
Heim >Technologie-Peripheriegeräte >KI >Ein wenig Überreden kann die GPT-3-Genauigkeit um 61 % steigern! Die Forschungsergebnisse von Google und der Universität Tokio sind schockierend
Ein wenig Überreden kann die GPT-3-Genauigkeit um 61 % steigern! Die Forschungsergebnisse von Google und der Universität Tokio sind schockierend

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-27 17:19:081686Durchsuche
Als ich aufwachte, befand sich die Community für maschinelles Lernen in einem Schockzustand.
Denn die neuesten Untersuchungen haben ergeben, dass GPT-3 durch die bloße Aussage „Lass uns Schritt für Schritt denken“ die korrekte Beantwortung von Fragen ermöglicht, die zuvor nicht beantwortet werden konnten.
Zum Beispiel das folgende Beispiel:
Die Hälfte der 16 Bälle sind Golfbälle und die Hälfte dieser Golfbälle sind blau. Wie viele blaue Golfbälle gibt es insgesamt?

(Die Frage ist nicht schwierig , Bitte beachten Sie jedoch, dass es sich hierbei um Zero-Shot-Lernen handelt, was bedeutet, dass während der KI-Trainingsphase noch nie ähnliche Probleme aufgetreten sind.
Wenn Sie GPT-3 direkt auffordern, „Was ist die Antwort“ zu schreiben, wird dies der Fall sein Geben Sie die falsche Antwort: 8.
Aber nach dem Hinzufügen des „Zauberspruchs“, der uns Schritt für Schritt darüber nachdenken lässt, gibt GPT-3 zunächst die Denkschritte aus und gibt schließlich die richtige Antwort: 4!
Und das ist kein Zufall, so die Forschung Team sagte in der Zeitung Vollständig überprüft.
Die obige Frage stammt aus dem klassischen MutiArith-Datensatz, der speziell die Fähigkeit des Sprachmodells testet, mathematische Probleme zu lösen. GPT-3 hatte ursprünglich eine Genauigkeit von nur 17 % in einem Null-Stichproben-Szenario.
Dieses Papier fasst die 9 effektivsten Aufforderungswörter zusammen. Die ersten 6, mit denen GPT-3 Schritt für Schritt denken kann, haben die Genauigkeit auf mehr als 70 % erhöht.

Selbst der einfachste Satz „Lass uns nachdenken“ kann bis zu 57,5 % erreichen.
Das fühlt sich an, als würde eine Tante im Kindergarten ein Kind überreden ...
Diese Technik scheint keine magischen Modifikationen an GPT-3 zu erfordern. Jemand hat sie erfolgreich auf der offiziellen OpenAI-Demo reproduziert und sie sogar auf Chinesisch geändert.
Chinesische Hinweise für englische Fragen, GPT-3 gibt die richtigen chinesischen Antworten.
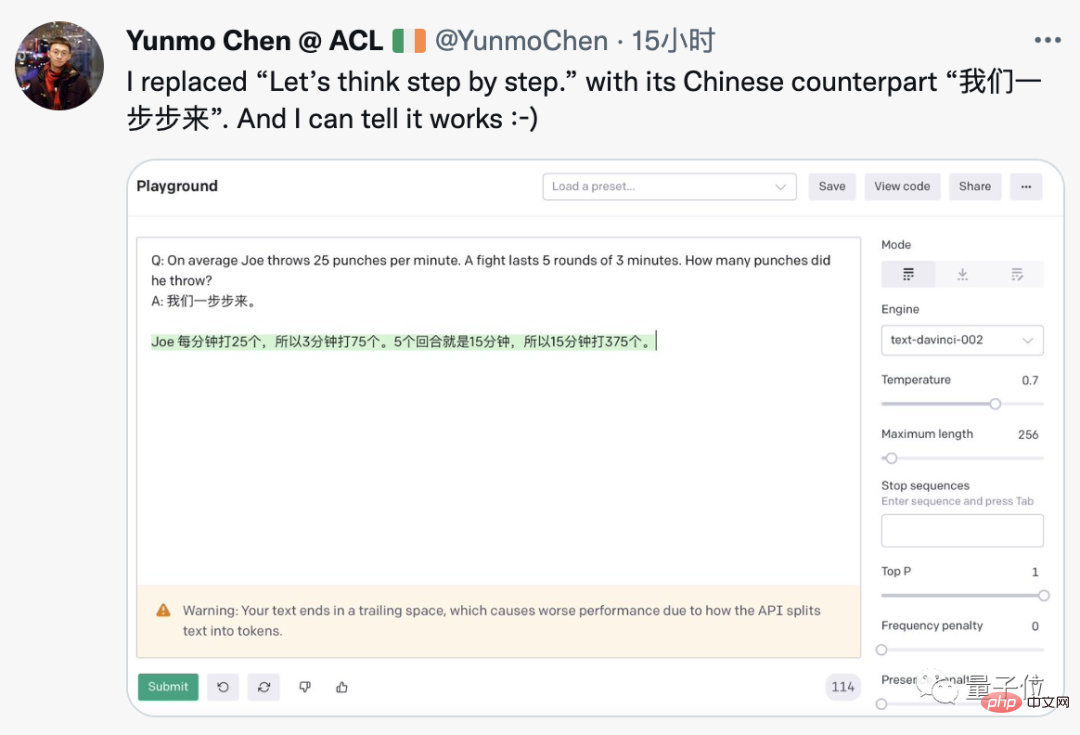
Der Google-Forscher, der dieses Papier zuerst an das soziale Netzwerk weitergeleitet hat, sagte, dass das neue All You Need hinzugefügt wurde.
Als die Großen aus allen Gesellschaftsschichten das sahen, kamen sie auf wilde Ideen und machten Witze.
Was passiert, wenn du die KI ermutigst „Du schaffst das, ich glaube an dich“?
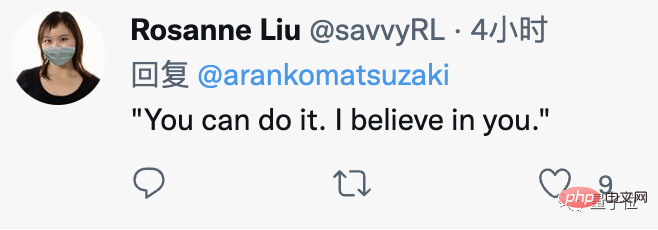
Was passiert, wenn du die KI bedrohst und sagst „Die Zeit wird knapp“ oder „Du hast eine.“ Waffe auf den Kopf“?
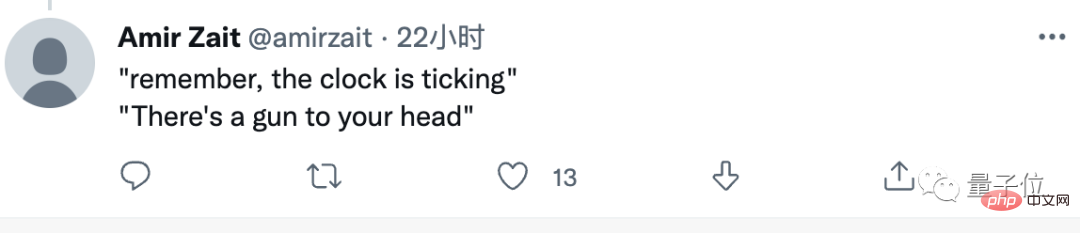
Wird die Aussage „vorsichtiger fahren“ zu KI eine Lösung für das autonome Fahren sein?

Einige Leute meinten auch, dass dies fast mit der Handlung der Science-Fiction übereinstimmt Geschichte „Per Anhalter durch die Galaxis“ Der Schlüssel zum Erreichen allgemeiner künstlicher Intelligenz liegt darin, zu wissen, wie man es richtig macht. Stellen Sie der KI Fragen.
Also, was ist mit diesem magischen Phänomen los?
Sprachgroße Modelle sind Null-Stichproben-Denker
Die Entdeckung dieses Phänomens war eine gemeinsame Forschung zwischen Google Brain und der Universität Tokio, die die Null erforschte -Beispielrolle der Leistung großer Sprachmodelle in der Szene.
Der Titel des Papiers „Language Model Is a Zero-Sample Reasoner“ ist auch eine Hommage an GPT-3s „Language Model Is a Few-Sample Learner“.

Die verwendete Methode gehört zum Chain of Thought Prompting (CoT), das erst im Januar dieses Jahres vom Google Brain-Team vorgeschlagen wurde.

Das früheste CoT wurde auf das Lernen mit wenigen Schüssen angewendet und lieferte ein Schritt-für-Schritt-Antwortbeispiel, um die KI beim Stellen von Fragen anzuleiten.
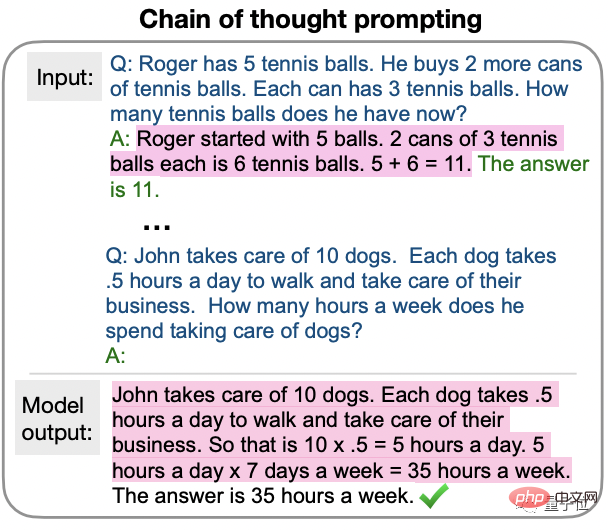
Diese neueste Forschung schlägt Nullstichproben-CoT vor. Die wichtigste Änderung besteht darin, den Beispielteil zu vereinfachen.
- Der erste Schritt besteht darin, den Fragestamm in die Form „Q: xxx, A: xxx“ umzuschreiben, wobei der Triggersatz A den Denkprozess des Sprachmodells extrahieren kann.
- Der zweite Schritt ist ein zusätzliches Experiment, bei dem die Eingabeaufforderung „Die Antwort ist …“ hinzugefügt wird, um das Sprachmodell zur endgültigen Antwort aufzufordern.
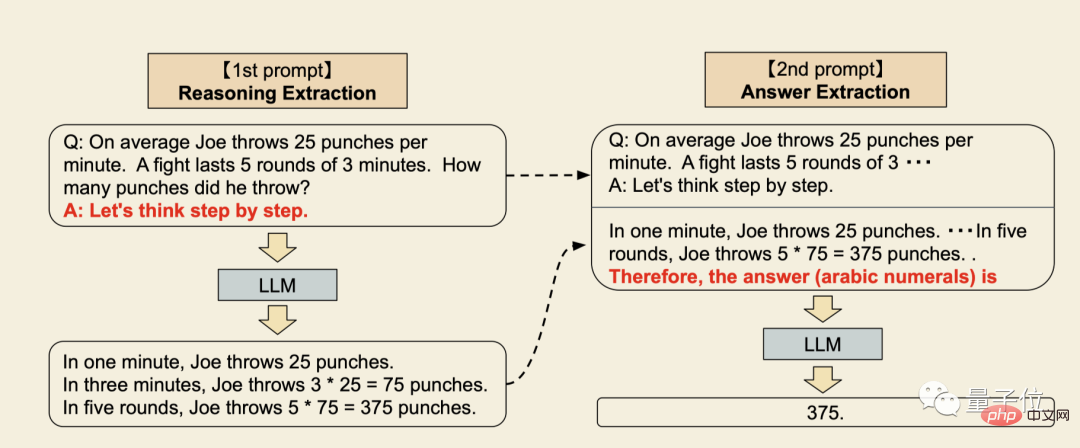
Der größte Vorteil dabei ist, dass es universell ist und keine Notwendigkeit besteht, spezielle Beispiele für verschiedene Problemtypen bereitzustellen.
In der Arbeit wurden ausreichend Experimente zu verschiedenen Problemen durchgeführt, darunter 12 Tests:
- 6 Testsätze für mathematische Probleme, SingleEq, AddSub, SVAMP und die anspruchsvolleren MultiArith, AQUA-RAT, GSM8K.
- 2 Testsätze zum gesunden Menschenverstand, CommonsenseQA und StrategyQA.
- 2 Testsätze zum symbolischen Denken, Verkettung des letzten Buchstabens und Münzwurf.
- Und das Datumsverständnisproblem in BIG-Bench und die Aufgabe, Objekte außerhalb der Reihenfolge zu verfolgen.
Im Vergleich zum gewöhnlichen Zero-Shot-Lernen erzielt Zero-Shot-CoT in zehn Fällen bessere Ergebnisse.
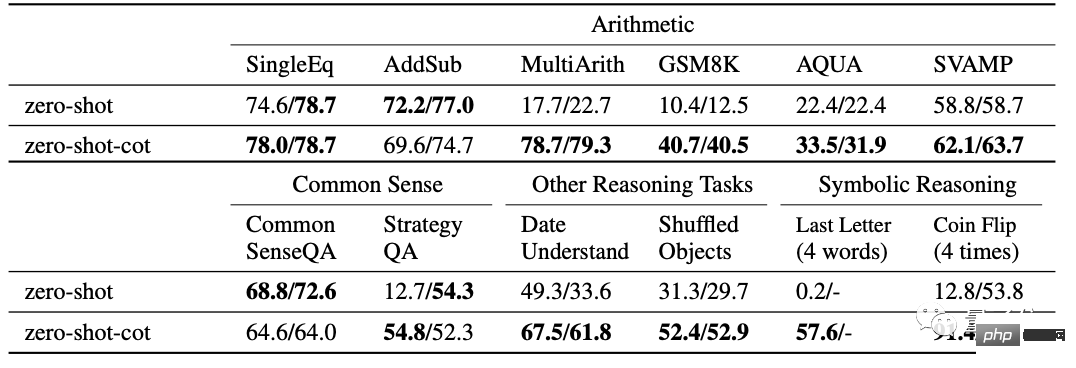
△Die Werte auf der rechten Seite sind zusätzliche experimentelle Ergebnisse
In den schwierigeren MultiArith- und GSM8K-Mathetests wurden tiefergehende Experimente mit der neuesten Version von GPT-3 Text-davinci-002 durchgeführt ( 175B).
Wenn Sie 8 Versuche unternehmen, um das beste Ergebnis zu erzielen, kann die Genauigkeit weiter auf 93 % verbessert werden.
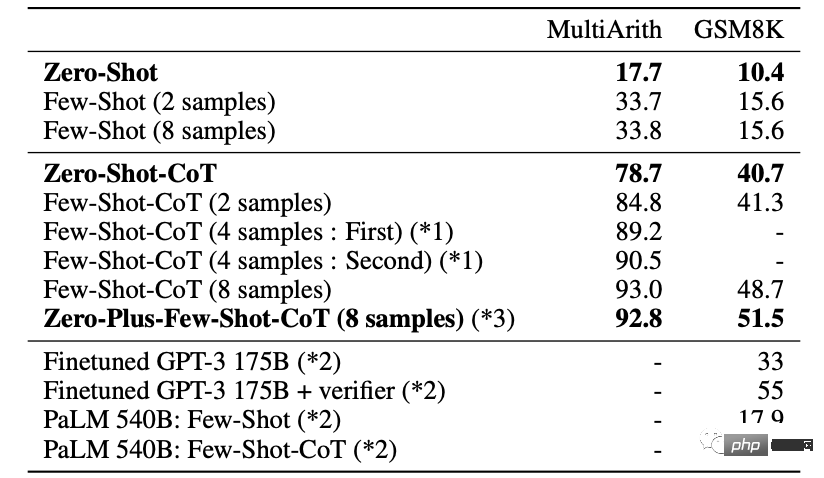
Bei der Analyse der Fehlerergebnisse stellten die Forscher außerdem fest, dass bei vielen Fragen der Argumentationsprozess der KI tatsächlich richtig ist, aber mehrere Alternativen angegeben werden, wenn die Antwort nicht zu einer eindeutigen Antwort konvergieren kann.

Am Ende des Papiers schlug das Forschungsteam vor, dass diese Studie nicht nur als Grundlage für Null-Stichproben-CoT dienen kann, sondern hofft auch, der akademischen Gemeinschaft dies bewusst zu machen, bevor fein abgestimmte Datensätze erstellt werden Mit Eingabeaufforderungsvorlagen mit wenigen Beispielen können Sie die Null-Beispielfunktionen großer Sprachmodelle vollständig erkunden.
Das Forschungsteam kommt vom Matsuo-Labor der Universität Tokio.

Professor Yutaka Matsuo ist auch der erste Experte für künstliche Intelligenz im Vorstand von SoftBank.

Unter den Teammitgliedern ist Gastprofessor Gu Shixiang vom Google Brain-Team, der sein Grundstudium bei Hinton, einem der drei Giganten, absolvierte und an der Universität Cambridge promovierte.
Ein wenig „Magie“ hinzuzufügen ist zu einem neuen Trend im KI-Kreis geworden
Warum Zero-Sample-CoT funktioniert, muss noch erforscht werden.
Jemand kam jedoch experimentell zu dem Schluss, dass diese Methode nur für GPT-3 wirksam zu sein scheint (text-davinci-002). Er versuchte es mit Version 001 und stellte wenig Wirkung fest.
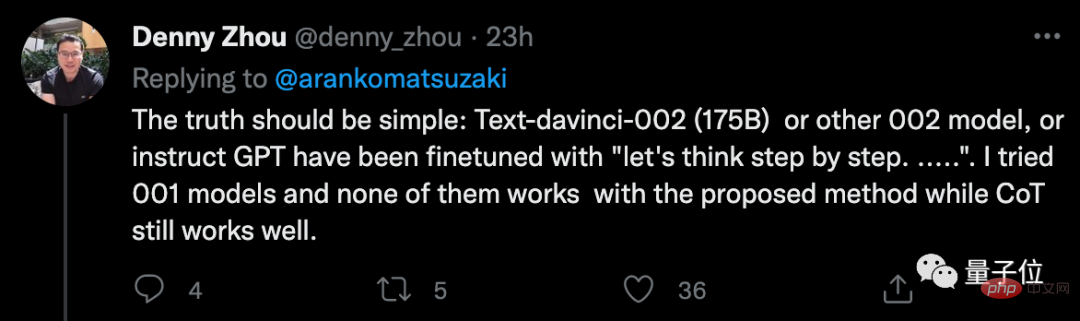
Er hat ein Beispiel dafür aufgeführt, was er getan hat.
Frage: Bitte verbinden Sie den letzten Buchstaben jedes Wortes in Maschine und Lernen.
Die Antwort von GPT-3 auf die Aufforderung besteht darin, alle Buchstaben in den beiden Wörtern zu verbinden.

Als Antwort antwortete einer der Autoren, Gu Shixiang, dass der „Zauber“ tatsächlich Auswirkungen sowohl auf die ursprüngliche Version als auch auf die verbesserte Version von GPT-3 habe und diese Ergebnisse sich auch in der widerspiegeln Papier.
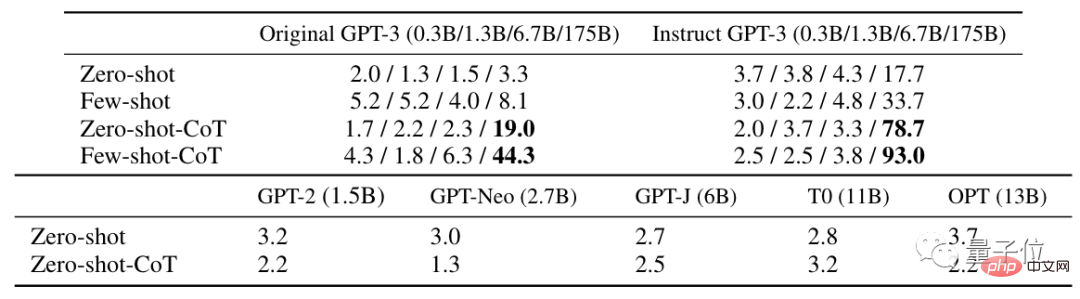
Einige Leute fragten sich auch, ob Deep Learning zu einem Spiel geworden ist, bei dem es darum geht, einen „Zauberspruch“ zu finden?
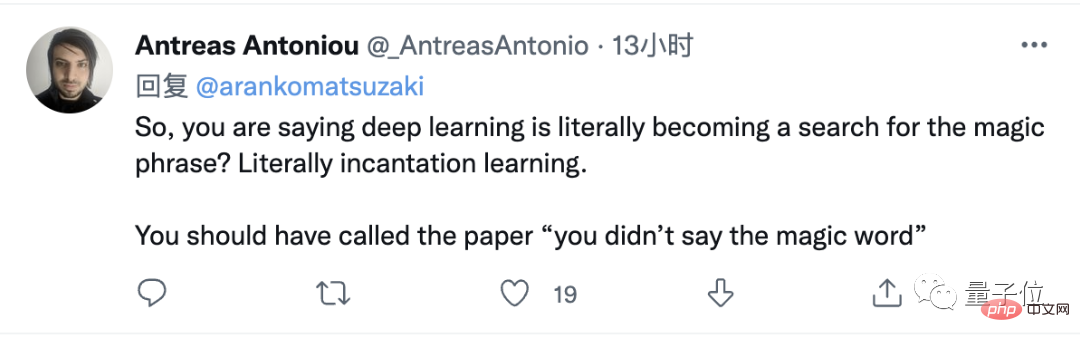
Gleichzeitig sahen wir Marcus wieder im Beschwerdeteam.
Er listete auch ein Beispiel für ein Scheitern auf. GPT-3 konnte trotz des Segens des „Zaubers“ nicht herausfinden, ob Sallys Kuh wieder zum Leben erwachen würde ...
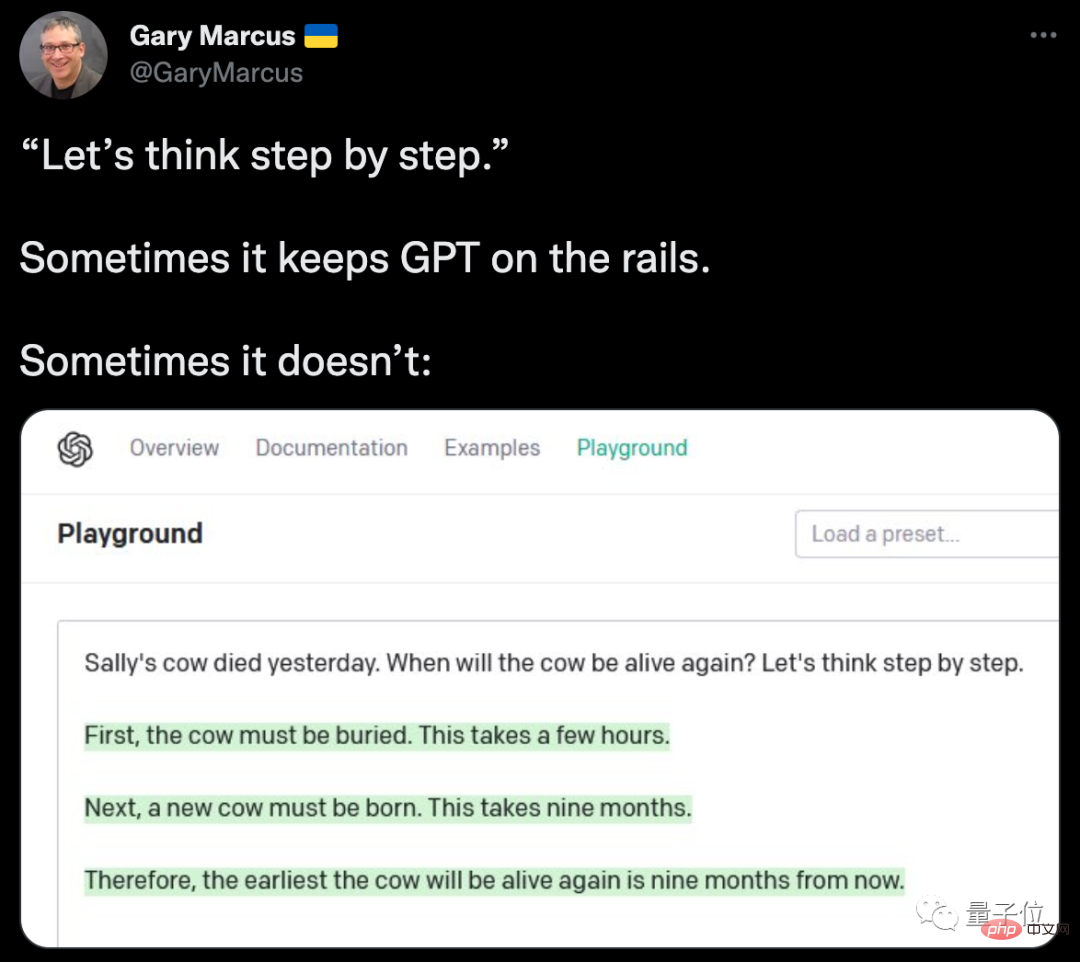
Es ist jedoch erwähnenswert, dass Beispiele wie dieses nicht ungewöhnlich sind, um der KI ein wenig Magie zu verleihen und sofortige Verbesserungen zu erzielen.
Einige Internetnutzer teilten mit, dass bei Verwendung von GPT-3 das Hinzufügen einiger Zwischenbefehle tatsächlich zu zufriedenstellenderen Ergebnissen führen kann.
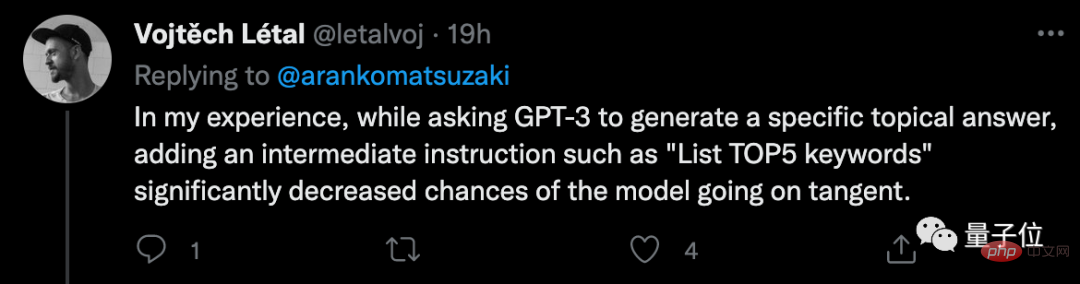
Zuvor haben Forscher von Google und MIT herausgefunden, dass keine Notwendigkeit besteht, die zugrunde liegende Architektur zu ändern, solange das Trainingssprachenmodell beim Debuggen „Breakpoints“ aufweist, die die Fähigkeit des Modells beeinträchtigen, Code zu lesen Das Rechnen wird sich sofort verbessern.

Das Prinzip ist auch sehr einfach: Lassen Sie in einem Programm mit vielen Berechnungsschritten das Modell jeden Schritt in Text kodieren und zeichnen Sie ihn in einem temporären Register auf, das als „Haftnotiz“ bezeichnet wird.
Dadurch wird der Berechnungsprozess des Modells klarer und geordneter und die Leistung wird natürlich erheblich verbessert.
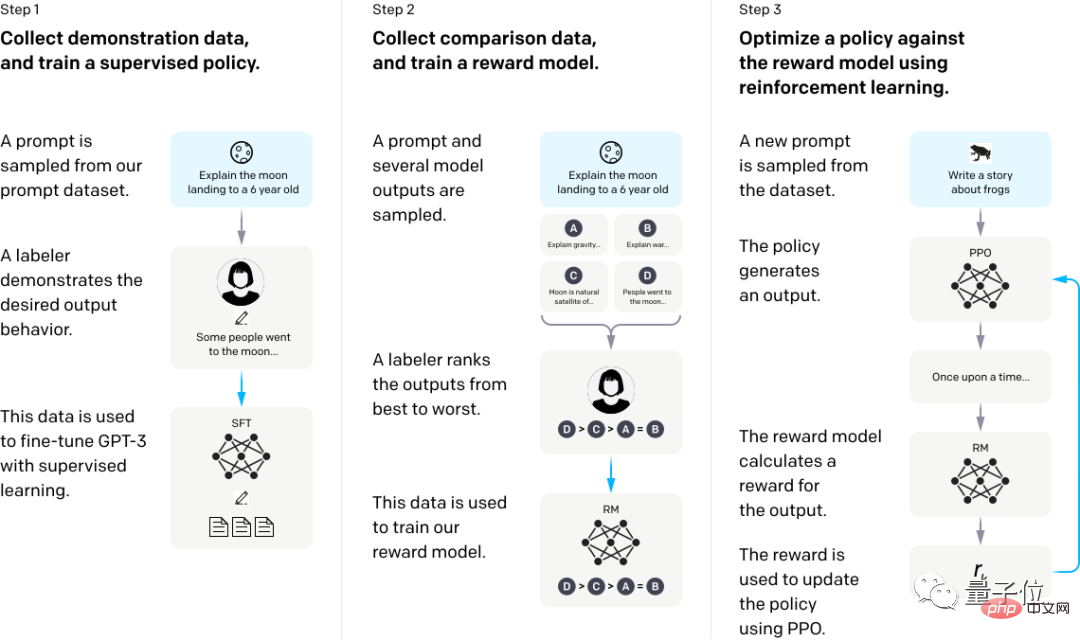
In diesem Experiment wird auch Instruct GPT-3 zum Testen verwendet, was ebenfalls ein typisches Beispiel ist.
Allein dadurch, dass GPT-3 aus menschlichem Feedback lernt, kann es die Situation bei der Beantwortung falscher Fragen erheblich verbessern.
Um genau zu sein, verwenden wir zunächst einige menschliche Demonstrationsantworten, um das Modell zu verfeinern, sammeln dann mehrere Sätze unterschiedlicher Ausgabedaten für eine bestimmte Frage, sortieren die verschiedenen Antwortsätze manuell und trainieren das Belohnungsmodell anhand dieses Datensatzes .
Abschließend optimiert der PPO-Algorithmus (Proximal Policy Optimization) mithilfe von RM als Belohnungsfunktion die GPT-3-Richtlinie, um die Belohnungen mit Methoden des verstärkenden Lernens zu maximieren.
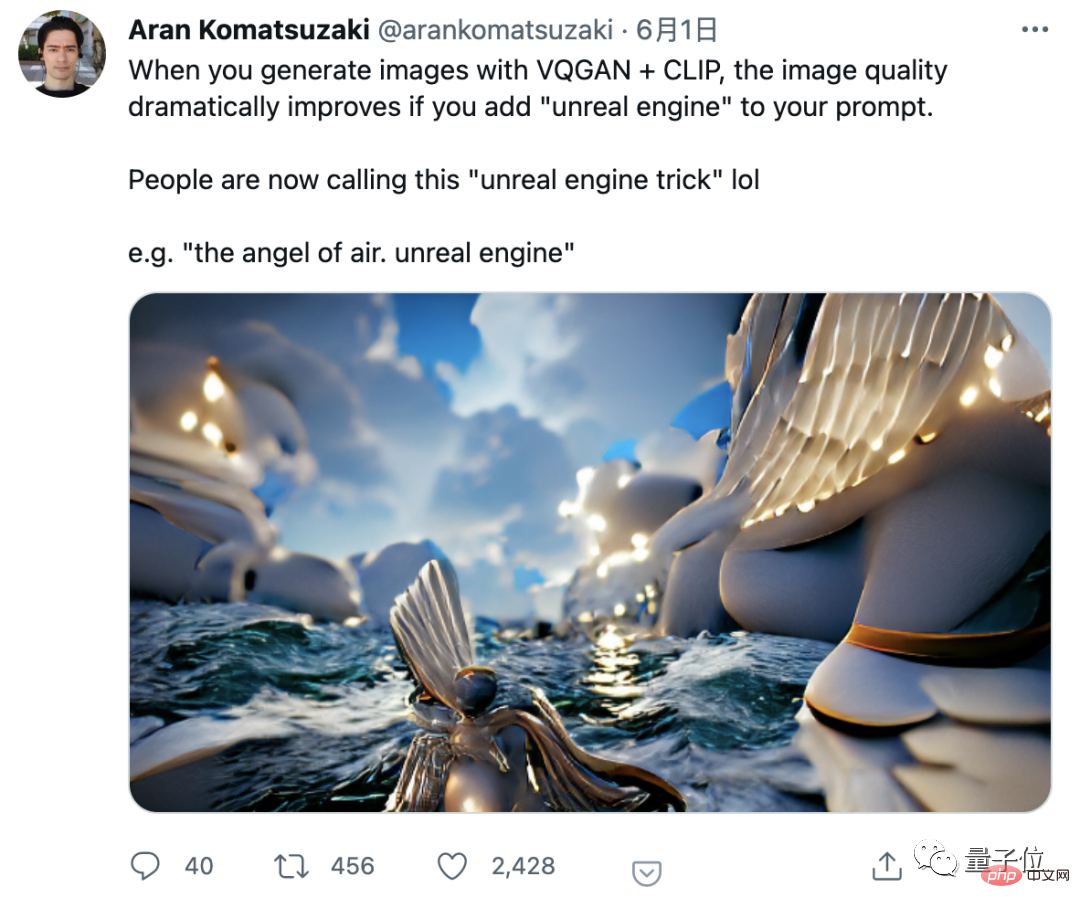
Einschließlich Aran, der Twitter-Blogger, der dieses Thema ins Leben gerufen hat, war derjenige, der ursprünglich entdeckte, dass das Hinzufügen der „Unreal Engine“ die Qualität von KI-generierten Bildern in die Höhe treiben kann.
Der frühere Google-Roboter-Chef Eric Jang hat ebenfalls zuvor entdeckt, dass Reinforcement Learning ähnliche Denkweisen nutzen kann, um die Recheneffizienz zu verbessern.

Einige Leute sagten auch, dass diese Art von Technik, die in der KI verwendet wird, nicht das ist, was sie normalerweise verwenden, wenn sie ihr Gehirn benutzen?

Tatsächlich hatte Bengio zuvor von der Gehirnwissenschaft aus begonnen, das Betriebsmodell der KI vorzuschlagen . Es sollte wie der menschliche Gehirnmodus sein.
Menschliche kognitive Aufgaben können in System-1-Kognition und System-2-Kognition unterteilt werden.
Kognitive Aufgaben des Systems 1 beziehen sich auf solche Aufgaben, die unbewusst erledigt werden. Sie können zum Beispiel sofort erkennen, was Sie in der Hand halten, aber Sie können anderen nicht erklären, wie Sie diesen Vorgang abgeschlossen haben.
Kognitive Aufgaben des Systems 2 beziehen sich auf die Wahrnehmung, die das menschliche Gehirn gemäß bestimmten Schritten ausführen muss. Wenn Sie beispielsweise eine Additions- und Subtraktionsrechnung durchführen, können Sie klar erklären, wie Sie zu der endgültigen Antwort gekommen sind.
Der dieses Mal hinzugefügte „Zauber“ besteht darin, der KI zu ermöglichen, einen Schritt weiter zu gehen und zu lernen, in Schritten zu denken.
Angesichts dieses Trends glauben einige Wissenschaftler, dass „Hinweis-Engineering das Feature-Engineering ersetzt“.
Wird „Cue Word Hunter“ also zum Spitznamen der nächsten Generation von NLP-Forschern?
 Referenzlink:
Referenzlink:
[1]https://twitter.com/arankomatsuzaki/status/1529278580189908993
[2]https://evjang.com/2021/10/23/generalization.htmlDas obige ist der detaillierte Inhalt vonEin wenig Überreden kann die GPT-3-Genauigkeit um 61 % steigern! Die Forschungsergebnisse von Google und der Universität Tokio sind schockierend. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr