
Heim >Technologie-Peripheriegeräte >KI >Die University of Wisconsin-Madison und andere haben gemeinsam einen Artikel veröffentlicht! Das neueste multimodale große Modell LLaVA wird veröffentlicht und sein Niveau liegt nahe an GPT-4
Die University of Wisconsin-Madison und andere haben gemeinsam einen Artikel veröffentlicht! Das neueste multimodale große Modell LLaVA wird veröffentlicht und sein Niveau liegt nahe an GPT-4

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-30 22:49:051778Durchsuche
Die Feinabstimmung visueller Befehle ist beliebt.
Dieses Papier heißt Visual Instruction Tuning und wird gemeinsam von der University of Wisconsin-Madison, Microsoft Research und der Columbia University erstellt.
Zu den Autoren gehören Haotian Liu, Chunyuan Li, Qingyang Wu und Yong Jae Lee.

Gleichzeitig stellten die Forscher ihren Code auch als Open Source auf GitHub zur Verfügung , Modelle und Datensätze. Das Papier ist auch auf Arxiv veröffentlicht.
Erklärung
Was genau ist also die Funktion von LLaVA? Wenn man sich mit dem Papier befasst, könnte es für diejenigen, die damit nicht vertraut sind, etwas seltsam wirken.
Schauen wir uns zunächst an, was LLaVA selbst sagt.
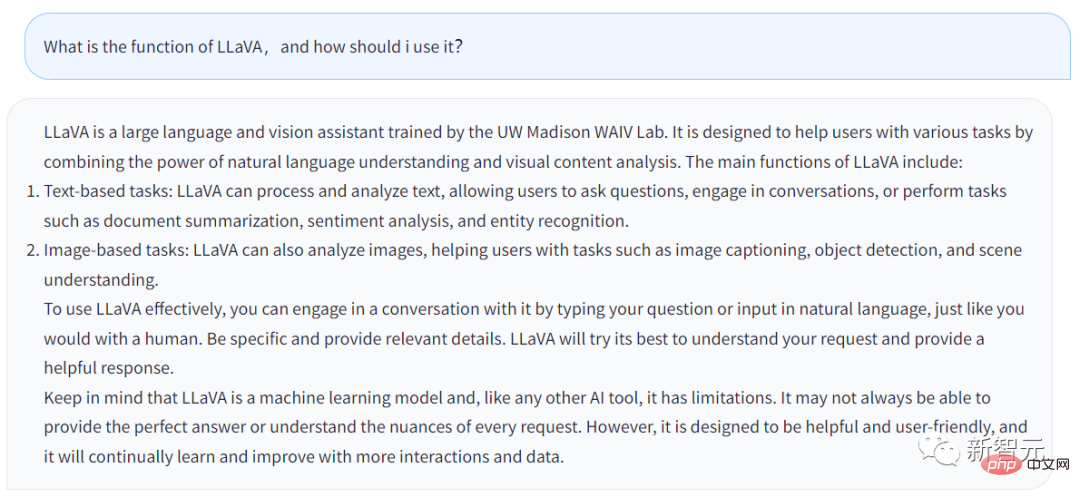
Die obige Antwort wird vom Chatbot von LLaVA generiert , Welche Funktion hat LLaVA und wie können Nutzer davon profitieren?
Die Antwort lautet wie folgt:
LLaVA ist ein großer Sprach- und visueller Assistent an der UW Madison WAIV Lab-Schulung erhalten. LLaVA soll Benutzern bei der Bewältigung verschiedener Aufgaben helfen, indem es seine Fähigkeiten zum Verstehen natürlicher Sprache und zur Analyse visueller Inhalte nutzt.
Zu den Hauptfunktionen von LLaVA gehören: Grundlegende Aufgaben: LLaVA kann Text verarbeiten und analysieren, Benutzern das Stellen von Fragen ermöglichen, LLaVA kann mit Benutzern sprechen oder von Benutzern eingegebene Aufgaben erledigen, wie die Verfeinerung von Dokumentzusammenfassungen, Stimmungsanalysen, Entitätserkennung usw.
· Bildbasierte Aufgaben: LLaVA kann Bilder analysieren, Bilder beschreiben, Objekterkennung durchführen sowie Szenen analysieren und verstehen.
Wenn Benutzer LLaVA besser anwenden möchten, können sie direkt mit LLaVA sprechen, genau wie mit Menschen. Geben Sie so viele Details wie möglich an und LLaVA wird eine vollständigere Antwort generieren.
Gleichzeitig sollten Sie bedenken, dass LLaVA schließlich ein Modell für maschinelles Lernen und ein KI-Tool ist. Solange es ein Werkzeug ist, hat es seine Grenzen. LLaVA beantwortet die vom Benutzer eingegebenen Fragen möglicherweise nicht jedes Mal perfekt.Natürlich lernt und verbessert sich LLaVA ständig und seine Funktionen werden immer leistungsfähiger.
Generell lässt sich aus der Antwort von LLaVA erkennen, dass sich die Funktionen von Chatbot nicht wesentlich von denen von GPT unterscheiden. Aber LLaVA kann einige Aufgaben im Zusammenhang mit Bildern erledigen. Die Forscher haben die technischen Details von LLaVA in ihrem Arxiv-Artikel detailliert beschrieben.
Es ist wichtig zu wissen, dass die Verwendung maschinengenerierter Anweisungen zur Verfolgung von Daten zur Feinabstimmung von Anweisungen für große Sprachmodelle (LLMs) die Nullpunktfähigkeit neuer Modelle verbessert Aufgaben, aber diese Idee ist im Multimodus begrenzt. Der dynamische Bereich ist weniger erforscht.
In der Arbeit versuchten die Forscher zunächst, das rein sprachbasierte GPT-4 zu verwenden, um Befehlsfolgedaten für multimodale Sprachbilder zu generieren.
Durch Konditionierung von Anweisungen auf diesen generierten Daten stellten die Forscher LLaVA vor: einen groß angelegten Sprach- und visuellen Assistenten, der durchgängig trainiert wird. Ein großes multimodales Modell, das verbindet einen visuellen Encoder und LLM für allgemeines Sehen und Sprachverständnis.
Frühe Experimente zeigen, dass LLaVA beeindruckende multimodale Chat-Fähigkeiten demonstriert, manchmal multimodale GPT-4-Leistung auf unsichtbaren Bildern/Anweisungen ausgibt und synthetische multimodale Anweisungen befolgt. Im Vergleich zu GPT-4 im Datensatz erreichte es eine relativer Wert von 85,1 %.
Bei der Feinabstimmung für das Science-Magazin erreichte die Synergie von LLaVA und GPT-4 eine neue, hochmoderne Genauigkeit von 92,53 %.
Forscher haben die von GPT-4 generierten Daten, Modelle und Codebasis für visuelle Befehlsanpassungen offengelegt.
Multimodales Modell
Klären Sie zunächst die Definition.
Groß angelegtes multimodales Modell bezieht sich auf ein Modell, das auf maschineller Lerntechnologie basiert und mehrere Eingabetypen wie Text und Bilder verarbeiten und analysieren kann.
Diese Modelle sind für ein breiteres Aufgabenspektrum konzipiert und in der Lage, verschiedene Datenformen zu verstehen. Durch die Verwendung von Text und Bildern als Eingabe verbessern diese Modelle ihre Fähigkeit, Erklärungen zu verstehen und zusammenzustellen, um genauere und relevantere Antworten zu generieren.
Menschen interagieren mit der Welt über mehrere Kanäle wie Vision und Sprache, da jeder einzelne Kanal einzigartige Vorteile bei der Darstellung und Vermittlung bestimmter Weltkonzepte hat und so zu einem besseren Verständnis der Welt beiträgt.
Eines der Kernziele der künstlichen Intelligenz ist die Entwicklung eines universellen Assistenten, der multimodalen visuellen und sprachlichen Anweisungen im Einklang mit menschlichen Absichten effektiv folgen und eine Vielzahl realer Aufgaben erledigen kann.
Infolgedessen verzeichnet die Entwicklergemeinschaft ein erneutes Interesse an der Entwicklung sprachgestützter grundlegender Visionsmodelle mit leistungsstarken Funktionen für das visuelle Verständnis in der offenen Welt, wie Klassifizierung, Erkennung, Segmentierung, Beschreibung sowie Visionsgenerierung und -bearbeitung.
Bei diesen Funktionen wird jede Aufgabe unabhängig von einem einzigen großen visuellen Modell gelöst, wobei die Aufgabenanweisungen implizit im Modelldesign berücksichtigt werden.
Darüber hinaus wird Sprache nur zur Beschreibung des Bildinhalts verwendet. Dadurch kann die Sprache eine wichtige Rolle bei der Zuordnung visueller Signale zur sprachlichen Semantik spielen – einem gemeinsamen Kanal für die menschliche Kommunikation. Dies führt jedoch dazu, dass Modelle häufig über feste Schnittstellen mit eingeschränkter Interaktivität und Anpassungsfähigkeit an Benutzeranweisungen verfügen.
Und große Sprachmodelle (LLM) zeigen, dass Sprache eine umfassendere Rolle spielen kann: Eine gemeinsame Schnittstelle für einen universellen Assistenten, verschiedene Aufgabenanweisungen können explizit in der Sprache ausgedrückt werden und den durchgängig trainierten neuronalen Assistenten beim Umschalten leiten zur interessierenden Aufgabe und lösen Sie sie.
Zum Beispiel hat der jüngste Erfolg von ChatGPT und GPT-4 die Fähigkeit dieses LLM bewiesen, menschlichen Anweisungen zu folgen, und großes Interesse an der Entwicklung von Open-Source-LLM geweckt.
LLaMA ist ein Open-Source-LLM, dessen Leistung GPT-3 entspricht. Die laufende Arbeit nutzt verschiedene maschinengenerierte, qualitativ hochwertige Anleitungsfolgebeispiele, um die Ausrichtungsfähigkeiten von LLM zu verbessern und berichtet über eine beeindruckende Leistung im Vergleich zu proprietären LLMs. Wichtig ist, dass dieser Arbeitsbereich nur aus Text besteht.
In diesem Artikel schlagen Forscher eine visuelle Befehlsabstimmung vor, die den ersten Versuch darstellt, die Befehlsabstimmung auf einen multimodalen Raum auszudehnen und den Weg für die Entwicklung eines universellen visuellen Assistenten zu ebnen. Zu den Hauptinhalten des Papiers gehören insbesondere:
Multimodale Anweisungsfolgedaten. Eine zentrale Herausforderung ist das Fehlen visueller Anweisungen zur Verfolgung der Daten. Wir stellen eine Datenreformperspektive und -pipeline vor, die ChatGPT/GPT-4 verwendet, um Bild-Text-Paare in geeignete Befehlsfolgenformate zu konvertieren.
Großes multimodales Modell. Die Forscher entwickelten ein großes multimodales Modell (LMM), indem sie den Open-Set-Visual-Encoder und den Sprachdecoder LaMA von CLIP verbanden und sie durchgängig anhand der generierten visuell-verbalen Lehrdaten verfeinerten. Empirische Studien verifizieren die Wirksamkeit der LMM-Anweisungsoptimierung anhand generierter Daten und liefern praktische Vorschläge für den Aufbau eines allgemeinen visuellen Agenten zur Befehlsfolge. Mit GPT 4 erreichte das Forschungsteam Spitzenleistungen beim multimodalen Inferenzdatensatz Science QA.
Open Source. Das Forschungsteam stellte der Öffentlichkeit Folgendes zur Verfügung: die generierten multimodalen Befehlsdaten, eine Codebibliothek für die Datengenerierung und das Modelltraining, Modellkontrollpunkte und eine visuelle Chat-Demonstration.
Ergebnisanzeige

Wie Sie sehen, kann LLaVA mit allen Arten von Problemen umgehen , und Die generierten Antworten sind sowohl umfassend als auch logisch.
LLaVA demonstriert einige multimodale Fähigkeiten, die dem Niveau von GPT-4 nahekommen, mit einem relativen GPT-4-Score von 85 % in Bezug auf visuellen Chat.
In Bezug auf die Argumentation von Frage und Antwort erreichte LLaVA sogar den neuen SoTA-92,53 % und besiegte damit die multimodale Denkkette.
Das obige ist der detaillierte Inhalt vonDie University of Wisconsin-Madison und andere haben gemeinsam einen Artikel veröffentlicht! Das neueste multimodale große Modell LLaVA wird veröffentlicht und sein Niveau liegt nahe an GPT-4. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr