
Heim >Technologie-Peripheriegeräte >KI >Die EMNLP-Konferenz 2022 ist offiziell abgeschlossen, der beste Langbeitrag, der beste Kurzbeitrag und weitere Auszeichnungen wurden bekannt gegeben
Die EMNLP-Konferenz 2022 ist offiziell abgeschlossen, der beste Langbeitrag, der beste Kurzbeitrag und weitere Auszeichnungen wurden bekannt gegeben

- PHPznach vorne
- 2023-05-09 14:10:141522Durchsuche
Kürzlich fand in Abu Dhabi, der Hauptstadt der Vereinigten Arabischen Emirate, die EMNLP 2022 statt, die Top-Konferenz im Bereich der Verarbeitung natürlicher Sprache.

Für die diesjährige Konferenz wurden insgesamt 4190 Beiträge eingereicht und schließlich 829 Beiträge angenommen (715 lange Beiträge, 114 Beiträge), mit einer Gesamtannahmequote von 20 %, was sich nicht wesentlich von der vorherigen unterscheidet Jahre.
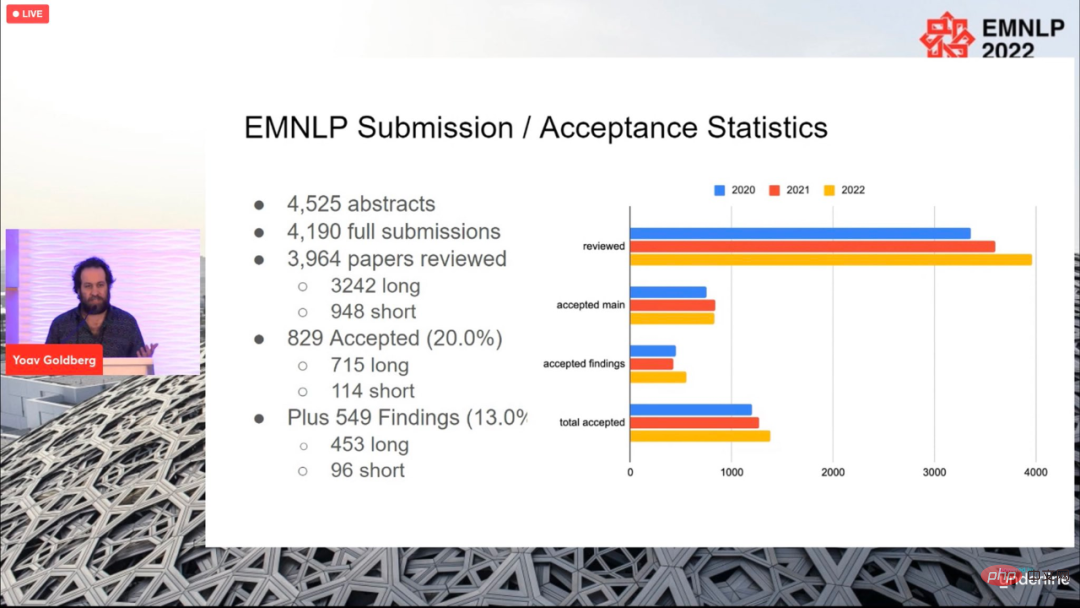
Die Konferenz endete am 11. Dezember Ortszeit, und auch die Paper Awards für dieses Jahr wurden bekannt gegeben, darunter der beste lange Paper (1 Stück), der beste kurze Paper (1 Stück) und der beste Demopapier (1 Artikel).
Best Long Paper

Paper: Abstract Visual Reasoning with Tangram Shapes
- Autoren: Anya Ji, Noriyuki Kojima, Noah Rush, Alane Suhr, Wai Keen Vong, Robert D. Hawkins, Yoav Artzi. Institutionen: Cornell University, New York University, Allen Institute, Princeton University Zusammenfassung:
- In diesem Artikel stellt der Forscher „KiloGram“ vor, eine Ressourcenbibliothek zum Studium des abstrakten visuellen Denkens von Menschen und Maschinen. KiloGram verbessert die vorhandenen Ressourcen auf zwei Arten erheblich. Zunächst kuratierten und digitalisierten die Forscher 1.016 Formen und schufen so eine Sammlung, die zwei Größenordnungen größer war als die in bestehenden Arbeiten verwendeten. Diese Sammlung erweitert die Abdeckung des gesamten Spektrums an Benennungsvarianten erheblich und bietet eine umfassendere Perspektive auf das menschliche Benennungsverhalten. Zweitens behandelt die Sammlung jedes Tangram nicht als einzelne Gesamtform, sondern als Vektorform, die aus den ursprünglichen Puzzleteilen besteht. Diese Zerlegung ermöglicht das Nachdenken über ganze Formen und ihre Teile. Die Forscher nutzten diese neue Sammlung digitaler Puzzle-Grafiken, um eine große Menge an Textbeschreibungsdaten zu sammeln, die die große Vielfalt des Benennungsverhaltens widerspiegeln.
- Die Forscher nutzten Crowdsourcing, um den Annotationsprozess zu erweitern, indem sie für jede Form mehrere Annotationen sammelten, um die Verteilung der von ihr hervorgerufenen Annotationen anstelle einer einzelnen Stichprobe darzustellen. Insgesamt wurden 13.404 Anmerkungen gesammelt, die jeweils ein vollständiges Objekt und seine zerlegten Teile beschreiben. Das Potenzial von KiloGram ist umfangreich. Wir nutzten diese Ressource, um die Fähigkeiten des abstrakten visuellen Denkens neuerer multimodaler Modelle zu bewerten und stellten fest, dass vorab trainierte Gewichte begrenzte Fähigkeiten des abstrakten Denkens aufwiesen, die sich mit der Feinabstimmung erheblich verbesserten. Sie stellten außerdem fest, dass explizite Beschreibungen das abstrakte Denken sowohl von Menschen als auch von Modellen erleichtern, insbesondere wenn Sprache und visuelle Eingaben gemeinsam kodiert werden.
Abbildung 1 ist ein Beispiel für zwei Tangrams mit jeweils zwei unterschiedlichen Anmerkungen. Jede Anmerkung enthält eine Beschreibung der gesamten Form (in Fettdruck), eine Segmentierung der Teile (in Farbe) und einen Namen für jedes Teil (mit jedem Teil verbunden). Das obere Beispiel zeigt eine geringe Variabilität für nahezu perfekte Übereinstimmung, während das untere Beispiel eine hohe Variabilität für Sprach- und Segmentierungsdivergenz zeigt.
KiloGram-Adresse: https://lil.nlp.cornell.edu/kilogram
Die Nominierungen für den besten Long Paper für diese Konferenz stammen von Kayo Yin und Graham Neubig Von zwei Forschern erhalten.
Aufsatz: Interpretation von Sprachmodellen mit kontrastiven Erklärungen
- Autor: Kayo Yin, Graham Neubig
Aufsatz: Die Interpretierbarkeitsmethode des Modells ist Wird oft zur Erklärung von NLP verwendet Modellieren Sie Entscheidungen zu Aufgaben wie der Textklassifizierung, bei denen der Ausgaberaum relativ klein ist. Bei der Anwendung auf die Sprachgenerierung besteht der Ausgaberaum jedoch oft aus Zehntausenden von Tokens, und diese Methoden können keine aussagekräftigen Erklärungen liefern. Sprachmodelle müssen verschiedene Merkmale berücksichtigen, um ein Token vorherzusagen, z. B. seine Wortart, Numerus, Zeitform oder Semantik. Da bestehende Erklärungsmethoden Belege für alle diese Merkmale in einer einzigen Erklärung vereinen, ist diese für das menschliche Verständnis weniger interpretierbar.
Um verschiedene Entscheidungen bei der Sprachmodellierung zu unterscheiden, untersuchen Forscher Sprachmodelle, die sich auf kontrastive Erklärungen konzentrieren. Sie suchen nach auffälligen Eingabe-Tokens und erklären, warum das Modell einen Token vorhergesagt hat, einen anderen jedoch nicht. Untersuchungen zeigen, dass kontrastive Erklärungen bei der Validierung wichtiger grammatikalischer Phänomene viel besser sind als nicht-kontrastive Erklärungen und dass sie die Simulierbarkeit kontrastiver Modelle für menschliche Beobachter erheblich verbessern. Die Forscher identifizierten auch gegensätzliche Entscheidungsgruppen, für die das Modell ähnliche Beweise verwendete, und konnten beschreiben, welche Eingabetoken das Modell bei verschiedenen Entscheidungen zur Sprachgenerierung verwendete. 🔜
Autor : Jitkapat Sawatphol, Nonthakit Chaiwong, Can Udomcharoenchaikit, Sarana NutanongInstitution: VISTEC Institute of Science and Technology, Thailand

In dieser Studie schlugen die Forscher die Autorschaft vor Präsentation Regularisierung, ein Destillationsframework, das die themenübergreifende Leistung verbessert und auch mit unbekannten Autoren umgehen kann. Dieser Ansatz kann auf jedes Modell der Autorendarstellung angewendet werden. Experimentelle Ergebnisse zeigen, dass in der themenübergreifenden Einstellung die Leistung von 4/6 verbessert wird. Gleichzeitig zeigt die Analyse der Forscher, dass in Datensätzen mit einer großen Anzahl von Themen themenübergreifende Trainings-Shards Probleme mit dem Verlust von Themeninformationen haben, wodurch ihre Fähigkeit zur Bewertung themenübergreifender Attribute geschwächt wird.
- Bestes Demo-Paper
- Paper: Evaluate & Evaluation on the Hub: Better Best Practices for Data and Model Measurements
Autoren: Leandro von Werra, Lewis Tunstall, Abhishek Thakur, Alexandra Sasha Luccioni et al. Institution: Hugging Face Beurteilung ist ein Maschine Als wichtiger Bestandteil des Lernens (ML) stellt diese Forschung Evaluate and Evaluation on Hub vor – eine Reihe von Tools, die bei der Bewertung von Modellen und Datensätzen in ML helfen. Evaluate ist eine Bibliothek zum Vergleich verschiedener Modelle und Datensätze, die verschiedene Metriken unterstützt. Die Evaluate-Bibliothek soll die Reproduzierbarkeit von Bewertungen unterstützen, den Bewertungsprozess dokumentieren und den Umfang der Bewertungen erweitern, um weitere Aspekte der Modellleistung abzudecken. Es umfasst mehr als 50 effiziente Spezifikationsimplementierungen für eine Vielzahl von Domänen und Szenarien, interaktive Dokumentation und die Möglichkeit, Implementierungs- und Evaluierungsergebnisse einfach zu teilen.
Projektadresse: https://github.com/huggingface/evaluate
Das obige ist der detaillierte Inhalt vonDie EMNLP-Konferenz 2022 ist offiziell abgeschlossen, der beste Langbeitrag, der beste Kurzbeitrag und weitere Auszeichnungen wurden bekannt gegeben. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr