
Heim >Technologie-Peripheriegeräte >KI >Mehrere Tipps zur Vermeidung von Fallstricken bei der Verwendung von ChatGLM
Mehrere Tipps zur Vermeidung von Fallstricken bei der Verwendung von ChatGLM

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-02 13:58:062194Durchsuche
Ich habe gestern gesagt, dass ich nach meiner Rückkehr vom Data Technology Carnival eine Reihe von ChatGLM bereitgestellt habe und geplant habe, die Verwendung großer Sprachmodelle zum Trainieren der Wissensbasis für den Datenbankbetrieb und die Wartung zu studieren. Viele Freunde haben es nicht geglaubt und gesagt, dass Sie es bereits tun Du bist in deinem Alter, Lao Bai, und schaffst es immer noch, diese Dinger wegzuwerfen? Um die Zweifel dieser Freunde zu zerstreuen, werde ich heute den Prozess der Abschaffung von ChatGLM in den letzten beiden Tagen mit Ihnen teilen und auch einige Tipps zur Vermeidung von Fallstricken für Freunde geben, die daran interessiert sind, ChatGLM abzuwerfen.
ChatGLM-6B wurde auf der Grundlage des Sprachmodells GLM entwickelt, das 2023 gemeinsam vom KEG-Labor der Tsinghua-Universität und Zhipu AI trainiert wurde. Es handelt sich um ein groß angelegtes Sprachmodell, das angemessene Antworten und Unterstützung für die Fragen und Anforderungen der Benutzer bietet. Die obige Antwort wird von ChatGLM selbst beantwortet. Es handelt sich um ein vorab trainiertes Open-Source-Modell mit 6,2 Milliarden Parametern. Seine Besonderheit besteht darin, dass es lokal in einer relativ kleinen Hardwareumgebung ausgeführt werden kann. Mit dieser Funktion können Anwendungen, die auf großen Sprachmodellen basieren, in Tausende von Haushalten gelangen. Der Zweck des KEG-Labors besteht darin, das Training des größeren GLM-130B-Modells (130 Milliarden Parameter, entspricht GPT-3.5) in einer Low-End-Umgebung mit einer 8-Wege-RTX 3090 zu ermöglichen.
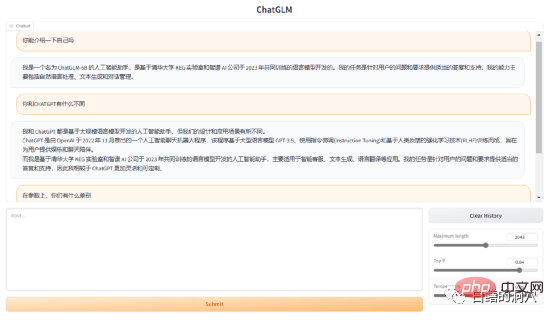
Wenn dieses Ziel wirklich erreicht werden kann, ist das auf jeden Fall eine gute Nachricht für Leute, die einige Anwendungen basierend auf großen Sprachmodellen erstellen möchten. Das aktuelle FP16-Modell von ChatGLP-6B hat etwas mehr als 13 GB und das INT-4-Quantisierungsmodell weniger als 4 GB. Es kann auf einer RTX 3060TI mit 6 GB Videospeicher ausgeführt werden.
Ich wusste vor der Bereitstellung nicht viel über diese Situationen, also kaufte ich eine 12 GB RTX 3060, die weder hoch noch niedrig war, sodass ich nach Abschluss der Installation und Bereitstellung das FP16-Modell immer noch nicht ausführen konnte. Wenn ich es besser gewusst hätte, Tests und Überprüfungen zu Hause durchzuführen, hätte ich einfach einen günstigeren 3060TI gekauft. Wenn Sie ein verlustfreies FP16-Modell betreiben möchten, müssen Sie sich eine 3090 mit 24 GB Videospeicher besorgen.
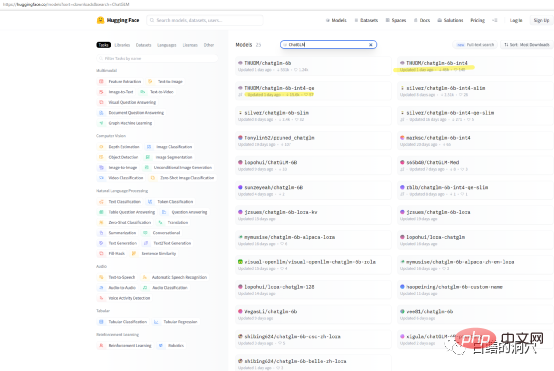
Wenn Sie nur die Funktionen von ChatGLP-6B auf Ihrem eigenen Computer testen möchten, müssen Sie das THUDM/ChatGLM-6B-Modell möglicherweise nicht direkt herunterladen. Es gibt einige paketierte quantitative Modelle auf Huggingface heruntergeladen. Die Downloadgeschwindigkeit des Modells ist sehr langsam. Sie können das quantitative Int4-Modell direkt herunterladen.
Ich habe diese Installation auf einem I7 8-Core-PC mit einer RTX 3060-Grafikkarte mit 12G-Videospeicher abgeschlossen. Da es sich bei diesem Computer um meinen Arbeitscomputer handelt, habe ich ChatGLM auf dem WSL-Subsystem installiert. Die Installation von ChatGLM auf dem WINDOWS WSL-Subsystem ist komplizierter als die direkte Installation in einer LINUX-Umgebung. Die größte Gefahr ist die Installation von Grafikkartentreibern. Wenn Sie ChatGLM direkt unter Linux bereitstellen, müssen Sie den NVIDIA-Treiber direkt installieren und den Netzwerkkartentreiber über modprobe aktivieren. Die Installation auf WSL ist ganz anders.
ChatGLM kann auf Github heruntergeladen werden, und auf der Website gibt es einige einfache Dokumente, darunter sogar ein Dokument für die Bereitstellung von ChatGLM auf WINDOWS WSL. Wenn Sie jedoch ein Neuling auf diesem Gebiet sind und die Implementierung vollständig gemäß diesem Dokument durchführen, werden Sie auf unzählige Fallstricke stoßen.
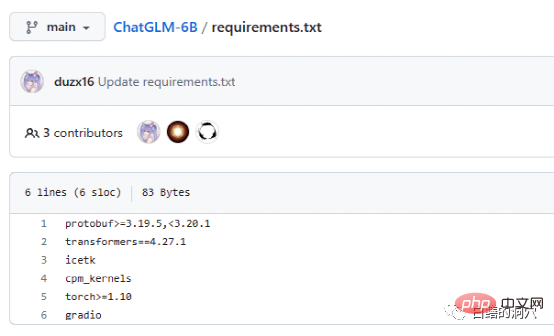
Das Dokument Requriements.txt listet die Liste und Versionsnummern der wichtigsten Open-Source-Komponenten auf, die von ChatGLM verwendet werden. Tatsächlich sind die Anforderungen nicht so streng. und es ist in Ordnung, wenn es etwas niedriger ist. Es ist ein großes Problem, aber aus Sicherheitsgründen ist es besser, die gleiche Version zu verwenden. Icetk dient der Token-Verarbeitung, cpm_kernels ist der Kernaufruf des chinesischen Verarbeitungsmodells und cuda und protobuf dient der strukturierten Datenspeicherung. Gradio ist ein Framework zur schnellen Generierung von KI-Anwendungen mit Python. Ich brauche keine Einführung in Torch.
ChatGLM kann in einer Umgebung ohne GPU verwendet werden, wobei die CPU und 32 GB physischer Speicher zum Ausführen verwendet werden. Die Laufgeschwindigkeit ist jedoch sehr langsam und kann nur zur Demonstrationsüberprüfung verwendet werden. Wenn Sie ChatGLM spielen möchten, rüsten Sie sich am besten mit einer GPU aus.
Die größte Gefahr bei der Installation von ChatGLM auf WSL ist der Grafikkartentreiber. Die Dokumentation für ChatGLM auf Git ist sehr unfreundlich. Für Leute, die nicht viel über dieses Projekt wissen oder noch nie eine solche Bereitstellung durchgeführt haben, ist die Dokumentation wirklich verwirrend. Tatsächlich ist die Softwarebereitstellung kein Problem, aber der Grafikkartentreiber ist sehr knifflig.
Da es auf dem WSL-Subsystem bereitgestellt wird, ist LINUX nur ein Emulationssystem, kein vollständiges LINUX. Daher muss der NVIDIA-Grafiktreiber nur unter WINDOWS installiert und nicht in WSL aktiviert werden. CUDA TOOLS muss jedoch weiterhin in der virtuellen LINUX-Umgebung von WSL installiert werden. Der NVIDIA-Treiber unter WINDOWS muss den neuesten Treiber von der offiziellen Website installieren und kann den mit WIN10/11 gelieferten Kompatibilitätstreiber nicht verwenden. Laden Sie daher den neuesten Treiber von der offiziellen Website herunter und installieren Sie ihn.
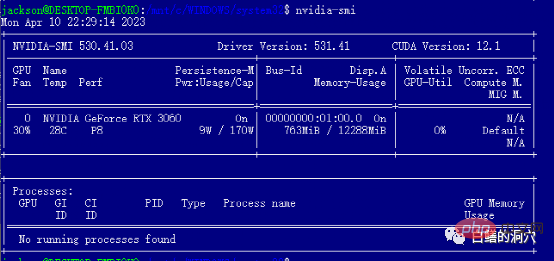
Nach der Installation des WIN-Treibers können Sie cuda tools direkt in WSL installieren. Wenn Sie die obige Schnittstelle sehen, haben Sie die erste Grube erfolgreich vermieden. Tatsächlich stoßen Sie bei der Installation von Cuda-Tools auf mehrere Fallstricke. Das heißt, auf Ihrem System müssen entsprechende Versionen von gcc, gcc-dev, make und anderen kompilierungsbezogenen Tools installiert sein. Wenn diese Komponenten fehlen, schlägt die Installation der cuda-Tools fehl.
Das Obige ist die Fallstrickvorbereitung. Tatsächlich wird der Fallstrick des NVIDIA-Treibers vermieden und die anschließende Installation verläuft immer noch sehr reibungslos. In Bezug auf die Systemauswahl empfehle ich weiterhin, Debian-kompatibles Ubuntu zu wählen. Die neue Version von Ubuntu ist sehr intelligent und kann Ihnen dabei helfen, Versionskompatibilitätsprobleme einer großen Anzahl von Software zu lösen und ein automatisches Versions-Downgrade einiger Software zu realisieren.
Der folgende Installationsvorgang kann reibungslos abgeschlossen werden, indem die Installationsanleitung vollständig befolgt wird. Es ist zu beachten, dass die Arbeit zum Ersetzen der Installationsquellen in /etc/apt/sources.list einerseits am besten durchgeführt wird , wird die Installationsgeschwindigkeit viel schneller sein, außerdem werden dadurch einerseits Kompatibilitätsprobleme mit der Softwareversion vermieden. Wenn Sie es nicht ersetzen, hat dies natürlich keine Auswirkungen auf den nachfolgenden Installationsprozess.
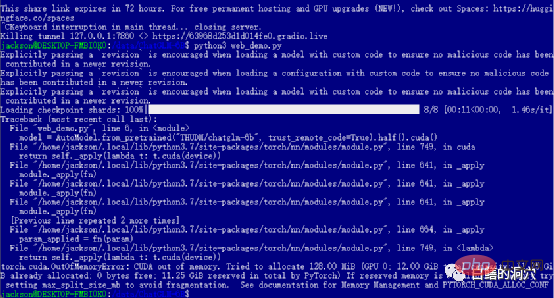
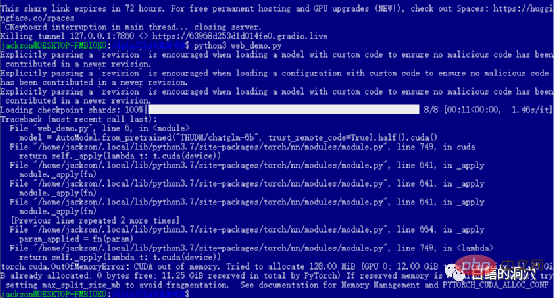
Wenn Sie die vorherigen Level erfolgreich bestanden haben, dann haben Sie den letzten Schritt erreicht und starten web_demo. Durch Ausführen von python3 web_demo.py kann ein Beispiel für eine WEB-Konversation gestartet werden. Wenn Sie zu diesem Zeitpunkt ein armer Mensch sind und nur eine 3060 mit 12 GB Videospeicher haben, wird Ihnen der obige Fehler definitiv angezeigt. Selbst wenn Sie PYTORCH_CUDA_ALLOC_CONF auf den Mindestwert 21 setzen, können Sie diesen Fehler nicht vermeiden. Zu diesem Zeitpunkt dürfen Sie nicht faul sein, Sie müssen einfach das Python-Skript neu schreiben.
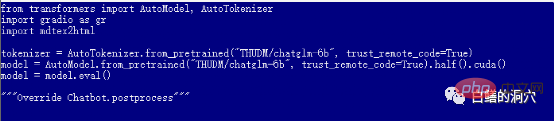
Die Standardeinstellung web_demo.py verwendet das vorab trainierte FP16-Modell. Ein Modell mit mehr als 13 GB wird definitiv nicht in die vorhandenen 12 GB geladen, daher müssen Sie eine kleine Anpassung an diesem Code vornehmen.

Sie können zu quantize(4) wechseln, um das INT4-Quantisierungsmodell zu laden, oder zu quantize(8) wechseln, um das INT8-Quantisierungsmodell zu laden. Auf diese Weise reicht der Speicher Ihrer Grafikkarte aus und Sie können verschiedene Gespräche führen.
Es ist zu beachten, dass der Download des Modells erst richtig beginnt, wenn web_demo.py gestartet wird, sodass das Herunterladen des 13-GB-Modells lange dauern wird. Sie können diese Arbeit mitten in der Nacht erledigen, oder Sie Sie können Thunder direkt verwenden. Warten Sie, bis das Download-Tool das Modell von Hugging Face im Voraus heruntergeladen hat. Wenn Sie nichts über das Modell wissen und nicht sehr gut darin sind, das heruntergeladene Modell zu installieren, können Sie auch den Modellnamen im Code, THUDM/chatglm-6b-int4, ändern und das INT4-quantisierte Modell mit weniger als 4 GB direkt von herunterladen Das Internet wird viel schneller sein, aber Ihre kaputte Grafikkarte kann das FP16-Modell sowieso nicht ausführen.
Zu diesem Zeitpunkt können Sie über die Webseite mit ChatGLM sprechen, aber das ist erst der Anfang des Problems. Erst wenn Sie Ihr fein abgestimmtes Modell trainieren können, kann Ihre Reise in ChatGLM wirklich beginnen. Das Spielen solcher Dinge erfordert immer noch viel Energie und Geld. Seien Sie also vorsichtig, wenn Sie in die Falle tappen.
Abschließend bin ich meinen Freunden vom KEG-Labor an der Tsinghua-Universität sehr dankbar. Ihre Arbeit ermöglicht es mehr Menschen, große Sprachmodelle zu geringen Kosten zu nutzen.
Das obige ist der detaillierte Inhalt vonMehrere Tipps zur Vermeidung von Fallstricken bei der Verwendung von ChatGLM. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr