
Heim >Technologie-Peripheriegeräte >KI >Von ODS zu ADS, eine detaillierte Erklärung der Data Warehouse-Stratifizierung!
Von ODS zu ADS, eine detaillierte Erklärung der Data Warehouse-Stratifizierung!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-30 20:22:042107Durchsuche
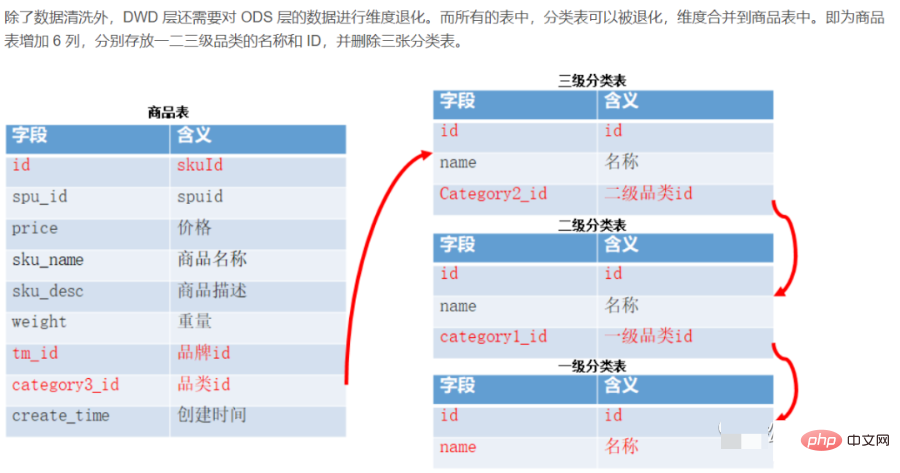
1. Warum sollten wir das Data Warehouse schichten? Big Data kann mit hoher Leistung, geringen Kosten, hoher Effizienz und hoher Qualität genutzt werden.
01 Hierarchische Bedeutung
1) Klare Datenstruktur: # 🎜🎜#Jede Datenschicht hat ihren Umfang, sodass wir sie bei Verwendung der Tabelle leichter finden und verstehen können. Organisierte Datenbeziehungen: Es gibt komplexe Datenbeziehungen zwischen Quellsystemen. Beispielsweise liegen Kundeninformationen im Kernsystem, dem Kreditsystem, vor , Finanzmanagementsystem, Kapitalsystem, wie trifft man Entscheidungen beim Abheben von Daten? Das Data Warehouse führt eine einheitliche Modellierung von Daten zum gleichen Thema durch und sortiert komplexe Datenbeziehungen in klare Datenmodelle, wodurch die oben genannten Probleme bei der Verwendung vermieden werden können.
2) Datenherkunftsverfolgung:
Einfach gesagt, es Auf diese Weise können wir verstehen, dass wir letztendlich eine Geschäftstabelle bereitstellen, die direkt verwendet werden kann. Wenn jedoch ein Problem mit einer der Quelltabellen auftritt, hoffen wir, dies schnell und genau tun zu können Lokalisieren Sie das Problem und verstehen Sie seinen Schaden. 3) Datenwiederverwendung, wiederholte Entwicklung reduzieren:
Standardisierung Durch die Datenschichtung und die Entwicklung einiger gemeinsamer Daten der mittleren Ebene können umfangreiche, sich wiederholende Berechnungen reduziert werden. Basierend auf dem schichtweisen Verarbeitungsprinzip der Daten enthält die untere Schicht alle Daten, die für die Datenverarbeitung der oberen Schicht erforderlich sind. Diese Verarbeitungsmethode vermeidet, dass jeder Datenentwickler Daten zur Verarbeitung erneut aus dem Quellsystem extrahieren muss. Durch die Einführung der Zusammenfassungsschicht werden wiederholte Berechnungen der nachgelagerten Benutzerlogik vermieden, was den Benutzern Entwicklungszeit und -energie sowie Berechnungs- und Speicherkosten spart. Es reduziert unnötige Datenredundanz erheblich, ermöglicht die Wiederverwendung von Berechnungsergebnissen und reduziert die Speicher- und Rechenkosten erheblich. 4) Komplexe Probleme vereinfachen.
Zerlegen Sie eine komplexe Aufgabe in mehrere Schritte, um sie abzuschließen. Jede Ebene behandelt nur einen einzigen Schritt, was relativ einfach und leicht zu verstehen ist. Es ist auch einfach, die Genauigkeit der Daten aufrechtzuerhalten. Wenn ein Problem mit den Daten auftritt, müssen Sie nicht alle Daten reparieren, sondern nur beim problematischen Schritt beginnen. 5) Schützen Sie den (Einfluss) der Originaldaten und schirmen Sie die Auswirkungen auf das Unternehmen ab.
Wenn sich das Unternehmen oder System ändert, ist es nicht erforderlich, das Unternehmen einmal zu ändern, bevor erneut auf die Daten zugegriffen werden kann. Verbessern Sie die Datenstabilität und -kontinuität. Schützen Sie die Komplexität des Quellgeschäftssystems: Das Quellsystem kann äußerst kompliziert sein und Tabellennamen, Feldnamen und Feldbedeutungen umfassen usw. können vielfältig sein, all diese Komplexitäten durch die DW-Schicht standardisieren und abschirmen und so die Bequemlichkeit und Standardisierung der Datennutzung durch nachgelagerte Datennutzer gewährleisten. Wenn sich das Quellsystemgeschäft ändert, werden die relevanten Änderungen von der DW-Schicht verarbeitet, die für nachgeschaltete Benutzer transparent ist, ohne den Code und die Logik der nachgeschalteten Benutzer zu ändern.
Wartbarkeit des Data Warehouse: Durch das geschichtete Design können Probleme auf einer bestimmten Ebene nur auf dieser Ebene ohne Änderungen gelöst werden. Die nächste Ebene aus Code und Logik.
Big-Data-Systeme erfordern Datenmodellansätze, um Daten besser zu organisieren und zu speichern und so Leistung, Kosten, Effizienz und Qualität zu verbessern. Holen Sie sich das Beste Gleichgewicht zwischen ihnen!
02 Die vier Operationen des Data Warehouse (ETL) ETL (Extraction Transformation Loading) ist verantwortlich zur Dezentralisierung Daten aus heterogenen Datenquellen werden zur Bereinigung, Konvertierung, Integration in die temporäre mittlere Schicht extrahiert und schließlich in ein Data Warehouse oder einen Data Mart geladen. ETL ist der Kern und die Seele der Implementierung eines Data Warehouse. Der Entwurf und die Implementierung von ETL-Regeln machen etwa 60 bis 80 % des gesamten Arbeitsaufwands für den Aufbau eines Data Warehouse aus.
1) Die Datenextraktion umfasst das anfängliche Laden und Aktualisieren von Daten: Das anfängliche Laden von Daten konzentriert sich hauptsächlich auf das Erstellen von Dimensionstabellen und Faktentabellen und das Einfügen entsprechender Daten in diese Datentabellen Hängen Sie die entsprechenden Daten im Data Warehouse an und aktualisieren Sie sie, wenn sich die Quelldaten ändern (Sie können beispielsweise geplante Aufgaben erstellen oder die Daten regelmäßig in Form von Triggern aktualisieren).
2) Datenbereinigung dient hauptsächlich der einheitlichen Verarbeitung von Daten mit Problemen wie Mehrdeutigkeit, Duplizierung, Unvollständigkeit, Verletzung von Geschäfts- oder Logikregeln usw., die in der Quelldatenbank auftreten. Das heißt, Daten zu bereinigen, die nicht geschäftsrelevant oder nutzlos sind. Schreiben Sie beispielsweise Hive oder MR, um Daten zu bereinigen, deren Länge nicht den Anforderungen im Feld entspricht.
3) Datentransformation (Transformation) besteht hauptsächlich darin, die bereinigten Daten in die vom Data Warehouse benötigten Daten umzuwandeln: Datenwörterbücher oder Datenformate desselben Datenfelds aus verschiedenen Quellsystemen Anders (z. B. heißt es in Tabelle A ids und in Tabelle B ids). Im Data Warehouse ist es erforderlich, ihnen ein einheitliches Datenwörterbuch und -format zur Verfügung zu stellen, um den Dateninhalt zu normalisieren Warehouse-Anforderungen: Der Inhalt einiger Felder ist möglicherweise nicht im Quellsystem verfügbar, muss jedoch anhand des Inhalts mehrerer Felder im Quellsystem ermittelt werden.
4) Beim Laden von Daten werden die zuletzt verarbeiteten Daten in den entsprechenden Speicherbereich (hbase, mysql usw.) importiert, um die Bereitstellung für den Datenmart zur Visualisierung zu erleichtern.
Im Allgemeinen verfügen große Unternehmen über eine eigene gekapselte Datenplattform und Aufgabenplanungsplattform für Datensicherheit und Betriebskomfort. Die unterste Ebene kapselt große Datencluster wie Hadoop-Cluster, Spark-Cluster, Sqoop, Hive, Zookeeper, Hbase usw. usw. Stellen Sie eine Webschnittstelle bereit, erteilen Sie verschiedenen Mitarbeitern unterschiedliche Berechtigungen und führen Sie dann unterschiedliche Vorgänge und Aufrufe im Cluster aus. Am Beispiel des Data Warehouse ist das Data Warehouse in mehrere logische Ebenen unterteilt. Auf diese Weise können für unterschiedliche Ebenen von Datenoperationen unterschiedliche Ebenen von Aufgaben erstellt und in unterschiedlichen Ebenen von Aufgabenabläufen ausgeführt werden (ein Cluster in einem großen Unternehmen verfügt normalerweise über Tausende oder sogar Zehntausende geplanter Aufgaben, die darauf warten, ausgeführt zu werden). Da die Unterteilungen jeden Tag unterschiedlich sind, werden Aufgaben auf verschiedenen Ebenen in entsprechenden Aufgabenabläufen ausgeführt, was die Verwaltung und Wartung erleichtert.
03 Missverständnisse über Layering
Die interne Aufteilung der Data-Warehouse-Schicht ist nicht Layering um der Layering willen, um die Organisation von ETL-Aufgaben und -Workflows, den Datenfluss und die Kontrolle zu lösen Lese- und Schreibberechtigungen. Verschiedene Probleme, z. B. die Erfüllung unterschiedlicher Anforderungen.
Eine gängige Praxis in der Branche besteht darin, die gesamte Data Warehouse-Schicht in viele Schichten wie DWD, DWT, DWS, DIM, DM usw. zu unterteilen. Wir konnten jedoch nie die klaren Grenzen zwischen diesen Ebenen erkennen oder die Grenzen zwischen ihnen klar erklären. Die komplexen Geschäftsszenarien hindern uns jedoch daran, sie tatsächlich umzusetzen.
Im Allgemeinen sind drei Schichten die grundlegendsten, wenn es um die Datenschichtung geht. Die Segmentierung der DW-Schicht wird auf der Grundlage der spezifischen Geschäftsanforderungen und Unternehmensszenarien definiert. 2. Technische Architektur des Data Warehouse
- Systemarchitektur: Ein Architektursystem, das sich auf Hadoop, Spark und andere Komponenten konzentriert
- Datenarchitektur: Top-Level-Design, Fachdomänenaufteilung, hierarchisches Design, ODS-DW-ADS
- Datenmodellierung: Dimensionsmodellierung, Geschäftsprozess – Granularität bestimmen – Dimension – Faktentabelle
- Datenmanagement: Asset-Management, Metadatenmanagement, Qualitätsmanagement, Stammdatenmanagement, Datenstandards, Daten Sicherheitsmanagement
- Hilfssysteme: Planungssystem, ETL-System, Überwachungssystem
- Datendienste: Datenportal, maschinelles Lernen, Data Mining, Datenabfrage, Analyse, Berichtssystem, Visualisierungssystem , Datenaustausch, Teilen und Herunterladen
3. Data Warehouse-Schichtenarchitektur
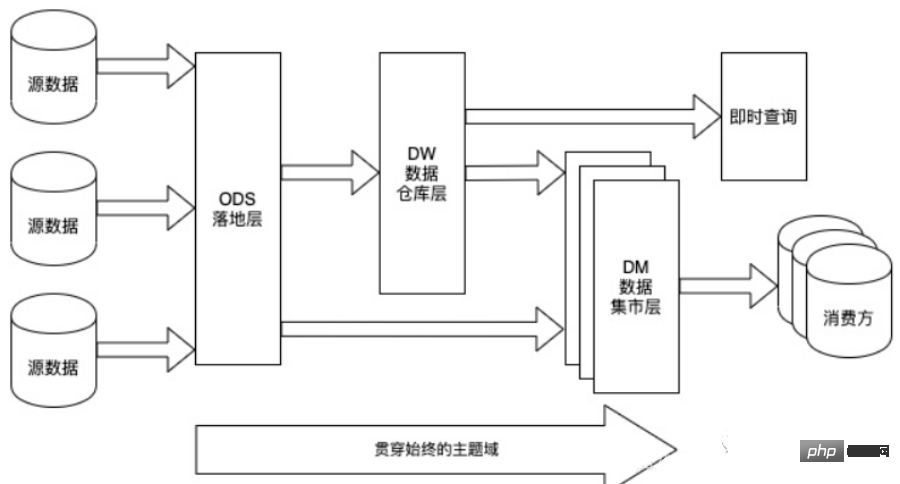
Data Warehouse kann standardmäßig in vier Schichten unterteilt werden. Bitte beachten Sie jedoch, dass diese Aufteilung und Benennung nicht eindeutig ist. Im Allgemeinen haben Data Warehouses vier Ebenen, verschiedene Unternehmen können jedoch unterschiedliche Namen haben. Die Kernkonzepte stammen jedoch alle aus dem vierschichtigen Datenmodell.


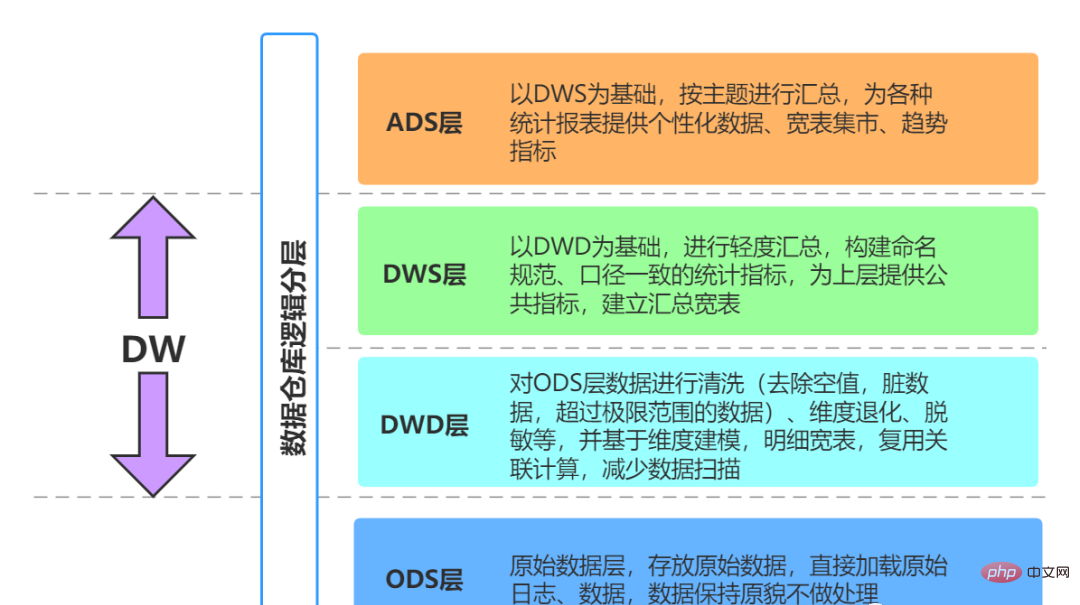
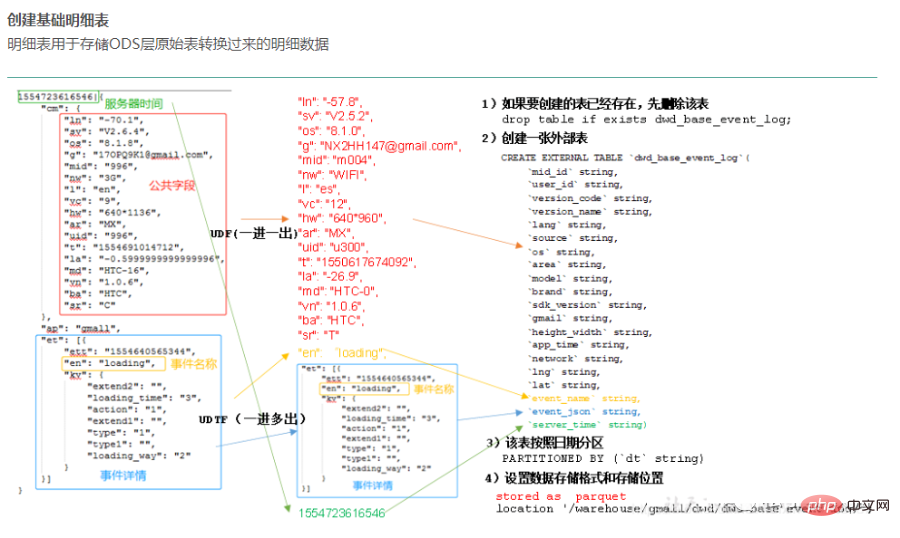
01 Quellschicht einfügen (ODS, Operational Data Store)
Dateneinführungsschicht (ODS, Operational Data Store, auch als Datenbankschicht bekannt). ) : Die Originaldaten werden nahezu ohne Verarbeitung im Data Warehouse-System gespeichert und die Struktur stimmt im Wesentlichen mit dem Quellsystem überein. Es handelt sich um den Datenvorbereitungsbereich des Data Warehouse. Die Hauptaufgabe dieser Schicht besteht darin, Basisdaten zu synchronisieren und zu speichern.
Im Allgemeinen sind die Daten der ODS-Schicht und die Daten des Quellsystems isomorph, und der Hauptzweck besteht darin, die nachfolgende Datenverarbeitung zu vereinfachen. In Bezug auf die Datengranularität ist die Datengranularität der ODS-Schicht in Ordnung. Tabellen in der ODS-Schicht umfassen normalerweise zwei Typen: einen zum Speichern der aktuellen Daten, die geladen werden müssen, und einen zum Speichern der historischen Daten nach der Verarbeitung. Historische Daten werden in der Regel 3–6 Monate lang gespeichert und müssen dann aus Platzgründen gelöscht werden. Allerdings sollten unterschiedliche Projekte unterschiedlich behandelt werden. Wenn die Datenmenge im Quellsystem nicht groß ist, können sie über einen längeren Zeitraum aufbewahrt oder sogar vollständig gespeichert werden.
Hinweis: Auf dieser Ebene sollte es sich nicht um einen einfachen Datenzugriff handeln, sondern es sollten bestimmte Datenbereinigungen in Betracht gezogen werden, z. B. die Verarbeitung abnormaler Felder, die Standardisierung der Feldbenennung, die Vereinheitlichung von Zeitfeldern usw. Im Allgemeinen gilt: Diese werden leicht übersehen, sind aber lebenswichtig. Dies wird insbesondere dann sehr nützlich sein, wenn wir später verschiedene Funktionen automatisch generieren.
Hinweis: Die ODS-Schicht einiger Unternehmen führt keine übermäßige Datenfilterung durch und wird zur Verarbeitung in der DWD-Schicht platziert. Einige Unternehmen führen von Anfang an eine relativ verfeinerte Filterung der Daten auf der ODS-Ebene durch. Dies ist nicht klar definiert und hängt von den eigenen Vorstellungen und technischen Spezifikationen des jeweiligen Unternehmens ab.
Die allgemeine Unternehmensentwicklung führt einige grundlegende Verarbeitungen durch, wenn die Originaldaten in ODS gespeichert werden.
Datenquellendifferenzierung
Daten werden nach Zeitpartitionen gespeichert, normalerweise nach Tag, und einige Unternehmen verwenden dreistufige Partitionen für Jahr, Monat und Tag zur Speicherung.
Führen Sie die grundlegendste Datenverarbeitung durch, z. B. das Verwerfen von Formatfehlern, das Herausfiltern fehlender Schlüsselinformationen usw.
Daten in Echtzeit offline
- Offline-Aspekte: täglich geplante Aufgaben: Ausführen von Batch-Aufgaben, Geschäftsbibliotheken, wie unsere typischen täglichen Computeraufgaben, bei denen Sqoop häufig zum Extrahieren verwendet wird, beispielsweise extrahieren wir regelmäßig einmal am Tag. Berechnen Sie jeden frühen Morgen die Daten des Vortages und lesen Sie den Bericht am Morgen. Diese Art von Aufgabe wird häufig mit Hive und Spark berechnet und die Endergebnisse werden in Hive, Hbase, Mysql, Es oder Redis geschrieben.
- Echtzeitdaten: Vergrabene Daten oder Geschäftsbibliothek protokollieren. Dieser Teil wird hauptsächlich von verschiedenen Echtzeitsystemen verwendet, z. B. von unseren Echtzeitempfehlungen und Echtzeit-Benutzerporträts Streaming und Flink fallen schließlich in Es, Hbase oder Redis. Die Datenquelle ist eine Geschäftsdatenbank. Sie können Canal verwenden, um das Binlog von MySQL zu überwachen und in Echtzeit darauf zuzugreifen. Anschließend werden sie ebenfalls in der Nachrichtenwarteschlange gesammelt und schließlich von Camus an HDFS übertragen.
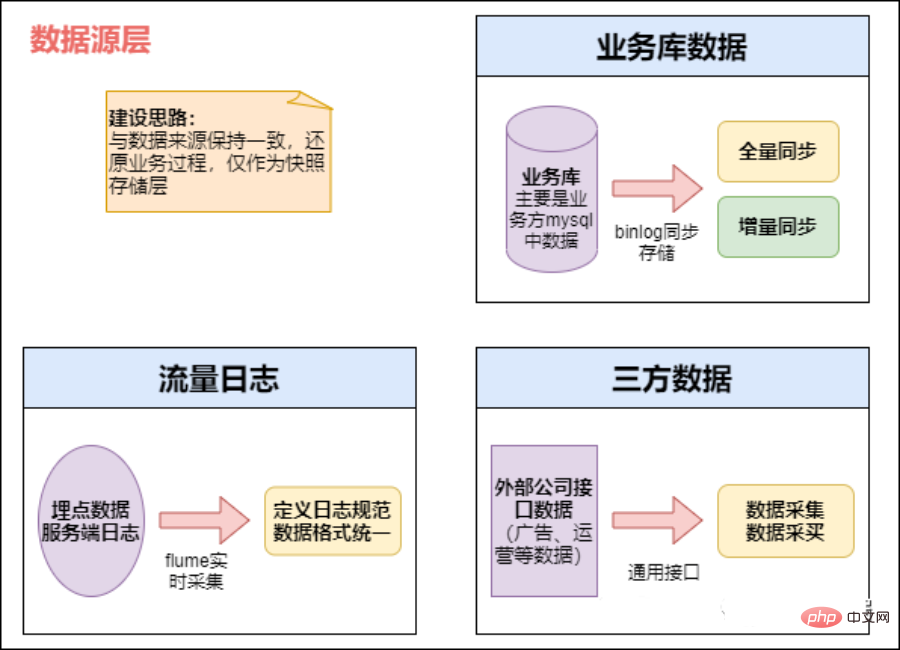
1) Hauptdatenquelle:
- Die Datenquelle ist die Unternehmensdatenbank. Die von allen Systemen des Unternehmens generierten Daten
- werden vom Kunden gemeldet und gesammelt aus Benutzerverhaltensprotokollen sowie Protokolltyp-Datenquellen für einige Backend-Protokolle. Bei vergrabenen Verhaltensprotokollen erfolgt normalerweise ein Prozess wie dieser. Zuerst werden die Daten an Nginx gemeldet und dann von Flume gesammelt. Anschließend werden sie in einer Nachrichtenwarteschlange wie Kafka gespeichert und dann in Echtzeit abgerufen oder Offline-Pull-Aufgaben. Holen Sie sich unsere Offline-Data-Warehouse-HDFS
- externe Daten (einschließlich kooperativer Daten und von Crawlern erhaltener Daten) und fassen Sie die gesammelten Daten zusammen
2) Datenspeicherstrategie (inkrementell). , volle Menge)
In der tatsächlichen Anwendung können Sie wählen, ob Sie inkrementelle Speicherung, vollständige Speicherung oder Reißverschluss-Speicherung verwenden möchten.
- Inkrementeller Speicher
Um den Anforderungen der historischen Datenanalyse gerecht zu werden, können Sie die Zeitdimension als Partitionsfeld in der ODS-Layer-Tabelle hinzufügen. Inkrementeller Speicher in Tagen, mit Geschäftsdaten als Partitionen, und jede Partition speichert täglich inkrementelle Geschäftsdaten.
Zum Beispiel:
Am 1. Januar besuchte Benutzer A den E-Commerce-Shop B von Unternehmen A, und das E-Commerce-Protokoll von Unternehmen A generierte einen Datensatz t1. Am 2. Januar besuchte Benutzer A erneut Nach dem Betreten des E-Commerce-Shops C von Unternehmen A generiert das E-Commerce-Protokoll von Unternehmen A einen Datensatz t2.
Bei Verwendung der inkrementellen Speichermethode wird t1 am 1. Januar in der Partition und t2 am 2. Januar in der Partition gespeichert.
Am 1. Januar hat Benutzer A Produkt B auf der E-Commerce-Website von Unternehmen A gekauft, und das Transaktionsprotokoll generiert einen Datensatz t1. Am 2. Januar hat Benutzer A Produkt B erneut zurückgegeben, und das Transaktionsprotokoll wird angezeigt aktualisiert. t1-Datensatz.
Bei Verwendung der inkrementellen Speichermethode wird der ursprünglich erworbene t1-Datensatz am 1. Januar in der Partition gespeichert und der aktualisierte t1-Datensatz wird am 2. Januar in der Partition gespeichert.
ODS-Tabellen mit starker Transaktionsnatur wie Transaktionen und Protokolle eignen sich für die inkrementelle Speicherung. Diese Art von Tabelle enthält große Datenmengen und die Speicherkosten für die Nutzung des vollen Speichers sind hoch. Darüber hinaus besteht bei nachgelagerten Anwendungen solcher Tabellen ein geringerer Bedarf an vollständigem Zugriff auf historische Daten (dieser Bedarf kann durch anschließende Aggregation durch das Data Warehouse gedeckt werden). Beispielsweise verfügt eine Protokoll-ODS-Tabelle nicht über einen Datenaktualisierungsgeschäftsprozess, daher werden alle inkrementellen Partitionen mit UNION zusammengefügt, um einen vollständigen Datensatz zu bilden.
- Voller Speicher
Voller Speicher in Tagen, mit dem Geschäftsdatum als Partition, und jede Partition speichert die vollständigen Geschäftsdaten bis zum Geschäftsdatum.
Zum Beispiel hat Verkäufer A am 1. Januar zwei Produkte, B und C, auf der E-Commerce-Website von Unternehmen A veröffentlicht. Am 2. Januar generiert die Front-End-Produkttabelle zwei Datensätze A wird Produkt B aus den Regalen entfernt und Produkt D wird gleichzeitig freigegeben. Die Front-End-Produkttabelle aktualisiert Datensatz t1 und erstellt einen neuen Datensatz t3. Bei Verwendung der Vollspeichermethode werden am 1. Januar zwei Datensätze von t1 und t2 in der Partition gespeichert, und die aktualisierten Datensätze t1, t2 und t3 werden am 2. Januar in der Partition gespeichert.
Für sich langsam ändernde Dimensionsdaten mit einer kleinen Datenmenge, wie z. B. Produktkategorien, kann direkt der volle Speicher verwendet werden.
- Zip Storage
Zip Storage zeichnet alle Änderungsdaten mit täglicher Granularität auf, indem zwei neue Zeitstempelfelder (start_dt und end_dt) hinzugefügt werden.
Lösung
Konzept: Wird auch als Schnittstellenschicht (Stufe) bezeichnet und zum Speichern täglicher inkrementeller Daten und Änderungsdaten verwendet.
Datengenerierungsmethode: Empfangen der Quelle direkt von Kafka Daten muss die Geschäftstabelle jeden Tag Aktualisierungs-, Lösch- und Einfügungsdaten generieren. Es wird nur die Geschäftstabelle für Einfügungsdaten generiert und die Daten werden direkt in die Detailebene eingegeben.
Diskussionsplan: Legen Sie den Kanalstamm nur direkt in die Pufferschicht. Wenn es andere Unternehmen mit Reißverschlussdaten gibt, legen Sie diese ebenfalls in die Pufferschicht ein.
Protokollspeichermethode: Verwendung des Impala-Erscheinungsbilds und des Parkett-Dateiformats, um das Lesen von Daten zu erleichtern, die eine MR-Verarbeitung erfordern.
Protokolllöschmethode: Langzeitspeicherung, nur die Daten der letzten Tage können gespeichert werden. Diskussionsplan: direkte Langzeitspeicherung.
Tabellenschema: Partitionen werden im Allgemeinen täglich erstellt und die Partitionierung nach wird im Allgemeinen täglich gespeichert.
Bibliotheks- und Tabellenbenennung. Bibliotheksname: ods, Tabellenname: Das anfängliche Überlegungsformat ist der Name der ods-Datumsgeschäftstabelle, der noch festgelegt werden muss. Die externe Tabelle von
hive entspricht der Business-Tabelle.
Bei externen Hive-Tabellen befinden sich die Dateien, in denen Daten gespeichert sind, möglicherweise nicht am Standardspeicherort des Hive-HDFS. Wenn die entsprechende Hive-Tabelle gelöscht wird, werden die entsprechenden Datendateien nicht gelöscht. Dies ist für die Unternehmensentwicklung geeignet Um zu verhindern, dass durch den Tabellenlöschvorgang wertvolle Daten aus der Hive-Geschäftstabelle gelöscht werden, werden die Datendateien auch am Standardspeicherort des Hive gespeichert gelöscht.
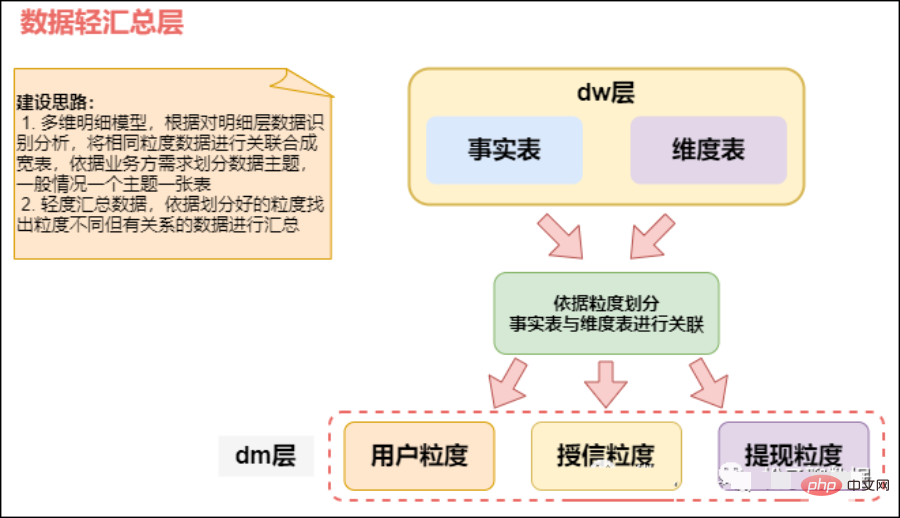
02 Data Warehouse (DW)
Data Warehouse (DW)-Schicht: Die Data Warehouse-Schicht ist die Kernentwurfsschicht, wenn wir Data Warehouse erstellen. Diese Schicht wird von ODS abgeleitet Die Ebene des Data Warehouse schließt Themen aus, die für die Entscheidungsfindung unbrauchbar sind. Jedes Thema entspricht einem Makroanalysebereich. Alle historischen Daten im BI-System werden auf der DW-Ebene gespeichert, beispielsweise Daten aus 10 Jahren.
DW speichert detaillierte Faktendaten, Dimensionstabellendaten und öffentliche Indikatorzusammenfassungsdaten. Darunter werden detaillierte Faktendaten und Dimensionstabellendaten im Allgemeinen auf der Grundlage der Datenverarbeitung auf der ODS-Ebene generiert. Zusammenfassende Daten zu öffentlichen Indikatoren werden im Allgemeinen auf der Grundlage von Dimensionstabellendaten und detaillierten Faktendaten generiert.
Die DW-Schicht ist in die Dimensionsschicht (DIM), die detaillierte Datenschicht (DWD) und die zusammenfassende Datenschicht (DWS) unterteilt, die als theoretische Grundlage und als Primärschlüssel verwendet wird Das dimensionale Modell und der Fremdschlüssel im Faktenmodell können Beziehungen definiert werden, wodurch Datenredundanz reduziert und die Benutzerfreundlichkeit detaillierter Datentabellen verbessert wird. In der zusammenfassenden Datenschicht können auch Dimensionen in der wiederverwendeten statistischen Granularität zugeordnet werden, und breitere Tabellenmethoden können zum Aufbau der Datenschicht für öffentliche Indikatoren verwendet werden, um die Wiederverwendbarkeit öffentlicher Indikatoren zu verbessern und wiederholte Verarbeitungen zu reduzieren.
Dimensionsebene (DIM, Dimension): Unter Verwendung von Dimensionen als Modellierungstreiber wird die Berechnungslogik basierend auf der Geschäftsbedeutung jeder Dimension durch Hinzufügen von Dimensionsattributen, zugehörigen Dimensionen usw. definiert, um die Attributdefinition zu vervollständigen Verarbeiten und erstellen Sie eine konsistente Datenanalyse-Dimensionstabelle. Um redundant zugeordnete Dimensionsattribute im Dimensionsmodell zu vermeiden, wird eine Dimensionstabelle basierend auf dem Schneeflockenmodell erstellt.
Detaillierte Datenschicht (DWD, Data Warehouse Detail): Unter Verwendung des Geschäftsprozesses als Modellierungstreiber wird die detaillierteste Faktentabelle basierend auf den Merkmalen jedes einzelnen Geschäftsprozesses erstellt. Einige wichtige Attributfelder können entsprechend redundant ausgelegt werden, d. h. es können breite Tabellen verarbeitet werden.
Data Warehouse Summary (DWS): Unter Verwendung des analysierten Subjektobjekts als Modellierungstreiber wird eine öffentlich-granulare zusammenfassende Indikatortabelle erstellt, die auf den Indikatoranforderungen von Anwendungen und Produkten der oberen Schicht basiert. Verwenden Sie Wide-Table-Methoden, um das Modell zu physikalischisieren, statistische Indikatoren mit Benennungsstandards und konsistenten Kalibern zu erstellen, öffentliche Indikatoren für die obere Schicht bereitzustellen und zusammenfassende Wide-Tables und detaillierte Faktentabellen zu erstellen.
Themendomäne: orientiert an Geschäftsprozessen, abstrakte Sammlung von Geschäftsaktivitätsereignissen wie Auftragserteilung, Zahlung und Rückerstattung sind alles Geschäftsprozesse. Themenpartitionierung für den Common Level of Detail (DWD).
Datendomäne: Für die Geschäftsanalyse handelt es sich um eine abstrakte Sammlung von Geschäftsprozessen oder -dimensionen. Datendomänenpartitionierung für die Common Summary Layer (DWS).
Die DWD-Schicht wird durch Geschäftsprozesse gesteuert.
DWS-Schicht, DWT-Schicht und ADS-Schicht sind alle nachfragegesteuert.
DWD: Data Warehouse-Details Datendetailebene. Führen Sie hauptsächlich einige Datenbereinigungs- und Standardisierungsvorgänge auf der ODS-Datenschicht durch.
Datenbereinigung: Entfernen Sie Nullwerte, fehlerhafte Daten, die Konvertierung von Aufzählungswerten und solche, die den Grenzbereich überschreiten.
DWB: Data Warehouse-Basisdatenbankschicht, die objektive Daten speichert. Sie wird im Allgemeinen als Zwischenschicht verwendet und kann als Datenschicht für eine große Anzahl von Indikatoren betrachtet werden.
DWS: Data Warehouse-Dienstdatendienstschicht, basierend auf den Basisdaten von DWB, integriert und zusammengefasst in einer Dienstdatenschicht zur Analyse eines bestimmten Themenbereichs, normalerweise einer breiten Tabelle. Wird zur Bereitstellung nachfolgender Geschäftsabfragen, OLAP-Analyse, Datenverteilung usw. verwendet.
Benutzerverhalten, leichte Aggregation
Erstellen Sie hauptsächlich eine leichte Zusammenfassung der ODS/DWD-Layer-Daten.
1) Öffentliche Dimensionsebene (DIM, Dimension)
DIM: Diese Ebene ist relativ einfach, indem Sie ein Beispiel wie Ländercode und Ländername, geografischen Standort usw. angeben. Chinesischer Name und Nationalflagge werden in der DIM-Schicht gespeichert.
Basierend auf dem Konzept der dimensionalen Modellierung etablieren Sie konsistente Dimensionen im gesamten Unternehmen. Reduzieren Sie das Risiko inkonsistenter Datenberechnungskalibern und -algorithmen.
Die öffentliche Dimensionszusammenfassungsschicht (DIM) besteht hauptsächlich aus Dimensionstabellen (Dimensionstabellen). Dimension ist ein logisches Konzept, eine Perspektive, aus der sich Geschäfte messen und beobachten lassen. Dimensionstabellen sind Tabellen, die auf der Datenplattform erstellte Tabellen basierend auf Dimensionen und ihren Attributen physischisieren und das Prinzip des breiten Tabellendesigns übernehmen. Daher müssen beim Aufbau einer Common Dimensions Summary Layer (DIM) zunächst die Dimensionen definiert werden.
Dimensionale Daten mit hoher Kardinalität: im Allgemeinen Datentabellen, die Benutzerdatentabellen und Produktdatentabellen ähneln. Die Datenmenge kann Dutzende Millionen oder Hunderte Millionen betragen.
Dimensionale Daten mit niedriger Kardinalität: Normalerweise eine Konfigurationstabelle, z. B. die chinesische Bedeutung, die dem Aufzählungswert entspricht, oder eine Datumsdimensionstabelle. Die Datenmenge kann einstellige oder zehntausende sein.
Bemaßungstabelle entwerfen:
Nach Abschluss der Bemaßungsdefinition können Sie die Bemaßungen ergänzen und die Bemaßungstabelle erstellen. Die Gestaltung von Maßtabellen erfordert Aufmerksamkeit:
Es wird empfohlen, dass die Informationen in der Maßformtabelle 10 Millionen Teile nicht überschreiten.
Beim Verbinden einer Dimensionstabelle mit anderen Tabellen wird empfohlen, Map Join
zu verwenden, um zu vermeiden, dass die Daten der Dimensionstabelle zu häufig aktualisiert werden. Sich langsam ändernde Dimensionen: Zipper-Tabelle
Public Dimension Summary Layer (DIM)-Dimensionstabellenspezifikation
Public Dimension Summary Layer (DIM)-Dimensionstabellenbenennungsspezifikation: dim_{Geschäftssegmentname/pub} _{Dimensionsdefinition}[_{Benutzerdefiniertes Namens-Tag}], der sogenannte Pub ist eine Dimension, die nichts mit dem spezifischen Geschäftsbereich zu tun hat oder allen Geschäftsbereichen gemeinsam ist, wie beispielsweise die Zeitdimension.
Zum Beispiel: Dimensionstabelle für den öffentlichen Bereich dim_pub_area Produktdimensionstabelle dim_asale_itm
Der Grad der Geschäftsdetails, der durch einen Datensatz in der Faktentabelle ausgedrückt wird, wird als Granularität bezeichnet. Im Allgemeinen kann die Granularität auf zwei Arten ausgedrückt werden: Zum einen durch den Detaillierungsgrad, der durch die Kombination von Dimensionsattributen dargestellt wird, und zum anderen durch die dargestellte spezifische Geschäftsbedeutung. Transparent! Gängige Modellierungsmethoden und praktische Beispiele im Data Warehouse-Bereich.
Modellierungsmethoden und -prinzipien
Es ist notwendig, ein Dimensionsmodell zu erstellen, im Allgemeinen unter Verwendung eines Sternmodells, und der dargestellte Zustand ist im Allgemeinen ein Konstellationsmodell (bestehend aus mehreren Faktentabellen, der Dimensionstabelle). ist öffentlich und kann von mehreren Faktentabellen gemeinsam genutzt werden); und die DWD-bezogene Tabelle des Vortages kann für die Zusammenführungsverarbeitung verwendet werden?
Granularität bedeutet, dass eine Informationszeile ein Verhalten darstellt, beispielsweise das Aufgeben einer Bestellung.
Dimensionale Modellierungsschritte
Geschäftsprozess auswählen: Wählen Sie im Geschäftssystem den Geschäftsbereich aus, der Sie interessiert, z. B. Bestellgeschäft, Zahlungsgeschäft, Rückerstattungsgeschäft, Logistikgeschäft, einem Geschäftsbereich, der entspricht eine Faktentabelle. Wenn es sich um ein kleines oder mittleres Unternehmen handelt, versuchen Sie, alle Geschäftsprozesse auszuwählen. Wenn es sich bei DWD um ein großes Unternehmen (mehr als 1.000 Tische) handelt, wählen Sie den Geschäftsbereich, der Ihren Anforderungen entspricht.
Deklarationsgranularität: Datengranularität bezieht sich auf den Grad der Verfeinerung oder Vollständigkeit der im Data Warehouse gespeicherten Daten. Granularität zu deklarieren bedeutet, genau zu definieren, was eine Datenzeile in der Faktentabelle darstellt. Sie sollten die kleinstmögliche Granularität wählen, um verschiedenen Anforderungen gerecht zu werden. Eine typische Granularitätsanweisung lautet wie folgt: Jeder Artikel in der Bestellung wird als Zeile in der Bestellfaktentabelle behandelt, und die Granularität beträgt jedes Mal. Die Anzahl der Bestellungen pro Woche wird als Zeile angegeben, wobei die Granularität wöchentlich ist. Die Anzahl der Bestellungen pro Monat wird als Zeile dargestellt, wobei die Granularität monatlich ist. Wenn die Granularität auf der DWD-Ebene wöchentlich oder monatlich ist, wird es in Zukunft keine Möglichkeit mehr geben, feinkörnige Indikatoren zu zählen. Daher wird empfohlen, die kleinste Granularität zu verwenden.
Dimensionen bestimmen: Die Hauptaufgabe von Dimensionen besteht darin, geschäftliche Fakten zu beschreiben, die hauptsächlich Informationen wie „Wer, wo, wann“ darstellen. Das Prinzip zur Bestimmung von Dimensionen lautet: ob Indikatoren relevanter Dimensionen in nachfolgenden Anforderungen analysiert werden sollen. Beispielsweise werden Statistiken benötigt, um festzustellen, wann mehr Bestellungen aufgegeben wurden, welche Region mehr Bestellungen aufgegeben hat und welcher Benutzer mehr Bestellungen aufgegeben hat. Zu den Dimensionen, die bestimmt werden müssen, gehören: Zeitdimension, regionale Dimension und Benutzerdimension. Dimensionstabelle: Die Dimensionsverschlechterung muss bei der Dimensionsmodellierung nach dem Sternschemaprinzip durchgeführt werden.
Bestimmen Sie die Fakten: Das Wort „Tatsache“ bezieht sich hier auf den Messwert im Unternehmen (Häufigkeit, Stückzahl, Stückzahl, Menge, die akkumuliert werden kann), wie z. B. Bestellmenge, Anzahl der Bestellungen usw. In der DWD-Schicht wird der Geschäftsprozess als Modellierungstreiber verwendet und die detaillierteste Faktentabelle der Detailschicht wird basierend auf den Merkmalen jedes einzelnen Geschäftsprozesses erstellt. Die Faktentabelle kann entsprechend erweitert werden.
Hinweis: Die DWD-Schicht wird durch Geschäftsprozesse gesteuert. Die DWS-Schicht, die DWT-Schicht und die ADS-Schicht sind alle bedarfsgesteuert und haben nichts mit dimensionaler Modellierung zu tun. Sowohl DWS als auch DWT erstellen breite Tabellen und erstellen Tabellen nach Themen. Das Thema entspricht der Perspektive, aus der das Problem betrachtet wird. Entspricht der Maßtabelle.
Über das Thema:
Die Daten im Data Warehouse sind nach Themen organisiert, um die Daten im Unternehmensinformationssystem auf einer höheren Ebene zu synthetisieren, zu klassifizieren und zu analysieren Konzepten entspricht jedes Thema grundsätzlich einem Makroanalysefeld. Beispielsweise ist die Finanzanalyse ein Analysefeld, daher lautet das Thema dieser Data Warehouse-Anwendung „Finanzanalyse“.
Über den Themenbereich:
Ein Themenbereich ist normalerweise eine Sammlung eng verwandter Datenthemen. Diese Datenthemen können je nach Geschäftsanliegen in verschiedene Themenbereiche unterteilt werden (d. h. die Themengrenzen werden nach der Analyse eines Themas festgelegt)
Über die Aufteilung der Themenbereiche:
Die Bestimmung der Betreffdomäne muss gemeinsam vom Endbenutzer (Unternehmen) und dem Data Warehouse-Designer durchgeführt werden. Bei der Aufteilung der Betreffdomäne können die unterschiedlichen Einstiegspunkte aller Beteiligten zu einigen Debatten, Umgestaltungen usw. führen einige der folgenden Aspekte sein:
- Unterteilt nach Geschäft oder Geschäftsprozess: Beispielsweise kann eine Portal-Website, die auf den Verkauf von Werbepositionen angewiesen ist, über eine Werbedomäne, eine Kundendomäne usw. und die Werbung verfügen Domäne kann sein: Werbeinventar, Verkaufsanalyse, interne Lieferanalyse und andere Themen; Bereich, und der Finanzthemenbereich kann Folgendes umfassen: Es wird Themen wie Mitarbeitergehaltsanalyse, Analyse der Kapitalrenditequote usw. geben, unterteilt nach Funktionen oder Anwendungen: wie dem Datenfeld „Freundeskreis“, Gruppe Chat-Datenfeld usw. in WeChat und das Freundeskreis-Datenfeld können dynamische Informationsthemen, Werbethemen usw. enthalten Domänen usw. Im operativen Bereich kann es Themen wie Analyse der Gehaltsausgaben, Analyse der Wirkung von Veranstaltungsförderung usw. geben Logiken. Während des Konstruktionsprozesses kann ein iterativer Ansatz gewählt werden, anstatt sich darauf zu konzentrieren, alle Themen auf einmal zu abstrahieren, können Sie mit klar definierten Themen beginnen und diese dann schrittweise in einem Standardmodell für Ihre eigene Branche zusammenfassen.
- Themen: Parteien, Marketing, Finanzen, Vertragsvereinbarung, Organisation, Adresse, Kanal, Produkt,
- Was sind die Finanzgeschäftsthemen: lassen sich in vier Themenbereiche unterteilen:
- Benutzerthema (Benutzeralter, Geschlecht, Lieferadresse, Telefonnummer, Provinz usw.)
Transaktionsthema (Bestelldaten, Rechnungsdaten usw.)
Risikokontrollthema (Benutzer Risikokontrollebene, Kreditdaten von Drittanbietern)
Marketingthemen (Marketingaktivitätsliste, Aktivitätskonfigurationsinformationen usw.)
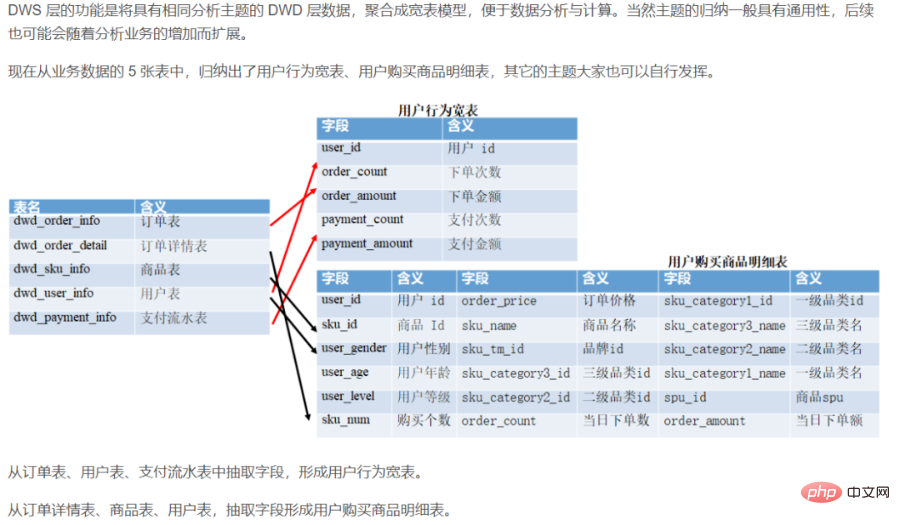
- 2) DWD-Datendetailebene (Data Warehouse Detail), granular Faktenschicht
- DWD ist die Isolationsschicht zwischen der Geschäftsschicht und dem Data Warehouse. Diese Schicht löst hauptsächlich einige Datenqualitätsprobleme und Datenintegritätsprobleme.
- Die detaillierte Tabelle wird zum Speichern der detaillierten Daten verwendet, die aus der Originaltabelle der ODS-Schicht konvertiert wurden. Die Daten der DWD-Schicht sollten konsistente, genaue und saubere Daten sein, dh die Daten der Quellsystemdaten-ODS-Schicht Daten sollten bereinigt werden (leere Daten entfernen, schmutzige Daten, Daten, die den Grenzbereich überschreiten, Zeilenspeicher in Spaltenspeicher ändern, Komprimierungsformat ändern), Normalisierung, Dimensionsverschlechterung, Desensibilisierung und andere Vorgänge. Benutzerdateninformationen stammen beispielsweise aus vielen verschiedenen Tabellen, und es treten häufig Probleme wie verzögerter Datenverlust auf. Um jedem Benutzer die bessere Nutzung der Daten zu erleichtern, können wir auf dieser Ebene einen Schutzschild erstellen. Diese Ebene enthält auch einheitliche Dimensionsdaten.
Verantwortlich für die detailliertesten Daten der Daten, basierend auf der DWD-Schicht, leicht zusammengefasst, kombiniert mit gemeinsamen Dimensionen (Zeit, Ort, Organisationsebene, Benutzer, Produkte usw.)
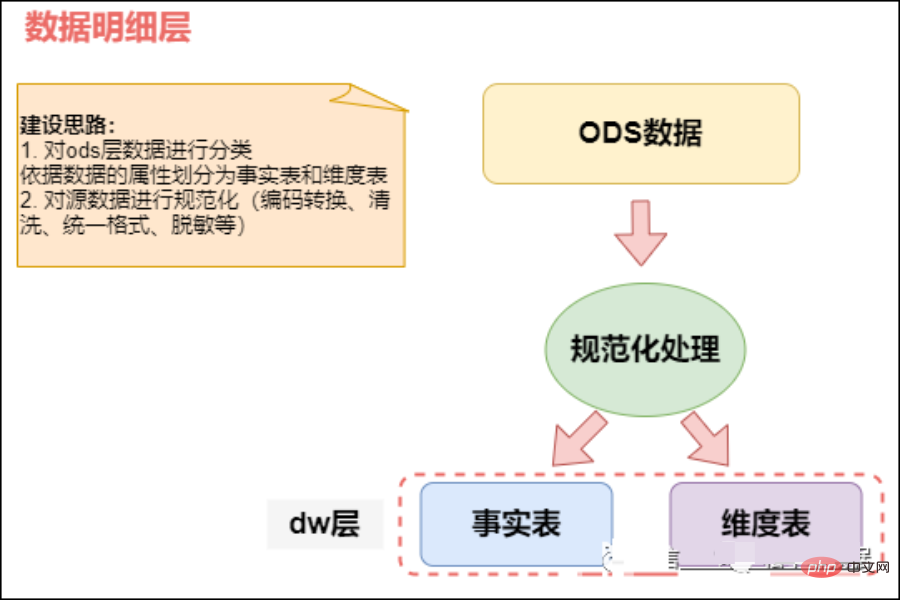
Diese Schicht behält im Allgemeinen die gleiche Datengranularität wie die ODS-Schicht bei und bietet eine gewisse Datenqualitätsgarantie. Die Daten werden auf der Grundlage von ODS verarbeitet, um sauberere Daten bereitzustellen. Um die Benutzerfreundlichkeit der Datendetailschicht zu verbessern, wendet diese Schicht gleichzeitig einige Techniken zur Dimensionsverschlechterung an. Wenn eine Dimension keine vom Data Warehouse benötigten Daten enthält, kann die Dimension herabgestuft werden zur Faktentabelle herabgestuft, wodurch die Anzahl der Faktentabellen und Dimensionstabellenzuordnungen verringert wird.
Zum Beispiel:
Bestell-ID, eine so große Dimension, es ist nicht erforderlich, eine Dimensionstabelle zum Speichern zu verwenden, und die Bestell-ID ist im Allgemeinen sehr wichtig, wenn wir eine Datenanalyse durchführen, daher haben wir die Die Bestell-ID ist in der Faktentabelle redundant. Diese Dimension ist eine degenerierte Dimension.
Die Daten auf dieser Ebene folgen im Allgemeinen der dritten Normalform oder dimensionalen Modellierung der Datenbank, und ihre Datengranularität entspricht normalerweise der von ODS. Alle historischen Daten im BI-System werden auf der PDW-Ebene gespeichert, beispielsweise Daten aus 10 Jahren.
Die folgenden Arbeiten müssen durchgeführt werden, bevor die Daten in diese Ebene geladen werden: Rauschunterdrückung, Deduplizierung, Schmutzentfernung, Geschäftsextraktion, Einheitsvereinigung, Feldschneiden und Geschäftsidentifizierung.
Arten der bereinigten Daten:
- Unvollständige Daten
- Fehlerdaten
- Doppelte Daten
Die Aufgabe der Datenbereinigung ist Filter die Daten, die den Anforderungen nicht entsprechen, und übermitteln Sie die gefilterten Ergebnisse an die Geschäftsabteilung, um vor der Extraktion zu bestätigen, ob sie von der Geschäftseinheit herausgefiltert oder korrigiert wurden.
Was macht die DWD-Schicht?
①Datenbereinigung und -filterung
Entfernen Sie verlassene Felder, entfernen Sie falsch formatierte Informationen
Entfernen Sie Informationen, die Schlüssel verloren haben Filterkernfeld sind bedeutungslose Daten, Beispielsweise ist die Bestell-ID in der Bestelltabelle null und die Zahlungs-ID in der Zahlungstabelle leer.
Sensibilisieren Sie vertrauliche Daten wie Mobiltelefonnummern und ID-Nummern keine Zeitinformationen enthalten (Dies hängt vom spezifischen Geschäft des Unternehmens ab, aber im Allgemeinen werden die Daten mit einem Zeitstempel versehen, um die anschließende Verarbeitung, Informationsanalyse, Verarbeitung und Extraktion in der Zeitdimension zu erleichtern)
Einige Unternehmen drucken auch Die Daten auf dieser Ebene sind flach, dies hängt jedoch von den Geschäftsanforderungen ab. Dies liegt daran, dass Kylin für die Verarbeitung abgeflachter Daten geeignet ist, jedoch nicht für die Verarbeitung verschachtelter Tabellendateninformationen. Einige Unternehmen schneiden auch die Datensitzung ab. Dies liegt normalerweise daran, dass die App für andere Geschäftsszenarien nicht geeignet ist. Beispielsweise öffnet der Benutzer die App 10 Minuten lang und dann wechselt die App in den Hintergrund Zu diesem Zeitpunkt ist die Sitzung immer noch eine, und eigentlich sollte sie unterbrochen werden. (Es gibt auch Unternehmen, die die Aufzeichnungen der App im Hintergrund aufzeichnen und die Rezeption erneut betreten Sitzungsausschnitt)
②Datenzuordnung und -konvertierung
Konvertieren Sie GPS-Längen- und Breitengrad in Provinz- und Stadtdetails, Adresse. Gängige GPS-Schnellabfragen in der Branche verwenden im Allgemeinen Geohash, um die Wissensbasis für den geografischen Standort abzubilden, das zu vergleichende GPS dann in Geohash umzuwandeln und dann den Geohash in der Wissensdatenbank zu vergleichen, um die geografischen Standortinformationen herauszufinden Unternehmen, die offene APIs verwenden, wie z. B. Amap, die API von Baidu Map, stellen GPS und geografische Standortinformationen dar, aber es kostet Geld, eine bestimmte Anzahl von Malen zu erreichen, sodass jeder weiß, dass die IP-Adresse auch in detaillierte Adressen von Provinzen umgewandelt wird Städte. Es gibt viele Schnellsuchbibliotheken, aber das Grundprinzip ist die binäre Suche, da die IP-Adresse in eine lange Ganzzahl umgewandelt werden kann. Ein typisches Beispiel ist die ip2region-Bibliothek
, die Zeit in Jahr, Monat, Tag oder umwandelt Informationen zu geraden Wochen- und Quartalsdimensionen
Datenstandardisierung, da die von Big Data verarbeiteten Daten aus verschiedenen Abteilungen des Ressourcenunternehmens, verschiedenen Projekten und verschiedenen Kunden stammen können. Zu diesem Zeitpunkt handelt es sich um dieselben Geschäftsdatenfelder Typen, Nullwerte usw. können zu diesem Zeitpunkt unterschiedlich sein. Glätten Sie die DWD-Ebene. Andernfalls wird es bei der nachfolgenden Verarbeitung zu großen Problemen kommen mit true und false. Die Werte können entweder „“ oder null sein Zum Beispiel das Datumsformat, das unterschiedlicher ist und auf der Grundlage tatsächlicher Geschäftsdaten bestimmt werden muss, aber im Allgemeinen wird es in Standardformaten wie JJJJ-MM-TT HH:mm:ss Abmessungen formatiert Verschlechterung: Führen Sie eine Dimensionsverschlechterung und Dimensionsreduzierung für die aus Geschäftsdaten übertragenen Tabellen durch. (Produktebene eins, Ebene zwei, Ebene drei, Provinz, Stadt, Landkreis, Jahr, Monat, Tag) Die Bestell-ID ist in der Faktentabelle redundant Wie viele Daten sind sinnvoll zu bereinigen: 1 Datenelement wird aus 10.000 gereinigt. Angemessene Anzahl von Tabellen: Aus zehntausend Tabellen werden dreitausend Tabellen, aus dreitausend Tabellen werden eintausend Tabellen Detaillierte Gestaltungsprinzipien für granulare Faktentabellen: Plan Diskussionsplan: Die Datensynthesemethode ist: Vollständige Menge: Jeden Tag die vollständige Datenmenge von vorgestern und die neuen Daten von gestern werden auf der Detailebene zu einer neuen Datentabelle synthetisiert. Überschreiben Sie die alte Tabelle. Verwenden Sie gleichzeitig die historische Spiegelung, um eine historische Spiegelung nach Woche/Monat/Jahr in einer neuen Tabelle zu speichern. Protokollspeichermethode: Direkte Daten verwenden das Impala-Erscheinungsbild und das Parkett-Dateiformat. Die folgenden Ebenen sind alle aus Impala generierten Daten. Es wird empfohlen, interne Tabellen + statische/dynamische Partitionierung zu verwenden . Tabellenschema: Erstellen Sie im Allgemeinen Partitionen nach Tag und wählen Sie Partitionsfelder entsprechend dem spezifischen Geschäft aus, ohne das Konzept der Zeit. Partitioniert nach wird im Allgemeinen nach Tagen gespeichert. Bibliotheks- und Tabellenbenennung. Bibliotheksname: dwd, Tabellenname: Das anfängliche Überlegungsformat ist der dwd-Datumsname der Geschäftstabelle, der noch festgelegt werden muss. Alte Datenaktualisierungsmethode: direkte Abdeckung Detaillierte Granularity Fact Layer (DWD)-Spezifikation Die Benennungsspezifikation lautet: dwd_{Business Section/pub}_{Abkürzung der Datendomäne } _{Abkürzung für Geschäftsprozesse}[_{Abkürzung für benutzerdefinierte Tabellenbenennungsbezeichnungen}] _{Inkrementelle vollständige Identifizierung einer einzelnen Partition}, pub bedeutet, dass die Daten Daten aus mehreren Geschäftsbereichen enthalten. Die inkrementelle Gesamtmengenkennung einer einzelnen Partition lautet normalerweise: i bedeutet Inkrement, f bedeutet Gesamtmenge. Zum Beispiel: dwd_asale_trd_ordcrt_trip_di (Faktentabelle zur Bestellung von Flugticketbestellungen eines E-Commerce-Unternehmens, tägliche Aktualisierungsinkrement) dwd_asale_itm_item_df (Eine Fakttabelle zur Momentaufnahme eines E-Commerce-Produkts, tägliche Aktualisierung in voller Höhe). In diesem Tutorial besteht die DWD-Ebene hauptsächlich aus drei Tabellen: 3) DWS-Datendienstschicht (Data Warehouse Service), Zusammenfassungsschicht-weite Tabelle Basierend auf der detaillierten DWD-Datenschicht organisieren wir unsere Daten nach einigen Analyseszenarien, Analyseeinheiten, usw. Die zusammenfassende Datenschicht DWS ist in einige Unterthemen unterteilt. Detaillierte Granularität ==> Zusammenfassungsgranularität DWS-Schicht (Datenzusammenfassungsschicht) breite Tabelle, themenorientierte Zusammenfassung, relativ wenige Dimensionen, DWS basiert auf den Grunddaten der DWD-Schicht. Die Dimensions-ID führt eine grobkörnige zusammenfassende Aggregation durch, beispielsweise eine Aggregation nach Transaktionsquelle und Transaktionstyp. Integrieren und fassen Sie Servicedaten zur Analyse eines bestimmten Themenbereichs zusammen, normalerweise in einer breiten Tabelle. Basierend auf DWD, leichte Zusammenfassung pro Tag. Statistiken zum täglichen Verhalten jedes Subjektobjekts (z. B. Kaufverhalten, Statistiken zur Produktwiederkaufrate). In dieser Ebene gibt es relativ wenige Datentabellen, und die meisten davon sind breite Tabellen (eine Tabelle deckt mehr Geschäftsinhalte ab und die Tabelle enthält mehr Felder). Abhängig von den Themen wie Bestellungen, Benutzer usw. wird eine breite Tabelle mit vielen Feldern generiert, um spätere Geschäftsabfragen, OLAP-Analysen, Datenverteilung usw. bereitzustellen. Integrieren Sie mehrere Daten der mittleren Ebene und bilden Sie Faktentabellen basierend auf Themen, z. B. Benutzerfaktentabellen, Kanalfaktentabellen, Terminalfaktentabellen, Anlagenfaktentabellen usw. Faktentabellen sind im Allgemeinen breite Tabellen und werden darauf implementiert Schicht unternehmensweite Datenkonsistenz. Unterteilen Sie zunächst die Geschäftsthemen in Verkaufsdomäne, Inventardomäne, Kundendomäne, Einkaufsdomäne usw. und bestimmen Sie dann die Faktentabelle und Dimensionstabelle jeder Themendomäne. Normalerweise wird es basierend auf den Geschäftsanforderungen in Verkehr, Bestellungen, Benutzer usw. unterteilt und eine breite Tabelle mit vielen Feldern generiert, um nachfolgende Geschäftsabfragen, OLAP-Analysen, Datenverteilung usw. bereitzustellen. Der Gesamtumsatz einer bestimmten Kategorie (z. B. Küchenutensilien) in jeder Provinz am letzten Tag, die Namen der 10 meistverkauften Produkte in der Kategorie und die Verteilung der Kaufkraft der Benutzer in jeder Provinz. Daher können wir die Daten des letzten Tages aus der Perspektive der endgültigen erfolgreichen Transaktion von Waren, Kategorien, Käufern usw. zusammenfassen. Zum Beispiel die Anzahl der Produkte, die Benutzer in jedem Zeitraum mit unterschiedlichen Anmelde-IPs gekauft haben usw. Eine kurze Zusammenfassung hier macht die Berechnung effizienter. Auf dieser Grundlage wird es viel schneller, wenn das Verhalten von nur 7 Tagen, 30 Tagen und 90 Tagen berechnet wird. Wir hoffen, dass 80 % des Geschäfts über unsere DWS-Schicht anstelle von ODS berechnet werden können. Was macht die DWS-Schicht? dws fasst die Daten in der DWD-Ebene nach Themen zusammen und legt sie entsprechend dem Thema in einer Tabelle ab. Zum Beispiel unter dem Benutzerthema die Benutzerregistrierungsinformationen, die Benutzerversandadresse, und Benutzerkreditbericht werden in derselben Tabelle abgelegt, und diese entsprechen mehreren Tabellen in der DWD-Ebene, z. B. Verkehr, Bestellungen, Benutzer usw., eine breite Tabelle mit mehr Feldern generierte Themenmodellierung rund um ein bestimmtes Thema. Führen Sie eine Datenmodellierung zu Geschäftsthemen durch und extrahieren Sie relevante Daten Aggregation täglich aktiver Benutzer Spezifische breite Tabellennamen: breite Tabelle zum Benutzerverhalten, breite Tabelle zum Benutzerkaufproduktdetailverhalten, breite Tabelle zum Produkt, breite Tabelle zur Logistik, Kundendienst usw. ②Welche Tischbreite ist am breitesten? Wie viele Felder gibt es ungefähr? Die breiteste ist die breite Tabelle zum Benutzerverhalten. Es gibt etwa 60–200 Felder Veröffentlichung, Aktivität, Anmeldung, Karte neu signieren, Glückshaus, Geschenk, Goldmünze, E-Commerce-Klick, GMV ④Analysierte Indikatoren täglich aktiv, monatlich aktiv, wöchentlich aktiv, Retention, Retention Rate, Neuzugänge (Tag, Woche, Jahr), Conversion Rate, Churn, Return, 3 aufeinanderfolgende Tage der Anmeldung (Likes, Sammlungen, Kommentare, Käufe, Zusatzkäufe, Bestellungen, Aktivitäten) innerhalb von sieben Tagen, 3 aufeinanderfolgende Tage Wöchentliche (monatliche) Anmeldung, GMV (Transaktionsbetrag, Bestellung), Rückkaufsrate, Rangfolge der Rückkaufsraten, Likes, Kommentare, Sammlungen, Anzahl der Personen, die Rabatte erhalten, Rabatte nutzen, Ruhe, ob sich der Kauf lohnt und Anzahl der Rückerstattungen, Rückerstattung Bewerten Sie die beliebtesten Produkte. Zwischen 10 und 30 Millionen GMV: Welches Produkt verkauft sich am besten? Wie viele Bestellungen werden täglich aufgegeben? GMV: 100.000 Bestellungen pro Tag (50–100 Yuan) 5 Millionen–10 Millionen Person, pro Tag Das GMV beträgt 10 Millionen 1000.000-2 Millionen Rückkauf eines täglichen Produkts; Gesichtsmaske, Zahnpasta) 10%-20% Computer, Monitore, Uhren 1% Produktdetails=》In den Warenkorb legen=》Bestellen= 》Bezahlen 5 %–10 % 60–70 % 90 %–95 % Aktivität: 10-20 % Datengenerierungsmethode: wird durch eine leichte Zusammenfassungsebene und eine detaillierte Berechnung der Ebenendaten generiert. Protokollspeichermethode: Verwendung der internen Impala-Tabelle, Parkettdateiformat. Bibliotheks- und Tabellenbenennung. Bibliotheksname: DWS, Tabellenname: Das anfängliche Überlegungsformat lautet: DWS-Datumsname der Geschäftstabelle, noch festzulegen. Alte Datenaktualisierungsmethode: direkte Überschreibung 公共汇总事实表命名规范:dws_{业务板块缩写/pub}_{数据域缩写}_{数据粒度缩写}[_{自定义表命名标签缩写}]_{统计时间周期范围缩写}。关于统计实际周期范围缩写,缺省情况下,离线计算应该包括最近一天(_1d),最近N天(_nd)和历史截至当天(_td)三个表。如果出现_nd的表字段过多需要拆分时,只允许以一个统计周期单元作为原子拆分。即一个统计周期拆分一个表,例如最近7天(_1w)拆分一个表。不允许拆分出来的一个表存储多个统计周期。 对于小时表(无论是天刷新还是小时刷新),都用_hh来表示。对于分钟表(无论是天刷新还是小时刷新),都用_mm来表示。 举例如下: dws_asale_trd_byr_subpay_1d(买家粒度交易分阶段付款一日汇总事实表) dws_asale_trd_byr_subpay_td(买家粒度分阶段付款截至当日汇总表) dws_asale_trd_byr_cod_nd(买家粒度货到付款交易汇总事实表) dws_asale_itm_slr_td(卖家粒度商品截至当日存量汇总表) dws_asale_itm_slr_hh(卖家粒度商品小时汇总表)---维度为小时 dws_asale_itm_slr_mm(卖家粒度商品分钟汇总表)---维度为分钟 问:数据集市层是不是没地方放了,各个业务的数据集市表是应该在 dws 还是在 app? 答:这个问题不太好回答,我感觉主要就是明确一下数据集市层是干什么的,如果你的数据集市层放的就是一些可以供业务方使用的宽表,放在 app 层就行。如果你说的数据集市层是一个比较泛一点的概念,那么其实 dws、dwd、app 这些合起来都算是数据集市的内容。 数据应用层(ADS,Application Data Store):存放数据产品个性化的统计指标数据,报表数据。主要是提供给数据产品和数据分析使用的数据,通常根据业务需求,划分成流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。从数据粒度来说,这层的数据是汇总级的数据,也包括部分明细数据。从数据的时间跨度来说,通常是DW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年的即可。从数据的广度来说,仍然覆盖了所有业务数据。 在 DWS 之上,我们会面向应用场景去做一些更贴近应用的 APP 应用数据层,这些数据应该是高度汇总的,并且能够直接导入到我们的应用服务去使用。 应用层(ADS):应用层主要是各个业务方或者部门基于DWD和DWS建立的数据集市(Data Market, DM),一般来说应用层的数据来源于DW层,而且相对于DW层,应用层只包含部门或者业务方面自己关心的明细层和汇总层的数据。 该层主要是提供数据产品和数据分析使用的数据。一般就直接对接OLAP分析,或者业务层数据调用接口了 数据应用层APP:面向业务定制的应用数据主要提供给数据铲平和数据分析使用的数据,一般会放在ES,MYSQL,Oracle,Redis等系统供线上系统使用,也可以放在Hive 或者 Druid 中供数据分析和数据挖掘使用。 APP 层:为应用层,这层数据是完全为了满足具体的分析需求而构建的数据,也是星形或雪花结构的数据。如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。包括前端报表、分析图表、KPI、仪表盘、OLAP、专题等分析,面向最终结果用户; 概念:应用层是根据业务需要,由前面三层数据统计而出的结果,可以直接提供查询展现,或导入至Mysql中使用。 数据生成方式:由明细层、轻度汇总层,数据集市层生成,一般要求数据主要来源于集市层。 日志存储方式:使用impala内表,parquet文件格式。 表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。 库与表命名。库名:暂定ads,另外根据业务不同,不限定一定要一个库。 旧数据更新方式:直接覆盖。 ADS 层复购率统计 ①如何分析用户活跃? 在启动日志中统计不同设备 id 出现次数。 ②如何分析用户新增? 用活跃用户表 left join 用户新增表,用户新增表中 mid 为空的即为用户新增。 ③如何分析用户 1 天留存? 留存用户=前一天新增 join 今天活跃 用户留存率=留存用户/前一天新增 ④如何分析沉默用户? (登录时间为 7 天前,且只出现过一次) 按照设备 id 对日活表分组,登录次数为 1,且是在一周前登录。 ⑤如何分析本周回流用户? 本周活跃 left join 本周新增 left join 上周活跃,且本周新增 id 和上周活跃 id 都为 null。 ⑥如何分析流失用户? (登录时间为 7 天前) 按照设备 id 对日活表分组,且七天内没有登录过。 ⑦如何分析最近连续 3 周活跃用户数? 按照设备 id 对周活进行分组,统计次数大于 3 次。 ⑧Wie analysiert man die Anzahl der aktiven Benutzer an drei aufeinanderfolgenden Tagen in den letzten sieben Tagen? 1 Monat für 7 aufeinanderfolgende Tage zwei aufeinanderfolgende Wochen TMP: Jede Berechnungsebene verfügt über viele temporäre Tabellen, und eine DW-TMP-Schicht ist speziell für die Speicherung der temporären Tabellen unseres Data Warehouse konzipiert. 04 Hierarchische Rufspezifikation
CREATE TABLE IF NOT EXISTS dwd_asale_trd_itm_di
(
item_id BIGINT COMMENT '商品ID',
item_title STRING COMMENT '商品名称',
item_price DOUBLE COMMENT '商品价格',
item_stuff_status BIGINT COMMENT '商品新旧程度_0全新1闲置2二手',
item_prov STRING COMMENT '商品省份',
item_city STRING COMMENT '商品城市',
cate_id BIGINT COMMENT '商品类目ID',
cate_name STRING COMMENT '商品类目名称',
commodity_id BIGINT COMMENT '品类ID',
commodity_name STRING COMMENT '品类名称',
buyer_id BIGINT COMMENT '买家ID',
)
COMMENT '交易商品信息事实表'
PARTITIONED BY (ds STRING COMMENT '日期')
LIFECYCLE 400;
Konzept: Auch bekannt als Data Mart oder Wide Table. Je nach Geschäftsbereich, wie Verkehr, Bestellungen, Benutzer usw., wird eine breite Tabelle mit vielen Feldern generiert, um nachfolgende Geschäftsabfragen, OLAP-Analysen, Datenverteilung usw. bereitzustellen.
drop table
if exists dws_sale_detail_daycount;
create external table dws_sale_detail_daycount(
user_id string comment '用户 id',
--用户信息
user_gender string comment '用户性别',
user_age string comment '用户年龄',
user_level string comment '用户等级',
buyer_nick string comment '买家昵称',
mord_prov string comment '地址',
--下单数、 商品数量, 金额汇总
login_count bigint comment '当日登录次数',
cart_count bigint comment '加入购物车次数',
order_count bigint comment '当日下单次数',
order_amount decimal(16,2) comment '当日下单金额',
payment_count bigint comment '当日支付次数',
payment_amount decimal(16,2) comment '当日支付金额',
confirm_paid_amt_sum_1d double comment '最近一天订单已经确认收货的金额总和'
order_detail_stats array<struct<sku_id:string,sku_num:bigint,order_count:bigint,order_amount:decimal(20,2)>> comment '下单明细统计'
) comment '每日购买行为'
partitioned by(`dt`
string)
stored as parquet
location '/warehouse/gmall/dws/dws_sale_detail_daycount/'
tblproperties("parquet.compression" = "lzo");CREATE TABLE IF NOT EXISTS dws_asale_trd_itm_ord_1d
(
item_id BIGINT COMMENT '商品ID',
--商品信息,产品信息
item_title STRING COMMENT '商品名称',
cate_id BIGINT COMMENT '商品类目ID',
cate_name STRING COMMENT '商品类目名称',
--mord_prov STRING COMMENT '收货人省份',
--商品售出金额汇总
confirm_paid_amt_sum_1d DOUBLE COMMENT '最近一天订单已经确认收货的金额总和'
)
COMMENT '商品粒度交易最近一天汇总事实表'
PARTITIONED BY (ds STRING COMMENT '分区字段YYYYMMDD')
LIFECYCLE 36000;
03 应用层(ADS)applicationData Service应用数据服务
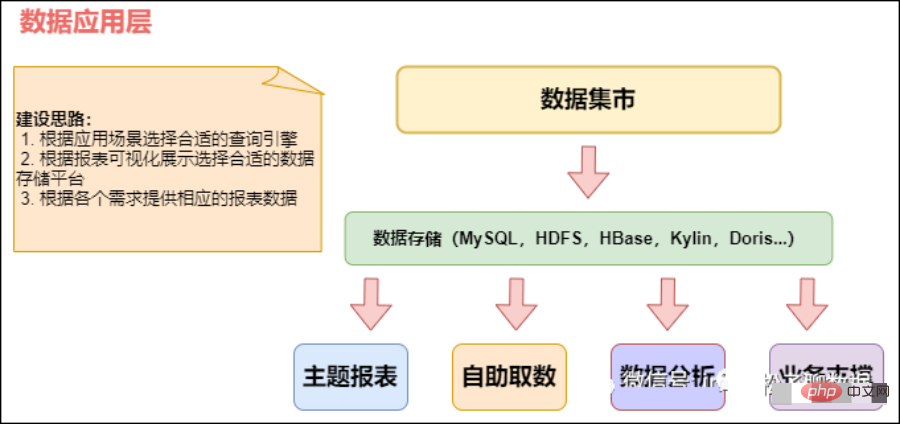



CREATE TABLE app_usr_interact( user_id string COMMENT '用户id',
nickname string COMMENT '用户昵称',
register_date string COMMENT '注册日期',
register_from string COMMENT '注册来源',
remark string COMMENT '细分渠道',
province string COMMENT '注册省份',
pl_cnt bigint COMMENT '评论次数',
ds_cnt bigint COMMENT '打赏次数',
sc_add bigint COMMENT '添加收藏',
sc_cancel bigint COMMENT '取消收藏',
gzg_add bigint COMMENT '关注商品',
gzg_cancel bigint COMMENT '取消关注商品',
gzp_add bigint COMMENT '关注人',
gzp_cancel bigint COMMENT '取消关注人',
buzhi_cnt bigint COMMENT '点不值次数',
zhi_cnt bigint COMMENT '点值次数',
zan_cnt bigint COMMENT '点赞次数',
share_cnts bigint COMMENT '分享次数',
bl_cnt bigint COMMENT '爆料数',
fb_cnt bigint COMMENT '好价发布数',
online_cnt bigint COMMENT '活跃次数',
checkin_cnt bigint COMMENT '签到次数',
fix_checkin bigint COMMENT '补签次数',
house_point bigint COMMENT '幸运屋金币抽奖次数',
house_gold bigint COMMENT '幸运屋积分抽奖次数',
pack_cnt bigint COMMENT '礼品兑换次数',
gold_add bigint COMMENT '获取金币',
gold_cancel bigint COMMENT '支出金币',
surplus_gold bigint COMMENT '剩余金币',
event bigint COMMENT '电商点击次数',
gmv_amount bigint COMMENT 'gmv',
gmv_sales bigint COMMENT '订单数'
)
PARTITIONED BY( dt string)
--stat_dt
date COMMENT '互动日期',
Rückwärtsrufe sind verboten
Das obige ist der detaillierte Inhalt vonVon ODS zu ADS, eine detaillierte Erklärung der Data Warehouse-Stratifizierung!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr