
Heim >Technologie-Peripheriegeräte >KI >Wenn maschinelles Lernen beim autonomen Fahren implementiert wird, ist der Kern nicht das Modell, sondern die Pipeline
Wenn maschinelles Lernen beim autonomen Fahren implementiert wird, ist der Kern nicht das Modell, sondern die Pipeline

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-05 11:46:061512Durchsuche
Dieser Artikel wurde von Lei Feng.com reproduziert. Wenn Sie ihn erneut drucken möchten, besuchen Sie bitte die offizielle Website von Lei Feng.com, um eine Genehmigung zu beantragen.
Als ich meinen ersten Job nach dem College antrat, dachte ich, ich wüsste viel über maschinelles Lernen. Ich absolvierte zwei Praktika bei Pinterest und der Khan Academy zum Aufbau maschineller Lernsysteme. Während meines letzten Jahres in Berkeley forschte ich über Deep Learning für Computer Vision und arbeitete an Caffe, einer der ersten beliebten Deep-Learning-Bibliotheken. Nach meinem Abschluss bin ich einem kleinen Startup namens „Cruise“ beigetreten, das sich auf die Herstellung selbstfahrender Autos spezialisiert hat. Jetzt bin ich bei Aquarium und helfe Unternehmen dabei, Deep-Learning-Modelle einzusetzen, um wichtige soziale Probleme zu lösen.
Im Laufe der Jahre habe ich einen ziemlich coolen Deep-Learning- und Computer-Vision-Stack aufgebaut. Mittlerweile nutzen mehr Menschen Deep Learning in Produktionsanwendungen als zu der Zeit, als ich in Berkeley forschte. Viele der Probleme, mit denen sie jetzt konfrontiert sind, sind die gleichen, mit denen ich 2016 bei Cruise konfrontiert war. Ich habe viele Lektionen über Deep Learning in der Produktion gelernt, die ich mit Ihnen teilen möchte, und ich hoffe, dass Sie diese nicht auf die harte Tour lernen müssen.

Hinweis: Das Team des Autors entwickelt das erste Modell für maschinelles Lernen, das in einem Auto eingesetzt wird# 🎜🎜 #
1 Die Geschichte des Einsatzes von ML-Modellen in selbstfahrenden AutosLassen Sie mich zunächst über Cruises erstes ML-Modell sprechen, das in einem Auto eingesetzt wurde. Als wir das Modell entwickelten, fühlte sich der Arbeitsablauf sehr ähnlich an, wie ich ihn aus meiner Forschungszeit gewohnt war. Wir trainieren Open-Source-Modelle anhand von Open-Source-Daten, integrieren sie in den Produktsoftware-Stack des Unternehmens und stellen sie in Autos bereit. Nach einigen Wochen Arbeit haben wir die endgültige PR zusammengeführt und das Modell am Auto getestet. „Mission erfüllt!“ Ich dachte mir, wir sollten das nächste Feuer weiter löschen. Ich wusste nicht, dass die eigentliche Arbeit gerade erst begann. Das Modell wurde in Produktion genommen und unser QA-Team begann, Probleme mit seiner Leistung zu bemerken. Aber wir mussten andere Modelle bauen und andere Aufgaben erledigen, also haben wir uns nicht sofort mit diesen Problemen befasst. Als wir die Probleme drei Monate später untersuchten, stellten wir fest, dass alle Trainings- und Validierungsskripte fehlerhaft waren, weil sich die Codebasis seit unserer ersten Bereitstellung geändert hatte. Nach einer Woche voller Korrekturen haben wir uns die Ausfälle der letzten Monate angesehen und festgestellt, dass viele der bei Modellproduktionsläufen beobachteten Probleme nicht einfach durch eine Änderung des Modellcodes gelöst werden konnten und wir sie sammeln mussten und markieren Sie sie mit neuen Daten aus unseren Firmenfahrzeugen, anstatt sich auf Open-Source-Daten zu verlassen. Das bedeutet, dass wir einen Etikettierungsprozess einrichten müssen, einschließlich aller für den Prozess erforderlichen Tools, Abläufe und Infrastruktur. Weitere 3 Monate später ließen wir ein neues Modell laufen, das auf Daten trainiert wurde, die wir zufällig aus dem Auto ausgewählt hatten. Markieren Sie es dann mit unseren eigenen Werkzeugen. Aber wenn wir anfangen, einfache Probleme zu lösen, müssen wir kritischer darüber werden, welche Veränderungen voraussichtlich Konsequenzen haben werden. Etwa 90 % der Probleme werden durch sorgfältige Datenkuratierung schwieriger oder seltener Szenarien gelöst, und nicht durch tiefgreifende Änderungen der Modellarchitektur oder Optimierung von Hyperparametern. Wir haben beispielsweise festgestellt, dass das Modell an Regentagen eine schlechte Leistung erbringt (eine Seltenheit in San Francisco), also haben wir mehr Daten von Regentagen gekennzeichnet, das Modell anhand der neuen Daten neu trainiert und die Leistung des Modells verbessert. Ebenso haben wir festgestellt, dass das Modell bei grünen Kegelstümpfen (die im Vergleich zu orangefarbenen Kegelstümpfen seltener vorkommen) eine schlechte Leistung erbringt. Deshalb haben wir Daten zu grünen Kegelstümpfen gesammelt und den gleichen Prozess durchgeführt, wodurch sich die Leistung des Modells verbessert hat. Wir müssen einen Prozess etablieren, der diese Art von Problemen schnell erkennen und lösen kann. Es dauerte ein paar Wochen, die 1.0-Version dieses Modells zusammenzubauen, und es dauerte weitere 6 Monate, um eine neue und verbesserte Version des Modells auf den Markt zu bringen. Da wir immer mehr an verschiedenen Aspekten arbeiten (bessere Kennzeichnungsinfrastruktur, Cloud-Datenverarbeitung, Schulungsinfrastruktur, Bereitstellungsüberwachung), schulen wir Modelle etwa jeden Monat bis jede Woche neu und stellen sie erneut bereit. Während wir weitere Modellpipelines von Grund auf erstellen und an deren Verbesserung arbeiten, erkennen wir einige gemeinsame Themen. Durch die Anwendung unserer Erkenntnisse auf neue Pipelines wurde es einfacher, bessere Modelle schneller und mit weniger Aufwand auszuführen. 2 Lerne iterativ weiter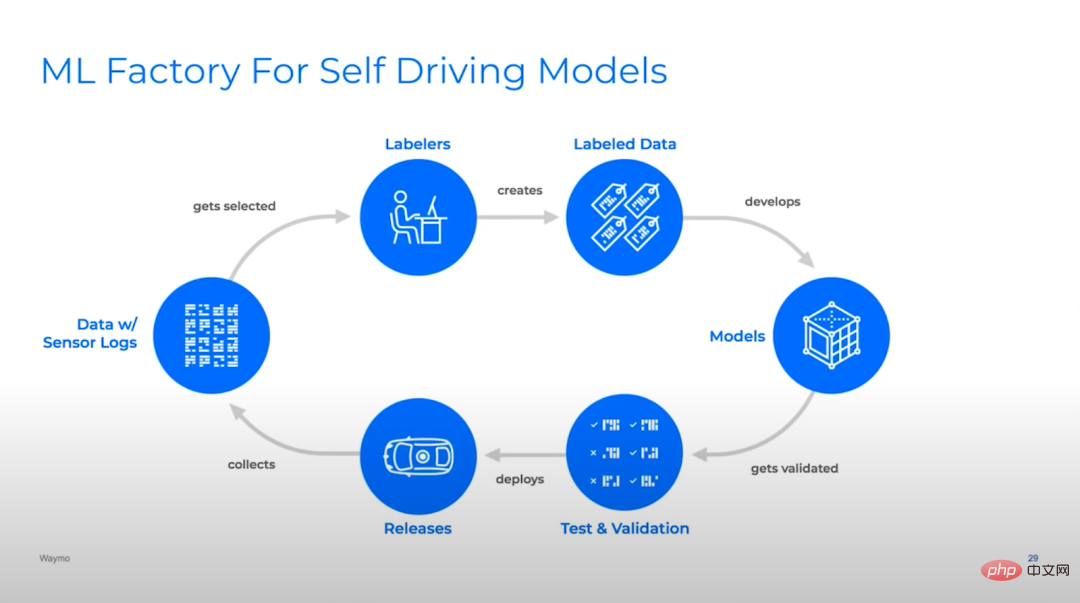
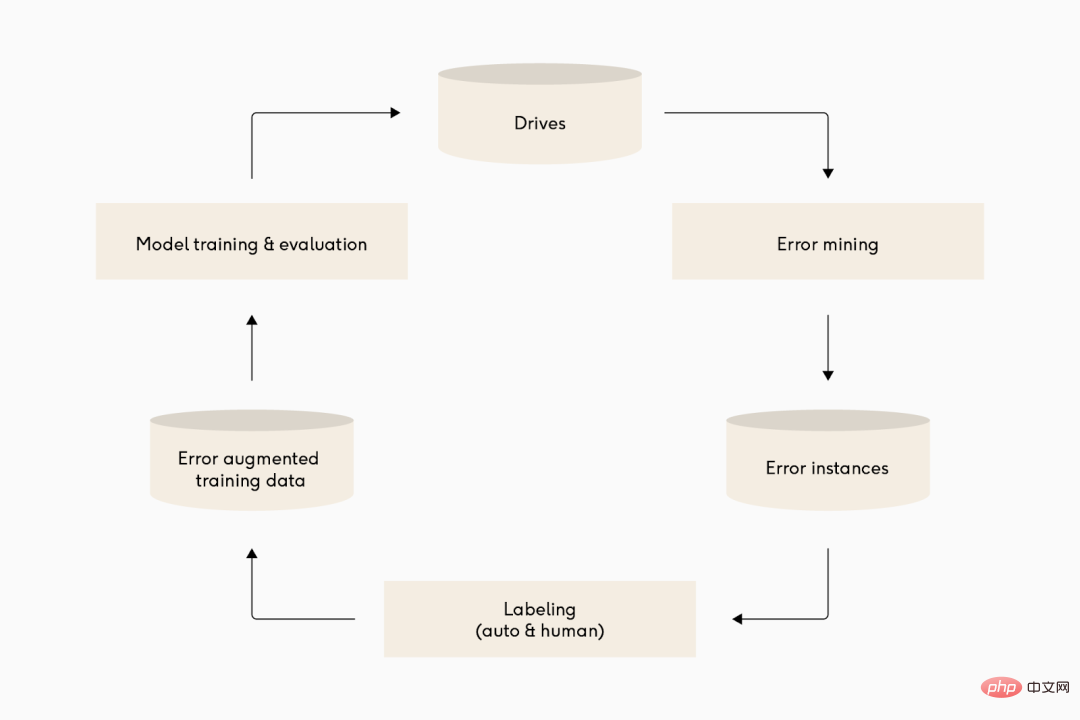
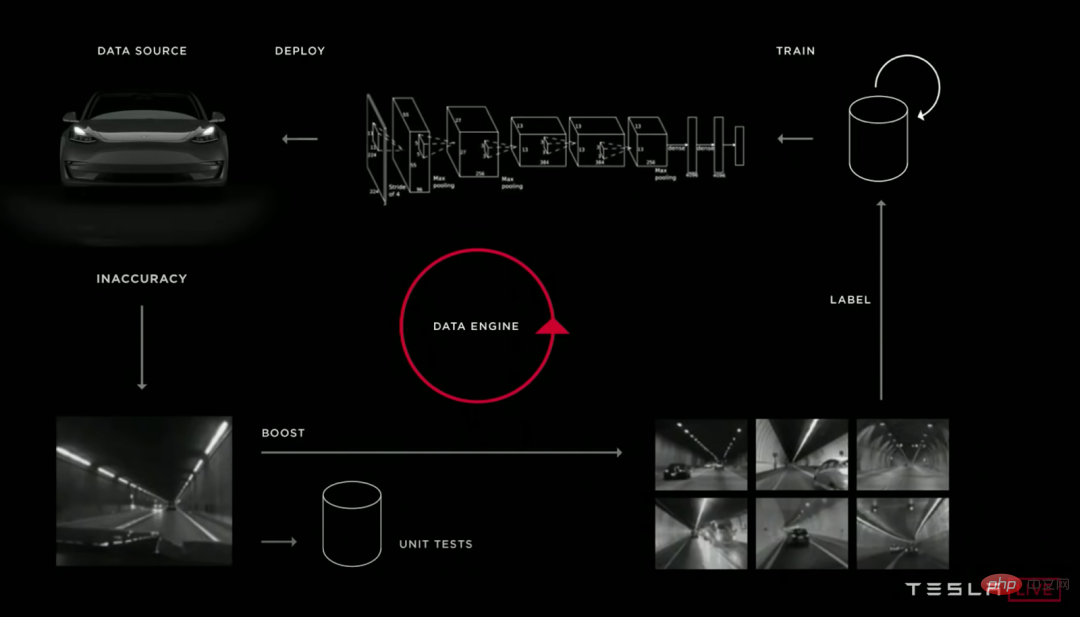
Bildunterschrift: Viele verschiedene Deep-Learning-Teams für autonomes Fahren haben recht ähnliche Iterationszyklen ihrer Modellpipelines. Von oben nach unten: Waymo, Cruise und Tesla.
Früher dachte ich, dass es beim maschinellen Lernen hauptsächlich um Modelle geht. Tatsächlich ist maschinelles Lernen in der industriellen Produktion größtenteils eine Pipeline. Einer der besten Erfolgsindikatoren ist die Fähigkeit, die Modellpipeline effizient zu iterieren. Das bedeutet nicht nur, schnell zu iterieren, sondern auch, intelligent zu iterieren, und der zweite Teil ist entscheidend, sonst wird Ihre Pipeline sehr schnell schlechte Modelle produzieren.
Die meisten herkömmlichen Softwareprogramme legen Wert auf schnelle Iteration und agile Bereitstellungsprozesse, da Produktanforderungen unbekannt sind und durch Anpassung ermittelt werden müssen. Daher ist es besser, schnell ein MVP bereitzustellen und fortzufahren, anstatt in der frühen Phase eine detaillierte Planung vorzunehmen Iterieren.
So wie herkömmliche Softwareanforderungen komplex sind, ist auch der Bereich der Dateneingabe, mit dem maschinelle Lernsysteme umgehen müssen, wirklich riesig. Im Gegensatz zur normalen Softwareentwicklung hängt die Qualität eines maschinellen Lernmodells von seiner Implementierung im Code und den Daten ab, auf denen der Code basiert. Diese Abhängigkeit von Daten bedeutet, dass das Modell für maschinelles Lernen die Eingabedomäne durch die Erstellung/Verwaltung von Datensätzen „erkunden“ kann, sodass es die Aufgabenanforderungen verstehen und sich im Laufe der Zeit daran anpassen kann, ohne den Code ändern zu müssen.
Um diese Funktion nutzen zu können, erfordert maschinelles Lernen ein Konzept des kontinuierlichen Lernens, bei dem die Iteration von Daten und Code im Vordergrund steht. Teams für maschinelles Lernen müssen:
- Probleme bei der Daten- oder Modellleistung entdecken
- diagnostizieren, warum Probleme auftreten
- Daten oder Modellcode ändern, um sie zu beheben
- überprüfen, ob Modelle nach dem erneuten Training besser werden
- neue Modelle bereitstellen und wiederholen
Teams sollten versuchen, diesen Zyklus mindestens jeden Monat zu durchlaufen. Wenn du gut bist, mach es vielleicht jede Woche.
Große Unternehmen können einen Modellbereitstellungszyklus in weniger als einem Tag abschließen, aber der schnelle und automatische Aufbau einer Infrastruktur ist für die meisten Teams sehr schwierig. Wenn das Modell seltener aktualisiert wird, kann es zu Codebeschädigungen (die Modellpipeline wird aufgrund von Änderungen in der Codebasis unterbrochen) oder zu einer Verschiebung der Datendomäne (das Modell in der Produktion kann sich nicht auf Änderungen in den Daten im Laufe der Zeit verallgemeinern) führen.
Große Unternehmen können einen Modellbereitstellungszyklus an einem Tag abschließen, aber für die meisten Teams ist es sehr schwierig, die Infrastruktur schnell und automatisch aufzubauen. Eine seltenere Aktualisierung des Modells kann zu einer Codebeschädigung (die Modellpipeline ist aufgrund von Änderungen in der Codebasis unterbrochen) oder einer Datendomänenverschiebung (das Modell in der Produktion kann sich nicht auf Änderungen in den Daten im Laufe der Zeit verallgemeinern) führen.
Wenn es jedoch richtig gemacht wird, kann das Team in einen guten Rhythmus kommen und das verbesserte Modell in der Produktion einsetzen.
3 Rückkopplungsschleifen aufbauen
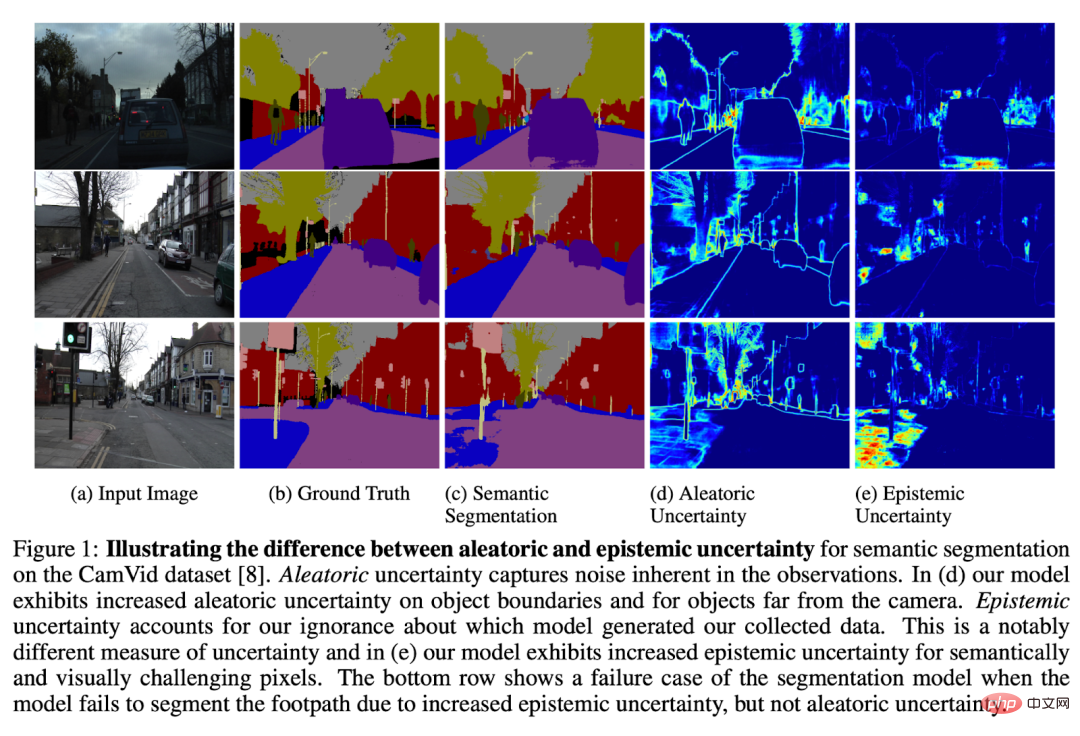
Die Kalibrierung der Modellunsicherheit ist ein verlockender Forschungsbereich, in dem das Modell markieren kann, wo es seiner Meinung nach scheitern könnte.
Ein wichtiger Teil der effektiven Iteration an einem Modell besteht darin, sich auf die Lösung der wirkungsvollsten Probleme zu konzentrieren. Um ein Modell zu verbessern, müssen Sie wissen, was daran falsch ist, und in der Lage sein, die Probleme nach Produkt-/Geschäftsprioritäten zu kategorisieren. Es gibt viele Möglichkeiten, Feedbackschleifen aufzubauen, aber am Anfang steht das Finden und Klassifizieren von Fehlern.
Nutzen Sie domänenspezifische Feedbackschleifen.
Wenn überhaupt, kann dies eine sehr wirkungsvolle und effektive Möglichkeit sein, Feedback zu Ihrem Modell zu erhalten. Beispielsweise können Vorhersageaufgaben „kostenlos“ gekennzeichnete Daten erhalten, indem sie auf historischen Daten tatsächlicher Ereignisse trainieren, sodass sie kontinuierlich mit großen Mengen neuer Daten gefüttert werden und sich ziemlich automatisch an neue Situationen anpassen können.
Richten Sie einen Workflow ein, der es den Leuten ermöglicht, die Ausgabe Ihres Modells zu überprüfen und Fehler zu kennzeichnen, wenn sie auftreten.
Dieser Ansatz ist besonders nützlich, wenn man durch viele Modellinferenzen leicht Fehler erkennen kann. Dies geschieht am häufigsten, wenn ein Kunde einen Fehler in der Modellausgabe bemerkt und sich beim Machine-Learning-Team beschwert. Dies ist nicht zu unterschätzen, da Sie über diesen Kanal Kundenfeedback direkt in den Entwicklungszyklus einfließen lassen können! Ein Team könnte Menschen die Modellausgaben noch einmal überprüfen lassen, die Kunden möglicherweise übersehen haben: Stellen Sie sich vor, ein Bediener beobachtet einen Roboter, der Pakete auf einem Förderband sortiert, und klickt auf eine Schaltfläche, wenn ein Fehler auftritt.
Richten Sie einen Workflow ein, in dem Benutzer die Ausgabe Ihres Modells überprüfen und auftretende Fehler kennzeichnen können. Dies ist insbesondere dann sinnvoll, wenn Fehler in einer großen Anzahl von Modellinferenzen durch eine menschliche Überprüfung leicht erkannt werden. Der häufigste Weg ist, wenn ein Kunde einen Fehler in der Modellausgabe bemerkt und sich beim ML-Team beschwert. Dies sollte nicht unterschätzt werden, da Sie über diesen Kanal Kundenfeedback direkt in den Entwicklungszyklus einbeziehen können. Ein Team kann Menschen die Modellergebnisse überprüfen lassen, die Kunden möglicherweise übersehen haben: Stellen Sie sich einen Bediener vor, der einem Roboter beim Sortieren von Paketen auf einem Förderband zusieht. Klicken Sie jedes Mal auf eine Schaltfläche, wenn ein Fehler auftritt.
Erwägen Sie die Einrichtung einer automatischen Überprüfung, wenn das Modell zu häufig ausgeführt wird, als dass es von Menschen überprüft werden könnte.
Dies ist besonders nützlich, wenn es einfach ist, „Sanity Checks“ anhand der Modellausgabe zu schreiben. Markieren Sie beispielsweise jedes Mal, wenn der Lidar-Objektdetektor und der 2D-Bildobjektdetektor inkonsistent sind oder der Frame-to-Frame-Detektor nicht mit dem zeitlichen Trackingsystem übereinstimmt. Wenn es funktioniert, liefert es viele nützliche Rückmeldungen und sagt uns, wo Fehlerbedingungen auftreten. Wenn es nicht funktioniert, werden nur Fehler in Ihrem Prüfsystem aufgedeckt oder es werden immer Fehler im System erkannt, was ein sehr geringes Risiko und einen hohen Nutzen darstellt.
Die allgemeinste (aber schwierigste) Lösung besteht darin, die Modellunsicherheit der Daten zu analysieren, auf denen es ausgeführt wird.
Ein einfaches Beispiel besteht darin, sich Beispiele von Modellen anzusehen, die in der Produktion Ergebnisse mit geringer Konfidenz erzeugen. Dies kann zeigen, dass das Modell zwar unsicher, aber nicht 100 % genau ist. Manchmal kann ein Modell getrost falsch liegen. Manchmal sind Modelle unbestimmt, weil Informationen für eine gute Schlussfolgerung fehlen (z. B. verrauschte Eingabedaten, die für Menschen schwer zu verstehen sind). Es gibt Modelle, die sich mit diesen Problemen befassen, aber dies ist ein aktives Forschungsgebiet.
Abschließend kann das Feedback des Modells zum Trainingssatz genutzt werden.
Zum Beispiel weist die Überprüfung auf Inkonsistenzen zwischen einem Modell und seinem Trainings-/Validierungsdatensatz (d. h. Beispiele mit hohem Verlust) auf Fehler mit hoher Zuverlässigkeit oder eine falsche Kennzeichnung hin. Die Einbettungsanalyse neuronaler Netze kann eine Möglichkeit bieten, das Muster von Fehlermodi im Trainings-/Validierungsdatensatz zu verstehen und Unterschiede in der Rohdatenverteilung im Trainingsdatensatz und im Produktionsdatensatz zu entdecken.

Abbildung: Die Zeit der meisten Menschen lässt sich leicht von einem typischen Umschulungszyklus entfernen. Auch wenn dies mit einer weniger effizienten Maschinenzeit verbunden ist, entfällt dadurch eine Menge manueller Aufwand.
Das Wichtigste zur Beschleunigung der Iteration besteht darin, den Arbeitsaufwand für den Abschluss eines Iterationszyklus zu reduzieren. Es gibt jedoch immer Möglichkeiten, die Dinge einfacher zu machen. Daher müssen Sie Prioritäten setzen, was Sie verbessern möchten. Ich betrachte Anstrengung gerne auf zwei Arten: als Uhrzeit und als menschliche Zeit.
Uhrzeit bezieht sich auf die Zeit, die zum Ausführen bestimmter Rechenaufgaben erforderlich ist, z. B. ETL von Daten, Trainingsmodelle, Ausführen von Inferenzen, Berechnen von Metriken usw. Unter menschlicher Zeit versteht man die Zeit, die ein Mensch aktiv eingreifen muss, um die Pipeline zu durchlaufen, z. B. manuell Ergebnisse zu prüfen, Befehle auszuführen oder Skripte mitten in der Pipeline auszulösen.
Zum Beispiel müssen mehrere Skripte manuell nacheinander ausgeführt werden, indem Dateien manuell zwischen den Schritten verschoben werden, was sehr häufig vorkommt, aber verschwenderisch ist. Eine kleine Mathematikrechnung: Wenn ein Ingenieur für maschinelles Lernen 90 US-Dollar pro Stunde kostet und zwei Stunden pro Woche damit verschwendet, Skripte manuell auszuführen, summiert sich das auf 9.360 US-Dollar pro Person und Jahr!
Durch die Kombination mehrerer Skripte und menschlicher Interrupts in einem vollautomatischen Skript wird die Ausführung einer Modell-Pipeline-Schleife schneller und einfacher, was eine Menge Geld spart und Ihre Machine-Learning-Ingenieure weniger verrückt macht.
Im Gegensatz dazu muss die Uhrzeit normalerweise „angemessen“ sein (z. B. über Nacht möglich). Die einzigen Ausnahmen bestehen, wenn Ingenieure für maschinelles Lernen umfangreiche Experimente durchführen oder wenn extreme Kosten-/Skalierungsbeschränkungen bestehen. Dies liegt daran, dass die Uhrzeit im Allgemeinen proportional zur Datengröße und Modellkomplexität ist. Beim Übergang von der lokalen Verarbeitung zur verteilten Cloud-Verarbeitung wird die Taktzeit erheblich verkürzt. Danach löst die horizontale Skalierung in der Cloud für die meisten Teams tendenziell die meisten Probleme, bis das Problem größer wird.
Leider ist es nicht möglich, einige Aufgaben vollständig zu automatisieren. Bei fast allen Produktionsanwendungen für maschinelles Lernen handelt es sich um überwachte Lernaufgaben, und die meisten sind auf ein gewisses Maß an menschlicher Interaktion angewiesen, um dem Modell mitzuteilen, was es tun soll. In einigen Bereichen ist die Mensch-Computer-Interaktion kostenlos (z. B. Anwendungsfälle für Social-Media-Empfehlungen oder andere Anwendungen mit großen Mengen an direktem Benutzer-Feedback). In anderen Fällen ist die menschliche Zeit begrenzter oder teurer, beispielsweise wenn ausgebildete Radiologen CT-Scans als Trainingsdaten „kennzeichnen“.
In jedem Fall ist es wichtig, die Arbeitszeit und andere Kosten zu minimieren, die zur Verbesserung des Modells erforderlich sind. Während sich frühe Teams bei der Verwaltung von Datensätzen möglicherweise auf Ingenieure für maschinelles Lernen verlassen, ist es häufig wirtschaftlicher (oder im Fall von Radiologen notwendig), die schwere Arbeit der Datenverwaltung einem operativen Benutzer oder Fachexperten ohne Kenntnisse im Bereich maschinelles Lernen zu überlassen. . An diesem Punkt wird es wichtig, einen betrieblichen Prozess zum Kennzeichnen, Überprüfen, Verbessern und Versionieren von Datensätzen mithilfe guter Softwaretools zu etablieren.
5 Ermutigen Sie ML-Ingenieure, fit zu werden 🎜🎜#
Abbildung: Wenn ML-Ingenieure Gewichte heben, erhöhen sie auch das Gewicht ihres Modelllernens# 🎜🎜#
Der Aufbau ausreichender Tools zur Unterstützung einer neuen Domain oder einer neuen Benutzergruppe kann viel Zeit und Mühe kosten, aber wenn es gut gemacht wird, werden sich die Ergebnisse durchaus lohnen. Einer meiner Ingenieure bei Cruise war besonders schlau (manche würden sagen, faul).
Dieser Ingenieur richtete eine iterative Schleife ein, in der eine Kombination aus betrieblichem Feedback und Metadatenabfragen Daten zur Kennzeichnung extrahierte, wenn die Modellleistung schlecht war. Anschließend beschriftet ein Team von Offshore-Betrieben die Daten und fügt sie einer neuen Version des Trainingsdatensatzes hinzu. Anschließend richteten die Ingenieure eine Infrastruktur ein, die es ihnen ermöglichte, ein Skript auf ihrem Computer auszuführen und eine Reihe von Cloud-Aufgaben zu starten, um ein einfaches Modell anhand neu hinzugefügter Daten automatisch neu zu trainieren und zu validieren.
Jede Woche führen sie das Umschulungsskript aus. Während das Modell trainierte und sich selbst validierte, gingen sie ins Fitnessstudio. Nach ein paar Stunden Fitness und Abendessen kamen sie zurück, um die Ergebnisse zu überprüfen. Zufälligerweise führen neue und verbesserte Daten zu Verbesserungen am Modell, und nach einer kurzen Doppelprüfung, um sicherzustellen, dass alles Sinn macht, wird das neue Modell dann in die Produktion geschickt und das Fahrverhalten des Autos wird sich verbessern. Anschließend verbrachten sie eine Woche damit, die Infrastruktur zu verbessern, mit neuen Modellarchitekturen zu experimentieren und neue Modellpipelines zu bauen. Dieser Ingenieur wurde am Ende des Quartals nicht nur befördert, er war auch in hervorragender Verfassung.
6 Fazit
Zusammenfassend: Während der Forschungs- und Prototyping-Phase liegt der Schwerpunkt auf dem Aufbau und der Veröffentlichung eines Modells. Wenn ein System jedoch in Produktion geht, besteht die Kernaufgabe darin, ein System aufzubauen, das mit minimalem Aufwand regelmäßig verbesserte Modelle veröffentlichen kann. Je besser Sie darin werden, desto mehr Modelle können Sie bauen!
Dazu müssen wir uns auf Folgendes konzentrieren:
- Lassen Sie die Modellpipeline in regelmäßigen Abständen laufen und konzentrieren Sie sich darauf, das Versandmodell besser als zuvor zu machen. Bringen Sie jede Woche oder weniger ein neues und verbessertes Modell in Produktion!
- Etablieren Sie eine gute Feedbackschleife von der Modellausgabe bis zum Entwicklungsprozess. Finden Sie heraus, bei welchen Beispielen das Modell schlecht abschneidet, und fügen Sie Ihrem Trainingsdatensatz weitere Beispiele hinzu.
- Automatisieren Sie besonders anspruchsvolle Aufgaben in Ihrer Pipeline und etablieren Sie eine Teamstruktur, die es Ihren Teammitgliedern ermöglicht, sich auf ihre Fachgebiete zu konzentrieren. Andrej Karpathy von Tesla nennt den idealen Endzustand „Operation Holiday“. Ich schlage vor, einen Workflow einzurichten, bei dem Ihre Machine-Learning-Ingenieure ins Fitnessstudio gehen und Ihre Machine-Learning-Pipeline die schwere Arbeit erledigen lassen!
Abschließend muss betont werden, dass meiner Erfahrung nach die meisten Probleme mit der Modellleistung mithilfe von Daten gelöst werden können, einige Probleme jedoch nur durch Änderung des Modellcodes gelöst werden können.
Diese Änderungen sind in der Regel sehr spezifisch für die jeweilige Modellarchitektur. Nachdem ich beispielsweise mehrere Jahre an Bildobjektdetektoren gearbeitet habe, habe ich zu viel Zeit damit verbracht, mir Gedanken über optimale vorherige Boxzuweisungen für bestimmte Ausrichtungsverhältnisse und die Verbesserung der Feature-Mapping-Auflösung zu machen kleine Gegenstände.
Da sich Transformers jedoch als Allround-Modellarchitekturtyp für viele verschiedene Deep-Learning-Aufgaben erweist, vermute ich, dass mehr dieser Techniken an Relevanz verlieren und sich der Schwerpunkt der maschinellen Lernentwicklung weiter auf die Verbesserung von Datensätzen verlagern wird.
Das obige ist der detaillierte Inhalt vonWenn maschinelles Lernen beim autonomen Fahren implementiert wird, ist der Kern nicht das Modell, sondern die Pipeline. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr