
Heim >Technologie-Peripheriegeräte >KI >Anwendung des domänenübergreifenden Empfehlungsrankingmodells für kontinuierliches Transferlernen im Taobao-Empfehlungssystem
Anwendung des domänenübergreifenden Empfehlungsrankingmodells für kontinuierliches Transferlernen im Taobao-Empfehlungssystem

- PHPznach vorne
- 2023-05-13 14:04:061556Durchsuche
In diesem Artikel wird untersucht, wie ein domänenübergreifendes Empfehlungsmodell im Rahmen des kontinuierlichen Lernens in der Branche implementiert werden kann, und ein neues domänenübergreifendes Empfehlungsparadigma des kontinuierlichen Transferlernens unter Verwendung der Ergebnisse der Zwischenschichtdarstellung der kontinuierlich vorab trainierten Quelle vorgeschlagen Domänenmodell als Zieldomäne Mit dem zusätzlichen Wissen des Modells wurde ein leichtes Adaptermodul entwickelt, um die Migration domänenübergreifenden Wissens zu realisieren, und erzielte signifikante Geschäftsergebnisse im Ranking der empfohlenen Produkte.
Hintergrund
In den letzten Jahren wurde durch die Anwendung tiefer Modelle die Empfehlungswirkung von Empfehlungssystemen in der Branche erheblich verbessert. Durch die kontinuierliche Optimierung von Modellen wurden die Modellstruktur und Funktionsänderungen ausschließlich durch Vertrauen optimiert auf Daten innerhalb der Szene ist schwieriger. Auf großen E-Commerce-Plattformen wie Taobao gibt es eine Reihe von Empfehlungsszenarien unterschiedlicher Größe, um den unterschiedlichen Bedürfnissen verschiedener Benutzer gerecht zu werden, z. B. Informationsflussempfehlungen (es könnte Ihnen auf der Homepage gefallen) und gute Produkte , Empfehlungen nach dem Kauf und Sammeln Diese Szenarien teilen sich das Taobao-Produktsystem, es gibt jedoch erhebliche Unterschiede in den spezifischen Produktauswahlpools, Kernbenutzern und Geschäftszielen, und der Umfang der verschiedenen Szenarien variiert stark. Unser Szenario „Gute Produkte“ ist ein Einkaufsführerszenario für ausgewählte Produkte von Taobao. Der Umfang ist daher relativ gering Methoden zur Verbesserung des Modelleffekts waren schon immer ein Problem bei der Optimierung des Gute-Waren-Sortiermodells. Obwohl sich Produkte und Benutzer in verschiedenen Geschäftsszenarien auf Taobao überschneiden, funktioniert das Ranking-Modell großer Szenarien wie Informationsflussempfehlungen aufgrund der erheblichen Unterschiede in den Szenarien nicht gut, wenn es direkt auf Szenarien angewendet wird, in denen gute Waren verfügbar sind. Daher hat das Team erhebliche Anstrengungen in Richtung einer domänenübergreifenden Empfehlung unternommen, einschließlich der Verwendung einer Reihe vorhandener Methoden wie Vortraining und Feinabstimmung, gemeinsames Training für mehrere Szenarien und globales Lernen. Diese Methoden sind entweder nicht effektiv genug oder weisen in tatsächlichen Online-Anwendungen viele Probleme auf. Das Projekt zum kontinuierlichen Transferlernen schlägt eine einfache und effektive neue domänenübergreifende Empfehlungsmethode für eine Reihe von Problemen bei der Anwendung dieser Methoden in Unternehmen vor. Diese Methode nutzt die Ergebnisse der Zwischenschichtdarstellung des kontinuierlich vorab trainierten Quelldomänenmodells als zusätzliches Wissen über das Zieldomänenmodell
und hat bedeutende Geschäftsergebnisse beim Ranking guter Produktempfehlungen auf Taobao erzielt.Die ausführliche Version dieses Artikels „Continual Transfer Learning for Cross-Domain Click-Through Rate Prediction at Taobao“ wurde auf ArXiv https://arxiv.org/abs/2208.05728 veröffentlicht.
Methode
▐ Bestehende Arbeiten und ihre Mängel
Analyse bestehender Cross-Domain-Empfehlung (CDR)-bezogener Arbeiten in Wissenschaft und Industrie, die in zwei Hauptkategorien unterteilt werden können: Gemeinsames Lernen und Vorschulung & Feinabstimmung. Unter anderem optimiert die gemeinsame Trainingsmethode gleichzeitig die Modelle der Quelldomäne (Source Domain) und der Zieldomäne (Target Domain). Diese Art von Methode erfordert jedoch die Einführung von Quelldomänendaten in das Training, und Quelldomänenstichproben sind normalerweise groß und verbrauchen daher enorme Rechen- und Speicherressourcen. Viele kleinere Unternehmen können sich einen so großen Ressourcenaufwand nicht leisten. Andererseits muss diese Art von Methode mehrere Szenenziele gleichzeitig optimieren, und Unterschiede zwischen Szenen können auch negative Auswirkungen von Zielkonflikten haben. Daher finden Methoden zur Feinabstimmung vor dem Training in vielen Szenen breitere Anwendung die Branche.
Ein wichtiges Merkmal des industriellen Empfehlungssystems besteht darin, dass das Modelltraining dem Paradigma des „kontinuierlichen Lernens“ folgt, d und andere Methoden zum Erlernen der neuesten Datenverteilung. Für die in diesem Artikel untersuchte domänenübergreifende Empfehlungsaufgabe folgen sowohl die Modelle in der Quelldomäne als auch in der Zieldomäne der kontinuierlichen Lerntrainingsmethode. Wir schlagen daher ein neues Problem vor, das in akademischen und industriellen Anwendungen weit verbreitet sein wird: Kontinuierliches Transferlernen (kontinuierliches Transferlernen), definiert als der Transfer von Wissen von einem Bereich, der sich im Laufe der Zeit ändert, in einen anderen Bereich, der sich ebenfalls im Laufe der Zeit ändert. Wir glauben, dass die Anwendung bestehender domänenübergreifender Empfehlungs- und Transferlernmethoden in industriellen Empfehlungssystemen, Suchmaschinen, Computerwerbung usw. dem Paradigma des kontinuierlichen Transferlernens folgen sollte, das heißt, der Transferprozess sollte kontinuierlich und mehrfach erfolgen. Der Grund dafür ist, dass sich die Datenverteilung schnell ändert und nur eine kontinuierliche Migration einen stabilen Migrationseffekt gewährleisten kann. In Kombination mit den Merkmalen dieses industriellen Empfehlungssystems können wir Probleme bei der praktischen Anwendung des Vortrainings und der Feinabstimmung feststellen. Aufgrund der Szenenunterschiede zwischen der Quelldomäne und der Zieldomäne ist es normalerweise erforderlich, eine große Anzahl von Stichproben zu verwenden, um durch Feinabstimmung des Quelldomänenmodells ein besseres Ergebnis zu erzielen. Um ein kontinuierliches Transferlernen zu erreichen, müssen wir von Zeit zu Zeit das neueste Quelldomänenmodell verwenden, um es zu verfeinern, was zu sehr hohen Schulungskosten führt. Diese Trainingsmethode ist auch schwierig online zu nutzen. Darüber hinaus kann die Verwendung dieser großen Anzahl von Stichproben zur Feinabstimmung auch dazu führen, dass das Quelldomänenmodell das gespeicherte nützliche Wissen vergisst, wodurch das katastrophale Vergessensproblem im Modell vermieden wird, indem die ursprünglichen Parameter des Quelldomänenmodells ersetzt werden Es ist auch möglich, dass in der Zieldomäne gelernte nützliche Erkenntnisse, die historisch aus dem Originalmodell gewonnen wurden, verworfen werden. Daher müssen wir ein effizienteres Lernmodell für den kontinuierlichen Transfer entwerfen, das für industrielle Empfehlungsszenarien geeignet ist. Dieser Artikel schlägt ein einfaches und effektives Modell CTNet (Continual Transfer Network, Continuous Transfer Network) zur Lösung der oben genannten Probleme vor. Im Gegensatz zu herkömmlichen Methoden zur Feinabstimmung vor dem Training besteht die Kernidee von CTNet darin, dass es nicht das gesamte vom Modell in der Geschichte erworbene Wissen vergessen und verwerfen kann und alle Parameter des ursprünglichen Quelldomänenmodells und des Zieldomänenmodells beibehält . Diese Parameter speichern Wissen, das durch sehr langes Lernen historischer Daten gewonnen wurde (z. B. wird das Feinranking-Modell von Taobao seit mehr als zwei Jahren kontinuierlich inkrementell trainiert). CTNet übernimmt eine einfache Twin-Tower-Struktur und verwendet eine leichte Adapterschicht, um die Ergebnisse der Zwischenschichtdarstellung des kontinuierlich vorab trainierten Quelldomänenmodells als zusätzliches Wissen über das Zieldomänenmodell abzubilden. Im Gegensatz zu Methoden zur Feinabstimmung vor dem Training, bei denen Daten zurückverfolgt werden müssen, um ein kontinuierliches Transferlernen zu erreichen, erfordert CTNet nur die Aktualisierung inkrementeller Daten, wodurch ein effizientes kontinuierliches Transferlernen erreicht wird.
|
Nicht betroffen Quelldomäne Szene Ziel |
Muss nur hinzugefügt werden: | Kontinuierliches Transferlernenkann mit einer großen Datenmenge erreicht werden | Nein |
Nein |
Ja |
|
Vortraining - Feinabstimmung |
Ja |
Ja | Nein |
|||
|
CTNet vorgeschlagen in diesem Artikel ist |
|
ist |
ist |
Tabelle 1: Vergleich zwischen CTNet und bestehenden domänenübergreifenden Empfehlungsmodellen
▐Problemdefinition# 🎜 🎜#
Dieser Artikel untersucht das neue Problem des kontinuierlichen Transferlernens:
Angesichts einer kontinuierlichen Änderung im Laufe der Zeit Quelldomäne und Zieldomäne: Continuous Transfer Learning hofft, das in der Vergangenheit oder aktuell erworbene Quelldomänen- und Zieldomänenwissen nutzen zu können, um die Vorhersagegenauigkeit in der zukünftigen Zieldomäne zu verbessern.
Wir wenden das Problem des kontinuierlichen Transferlernens auf die domänenübergreifende Empfehlungsaufgabe von Taobao an. Diese Aufgabe weist die folgenden Merkmale auf:
- Der Umfang verschiedener Empfehlungsszenarien variiert stark, und das Wissen des Modells, das in der größeren Quelldomäne trainiert wird, kann sein Wird verwendet, um die empfohlenen Ergebnisse der Zieldomäne zu verbessern.
- Benutzer und Produkte in verschiedenen Szenarien teilen sich den gleichen großen Pot. Aufgrund unterschiedlicher Anzeigeeffekte ausgewählter Produktpools, Hauptbenutzer, Grafiken und Texte usw. gibt es jedoch offensichtliche Feldunterschiede in verschiedenen Szenarien.
- Alle empfohlenen Szenariomodelle werden kontinuierlich inkrementell auf Basis der neuesten Daten trainiert. Abbildung 1: Modellbereitstellungsdiagramm Das Bild oben zeigt die Online-Bereitstellung unserer Methode. Vor dem
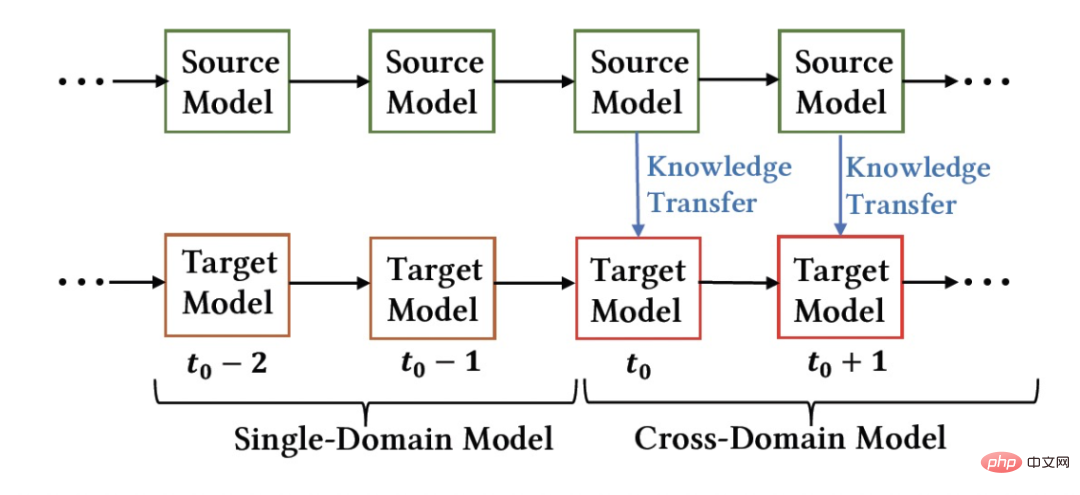 Moment wurden das Quelldomänenmodell und das Zieldomänenmodell separat und kontinuierlich inkrementell trainiert, wobei nur die Überwachungsdaten der jeweiligen Szenen verwendet wurden. Ab dem
Moment wurden das Quelldomänenmodell und das Zieldomänenmodell separat und kontinuierlich inkrementell trainiert, wobei nur die Überwachungsdaten der jeweiligen Szenen verwendet wurden. Ab dem
-Moment haben wir das domänenübergreifende Empfehlungsmodell CTNet auf der Zieldomäne eingesetzt. Dieses Modell wird weiterhin an den Zieldomänendaten arbeiten, ohne das im Verlauf erworbene Wissen zu vergessen Inkrementelles Training bei gleichzeitiger kontinuierlicher Wissensübertragung aus dem neuesten Quelldomänenmodell. Kontinuierliches Migrationsnetzwerkmodell (CTNet) :Continuous Transfer Network CTNet
Wie in Abbildung 2 dargestellt, ist das Continuous Transfer Network (CTNet)-Modell Wir haben vorgeschlagen, dass einige Feinabstimmungsmodelle der Zieldomäne alle Merkmale des Quelldomänenmodells und seiner Netzwerkparameter einbetten und eine Zwei-Turm-Struktur bilden. Der linke Turm von CTNet ist der Quellturm und der rechte Turm der Zielturm. Im Gegensatz zu herkömmlichen Methoden, die nur die endgültige Bewertung des Quelldomänenmodells verwenden oder nur einige flache Darstellungen verwenden (z. B. Einbetten), verwenden wir ein leichtes Adapternetzwerk, um alle verborgenen Zwischenschichten des Quelldomänenmodells zu kombinieren MLP#🎜 🎜# (insbesondere die 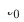 High-Order-Feature-Interaktionsinformationen, die tief im Quelldomänen-MLP enthalten sind) Darstellungsergebnisse
High-Order-Feature-Interaktionsinformationen, die tief im Quelldomänen-MLP enthalten sind) Darstellungsergebnisse #🎜 🎜#Ordnen Sie die Zielempfehlungsdomäne zu und fügen Sie das Ergebnis der entsprechenden Ebene von Target Tower hinzu 🎜#
#🎜 🎜#Ordnen Sie die Zielempfehlungsdomäne zu und fügen Sie das Ergebnis der entsprechenden Ebene von Target Tower hinzu 🎜#
Der Schlüssel zur Verbesserung der Leistung von CTNet liegt in der Nutzung der Migration von Deep-Representation-Informationen in MLP. Basierend auf der Idee der Gated Linear Units (GLU) verwendet das Adapternetzwerk eine Gated-Linear-Schicht, mit der die adaptive Merkmalsauswahl von Quelldomänenmerkmalen effektiv umgesetzt werden kann. Nützliches Wissen wird in das Modell migriert und Informationen, die damit inkonsistent sind Die Szeneneigenschaften werden übertragen und können herausgefiltert werden. Da das Quelldomänenmodell weiterhin die neuesten Quelldomänenüberwachungsdaten für das kontinuierliche Vortraining verwendet, lädt Source Tower während unseres Trainingsprozesses auch weiterhin die neuesten aktualisierten Quelldomänenmodellparameter und bleibt während des Backpropagation-Prozesses unverändert Effizienter Fortschritt des kontinuierlichen Transferlernens. Daher eignet sich das CTNet-Modell sehr gut für das Paradigma des kontinuierlichen Lernens und ermöglicht es dem Zieldomänenmodell, kontinuierlich das neueste Wissen zu lernen, das vom Quelldomänenmodell bereitgestellt wird, um sich an die neuesten Änderungen der Datenverteilung anzupassen. Da das Modell nur auf den Zieldomänendaten trainiert wird, wird gleichzeitig sichergestellt, dass das Modell nicht von den Trainingszielen der Quelldomäne beeinflusst wird und überhaupt kein Training der Quelldomänendaten erforderlich ist, wodurch eine große Speichermenge vermieden wird und Rechenaufwand. Darüber hinaus verwendet eine solche Netzwerkstruktur eine additive Entwurfsmethode, sodass die Abmessungen der MLP-Schicht des ursprünglichen Modells während des Migrationsprozesses nicht geändert werden müssen. Zielturm wird vollständig durch das ursprüngliche Zieldomänenmodell initialisiert, wodurch vermieden wird Zufällige Neuinitialisierung der MLP-Schicht Es stellt sicher, dass die Wirkung des ursprünglichen Modells nicht zu stark beeinträchtigt wird und nur weniger inkrementelle Daten erforderlich sind, um gute Ergebnisse zu erzielen, wodurch ein Heißstart des Modells realisiert wird.

Wir definieren das Quelldomänenmodell als 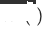 , das ursprünglich für eine einzelne Domäne empfohlene Zieldomänenmodell als
, das ursprünglich für eine einzelne Domäne empfohlene Zieldomänenmodell als 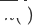 und das neu bereitgestellte domänenübergreifende Empfehlungsmodell für die Zieldomäne als
und das neu bereitgestellte domänenübergreifende Empfehlungsmodell für die Zieldomäne als 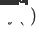 ,
, 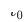 Durch die Bereitstellung der Online-Zeit für das domänenübergreifende Empfehlungsmodell wird das Modell kontinuierlich und inkrementell auf die Zeit aktualisiert
Durch die Bereitstellung der Online-Zeit für das domänenübergreifende Empfehlungsmodell wird das Modell kontinuierlich und inkrementell auf die Zeit aktualisiert 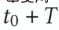 . Die Parameter von Adapter, Quellturm und Zielturm sind
. Die Parameter von Adapter, Quellturm und Zielturm sind  ,
, 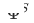 bzw.
bzw. 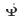 . Der Prozess des CTNet-Trainings ist wie folgt:
. Der Prozess des CTNet-Trainings ist wie folgt:

Abbildung 3: CTNet-Training
Experiment
▐ Offline-Effekt
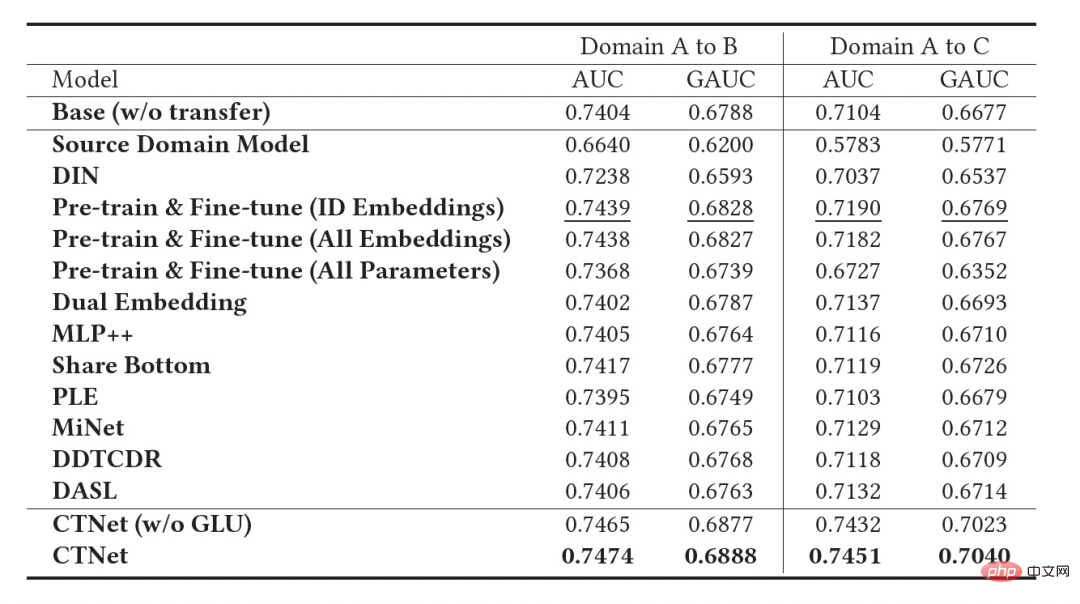
Tabelle 2: Offline Experimentelle Ergebnisse
Wie in der obigen Tabelle gezeigt, haben wir eine Reihe von Offline-Experimenten mit den entsprechenden Produktionsdatensätzen von zwei Unterszenarien mit gutem Warengeschäft (Domäne B und C in der Tabelle) durchgeführt, in denen die Quelle Domain (Domain B und C in der Tabelle) Domain A) empfiehlt Szenarien für den Homepage-Informationsfluss. Es ist ersichtlich, dass die direkte Verwendung der Bewertungsergebnisse des Informationsflusses (es könnte Ihnen auf der Homepage gefallen) (Quelldomänenmodell in der Tabelle) im Vergleich zum Online-Vollvolumenmodell nicht effektiv ist Der absolute Wert beträgt GAUC-5,88 % und GAUC-9,06 %, was die Unterschiede zwischen den Szenarien beweist.
Wir haben auch eine Reihe traditioneller domänenübergreifender Empfehlungs-Baseline-Methoden verglichen, darunter gängige Methoden zur Feinabstimmung vor dem Training und gemeinsame Trainingsmethoden (wie MLP++, PLE, MiNet, DDTCDR, DASL usw.). weist in beiden Fällen die beste Leistung auf. Es ist bei allen Datensätzen deutlich besser als bestehende Methoden. Im Vergleich zum vollständigen Online-Hauptmodell erzielte CTNet bei beiden Datensätzen erhebliche Verbesserungen des GAUC von +1,0 % bzw. +3,6 %. Wir haben die Vorteile des kontinuierlichen Transfers im Vergleich zum Einzeltransfer durch Experimente weiter analysiert. Im Rahmen von CTNet wird die durch eine einzelne Übertragung erzielte Effektverbesserung mit der inkrementellen Aktualisierung des Modells abgeschwächt, während kontinuierliches Transferlernen eine stabile Verbesserung des Modelleffekts gewährleisten kann.
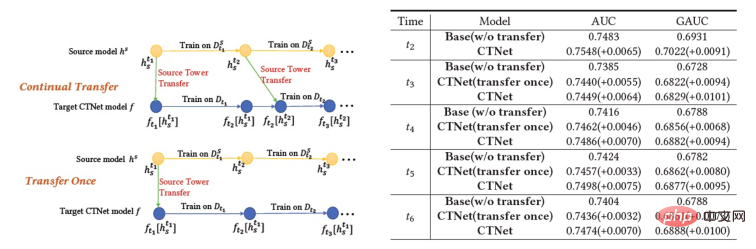
Abbildung 4: Vorteile des kontinuierlichen Transferlernens im Vergleich zum Einzeltransfer
Die folgende Tabelle zeigt die Wirkung der herkömmlichen Feinabstimmung vor dem Training. Für die Durchführung verwenden wir das vollständige Quelldomänenmodell auf den Zieldomänendaten Auf Training. Aufgrund der Unterschiede zwischen den Feldern ist eine sehr große Anzahl von Stichproben (z. B. 120-Tage-Stichproben) erforderlich, um die Wirkung des Modells auf ein Niveau anzupassen, das mit dem vollständigen Online-Basismodell vergleichbar ist. Um ein kontinuierliches Transferlernen zu erreichen, müssen wir in regelmäßigen Abständen eine Neuanpassung mit dem neuesten Quelldomänenmodell durchführen. Die enormen Kosten jeder Anpassung machen diese Methode auch für kontinuierliches Transferlernen ungeeignet. Darüber hinaus übertrifft diese Methode das Basismodell ohne Migration in Bezug auf die Wirkung nicht. Der Hauptgrund dafür ist, dass die Verwendung eines massiven Zieldomänen-Stichprobentrainings auch dazu führt, dass das Modell das ursprüngliche Quelldomänenwissen und den endgültigen Modelleffekt vergisst Das Training ähnelt einem Training nur auf Zieldomänendaten. Unter dem Paradigma der Feinabstimmung vor dem Training ist es besser, nur einige Einbettungsparameter zu laden, als alle Parameter wiederzuverwenden (wie in Tabelle 2 gezeigt). ▐ Das Geschäft mit der Empfehlung guter Produkte ist vollständig gestartet. Im Vergleich zum Vollmodell der vorherigen Generation wurden in zwei Empfehlungsszenarien deutliche Verbesserungen der Geschäftsindikatoren erzielt: Szenario B: CTR+2,5 %, zusätzliche Käufe +6,7 %, Anzahl der Transaktionen +3,4 %, GMV+7,7 %
Szenario C : CTR +12,3 %, Verweildauer +8,8 %, zusätzliche Käufe +10,9 %, Anzahl der Transaktionen +30,9 %, GMV +31,9 %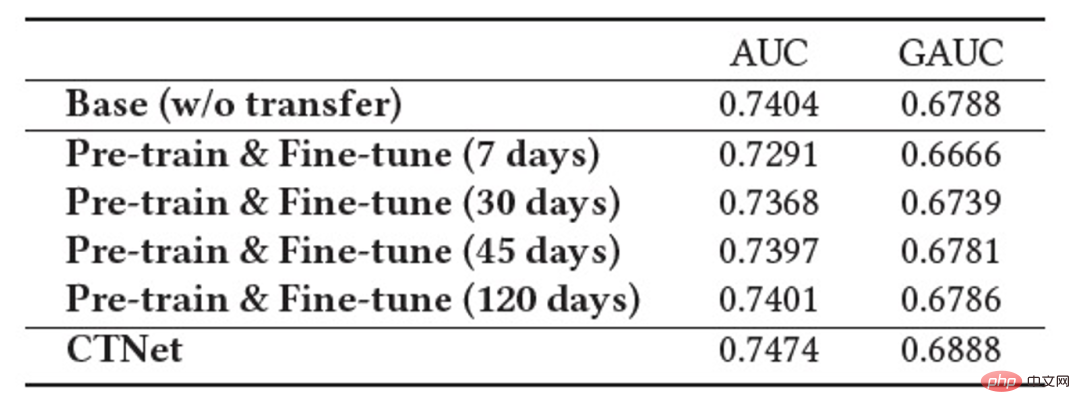
CTNet verwendet eine parallele Netzwerkstruktur, um Rechenressourcen zu sparen. Wir teilen einige Parameter und Ergebnisse der Aufmerksamkeitsschicht, sodass die Aufmerksamkeitsschicht im selben Teil des Quellturms und des Zielturms nur einmal berechnet werden kann. Im Vergleich zum Basismodell ist die Online-Antwortzeit (RT) von CTNet grundsätzlich gleich.
Zusammenfassung und AusblickIn diesem Artikel wird untersucht, wie ein domänenübergreifendes Empfehlungsmodell im Rahmen des kontinuierlichen Lernens in der Branche implementiert werden kann, und es wird ein neues domänenübergreifendes Empfehlungsparadigma für kontinuierliches Transferlernen unter Verwendung kontinuierlich vorab trainierter Methoden vorgeschlagen Quelldomänenmodelle Die Ergebnisse der Darstellung der mittleren Ebene werden als zusätzliches Wissen des Zieldomänenmodells verwendet. Ein leichtes Adaptermodul wurde entwickelt, um die Migration von domänenübergreifendem Wissen zu realisieren, und hat bei der Bewertung guter Produktempfehlungen erhebliche Geschäftsergebnisse erzielt. Obwohl diese Methode für die Geschäftsmerkmale guter Güter implementiert ist, handelt es sich auch um eine relativ allgemeine Modellierungsmethode. Die zugehörigen Modellierungsmethoden und -ideen können auf die Optimierung vieler anderer ähnlicher Geschäftsszenarien angewendet werden. Da das bestehende kontinuierlich vorab trainierte Quelldomänenmodell von CTNet nur Informationsfluss-Empfehlungsszenarien verwendet, werden wir in Zukunft erwägen, das kontinuierlich vorab trainierte Quelldomänenmodell auf ein vollständig domänenlernendes Vortrainingsmodell zu aktualisieren, das Empfehlung, Suche, private Domäne und andere weitere Szenarien.
TeamvorstellungWir sind das Big Taobao Technology-Content-Algorithmus-Good-Goods-Algorithmus-Team. Gute Produkte werden von Taobao auf der Grundlage von Mundpropaganda empfohlen und sind ein Einkaufsführer, der Verbrauchern dabei helfen soll, gute Produkte zu entdecken. Das Team ist für die Optimierung des Full-Link-Algorithmus für Produktempfehlungen und das Empfehlungsgeschäft für kurze Videoinhalte verantwortlich, um vorteilhafte Produkt-Mining-Funktionen und Channel-Shopping-Guide-Funktionen zu verbessern. Die aktuellen wichtigsten technischen Richtungen sind domänenübergreifende Empfehlungen für kontinuierliches Transferlernen, unvoreingenommenes Lernen, Empfehlungssystem-Vollverbindungsmodellierung, Sequenzmodellierung usw. Während wir geschäftlichen Mehrwert schaffen, haben wir auch mehrere Artikel auf internationalen Konferenzen wie SIGIR veröffentlicht. Zu den wichtigsten Ergebnissen zählen PDN, UMI, CDAN usw.
Das obige ist der detaillierte Inhalt vonAnwendung des domänenübergreifenden Empfehlungsrankingmodells für kontinuierliches Transferlernen im Taobao-Empfehlungssystem. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr