
Heim >Technologie-Peripheriegeräte >KI >Das MIT fasst die letzten drei Jahre zusammen und veröffentlicht einen Übersichtsartikel zu KI-Beschleunigern
Das MIT fasst die letzten drei Jahre zusammen und veröffentlicht einen Übersichtsartikel zu KI-Beschleunigern

- 王林nach vorne
- 2023-04-29 09:07:061688Durchsuche
Im vergangenen Jahr haben sowohl Startups als auch etablierte Unternehmen nur langsam Beschleuniger für künstliche Intelligenz (KI) und maschinelles Lernen (ML) angekündigt, eingeführt und eingesetzt. Aber es ist nicht unangemessen, und viele Unternehmen, die Beschleunigerberichte veröffentlichen, verbringen drei bis vier Jahre damit, das Design des Beschleunigers zu erforschen, zu analysieren, zu entwerfen, zu validieren und abzuwägen und den Technologie-Stack zur Programmierung des Beschleunigers aufzubauen. Bei den Unternehmen, die aktualisierte Versionen ihrer Beschleuniger herausgebracht haben, betragen die Entwicklungszyklen immer noch mindestens zwei bis drei Jahre, obwohl sie berichten, dass sie kürzer sind. Der Schwerpunkt dieser Beschleuniger liegt weiterhin auf der Beschleunigung von Deep Neural Network (DNN)-Modellen. Die Anwendungsszenarien reichen von eingebetteter Spracherkennung und Bildklassifizierung mit extrem geringem Stromverbrauch bis hin zum Training großer Rechenzentren Ein wichtiger Teil des Wandels vom modernen traditionellen Computing hin zu Lösungen für maschinelles Lernen für Industrie- und Technologieunternehmen.
Das KI-Ökosystem vereint Komponenten des Edge Computing, des traditionellen Hochleistungsrechnens (HPC) und der Hochleistungsdatenanalyse (HPDA), die zusammenarbeiten müssen , um Entscheidungsträger, Mitarbeiter an vorderster Front und Analysten effektiv zu befähigen. Abbildung 1 zeigt einen Architekturüberblick über diese End-to-End-KI-Lösung und ihre Komponenten.
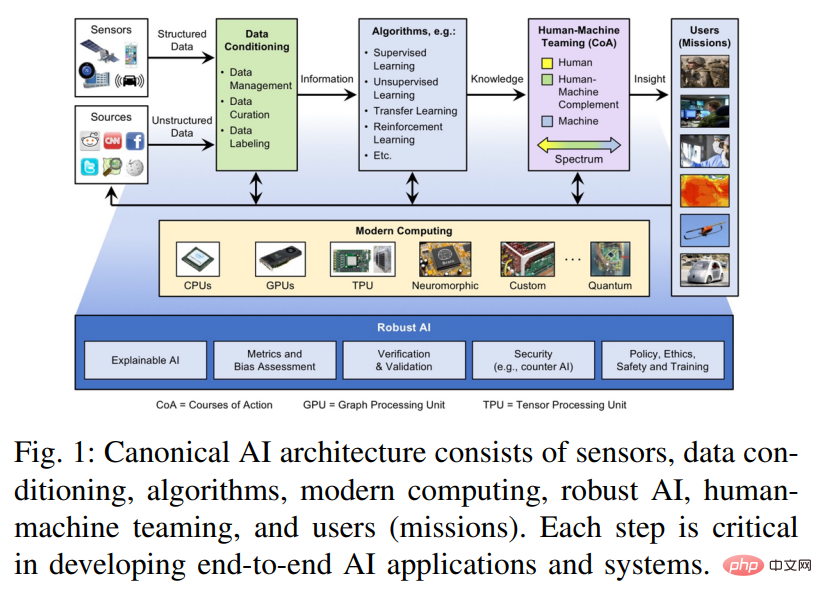
Die Originaldaten müssen zunächst datenkuratiert werden. In diesem Schritt werden die Daten fusioniert, aggregiert und strukturiert , gesammelt und in Informationen umgewandelt. Die durch den Data-Wrangling-Schritt generierten Informationen dienen als Eingabe für überwachte oder unüberwachte Algorithmen wie neuronale Netze, die Muster extrahieren, fehlende Daten ergänzen oder Ähnlichkeiten zwischen Datensätzen finden und Vorhersagen treffen, wodurch die Eingabeinformationen in umsetzbares Wissen umgewandelt werden. Dieses umsetzbare Wissen wird auf den Menschen übertragen und im Entscheidungsprozess während der Phase der Mensch-Maschine-Zusammenarbeit genutzt. Die Phase der Mensch-Maschine-Kollaboration liefert Benutzern nützliche und wichtige Erkenntnisse und wandelt Wissen in umsetzbare Intelligenz oder Erkenntnisse um.
Diesem System liegt ein modernes Computersystem zugrunde. Der Trend zum Mooreschen Gesetz ist beendet, aber gleichzeitig werden viele verwandte Gesetze und Trends vorgeschlagen, wie zum Beispiel das Denardsche Gesetz (Leistungsdichte), Taktfrequenz, Kernanzahl, Anweisungen pro Taktzyklus und Anweisungen pro Joule (Koomeys Gesetz). Vom System-on-a-Chip (SoC)-Trend, der erstmals in Automobilanwendungen, Robotik und Smartphones auftrat, schreitet die Innovation durch die Entwicklung und Integration von Beschleunigern häufig verwendeter Kerne, Methoden oder Funktionen weiter voran. Diese Beschleuniger bieten ein unterschiedliches Gleichgewicht zwischen Leistung und funktionaler Flexibilität, einschließlich einer Explosion von Innovationen bei Deep-Learning-Prozessoren und -Beschleunigern. In diesem Artikel werden die relativen Vorteile dieser Technologien durch die Lektüre einer großen Anzahl verwandter Artikel untersucht, da sie besonders wichtig für die Anwendung künstlicher Intelligenz in eingebetteten Systemen und Rechenzentren sind, in denen Größe, Gewicht und Leistung äußerst wichtig sind.
Dieser Artikel ist eine Aktualisierung der IEEE-HPEC-Papiere der letzten drei Jahre. Wie in den vergangenen Jahren konzentriert sich dieser Artikel weiterhin auf Beschleuniger und Prozessoren für Deep Neural Networks (DNN) und Convolutional Neural Networks (CNN), die äußerst rechenintensiv sind. Dieser Artikel konzentriert sich auf die Entwicklung von Beschleunigern und Prozessoren im Bereich Inferenz, da viele KI/ML-Edge-Anwendungen stark auf Inferenz angewiesen sind. In diesem Artikel werden alle von Beschleunigern unterstützten numerischen Präzisionstypen behandelt. Bei den meisten Beschleunigern ist die beste Inferenzleistung jedoch int8 oder fp16/bf16 (16-Bit-Gleitkomma von IEEE oder 16-Bit-Brain-Float von Google).

Papierlink: https://arxiv.org/pdf/2210.04055.pdf#🎜 🎜#
Derzeit gibt es viele Artikel über KI-Beschleuniger. Im ersten Artikel dieser Umfragereihe wird beispielsweise die Spitzenleistung von FPGAs für bestimmte KI-Modelle erörtert. Frühere Umfragen haben FPGAs ausführlich behandelt und sind daher nicht mehr in dieser Umfrage enthalten. Diese laufende Umfrage und dieser Artikel zielen darauf ab, eine umfassende Liste von KI-Beschleunigern zusammenzustellen, einschließlich ihrer Rechenfähigkeiten, Energieeffizienz und Recheneffizienz bei der Verwendung von Beschleunigern in eingebetteten Anwendungen und Rechenzentrumsanwendungen. Gleichzeitig werden in dem Artikel hauptsächlich neuronale Netzwerkbeschleuniger für staatliche und industrielle Sensor- und Datenverarbeitungsanwendungen verglichen. Einige Beschleuniger und Prozessoren, die in Veröffentlichungen aus früheren Jahren enthalten waren, wurden von der diesjährigen Umfrage ausgeschlossen, da sie möglicherweise durch neue Beschleuniger desselben Unternehmens ersetzt wurden, nicht mehr gewartet werden oder für das Thema nicht mehr relevant sind.
Prozessorumfrage
Viele aktuelle Fortschritte in der künstlichen Intelligenz sind teilweise auf Verbesserungen der Hardwareleistung zurückzuführen, die maschinelle Lernalgorithmen ermöglichen, die enorme Rechenleistung erfordern, insbesondere Netzwerke wie DNNs. Die Umfrage für diesen Artikel sammelte eine Vielzahl von Informationen aus öffentlich zugänglichen Materialien, darunter verschiedene Forschungsarbeiten, Fachzeitschriften, von Unternehmen veröffentlichte Benchmarks usw. Es gibt zwar andere Möglichkeiten, Informationen über Unternehmen und Start-ups zu erhalten (auch solche in stillen Phasen), in diesem Artikel werden diese Informationen zum Zeitpunkt dieser Umfrage jedoch weggelassen und die Daten werden in die Umfrage einbezogen, wenn sie veröffentlicht werden. Die wichtigsten Kennzahlen dieser öffentlichen Daten sind in der folgenden Tabelle dargestellt, die die aktuelle Spitzenleistung des Prozessors im Vergleich zum Stromverbrauch widerspiegelt (Stand: Juli 2022).
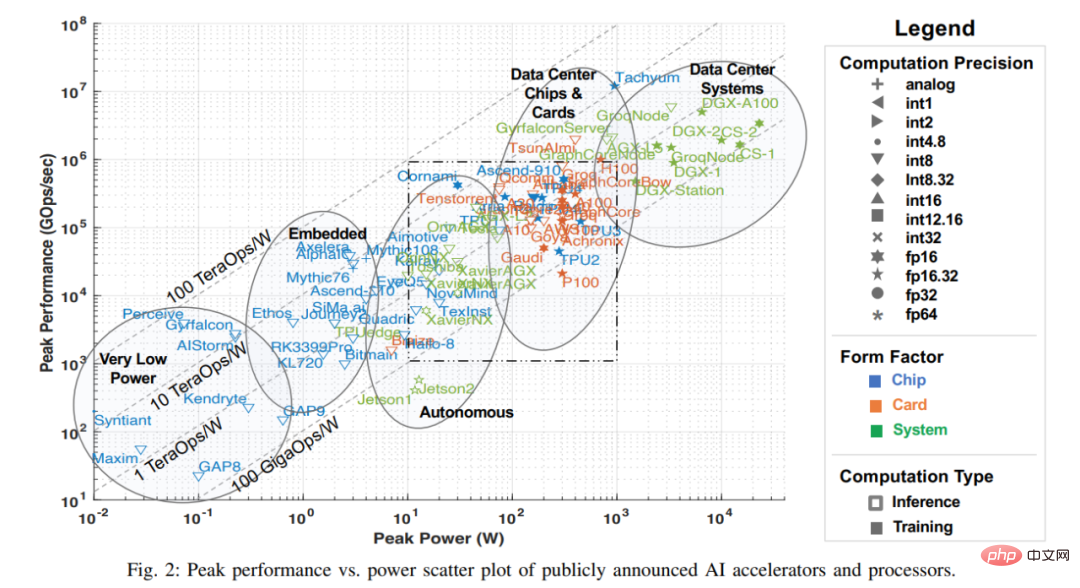
Hinweis: Das gepunktete Kästchen in Abbildung 2 entspricht Abbildung 3 unten. Abbildung 3 ist eine vergrößerte Version des gepunkteten Kästchens.
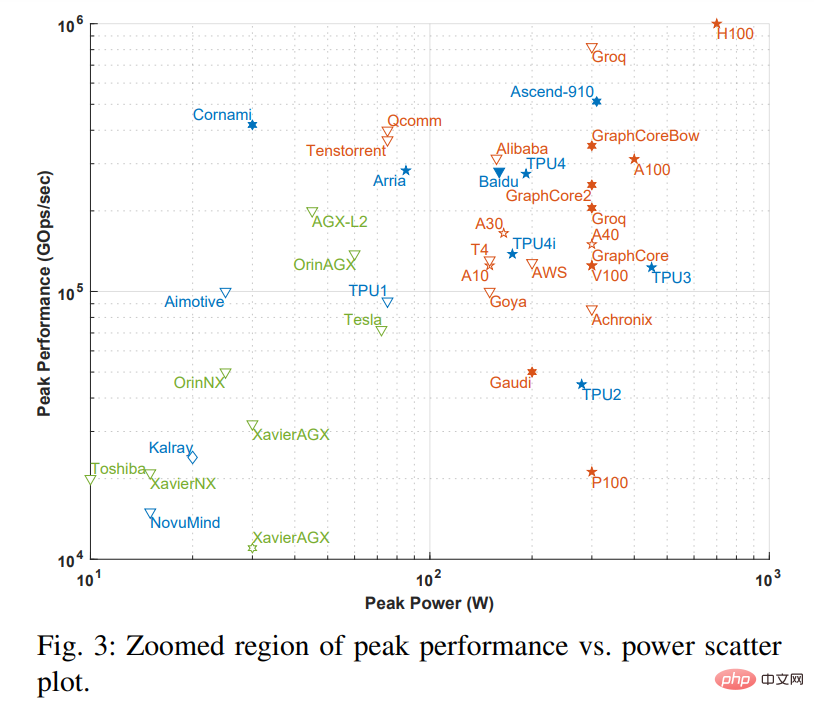
Die X-Achse in der Abbildung stellt die Spitzenleistung dar, und die Y-Achse stellt die Spitzen-Gigabit-Operationen pro Sekunde (GOps/s) dar, beide im logarithmischen Maßstab. Die Berechnungsgenauigkeit der Rechenleistung wird durch unterschiedliche Geometrien dargestellt, die von int1 bis int32 und von fp16 bis fp64 reichen. Es werden zwei Arten der Genauigkeit angezeigt. Die linke Seite stellt die Genauigkeit von Multiplikationsoperationen dar und die rechte Seite stellt die Genauigkeit von Akkumulations-/Additionsoperationen dar (z. B. stellt fp16.32 die fp16-Multiplikation und die fp32-Akkumulation/Addition dar). Verwenden Sie Farben und Formen, um zwischen verschiedenen Systemtypen und Spitzenleistungen zu unterscheiden. Blau steht für einen einzelnen Chip; Orange steht für eine Karte; Grün steht für ein Gesamtsystem (Einzelknoten-Desktop- und Serversysteme). Diese Untersuchung ist auf Systeme mit einem Motherboard und einem Speicher beschränkt. Die offenen Geometrien in der Abbildung stellen die Spitzenleistung von Beschleunigern dar, die nur Inferenz durchführen, während die Volumengeometrien die Leistung von Beschleunigern darstellen, die sowohl Training als auch Inferenz durchführen.
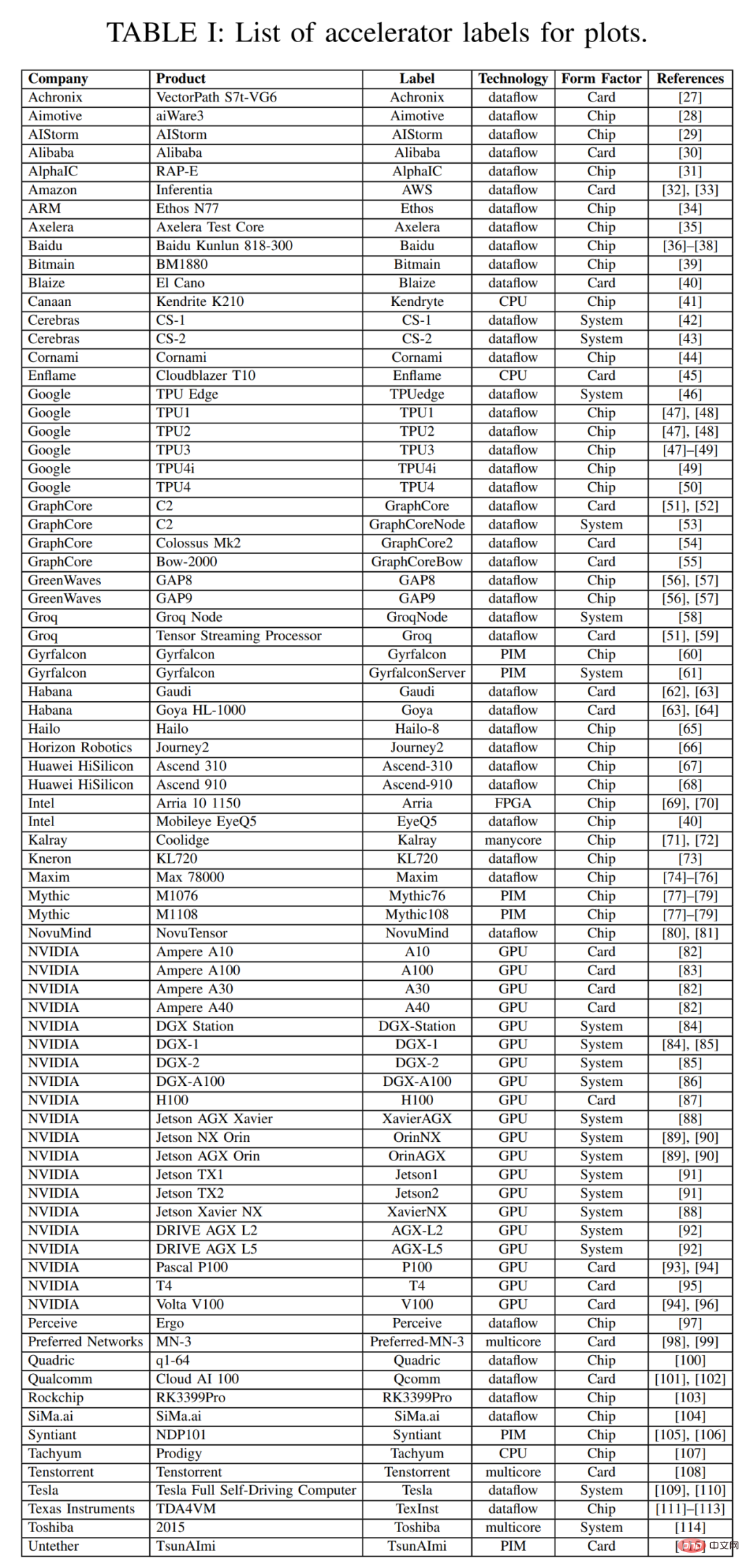
In dieser Umfrage beginnt dieser Artikel mit einem Streudiagramm der Umfragedaten der letzten drei Jahre. Dieser Artikel fasst einige wichtige Metadaten für den Beschleuniger, die Karte und das Gesamtsystem in Tabelle 1 unten zusammen, einschließlich Beschriftungen für jeden Punkt in Abbildung 2, wobei viele Punkte aus der letztjährigen Umfrage stammen. Die meisten Spalten und Einträge in Tabelle 1 sind korrekt und klar. Bei zwei Technologieelementen ist dies jedoch wahrscheinlich nicht der Fall: Dataflow und PIM. Prozessoren vom Typ „Datenfluss“ sind Prozessoren, die für die Inferenz und das Training neuronaler Netzwerke angepasst sind. Da neuronale Netzwerktrainings- und Inferenzberechnungen vollständig deterministisch aufgebaut sind, eignen sie sich für die Datenflussverarbeitung, bei der Berechnungen, Speicherzugriffe und Inter-ALU-Kommunikationen explizit/statisch programmiert oder platziert und an die Rechenhardware weitergeleitet werden. Processor-in-Memory-Beschleuniger (PIM) integrieren Verarbeitungselemente mit Speichertechnologie. Zu diesen PIM-Beschleunigern gehören solche, die auf analoger Computertechnologie basieren und Flash-Speicherschaltungen mit integrierten analogen Multiplikations-Add-Funktionen erweitern. Weitere Einzelheiten zu dieser innovativen Technologie finden Sie in der Dokumentation der Mythic- und Gyrfalcon-Beschleuniger.
In diesem Artikel werden Beschleuniger sinnvoll nach ihren erwarteten Anwendungen kategorisiert. Abbildung 1 verwendet Ellipsen, um fünf Arten von Beschleunigern entsprechend ihrer Leistung und ihrem Stromverbrauch zu identifizieren: sehr geringer Stromverbrauch, sehr kleiner Sensor, eingebettete Kameras , kleine Drohnen und Roboter; Fahrerassistenzsysteme, autonomes Fahren und autonome Roboter;
Die Leistung, Funktionen und andere Indikatoren der meisten Beschleuniger haben sich nicht geändert. Relevante Informationen finden Sie in den Veröffentlichungen der letzten zwei Jahre. Im Folgenden finden Sie Beschleuniger, die in früheren Artikeln nicht enthalten waren.
Das niederländische Embedded-System-Startup Acelera behauptet, dass der von ihnen hergestellte Embedded-Testchip über digitale und analoge Designfähigkeiten verfügt, und dieser Testchip soll den Umfang der digitalen Designfähigkeiten testen. Sie hoffen, in zukünftigen Arbeiten analoge (und möglicherweise Flash-)Designelemente hinzufügen zu können.
Maxim Integrated hat ein System-on-Chip (SoC) namens MAX78000 für Anwendungen mit extrem geringem Stromverbrauch herausgebracht. Es umfasst ARM-CPU-Kerne, RISC-V-CPU-Kerne und KI-Beschleuniger. Der ARM-Kern wird für schnelles Prototyping und Code-Wiederverwendung verwendet, während der RISC-V-Kern für niedrigsten Stromverbrauch optimiert ist. Der KI-Beschleuniger verfügt über 64 parallele Prozessoren, die 1-Bit-, 2-Bit-, 4-Bit- und 8-Bit-Integer-Operationen unterstützen. Der SoC arbeitet mit einer maximalen Leistung von 30 mW und eignet sich daher für batteriebetriebene Anwendungen mit geringer Latenz.
Tachyum hat kürzlich einen All-in-One-Prozessor namens Prodigy herausgebracht, der die Funktionen von CPU und GPU integriert. Er ist für HPC- und Machine-Learning-Anwendungen konzipiert und läuft mit einem Frequenz von 5,7 GHz.
NVIDIA hat im März 2022 seine GPU der nächsten Generation namens Hopper (H100) veröffentlicht. Hopper integriert mehr symmetrische Multiprozessoren (SIMD- und Tensor-Kerne), 50 % mehr Speicherbandbreite und SXM-Mezzanine-Karteninstanzen mit 700 W Leistung. (Die Leistung der PCIe-Karte beträgt 450 W)
In den letzten Jahren hat NVIDIA eine Reihe von Systemplattformen für GPUs mit Ampere-Architektur herausgebracht, die in der Automobil-, Robotik- und anderen eingebetteten Anwendungen eingesetzt werden. Für Automobilanwendungen fügt die DRIVE AGX-Plattform zwei neue Systeme hinzu: DRIVE AGX L2 ermöglicht autonomes Fahren der Stufe 2 im 45-W-Leistungsbereich und DRIVE AGX L5 ermöglicht autonomes Fahren der Stufe 5 im 800-W-Leistungsbereich. Jetson AGX Orin und Jetson NX Orin verwenden auch GPUs mit Ampere-Architektur für Robotik, Fabrikautomation und mehr und haben eine maximale Spitzenleistung von 60 W und 25 W.
Graphcore bringt seinen Beschleunigerchip CG200 der zweiten Generation auf den Markt, der auf einer PCIe-Karte eingesetzt wird und eine Spitzenleistung von etwa 300 W hat. Im vergangenen Jahr brachte Graphcore außerdem den Bow-Beschleuniger auf den Markt, den ersten Wafer-to-Wafer-Prozessor, der in Zusammenarbeit mit TSMC entwickelt wurde. Der Beschleuniger selbst ist derselbe wie beim oben erwähnten CG200, ist jedoch mit einem zweiten Chip gekoppelt, der die Leistungs- und Taktverteilung über den gesamten CG200-Chip erheblich verbessert. Dies entspricht einer Leistungssteigerung von 40 % und einer Leistungssteigerung pro Watt von 16 %.
Im Juni 2021 gab Google Einzelheiten zu seinem reinen Inferenz-TPU4i-Beschleuniger der vierten Generation bekannt. Fast ein Jahr später hat Google Details zu seinem Trainingsbeschleuniger der 4. Generation, TPUv4, veröffentlicht. Obwohl die offizielle Ankündigung nur wenige Details enthält, werden Spitzenleistung und damit verbundene Leistungsdaten genannt. Wie frühere TPU-Versionen ist TPU4 über Google Compute Cloud verfügbar und wird für interne Vorgänge verwendet.
Das Folgende ist eine Einführung in Beschleuniger, die nicht in Abbildung 2 angezeigt werden. Jede Version veröffentlicht einige Benchmark-Ergebnisse, aber einigen fehlt die Spitzenleistung und andere veröffentlichen keine Spitzenleistung, wie folgt.
SambaNova veröffentlichte letztes Jahr einige Benchmark-Ergebnisse der rekonfigurierbaren KI-Beschleunigertechnologie und veröffentlichte in Zusammenarbeit mit dem Argonne National Laboratory keine Details Leistung oder Stromverbrauch ihrer Lösung aus öffentlich zugänglichen Quellen.
Im Mai dieses Jahres kündigten Intel Habana Labs die Einführung des Goya-Inferenzbeschleunigers und des Gaudi-Trainingsbeschleunigers der zweiten Generation mit den Namen Greco bzw. Gaudi2 an. Beide schneiden um ein Vielfaches besser ab als frühere Versionen. Die Greco ist eine 75-W-PCIe-Karte mit einfacher Breite, während die Gaudi2 ebenfalls eine 650-W-PCIe-Karte mit doppelter Breite ist (wahrscheinlich in einem PCIe 5.0-Steckplatz). Habana veröffentlichte einige Benchmark-Vergleiche von Gaudi2 mit der Nvidia A100-GPU, gab jedoch keine Spitzenleistungswerte für einen der beiden Beschleuniger bekannt.
Esperanto hat einige Demo-Chips für Samsung und andere Partner zur Evaluierung produziert. Der Chip ist ein 1000-Kern-RISC-V-Prozessor mit einem KI-Tensorbeschleuniger pro Kern. Esperanto hat einige Leistungsdaten veröffentlicht, die Spitzenleistung oder Spitzenleistung werden jedoch nicht bekannt gegeben.
Am Tesla AI Day stellte Tesla seinen maßgeschneiderten Dojo-Beschleuniger und einige Details des Systems vor. Ihre Chips haben eine Spitzenleistung von 22,6 TF FP32, der Spitzenstromverbrauch für jeden Chip wurde jedoch nicht bekannt gegeben. Möglicherweise werden diese Details zu einem späteren Zeitpunkt bekannt gegeben.
Letztes Jahr brachte Centaur Technology eine x86-CPU mit integriertem KI-Beschleuniger auf den Markt, die über eine 4096 Byte breite SIMD-Einheit verfügt und eine sehr wettbewerbsfähige Leistung bietet. Doch die Muttergesellschaft von Centaur, VIA Technologies, scheint die Entwicklung von CNS-Prozessoren eingestellt zu haben, nachdem sie ihr in den USA ansässiges Prozessorentwicklungsteam an Intel verkauft hat.
Einige Beobachtungen und Trends
In Abbildung 2 gibt es mehrere erwähnenswerte Beobachtungen, die Details sind wie folgt.
Int8 bleibt die standardmäßige numerische Genauigkeit für eingebettete, autonome und Rechenzentrums-Inferenzanwendungen. Diese Genauigkeit reicht für die meisten KI/ML-Anwendungen aus, die rationale Zahlen verwenden. Einige Beschleuniger verwenden auch fp16 oder bf16. Das Modelltraining verwendet eine Ganzzahldarstellung.
Neben dem Beschleuniger für maschinelles Lernen wurden in dem extrem stromsparenden Chip keine weiteren Zusatzfunktionen gefunden. In den Kategorien Ultra-Low-Power-Chip und Embedded werden häufig System-on-Chip-Lösungen (SoC) auf den Markt gebracht, die häufig CPU-Kerne mit geringem Stromverbrauch, Audio- und Video-Analog-Digital-Wandler (ADCs) und kryptografische Engines umfassen , Netzwerkschnittstellen usw. . Diese zusätzlichen Funktionen des SoC verändern die Spitzenleistungsmetriken nicht, haben aber einen direkten Einfluss auf die vom Chip gemeldete Spitzenleistung, was beim Vergleich wichtig ist.
Am eingebetteten Teil hat sich nicht viel geändert, was bedeutet, dass die Rechenleistung und Spitzenleistung ausreichen, um die Anwendungsanforderungen in diesem Bereich zu erfüllen.
Mehrere Unternehmen, darunter Texas Instruments, haben in den letzten Jahren KI-Beschleuniger herausgebracht. Und NVIDIA hat, wie bereits erwähnt, auch einige leistungsstärkere Systeme für Automobil- und Robotikanwendungen herausgebracht. Im Rechenzentrum wird die PCIe v5-Spezifikation mit Spannung erwartet, um die 300-W-Leistungsgrenze von PCIe v4 zu durchbrechen.
Schließlich liefern High-End-Trainingssysteme nicht nur beeindruckende Leistungszahlen, sondern diese Unternehmen bringen auch hoch skalierbare Verbindungstechnologie auf den Markt, um Tausende von Karten miteinander zu verbinden. Dies ist besonders wichtig für Datenflussbeschleuniger wie Cerebras, GraphCore, Groq, Tesla Dojo und SambaNova, die über explizite/statische Programmierung oder Place-and-Route auf der Rechenhardware programmiert werden. Auf diese Weise können diese Beschleuniger in sehr große Modelle wie Transformatoren eingebaut werden.
Weitere Informationen finden Sie im Originalartikel.
Das obige ist der detaillierte Inhalt vonDas MIT fasst die letzten drei Jahre zusammen und veröffentlicht einen Übersichtsartikel zu KI-Beschleunigern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr