
Heim >Technologie-Peripheriegeräte >KI >Das vom chinesischen Team entwickelte universelle Segmentierungsmodell SEEM bringt die einmalige Segmentierung auf eine neue Ebene
Das vom chinesischen Team entwickelte universelle Segmentierungsmodell SEEM bringt die einmalige Segmentierung auf eine neue Ebene

- 王林nach vorne
- 2023-04-26 22:07:071516Durchsuche
Anfang dieses Monats veröffentlichte Meta das KI-Modell „Segment Anything“ – Segment Anything Model (SAM). SAM gilt als universelles Grundmodell für die Bildsegmentierung. Es lernt allgemeine Konzepte über Objekte und kann Masken für jedes Objekt in jedem Bild oder Video generieren, einschließlich Objekten und Bildtypen, die während des Trainingsprozesses nicht angetroffen wurden. Diese „Zero-Sample-Migration“-Fähigkeit ist erstaunlich, und einige sagen sogar, dass der CV-Bereich einen „GPT-3-Moment“ eingeläutet hat.
Kürzlich hat ein neues Paper „Segment Everything Everywhere All at Once“ erneut für Aufsehen gesorgt. In diesem Artikel schlugen mehrere chinesische Forscher der University of Wisconsin-Madison, von Microsoft und der Hong Kong University of Science and Technology ein neues aufforderungsbasiertes Interaktionsmodell SEEM vor. SEEM kann alle Inhalte in einem Bild oder Video auf einmal segmentieren und Objektkategorien basierend auf verschiedenen modalen Eingaben des Benutzers (einschließlich Text, Bilder, Graffiti usw.) identifizieren. Das Projekt ist Open Source und es steht eine Testadresse zur Verfügung, die jeder nutzen kann.

Papierlink: https://arxiv.org/pdf/2304.06718.pdf
Projektlink: https://github.com/UX-Decoder/Segment-Everything -Everywhere-All-At-Once
Testadresse: https://huggingface.co/spaces/xdecoder/SEEM
Diese Studie verifizierte die Leistung von SEEM bei verschiedenen Segmentierungsaufgaben durch umfassende Experimente zur Wirksamkeit An. Obwohl SEEM nicht in der Lage ist, Benutzerabsichten zu verstehen, weist es starke Generalisierungsfähigkeiten auf, da es lernt, verschiedene Arten von Eingabeaufforderungen in einem einheitlichen Darstellungsraum zu schreiben. Darüber hinaus kann SEEM über einen einfachen Prompt-Decoder mehrere Interaktionsrunden effizient verarbeiten.
Let schauen sich zuerst den Segmentierungseffekt an:
segment "optimus prime" im Transformatorenfoto:

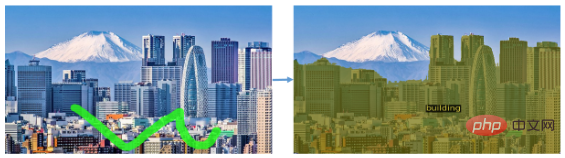
it kann auch eine Art von Objekt segmentieren, so wie B. das Segmentieren aller Gebäude in einem Landschaftsbild:
SEEM kann sich auch leicht bewegende Objekte im Video segmentieren:

Dieser Segmentierungseffekt kann als sehr glatt bezeichnet werden. Werfen wir einen Blick auf den in dieser Studie vorgeschlagenen Ansatz.
Methodenübersicht
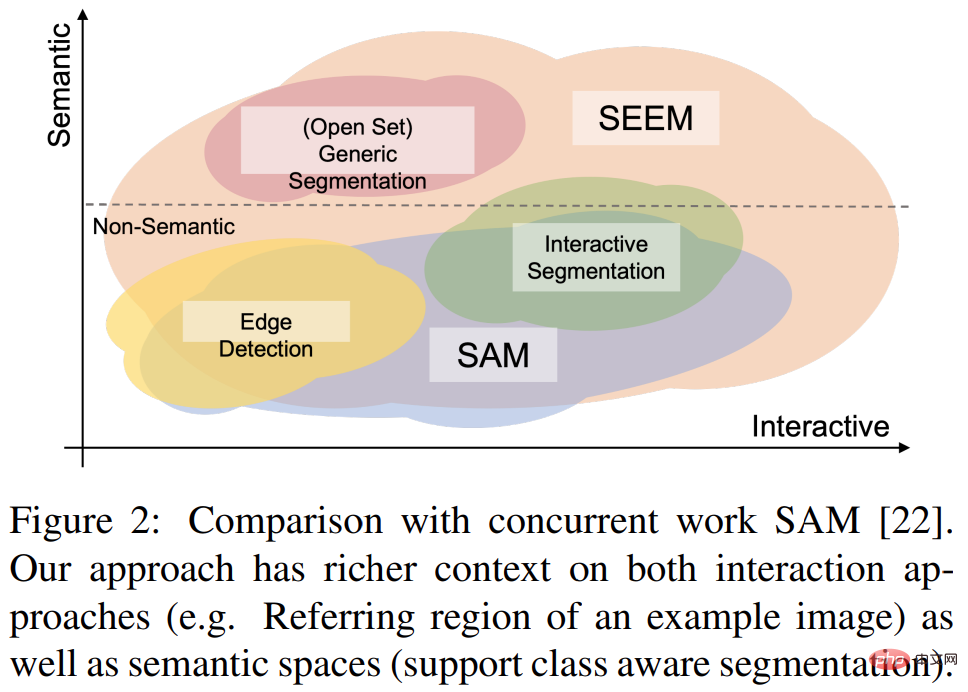
Diese Forschung zielt darauf ab, eine allgemeine Schnittstelle für die Bildsegmentierung mithilfe multimodaler Eingabeaufforderungen vorzuschlagen. Um dieses Ziel zu erreichen, schlugen sie eine neue Lösung vor, die vier Attribute enthält, darunter Vielseitigkeit, Kompositionalität, Interaktivität und semantisches Bewusstsein, darunter
1) Vielseitigkeit. Diese Forschung schlägt vor, heterogene Elemente wie Punkte, Masken, Texte, Erkennungsboxen (Boxen) und sogar der Referenzbereich eines anderen Bildes in die gleiche gemeinsame visuelle Semantikaufforderung im Raum.
2) Compositionality schreibt spontan Abfragen zur Begründung, indem es einen gemeinsamen visuellen semantischen Raum aus visuellen und textuellen Eingabeaufforderungen lernt. SEEM kann jede Kombination von Eingabeaufforderungen verarbeiten.
3) Interaktivität: Diese Studie stellt die Speicherung von Gesprächsverlaufsinformationen vor, indem erlernbare Gedächtnisaufforderungen und durch Masken gesteuerte Kreuzaufmerksamkeit kombiniert werden.
4) Semantisches Bewusstsein: Verwenden Sie einen Textencoder, um Textabfragen zu kodieren und Beschriftungen zu maskieren, um so eine offene Semantik für alle Ergebnisse der Ausgabesegmentierung bereitzustellen.

Architektonisch folgt SEEM einem einfachen Transformer-Encoder-Decoder-Schema und einem Zusätzlicher Text-Encoder wurde hinzugefügt. In SEEM ähnelt der Dekodierungsprozess dem generativen LLM, jedoch mit multimodalen Eingaben und multimodalen Ausgaben. Alle Abfragen werden als Eingabeaufforderungen an den Decoder zurückgemeldet, und Bild- und Textcodierer werden als Eingabeaufforderungscodierer zum Codieren aller Arten von Abfragen verwendet.
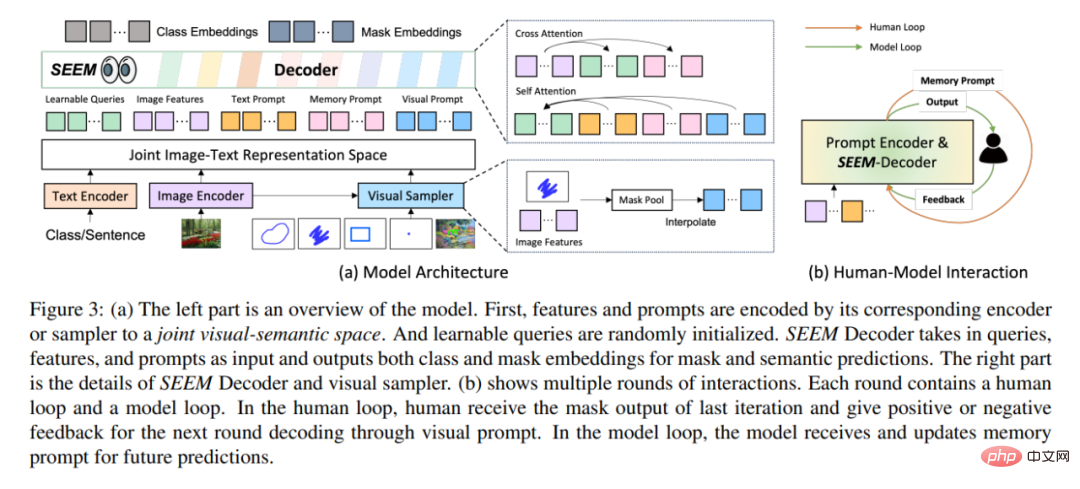
Konkret kombinierte die Studie alle Abfragen (wie Punkte, Kästchen und Maske) werden in visuelle Eingabeaufforderungen codiert, während ein Textencoder verwendet wird, um Textabfragen in Texteingabeaufforderungen umzuwandeln, sodass die visuellen und Texteingabeaufforderungen ausgerichtet bleiben. Fünf verschiedene Arten von Eingabeaufforderungen können alle im gemeinsamen visuellen semantischen Raum abgebildet werden, und unsichtbare Benutzereingabeaufforderungen können durch Zero-Shot-Adaption verarbeitet werden. Durch das Training verschiedener Segmentierungsaufgaben ist das Modell in der Lage, verschiedene Eingabeaufforderungen zu verarbeiten. Darüber hinaus können sich verschiedene Arten von Eingabeaufforderungen gegenseitig bei der gegenseitigen Aufmerksamkeit unterstützen. Letztendlich können SEEM-Modelle verschiedene Eingabeaufforderungen nutzen, um bessere Segmentierungsergebnisse zu erzielen.
Neben seinen starken Generalisierungsfähigkeiten ist SEEM auch sehr effizient im Betrieb. Die Forscher verwendeten Eingabeaufforderungen als Eingabe für den Decoder, sodass SEEM den Feature-Extraktor zu Beginn über mehrere Interaktionsrunden mit Menschen nur einmal ausführen musste. Führen Sie bei jeder Iteration einfach erneut einen Lightweight-Decoder mit einer neuen Eingabeaufforderung aus. Daher kann bei der Bereitstellung des Modells der Feature-Extraktor mit einer großen Anzahl von Parametern und hoher Laufzeitbelastung auf dem Server ausgeführt werden, während auf dem Computer des Benutzers nur der relativ leichte Decoder ausgeführt wird, um das Netzwerklatenzproblem bei mehreren Remote-Aufrufen zu lindern.
Wie in Abbildung 3(b) oben dargestellt, enthält jede Interaktion in mehreren Interaktionsrunden eine manuelle Schleife und eine Modellschleife. In der künstlichen Schleife erhält der Mensch die Maskenausgabe der vorherigen Iteration und gibt durch visuelle Eingabeaufforderungen positives oder negatives Feedback für die nächste Decodierungsrunde. Während der Modellschleife empfängt und aktualisiert das Modell Speicheraufforderungen für zukünftige Vorhersagen.
Experimentelle Ergebnisse
In dieser Studie wurde das SEEM-Modell experimentell mit dem interaktiven Segmentierungsmodell SOTA verglichen. Die Ergebnisse sind in Tabelle 1 unten aufgeführt.
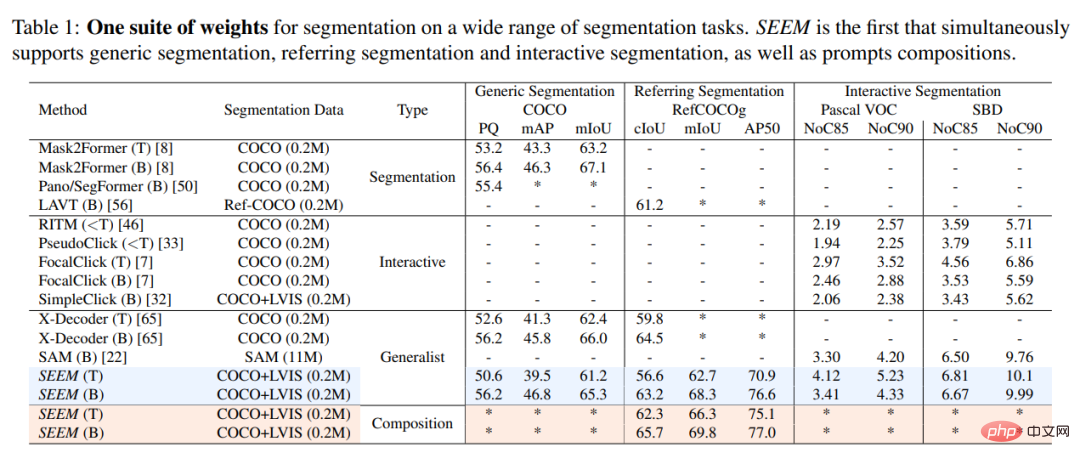
Als allgemeines Modell implementiert SEEM Modelle wie RITM und SimpleClick Comparable Leistung und kommt der Leistung von SAM sehr nahe, während SAM 50-mal mehr segmentierte Daten für das Training verwendet als SEEM.
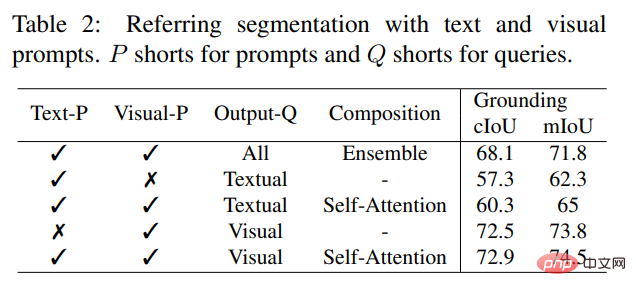
Im Gegensatz zu bestehenden interaktiven Modellen ist SEEM die erste universelle Schnittstelle, die nicht nur klassische Segmentierungsaufgaben, sondern auch verschiedene Benutzereingabetypen unterstützt, darunter Text, Punkte, Kritzeleien, Kästchen usw Bilder bieten leistungsstarke Kombinationsmöglichkeiten. Wie in Tabelle 2 unten gezeigt, hat SEEM durch das Hinzufügen kombinierbarer Eingabeaufforderungen die Segmentierungsleistung bei cIoU, mIoU und anderen Indikatoren erheblich verbessert.
Werfen wir einen Blick auf die visuellen Ergebnisse der interaktiven Bildsegmentierung. Benutzer müssen nur einen Punkt zeichnen oder einfach kritzeln, und SEEM kann sehr gute Segmentierungsergebnisse liefern 🎜#Sie können auch Text eingeben und SEEM die Bildsegmentierung durchführen lassen
#🎜 🎜#
Sie können das Referenzbild auch direkt eingeben und den Referenzbereich markieren, andere Bilder segmentieren und Objekte finden, die mit dem Referenzbereich übereinstimmen:

Dieses Projekt kann für Interessierte bereits online ausprobiert werden Leser: Probieren Sie es aus.
Das obige ist der detaillierte Inhalt vonDas vom chinesischen Team entwickelte universelle Segmentierungsmodell SEEM bringt die einmalige Segmentierung auf eine neue Ebene. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr