
Heim >Technologie-Peripheriegeräte >KI >Die Vorhersage der Gehirnhierarchie macht große Modelle effizienter!
Die Vorhersage der Gehirnhierarchie macht große Modelle effizienter!

- 王林nach vorne
- 2023-05-03 14:37:061802Durchsuche
100 Milliarden Neuronen, jedes Neuron hat etwa 8.000 Synapsen. Die komplexe Struktur des Gehirns inspiriert die Forschung im Bereich der künstlichen Intelligenz.
Derzeit ist die Architektur der meisten Deep-Learning-Modelle ein künstliches neuronales Netzwerk, das von biologischen Gehirnneuronen inspiriert ist.
Die Explosion generativer KI zeigt, dass Deep-Learning-Algorithmen beim Generieren, Zusammenfassen, Übersetzen und Klassifizieren von Texten immer leistungsfähiger werden.
Allerdings können diese Sprachmodelle immer noch nicht mit den menschlichen Sprachfähigkeiten mithalten.
Die prädiktive Codierungstheorie liefert eine vorläufige Erklärung für diesen Unterschied:
Obwohl Sprachmodelle benachbarte Wörter vorhersagen können, wird das menschliche Gehirn Wörter ständig über mehrere Zeitskalendarstellungsebenen hinweg vorhersagen.
Um diese Hypothese zu testen, analysierten Wissenschaftler von Meta AI die fMRT-Signale des Gehirns von 304 Personen, die Kurzgeschichten hörten.
Kommte zu dem Schluss, dass hierarchisches prädiktives Codieren eine entscheidende Rolle bei der Sprachverarbeitung spielt.
Unterdessen zeigt die Forschung, wie Synergien zwischen Neurowissenschaften und künstlicher Intelligenz die rechnerischen Grundlagen der menschlichen Kognition aufdecken können.
Die neuesten Forschungsergebnisse wurden in der Nature-Unterzeitschrift Nature Human Behavior veröffentlicht. Erwähnenswert ist, dass während des Experiments GPT-2 verwendet wurde ungewisse Zukunft Diese Forschung kann die ungeöffneten Modelle von OpenAI inspirieren.

Brain Predictive Coding Layered
In weniger als 3 Jahren hat Deep Learning dank eines gut trainierten Algorithmus erhebliche Fortschritte bei der Textgenerierung, Übersetzung usw. gemacht: Vorhersage von Wörtern basierend auf dem Kontext in der Nähe.
Bemerkenswert ist, dass sich die Aktivierung dieser Modelle linear auf die Reaktionen des Gehirns auf Sprache und Text auswirkt.
Darüber hinaus hängt diese Zuordnung in erster Linie von der Fähigkeit des Algorithmus ab, zukünftige Wörter vorherzusagen, was darauf hindeutet, dass dieses Ziel ausreicht, um zu gehirnähnlichen Berechnungen zu konvergieren.Allerdings besteht immer noch eine Lücke zwischen diesen Algorithmen und dem Gehirn: Trotz großer Mengen an Trainingsdaten stoßen aktuelle Sprachmodelle auf Herausforderungen bei der Generierung langer Geschichten, dem Zusammenfassen und kohärenten Dialog sowie dem Informationsabruf.
Weil der Algorithmus einige syntaktische Strukturen und semantische Eigenschaften nicht erfassen kann und auch das Verständnis der Sprache sehr oberflächlich ist.
Zum Beispiel neigen Algorithmen dazu, Verben in verschachtelten Phrasen fälschlicherweise Subjekten zuzuordnen. „Die Schlüssel, die der Mann hält, SIND hier“ in einer sich unendlich wiederholenden Schleife.
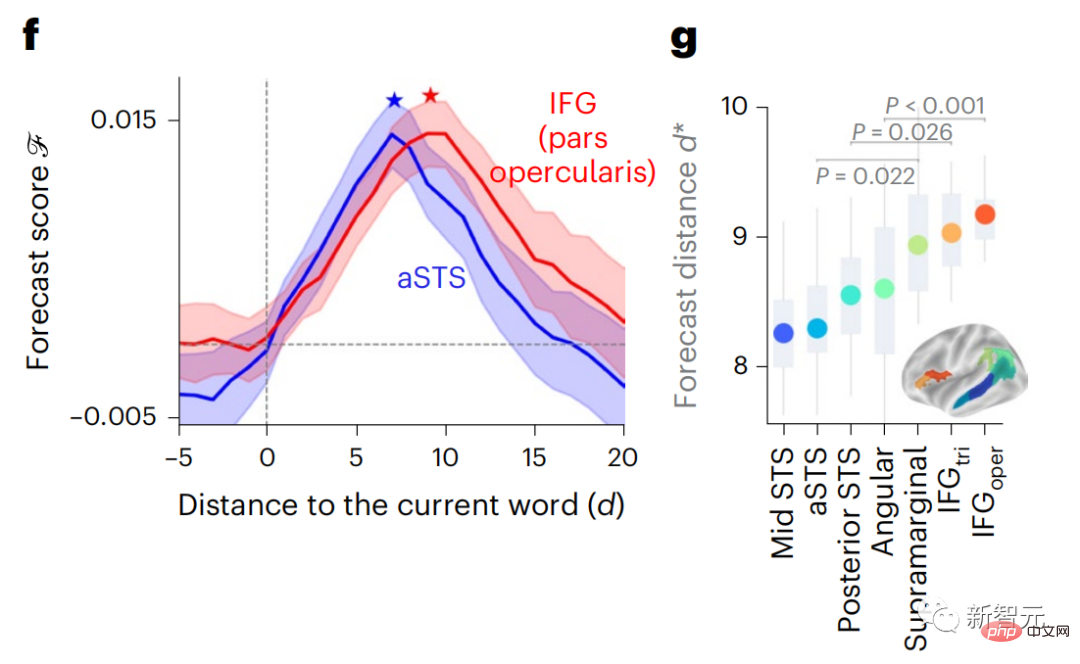
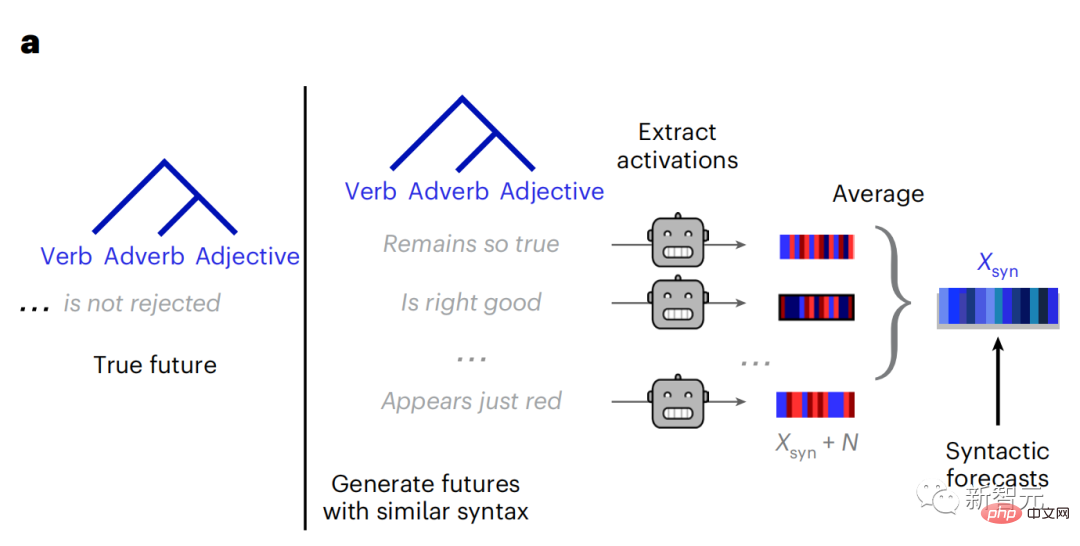
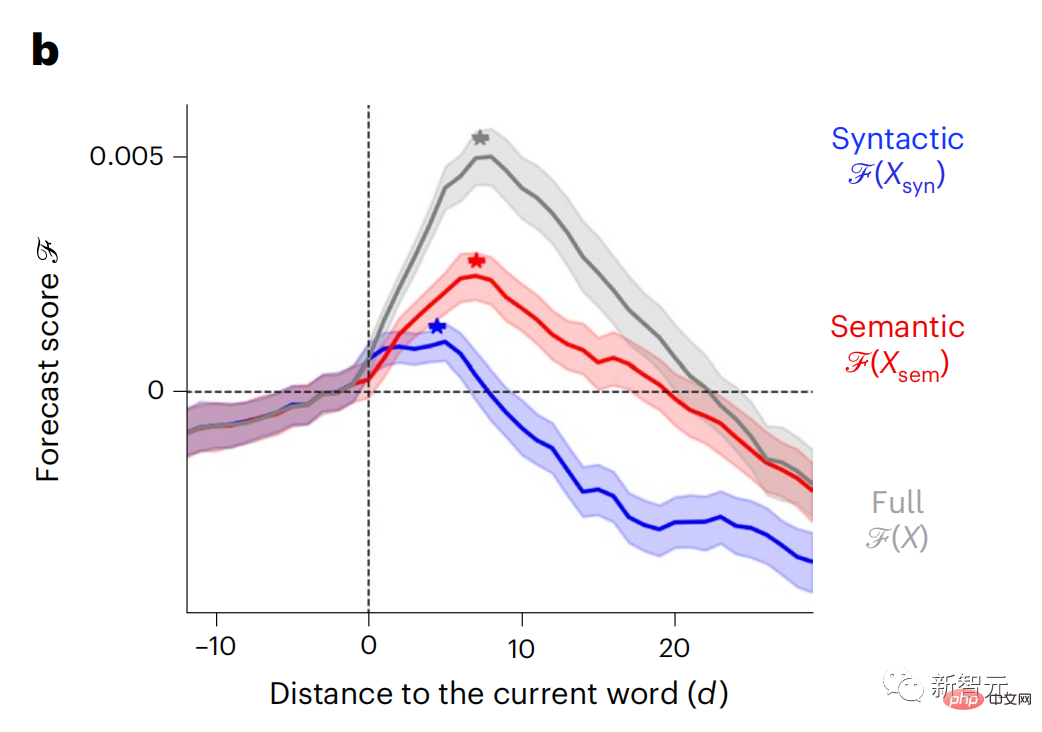
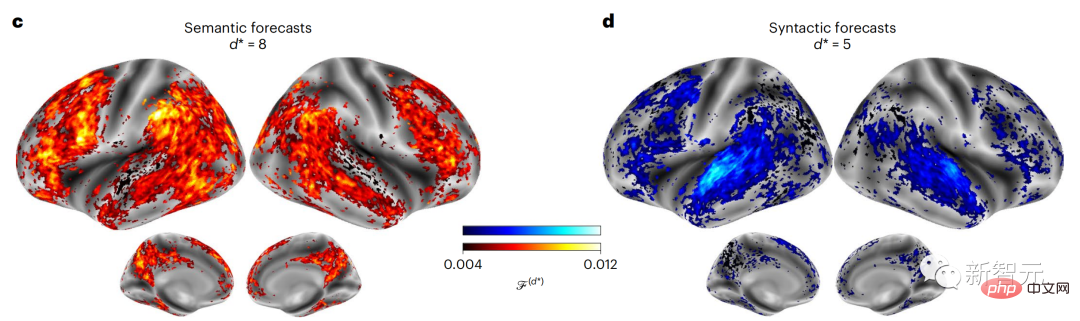
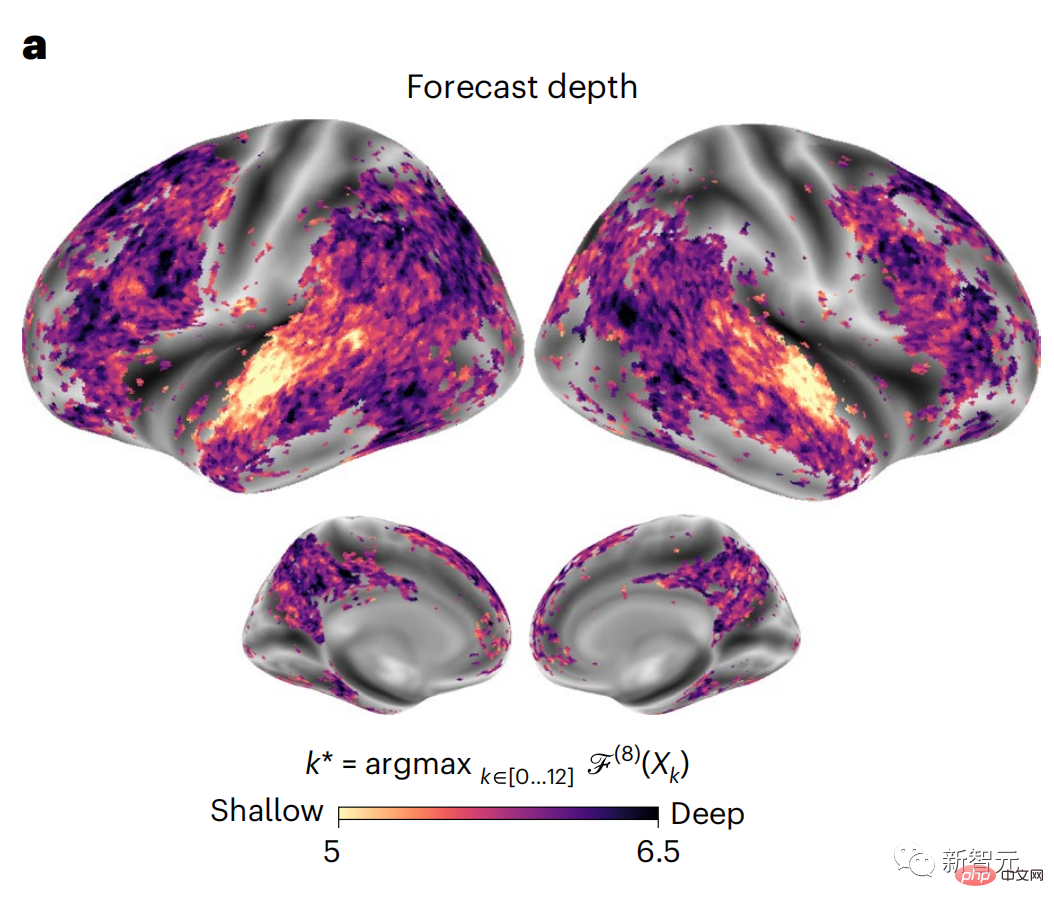
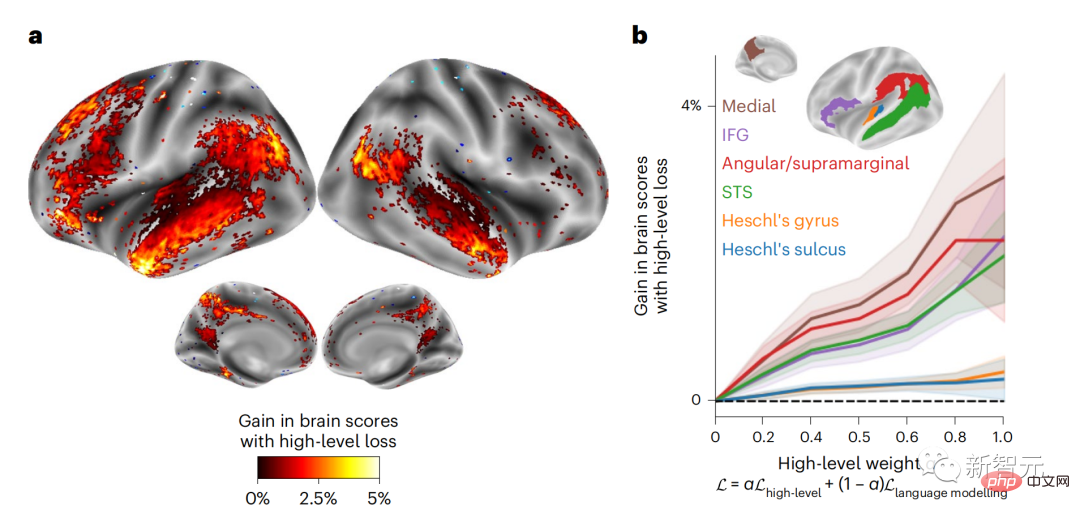
Derzeit liefert die prädiktive Codierungstheorie eine mögliche Erklärung für diesen Fehler: Während tiefe Sprachmodelle in erster Linie darauf ausgelegt sind, das nächste Wort vorherzusagen, zeigt dieses Framework, dass das menschliche Gehirn auf mehreren Zeitskalen und kortikal arbeiten kann Darstellungen auf -Ebene. Frühere Untersuchungen haben gezeigt, dass die Vorhersage von Sprache im Gehirn, also eines Wortes oder Phonems, mit funktioneller Magnetresonanztomographie (fMRT), Elektroenzephalographie, Magnetenzephalographie und Elektrokortikographie korreliert. Die Ausgabe eines Modells, das darauf trainiert ist, das nächste Wort oder Phonem vorherzusagen, kann auf eine einzelne Zahl reduziert werden, die Wahrscheinlichkeit des nächsten Symbols. Die Art und der Zeitrahmen prädiktiver Darstellungen sind jedoch weitgehend unbekannt. In dieser Studie extrahierten Forscher die fMRT-Signale von 304 Personen, baten jede Person, sich etwa 26 Minuten lang eine Kurzgeschichte (Y) anzuhören, und gaben denselben Inhalt ein, um den Sprachalgorithmus zu aktivieren ( X). Dann wird die Ähnlichkeit zwischen X und Y durch den „Brain Score“ quantifiziert, der der Pearson-Korrelationskoeffizient (R) nach der besten linearen Abbildung W ist. Um zu testen, ob das Hinzufügen einer Darstellung des vorhergesagten Wortes diese Korrelation verbessert, verbinden Sie die Aktivierung des Netzwerks (schwarzes Rechteck X) mit dem Vorhersagefenster (farbiges Rechteck ~X) und verwenden Sie dann PCA dazu Teilen Sie das Vorhersagefenster. Die Dimensionalität von wird auf die Dimensionalität von X reduziert. Abschließend quantifiziert F den Brain-Score-Gewinn, der durch die Verbesserung der Aktivierung dieses Vorhersagefensters durch den Sprachalgorithmus erzielt wird. Wir wiederholen diese Analyse (d) mit unterschiedlichen Distanzfenstern. Es wurde festgestellt, dass diese Gehirnkartierung verbessert werden könnte, indem diese Algorithmen mit Vorhersagen erweitert werden, die sich über mehrere Zeitskalen erstrecken, d. h. Vorhersagen mit großer Reichweite und hierarchische Vorhersagen. Abschließend ergaben experimentelle Ergebnisse, dass diese Vorhersagen hierarchisch organisiert sind: Der frontale Kortex sagt Darstellungen auf höherer Ebene, größerem Maßstab und mehr Kontext voraus als der temporale Kortex. Das Deep-Language-Modell wird der Gehirnaktivität zugeordnet Die Forscher untersuchten quantitativ die Ähnlichkeit zwischen dem Deep-Language-Modell und dem Gehirn, wenn der Eingabeinhalt derselbe ist. Anhand des Narratives-Datensatzes wurde die fMRT (funktionelle Magnetresonanztomographie) von 304 Personen analysiert, die Kurzgeschichten hörten. Führen Sie eine unabhängige lineare Ridge-Regression für die Ergebnisse für jedes Voxel und jedes experimentelle Individuum durch, um das fMRI-Signal vorherzusagen, das aus der Aktivierung mehrerer Deep-Language-Modelle resultiert. Anhand der gespeicherten Daten haben wir den entsprechenden „Brain Score“ berechnet, d. h. die Korrelation zwischen dem fMRI-Signal und den Ergebnissen der Ridge-Regressionsvorhersage, die durch Eingabe des angegebenen Sprachmodellstimulus erhalten wurden. Der Klarheit halber konzentrieren wir uns zunächst auf die Aktivierungen der achten Schicht von GPT-2, einem 12-schichtigen kausalen tiefen neuronalen Netzwerk, das von HuggingFace2 unterstützt wird und die Gehirnaktivität am besten vorhersagt. In Übereinstimmung mit früheren Studien wurden die Ergebnisse der GPT-2-Aktivierung genau auf einen verteilten Satz bilateraler Hirnregionen abgebildet, wobei die Gehirnwerte im auditorischen Kortex sowie in den vorderen und oberen Schläfenregionen ihren Höhepunkt erreichten. Das Meta-Team testete dann, ob eine zunehmende Stimulation eines Sprachmodells mit Fernvorhersagefähigkeiten zu höheren Hirnwerten führen könnte. Für jedes Wort verknüpften die Forscher die Modellaktivierung des aktuellen Wortes mit einem „Vorhersagefenster“, das aus zukünftigen Wörtern besteht. Zu den Darstellungsparametern des Vorhersagefensters gehören d, das den Abstand zwischen dem aktuellen Wort und dem letzten zukünftigen Wort im Fenster darstellt, und w, das die Anzahl der verketteten Wörter darstellt. Vergleichen Sie für jedes d die Gehirnwerte mit und ohne Vorhersagedarstellung und berechnen Sie den „Vorhersagewert“. Die Ergebnisse zeigen, dass der Vorhersagewert bei d=8 am höchsten ist und der Spitzenwert im Gehirnbereich auftritt, der mit der Sprachverarbeitung zusammenhängt. d=8 entspricht 3,15 Sekunden Audio, was der Zeit von zwei aufeinanderfolgenden fMRT-Scans entspricht. Die Vorhersagewerte waren im Gehirn bilateral verteilt, mit Ausnahme der Gyri inferior frontalis und supramarginalis. Durch ergänzende Analysen erhielt das Team außerdem die folgenden Ergebnisse: (1) Jedes zukünftige Wort mit einem Abstand von 0 bis 10 vom aktuellen Wort trägt erheblich zum Vorhersageergebnis bei um etwa 8 Vorhersagedarstellungen zu verwenden Die Fenstergröße des zu erfassenden Wortes (3) Die zufällige Vorhersagedarstellung kann den Gehirnwert nicht verbessern. (4) Im Vergleich zu echten zukünftigen Wörtern können mit GPT-2 generierte Wörter ähnliche Ergebnisse erzielen, jedoch mit niedrigeren Werten . Der vorhergesagte Zeitrahmen ändert sich entlang der Schichten des Gehirns Sowohl anatomische als auch funktionelle Studien haben gezeigt, dass die Großhirnrinde hierarchisch ist. Sind die Vorhersagezeitfenster für verschiedene Kortexebenen gleich? Die Forscher schätzten den Spitzenvorhersagewert jedes Voxels und drückten seinen entsprechenden Abstand als d aus. Die Ergebnisse zeigen, dass der d, der dem vorhergesagten Peak im präfrontalen Bereich entspricht, im Durchschnitt größer ist als der des Temporallappenbereichs (Abbildung 2e) und der d des unteren Temporalgyrus größer ist als der des oberen temporaler Sulcus. Die Variation des am besten vorhergesagten Abstands entlang der temporal-parietalen-frontalen Achse ist grundsätzlich symmetrisch über die beiden Gehirnhälften hinweg. Für jedes Wort und seinen vorhergehenden Kontext werden zehn mögliche zukünftige Wörter generiert, die der Syntax der realen zukünftigen Wörter entsprechen. Für jedes mögliche zukünftige Wort wird die entsprechende GPT-2-Aktivierung extrahiert und gemittelt. Dieser Ansatz ist in der Lage, eine gegebene Sprachmodellaktivierung in syntaktische und semantische Komponenten zu zerlegen und so deren jeweilige Vorhersagewerte zu berechnen. Die Ergebnisse zeigen, dass die semantische Vorhersage eine große Reichweite hat (d = 8) und ein verteiltes Netzwerk mit Spitzenwerten im Frontal- und Parietallappen beinhaltet, während die syntaktische Vorhersage eine kürzere Reichweite hat (d = 5). konzentriert sich auf die obere Schläfenregion und die linke Frontalregion. Diese Ergebnisse zeigen mehrere Ebenen der Vorhersage im Gehirn, wobei der obere temporale Kortex hauptsächlich kurzfristige, flache und syntaktische Darstellungen vorhersagt, während die unteren frontalen und parietalen Regionen hauptsächlich langfristige, kontextbezogene, hochstufige und semantische Darstellungen vorhersagen Darstellungen. Der vorhergesagte Hintergrund wird entlang der Gehirnhierarchie komplexer. Berechnung der Vorhersagebewertung immer noch wie zuvor, aber Änderung der Nutzungsebene von GPT-2, um k für jedes Voxel zu bestimmen, d. h. die Tiefe bei bei dem der Vorhersagewert maximiert ist. Unsere Ergebnisse zeigen, dass die optimale Vorhersagetiefe entlang der erwarteten kortikalen Hierarchie variiert, wobei der assoziative Kortex das beste Modell für tiefere Vorhersagen aufweist als Sprachbereiche auf niedrigerer Ebene. Die Unterschiede zwischen den Regionen sind zwar im Durchschnitt gering, bei verschiedenen Individuen jedoch sehr deutlich. Im Allgemeinen ist der Langzeitvorhersagehintergrund des Frontalkortex komplexer und höher als der Kurzzeitvorhersagehintergrund von Gehirnregionen auf niedriger Ebene. Passen Sie GPT-2 an eine prädiktive Codierungsstruktur an Die Verkettung der GPT-2-Darstellungen aktueller und zukünftiger Wörter kann zu besseren Gehirnaktivitätsmodellen führen, insbesondere im Frontalbereich. Kann die Feinabstimmung von GPT-2 zur Vorhersage von Darstellungen in größeren Entfernungen, mit umfassenderem Kontext und auf höheren Ebenen die Gehirnkartierung in diesen Regionen verbessern? Bei der Anpassung wird nicht nur die Sprachmodellierung verwendet, sondern auch Ziele auf hoher Ebene und mit großer Reichweite. Das Ziel auf hoher Ebene ist hier die 8. Schicht des vorab trainierten GPT-2-Modells. Die Ergebnisse zeigten, dass die Feinabstimmung von GPT-2 mit High-Level- und Long-Range-Modellierungspaaren die Reaktion des Frontallappens am besten verbesserte, während Hörbereiche und niedrigere Gehirnbereiche nicht von diesem Hoch profitierten -Targeting auf Ebene Der offensichtliche Vorteil spiegelt außerdem die Rolle der Frontalbereiche bei der Vorhersage weiträumiger, kontextueller und hochrangiger Darstellungen von Sprache wider. Referenz: https://www.php.cn/link/7eab47bf3a57db8e440e5a788467c37f. 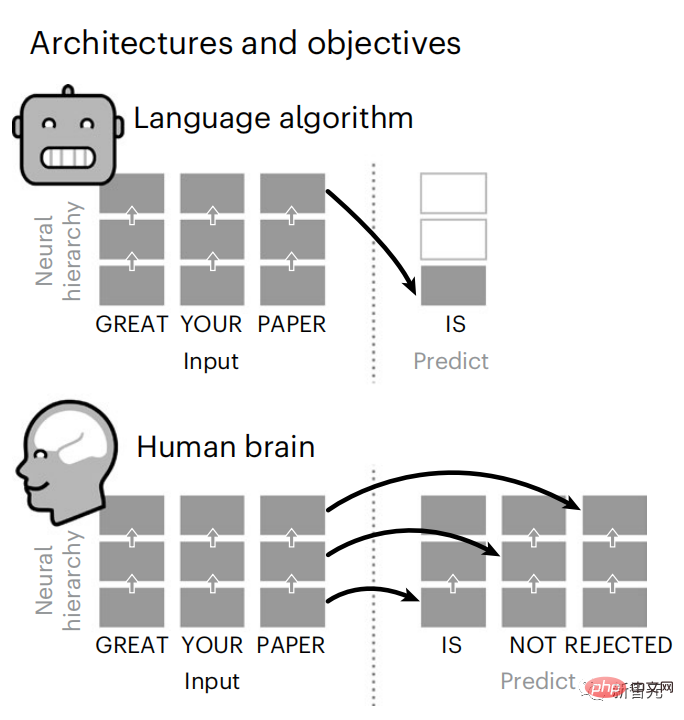
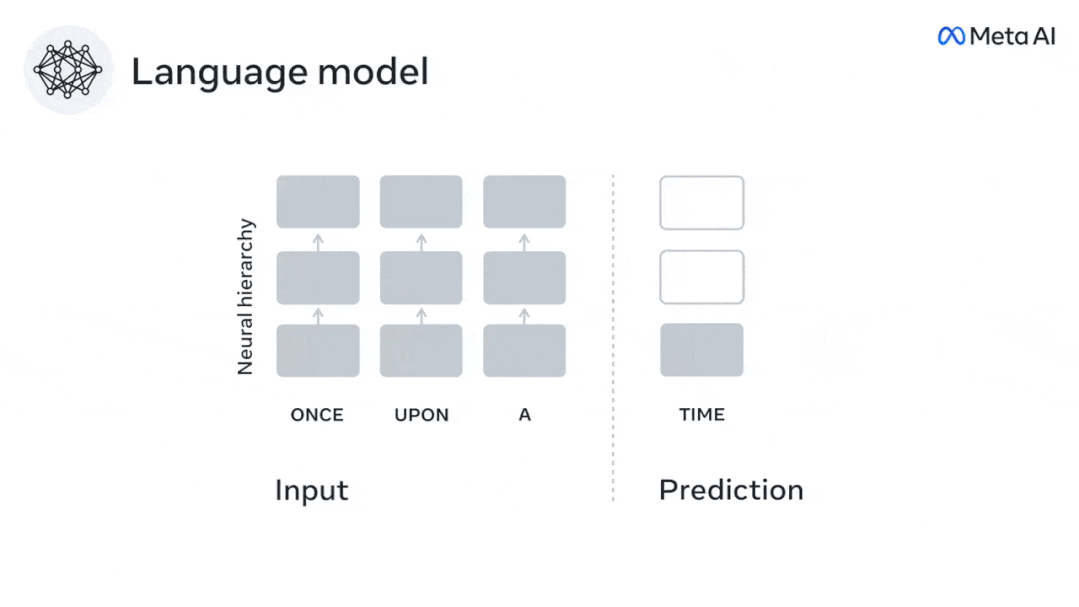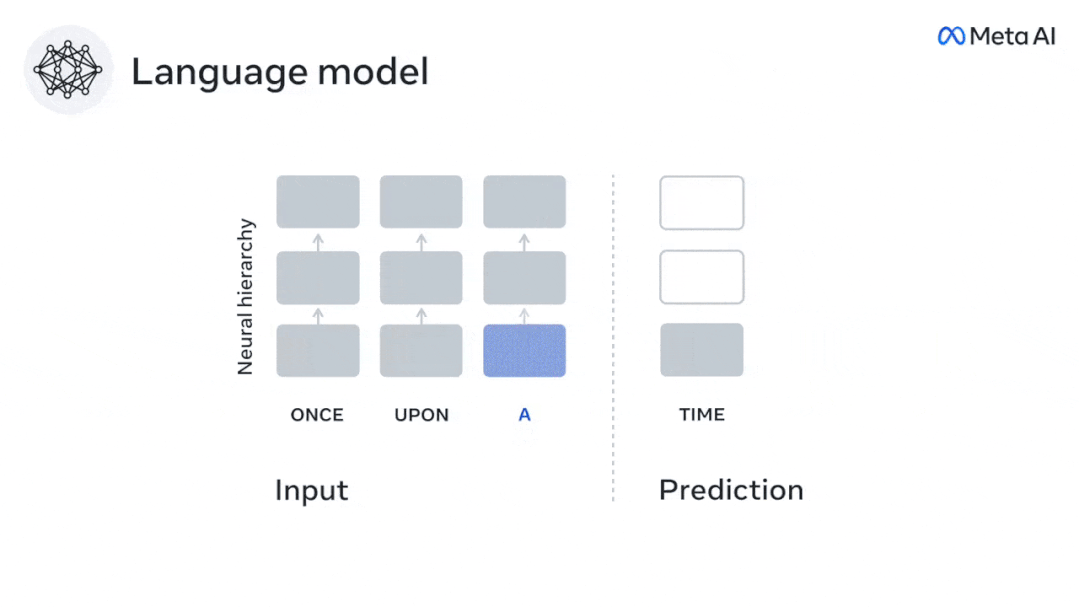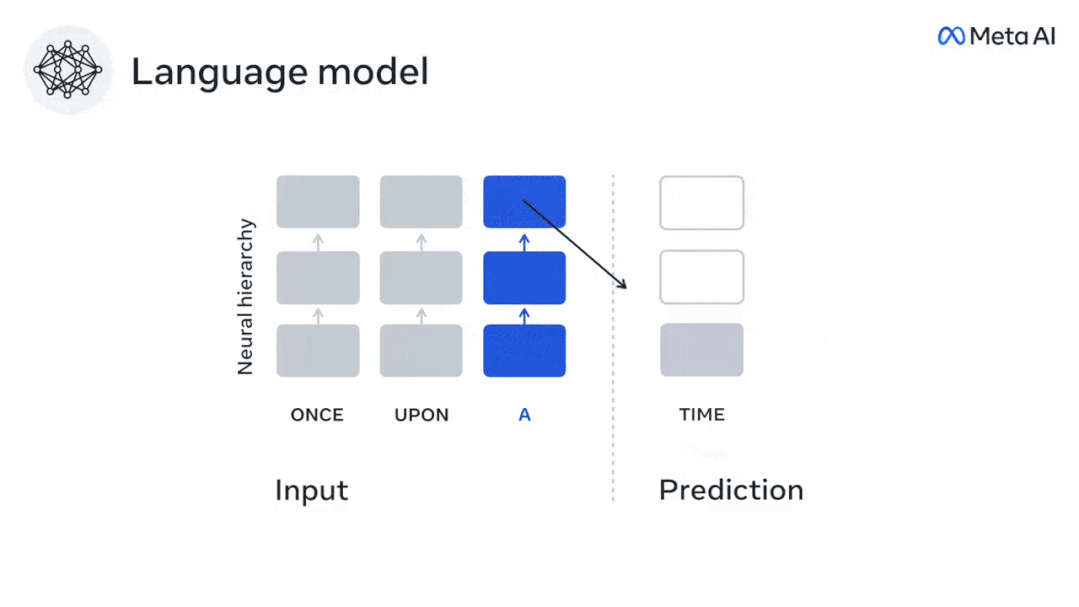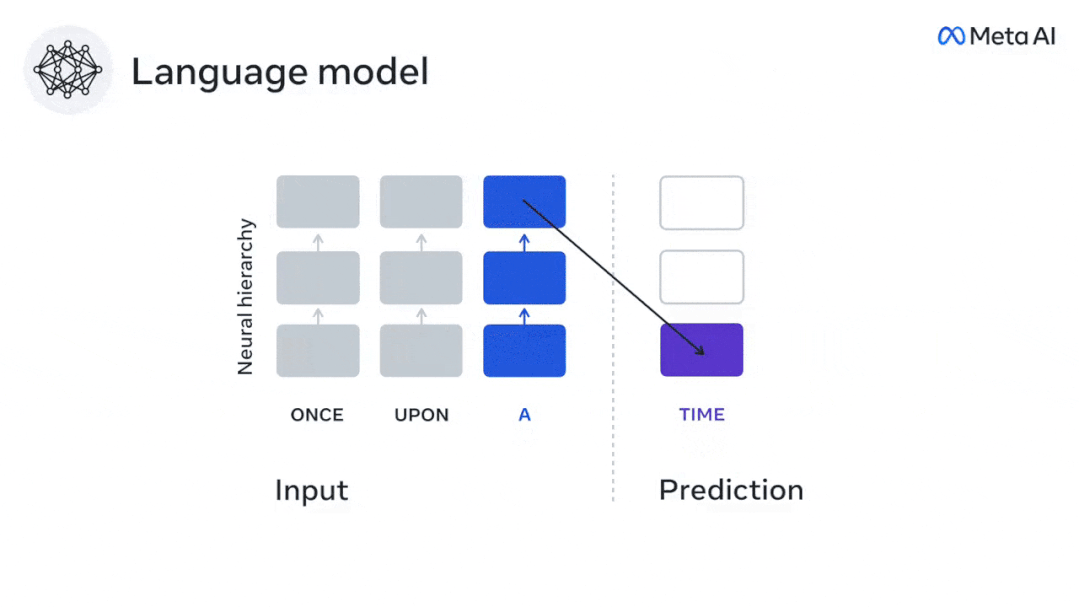
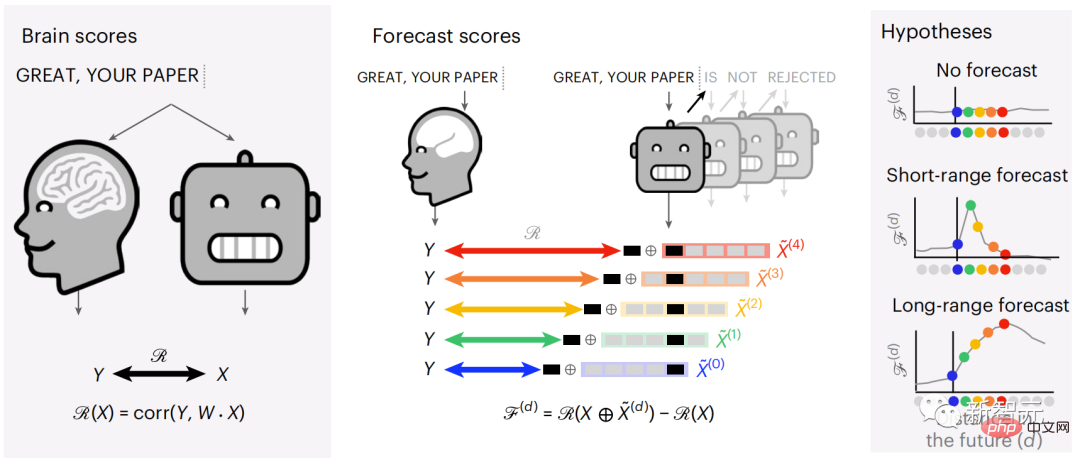
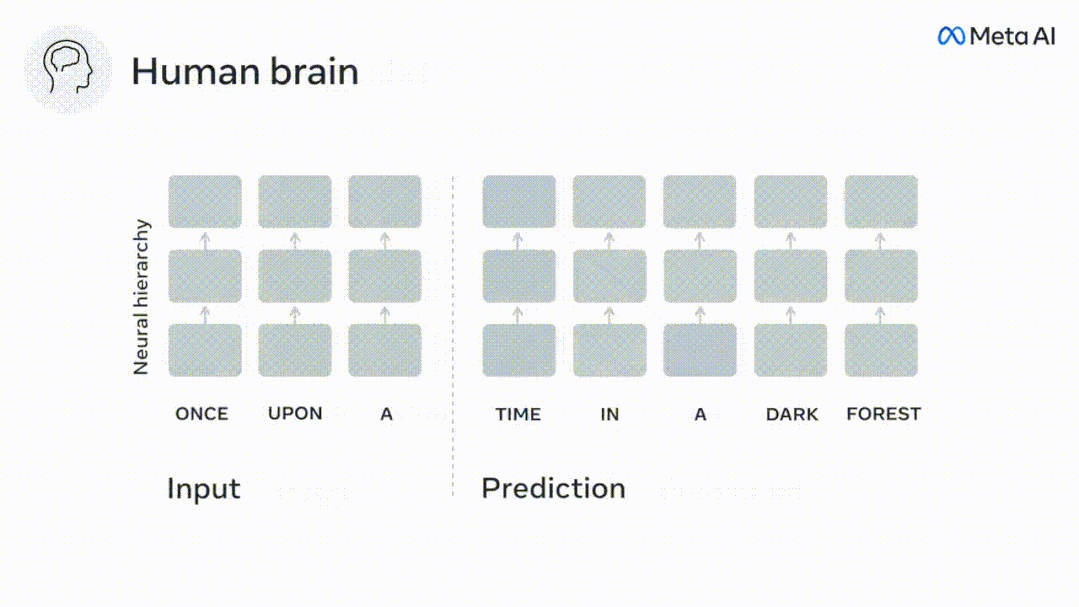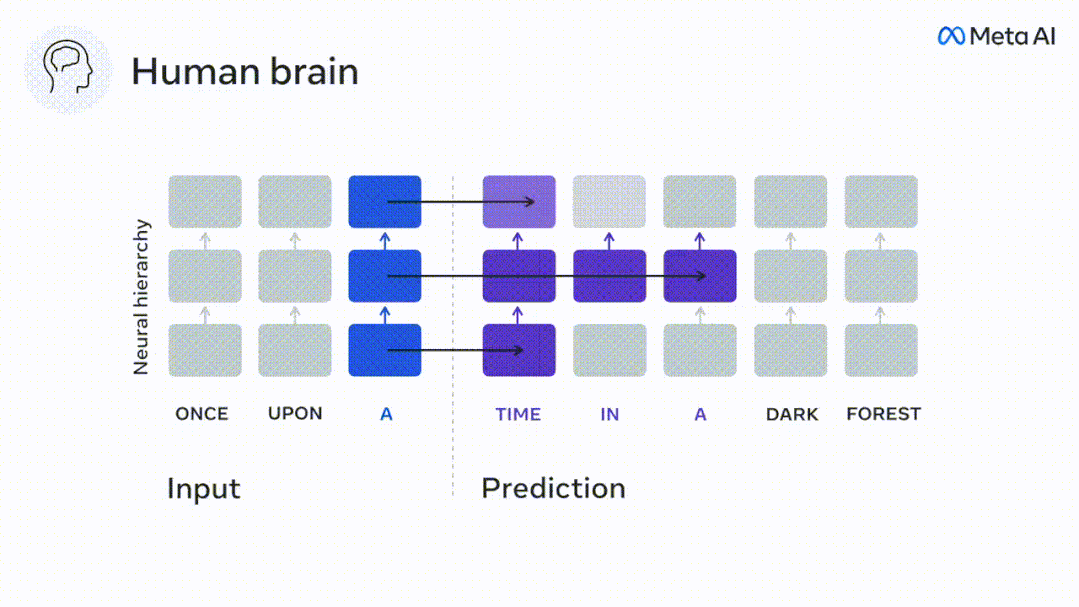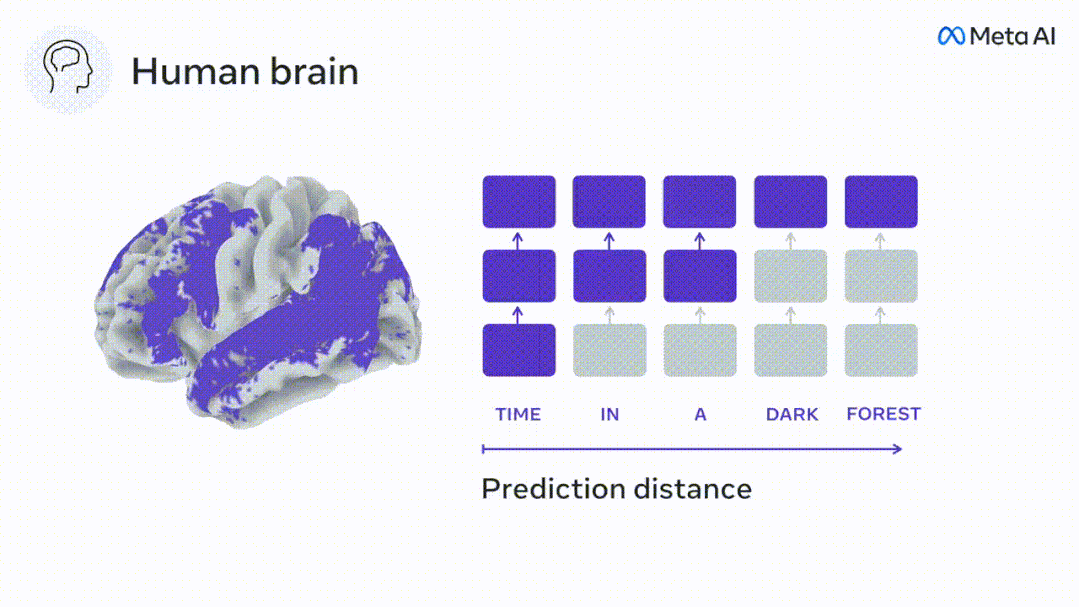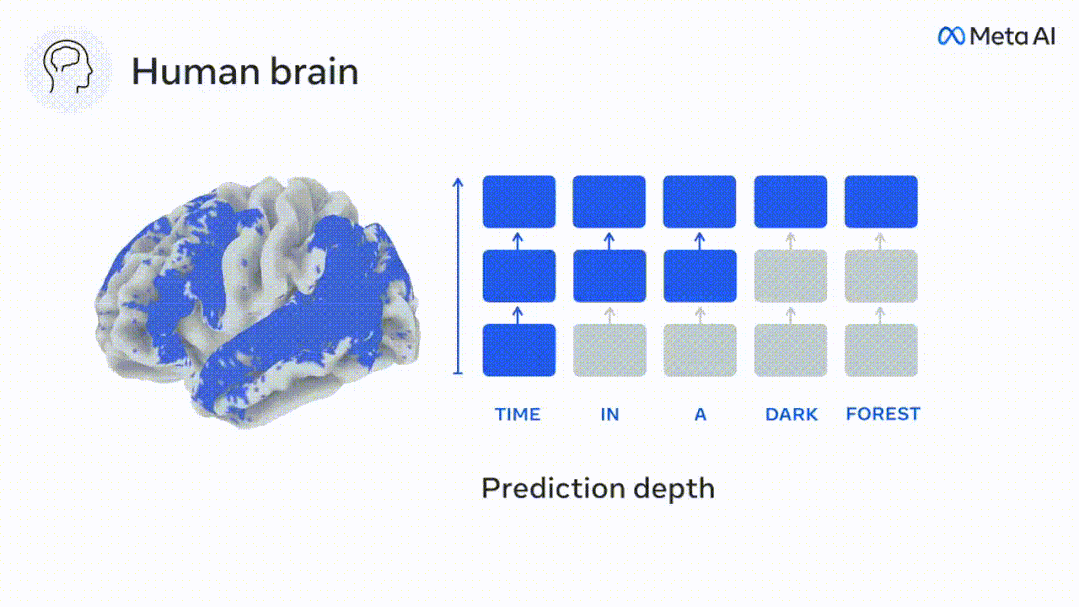
Experimentelle Ergebnisse
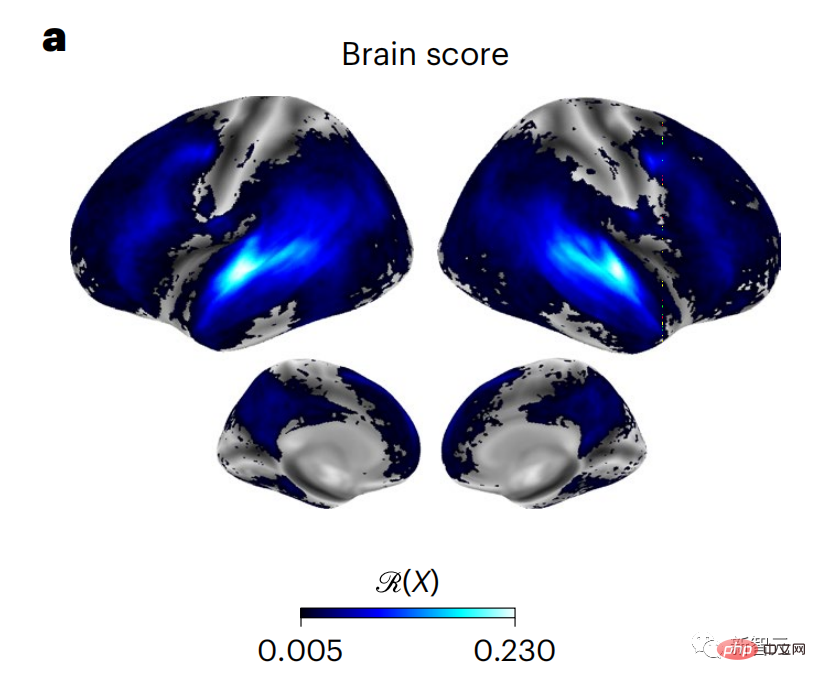
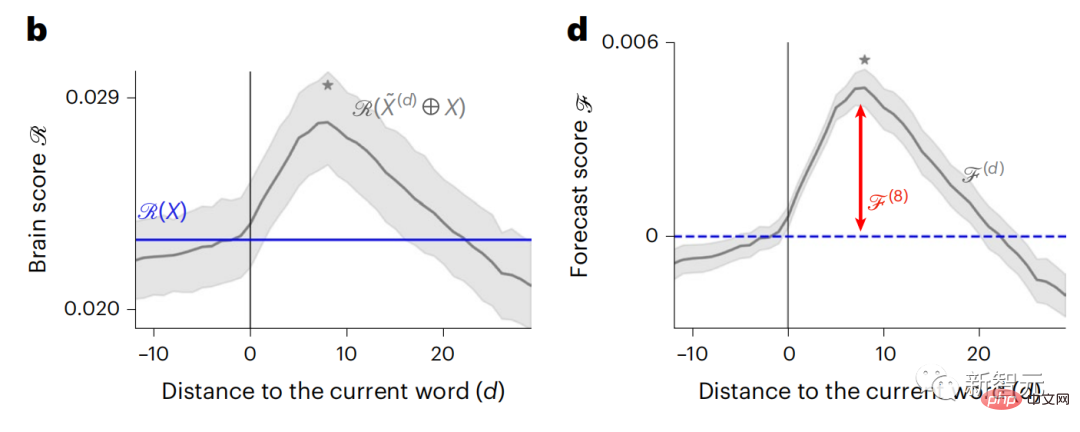
Das obige ist der detaillierte Inhalt vonDie Vorhersage der Gehirnhierarchie macht große Modelle effizienter!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr