
Heim >Technologie-Peripheriegeräte >KI >Optimierungsmethode für Transformer-Modelle für lange Codesequenzen zur Verbesserung der Leistung in Szenarien mit langem Code
Optimierungsmethode für Transformer-Modelle für lange Codesequenzen zur Verbesserung der Leistung in Szenarien mit langem Code

- PHPznach vorne
- 2023-04-29 08:34:061845Durchsuche
Die Alibaba Cloud-Plattform für maschinelles Lernen PAI hat mit dem Team von Professor Gao Ming von der East China Normal University zusammengearbeitet, um das strukturbewusste Transformer-Modell SASA mit geringer Aufmerksamkeit auf der SIGIR2022 zu veröffentlichen. Dies ist eine Transformer-Modelloptimierungsmethode für lange Codesequenzen, die der Verbesserung gewidmet ist Leistung langer Codesequenzen und Leistung. Da die Komplexität des Selbstaufmerksamkeitsmoduls exponentiell mit der Sequenzlänge zunimmt, verwenden die meisten programmierbasierten Pretrained Language Models (PPLM) Sequenzkürzungen, um Codesequenzen zu verarbeiten. Die SASA-Methode spart die Berechnung der Selbstaufmerksamkeit und kombiniert die Strukturmerkmale des Codes, wodurch die Leistung von Aufgaben mit langen Sequenzen verbessert und Speicher und Rechenkomplexität reduziert werden.
Artikel: Tingting Liu, Chengyu Wang, Cen Chen, Ming Gao und Aoying Zhou. Verständnis langer Programmiersprachen mit strukturbewusster, spärlicher Aufmerksamkeit.
Modellrahmen: Die folgende Abbildung zeigt den Gesamtrahmen von SASA :
 Davon umfasst SASA hauptsächlich zwei Phasen: die Vorverarbeitungsphase und die Sparse Transformer-Trainingsphase. In der Vorverarbeitungsphase werden die Interaktionsmatrizen zwischen zwei Token erhalten, eine ist die Top-k-Frequenzmatrix und die andere ist die AST-Mustermatrix. Die Top-k-Häufigkeitsmatrix verwendet ein vorab trainiertes Code-Sprachmodell, um die Aufmerksamkeitsinteraktionshäufigkeit zwischen Token im CodeSearchNet-Korpus zu lernen. Die AST-Mustermatrix ist ein abstrakter Syntaxbaum (AST), der den Code analysiert über die Verbindungsbeziehung des Syntaxbaums. Interaktive Informationen zwischen Token. Die Sparse Transformer-Trainingsphase verwendet Transformer Encoder als Grundgerüst, ersetzt die vollständige Selbstaufmerksamkeit durch strukturbewusste, spärliche Selbstaufmerksamkeit und führt Aufmerksamkeitsberechnungen zwischen Token-Paaren durch, die bestimmten Mustern entsprechen, wodurch die Rechenkomplexität reduziert wird.
Davon umfasst SASA hauptsächlich zwei Phasen: die Vorverarbeitungsphase und die Sparse Transformer-Trainingsphase. In der Vorverarbeitungsphase werden die Interaktionsmatrizen zwischen zwei Token erhalten, eine ist die Top-k-Frequenzmatrix und die andere ist die AST-Mustermatrix. Die Top-k-Häufigkeitsmatrix verwendet ein vorab trainiertes Code-Sprachmodell, um die Aufmerksamkeitsinteraktionshäufigkeit zwischen Token im CodeSearchNet-Korpus zu lernen. Die AST-Mustermatrix ist ein abstrakter Syntaxbaum (AST), der den Code analysiert über die Verbindungsbeziehung des Syntaxbaums. Interaktive Informationen zwischen Token. Die Sparse Transformer-Trainingsphase verwendet Transformer Encoder als Grundgerüst, ersetzt die vollständige Selbstaufmerksamkeit durch strukturbewusste, spärliche Selbstaufmerksamkeit und führt Aufmerksamkeitsberechnungen zwischen Token-Paaren durch, die bestimmten Mustern entsprechen, wodurch die Rechenkomplexität reduziert wird.
SASA spärliche Aufmerksamkeit umfasst insgesamt die folgenden vier Module:
Sliding-Window-Aufmerksamkeit: Berechnet nur die Selbstaufmerksamkeit zwischen Token im Schiebefenster und behält dabei die Eigenschaften des lokalen Kontexts, die Rechenkomplexität und die Sequenzlänge bei. ist die Größe des Schiebefensters.- Globale Aufmerksamkeit: Legen Sie bestimmte globale Token fest, um Aufmerksamkeitsberechnungen mit allen Token in der Sequenz durchzuführen, um die globalen Informationen der Sequenz zu erhalten.
- Spärliche Top-k-Aufmerksamkeit: Die Aufmerksamkeitsinteraktion im Transformer-Modell ist spärlich und langschwänzig. Für jeden Token werden nur die Top-k-Token mit der höchsten Aufmerksamkeitsinteraktion berechnet.
- AST-bewusste Strukturaufmerksamkeit: Code unterscheidet sich von Sequenzen in natürlicher Sprache und weist stärkere Strukturmerkmale auf. Durch das Parsen des Codes in einen abstrakten Syntaxbaum (AST) wird der Umfang der Aufmerksamkeitsberechnung basierend auf der Verbindungsbeziehung im Syntaxbaum bestimmt .
- Um uns an die parallelen Recheneigenschaften moderner Hardware anzupassen, teilen wir die Sequenz in mehrere Blöcke auf, anstatt in Token-Einheiten zu berechnen. Jeder Abfrageblock verfügt über
 Schiebefensterblöcke und
Schiebefensterblöcke und
 Globale Blöcke und
Globale Blöcke und
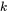 Top-K- und AST-Blöcke berechnen die Aufmerksamkeit. Die gesamte Rechenkomplexität beträgt
Top-K- und AST-Blöcke berechnen die Aufmerksamkeit. Die gesamte Rechenkomplexität beträgt
 b ist die Blockgröße.
b ist die Blockgröße.
Jedes spärliche Aufmerksamkeitsmuster entspricht einer Aufmerksamkeitsmatrix. Am Beispiel der Schiebefenster-Aufmerksamkeit lautet die Berechnung der Aufmerksamkeitsmatrix:
 ASA-Pseudocode:
ASA-Pseudocode:
Experimentelle Ergebnisse
Wir verwenden zur Auswertung vier von CodeXGLUE[1] bereitgestellte Aufgabendatensätze, nämlich Code-Klonerkennung, Fehlererkennung, Codesuche und Codezusammenfassung. Wir haben die Daten extrahiert, deren Sequenzlänge größer als 512 ist, um einen langen Sequenzdatensatz zu bilden. Die experimentellen Ergebnisse sind wie folgt:
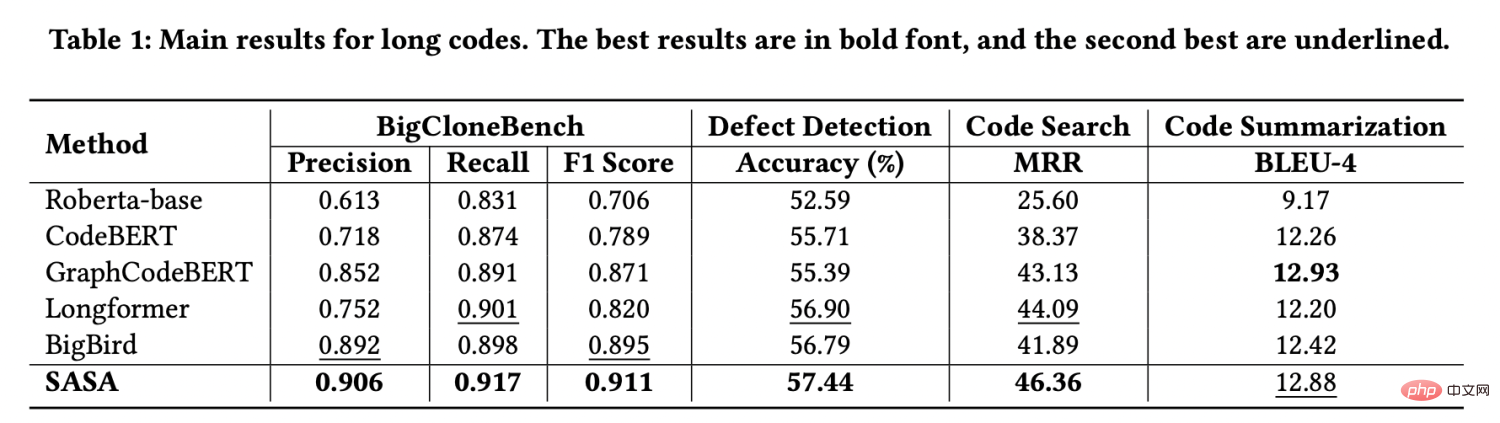
Wie aus den experimentellen Ergebnissen ersichtlich ist, ist die Leistung von SASA bei den drei Datensätzen signifikant übersteigt die aller Baselines. Unter diesen verwenden Roberta-base[2], CodeBERT[3] und GraphCodeBERT[4] die Kürzung, um lange Sequenzen zu verarbeiten, wodurch ein Teil der Kontextinformationen verloren geht. Longformer[5] und BigBird[6] sind Methoden zur Verarbeitung langer Sequenzen in der Verarbeitung natürlicher Sprache. Sie berücksichtigen jedoch nicht die strukturellen Eigenschaften des Codes und die direkte Übertragung auf die Codeaufgabe ist wirkungslos.
Um die Wirkung von Top-K-Spärse-Aufmerksamkeits- und AST-bewussten Sparse-Aufmerksamkeits-Modulen zu überprüfen, haben wir Ablationsexperimente an BigCloneBench- und Defekterkennungsdatensätzen durchgeführt. Die Ergebnisse sind wie folgt:

Das Sparse-Aufmerksamkeitsmodul ist Nicht nur für lange Codeaufgaben geeignet. Die Leistung wurde verbessert und die Nutzung des Videospeichers kann erheblich reduziert werden. Auf demselben Gerät kann SASA eine größere Stapelgröße festlegen, während das Modell mit vollständiger Selbstaufmerksamkeit dem Problem des Speichermangels gegenübersteht . Die spezifische Videospeichernutzung ist wie folgt:

SASA kann als Modul mit geringer Aufmerksamkeit auf andere vorab trainierte Modelle migriert werden, die auf Transformer basieren, um Aufgaben zur Verarbeitung natürlicher Sprache mit langen Sequenzen zu bewältigen Open-Source-Framework EasyNLP (https://github.com/alibaba/EasyNLP) und leisten Sie einen Beitrag zur Open-Source-Community.
Link zum Papier:
https://arxiv.org/abs/2205.13730
Das obige ist der detaillierte Inhalt vonOptimierungsmethode für Transformer-Modelle für lange Codesequenzen zur Verbesserung der Leistung in Szenarien mit langem Code. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr