
Heim >Technologie-Peripheriegeräte >KI >Untersuchungen zeigen, dass ähnlichkeitsbasiertes, verschachteltes Lernen das Problem der „Amnesie' beim Deep Learning wirksam lösen kann
Untersuchungen zeigen, dass ähnlichkeitsbasiertes, verschachteltes Lernen das Problem der „Amnesie' beim Deep Learning wirksam lösen kann

- 王林nach vorne
- 2023-04-26 21:40:07929Durchsuche
Im Gegensatz zu Menschen vergessen künstliche neuronale Netze schnell zuvor gelernte Informationen, wenn sie neue Dinge lernen, und müssen durch die Verschachtelung alter und neuer Informationen neu trainiert werden. Die Verschachtelung aller alten Informationen ist jedoch sehr zeitaufwändig und möglicherweise nicht notwendig. Es kann ausreichend sein, nur alte Informationen zu verschachteln, die im Wesentlichen den neuen Informationen ähneln.
Kürzlich veröffentlichte die Proceedings of the National Academy of Sciences (PNAS) einen gesponserten Artikel mit dem Titel „Learning in Deep Neural Networks and Brains with Similarity-Weighted Interleaved Learning“. von der Royal Canadian Academy of Sciences. Herausgegeben vom Team von Bruce McNaughton, einem Mitglied der Gesellschaft und einem bekannten Neurowissenschaftler. Ihre Arbeit ergab, dass tiefe Netzwerke durch die Durchführung eines ähnlichkeitsgewichteten Interleaving-Trainings alter Informationen mit neuen Informationen schnell neue Dinge lernen können, was nicht nur die Vergessensrate reduziert, sondern auch deutlich weniger Daten verbraucht.
Die Autoren stellten außerdem die Hypothese auf, dass es durch die Verfolgung der laufenden Erregbarkeitsverläufe kürzlich aktiver Neuronen und neurodynamischer Attraktoren (Attraktordynamik) möglich ist, eine ähnlichkeitsgewichtete Verschachtelung zu implementieren. Diese Erkenntnisse könnten zu weiteren Fortschritten in den Neurowissenschaften und im maschinellen Lernen führen. Zu verstehen, wie das Gehirn im Laufe des Lebens lernt, bleibt eine langfristige Herausforderung.
In künstlichen neuronalen Netzen (KNN) kann die zu schnelle Integration neuer Informationen zu katastrophalen Störungen führen, bei denen zuvor erworbenes Wissen plötzlich verloren geht. Die Complementary Learning Systems Theory (CLST) legt nahe, dass neue Erinnerungen schrittweise in den Neocortex integriert werden können, indem sie mit vorhandenem Wissen verschachtelt werden.
CLST weist darauf hin, dass das Gehirn auf komplementäre Lernsysteme angewiesen ist: den Hippocampus (HC) für den schnellen Erwerb neuer Erinnerungen und den Neocortex (NC) für die schrittweise Umwandlung neuer Daten Integriert in kontextfrei strukturiertes Wissen. Während „Offline-Perioden“, wie zum Beispiel während des Schlafens und der ruhigen Wachruhe, löst der HC eine Wiederholung aktueller Erfahrungen im NC aus, während der NC spontan Darstellungen bestehender Kategorien abruft und verschachtelt. Die verschachtelte Wiedergabe ermöglicht eine schrittweise Anpassung der synaptischen NC-Gewichte im Gradientenabstiegsverfahren, um kontextunabhängige Kategoriedarstellungen zu erstellen, die neue Erinnerungen elegant integrieren und katastrophale Interferenzen überwinden. In vielen Studien wurde Interleaved Replay erfolgreich eingesetzt, um lebenslanges Lernen neuronaler Netze zu erreichen.
Bei der praktischen Anwendung von CLST müssen jedoch zwei wichtige Probleme gelöst werden. Erstens: Wie kann eine umfassende Informationsverschachtelung erfolgen, wenn das Gehirn nicht auf alle alten Daten zugreifen kann? Eine mögliche Lösung ist die „Pseudoprobe“, bei der zufällige Eingaben eine generative Wiedergabe interner Darstellungen auslösen können, ohne expliziten Zugriff auf zuvor erlernte Beispiele. Attraktorähnliche Dynamiken können es dem Gehirn ermöglichen, eine „Pseudoprobe“ durchzuführen, der Inhalt der „Pseudoprobe“ ist jedoch noch nicht geklärt. Die zweite Frage ist daher, ob das Gehirn nach jeder neuen Lernaktivität genügend Zeit hat, alle zuvor gelernten Informationen zu verknüpfen.
Der Algorithmus Similarity-Weighted Interleaved Learning (SWIL) gilt als Lösung für das zweite Problem, das zeigt, dass nur die Verschachtelung mit neuen Informationen alte Informationen enthält, die die Ähnlichkeit wesentlich charakterisieren kann ausreichend sein. Empirische Verhaltensstudien zeigen, dass hochkonsistente neue Informationen schnell und störungsarm in NC-strukturiertes Wissen integriert werden können. Dies deutet darauf hin, dass die Geschwindigkeit, mit der neue Informationen integriert werden, von ihrer Konsistenz mit dem Vorwissen abhängt. Inspiriert durch dieses Verhaltensergebnis und durch die erneute Untersuchung zuvor ermittelter Verteilungen katastrophaler Interferenzen zwischen Kategorien zeigten McClelland et al., dass SWIL in Kontexten mit zwei Hypernym-Kategorien verwendet werden kann (z. B. „Frucht“ ist „Apfel“ und „Banane“). „“), jede Epoche verbraucht weniger als das 2,5-fache der Datenmenge, um neue Informationen zu lernen, wodurch die gleiche Leistung erzielt wird, als würde das Netzwerk auf allen Daten trainiert. Bei der Verwendung komplexerer Datensätze konnten die Forscher jedoch keine ähnlichen Effekte feststellen, was Bedenken hinsichtlich der Skalierbarkeit des Algorithmus aufkommen lässt.
Experimente zeigen, dass tiefe nichtlineare künstliche neuronale Netze neue Informationen lernen können, indem sie nur Teilmengen alter Informationen verschachteln, die ein großes Maß an repräsentativer Ähnlichkeit mit den neuen Informationen aufweisen. Durch die Verwendung des SWIL-Algorithmus ist das ANN in der Lage, schnell neue Informationen mit ähnlicher Genauigkeit und minimaler Interferenz zu lernen und dabei nur eine sehr kleine Menge alter Informationen zu verwenden, die in jeder Epoche präsentiert werden, was eine hohe Datenauslastung und schnelles Lernen bedeutet.
Gleichzeitig kann SWIL auch auf das Sequenz-Lern-Framework angewendet werden. Darüber hinaus kann das Erlernen einer neuen Kategorie die Datennutzung erheblich verbessern. Wenn die alten Informationen nur sehr wenig Ähnlichkeit mit zuvor erlernten Kategorien aufweisen, ist die Menge der präsentierten alten Informationen viel geringer, was wahrscheinlich beim menschlichen Lernen der Fall ist.
Schließlich schlagen die Autoren ein theoretisches Modell vor, wie SWIL im Gehirn implementiert wird, mit einer Erregbarkeitsverzerrung proportional zur Überlappung neuer Informationen.
DNN-Dynamikmodell angewendet auf Bildklassifizierungsdatensatz
Die Experimente von McClelland et al. zeigten, dass In einem tiefen linearen Netzwerk mit einer verborgenen Schicht kann SWIL eine neue Kategorie lernen, ähnlich dem Fully Interleaved Learning (FIL), das die gesamte alte Kategorie mit der neuen Kategorie verschachtelt, aber 40 % weniger Daten verbraucht.
Allerdings wurde das Netzwerk auf einem sehr einfachen Datensatz mit nur zwei Hypernym-Kategorien trainiert, was Fragen zur Skalierbarkeit des Algorithmus aufwirft.
Erkunden Sie zunächst, wie sich verschiedene Lernkategorien in einem tiefen linearen neuronalen Netzwerk mit einer verborgenen Schicht für einen komplexeren Datensatz (wie Fashion-MNIST) entwickeln. Nach dem Entfernen der Kategorien „Stiefel“ und „Tasche“ erreichte das Modell in den verbleibenden acht Kategorien eine Testgenauigkeit von 87 %. Anschließend trainierte das Autorenteam das Modell neu, um die (neue) „Boot“-Klasse unter zwei verschiedenen Bedingungen zu lernen, die jeweils zehnmal wiederholt wurden:
- Focused Learning (FoL) ), also nur neu „ boot“-Klassen werden präsentiert;
- Fully Interleaved Learning (FIL), d. h. alle Kategorien (neue Kategorien + zuvor gelernte Kategorien) werden mit gleicher Wahrscheinlichkeit präsentiert. In beiden Fällen werden insgesamt 180 Bilder pro Epoche präsentiert, wobei in jeder Epoche identische Bilder vorhanden sind.
Das Netzwerk wurde an insgesamt 9000 noch nie gesehenen Bildern getestet, wobei der Testdatensatz aus 1000 Bildern pro Klasse bestand, ohne „bag“. Kategorie. Das Training wird beendet, wenn die Leistung des Netzwerks Asymptote erreicht.
Wie erwartet verursachte FoL Störungen in der alten Kategorie, während FIL diese überwand (Abbildung 1, Spalte 2). Wie oben erwähnt, variiert der Eingriff von FoL in alte Daten je nach Kategorie, was Teil der ursprünglichen Inspiration für SWIL war und auf eine hierarchische Ähnlichkeitsbeziehung zwischen der neuen „Boot“-Kategorie und der alten Kategorie schließen lässt. Beispielsweise nimmt die Erinnerung an „Sneaker“ („Turnschuhe“) und „Sandalen“ („Sandalen“) schneller ab als die an „Hosen“ („Hosen“) (Abbildung 1, Spalte 2), möglicherweise aufgrund der Integration von neu Die Klasse „Boot“ ändert selektiv die synaptischen Gewichte, die die Klassen „Sneaker“ und „Sandalen“ repräsentieren, was zu mehr Interferenzen führt.
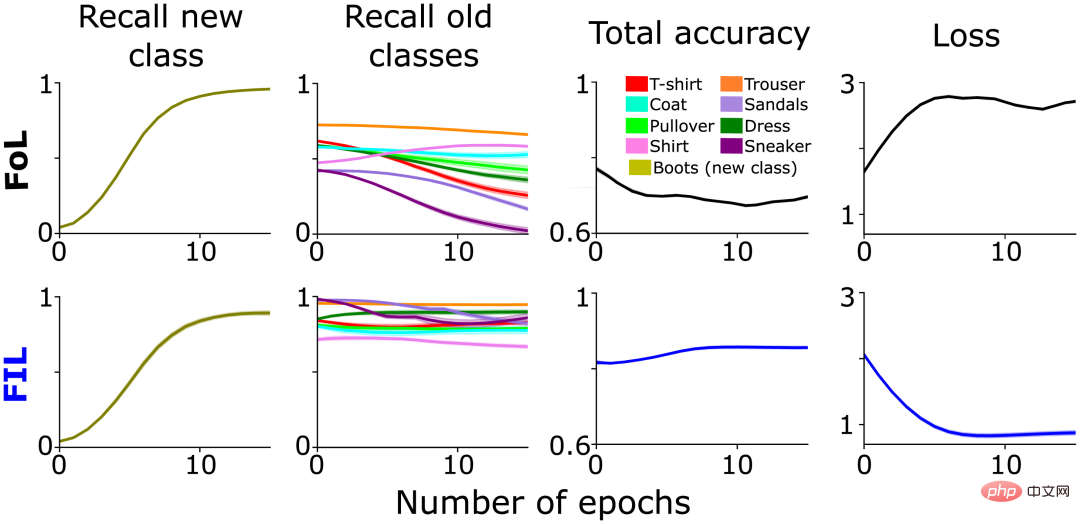
Abbildung 1: Vorab trainiertes Netzwerk lernt Neues " Vergleichende Leistungsanalyse „Boot“-Klasse: FoL (oben) und FIL (unten). Von links nach rechts: Rückruf für die Vorhersage neuer „Boot“-Klassen (oliv), Rückruf für vorhandene Klassen (in verschiedenen Farben dargestellt), Gesamtgenauigkeit (hohe Punktzahl bedeutet geringen Fehler) und Kreuzentropieverlust (insgesamt ein Maß für den Fehler). Die Kurve ist eine Funktion der Anzahl der Epochen im gespeicherten Testdatensatz.
Berechnen Sie die Ähnlichkeit zwischen verschiedenen Kategorien
Wenn FoL neue Kategorien lernt, wird die Klassifizierungsleistung bei ähnlichen alten Kategorien erheblich sinken.
Der Zusammenhang zwischen der Attributähnlichkeit mehrerer Kategorien und dem Lernen wurde bereits zuvor untersucht und gezeigt, dass tiefe lineare Netzwerke schnell bekannte konsistente Attribute erwerben können. Im Gegensatz dazu erfordert das Hinzufügen neuer Zweige inkonsistenter Attribute zu einer bestehenden Kategoriehierarchie langsames, inkrementelles und gestaffeltes Lernen.
In der aktuellen Arbeit verwendet das Autorenteam die vorgeschlagene Methode, um die Ähnlichkeit auf Merkmalsebene zu berechnen. Kurz gesagt wird die Kosinusähnlichkeit zwischen den durchschnittlichen Aktivierungsvektoren pro Klasse bestehender und neuer Klassen in der verborgenen Zielschicht (normalerweise der vorletzten Schicht) berechnet. Abbildung 2A zeigt die vom Autorenteam berechnete Ähnlichkeitsmatrix basierend auf der vorletzten Schichtaktivierungsfunktion des vorab trainierten Netzwerks für die neue Kategorie „Boot“ und die alte Kategorie basierend auf dem Fashion MNIST-Datensatz.
Die Ähnlichkeit zwischen Kategorien steht im Einklang mit unserer visuellen Wahrnehmung von Objekten. Im hierarchischen Clusterdiagramm (Abbildung 2B) können wir beispielsweise die Beziehung zwischen der Klasse „Boot“ und den Klassen „Sneaker“ und „Sandale“ sowie zwischen „Shirt“ („Shirt“) und „T“ beobachten -shirt“ („T-Shirt“) weisen eine hohe Ähnlichkeit zwischen den Kategorien auf. Die Ähnlichkeitsmatrix (Abbildung 2A) entspricht genau der Verwirrungsmatrix (Abbildung 2C). Je höher die Ähnlichkeit, desto leichter ist es möglich, Bilder zu verwechseln. Beispielsweise werden Bilder der Kategorie „Hemd“ leicht mit Bildern der Kategorien „T-Shirt“, „Pullover“ und „Jacke“ verwechselt, was auf die Ähnlichkeit hindeutet Maß sagt die Lerndynamik des neuronalen Netzwerks voraus.
Im FoL-Ergebnisdiagramm im vorherigen Abschnitt (Abbildung 1) gibt es eine ähnliche Klassenähnlichkeitskurve in der Rückrufkurve der alten Kategorie. Im Vergleich zu verschiedenen alten Kategorien („Hosen“ usw.) vergisst FoL beim Erlernen der neuen Kategorie „Stiefel“ schnell ähnliche alte Kategorien („Sneaker“ und „Sandale“).
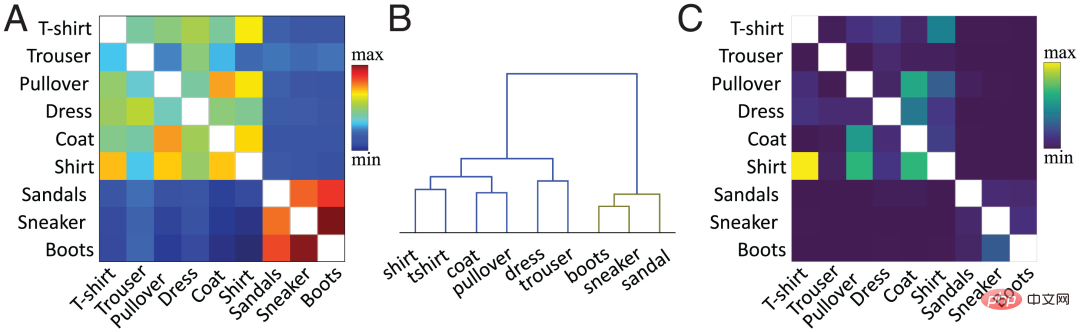
Abbildung 2: (A) Der Countdown des Autorenteams laut Vor -Trainingsnetzwerk Aktivierungsfunktion der zweiten Schicht, berechnete Ähnlichkeitsmatrix bestehender Klassen und neuer „Boot“-Klassen, wobei Diagonalwerte (Ähnlichkeiten für dieselbe Klasse werden in Weiß dargestellt) entfernt werden. (B) Hierarchische Clusterbildung der Ähnlichkeitsmatrix in A. (C) Die vom FIL-Algorithmus nach dem Training zum Erlernen der „Boot“-Klasse generierte Verwirrungsmatrix. Diagonalwerte wurden aus Gründen der Skalierungsklarheit entfernt.
Tiefes lineares neuronales Netzwerk ermöglicht schnelles und effizientes Lernen neuer Dinge
Weiter zu den ersten beiden Bedingungen Auf dieser Grundlage wurden drei neue Bedingungen hinzugefügt, um die Lerndynamik der neuen Klassifizierung zu untersuchen, wobei jede Bedingung zehnmal wiederholt wurde:
- FoL (insgesamt n=6000 Bilder/Epoche);
- FIL (insgesamt n=54000 Bilder/Epoche, 6000 Bilder/Klasse);
- Partial Interleaved Learning (PIL) verwendet eine kleine A-Teilmenge von Bildern (insgesamt n= 350 Bilder/Epoche, ca. 39 Bilder/Klasse), Bilder jeder Kategorie (neue Kategorie + bestehende Kategorie) werden mit gleicher Wahrscheinlichkeit präsentiert
- SWIL, jede Epoche verwendet und trainiert PIL mit der gleichen Gesamtzahl von Bildern, aber vorhandenen Gewichtungen Kategoriebilder basierend auf Ähnlichkeit mit der (neuen) „Boot“-Kategorie;
- Equally Weighted Interleaved Learning (EqWIL), verwendet die gleiche Nummer wie SWIL Die „Boot“-Klassenbilder werden neu trainiert, aber mit den gleichen Gewichtungen für vorhandene Klassenbilder ( Abbildung 3A).
Das Autorenteam verwendete den gleichen oben genannten Testdatensatz (insgesamt n=9000 Bilder). Das Training wird beendet, wenn die Leistung des neuronalen Netzwerks unter jeder Bedingung die Asymptote erreicht. Obwohl pro Epoche weniger Trainingsdaten verwendet werden, dauert es länger, bis die Genauigkeit der Vorhersage der neuen „Boot“-Klasse die Asymptote erreicht, und PIL hat im Vergleich zu FIL einen geringeren Rückruf (H = 7,27, P
Für SWIL wird die Ähnlichkeitsberechnung verwendet, um den Anteil vorhandener Bilder alter Kategorien zu bestimmen, die verschachtelt werden sollen. Auf dieser Grundlage zieht das Autorenteam zufällig Eingabebilder mit gewichteten Wahrscheinlichkeiten aus jeder alten Kategorie. Im Vergleich zu anderen Kategorien sind die Kategorien „Sneaker“ und „Sandale“ am ähnlichsten, was zu einem höheren Anteil an Verschachtelungen führt (Abbildung 3A).
Laut Dendrogramm (Abbildung 2B) bezeichnet das Autorenteam die Klassen „Sneaker“ und „Sandale“ als ähnliche alte Klassen und den Rest als unterschiedliche alte Klassen. Der Rückruf der neuen Klasse (Spalte 1 von Abbildung 3B und Spalte „Neue Klasse“ von Tabelle 1), die Gesamtgenauigkeit und der Verlust von PIL (H=5,44, P0,05) sind mit FIL vergleichbar. Das Lernen der neuen „Boot“-Klasse in EqWIL (H=10,99, P
Das Autorenteam verwendet die folgenden zwei Methoden, um SWIL und FIL zu vergleichen:
- Speicherverhältnis, das das Verhältnis der Anzahl der in FIL und SWIL gespeicherten Bilder darstellt, was auf eine Reduzierung der gespeicherten Datenmenge hinweist
- Beschleunigungsverhältnis, das das Verhältnis zwischen FIL und SWIL ist. Das Verhältnis der Gesamtzahl der in SWIL präsentierten Inhalte, um eine Sättigungsgenauigkeit für den Abruf neuer Kategorien zu erreichen, was auf eine Reduzierung der Zeit hinweist, die zum Erlernen einer neuen Kategorie erforderlich ist.
SWIL kann neue Inhalte mit reduziertem Datenbedarf lernen, Speicherverhältnis = 154,3x (54000/350), und ist schneller, Beschleunigungsverhältnis = 77,1x (54000/(350×2)). Auch wenn die Anzahl der Bilder im Zusammenhang mit neuen Inhalten geringer ist, kann das Modell durch die Verwendung von SWIL, das die hierarchische Struktur des Vorwissens des Modells nutzt, die gleiche Leistung erzielen. SWIL bietet einen Zwischenpuffer zwischen PIL und EqWIL und ermöglicht die Integration einer neuen Kategorie mit minimaler Unterbrechung bestehender Kategorien.
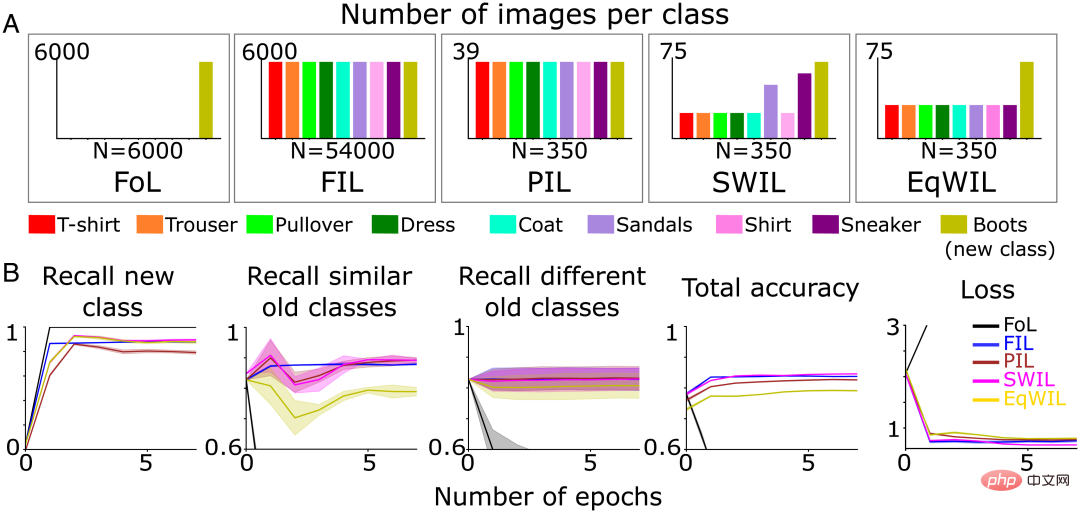
Abbildung 3 (A) Das Autorenteam trainierte das neuronale Netzwerk vorab, um die neue „Boot“-Klasse (olivgrün) unter fünf verschiedenen Lernbedingungen zu lernen, bis die Leistung ein Plateau erreichte: 1) FoL (insgesamt n= 6000 Bilder/Epoche); 2) FIL (insgesamt n=54000 Bilder/Epoche); 3) PIL (insgesamt n=350 Bilder/Epoche); 4) SWIL (insgesamt n=350 Bilder/Epoche) und 5) EqWIL (insgesamt n=350 Bilder/Epoche). (B) FoL (schwarz), FIL (blau), PIL (braun), SWIL (magenta) und EqWIL (gold) sagen neue Kategorien, ähnliche alte Kategorien („Sneaker“ und „Sandalen“) und verschiedene alte Kategorien voraus. die Gesamtgenauigkeit der Vorhersage aller Kategorien und der Kreuzentropieverlust im Testdatensatz, wobei die Abszisse die Anzahl der Epochen ist.
Verwendung von SWIL zum Erlernen neuer Kategorien in CNN basierend auf CIFAR10
Als nächstes trainierte das Autorenteam ein 6-schichtiges nichtlineares CNN mit einer vollständig verbundenen Ausgabeschicht, um zu testen, ob SWIL in komplexeren Umgebungen funktionieren kann (Abbildung 4A), um Bilder der verbleibenden 8 verschiedenen Kategorien (außer „Katze“ und „Auto“) im CIFAR10-Datensatz zu identifizieren. Außerdem haben sie das Modell neu trainiert, um die „Katze“-Klasse unter fünf verschiedenen, zuvor definierten Trainingsbedingungen (FoL, FIL, PIL, SWIL und EqWIL) zu lernen. Abbildung 4C zeigt die Verteilung der Bilder in jeder Kategorie unter 5 Bedingungen. Die Gesamtzahl der Bilder pro Epoche betrug 2400 für die Bedingungen SWIL, PIL und EqWIL, während die Gesamtzahl der Bilder pro Epoche 45000 bzw. 5000 für FIL und FoL betrug. Das Team des Autors trainierte das Netzwerk für jede Situation separat, bis sich die Leistung stabilisierte.
Sie haben das Modell anhand von insgesamt 9000 bisher unveröffentlichten Bildern getestet (1000 Bilder/Klasse, ohne die Klasse „Auto“). Abbildung 4B ist die vom Autorenteam basierend auf dem CIFAR10-Datensatz berechnete Ähnlichkeitsmatrix. Die Klasse „Katze“ ähnelt eher der Klasse „Hund“, während andere Tierklassen zum gleichen Zweig gehören (Abbildung 4B links).
Gemäß dem Baumdiagramm (Abbildung 4B) werden die Kategorien „LKW“ („Truck“), „Schiff“ („Schiff“) und „Flugzeug“ („Flugzeug“) als verschiedene alte Kategorien bezeichnet, mit Ausnahme der „Katze“. " Kategorie Die übrigen Tierkategorien werden als ähnliche alte Kategorien bezeichnet. Für FoL lernt das Modell die neue „cat“-Klasse, vergisst aber die alte Klasse. Ähnlich wie bei den Ergebnissen des Fashion-MNIST-Datensatzes gibt es Interferenzgradienten sowohl in der „Hund“-Klasse (die der „Katze“-Klasse am ähnlichsten ist) als auch in der „LKW“-Klasse (die der „Katze“-Klasse am wenigsten ähnlich ist). ), wobei die Kategorie „Hund“ die höchste Vergessensrate aufweist, während die Kategorie „LKW“ die niedrigste Vergessensrate aufweist.
Wie in Abbildung 4D gezeigt, überwindet der FIL-Algorithmus katastrophale Störungen beim Erlernen der neuen „Katze“-Klasse. Für den PIL-Algorithmus verwendet das Modell die 18,75-fache Datenmenge in jeder Epoche, um die neue „Katze“-Klasse zu lernen, aber die Rückrufrate der „Katze“-Klasse ist höher als die von FIL (H=5,72, P0,05). ; siehe Tabelle 2 und Abbildung 4D). SWIL hat eine höhere Rückrufrate für die neue „Katze“-Klasse als PIL (H=7,89, P
FIL, PIL, SWIL und EqWIL weisen eine ähnliche Leistung bei der Vorhersage verschiedener alter Kategorien auf (H=0,6, P>0,05). SWI integriert die neue „Cat“-Klasse besser als PIL und hilft, Beobachtungsinterferenzen in EqWIL zu überwinden. Im Vergleich zu FIL ist die Verwendung von SWIL zum Erlernen neuer Kategorien schneller, Beschleunigungsverhältnis = 31,25x (45000×10/(2400×6)), während weniger Daten verbraucht werden (Speicherverhältnis = 18,75x). Diese Ergebnisse zeigen, dass SWIL selbst auf nichtlinearen CNNs und realistischeren Datensätzen effektiv neue Kategorien von Dingen lernen kann.
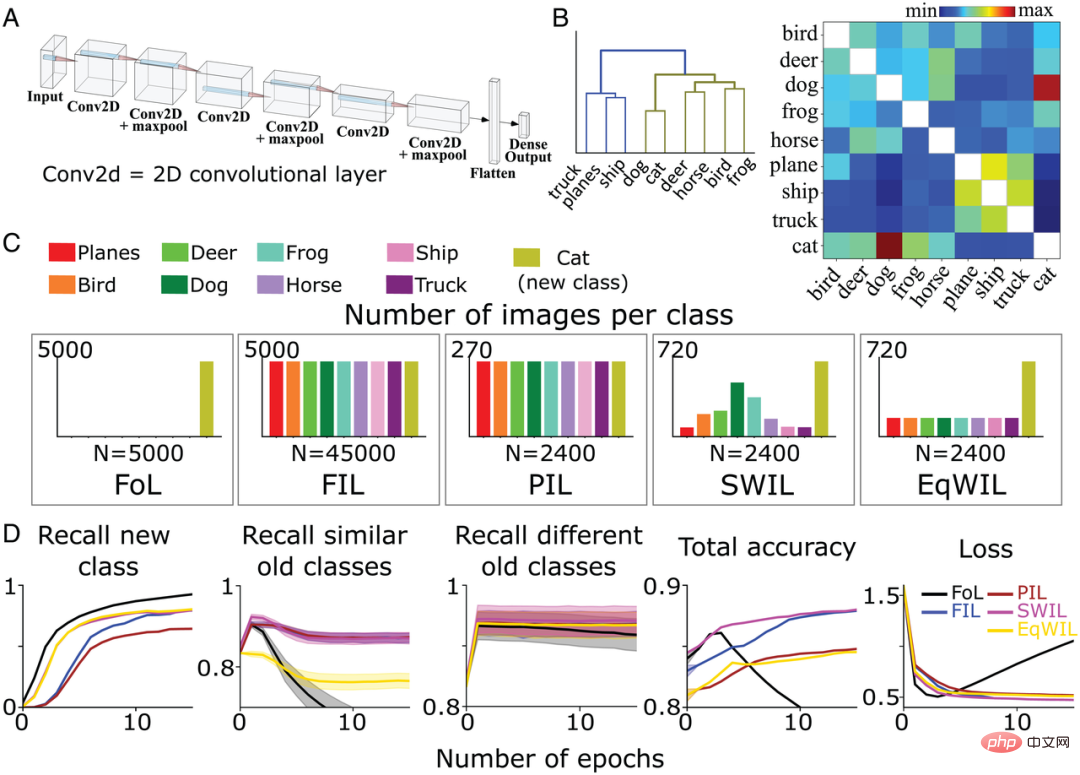
Abbildung 4: (A) Das Autorenteam verwendet ein 6-schichtiges nichtlineares CNN mit einer vollständig verbundenen Ausgabeschicht, um 8 Kategorien von Dingen im CIFAR10-Datensatz zu lernen. (B) Die Ähnlichkeitsmatrix (rechts) wird vom Autorenteam basierend auf der Aktivierungsfunktion der letzten Faltungsschicht nach Präsentation der neuen „Katze“-Klasse berechnet. Die Anwendung hierarchischer Clusterbildung auf die Ähnlichkeitsmatrix (links) zeigt die Gruppierung der beiden Hypernymkategorien Tiere (olivgrün) und Fahrzeuge (blau) in einem Dendrogramm. (C) Das Autorenteam trainierte CNN vorab, um die neue „Katzen“-Klasse (olivgrün) unter 5 verschiedenen Bedingungen zu lernen, bis sich die Leistung stabilisierte: 1) FoL (insgesamt n = 5000 Bilder/Epoche); 2) FIL (insgesamt n). =45000 Bilder/Epoche); 3) PIL (insgesamt n=2400 Bilder/Epoche); 4) SWIL (insgesamt n=2400 Bilder/Epoche); 5) EqWIL (insgesamt n=2400 Bilder/Epoche); Jede Bedingung wurde zehnmal wiederholt. (D) FoL (schwarz), FIL (blau), PIL (braun), SWIL (magenta) und EqWIL (gold) sagen neue Klassen, ähnliche alte Klassen (andere Tierklassen im CIFAR10-Datensatz) und verschiedene alte Klassen voraus ( Der Rückruf Rate von „Flugzeug“, „Schiff“ und „LKW“), die Gesamtvorhersagegenauigkeit aller Kategorien und der Kreuzentropieverlust im Testdatensatz, wobei die Abszisse die Anzahl der Epochen ist.
Auswirkungen der Konsistenz neuer Inhalte mit alten Kategorien auf Lernzeit und erforderliche Daten
Wenn ein neuer Inhalt zu einer zuvor erlernten Kategorie hinzugefügt werden kann, ohne dass größere Änderungen am Netzwerk erforderlich sind, sollen die beiden dies tun konsequent sein. Basierend auf diesem Rahmen kann das Erlernen neuer Kategorien, die weniger bestehende Kategorien beeinträchtigen (hohe Konsistenz), einfacher in das Netzwerk integriert werden als das Erlernen neuer Kategorien, die mehrere bestehende Kategorien beeinträchtigen (geringe Konsistenz).
Um die obige Schlussfolgerung zu testen, nutzte das Autorenteam das vorab trainierte CNN aus dem vorherigen Abschnitt, um eine neue „Auto“-Kategorie unter allen fünf zuvor beschriebenen Lernbedingungen zu lernen. Abbildung 5A zeigt die Ähnlichkeitsmatrix der Kategorie „Auto“ im Vergleich zu anderen vorhandenen Kategorien. „Auto“ und „Lkw“, „Schiff“ und „Flugzeug“ befinden sich unter demselben Ebenenknoten, was darauf hinweist, dass sie ähnlicher sind. Zur weiteren Bestätigung führte das Autorenteam eine Visualisierungsanalyse zur Reduzierung der t-SNE-Dimensionalität auf der Aktivierungsschicht durch, die für die Ähnlichkeitsberechnung verwendet wurde (Abbildung 5B). Die Studie ergab, dass sich die Klasse „Auto“ deutlich mit anderen Fahrzeugklassen („Lkw“, „Schiff“ und „Flugzeug“) überschnitt, während sich die Klasse „Katze“ mit anderen Tierklassen („Hund“, „Frosch“) überschnitt. „Pferd“ („Pferd“), „Vogel“ („Vogel“) und „Hirsch“ („Hirsch“)) überschneiden sich.
Im Einklang mit den Erwartungen des Autorenteams führt FoL zu katastrophalen Störungen beim Erlernen der Kategorie „Auto“ und stört ähnliche alte Kategorien stärker. Dies wird durch die Verwendung von FIL überwunden (Abbildung 5D). Für PIL, SWIL und EqWIL gibt es insgesamt n = 2000 Bilder pro Epoche (Abbildung 5C). Mithilfe des SWIL-Algorithmus kann das Modell neue „Auto“-Kategorien mit einer Genauigkeit ähnlich der von FIL (H=0,79, P>0,05) lernen, mit minimaler Beeinträchtigung vorhandener Kategorien (einschließlich ähnlicher und unterschiedlicher Kategorien). Wie in Spalte 2 von Abbildung 5D gezeigt, lernt das Modell mithilfe von EqWIL die neue Klasse „Auto“ auf die gleiche Weise wie SWIL, jedoch mit einem höheren Grad an Interferenz mit anderen ähnlichen Kategorien (z. B. „Lkw“) (H=53,81). , P
Im Vergleich zu FIL kann SWIL neue Inhalte schneller lernen, Beschleunigungsverhältnis = 48,75x (45000×12/(2000×6)), und der Speicherbedarf ist reduziert, Speicherverhältnis = 22,5x. Im Vergleich zu „Katze“ (48,75x vs. 31,25x) kann „Auto“ durch die Verschachtelung weniger Klassen (z. B. „Lkw“, „Schiff“ und „Flugzeug“) schneller lernen, während „Katze“ mehr Kategorien hat (z als „Hund“, „Frosch“, „Pferd“, „Frosch“ und „Hirsch“) überschneiden sich. Diese Simulationsexperimente zeigen, dass die Menge an alten Kategoriedaten, die für den Crossover und das beschleunigte Lernen neuer Kategorien erforderlich ist, von der Konsistenz der neuen Informationen mit dem Vorwissen abhängt.
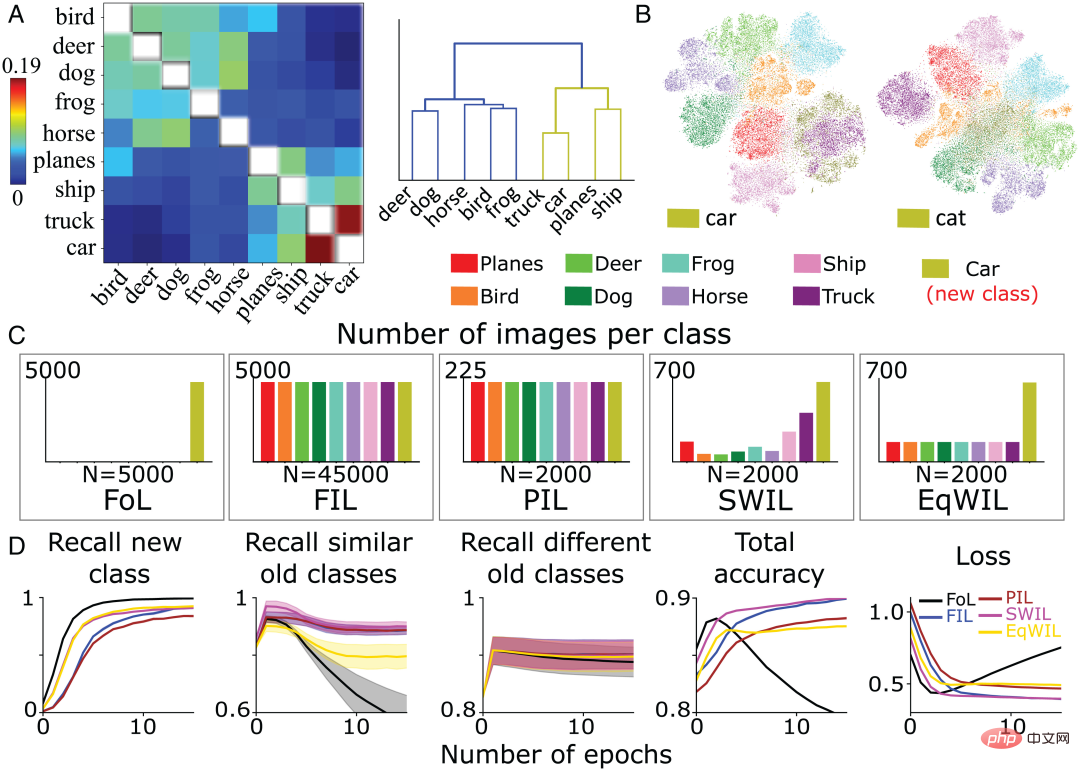
Abbildung 5: (A) Das Autorenteam berechnete die Ähnlichkeitsmatrix (links) basierend auf der vorletzten Schichtaktivierungsfunktion und führte nach der Präsentation der neuen Kategorie „Auto“ eine hierarchische Gruppierung der Ähnlichkeitsmatrix durch Endergebnisbild (rechts). (B) Das Modell lernt neue „Auto“-Kategorien bzw. „Katze“-Kategorien. Nachdem die letzte Faltungsschicht die Aktivierungsfunktion bestanden hat, führt das Autorenteam die Visualisierungsergebnisse zur t-SNE-Dimensionalitätsreduzierung durch. (C) Das Autorenteam trainierte CNN vorab, um die neue „Auto“-Klasse (olivgrün) unter 5 verschiedenen Bedingungen zu lernen, bis sich die Leistung stabilisierte: 1) FoL (insgesamt n = 5000 Bilder/Epoche); 2) FIL (insgesamt n). =45000 Bilder/Epoche); 3) PIL (insgesamt n=2000 Bilder/Epoche); 4) SWIL (insgesamt n=2000 Bilder/Epoche); 5) EqWIL (insgesamt n=2000 Bilder/Epoche); (D) FoL (schwarz), FIL (blau), PIL (braun), SWIL (magenta) und EqWIL (gold) sagen neue Kategorien voraus, ähnliche alte Kategorien („Flugzeug“, „Schiff“ und „LKW“) und den Rückruf Rate verschiedener alter Kategorien (andere Tierkategorien im CIFAR10-Datensatz), die Gesamtvorhersagegenauigkeit aller Kategorien und der Kreuzentropieverlust im Testdatensatz, wobei die Abszisse die Anzahl der Epochen ist. Jedes Diagramm zeigt den Durchschnitt von 10 Wiederholungen und der schattierte Bereich beträgt ±1 SEM.
Verwendung von SWIL zum Sequenzlernen
Als nächstes testete das Autorenteam, ob neue Inhalte, die in Form einer Serialisierung (Sequenzlernframework) präsentiert werden, mit SWIL gelernt werden können. Zu diesem Zweck übernahmen sie das trainierte CNN-Modell in Abbildung 4, um die „Katze“-Klasse (Aufgabe 1) im CIFAR10-Datensatz unter FIL- und SWIL-Bedingungen zu lernen, trainierten nur für die verbleibenden 9 Kategorien von CIFAR10 und trainierten dann für jede Bedingung Als nächstes trainieren Sie das Modell, um die neue „Auto“-Klasse zu lernen (Aufgabe 2). Die erste Spalte von Abbildung 6 zeigt die Verteilung der Anzahl der Bilder in anderen Kategorien beim Lernen der Kategorie „Auto“ unter SWIL-Bedingungen (insgesamt n = 2500 Bilder/Epoche). Beachten Sie, dass bei der Vorhersage der Klasse „Katze“ auch die neue Klasse „Auto“ gegenseitig erlernt wird. Da die Modellleistung unter FIL-Bedingungen am besten ist, wurden die SWIL-Ergebnisse nur mit FIL verglichen.
Wie in Abbildung 6 dargestellt, entspricht die Fähigkeit von SWIL, neue und alte Kategorien vorherzusagen, der von FIL (H=14,3, P>0,05). Das Modell verwendet den SWIL-Algorithmus, um neue „Auto“-Kategorien schneller zu lernen, mit einem Beschleunigungsverhältnis von 45x (50000×20/(2500×8)) und der Speicherbedarf jeder Epoche ist 20-mal geringer als bei FIL. Wenn das Modell die Kategorien „Katze“ und „Auto“ lernt, ist die Anzahl der pro Epoche unter der SWIL-Bedingung verwendeten Bilder (Speicherverhältnis und Beschleunigungsverhältnis betragen 18,75x bzw. 20x) geringer als die gesamten Daten, die pro Epoche unter der FIL verwendet werden Bedingungssatz (Speicherverhältnis und Beschleunigungsverhältnis von 31,25x bzw. 45x) und erlernen trotzdem schnell neue Kategorien. Das Autorenteam erweitert diese Idee und geht davon aus, dass die Lernzeit und die Datenspeicherung des Modells exponentiell reduziert werden, da die Anzahl der erlernten Kategorien weiter zunimmt, sodass neue Kategorien effizienter erlernt werden können, was möglicherweise widerspiegelt, was passiert, wenn das menschliche Gehirn tatsächlich lernt.
Experimentelle Ergebnisse zeigen, dass SWIL mehrere neue Klassen in das Sequenz-Lern-Framework integrieren kann, sodass das neuronale Netzwerk ohne Störungen weiterlernen kann.
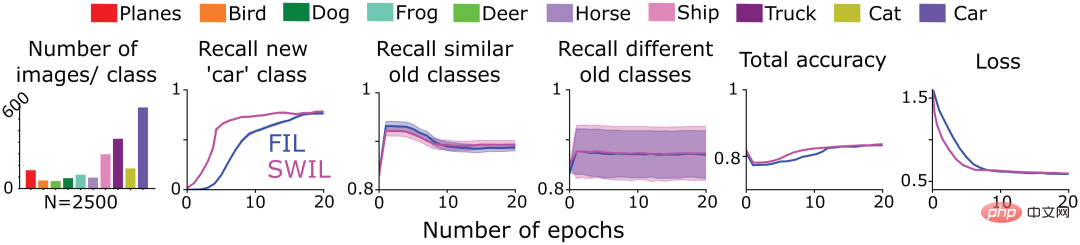
Abbildung 6: Das Autorenteam trainierte ein 6-schichtiges CNN, um die neue „Katze“-Klasse zu lernen (Aufgabe 1) und dann die „Auto“-Klasse (Aufgabe 2) zu lernen, bis die Leistung konvergierte in den folgenden beiden Fällen Yu Stable: 1) FIL: Enthält alle alten Kategorien (in verschiedenen Farben gezeichnet) und neue Kategorien („Katze“/„Auto“), die mit der gleichen Wahrscheinlichkeit dargestellt werden. 2) SWIL: Basierend auf Bildern mit neuen Kategorien („Katze“/„Auto“) und verwenden anteilig alte Kategoriebeispiele. Beziehen Sie auch die in Aufgabe 1 gelernte Klasse „Katze“ ein und gewichten Sie sie basierend auf der Ähnlichkeit der in Aufgabe 2 gelernten Klasse „Auto“. Die erste Unterabbildung zeigt die Verteilung der Anzahl der in jeder Epoche verwendeten Bilder. Die übrigen Unterabbildungen geben jeweils die Rückrufraten von FIL (blau) und SWIL (magenta) bei der Vorhersage neuer Kategorien, ähnlicher alter Kategorien und verschiedener alter Kategorien an Rückrufraten aller Kategorien Die Gesamtgenauigkeit und der Kreuzentropieverlust im Testdatensatz, wobei die Abszisse die Anzahl der Epochen ist.
Verwenden Sie SWIL, um den Abstand zwischen Kategorien zu vergrößern und Lernzeit und Datenvolumen zu reduzieren
Das Autorenteam testete schließlich die Verallgemeinerung des SWIL-Algorithmus und überprüfte, ob er Datensätze mit mehr Kategorien lernen kann und ob dies der Fall ist ist für komplexere Netzwerkarchitekturen anwendbar.
Sie trainierten ein komplexes CNN-Modell-VGG19 (insgesamt 19 Schichten) auf dem CIFAR100-Datensatz (Trainingssatz 500 Bilder/Kategorie, Testsatz 100 Bilder/Kategorie) und lernten 90 Kategorien. Das Netzwerk wird dann neu trainiert, um neue Kategorien zu lernen. Abbildung 7A zeigt die vom Autorenteam berechnete Ähnlichkeitsmatrix basierend auf der Aktivierungsfunktion der vorletzten Schicht basierend auf dem CIFAR100-Datensatz. Wie in Abbildung 7B dargestellt, ist die neue Klasse „Zug“ mit vielen bestehenden Transportklassen wie „Bus“ („Bus“), „Straßenbahn“ („Straßenbahn“) und „Traktor“ („Traktor“) usw. kompatibel. ) sind sehr ähnlich.
Im Vergleich zu FIL kann SWIL neue Dinge schneller lernen (Beschleunigungsverhältnis = 95,45x (45500×6/(1430×2))) und nutzt die Datenmenge (Speicherverhältnis=31,8x) wird deutlich reduziert, während die Leistung grundsätzlich gleich bleibt (H=8,21, P>0,05). Wie in Abbildung 7C dargestellt, sagt das Modell unter den Bedingungen von PIL (H=10,34, P
Um gleichzeitig zu untersuchen, ob der große Abstand zwischen Darstellungen verschiedener Kategorien eine Grundvoraussetzung für die Beschleunigung des Modelllernens darstellt, trainierte das Autorenteam zusätzlich zwei neuronale Netzwerkmodelle:
- 6-Schicht-CNN (wie Abbildung 4 und Abbildung 5 basierend auf CIFAR10);
- VGG11 (11 Schichten) lernt 90 Kategorien im CIFAR100-Datensatz. Die neue „Train“-Klasse wird nur unter zwei Bedingungen trainiert: FIL und SWIL.
Wie in Abbildung 7B gezeigt, ist die Überlappung zwischen der neuen „Zug“-Klasse und der Transportklasse für die beiden oben genannten Netzwerkmodelle höher, aber Im Vergleich zum VGG19-Modell ist die Trennung der einzelnen Kategorien geringer. Im Vergleich zu FIL ist die Geschwindigkeit, mit der SWIL neue Dinge lernt, ungefähr linear mit der Zunahme der Anzahl der Schichten (Steigung = 0,84). Dieses Ergebnis zeigt, dass eine Vergrößerung des Darstellungsabstands zwischen Kategorien das Lernen beschleunigen und die Speicherbelastung verringern kann.
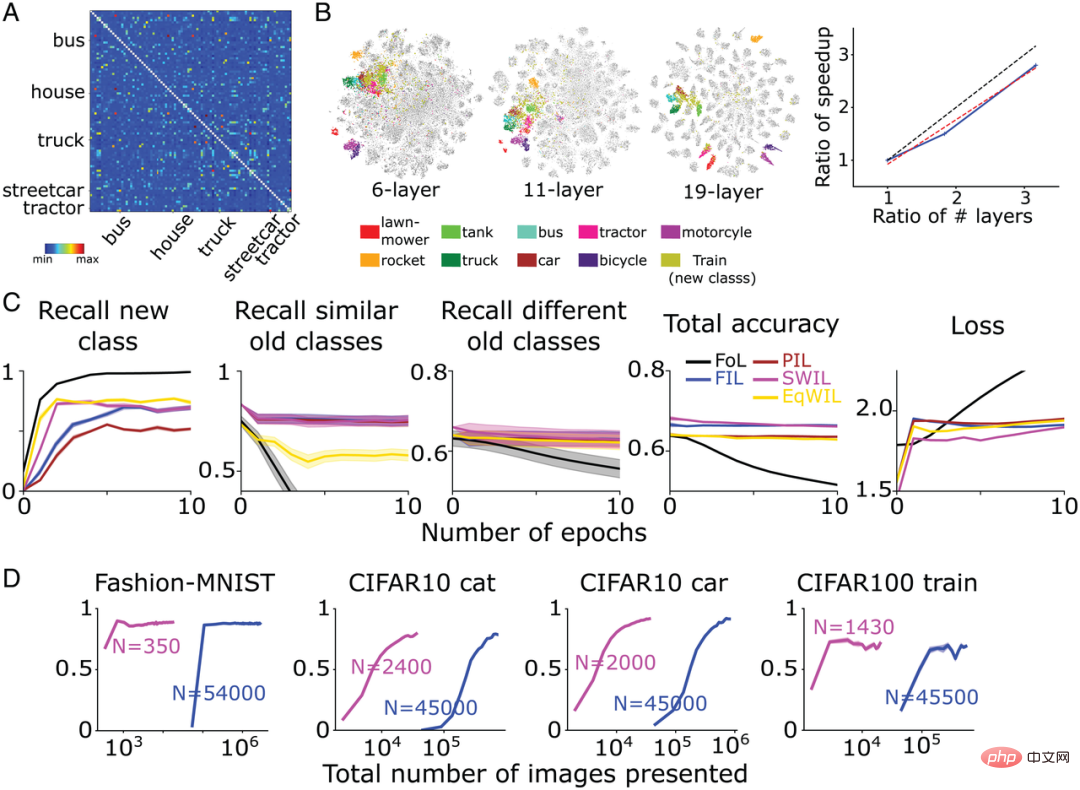
Abbildung 7: (A) VGG19 lernt die neue „Zug“-Klasse Abschließend berechnete das Autorenteam die Ähnlichkeitsmatrix basierend auf der Aktivierungsfunktion der vorletzten Schicht. Die fünf Kategorien „Lkw“, „Straßenbahn“, „Bus“, „Haus“ und „Traktor“ sind der „Eisenbahn“ am ähnlichsten. Diagonale Elemente aus der Ähnlichkeitsmatrix ausschließen (Ähnlichkeit=1). (B, links) Die t-SNE-Dimensionsreduktionsvisualisierungsergebnisse des Autorenteams für 6-schichtige CNN-, VGG11- und VGG19-Netzwerke nach Durchlaufen der vorletzten Schicht der Aktivierungsfunktion. (B, rechts) Die vertikale Achse stellt das Beschleunigungsverhältnis (FIL/SWIL) dar, und die horizontale Achse stellt das Verhältnis der Anzahl der Schichten von drei verschiedenen Netzwerken im Verhältnis zum 6-schichtigen CNN dar. Die schwarz gepunktete Linie, die rot gepunktete Linie und die blaue durchgezogene Linie repräsentieren die Standardlinie mit Steigung = 1, die beste Anpassungslinie bzw. die Simulationsergebnisse. (C) Lernsituation des VGG19-Modells: FoL (schwarz), FIL (blau), PIL (braun), SWIL (magenta) und EqWIL (gold) sagen eine neue „Zug“-Klasse, eine ähnliche alte Klasse (Transportklasse) und den Rückruf voraus Rate verschiedener alter Kategorien (außer der Transportkategorie), die Gesamtvorhersagegenauigkeit aller Kategorien und der Kreuzentropieverlust im Testdatensatz, wobei die Abszisse die Epochennummer ist. Jedes Diagramm zeigt den Durchschnitt von 10 Wiederholungen und der schattierte Bereich beträgt ±1 SEM. (D) Von links nach rechts sagt das Modell den Rückruf der Fashion-MNIST-Klasse „Stiefel“ (Abb. 3), der CIFAR10-Klasse „Katze“ (Abb. 4), der CIFAR10-Klasse „Auto“ (Abb. 5) und voraus CIFAR100-„Zug“-Klasse als Funktion der Gesamtzahl der von SWIL (Magenta) und FIL (Blau) verwendeten Bilder (Log-Skala). „N“ stellt die Gesamtzahl der Bilder dar, die in jeder Epoche unter jeder Lernbedingung verwendet werden (einschließlich neuer und alter Kategorien).
Wird die Geschwindigkeit weiter verbessert, wenn das Netzwerk auf mehr nicht überlappende Klassen trainiert wird und der Abstand zwischen den Darstellungen größer ist?
Zu diesem Zweck übernahm das Autorenteam ein tiefes lineares Netzwerk (verwendet für das Fashion-MNIST-Beispiel in Abbildung 1-3) und trainierte es zum Lernen eines kombinierten Datensatzes Es besteht aus 8 Fashion-MNIST-Kategorien (ausgenommen „Taschen“- und „Stiefel“-Kategorien) und 10 Digit-MNIST-Kategorien. Anschließend wird das Netzwerk darauf trainiert, die neue „Stiefel“-Kategorie zu erlernen.
Entsprechend den Erwartungen des Autorenteams ähnelt „Boot“ eher den alten Kategorien „Sandalen“ und „Sneaker“, gefolgt vom Rest der Mode- MNIST-Kategorien (beinhaltet hauptsächlich Kleidungsbilder) und schließlich die Digit-MNIST-Kategorie (beinhaltet hauptsächlich digitale Bilder).
Auf dieser Grundlage verschachtelte das Autorenteam zunächst weitere ähnliche alte Kategoriestichproben und verschachtelte dann die Kategoriestichproben Fashion-MNIST und Digit-MNIST (insgesamt n = 350). Bilder/Epoche). Experimentelle Ergebnisse zeigen, dass SWIL ähnlich wie FIL schnell und ohne Störungen neue Kategorieinhalte lernen kann, jedoch eine viel kleinere Datenteilmenge mit einem Speicherverhältnis von 325,7x (114000/350) und einem Beschleunigungsverhältnis von 162,85x (228000/228000) verwendet /350). Das Autorenteam beobachtete in den aktuellen Ergebnissen eine Beschleunigung um das 2,1-fache (162,85/77,1) und einen 2,25-fachen Anstieg der Anzahl der Kategorien (18/8) im Vergleich zum Fashion-MNIST-Datensatz.
Die experimentellen Ergebnisse in diesem Abschnitt helfen festzustellen, dass SWIL auf komplexere Datensätze (CIFAR100) und neuronale Netzwerkmodelle (VGG19) angewendet werden kann, was die Verallgemeinerung des Algorithmus beweist. Wir zeigen auch, dass eine Vergrößerung des internen Abstands zwischen Kategorien oder eine Erhöhung der Anzahl nicht überlappender Kategorien die Lerngeschwindigkeit weiter erhöhen und die Speicherbelastung verringern kann.
Zusammenfassung
Künstliche neuronale Netze stehen beim kontinuierlichen Lernen vor großen Herausforderungen und weisen häufig katastrophale Interferenzen auf. Um dieses Problem zu lösen, haben viele Studien das vollständig verschachtelte Lernen (FIL) eingesetzt, bei dem neue und alte Inhalte gegenseitig erlernt werden, um das Netzwerk gemeinsam zu trainieren. FIL erfordert die Verflechtung aller vorhandenen Informationen jedes Mal, wenn neue Informationen erlernt werden, was es zu einem biologisch unplausiblen und zeitaufwändigen Prozess macht. Kürzlich haben einige Untersuchungen gezeigt, dass FIL möglicherweise nicht erforderlich ist und der gleiche Lerneffekt erzielt werden kann, indem nur alte Inhalte verschachtelt werden, die eine erhebliche Darstellungsähnlichkeit mit den neuen Inhalten aufweisen, d. h. mithilfe der Methode des ähnlichkeitsgewichteten verschachtelten Lernens (SWIL). Es wurden jedoch Bedenken hinsichtlich der Skalierbarkeit von SWIL geäußert.
Dieses Papier erweitert den SWIL-Algorithmus und testet ihn anhand verschiedener Datensätze (Fashion-MNIST, CIFAR10 und CIFAR100) und neuronaler Netzwerkmodelle (Deep Linear Network und CNN). Unter allen Bedingungen schnitten ähnlichkeitsgewichtetes verschachteltes Lernen (SWIL) und gleichgewichtetes verschachteltes Lernen (EqWIL) beim Erlernen neuer Kategorien besser ab als teilweise verschachteltes Lernen (PIL). Dies entspricht den Erwartungen des Autorenteams, da SWIL und EqWIL die relative Häufigkeit neuer Kategorien im Vergleich zu alten Kategorien erhöhen.
Dieses Papier zeigt auch, dass eine sorgfältige Auswahl und Verflechtung ähnlicher Inhalte katastrophale Interferenzen mit ähnlichen alten Kategorien im Vergleich zur gleichmäßigen Unterabtastung bestehender Kategorien (d. h. der EqWIL-Methode) reduziert. SWIL funktioniert bei der Vorhersage neuer und bestehender Kategorien ähnlich wie FIL, beschleunigt jedoch das Erlernen neuer Inhalte erheblich (Abbildung 7D) und reduziert gleichzeitig die erforderlichen Trainingsdaten erheblich. SWIL kann neue Kategorien in einem Sequenz-Lern-Framework lernen und damit seine Generalisierungsfähigkeiten weiter demonstrieren.
Wenn es schließlich weniger Überschneidungen (größere Distanz) mit zuvor erlernten Kategorien gibt als bei einer neuen Kategorie mit Ähnlichkeiten zu vielen alten Kategorien, kann die Integrationszeit verkürzt werden und die Dateneffizienz ist höher. Insgesamt liefern die experimentellen Ergebnisse einen möglichen Einblick, dass das Gehirn tatsächlich eine der größten Schwächen des ursprünglichen CLST-Modells überwindet, indem es die unrealistische Trainingszeit verkürzt.
Das obige ist der detaillierte Inhalt vonUntersuchungen zeigen, dass ähnlichkeitsbasiertes, verschachteltes Lernen das Problem der „Amnesie' beim Deep Learning wirksam lösen kann. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr