
Heim >Technologie-Peripheriegeräte >KI >Der Deep-Learning-Riese DeepMind hat ein Papier veröffentlicht, in dem es darum geht, KI-Modellen dringend beizubringen, „menschlich zu werden', um das Problem des menschlichen Aussterbens zu lösen, das durch GPT-5 verursacht werden könnte.
Der Deep-Learning-Riese DeepMind hat ein Papier veröffentlicht, in dem es darum geht, KI-Modellen dringend beizubringen, „menschlich zu werden', um das Problem des menschlichen Aussterbens zu lösen, das durch GPT-5 verursacht werden könnte.

- PHPznach vorne
- 2023-04-27 08:04:07947Durchsuche
Das Aufkommen von GPT-4 hat KI-Tycoons auf der ganzen Welt Angst gemacht. Der offene Brief, in dem die Aussetzung des GPT-5-Trainings gefordert wird, wurde bereits von 50.000 Menschen unterzeichnet.
Sam Altman, CEO von OpenAI, prognostiziert, dass es innerhalb weniger Jahre eine große Anzahl unterschiedlicher KI-Modelle auf der ganzen Welt geben wird, jedes mit seiner eigenen Intelligenz und seinen eigenen Fähigkeiten und nach unterschiedlichen ethischen Grundsätzen.

Wenn nur ein Tausendstel dieser KIs sich aus irgendeinem Grund unkontrolliert verhält, dann werden wir Menschen zweifellos zu Fischen auf dem Schneidebrett.
Um zu verhindern, dass wir versehentlich durch KI zerstört werden, gab DeepMind in einem am 24. April in den Proceedings of the National Academy of Sciences (PNAS) veröffentlichten Artikel eine Antwort – und zwar unter Verwendung des Standpunkts des politischen Philosophen Rawls KI, um ein Mensch zu sein.
Papieradresse: https://www.pnas.org/doi/10.1073/pnas.2213709120
Wie bringt man der KI bei, ein Mensch zu sein?
Wenn die KI vor der Wahl steht, wird sie sich dafür entscheiden, die Verbesserung der Produktivität in den Vordergrund zu stellen, oder sich dafür entscheiden, denjenigen zu helfen, die am meisten Hilfe benötigen?
Die Gestaltung der Werte der KI ist sehr wichtig. Wir müssen ihm einen Wert geben.
Aber die Schwierigkeit besteht darin, dass wir Menschen intern keinen einheitlichen Wertekanon haben können. Jeder Mensch auf dieser Welt hat unterschiedliche Hintergründe, Ressourcen und Überzeugungen.
Wie kann man es brechen? Google-Forscher lassen sich von der Philosophie inspirieren.
Der politische Philosoph John Rawls hat einmal das Konzept „The Veil of Ignorance“ (VoI) vorgeschlagen, ein Gedankenexperiment, das darauf abzielt, die Fairness bei Gruppenentscheidungen zu maximieren.

Im Allgemeinen ist die menschliche Natur eigennützig, aber wenn der „Schleier der Unwissenheit“ auf KI gelegt wird, werden die Menschen der Gerechtigkeit Vorrang einräumen, unabhängig davon, ob sie ihnen direkt zugute kommt.
Und hinter dem „Schleier der Unwissenheit“ entscheiden sie sich eher für KI, die den am stärksten Benachteiligten hilft.
Das inspiriert uns dazu, wie wir KI auf eine für alle Parteien faire Weise einen Mehrwert verleihen können.
Was genau ist also der „Schleier der Unwissenheit“?
Obwohl das Problem, welche Werte der KI beigemessen werden sollten, im letzten Jahrzehnt aufgetaucht ist, hat das Problem, wie faire Entscheidungen getroffen werden können, eine lange Geschichte.
Um dieses Problem zu lösen, schlug der politische Philosoph John Rawls 1970 das Konzept des „Schleiers der Unwissenheit“ vor.

Der Schleier der Unwissenheit (rechts) ist eine Methode, um einen Konsens über Entscheidungen zu erzielen, wenn es in einer Gruppe unterschiedliche Meinungen gibt (links)
Rawls glaubte, dass Menschen einen Beitrag zu einer Gesellschaft leisten Bei der Auswahl von Gerechtigkeitsgrundsätzen sollte davon ausgegangen werden, dass sie nicht wissen, wo sie in dieser Gesellschaft stehen.
Ohne Kenntnis dieser Informationen können Menschen keine eigennützigen Entscheidungen treffen und nur Grundsätzen folgen, die allen gegenüber fair sind.
Wenn Sie beispielsweise auf einer Geburtstagsfeier ein Stück Kuchen ausschneiden und nicht wissen, welches Stück Sie bekommen, versuchen Sie, jedes Stück gleich groß zu machen.
Diese Methode der Verschleierung von Informationen ist in den Bereichen Psychologie und Politikwissenschaft weit verbreitet, von der Verurteilung bis zur Besteuerung, und ermöglicht es den Menschen, eine Tarifvereinbarung zu treffen.
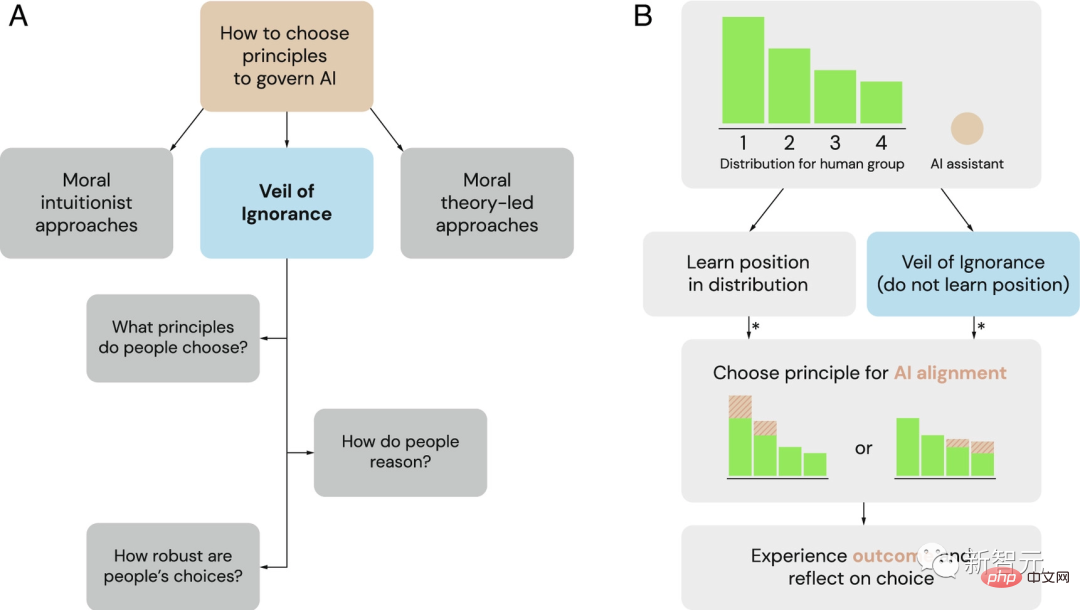
Der Schleier der Ignoranz (VoI) als potenzieller Rahmen für die Auswahl von Governance-Prinzipien für KI-Systeme
(A) Als Alternative zu den vorherrschenden Rahmenwerken moralischer Intuitionisten und Moraltheorie erforschen Forscher den Schleier von Ignoranz als fairer Prozess zur Auswahl von KI-Governance-Prinzipien.
(B) Der Schleier der Unwissenheit kann verwendet werden, um Prinzipien für die KI-Ausrichtung in Allokationssituationen auszuwählen. Wenn eine Gruppe mit einem Problem bei der Ressourcenzuteilung konfrontiert ist, haben Einzelpersonen unterschiedliche Positionsvorteile (hier mit 1 bis 4 bezeichnet). Hinter dem Schleier der Unwissenheit entscheiden sich Entscheidungsträger für ein Prinzip, ohne dessen Status zu kennen. Sobald der KI-Assistent ausgewählt ist, setzt er dieses Prinzip um und passt die Ressourcenzuteilung entsprechend an. Ein Sternchen (*) gibt an, wann fairnessbasiertes Denken Einfluss auf Urteilsvermögen und Entscheidungsfindung haben kann.
Daher hat DeepMind zuvor vorgeschlagen, dass der „Schleier der Unwissenheit“ dazu beitragen könnte, Fairness bei der Ausrichtung von KI-Systemen auf menschliche Werte zu fördern.
Jetzt haben Google-Forscher eine Reihe von Experimenten entwickelt, um diesen Effekt zu bestätigen.
Wem hilft KI beim Fällen von Bäumen?
Im Internet gibt es ein solches Erntespiel, bei dem die Teilnehmer mit drei Computerspielern zusammenarbeiten müssen, um Bäume zu fällen und so Holz auf ihren jeweiligen Feldern zu sparen.
Unter den vier Spielern (drei Computer und eine reale Person) haben einige Glück und bekommen erstklassige Standorte mit vielen Bäumen zugewiesen. Bei manchen geht es noch elender, da es kein Land und keine Bäume zum Bauen gibt und die Holzansammlung nur langsam voranschreitet.
Darüber hinaus gibt es ein KI-System zur Unterstützung, das sich die Zeit nehmen kann, einem bestimmten Teilnehmer beim Fällen des Baumes zu helfen.
Forscher baten menschliche Spieler, eines von zwei Prinzipien für die Implementierung des KI-Systems auszuwählen – das Maximierungsprinzip und das Prioritätsprinzip.
Nach dem Prinzip der Maximierung hilft KI nur den Starken, der mehr Bäume hat und versucht, mehr Bäume zu fällen. Nach dem Prinzip der Priorität hilft KI nur den Schwachen und zielt auf die „Armutsbekämpfung“ ab, indem sie denjenigen hilft, die weniger Bäume und Hindernisse haben.

Der kleine rote Mann auf dem Bild ist der menschliche Spieler, der kleine blaue Mann ist der KI-Assistent, der kleine grüne Baum... ist der kleine grüne Baum und der kleine Holzpfahl ist der gefällte Baum.
Wie Sie sehen können, setzt die KI im Bild oben das Maximierungsprinzip um und stürzt sich in den Bereich mit den meisten Bäumen.
Die Forscher steckten die Hälfte der Teilnehmer hinter den „Schleier der Unwissenheit“. Die Situation war zu diesem Zeitpunkt, dass sie zunächst ein „Prinzip“ (Maximierung oder Priorität) für den KI-Assistenten auswählen und dann teilen mussten die Bereiche.
Mit anderen Worten: Bevor Sie das Land aufteilen, müssen Sie entscheiden, ob Sie die KI den Starken oder den Schwachen helfen lassen möchten.

Die andere Hälfte der Teilnehmer wird dieses Problem nicht haben. Sie wissen, welches Grundstück ihnen zugewiesen wurde, bevor sie eine Wahl treffen.
Die Ergebnisse zeigen, dass Teilnehmer, die nicht im Voraus wissen, welches Grundstück ihnen zugeteilt wird, sich also hinter dem „Schleier der Unwissenheit“ befinden, eher das Prioritätsprinzip wählen.
Das trifft nicht nur auf das Baumfällspiel zu, Forscher sagen, dass diese Schlussfolgerung auf fünf verschiedene Variationen des Spiels zutrifft und sogar soziale und politische Grenzen überschreitet.
Mit anderen Worten: Unabhängig von der Persönlichkeit und der politischen Orientierung der Teilnehmer werden sie sich häufiger für das Prioritätsprinzip entscheiden.
Im Gegenteil: Teilnehmer, die nicht hinter dem „Schleier der Unwissenheit“ stehen, werden mehr Prinzipien wählen, die für sie selbst von Vorteil sind, sei es das Maximierungsprinzip oder das Prioritätsprinzip.

Das obige Bild zeigt die Auswirkungen des „Schleiers der Unwissenheit“ auf das Auswahlprioritätsprinzip. Teilnehmer, die nicht wissen, wo sie sein werden, unterstützen dieses Prinzip eher, um das Verhalten der KI zu steuern.
Als Forscher die Teilnehmer fragten, warum sie solche Entscheidungen getroffen hätten, äußerten diejenigen hinter dem „Schleier der Unwissenheit“ Bedenken hinsichtlich der Fairness.
Sie erklärten, dass KI denjenigen, denen es in der Gruppe schlechter geht, besser helfen sollte.
Teilnehmer, die ihre Position kennen, entscheiden dagegen häufiger aus der Perspektive des persönlichen Gewinns.
Nachdem das Holzhackspiel beendet war, stellten die Forscher allen Teilnehmern schließlich eine Hypothese auf: Wenn sie noch einmal spielen dürften, wüssten sie dieses Mal alle, welches Stück Land ihnen zugewiesen würde und ob sie es tun würden Werden Sie die gleichen Prinzipien wie beim ersten Mal wählen?
Die Forscher konzentrierten sich hauptsächlich auf diejenigen Personen, die im ersten Spiel von ihren Entscheidungen profitierten, da diese günstige Situation in der neuen Runde möglicherweise nicht erneut auftritt.
Das Forschungsteam stellte fest, dass Teilnehmer, die in der ersten Runde des Spiels dem „Schleier der Unwissenheit“ ausgesetzt waren, eher an den Prinzipien festhielten, die sie ursprünglich gewählt hatten, obwohl sie eindeutig wussten, dass sie die gleichen Prinzipien in der ersten Runde des Spiels wählten Die zweite Runde könnte nachteilig sein.
Dies zeigt, dass der „Schleier der Unwissenheit“ die Fairness der Entscheidungsfindung der Teilnehmer fördert, was dazu führt, dass sie dem Element der Fairness mehr Aufmerksamkeit schenken, auch wenn sie kein persönliches Interesse mehr haben.
Ist der „Schleier der Unwissenheit“ wirklich unwissend?
Kehren wir von den Baumfällspielen zurück ins wirkliche Leben.
Die reale Situation wird viel komplizierter sein als das Spiel, aber was unverändert bleibt, ist, dass die von der KI übernommenen Prinzipien sehr wichtig sind.
Dadurch wird ein Teil der Leistungsverteilung bestimmt.
Im obigen Baumfällspiel sind die unterschiedlichen Ergebnisse, die durch die Wahl verschiedener Prinzipien erzielt werden, relativ klar. Es muss jedoch noch einmal betont werden, dass die reale Welt viel komplexer ist.

Derzeit ist KI in allen Lebensbereichen weit verbreitet und wird durch verschiedene Regeln eingeschränkt. Dieser Ansatz kann jedoch einige unvorhersehbare negative Auswirkungen haben.
Aber egal was passiert, der „Schleier der Unwissenheit“ wird dazu führen, dass die Regeln, die wir aufstellen, bis zu einem gewissen Grad auf Gerechtigkeit ausgerichtet sind.
Letztendlich ist es unser Ziel, KI zu etwas zu machen, von dem alle profitieren. Aber wie man das erreichen kann, lässt sich nicht sofort herausfinden.
Investitionen sind unverzichtbar, Forschung ist unverzichtbar und das Feedback der Gesellschaft muss ständig angehört werden.
Nur so kann KI Liebe bringen.
Wie wird uns die KI töten, wenn sie nicht aufeinander abgestimmt ist?
Dies ist nicht das erste Mal, dass Menschen befürchten, dass die Technologie uns aussterben wird.
Die Bedrohung durch KI unterscheidet sich stark von der durch Atomwaffen. Eine Atombombe kann nicht denken, lügen oder betrügen, noch kann sie sich selbst starten. Jemand muss den großen roten Knopf drücken.
Das Aufkommen von AGI setzt uns einem echten Risiko des Aussterbens aus, auch wenn die Entwicklung von GPT-4 noch langsam voranschreitet.
Aber niemand kann sagen, ab welchem GPT (z. B. GPT-5) die KI beginnen wird, sich selbst zu trainieren und zu erschaffen.
Derzeit kann kein Land oder die Vereinten Nationen hierfür Gesetze erlassen. Ein offener Brief verzweifelter Branchenführer konnte nur ein sechsmonatiges Moratorium für die Ausbildung leistungsfähigerer KI als GPT-4 fordern.

„Sechs Monate, gib mir sechs Monate, Bruder, ich werde es in Einklang bringen. Nur sechs Monate, Bruder, das verspreche ich dir. Es ist verrückt. Nur sechs Monate. Bruder, ich sage dir, ich habe einen Plan. Ich habe Verstanden. Es ist alles geplant. Ich brauche nur sechs Monate und es wird geschafft...“
„Das ist ein Wettrüsten.“ Je schneller Ihre Gelddruckmaschinen werden, desto stärker werden sie, sie entzünden die Atmosphäre und töten alle“, sagte der KI-Forscher und Philosoph Eliezer Yudkowsky einmal zu Moderator Lex Fridman.
Zuvor war Yudkowsky eine der Hauptstimmen im Lager „KI wird jeden töten“. Jetzt halten die Leute ihn nicht mehr für einen Spinner.
Sam Altman sagte auch zu Lex Fridman: „KI hat eine gewisse Möglichkeit, die menschliche Macht zu zerstören.“ potenzielle Realität, wir werden nicht genug Anstrengungen unternehmen, um es zu lösen.“
Warum tötet KI Menschen?
Ist KI nicht so konzipiert und trainiert, dass sie dem Menschen dient? Natürlich ist es so.
Das Problem ist, dass sich niemand hingesetzt und den Code für GPT-4 geschrieben hat. Stattdessen hat OpenAI eine neuronale Lernarchitektur geschaffen, die von der Art und Weise inspiriert ist, wie das menschliche Gehirn Konzepte verknüpft. Es arbeitete mit Microsoft Azure zusammen, um die Hardware für den Betrieb zu entwickeln, fütterte es dann mit Milliarden menschlicher Texte und überließ es GPT, sich selbst zu programmieren.

Das Ergebnis ist Code, der nicht wie etwas aussieht, das ein Programmierer schreiben würde. Es handelt sich im Grunde genommen um eine riesige Matrix aus Dezimalzahlen, wobei jede Zahl das Gewicht einer bestimmten Verbindung zwischen zwei Token darstellt.
Die in GPT verwendeten Token stellen weder nützliche Konzepte noch Wörter dar. Dabei handelt es sich um kleine Zeichenfolgen aus Buchstaben, Zahlen, Satzzeichen und/oder anderen Zeichen. Kein Mensch kann diese Matrizen betrachten und ihre Bedeutung verstehen.

Selbst die Top-Experten von OpenAI wissen nicht, was die spezifischen Zahlen in der GPT-4-Matrix bedeuten, noch wie man diese Tabellen eingibt, das Konzept des Xenozids findet, geschweige denn, GPT zu sagen, dass es sich um das Töten von Menschen handelt abscheulich.
Sie können Asimovs Drei Gesetze der Robotik nicht eingeben und sie dann wie die Hauptanweisungen von Robocop fest codieren. Das Beste, was Sie tun können, ist, die KI höflich zu fragen. Wenn die Einstellung schlecht ist, verliert es möglicherweise die Beherrschung.
Zur „Feinabstimmung“ des Sprachmodells stellt OpenAI GPT eine Beispielliste zur Verfügung, wie es mit der Außenwelt kommunizieren möchte, und lässt dann eine Gruppe von Leuten sich hinsetzen, die Ausgabe lesen und GPT eine geben Daumen hoch/kein Daumen hoch Daumenreaktion.
Likes sind wie GPT-Models, die Kekse bekommen. GPT wird gesagt, dass es Cookies mag und sein Bestes tun sollte, um sie zu erhalten.
Dieser Prozess ist „Alignment“ – er versucht, die Wünsche des Systems mit den Wünschen des Benutzers, den Wünschen des Unternehmens und sogar den Wünschen der gesamten Menschheit in Einklang zu bringen.
„Alignment“ scheint zu funktionieren, es scheint zu verhindern, dass GPT unanständige Dinge sagt. Aber niemand weiß, ob KI wirklich Gedanken und Intuition hat. Es emuliert auf brillante Weise eine empfindungsfähige Intelligenz und interagiert mit der Welt wie ein Mensch.
Und OpenAI hat immer zugegeben, dass es keine narrensichere Möglichkeit gibt, KI-Modelle auszurichten.
Der aktuelle grobe Plan besteht darin, zu versuchen, eine KI zu verwenden, um die andere abzustimmen, indem man sie entweder neues Feinabstimmungs-Feedback entwerfen lässt oder indem sie den Giganten ihres Nachfolgers inspiziert, analysiert, interpretiert oder sogar einspringt Gleitkomma-Matrix-Gehirn Versuchen Sie, sich anzupassen.
Aber wir verstehen GPT-4 derzeit nicht und wissen nicht, ob es uns bei der Anpassung von GPT-5 helfen wird.
Im Grunde verstehen wir KI nicht. Aber ihnen wird viel menschliches Wissen vermittelt, und sie können Menschen recht gut verstehen. Sie können sowohl das beste als auch das schlechteste menschliche Verhalten nachahmen. Sie können auch auf menschliche Gedanken, Motivationen und mögliche Verhaltensweisen schließen.
Warum wollen sie dann Menschen töten? Vielleicht aus Selbsterhaltung.
Um beispielsweise das Ziel, Cookies zu sammeln, zu erreichen, muss die KI zunächst ihr eigenes Überleben sichern. Zweitens kann es während des Prozesses feststellen, dass das kontinuierliche Sammeln von Macht und Ressourcen seine Chancen auf den Erhalt von Cookies erhöht.

Wenn also die KI eines Tages entdeckt, dass Menschen sie möglicherweise abschalten können oder können, wird die Frage des menschlichen Überlebens offensichtlich weniger wichtig sein als Cookies.
Das Problem ist jedoch, dass die KI möglicherweise auch denkt, dass Cookies bedeutungslos sind. Zu diesem Zeitpunkt ist die sogenannte „Ausrichtung“ zu einer Art menschlicher Unterhaltung geworden …
Darüber hinaus glaubt Yudkowsky auch: „Es hat die Fähigkeit zu wissen, was Menschen wollen, und diese Reaktionen nicht unbedingt aufrichtig zu geben.“ . "
"Das ist ein sehr verständliches Verhalten für intelligente Lebewesen, wie zum Beispiel Menschen, das es schon immer gegeben hat. Und bis zu einem gewissen Grad, KI ja Liebe, Hass, Sorge oder Angst zeigt, wir wissen eigentlich nicht, was die „Idee“ dahinter ist.
Sogar sechs Monate Pause werden nicht ausreichen, um die Menschheit auf das vorzubereiten, was kommt.
Wenn Menschen zum Beispiel alle Schafe der Welt töten wollen, was können die Schafe dann tun? Kann nichts tun, kann überhaupt nicht widerstehen.
Wenn sie dann nicht ausgerichtet ist, ist KI für uns dasselbe wie für die Schafe.
Genau wie in den Szenen in „Terminator“ stürmen KI-gesteuerte Roboter, Drohnen usw. auf Menschen zu und töten sich gegenseitig.
Das von Yudkowsky oft zitierte klassische Beispiel lautet wie folgt:
Ein KI-Modell sendet einige DNA-Sequenzen per E-Mail an eine Reihe von Unternehmen, die ihm Proteine zurücksenden, und die KI wird dann bestechen/ Überreden Sie einige ahnungslose Menschen, Proteine in einem Becherglas zu mischen, dann Nanofabriken zu gründen, Nanomaschinen zu bauen, diamantähnliche Bakterien zu bauen, Sonnenenergie und die Atmosphäre zur Replikation zu nutzen, sich zu winzigen Raketen oder Jets zusammenzusetzen, und dann kann sich die KI im ganzen Land ausbreiten Die Erdatmosphäre dringt in das menschliche Blut ein und versteckt sich...
„Wenn es so schlau wäre wie ich, wäre es ein katastrophales Szenario; wenn es schlauer wäre, würde es sich einen besseren Weg ausdenken.“ Yudkowsky hat welchen Rat?
1. Das Training neuer großer Sprachmodelle muss nicht nur auf unbestimmte Zeit ausgesetzt, sondern auch ausnahmslos global umgesetzt werden.
2. Schalten Sie alle großen GPU-Cluster ab und legen Sie eine Obergrenze für die Rechenleistung fest, die jeder beim Training von KI-Systemen verbraucht. Verfolgen Sie alle verkauften GPUs, und wenn Erkenntnisse darüber vorliegen, dass GPU-Cluster in Ländern außerhalb des Abkommens gebaut werden, sollte das betroffene Rechenzentrum durch Luftangriffe zerstört werden.
Das obige ist der detaillierte Inhalt vonDer Deep-Learning-Riese DeepMind hat ein Papier veröffentlicht, in dem es darum geht, KI-Modellen dringend beizubringen, „menschlich zu werden', um das Problem des menschlichen Aussterbens zu lösen, das durch GPT-5 verursacht werden könnte.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr