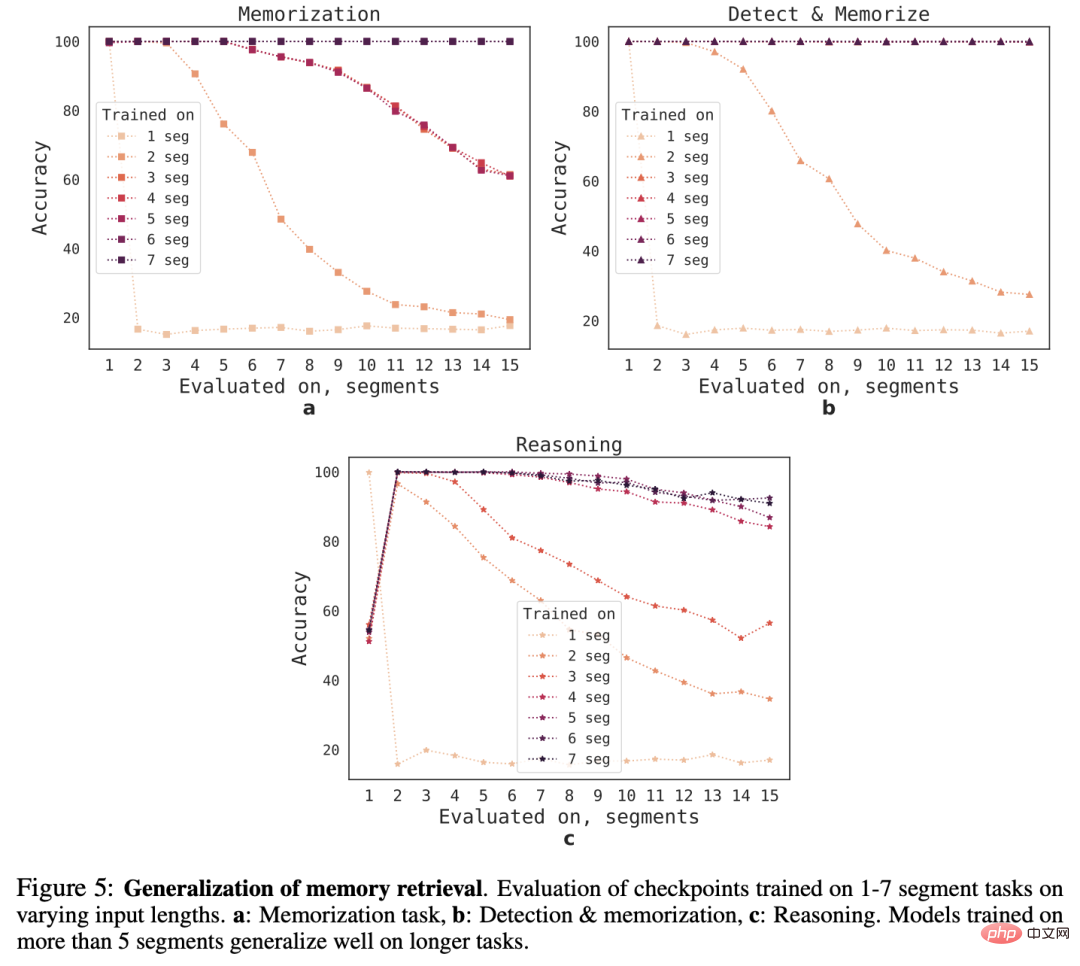
Es ist zu beobachten, dass das Modell bei kürzeren Aufgaben oft eine gute Leistung erbringt, aber nach dem Training des Modells bei längeren Sequenzen wird es schwierig, Einzelsegment-Inferenzaufgaben zu bewältigen.
Eine mögliche Erklärung ist, dass das Modell das Problem im ersten Segment nicht mehr antizipiert, weil die Aufgabengröße ein Segment überschreitet, was zu einer Verschlechterung der Qualität führt.
Interessanterweise zeigt sich mit zunehmender Anzahl der Trainingssegmente auch die Generalisierungsfähigkeit von RMT auf längere Sequenzen. Nach dem Training auf 5 oder mehr Segmenten kann RMT bei Aufgaben fast doppelt so lange arbeiten. Perfekte Generalisierung.
Um die Grenze der Generalisierung zu testen, erhöhten die Forscher die Größe der Verifizierungsaufgabe auf 4096 Segmente (d. h. 2.043.904 Token).
RMT hält sich bei so langen Sequenzen überraschend gut, wobei die Aufgabe „Erkennung und Gedächtnis“ die einfachste und die Inferenzaufgabe die komplexeste ist.
Referenz: https://www.php.cn/link/459ad054a6417248a1166b30f6393301
Das obige ist der detaillierte Inhalt vonLösen Sie die ChatGPT-Amnesie vollständig! Durchbrechen der Transformer-Eingabegrenze: Gemessen zur Unterstützung von 2 Millionen gültigen Token. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr