
Heim >Technologie-Peripheriegeräte >KI >Das Geheimnis der datenzentrierten KI im GPT-Modell
Das Geheimnis der datenzentrierten KI im GPT-Modell

- 王林nach vorne
- 2023-04-30 17:58:071602Durchsuche
Übersetzer |. 🎜🎜#rezension | ## 🎜🎜#Das Bild stammt aus dem Artikel https://www.php.cn/link/f74412c3c1c8899f3c130bb30ed0e363, erstellt vom Autor selbst. Unglaublicher Fortschritt. Ein Bereich, der in letzter Zeit erhebliche Fortschritte gemacht hat, ist die Entwicklung großer Sprachmodelle (LLMs), wie z 🎜# und GPT-4#🎜 🎜#. Diese Modelle sind in der Lage, Aufgaben wie Sprachübersetzung, Textzusammenfassung und Beantwortung von Fragen mit beeindruckender Genauigkeit auszuführen.
Während es schwer ist, die ständig wachsenden Modellgrößen großer Sprachmodelle zu ignorieren, ist es ebenso wichtig zu erkennen, dass ihr Erfolg größtenteils auf die Verwendung ihrer großen Mengen zurückzuführen ist hochwertiger Daten.
In diesem Artikel geben wir einen Überblick über die jüngsten Fortschritte bei groß angelegten Sprachmodellen aus einem datenzentrierten künstlichen Umfeld Sehen Sie sich bitte unsere Standpunkte in aktuellen Umfragepapieren (Ende der Literatur 1 und 2) und die entsprechenden Technische Ressourcen
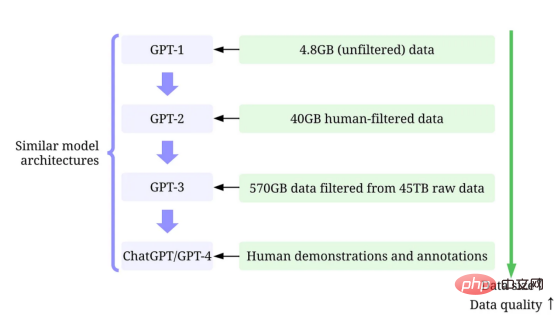
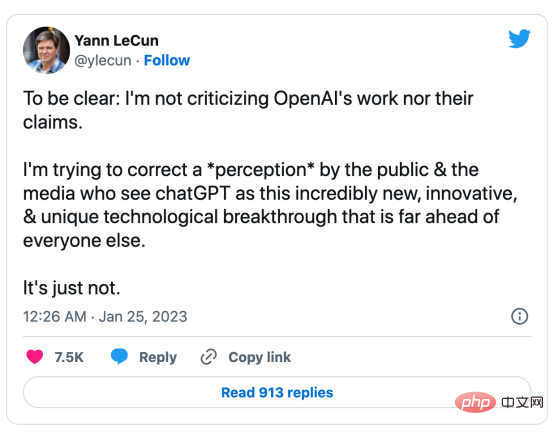
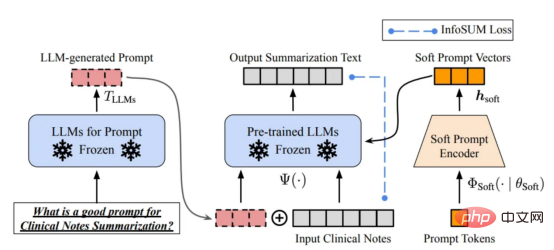
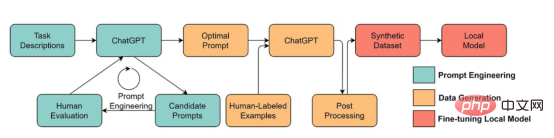
#🎜 an 🎜# auf GitHub. Insbesondere werden wir das GPT-Modell aus der Sicht der datenzentrierten künstlichen Intelligenz genauer betrachten, was in der Data-Science-Community eine wachsende Stimmung darstellt. Wir werden das datenzentrierte #🎜🎜 hinter dem GPT-Modell enthüllen, indem wir drei datenzentrierte Ziele der künstlichen Intelligenz diskutieren – Trainingsdatenentwicklung, Inferenzdatenentwicklung und Datenpflege #Konzept der künstlichen Intelligenz#🎜 🎜#. Groß angelegtes Sprachmodell und GPT-Modell LLM (Large-scale Language Model) ist ein trainiertes Modell zur Verarbeitung natürlicher Sprache im Kontext operieren, Wörter ableiten. Die grundlegendste Funktion von LLM besteht beispielsweise darin, fehlende Token im gegebenen Kontext vorherzusagen. Zu diesem Zweck wird LLM darauf trainiert, die Wahrscheinlichkeit jedes Kandidaten-Tokens aus riesigen Datenmengen vorherzusagen. Sagen Sie die Wahrscheinlichkeit fehlender Token mithilfe eines großen Sprachmodells mit Kontext voraus Anschauliches Beispiel für (Bild vom Autor selbst bereitgestellt) GPT-Modell bezieht sich auf eine Reihe groß angelegter Sprachmodelle, die von OpenAI erstellt wurden, wie z. B. GPT-1#🎜 🎜## 🎜🎜#, GPT-2, GPT-3, InstructGPT#🎜🎜 # und #🎜 🎜#ChatGPT/GPT-4. Wie andere große Sprachmodelle basiert die Architektur des GPT-Modells stark auf Transformern, die Text- und Positionseinbettungen als Eingabe verwenden und Aufmerksamkeitsebenen verwenden, um Beziehungen zwischen Token zu modellieren. GPT-1-Modellarchitekturdiagramm, dieses Bild stammt aus dem Artikel https://www.php.cn /link/c3bfbc2fc89bd1dd71ad5fc5ac96ae69 Das spätere GPT-Modell verwendet eine ähnliche Architektur wie GPT-1, verwendet jedoch mehr Modellparameter mit mehr Ebenen, größere Kontextlänge, ausgeblendete Ebenengröße usw. Vergleich verschiedener Modellgrößen von GPT-Modellen (Bild vom Autor bereitgestellt) Was ist datenzentrierte künstliche Intelligenz? In der Vergangenheit haben wir uns hauptsächlich darauf konzentriert, bessere Modelle zu erstellen, wenn die Daten im Wesentlichen unverändert sind (wobei wir das Modell als angenommen haben). Zentrum für Künstliche Intelligenz). Allerdings kann dieser Ansatz in der Praxis zu Problemen führen, da er verschiedene Probleme, die in den Daten auftreten können, wie etwa ungenaue Bezeichnungen, Duplikate und Verzerrungen, nicht berücksichtigt. Daher muss eine „Überanpassung“ eines Datensatzes nicht unbedingt zu einem besseren Modellverhalten führen. Im Gegensatz dazu konzentriert sich datenzentrierte KI auf die Verbesserung der Qualität und Quantität der zum Aufbau von KI-Systemen verwendeten Daten. Dies bedeutet, dass die Aufmerksamkeit auf die Daten selbst gerichtet wird, während das Modell vergleichsweise fester ist. Ein datenzentrierter Ansatz zur Entwicklung von KI-Systemen hat in der realen Welt ein größeres Potenzial, da die für das Training verwendeten Daten letztendlich die maximalen Fähigkeiten des Modells bestimmen. Datenzentrierte künstliche Intelligenz und modellzentrierte künstliche Intelligenz Vergleich von KI (Bild von https://www.php.cn/link/f9afa97535cf7c8789a1c50a2cd83787 Autor des Papiers), das datenzentrierte Framework für künstliche Intelligenz besteht aus drei Zielen: #🎜 🎜# Datenzentriertes Framework für künstliche Intelligenz (Bild vom Autor des Artikels https://www.php.cn/link/f74412c3c1c8899f3c130bb30ed0e363) Vor ein paar Monaten erklärte Yann LeCun, ein führendes Unternehmen in der Branche der künstlichen Intelligenz, auf seinem Twitter, dass ChatGPT nichts Neues sei. Tatsächlich sind alle in ChatGPT und GPT-4 verwendeten Techniken (TTransformer und verstärkendes Lernen aus menschlichem Feedback usw.) keine neuen Technologien. Allerdings erzielten sie unglaubliche Ergebnisse, die frühere Modelle nicht erreichen konnten. Was also treibt ihren Erfolg an? Stärken Sie zunächst die AusbildungDatenentwicklung. Durch bessere Datenerfassung, Datenkennzeichnung und Datenaufbereitungsstrategien ist die Quantität und Qualität der zum Training von GPT-Modellen verwendeten Daten erheblich gestiegen. Zweitens: Entwickeln Sie Inferenzdaten. Da neuere GPT-Modelle leistungsfähig genug geworden sind, können wir verschiedene Ziele erreichen, indem wir die Hinweise (oder die Inferenzdaten) anpassen und gleichzeitig das Modell korrigieren. Beispielsweise können wir eine Textzusammenfassung durchführen, indem wir den Text der Zusammenfassung zusammen mit Anweisungen wie „Zusammenfassen“ oder „TL;DR“ bereitstellen, um den Inferenzprozess zu leiten. Prompte Feinabstimmung, Bilder vom Autor zur Verfügung gestellt Das Entwerfen der richtigen Argumentationsaufforderungen ist eine herausfordernde Aufgabe. Es basiert stark auf heuristischen Techniken. Eine gute Umfrage fasst die verschiedenen Aufforderungsmethoden zusammen, die Menschen bisher verwenden. Manchmal können selbst semantisch ähnliche Hinweise sehr unterschiedliche Ergebnisse haben. In diesem Fall ist möglicherweise eine Soft-Cue-basierte Kalibrierung erforderlich, um die Diskrepanz zu verringern. Soft-Prompt-basierte Kalibrierung. Dieses Bild stammt aus dem Artikel https://arxiv.org/abs/2303.13035v1, mit Genehmigung des ursprünglichen Autors Die Forschung zur Entwicklung groß angelegter Sprachmodell-Inferenzdaten befindet sich noch in einem frühen Stadium . In naher Zukunft könnten weitere Techniken zur Entwicklung von Inferenzdaten, die bereits für andere Aufgaben verwendet werden, auf den Bereich großer Sprachmodelle angewendet werden. Im Hinblick auf die Datenpflege ist ChatGPT/GPT-4 als kommerzielles Produkt nicht nur ein erfolgreiches Training, sondern erfordert eine kontinuierliche Aktualisierung und Wartung. Offensichtlich wissen wir nicht, wie die Datenpflege außerhalb von OpenAI durchgeführt wird. Daher diskutieren wir einige allgemeine datenzentrierte KI-Strategien, die wahrscheinlich in GPT-Modellen verwendet werden oder verwendet werden: Das ChatGPT/GPT-4-System ist in der Lage, Benutzerfeedback über die beiden Symbolschaltflächen „Daumen hoch“ und „Daumen runter“ zu sammeln, wie im Bild gezeigt, um die Entwicklung ihres Systems weiter voranzutreiben. Der Screenshot hier stammt von https://chat.openai.com/chat. Der Erfolg groß angelegter Sprachmodelle hat die künstliche Intelligenz revolutioniert. Zukünftig könnten große Sprachmodelle den Lebenszyklus der Datenwissenschaft weiter revolutionieren. Dazu treffen wir zwei Prognosen: Verwenden Sie ein großes Sprachmodell, um synthetische Daten zu generieren und das Modell zu trainieren. Das Bild hier stammt aus dem Artikel https://arxiv.org/abs/2303.04360, mit Genehmigung des ursprünglichen Autors Ich hoffe, dieser Artikel inspiriert Sie bei Ihrer eigenen Arbeit. In den folgenden Artikeln können Sie mehr über datenzentrierte KI-Frameworks und deren Vorteile für große Sprachmodelle erfahren: [1]Ein Überblick über datenzentrierte künstliche Intelligenz. [2]Die Aussichten und Herausforderungen datenzentrierter künstlicher Intelligenz. Beachten Sie, dass wir auch ein GitHub-Code-Repository unterhalten, das relevante datenzentrierte Ressourcen für künstliche Intelligenz regelmäßig aktualisiert. In zukünftigen Artikeln werde ich mich mit den drei Zielen der datenzentrierten künstlichen Intelligenz (Trainingsdatenentwicklung, Inferenzdatenentwicklung und Datenpflege) befassen und repräsentative Methoden vorstellen. Zhu Xianzhong, 51CTO-Community-Redakteur, 51CTO-Expertenblogger, Dozent, Computerlehrer an einer Universität in Weifang und ein Veteran in der freiberuflichen Programmierbranche. Originaltitel: Was sind die datenzentrierten KI-Konzepte hinter GPT-Modellen?, Autor: Henry Lai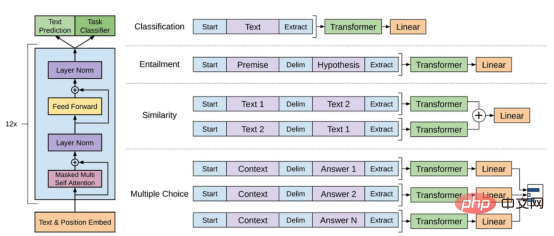
 ——Andrew Ng
——Andrew NgEs ist erwähnenswert, dass sich „datenzentriert“ grundlegend von „datengesteuert“ unterscheidet, da letzteres nur betont Nutzen Sie Daten zur Steuerung der KI-Entwicklung, bei der es oft immer noch um die Entwicklung von Modellen und nicht um technische Daten geht.
Warum Datenzentrierte KI macht das GPT-Modell so erfolgreich?

Was kann die Data-Science-Community aus dieser Welle großer Sprachmodelle lernen?
Referenzinformationen
Übersetzer-Einführung
Das obige ist der detaillierte Inhalt vonDas Geheimnis der datenzentrierten KI im GPT-Modell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr