
Heim >Technologie-Peripheriegeräte >KI >Effizientes und realistisches Stadtrendering in extrem großem Maßstab: Kombination von NeRF und Feature-Grid-Technologie
Effizientes und realistisches Stadtrendering in extrem großem Maßstab: Kombination von NeRF und Feature-Grid-Technologie

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-06 17:04:171213Durchsuche
Das rein MLP-basierte Neural Radiation Field (NeRF) leidet aufgrund der begrenzten Modellkapazität häufig unter einer unzureichenden Anpassung bei der Darstellung von Unschärfen in großen Szenen. Kürzlich haben einige Forscher vorgeschlagen, die Szene geografisch aufzuteilen und mehrere Sub-NeRFs zu verwenden, um jeden Bereich separat zu modellieren. Das dadurch verursachte Problem besteht jedoch darin, dass die Trainingskosten mit der schrittweisen Erweiterung der Szene linear mit der Anzahl der Sub-NeRFs werden. expandieren.
Eine andere Lösung ist die Verwendung einer Voxel-Feature-Rasterdarstellung, die recheneffizient ist und sich mit zunehmender Rasterauflösung auf natürliche Weise auf große Szenen skalieren lässt. Allerdings erzielen Feature-Netze aufgrund weniger Einschränkungen oft nur suboptimale Lösungen, was zu einigen Rauschartefakten beim Rendern führt, insbesondere in Bereichen mit komplexer Geometrie und Texturen.
In diesem Artikel schlagen Forscher der Chinesischen Universität Hongkong, des Shanghai Artificial Intelligence Laboratory und anderer Institutionen einen neuen Rahmen vor, um eine hochauflösende Darstellung städtischer (Ubran-)Szenen unter Berücksichtigung der Recheneffizienz zu erreichen für CVPR 2023. Die Studie verwendet eine kompakte, mehrfach auflösende Boden-Feature-Plane-Darstellung, um die Szene grob zu erfassen, und ergänzt sie mit positionscodierten Eingaben über ein NeRF-Zweignetzwerk, um sie auf gemeinsam erlernte Weise zu rendern. Dieser Ansatz vereint die Vorteile der beiden Ansätze: Unter der Führung der Feature-Grid-Darstellung reicht ein leicht gewichtetes NeRF aus, um eine realistische neue Perspektive mit Details darzustellen, die gemeinsam optimierte Boden-Feature-Ebene kann weiter verfeinert werden, um eine genauere und genauere Darstellung zu erzielen Detaillierter kompakter Funktionsraum, Ausgabe natürlicherer Rendering-Ergebnisse.

- Papieradresse: https://arxiv.org/pdf/2303.14001.pdf
- Projekthomepage: https://city-super.github.io/ gridnerf/
Das Bild unten zeigt Beispielergebnisse der Forschungsmethode in der realen Ubran-Szene und bietet den Menschen ein immersives Stadt-Roaming-Erlebnis:

Einführung in die Methode
Um Implizite neuronale Funktionen effektiv nutzen Um die Rekonstruktion großräumiger städtischer Szenen darzustellen, schlägt diese Studie eine Dual-Branche-Modellarchitektur vor, die eine einheitliche Szenendarstellung verwendet, die explizite Voxelgitter-basierte und implizite basierte NeRF-Methoden integriert ergänzen sich gegenseitig.
Die Zielszene wird zunächst in der Vortrainingsphase mithilfe eines Feature-Mesh modelliert, um die Geometrie und das Erscheinungsbild der Szene grob zu erfassen. Anschließend wird ein grobes Merkmalsgitter verwendet, um 1) die NeRF-Punktabtastung so zu steuern, dass sie um die Szenenoberfläche konzentriert ist, und 2) die Positionskodierung von NeRF mit zusätzlichen Merkmalen über die Szenengeometrie und das Erscheinungsbild an den abgetasteten Orten zu versorgen. Mit einer solchen Führung kann NeRF effizienter feinere Details in einem stark komprimierten Abtastraum erfassen. Da darüber hinaus grobe Geometrie- und Aussehensinformationen explizit für NeRF bereitgestellt werden, reicht ein leichter MLP aus, um die Zuordnung von globalen Koordinaten zu Volumendichte- und Farbwerten zu erlernen. In einer zweiten gemeinsamen Lernphase wird das grobe Merkmalsnetz über Gradienten aus dem NeRF-Zweig weiter optimiert und normalisiert, was bei alleiniger Anwendung zu genaueren und natürlicheren Rendering-Ergebnissen führt.
Der Kern dieser Forschung ist eine neue Doppelzweigstruktur, nämlich der Grid-Zweig und der NeRF-Zweig. 1) Die Forscher erfassten zunächst die Pyramidenszene der Merkmalsebene in der Vortrainingsphase, tasteten die Strahlpunkte grob durch einen flachen MLP-Renderer (Gitterzweig) ab und sagten ihre Strahlungswerte durch volumenintegriertes MSE auf dem Pixel vorher Farbverlustüberwachung. Dieser Schritt generiert einen informationsreichen Satz von Dichte-/Erscheinungsmerkmalsebenen mit mehreren Auflösungen. 2) Als nächstes treten die Forscher in die gemeinsame Lernphase ein und führen eine verfeinerte Stichprobe durch. Die Forscher nutzten das erlernte Merkmalsraster, um die NeRF-Zweigstichprobe so zu steuern, dass sie sich auf Szenenoberflächen konzentrierte. Die Gittereigenschaften der Abtastpunkte werden durch bilineare Interpolation auf der Merkmalsebene abgeleitet. Diese Merkmale werden dann mit der Positionskodierung verkettet und in den NeRF-Zweig eingespeist, um volumetrische Dichte und Farbe vorherzusagen. Beachten Sie, dass während des gemeinsamen Trainings die Ausgabe des Rasterzweigs weiterhin mithilfe von Ground-Truth-Bildern sowie feinen Rendering-Ergebnissen aus dem NeRF-Zweig überwacht wird.
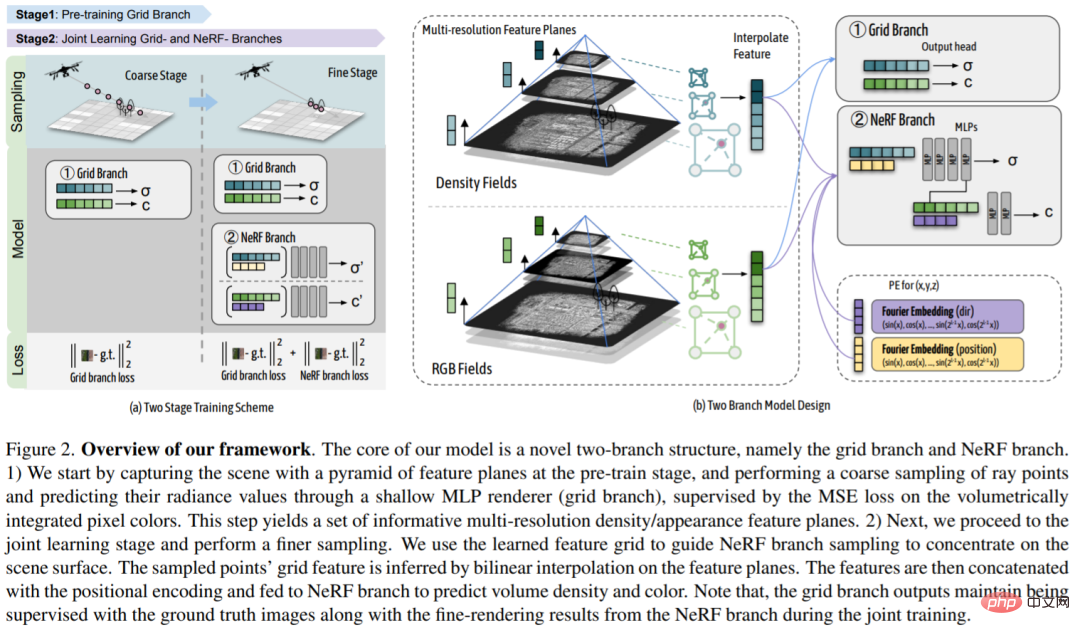
Zielszenario: In dieser Arbeit verwendet die Studie ein neuartiges gittergeführtes neuronales Strahlungsfeld, um eine groß angelegte Darstellung städtischer Szenen durchzuführen. Die linke Seite des Bildes unten zeigt ein Beispiel einer großen städtischen Szene, die sich über eine 2,7 km² große Bodenfläche erstreckt und mit über 5.000 Drohnenbildern aufgenommen wurde. Studien haben gezeigt, dass NeRF-basierte Methoden verschwommene und übermäßig geglättete Ergebnisse liefern und über eine begrenzte Modellkapazität verfügen, während eigengitterbasierte Methoden bei der Anpassung an große Szenen mit hochauflösenden Eigengittern tendenziell verrauschte Artefakte zeigen. Das in dieser Studie vorgeschlagene Dual-Branche-Modell kombiniert die Vorteile beider Methoden und erreicht durch erhebliche Verbesserungen gegenüber bestehenden Methoden eine realistische Darstellung neuartiger Ansichten. Beide Zweige erzielen erhebliche Verbesserungen gegenüber ihren jeweiligen Basislinien.

Experiment
Die Forscher berichteten über die Leistung der Basislinie und die Methode des Forschers in der Abbildung und Tabelle unten. Sowohl qualitativ als auch quantitativ. Hinsichtlich der visuellen Qualität und aller Kennzahlen sind deutliche Verbesserungen zu beobachten. Der Ansatz der Forscher offenbart schärfere Geometrien und feinere Details als rein MLP-basierte Methoden (NeRF und Mega-NeRF). Insbesondere aufgrund der begrenzten Kapazität und der spektralen Ausrichtung von NeRF ist es immer nicht in der Lage, schnelle Änderungen in Geometrie und Farbe zu simulieren, wie zum Beispiel Vegetation und Streifen auf einem Spielplatz. Obwohl die geografische Aufteilung der Szene in kleine Regionen, wie in der Mega-NeRF-Basislinie gezeigt, etwas hilft, scheinen die präsentierten Ergebnisse immer noch zu glatt zu sein. Im Gegenteil, basierend auf dem erlernten Merkmalsgitter wird der Abtastraum von NeRF in der Nähe der Szenenoberfläche effektiv und stark komprimiert. Dichte- und Erscheinungsmerkmale, die von der Bodenmerkmalsebene abgetastet werden, stellen explizit den Inhalt der Szene dar, wie in Abbildung 3 dargestellt. Obwohl weniger genau, liefert es bereits informative lokale Geometrie und Textur und unterstützt die Positionskodierung von NeRF, um fehlende Szenendetails zu erfassen.

Tabelle 1 unten zeigt die quantitativen Ergebnisse:
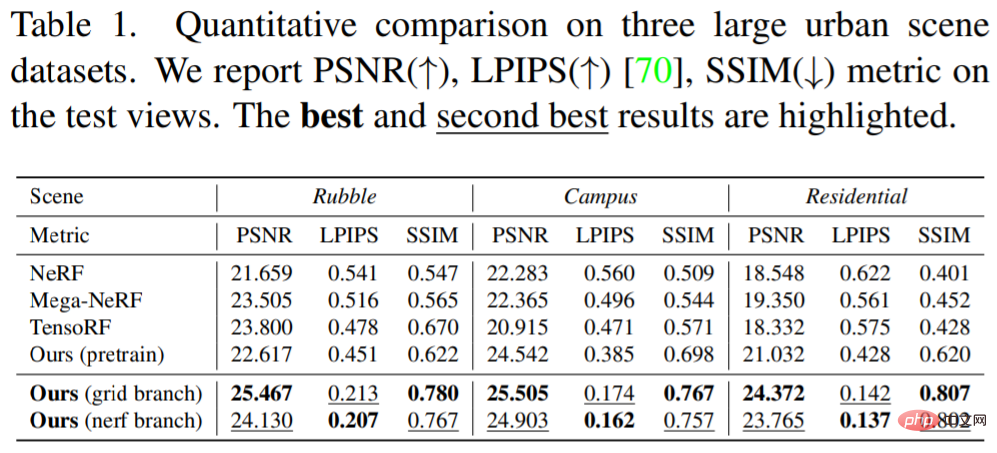
Abbildung 6 Eine schnelle Verbesserung der Wiedergabetreue ist zu beobachten:

Erfahren Sie mehr für Den Inhalt entnehmen Sie bitte dem Originalpapier.
Das obige ist der detaillierte Inhalt vonEffizientes und realistisches Stadtrendering in extrem großem Maßstab: Kombination von NeRF und Feature-Grid-Technologie. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr