
Heim >Technologie-Peripheriegeräte >KI >„Unter Verwendung der Stable Diffusion-Technologie zur Reproduktion von Bildern wurden entsprechende Forschungsergebnisse von der CVPR-Konferenz angenommen.'
„Unter Verwendung der Stable Diffusion-Technologie zur Reproduktion von Bildern wurden entsprechende Forschungsergebnisse von der CVPR-Konferenz angenommen.'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-26 12:43:08857Durchsuche
Was wäre, wenn künstliche Intelligenz Ihre Vorstellungskraft interpretieren und die Bilder in Ihrem Kopf in die Realität umsetzen könnte?

Auch wenn das ein bisschen Cyberpunk klingt. Doch ein kürzlich veröffentlichtes Papier hat im KI-Kreis für Aufsehen gesorgt.
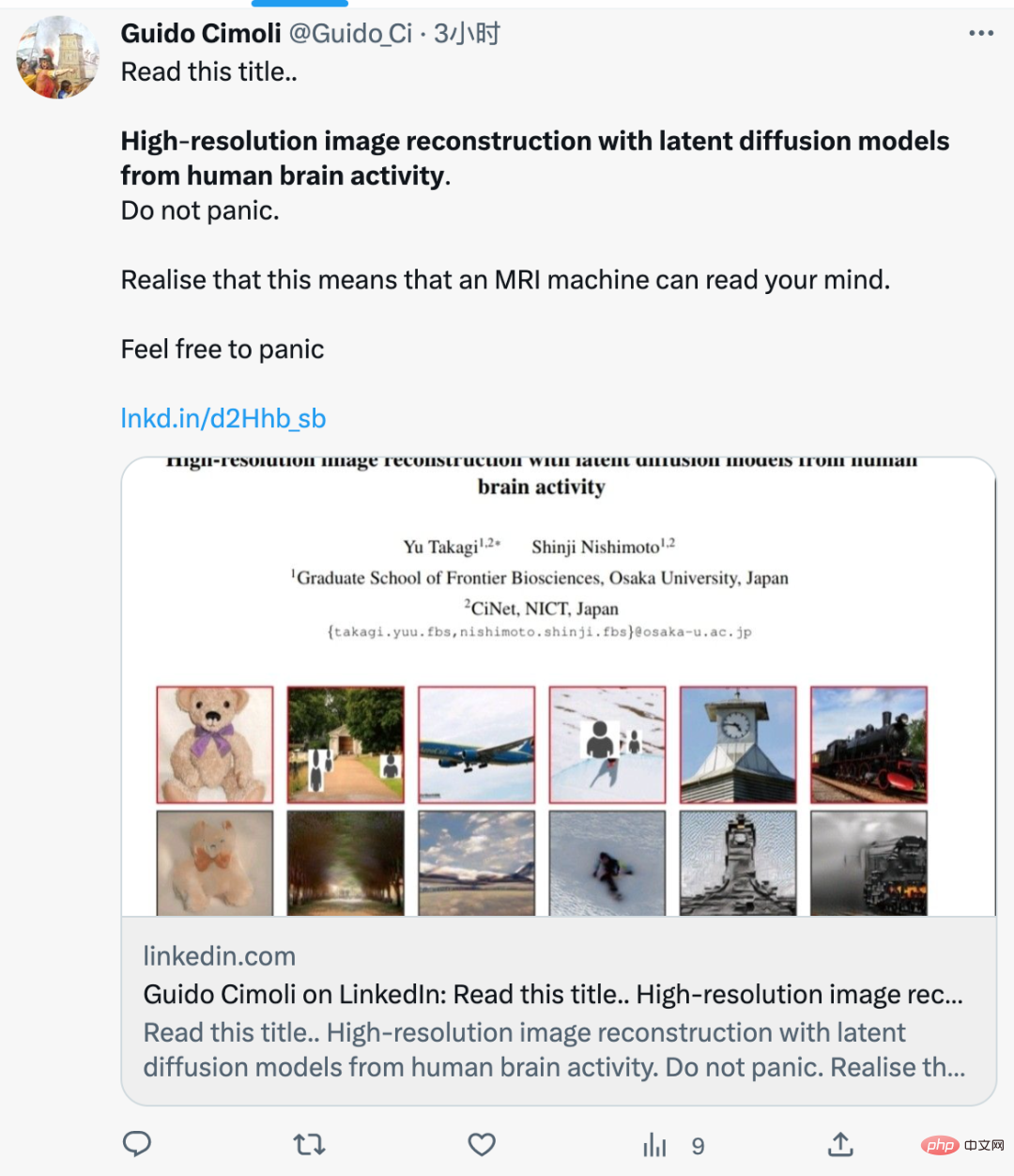
In diesem Artikel wurde festgestellt, dass sie mithilfe der kürzlich sehr beliebten stabilen Diffusion hochauflösende und hochpräzise Bilder der Gehirnaktivität rekonstruieren können. Die Autoren schrieben, dass sie im Gegensatz zu früheren Studien kein Modell der künstlichen Intelligenz trainieren oder verfeinern mussten, um diese Bilder zu erstellen. ??
Webseitenadresse: https: //sites.google.com/view/stablediffusion-with-brain/
Wie machen sie das?
- In dieser Studie verwendeten die Autoren Stable Diffusion, um Bilder der menschlichen Gehirnaktivität zu rekonstruieren, die durch funktionelle Magnetresonanztomographie (fMRT) gewonnen wurden. Der Autor erklärte außerdem, dass es auch hilfreich sei, den Mechanismus des latenten Diffusionsmodells zu verstehen, indem man verschiedene Komponenten gehirnbezogener Funktionen untersucht (wie den latenten Vektor des Bildes Z usw.). Dieses Papier wurde auch vom CVPR 2023 angenommen.
- Die wichtigsten Beiträge dieser Studie umfassen:
Es wurde gezeigt, dass sein einfaches Framework hochauflösende (512 × 512) Bilder aus der Gehirnaktivität mit hoher semantischer Genauigkeit ohne komplexes Training oder Feinabstimmung rekonstruieren kann. Ein tiefes Generativ Modell, wie in der Abbildung unten dargestellt;
Durch die Zuordnung spezifischer Komponenten zu verschiedenen Gehirnregionen erklärt diese Studie quantitativ jede Komponente von LDM aus neurowissenschaftlicher Sicht.
Diese Studie ist objektiv Der von LDM implementierte Text-zu-Bild-Konvertierungsprozess kombiniert die durch bedingten Text ausgedrückten semantischen Informationen und behält dabei das Erscheinungsbild des Originalbilds bei.
Überblick über die Methodik
Die Gesamtmethodik dieser Studie ist in Abbildung 2 unten dargestellt. Abbildung 2 (oben) ist ein schematisches Diagramm des in dieser Studie verwendeten LDM, wobei ε den Bildkodierer, D den Bilddekodierer und τ den Textkodierer (CLIP) darstellt.- Abbildung 2 (Mitte) ist ein schematisches Diagramm der Dekodierungsanalyse dieser Studie. Wir haben die zugrunde liegende Darstellung des präsentierten Bildes (z) und des zugehörigen Textes c aus fMRT-Signalen im frühen (blau) bzw. fortgeschrittenen (gelb) visuellen Kortex entschlüsselt. Diese latenten Darstellungen werden als Eingabe verwendet, um das rekonstruierte Bild X_zc zu erzeugen.
- Abbildung 2 (unten) ist ein schematisches Diagramm der Kodierungsanalyse dieser Studie. Wir haben Kodierungsmodelle erstellt, um fMRI-Signale aus verschiedenen Komponenten von LDM vorherzusagen, einschließlich z, c und z_c.
Ich werde hier nicht zu viel über Stable Diffusion vorstellen, ich glaube, dass viele Leute damit vertraut sind.
ErgebnisseWerfen wir einen Blick auf die visuellen Rekonstruktionsergebnisse dieser Studie.
Dekodierung
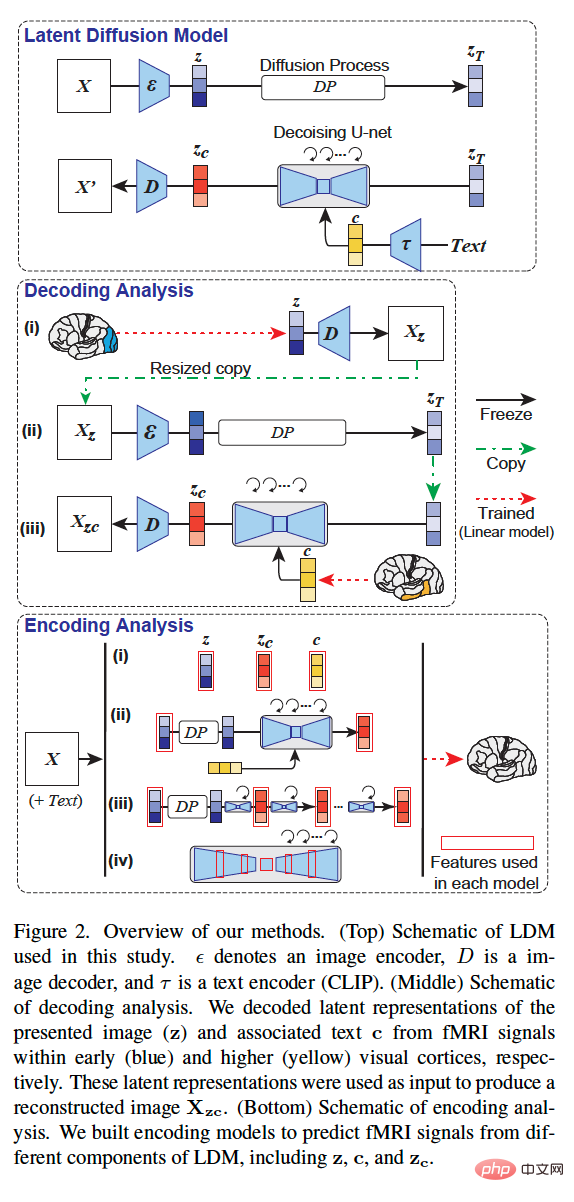
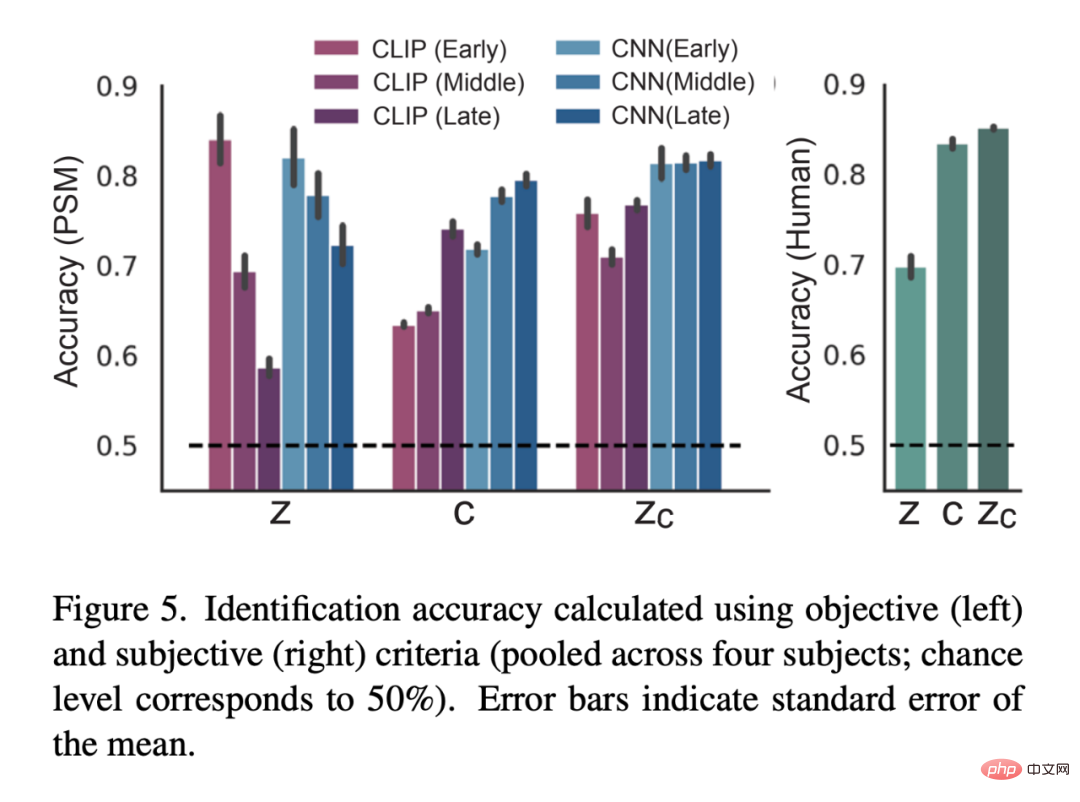
Abbildung 3 unten zeigt die visuellen Rekonstruktionsergebnisse eines Subjekts (subj01). Wir haben für jedes Testbild fünf Bilder erstellt und das Bild mit dem höchsten PSM ausgewählt. Einerseits stimmt das nur mit z rekonstruierte Bild optisch mit dem Originalbild überein, erfasst jedoch dessen semantischen Inhalt nicht. Andererseits erzeugen Bilder, die nur mit c rekonstruiert wurden, Bilder mit hoher semantischer Treue, sind aber visuell inkonsistent. Schließlich können durch die Verwendung von z_c-rekonstruierten Bildern hochauflösende Bilder mit hoher semantischer Genauigkeit erzeugt werden. Abbildung 4 zeigt die rekonstruierten Bilder desselben Bildes von allen Testern (Alle Bilder wurden mit z_c generiert). Insgesamt war die Rekonstruktionsqualität bei allen Testern stabil und genau. Abbildung 5 ist ein quantitatives Bewertungsergebnis:

Codierungsmodell
# 🎜🎜# Abbildung 6 zeigt die Vorhersagegenauigkeit des Kodierungsmodells für drei latente Bilder im Zusammenhang mit LDM: z, das latente Bild des Originalbilds; , das latente Bild der Bildtextanmerkung; und z_c, die verrauschte latente Bilddarstellung von z nach dem Kreuzaufmerksamkeits-Umkehrdiffusionsprozess mit c. Abbildung 7 zeigt das vorhergesagte Verhältnis von z zur Voxelaktivität im gesamten Kortex, wenn eine kleine Menge Rauschen hinzugefügt wird, z_c ist besser. Interessanterweise sagt z_c die Voxelaktivität im oberen visuellen Kortex besser voraus als z, wenn der Rauschpegel erhöht wird, was darauf hinweist, dass der semantische Inhalt des Bildes allmählich hervorgehoben wird. Wie verändert sich die latente Darstellung des hinzugefügten Rauschens während des iterativen Entrauschungsprozesses? Abbildung 8 zeigt, dass in den frühen Stadien des Entrauschungsprozesses das Z-Signal die Vorhersage des fMRI-Signals dominiert. In der Zwischenphase des Entrauschungsprozesses sagt z_c die Aktivität im oberen visuellen Kortex viel besser voraus als z, was darauf hindeutet, dass der größte Teil des semantischen Inhalts in dieser Phase entsteht. Die Ergebnisse zeigen, wie LDM Bilder aus Rauschen verfeinert und generiert. 
Schließlich untersuchten die Forscher jede Schicht von U-Net. Was Informationen sind verarbeitet wird. Abbildung 9 zeigt die Ergebnisse verschiedener Schritte des Entrauschungsprozesses (früh, mittel, spät) und des Codierungsmodells verschiedener Schichten von U-Net. In den frühen Phasen des Entrauschungsprozesses liefert die Engpassschicht (orange) von U-Net die höchste Vorhersageleistung im gesamten Kortex. Mit fortschreitender Rauschunterdrückung sagen jedoch die frühen Schichten von U-Net (blau) die Aktivität im frühen visuellen Kortex voraus, während die Engpassschichten zu einer höheren Vorhersagekraft für den höheren visuellen Kortex übergehen.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt von„Unter Verwendung der Stable Diffusion-Technologie zur Reproduktion von Bildern wurden entsprechende Forschungsergebnisse von der CVPR-Konferenz angenommen.'. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr