
Heim >Technologie-Peripheriegeräte >KI >DDD-Übung für das Telefonroboterteam
DDD-Übung für das Telefonroboterteam

- 王林nach vorne
- 2023-05-10 22:37:041387Durchsuche
Einführung
DDD ist eine Reihe von Methoden und Ideen. Eine Vielzahl von Metamodellen und Nominalkonzepten. Ihr Wesen ist „eine“ der Lösungen, die der Leitideologie entsprechen, und Anfänger geraten leicht in die Falle des Scheins. Wir sollten uns immer darüber im Klaren sein, dass „alle DDD-Metamodelle erstellt werden, um bestimmte Arten von Problemen in der tatsächlichen Entwicklung zu lösen“. Wenn Sie mit verschiedenen Metamodellen in Kontakt kommen, sollten Sie eine Überprüfung anhand der Probleme Ihres eigenen Unternehmens durchführen. Dies hilft, sich nicht in konzeptionellen Darstellungen zu verlieren und zum Kern der Problemlösung zurückzukehren.
Hintergrund
Das Datenarchitekturteam begann 2018 mit der Entwicklung des Telefonroboters basierend auf den Geschäftsanforderungen, und das innerhalb von einem Wimpernschlag. Derzeit wurden über 100 verschiedene Arten von Robotern auf dieser Plattform entwickelt, um den Händlern, Gebrauchtwagen-, OEM-, Finanz- und anderen BU-Unternehmen des Unternehmens ausgehende Anruffunktionen mit Hunderttausenden ausgehenden Anrufen pro Tag bereitzustellen. Das Telefonroboter-Projekt nimmt Gestalt an, ist dabei aber auch auf viele Herausforderungen gestoßen. Um diese Herausforderungen zu bewältigen, hat unser Team schließlich das DDD-Denken für Wiederaufbau und Entwicklung übernommen.
Bei der Anwendung von DDD implementierte das Datenarchitekturteam einige seiner eigenen Entwicklungsspezifikationen. Hier möchte ich einige Erfahrungen und Ideen mit Ihnen teilen und hoffe, dass sie als Ausgangspunkt dienen können. Lassen Sie mich das hier erklären. Viele multivariate Modelle werden in diesem Artikel nicht besprochen und es werden keine spezifischen Fälle angegeben. Betrachten Sie zunächst die Frage der Länge. Die zweite besteht darin, die DDD-Idee zu verstehen und durch die Kombination der jeweiligen Unternehmen umzusetzen. Es ist nicht sinnvoll, in meinem Unternehmen Beispiele zu nennen. Darüber hinaus sind solche Fälle leicht zu finden. Gleichzeitig bin ich der Meinung, dass es für alle wertvoller wäre, die Probleme und Lösungen unseres Teams, den Implementierungsprozess und die von uns erstellten Entwicklungsspezifikationen zu teilen. Studierende, die sich für DDD interessieren, mehr wissen möchten oder Fragen zu diesem Artikel haben, können mich gerne für eine Diskussion kontaktieren.
Im Folgenden werde ich aus diesen Teilen berichten: Herausforderungen im Roboterprojekt, warum DDD DDD ist, Schritte zur Implementierung von DDD, Verbesserungen im Team, aufgetretene Konflikte von der Theorie zur Praxis sowie zukünftige Verbesserungen und Zusammenfassungen in DDD-Anwendungen.
1. Aufgetretene Herausforderungen
Herausforderung 1: Hohe Komplexität der Geschäftslogik. Durch den Zugriff auf verschiedene Dienste wird ständig neue Logik hinzugefügt, um bestimmte Dienste in verschiedenen Szenarien zu behandeln.
Zum Beispiel: Absichtserkennungslogik im Prozess.
Absichtserkennung erfordert die Erkennung mehrerer KI-Modelle. Absichten, die von mehreren Modellen erkannt werden, können in Konflikt geraten, und es müssen widersprüchliche Absichtskonfigurationsregeln ausgewählt werden. Gleichzeitig ist es für einige Kaltstart- oder Notfalloptimierungsszenarien erforderlich, die Absichtserkennung durch die Konfiguration von Regeln zu unterstützen, die in Echtzeit wirksam werden. Und passende Wortslots müssen bei der Absichtserkennung von Regeln unterstützt werden. Es gibt viele Arten von Wortslots mit Szenarien und Wortslots mit Prozessen, die hinsichtlich der Priorität unterschieden werden. Anhand der Quelle der Datenidentifizierung können diese in Daten unterteilt werden, die von der KI identifiziert wurden, Daten, die durch Wörterbuchregeln abgeglichen wurden, oder Daten, die von der Geschäftspartei übermittelt wurden. Nachdem das Geschäft über einen bestimmten Zeitraum ausgeführt wurde, werden verschiedenen Arten von Slots unterschiedliche Attribute hinzugefügt. Zu den Slots für Autoserien gehören beispielsweise Produkt, Geschäftsumfang, Nichtbetrieb usw.; 🎜# Herausforderung 2: Die Struktur der Codearchitektur ist nicht klar. Wenn Geschäftsanforderungen hinzugefügt werden, nimmt die Codegröße zu. Gepaart mit der Komplexität der Logik und den unterschiedlichen Codes der Teamentwickler werden verschiedene logische Grenzen nach und nach unübersichtlich.
Zum Beispiel: Unsere übliche Entwicklungsmethode besteht darin, sie in Funktionsmodule zu zerlegen und den Geschäftsprozess in Reihe zu schalten, um jedes Modul zu koordinieren und gemeinsam die Geschäftsanforderungen zu erfüllen. Bei der Bewältigung der komplexen Logik dieser Art von Unternehmen weist dieses Lösungsdesign jedoch große Nachteile auf und Modulgrenzen werden leicht durchdrungen.
Die Beziehungen zwischen den Modulen rufen sich gegenseitig auf. Das ursprüngliche Isolationsdesign der Module wurde während des Implementierungsprozesses tatsächlich vollständig gebrochen. Aus den ursprünglich ideal vertikal geteilten Modulen wird eine netzartige Struktur.
Die vom Modulleiter in der mittleren Stufe entwickelten Attribute oder Methoden hängen von anderen externen Modulen ab, was zu unterschiedlichen Funktionen führt. Dies führt zu erhöhten Risiken, wenn sich die Anforderungen später ändern, oder es stellt sich heraus, dass Methoden, die nach Belieben geändert werden können, nicht geändert werden können und zusätzlicher Logikcode hinzugefügt werden muss, um dies zu implementieren. Dadurch wird bereits komplexer Code noch komplexer.
Der Abbau von Geschäftsanforderungen ist unzumutbar. Die erforderlichen Funktionen werden bei der Implementierung nicht strikt entwickelt, und der Abbau von Modulen wird nicht strikt befolgt, und es fehlt ein einheitliches Denken als Anleitung.
Herausforderung 3: Die Nachfrage nach dem Produkt ist so groß, dass es schwierig ist zu sagen, ob es einen echten Wert hat.
Herausforderung 4: Die Logik ändert sich schnell und viele Anforderungen erfordern eine Neugestaltung der Codelogik.
Herausforderung 5: Es gibt viele Unternehmen, inkonsistente Beschreibungen der einzelnen Unternehmen und hohe Kommunikationskosten.
Vertikale Grenzen werden durchbrochen, die Codekomplexität nimmt zu und Geschäftsprozesse werden häufig angepasst. Diese mehreren Dimensionen überlagern sich, was die Entwicklung und Wartung exponentiell erschwert. Die Stabilität des First-Level-Anwendungssystems des Telefonroboters ist schwer zu garantieren. Selbst wenn die technischen Klassenkameraden alle leitende Ingenieure sind, können sie das Projekt gemäß den Microservice-Ideen verstehen und in Module zerlegen. Auch wenn die Codelogik viele Entwurfsmuster zum Erstellen und Erweitern zitiert, selbst wenn sie verbunden sind Verschiedene Teile des Unternehmens, Plattformqualitätstools, viele Unit-Tests geschrieben. Als jedoch die neuen Anforderungen des Projekts iteriert wurden, gab es immer noch viele „Überraschungen“, die dem gesamten Team Kopfzerbrechen bereiteten.
2. Warum DDD
Warum DDD? Es gibt jeden Tag so viele Technologie-Stacks und so viele Ideen. Warum wird DDD verwendet, um damit umzugehen? Erstens modifiziert DDD den „Umgang mit der Kernkomplexität von Software“ sehr gut, was viele Menschen dazu bringt, es herauszufinden. Schauen wir uns also an, wie DDD die Herausforderungen des Projekts löst.
Werfen wir zunächst einen Blick auf die Komplexitätsklassifizierung von DDD und finden wir heraus, ob die Komplexität, mit der DDD zu kämpfen hat, eine Herausforderung für mich darstellt. In DDD-bezogenen Materialien werden die Ursachen der Komplexität anhand der beiden Dimensionen Verständnisfähigkeit und Vorhersagefähigkeit untersucht und analysiert.
Verständnisfähigkeit (das heißt, das Softwaresystem ist komplex und für Entwickler schwer zu verstehen):
Erste Skala: Der erste Faktor, der die Verständnisfähigkeit beeinflusst. Es gibt Hunderte Millionen Codezeilen, und die Beziehung zwischen den einzelnen Bedarfspunkten beeinflusst sich gegenseitig. Die Veränderung eines Bereichs wirkt sich auf den gesamten Körper aus.
Zweite Struktur: Eine unzumutbare oder sogar verwirrende Struktur erschwert Entwicklern die Aufrechterhaltung von Funktionen.
Vorhersagefähigkeit (d. h. die Geschäftsentwicklung ist schwer vorherzusagen):
Wenn sich Anforderungen ändern, ist es schwierig, die Richtung der Softwareimplementierung vorherzusagen, und es treten Probleme durch Über- und Unterdesign auf. Übermäßiges Design, viele Schnittstellen wurden reserviert und viele Muster wurden erstellt, um die Implementierungskomplexität des Codes zu erhöhen. Später stellte sich jedoch heraus, dass sie nicht verwendet wurden. Das Design ist unzureichend und die Umsetzung der Anforderungen berücksichtigt nicht die spätere Entwicklung. Bei Änderungen muss das bestehende Design aufgehoben und neu entwickelt werden.
Die Ursachen der Komplexität bei DDD lassen sich wie folgt zusammenfassen: Maßstab, Struktur und Veränderung; Maßstab und Struktur schaffen Hindernisse für das Verständnis, Veränderungen schaffen Hindernisse für die Vorhersage, und beides ergibt zusammen ein Komplexitätsproblem.
Zweitens ist DDD nicht nur eine Theorie der Code-Designphase, sondern umfasst auch eine vollständige Prozessdesign-Anleitung von der Anforderungsanalyse über die Architekturzuordnung bis hin zur Modellierung und Implementierung.
In der Phase der Bedarfsanalyse können wir den Geschäftswert durch relevante Leitideologien im Voraus genau verstehen und die Richtung zukünftiger Veränderungen erfassen. In der Architektur-Mapping-Phase wird die Leitideologie des Prozesses von den Anforderungen bis zur Architektur vorgegeben und das Designgewicht und die Spezifikationen hinzugefügt. Durch die Aufteilung von Unterdomänen, die Systemschichtung und die Geschäftsklassifizierung mit begrenztem Kontext werden Leitlinienspezifikationen bereitgestellt, um die Klarheit der Systemarchitektur sicherzustellen und die Systemkomplexität zu reduzieren. In der Modellierungs- und Implementierungsphase werden domänengesteuerte, designbezogene Metamodelle bereitgestellt, um die Funktionsaufteilung der einzelnen Teile zu verdeutlichen und schnell auf Geschäftsanforderungen und zukünftige Funktionsänderungen zu reagieren.
Schauen wir uns noch einmal die Leitideologie von DDD an:
Maßstabsproblem: Grenzen überwinden. Teilen und erobern Sie die Disassemblierung mit Subdomänen und begrenzten Kontexten.
Angesichts der Divide-and-Conquer-Idee bietet DDD zwei wichtige Design-Metamodelle: begrenzten Kontext und Kontextzuordnung.
Strukturelle Probleme: mehrschichtige Architektur + begrenzte Isolation.
Durch Layering können Probleme der Geschäftslogik und der Komplexität der technischen Implementierung isoliert werden. Die von DDD eingeführte Schichtarchitektur kapselt die Geschäftslogik in der Domänenschicht und platziert die technische Implementierung, die die Geschäftslogik unterstützt, in der Infrastrukturschicht. Die Anwendungsschicht über der Domänenschicht kapselt Anwendungsdienste und verbindet beide für die Zusammenarbeit.
Änderungsprobleme: Gestalten Sie Änderungen proaktiv.
Veränderungen sind nicht kontrollierbar, wir können sie nur annehmen. In der Phase der Bedarfsanalyse wird das 5W-Denken verwendet, um Änderungsmuster zu identifizieren und geschäftliche Änderungen zu steuern. DDD verwendet modellgesteuerte Design-Metamodelle, um die Domäne begrenzter Kontexte zu modellieren und ein Domänenmodell zu bilden, das Analyse, Design und Implementierung kombiniert.
Schauen wir uns abschließend die Lösung von DDD an. Es führt eine Reihe von Design-Metamodellen ein, die zu Mustern verfeinert werden und es Unternehmenssoftware ermöglichen, die Skalierung zu steuern, Strukturen aufzuteilen und proaktiv auf Änderungen zu reagieren.
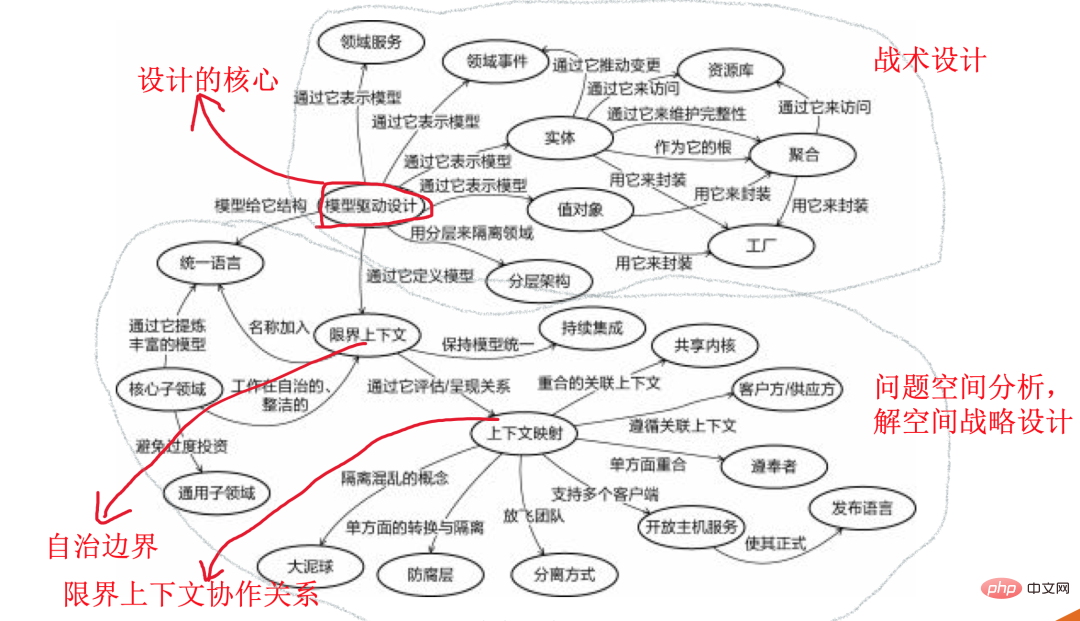
Lassen Sie mich dieses Bild, das in zwei Teile gegliedert ist, kurz vorstellen. Der erste Teil ist der unten mit Punkten eingekreiste Teil und beinhaltet keine spezifische technische Implementierung. Einige Metamodelllösungen zur Bewältigung des Problemraums werden während der Anforderungsanalysephase durchgeführt. Im anderen Teil, basierend auf dem ersten Teil, werden wir die spezifische Schichtung der Systemarchitektur, die Objektabstraktion und -aggregation sowie die Service-Disassemblierung durchführen. In dieser Phase werden wir das entsprechende Design implementieren.
Mein Verständnis ist, dass dieser Satz von Design-Metamodellen eine vollständige Lösung von der Bedarfsanalyse über das Design bis zur Implementierung bietet. Systemabbau in der Anforderungsanalysephase (entsprechend dem Subdomänen-Metamodell in der Abbildung). Teilen Sie es dann in den begrenzten Kontext der Aktualisierungsgranularität auf. Außerdem wird das kollaborative Beziehungsschema jedes Grenzwerts angegeben (entsprechend dem Kontextzuordnungs-Metamodell in der Abbildung). Die Entwurfsimplementierungsphase stellt den Entwurfselementplan des modellgesteuerten Entwurfs durch den granularen Entwurf der hierarchischen Architektur, der Domänendienste, der Aggregation usw. des Systems bereit. Bereitstellung einer Reihe vollständiger, theoretisch unterstützter, umsetzbarer Standardlösungen.
Die obige DDD-Analyse und Positionierung der Komplexität des Problems ist vollständig der Schmerzpunkt im Telefonrobotersystem. Die angebotenen Lösungen lösen auch perfekt verschiedene Herausforderungen, mit denen das Unternehmen konfrontiert ist. Nachdem das Team den Wert erkannt hatte, einigte es sich schnell darauf, es in Folgeprojekten umzusetzen.
3. DDD-Implementierungsschritte
Ich werde nicht im Detail auf die Details des Metamodells und die Geschäftsgrenzen eingehen, sondern direkt die tatsächlichen Schritte und Produkte unseres Teams nennen.
3.1 Der erste Schritt der Vorforschungsphase
Unsere Erfahrung in diesem Teil ist, dass jemand im Team als Vorreiter fungiert, der zunächst Energie für die eingehende Untersuchung von DDD-bezogenen Konzepten aufwendet und diese dann mit dem gesamten Team synchronisiert . Was unser Team betrifft, ist die Forschungsphase fragmentiert und es ist schwer abzuschätzen, wie lange sie dauern wird. Die Popularisierungsphase der Teamwissenschaft dauerte 8 Stunden. Danach haben die Studierenden im Team die Möglichkeit, auf der Grundlage konzeptioneller Anleitung schnell und tiefgreifend zu lernen. Und organisieren Sie Teammitglieder, die miteinander diskutieren, um das Verständnis zu bestätigen.
3.2 Der zweite Schritt besteht darin, Leitideologie und Umsetzungsspezifikationen einzuführen.
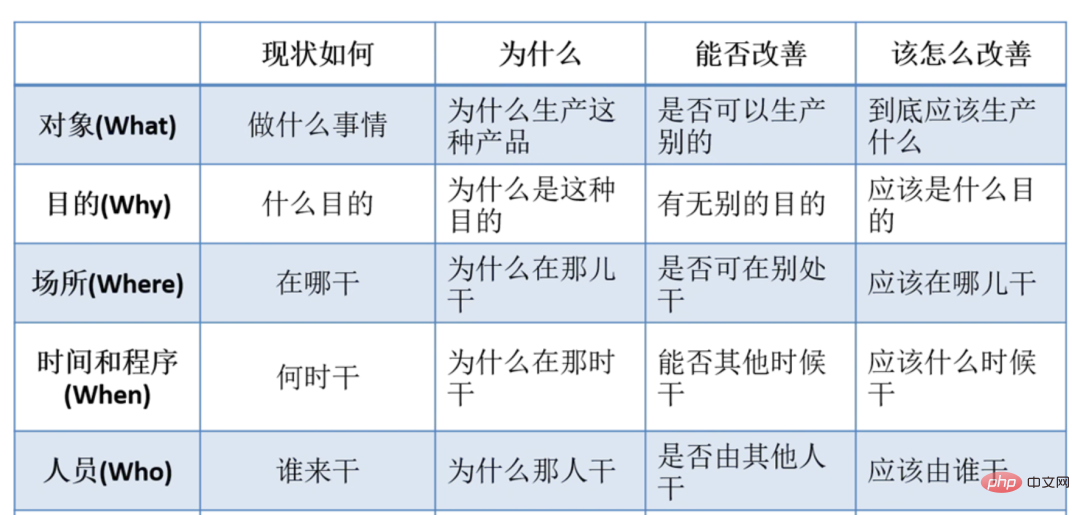
3.2.1 In der Phase der Bedarfsanalyse wird die theoretische Unterstützung des 5W-Modells eingeführt, um dabei zu helfen, tatsächliche Bedürfnisse zu identifizieren, die Richtung der Veränderung aktiv zu steuern und zu beseitigen bedeutungslose Bedürfnisse.
Dieser Teil ist die 5W-Theorie als theoretische Unterstützung für die Analyse von Produktbedürfnissen. Sie ist sehr hilfreich, um echte Bedürfnisse zu identifizieren und die Entwicklungsrichtung des Unternehmens besser zu analysieren. Ungültige Anforderungen können auch direkt aus der Quelle reduziert werden, wie im Bild oben gezeigt.
3.2.2 führt Servicespezifikationen ein und implementiert Geschäftsfunktionen mit dokumentenbasierten Vergleichscodes. Es ist hilfreich für die Entwicklung und die anschließende Anforderungssortierung und kann auch als Überlegung für die Unit-Test-Abdeckung verwendet werden.
- 3.2.2.1 Die Teammitglieder sind sich einig, dass die Leistungsbeschreibung zuerst geschrieben und dann entwickelt werden muss. Der Zeitaufwand für das Schreiben der Servicespezifikation besteht eigentlich darin, das technische Verständnis der Anforderungen zu klären und die Ideen zu klären. Dieser Teil der Zeit kann beim späteren Schreiben von Code zurückgewonnen werden.
- 3.2.2.2 Leistungsverzeichnis und Anforderungen Das Leistungsverzeichnis entspricht dem Einzeltest. Es löst übrigens das Problem, dass es vorher keinen Standard für Einzeltests gab (die Code- und Methodenabdeckung, die ich verstehe, kann nicht als Standard bezeichnet werden).
Hier ist die von unserem Team übernommene Servicespezifikationsvorlage:
Nummer: Eine eindeutige Nummer, die den Geschäftsservice kennzeichnet.
Name: Name des Unternehmensdienstes in Verbalphrasenform.
Beschreibung:
述 述 Ich möchte
das Auslösen von Ereignissen erleichtern:
Das Geschäftsdienstereignis, das den Charakter aktiv ausgelöst hat, kann ein Klick auf das UI-Steuerelement, eine bestimmte Strategie oder ein vom System gesendetes Begleitsystem sein System. Nachrichten usw.
Grundlegender Prozess: Wird verwendet, um den Hauptprozess von Geschäftsdienstleistungen auszudrücken, dh das Geschäftsszenario einer erfolgreichen Ausführung. Es kann auch als „Haupterfolgsszenario“ bezeichnet werden. Alternativer Prozess: Erweiterter Prozess zur Darstellung von Geschäftsdienstleistungen, also Geschäftsszenarien, bei denen die Ausführung fehlschlägt. Akzeptanzkriterien: Eine Reihe akzeptabler Bedingungen oder Geschäftsregeln, aufgeführt in Aufzählungspunkten. 3.3 Der dritte Schritt besteht darin, die Architekturlösung zu bestimmen. Lernen Sie die Lösung des modellgesteuerten Design-Metamodells in DDD. Der Hauptzweck besteht darin, die Verantwortungsgrenzen, dh den begrenzten Kontext, aufzuteilen, die traditionelle Netzwerkstrukturbeziehung in eine vertikale Segmentierungsbeziehung umzuwandeln und die gegenseitige Abhängigkeit zu verringern. Die allgemeine Verwendung einer begrenzten Online-Textzerlegung und des Diamond-Drive-Designs bildet die allgemeine ideologische Leitlinie. Das System verwendet eine mehrschichtige Architektur COLA 4.0 . Was ich hier sagen möchte ist, dass es keinen Referenzstandard gibt. Ich hoffe, dass jeder zunächst die Idee von DDD verstehen und sich dann mit großem Konsens in der Branche auf das Namensschema beziehen kann. Gleichzeitig müssen Sie die Programmierstilpräferenzen der Teammitglieder berücksichtigen und letztendlich die Codierungsstandards Ihres eigenen Teams formulieren.Als Beispiel anhand der Benennung unserer Input- und Output-Nachrichten. Nach Abwägung aller Beteiligten haben wir die oben dargestellte besonders feinkörnige Benennungsmethode nicht übernommen. Stattdessen herrscht im Team einfach Konsens darüber, dass der Eingabeparameter *request und der Ausgabeparameter *response als Standard benannt werden.
3.5 Der fünfte Schritt besteht darin, den begrenzten Kontext basierend auf Geschäftsmerkmalen zu identifizieren. 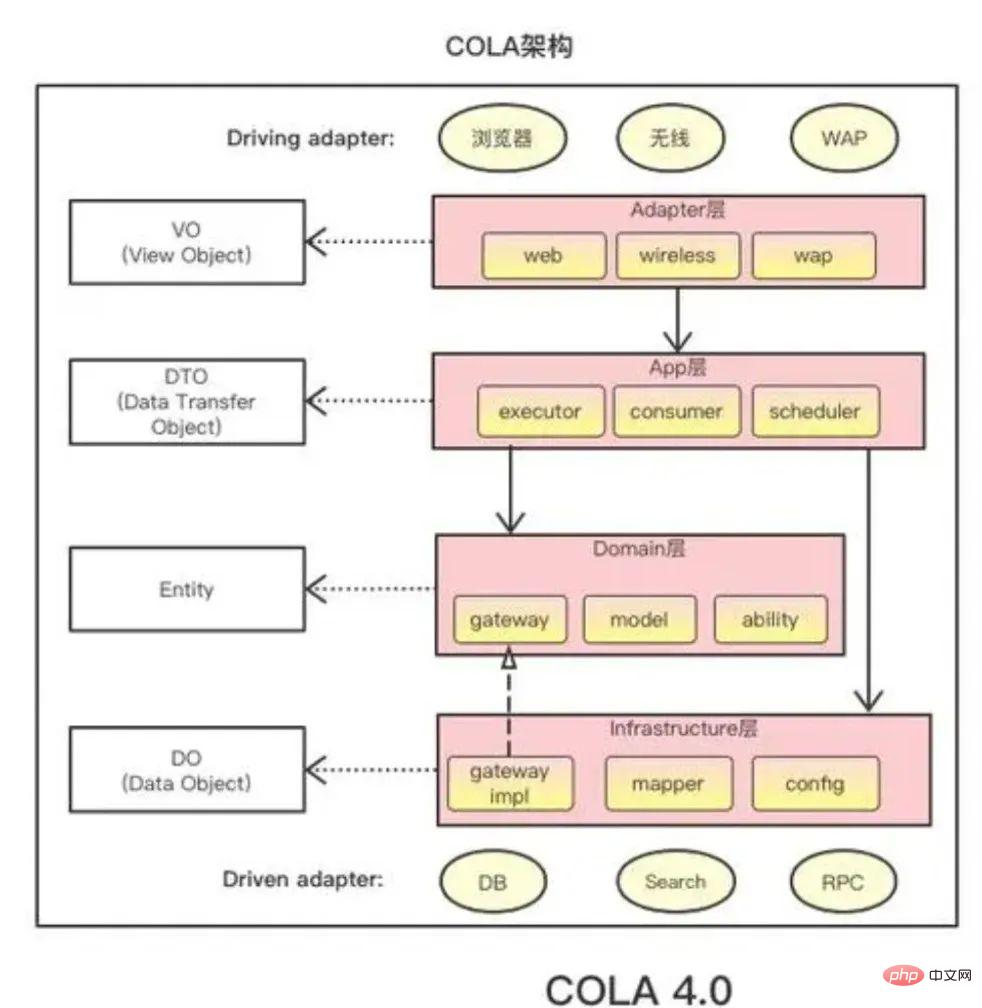
Gesetz 1 |
Schreiben Sie jeweils nur einen fehlgeschlagenen Test als Beschreibung der neuen Funktion. |
Gesetz Zwei |
Schreiben Sie keinen Produktionscode, es sei denn, er sorgt lediglich dafür, dass der fehlgeschlagene Test bestanden wird. |
Gesetz 3 |
Refaktorieren Sie den Code nur oder beginnen Sie mit dem Hinzufügen neuer Funktionen, wenn alle Tests erfolgreich sind. |
4. Verbesserung des Teams
4.1 Von der passiven Aufnahme von Bedürfnissen zur aktiven Reaktion
Nutzen Sie in der Bedarfsanalyse das 5W-Prinzip. Analysieren Sie die Rationalität der Anforderungen und können Sie die sich ändernde Richtung des Projekts proaktiv steuern. Lösen Sie „Herausforderung drei“, um den Nachfragewert zu ermitteln, und verbessern Sie „Herausforderung vier“, um die Richtung von Geschäftsentwicklungsänderungen zu steuern.
4.2 Kommunikationskosten reduzieren
Verwenden Sie eine einheitliche Sprache und ideologische Kommunikation, um die Kosten für die Zusammenarbeit in allen Aspekten von „Challenge Five“ zu senken.
4.3 Verbesserung des Architekturdesigns
Reduzieren Sie die Codegröße angemessen, indem Sie das Subdomänenmodell und den begrenzten Kontext des Metamodells entwerfen. Durch das mehrschichtige Denken von DDD werden die Komplexität der Geschäftslogik und die technischen Dimensionen isoliert und die Codestruktur klar. Gleichzeitig nimmt das Projekt eine rautenförmige symmetrische Struktur an und interagiert über Nord-Süd-Zugänge mit der Außenwelt, um die Entstehung eines Netzwerks aus Modulen zu vermeiden. Das „Challenge 2“-Problem wurde gelöst und die Komplexität von „Challenge 1“ reduziert.
4.4 Verbesserung der technischen Implementierung
Bei der Entwicklung von Geschäftsfunktionen berücksichtigt das Team die angemessenen Grenzen der Anforderungen. Während des Implementierungsprozesses werden wir überlegen, ob wir es in der Domänenschicht oder der Geschäftsdienstschicht platzieren und ob wir ein Anämiemodell oder ein Überlastungsmodell verwenden, um Funktionen zu implementieren.
4.5 Verbesserung der Dokumentspezifikationen
In Bezug auf Dokumentspezifikationen wird der Dienstspezifikationsmechanismus eingeführt. Es kann als Werkzeug zum Sortieren von Anforderungen und als Grundlage für Einzeltests verwendet werden. Gleichzeitig werden Leistungsbeschreibungsdokumente zur späteren Verwendung bereitgestellt.
4.6 Verbesserung der Code-Implementierung
In Bezug auf die Code-Implementierung, von der Architektur bis zur Codierungsimplementierung und Benennung, wurde eine Reihe markierter Spezifikationen gebildet.
Insgesamt hat sich in diesem Modus die Denkweise des Teams geändert. Durch die Anwendung verschiedener Metamodelle können wir den Herausforderungen begegnen, die sich aus verschiedenen Aspekten ergeben, von der Bedarfsanalyse über die Systemarchitektur bis hin zur Codeimplementierung.
5. Konflikte von der Theorie zur Praxis
5.1 Anämiemodell PK-Überlastungsmodell
Anämiemodell: Für Laien bedeutet es, dass die Domäne Das Objekt verfügt nur über reine Datenklassen mit Attribut-Getter/Setter-Methoden, Geschäftslogik und Anwendungslogik werden alle in der Serviceschicht platziert. Das Domänenobjekt unter diesem Modell wird von Martin Fowler als „anämisches Domänenobjekt“ bezeichnet.
Überlastungsmodell: Im Gegenteil, das Überlastungsmodell enthält nicht nur die Eigenschaften des Objekts, sondern auch das Verhalten des Objekts, einschließlich der Geschäftslogik.
Aus objektorientierter Sicht enthalten Objekte Attribute und Verhaltensweisen, daher sollte das Überlastungsmodell verwendet werden, und DDD empfiehlt grundsätzlich auch die Verwendung des Überlastungsmodells. Aber wenn es um den konkreten Entwicklungsstand geht, hat das Anämiemodell zwar viele Probleme, ist aber schon seit so vielen Jahren in der Branche und wird so häufig verwendet, und es hat immer noch seinen Wert. Darüber hinaus verwenden die meisten JAVA-Anwendungen den Mybatis-Technologie-Stack und viele Objekte sind anämische Einheiten, die automatisch von Plug-Ins generiert werden. Die Frage ist also, dass die Übernahme des Hyperämie-Modells den Verzicht auf einige praktische Hilfsmittel bedeutet. Bei diesem Thema gibt es innerhalb des Teams große Differenzen. Letztendlich ist unser Ansatz, dass es für diesen Teil keinen harten Standard gibt, es wird jedoch empfohlen, den Überlastungsmodus zu verwenden.
5.2 Halten Sie sich strikt an die Datenkonvertierungsbeschränkungen
PK Nutzen Sie optimierte und effiziente externe Daten direkt
Im Denken von DDD, um sicherzustellen Zuverlässigkeit des Domänendienstes. Die Daten, auf die sich die Domänendienste stützen, müssen Entitäten und aggregierte Daten in der Domäne sein, und die direkte Verwendung externer Nachrichtenvertragsdaten ist nicht zulässig. Die Konvertierung von Daten, die von Nord-Süd-Gateways entsprechend der rautensymmetrischen Architektur erhalten werden, wird zusätzlichen Arbeitsaufwand mit sich bringen. Einige Teammitglieder schlugen vor, dass bestimmte relativ stabile Strukturen diesem Prinzip nicht entsprechen müssen. Der Grund dafür ist, dass dies die Entwicklungsgeschwindigkeit erhöhen kann, und sie glauben, dass 90 % der Daten Ressourcen mit relativ stabilen Strukturen wie Datenbanken sein könnten. Letztendlich war das Team jedoch dennoch strikt verpflichtet, sich an diese Leitideologie zu halten.
5.3 Cache-Verarbeitung ermöglicht gemeinsame PK-Grenzisolation
Cache-Verarbeitung in verschiedenen Grenzen desselben Systems: ermöglicht gemeinsame PK-Grenzisolation.
Aus der damaligen Szene zu urteilen, kann das Ermöglichen des Teilens kurzfristig die Arbeitsbelastung verringern und Ressourcen sparen. Aber der Grund, warum wir Grenzen ziehen müssen, besteht darin, die Beziehung aufzubrechen und zu verhindern, dass sie zu groß wird. Der hier gegebene Vorschlag besteht darin, zunächst zu prüfen, ob es sinnvoll ist, Dienste, die Daten gemeinsam nutzen, in einer Grenze zusammenzuführen. Ist eine Zusammenführung nicht möglich, müssen die Daten isoliert werden.
5.4 Front-End-PK-Back-End der Servicespezifikation gegen Anforderungen
Die leitenden theoretischen Ideen sind sehr schön und es ist erforderlich, das technische Implementierungsdenken während der Bedarfsanalyse abzuschirmen. Aber schließlich muss es im Technologie-Stack implementiert werden. Wenn es um die Technologieimplementierung geht, wird es durch die Technologieimplementierung beeinträchtigt. Ein herausragendes Thema war damals, dass die Implementierung von Funktionen im Frontend platziert oder als Back-End-Dienst implementiert werden konnte.
Beispiel 1: Die Anforderung erfordert die Anzeige der Kombination „ID + Name“, aber die beiden von der Back-End-Schnittstelle zurückgegebenen Felder „ID“ und „Name“ werden durch die eigentliche Front-End-Technologie kombiniert Stack und die Servicespezifikationen für Front-End und Back-End sind inkonsistent.
Beispiel 2: Die Anforderung erfordert die Überprüfung, dass der Parameter nicht leer ist. In einigen internen Systemen besteht das technische Team unseres Teams aus Front-End- und Back-End-Full-Stack-Ingenieuren, die die Arbeit aufteilen und Module je nach Bedarf entwickeln. Oftmals sind sie nicht so streng, dass beide Enden überprüft werden können. Es kommt auch zu Konflikten, an denen sich die Leistungsbeschreibung orientiert.
Unsere letzte Wahl: Das Team führt eine Back-End-Serviceschicht ein. Aber gleichzeitig werden wir einige Verbesserungen vornehmen, wie zum Beispiel die Verlagerung der Verifizierung und anderer Funktionen auf die Schnittstellenebene.
5.5 Wer stellt sicher, dass die Leistungsbeschreibung korrekt geschrieben ist und die Produkt-PK-Technologie
Der Idealzustand in der Anfangsphase soll durch das nachfrageseitige Produkt überprüft werden, basierend auf dem Prinzip: Wer es braucht, bestätigt es. Aufgrund der Unterschiede in 4.4 wird unsere tatsächliche Implementierung jedoch von der verantwortlichen technischen Person überprüft.
6. Zukünftige Verbesserungen und Zusammenfassung der DDD-Anwendung. Das Team hat sie derzeit aus Sicht der Architektur und Spezifikationen implementiert. Einige Details, wie z. B. das Design von Aggregatklassen, Entitäten und Wertobjekten, sind jedoch nicht besonders detailliert. Diese feingranularen Verbesserungen werden wir in Zukunft weiter vorantreiben. Gleichzeitig werden einige alte Projekte im Einsatz nach DDD-Ideen umgestaltet und rekonstruiert.
Manche Leute glauben, dass die Anwendung von DDD die Entwicklungseffizienz verringert. Dies ist auch ein Problem vieler Teams. So betrachten wir dieses Problem. Das Szenario der Anwendung von DDD besteht darin, komplexe Geschäftsprobleme zu lösen, was tatsächlich die Menge an Code erhöht. Dies bedeutet jedoch nicht, dass die Entwicklungseffizienz verringert wird. Eine klare Architekturstruktur, aggregierte Domänendienste und standardisierte Standards bringen Vorteile mit sich, die weit über die Investition in spätere Bedarfs-Upgrades, Code-Wartung und Komplexitätskontrolle hinausgehen. Darüber hinaus werden nach Angaben der Softwareindustrie 80 % der Zeit für Bedarfsanalyse und Design aufgewendet, während die Entwicklungszeit nur 20 % ausmacht. Daher steht dieser Teil des Verlustes nicht im Mittelpunkt.
Beschreiben Sie abschließend Ihre Erfahrungen mit der Verwendung von DDD. Es gibt viele Arten von DDD-Metamodellen, und jeder kann sie lernen und gezielt anwenden, basierend auf den Schwachstellen, mit denen das Unternehmen konfrontiert ist. In der tatsächlichen Geschäftsumgebung weisen unsere Domänenmodelle mehr oder weniger „Spezialitäten“ auf. Wenn sie den DDD-Spezifikationen zu 100 % entsprechen, können die Kosten relativ hoch sein. Daher ist es am wichtigsten, die DDD-Idee zu verstehen und die endgültige Entscheidung zu treffen Eine Lösung, die zu Ihrem Unternehmen passt.
Über den Autor
 Li Xiaohua
Li Xiaohua
- Seit 2016 bei Autohome und arbeitet derzeit im Team für Händlerdatenarchitektur, verantwortlich für das Telefonroboterprojekt.
Das obige ist der detaillierte Inhalt vonDDD-Übung für das Telefonroboterteam. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr