
Heim >Technologie-Peripheriegeräte >KI >Kann Stable Diffusion Algorithmen wie JPEG übertreffen und die Bildkomprimierung bei gleichzeitiger Beibehaltung der Klarheit verbessern?
Kann Stable Diffusion Algorithmen wie JPEG übertreffen und die Bildkomprimierung bei gleichzeitiger Beibehaltung der Klarheit verbessern?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-27 08:28:072159Durchsuche
Das textbasierte Bildgenerierungsmodell ist sehr beliebt. Nicht nur das Diffusionsmodell ist beliebt, sondern auch das Open-Source-Stable-Diffusion-Modell. Kürzlich entdeckte ein Schweizer Softwareentwickler, Matthias Bühlmann, zufällig, dass Stable Diffusion nicht nur zum Generieren von Bildern verwendet werden kann, sondern auch zum Komprimieren von Bitmap-Bildern , sogar mit einer höheren Komprimierungsrate als JPEG und WebP.

Das Originalbild ist 768 KB, das mit JPEG und Stabil auf 5,66 KB komprimiert ist Die Diffusion kann weiter# 🎜🎜#auf 4,98 KB komprimiert werden und kann mehr hochauflösende Details beibehalten und
weniger Komprimierungsartefakte, was sichtbar besser ist das bloße Auge gegenüber anderen Komprimierungsalgorithmen. Diese Komprimierungsmethode weist jedoch auch Nachteile auf, das heißt, ist nicht für die Gesichtskomprimierung geeignet und Textbilder , in manchen Fällen erzeugt sogar einige Originalbilder ohne Inhalt
.
Obwohl das Neutraining eines Autoencoders auch etwas Ähnliches wie den Stable Diffusion-Komprimierungseffekt bewirken kann , aber einer der Hauptvorteile der Verwendung von Stable Diffusion besteht darin, dass jemand Millionen von Geldern
investiert hat, um Ihnen bei der Ausbildung zu helfen, und Sie Warum sich die Mühe machen, Geld auszugeben, um erneut zu trainieren# 🎜🎜 #Wie wäre es mit einem Komprimierungsmodell? 
Wie Stable Diffusion Bilder komprimiertDiffusionsmodelle stellen die Dominanz generativer Modelle in Frage, und das entsprechende Open-Source-Stable-Diffusion-Modell ist ebenfalls verfügbar Die Community für maschinelles Lernen Starten Sie eine künstlerische Revolution.
Stabile Diffusion wird durch die Verkettung von drei trainierten neuronalen Netzen erreicht, d. h.
ein Variations-Encoder ( VAE), U-Net-Modell und
ein Text-Encoder. 
Der Variations-Autoencoder kodiert und dekodiert das Bild im Bildraum, um das Bild in # 🎜🎜#The zu erhalten Darstellungsvektor des latenten Raums wird durch eine niedrigere Auflösung (64x64) mit höherer Präzision (4x32bit)
Vektor# 🎜🎜#Quellbild (512x512 Zoll) dargestellt 3x8 oder 4x8bit). 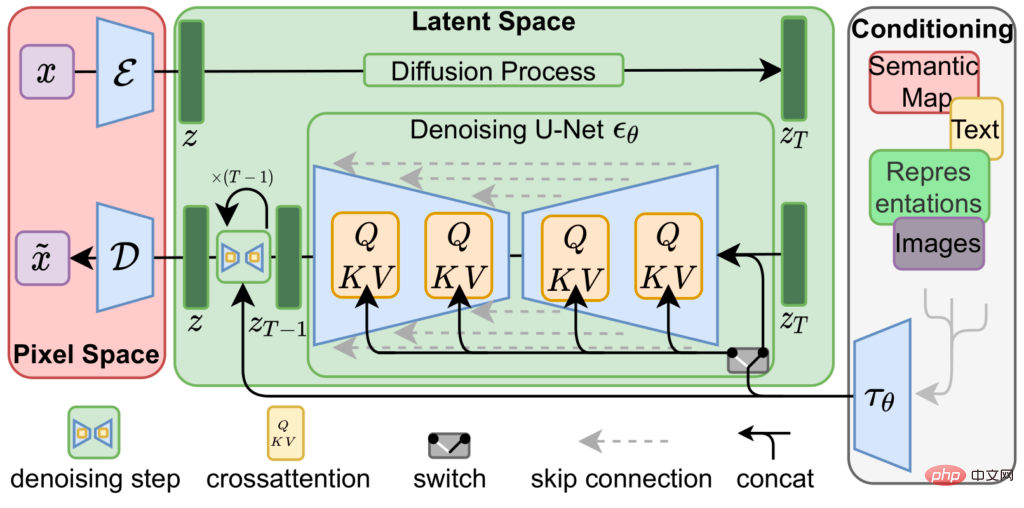
Der Trainingsprozess von VAE zum Codieren von Bildern in den latenten Raum basiert hauptsächlich auf selbstüberwachtem Lernen, das heißt, sowohl die Eingabe als auch die Ausgabe sind Quellbilder, also wie die Modell wird weiter trainiert, unterschiedlich Die Darstellung des latenten Raums kann für verschiedene Versionen des Modells unterschiedlich aussehen. Nach der Neuzuordnung und Interpretation der latenten Raumdarstellung in ein 4-Kanal-Farbbild mit Stable Diffusion v1.4 sieht es wie das mittlere Bild unten im Quellbild aus Die Hauptmerkmale sind weiterhin sichtbar . #? #.
Zum Beispiel ist nach der Dekodierung derANNA-Name auf dem blauen Band nicht so klar wie das Quellbild und die Lesbarkeit ist es deutlich reduziert. Variationelle Autoencoder in
Stable Diffusion v1.4 sind nicht sehr gut darin, #🎜 🎜#kleinen Text und Gesicht darzustellen images
, ich weiß nicht, ob es in Version 1.5 verbessert wird.
Der Hauptkomprimierungsalgorithmus von Stable Diffusion besteht darin, diese latente Raumdarstellung von Bildern zu nutzen, um aus kurzen Textbeschreibungen neue Bilder zu generieren.
Beginnen Sie mit dem zufälligen Rauschen, das durch den latenten Raum dargestellt wird, verwenden Sie ein vollständig trainiertes U-Net, um das Rauschen iterativ aus dem Bild des latenten Raums zu entfernen, und verwenden Sie eine einfachere Darstellung, um die Vorhersage auszugeben, die das Modell zu „sehen“ glaubt. In diesem Lärm ist es ein bisschen so, als würden wir, wenn wir Wolken betrachten, „die Formen oder Gesichter in unserem Kopf aus unregelmäßigen Formen wiederherstellen“.
Bei der Verwendung von Stable Diffusion zum Generieren von Bildern wird dieser iterative Entrauschungsschritt von einer dritten Komponente, dem Text-Encoder, gesteuert, der U-Net eine Vorstellung davon liefert, was es in den Rauschinformationen sehen soll.Für Komprimierungsaufgaben ist jedoch kein Text-Encoder erforderlich
, sodass der experimentelle Prozess nur eine leere ZeichenfolgeCodierung erstellt hat, um U-Net anzuweisen, während des Bildrekonstruktionsprozesses eine nicht-geführte Decodierung durchzuführen. Laut. Um Stable Diffusion als Bildkomprimierungscodec verwenden zu können, muss der Algorithmus die von VAE erzeugte latente Darstellung effektiv komprimieren.
In Experimenten konnte festgestellt werden, dass ein Downsampling der latenten Darstellung oder die direkte Verwendung vorhandener verlustbehafteter Bildkomprimierungsmethoden die Qualität des rekonstruierten Bildes erheblich verringert.
Aber der Autor stellte fest, dass die VAE-Dekodierung bei der Quantisierung latenter Darstellungen sehr effektiv zu sein scheint.
Das Skalieren, Klemmen und Neuzuordnen von Potentialen von Gleitkommazahlen zu vorzeichenlosen 8-Bit-Ganzzahlen führt nur zu kleinen sichtbaren Rekonstruktionsfehlern.
 Durch Quantisierung der latenten 8-Bit-Darstellung beträgt die durch das Bild dargestellte Datengröße jetzt 64*64*4*8bit=16kB, was viel kleiner ist als 512*512*3*8bit=768kB des unkomprimierten Quellbildes
Durch Quantisierung der latenten 8-Bit-Darstellung beträgt die durch das Bild dargestellte Datengröße jetzt 64*64*4*8bit=16kB, was viel kleiner ist als 512*512*3*8bit=768kB des unkomprimierten Quellbildes
Wenn die Anzahl der latenten Darstellungen weniger als 8 Bit beträgt, werden keine besseren Ergebnisse erzielt.
Wenn Sie das Bild weiter
palettierenund dithern durchführen, verbessert sich der Quantisierungseffekt erneut. Erstellte eine Palettendarstellung mit 256*4*8-Bit-Vektoren und Floyd-Steinberg-Dithering-Latentdarstellung und komprimierte die Datengröße weiter auf 64*64*8+256*4*8bit=5kB
 Durch das Zittern der Latentraumpalette entsteht Rauschen, das die Dekodierungsergebnisse verzerrt. Da die stabile Diffusion jedoch auf der Entfernung latenten Rauschens basiert, kann U-Net zum Entfernen des durch Jitter verursachten Rauschens verwendet werden.
Durch das Zittern der Latentraumpalette entsteht Rauschen, das die Dekodierungsergebnisse verzerrt. Da die stabile Diffusion jedoch auf der Entfernung latenten Rauschens basiert, kann U-Net zum Entfernen des durch Jitter verursachten Rauschens verwendet werden.
Nach 4 Iterationen kommt das Rekonstruktionsergebnis optisch der unquantisierten Version sehr nahe.
 Obwohl die Datenmenge stark reduziert ist (das Quellbild ist 155-mal größer als das komprimierte Bild), ist der Effekt sehr gut, es treten jedoch auch einige Artefakte auf (z. B. das herzförmige Muster). (ist im Originalbild nicht vorhanden) Artefakte).
Obwohl die Datenmenge stark reduziert ist (das Quellbild ist 155-mal größer als das komprimierte Bild), ist der Effekt sehr gut, es treten jedoch auch einige Artefakte auf (z. B. das herzförmige Muster). (ist im Originalbild nicht vorhanden) Artefakte).
Interessanterweise haben die durch dieses Komprimierungsschema eingeführten Artefakte einen größeren Einfluss auf den Bildinhalt als auf die Bildqualität, und auf diese Weise komprimierte Bilder können diese Art von Komprimierungsartefakten enthalten.
Der Autor hat auch
zlib verwendet, um eine verlustfreie Komprimierung auf der Palette und dem Index durchzuführen. In den Testbeispielen waren die meisten Komprimierungsergebnisseweniger als 5 KB, aber diese Komprimierungsmethode bietet noch mehr Raum für Optimierung. Um den Komprimierungscodec zu bewerten, hat der Autor keine im Internet gefundenen Standardtestbilder verwendet
, da die Bilder im Internet möglicherweise im Trainingssatz von Stable Diffusion erschienen sind und die Komprimierung solcher Bilder möglicherweise der Fall ist Ursache Unfairer komparativer Vorteil.Um den Vergleich so fair wie möglich zu gestalten, hat der Autor die hochwertigsten Encodereinstellungen aus der Python-Bildbibliothek verwendet und eine verlustfreie Datenkomprimierung der komprimierten JPG-Daten mithilfe der mozjpeg-Bibliothek hinzugefügt.
Es ist erwähnenswert, dass die Ergebnisse von Stable Diffusion zwar subjektiv viel besser aussehen als JPG- und WebP-komprimierte Bilder, bei Standardmessungen wie PSNR oder SSIM jedoch nicht wesentlich besser, aber nicht schlechter sind.
Es ist nur so, dass die Arten der eingeführten Artefakte weniger offensichtlich sind, weil sie einen größeren Einfluss auf den Bildinhalt als auf die Bildqualität haben.
Auch diese Komprimierungsmethode ist etwas gefährlich, denn obwohl die Qualität der rekonstruierten Features hoch ist, kann der Inhalt durch Komprimierungsartefakte beeinträchtigt werden, auch wenn er sehr scharf aussieht .
Zum Beispiel in einem Testbild, während Stable Diffusion als Codec die Bildqualität viel besser beibehält, sogar Kamerakörnung Die Textur (Kamerakörnung) bleibt erhalten (was für die meisten herkömmlichen Komprimierungsalgorithmen schwierig ist), aber ihr Inhalt wird immer noch durch Komprimierungsartefakte beeinträchtigt, und feine Merkmale wie Gebäudeformen können sich ändern.

Obwohl es natürlich unmöglich ist, in einem JPG-komprimierten Bild mehr Wahrheit zu erkennen als in einem mit stabiler Diffusion komprimierten Bild Wert, aber die hohe visuelle Qualität der Stable Diffusion-Komprimierungsergebnisse kann täuschen , da Komprimierungsartefakte in JPG und WebP leichter zu identifizieren sind.
Wenn Sie das Experiment auch reproduzieren möchten, hat der Autor den Code auf Colab als Open Source bereitgestellt.
Code-Link: https://colab.research.google.com/drive/ 1Ci1VYHuFJK5eOX9TB0Mq4NsqkeDr MaaH ?usp=sharing
Abschließend sagte der Autor, dass das im Artikel entworfene Experiment immer noch recht einfach sei, der Effekt aber dennoch überraschend sei,# 🎜🎜#Es gibt in Zukunft noch viel Raum für Verbesserungen.
Das obige ist der detaillierte Inhalt vonKann Stable Diffusion Algorithmen wie JPEG übertreffen und die Bildkomprimierung bei gleichzeitiger Beibehaltung der Klarheit verbessern?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr