
Heim >Technologie-Peripheriegeräte >KI >Entdecken Sie die Großmodelltechnologie in der Post-GPT 3.0-Ära und machen Sie sich auf den Weg, die Zukunft von AGI zu verwirklichen
Entdecken Sie die Großmodelltechnologie in der Post-GPT 3.0-Ära und machen Sie sich auf den Weg, die Zukunft von AGI zu verwirklichen

- PHPznach vorne
- 2023-04-26 10:58:081841Durchsuche
ChatGPT überraschte oder weckte viele Menschen nach seinem Erscheinen. Die Überraschung war, dass ich nicht erwartet hatte, dass das Large Language Model (LLM) so effektiv sein könnte; das Erwachen war die plötzliche Erkenntnis, dass unser Verständnis von LLM und seiner Entwicklungsphilosophie weit von den fortschrittlichsten Ideen der Welt entfernt ist. Ich gehöre zu der Gruppe, die sowohl überrascht als auch aufgeweckt war, und ich bin auch ein typischer Chinese. Die Menschen sind gut in der Selbstreflexion, also begannen sie nachzudenken, und dieser Artikel ist das Ergebnis dieser Reflexion.
Um ehrlich zu sein, hat sich in Bezug auf die LLM-Modelltechnologie in China derzeit die Kluft zwischen ihr und der fortschrittlichsten Technologie weiter vergrößert. Ich denke, dass die Frage der Technologieführerschaft oder Technologielücke dynamisch aus einer Entwicklungsperspektive betrachtet werden sollte. In den ein bis zwei Jahren nach dem Aufkommen von Bert war der Aufholprozess der heimischen Technologie in diesem Bereich tatsächlich immer noch sehr schnell, und es wurden auch einige gute Verbesserungsmodelle vorgeschlagen. Der Wendepunkt für die Vergrößerung der Lücke sollte nach der Veröffentlichung von GPT 3.0 liegen , also im Jahr 2020, etwa zur Jahresmitte. Damals war nur wenigen Menschen bewusst, dass GPT 3.0 nicht nur eine spezifische Technologie war, sondern tatsächlich ein Entwicklungskonzept verkörperte, wohin LLM gehen sollte. Seitdem hat sich die Kluft immer weiter vergrößert und ChatGPT ist nur eine natürliche Folge dieser unterschiedlichen Entwicklungsphilosophien. Daher denke ich persönlich, dass die Frage, ob man über die finanziellen Mittel verfügt, um ein sehr großes LLM aufzubauen, allein aus technischer Sicht hauptsächlich auf das unterschiedliche Verständnis von LLM und die unterschiedlichen Entwicklungskonzepte zurückzuführen ist geh in die Zukunft .
China fällt immer weiter hinter die ausländische Technologie zurück. Das ist eine Tatsache, und es ist in Ordnung, es nicht zuzugeben. Vor einiger Zeit machten sich viele Leute im Internet Sorgen, dass sich die heimische KI jetzt in einer „überlebenskritischen Phase“ befinde. Verstehen Sie nicht, ist OpenAI das einzige Unternehmen auf der Welt mit einer solch zukunftsorientierten Vision? Einschließlich Google liegt ihr Verständnis der LLM-Entwicklungskonzepte offensichtlich hinter OpenAI. Die Realität ist, dass OpenAI zu gute Leistungen erbracht hat und alle zurückgelassen hat, nicht nur im Inland.
Ich denke, dass OpenAI in Bezug auf Konzepte und verwandte Technologien für LLM im Ausland Google und DeepMind um etwa ein halbes bis ein Jahr voraus ist, und etwa zwei Jahre vor China. Wenn es um LLM geht, ist Google meiner Meinung nach an zweiter Stelle. Diejenigen, die die technische Vision von Google am besten widerspiegeln, sind zwischen Februar und April 2022 gestartet Es ist InstructGPT. Von hier aus können Sie die Lücke zwischen Google und OpenAI erkennen. Sie können es wahrscheinlich verstehen, nachdem Sie den Text hinter mir gelesen haben. Der bisherige Fokus von DeepMind lag auf der Stärkung des Lernens zur Eroberung von Spielen und KI für die Wissenschaft. Eigentlich hätte das Unternehmen erst vor 21 Jahren damit beginnen sollen, dieser Richtung Aufmerksamkeit zu schenken, und derzeit holt es auf. Ganz zu schweigen von Meta, der Fokus lag nicht auf LLM, und jetzt fühlt es sich so an, als würde man versuchen, aufzuholen. Dies ist immer noch eine Gruppe von Institutionen, die derzeit am besten abschneiden, ganz zu schweigen von den inländischen? Ich fühle mich entschuldbar. Was die LLM-Philosophie von OpenAI betrifft, werde ich im letzten Teil dieses Artikels über mein Verständnis sprechen.
Dieser Artikel fasst die Mainstream-LLM-Technologie seit dem Aufkommen von GPT 3.0 zusammen Für die Mainstream-Technologien davor können Sie sich auf „PTM, das auf Wind und Wellen reitet, ausführliche Interpretation des Fortschritts von“ beziehen Pre-Training-Modelle“.
Ich glaube, dass Sie nach der Lektüre dieser beiden Artikel ein klareres Verständnis des technischen Kontexts des LLM-Bereichs, der verschiedenen Entwicklungskonzepte, die bei der Entwicklung der LLM-Technologie entstanden sind, und sogar der möglichen zukünftigen Entwicklungstrends haben werden. Natürlich stellen die an vielen Stellen erwähnten Inhalte meine persönliche Meinung dar und sind höchst subjektiv. Fehler und Auslassungen sind unvermeidlich, also lesen Sie sie bitte mit Vorsicht.
Dieser Artikel versucht, einige der folgenden Fragen zu beantworten: Hat ChatGPT einen Paradigmenwechsel in der Forschung im Bereich NLP und sogar KI herbeigeführt? Wenn ja, welche Auswirkungen wird das haben? Was lernt LLM aus riesigen Datenmengen? Wie greift LLM auf dieses Wissen zu? Welche Auswirkungen wird es haben, wenn der Umfang des LLM allmählich zunimmt? Was ist In-Context-Learning? Warum ist es eine mysteriöse Technologie? Welche Beziehung besteht zu Instruct? Verfügt LLM über Denkfähigkeiten? Wie funktioniert das Thought Chain CoT? Warten Sie, ich glaube, dass Sie nach dem Lesen eine Antwort auf diese Fragen haben werden.
Bevor ich über den aktuellen Stand der LLM-Technologie spreche, möchte ich zunächst über den Forschungsparadigmenwechsel in meinem Kopf auf Makroebene sprechen. Auf diese Weise können wir „den Wald vor den Bäumen sehen“ und besser verstehen, warum sich bestimmte Technologien so verändert haben.
Top of the Trend: Die Transformation des NLP-Forschungsparadigmas
Wenn wir die Zeitachse länger ausdehnen, in die Ära des Deep Learning im Bereich NLP zurückkehren und technologische Veränderungen und ihre Auswirkungen in einem längeren Zeitfenster beobachten, ist das der Fall Möglicherweise ist es einfacher, einige der Schlüsselknoten zu erkennen. Ich persönlich glaube, dass es während der technologischen Entwicklung im Bereich NLP in den letzten 10 Jahren möglicherweise zwei große Paradigmenwechsel in der Forschung gegeben hat.
Paradigmenwechsel 1.0: Vom Deep Learning zum zweistufigen Pre-Training-Modell
Der von diesem Paradigmenwechsel abgedeckte Zeitraum reicht ungefähr von der Einführung des Deep Learning in den NLP-Bereich (ca. 2013). ) auf GPT 3.0, bevor es herauskam (ca. Mai 2020) .
Vor dem Aufkommen der Bert- und GPT-Modelle war die beliebte Technologie im NLP-Bereich das Deep-Learning-Modell, und Deep Learning im NLP-Bereich stützte sich hauptsächlich auf die folgenden Schlüsseltechnologien: eine große Anzahl verbesserter LSTM-Modelle und a Verwenden Sie als typischen Feature-Extraktor Sequence to Sequence (oder Encoder-Decoder) + Attention als typisches technisches Gesamtgerüst für verschiedene spezifische Aufgaben.
Mit der Unterstützung dieser Kerntechnologien besteht das Hauptforschungsziel von Deep Learning im NLP-Bereich zusammenfassend darin, wie die Modellschichttiefe oder die Modellparameterkapazität effektiv erhöht werden kann. Das heißt, wie können wir dem Encoder und Decoder kontinuierlich tiefere LSTM- oder CNN-Schichten hinzufügen, um das Ziel einer Erhöhung der Schichttiefe und der Modellkapazität zu erreichen? Obwohl diese Art von Bemühungen die Tiefe des Modells tatsächlich kontinuierlich erhöht hat, ist sie im Hinblick auf die Wirkung, bestimmte Aufgaben zu lösen, insgesamt nicht sehr erfolgreich. Mit anderen Worten, die Vorteile, die sie mit sich bringen, sind nicht im Vergleich zu nicht-tiefen Lernmethoden Großartig.
Der Grund, warum Deep Learning nicht erfolgreich genug ist, liegt meiner Meinung nach vor allem an zwei Aspekten: Einerseits ist die Gesamtmenge an Trainingsdaten für eine bestimmte Aufgabe begrenzt. Wenn die Kapazität des Modells zunimmt, muss es durch eine größere Menge an Trainingsdaten unterstützt werden. Andernfalls wird der Aufgabeneffekt nicht erreicht, selbst wenn Sie die Tiefe erhöhen. Vor dem Aufkommen von Pre-Training-Modellen war es offensichtlich, dass dies ein ernstes Problem im Bereich der NLP-Forschung darstellte. Ein weiterer Aspekt bestand darin, dass der LSTM/CNN-Merkmalsextraktor nicht über starke Ausdrucksfähigkeiten verfügte. Das heißt, egal wie viele Daten Ihnen zur Verfügung gestellt werden, sie sind nutzlos, weil Sie das in den Daten enthaltene Wissen nicht effektiv aufnehmen können. Es dürften vor allem diese beiden Gründe sein, die den erfolgreichen Durchbruch von Deep Learning im NLP-Bereich behindern.
Die Entstehung dieser beiden Pre-Training-Modelle, Bert/GPT, stellt einen Technologiesprung im Bereich NLP dar, sowohl aus der Perspektive der akademischen Forschung als auch der industriellen Anwendung, und hat zu einem Wandel des Forschungsparadigmas geführt das gesamte Feld. Die Auswirkungen dieses Paradigmenwechsels spiegeln sich in zwei Aspekten wider: Erstens im Niedergang und sogar im allmählichen Niedergang einiger Teilbereiche der NLP-Forschung; zweitens werden die technischen Methoden und technischen Rahmenbedingungen verschiedener Teilbereiche des NLP zunehmend vereinheitlicht Bert Ungefähr zu dieser Zeit hat sich der Technologie-Stack im Wesentlichen in zwei Technologiemodelle konvergiert. Lassen Sie uns diese beiden Punkte getrennt besprechen.
Auswirkung 1: Der Untergang von Zwischenaufgaben
NLP ist ein Sammelbegriff für ein Makroforschungsgebiet, das bei sorgfältiger Analyse eine Vielzahl spezifischer Unterfelder und Unterrichtungen aufweist Abhängig von der Art der Aufgabe können diese Aufgaben in zwei Kategorien unterteilt werden: Eine kann als „Zwischenaufgaben“ und die andere als „Endaufgaben“ bezeichnet werden.
Zu den typischen Zwischenaufgaben gehören: Chinesische Wortsegmentierung, Teil-der-Sprache-Tagging, NER, syntaktische Analyse, Referenzauflösung, semantischer Parser usw. Diese Art von Aufgaben erfüllen im Allgemeinen nicht die tatsächlichen Anforderungen in der Anwendung, und die meisten Davon werden die eigentlichen Anforderungen gelöst. Es gibt eine Zwischenstufe oder eine Hilfsstufe der Aufgabe. Ich möchte beispielsweise, dass ein Syntax-Parser dem Benutzer den syntaktischen Analysebaum dieses Satzes anzeigt. Der Benutzer muss die Verarbeitungsergebnisse dieser Zwischenstufen des NLP nicht sehen. Er kümmert sich nur darum. Haben Sie eine bestimmte Aufgabe gut erledigt? Zu den „letzten Aufgaben“ gehören Textklassifizierung, Textähnlichkeitsberechnung, maschinelle Übersetzung, Textzusammenfassung usw., davon gibt es viele. Das Merkmal dieser Art von Aufgabe besteht darin, dass jedes Unterfeld einen bestimmten tatsächlichen Bedarf löst und die Aufgabenergebnisse grundsätzlich direkt dem Benutzer präsentiert werden können. Beispielsweise muss der Benutzer Ihnen wirklich einen Satz auf Englisch geben und ihm sagen, was Chinesisch ist.
Logischerweise sollten „Zwischenaufgaben“ nicht erscheinen, und der Grund, warum sie existieren, spiegelt den unzureichenden Entwicklungsstand der NLP-Technologie wider. In den frühen Stadien der technologischen Entwicklung war es schwierig, schwierige Abschlussaufgaben in einem Schritt zu erledigen, da die Technologie zu dieser Zeit relativ rückständig war. Nehmen wir zum Beispiel die maschinelle Übersetzung. In den Anfängen der Technologie war es sehr schwierig, bei der maschinellen Übersetzung gute Arbeit zu leisten. Daher haben Forscher die schwierigen Probleme aufgeteilt und in verschiedene Zwischenstufen wie Wortsegmentierung zerlegt -Sprachkennzeichnung und syntaktische Analyse Sie haben zunächst jede Zwischenstufe gut abgeschlossen, und dann können wir nichts mehr tun, um die letzte Mission abzuschließen.
Aber seit dem Aufkommen von Bert/GPT besteht eigentlich keine Notwendigkeit, diese Zwischenaufgaben zu erledigen, denn durch Vortraining mit einer großen Datenmenge kann Bert/ GPT hat diese Zwischenaufgaben bereits als sprachliches Merkmal in die Parameter des Transformers integriert. Zu diesem Zeitpunkt können wir die endgültigen Aufgaben direkt durchgängig lösen, ohne diesen Zwischenprozess speziell modellieren zu müssen. Das vielleicht umstrittenste Problem ist die chinesische Wortsegmentierung. Sie müssen sich keine Gedanken darüber machen, welche Wörter ein Wort bilden sollen, solange es hilfreich ist Um die Aufgabe zu lösen, wird es natürlich lernen. Die sinnvolle Wortsegmentierungsmethode dieser Studie muss nicht unbedingt mit den Wortsegmentierungsregeln übereinstimmen, die wir Menschen verstehen.
Basierend auf dem obigen Verständnis sollten Sie tatsächlich zu dem Schluss kommen, dass sich diese Art von NLP-Zwischenstufenaufgaben allmählich von der Bühne zurückziehen werden, sobald Bert/GPT auftaucht der Geschichte.
Auswirkung 2: Vereinheitlichung technischer Routen in verschiedenen Forschungsrichtungen
#🎜🎜 # Bevor wir die spezifischen Auswirkungen erläutern, diskutieren wir zunächst eine andere Möglichkeit zur Aufteilung der NLP-Aufgaben, die für das Verständnis des folgenden Inhalts hilfreich sein wird. Wenn die „endgültige Aufgabe“ weiter klassifiziert wird, kann sie grob in zwei verschiedene Arten von Aufgaben unterteilt werden: Aufgaben zum Verstehen natürlicher Sprache und Aufgaben zur Erzeugung natürlicher Sprache. Wenn die „Zwischenaufgaben“ ausgeschlossen sind, umfassen typische Aufgaben zum Verstehen natürlicher Sprache die Textklassifizierung, die Beurteilung von Satzbeziehungen, die Beurteilung emotionaler Tendenzen usw. Bei diesen Aufgaben handelt es sich im Wesentlichen um Klassifizierungsaufgaben, dh die Eingabe eines Satzes (Artikels) oder zweier Sätze. Das Modell bezieht sich auf den gesamten Eingabeinhalt und beurteilt schließlich, zu welcher Kategorie er gehört. Die Erzeugung natürlicher Sprache umfasst auch viele Unterrichtungen der NLP-Forschung, wie Chat-Roboter, maschinelle Übersetzung, Textzusammenfassung, Frage- und Antwortsysteme usw. Das Merkmal der Generierungsaufgabe besteht darin, dass das Modell bei gegebenem Eingabetext entsprechend eine Zeichenfolge mit Ausgabetext generieren muss. Der Unterschied zwischen den beiden spiegelt sich hauptsächlich in den Eingabe- und Ausgabeformen wider.
Seit der Geburt des Bert/GPT-Modells gibt es einen offensichtlichen Trend zur technischen Vereinheitlichung. Zunächst werden die Merkmalsextraktoren verschiedener Unterfelder im NLP schrittweise von LSTM/CNN zu Transformer vereinheitlicht. Tatsächlich hätten wir bald nach der Veröffentlichung von Bert erkennen müssen, dass dies unweigerlich zu einem Technologietrend werden würde. Der Grund dafür wurde in diesem Artikel erklärt und analysiert, den ich vor einigen Jahren geschrieben habe: „Zhang Junlin: Fantasie aufgeben, Transformer voll und ganz annehmen: Vergleich der drei wichtigsten Feature-Extraktoren (CNN/RNN/TF) für die Verarbeitung natürlicher Sprache“ Interessierte Studierende können darauf verweisen.
Artikellink: https://zhuanlan.zhihu.com/p/54743941#🎜 🎜#
Darüber hinaus vereinheitlicht Transformer nicht nur viele Bereiche des NLP, sondern ist auch dabei, nach und nach CNN und andere Modelle zu ersetzen, die in verschiedenen Bildverarbeitungsaufgaben weit verbreitet sind. In ähnlicher Weise werden derzeit auch multimodale Modelle verwendet Es wird das Transformer-Modell verwendet. Diese Art von Transformer geht von NLP aus und vereinheitlicht nach und nach den Trend in immer mehr Bereichen der KI. Es begann mit dem Ende 2020 erschienenen Vision Transformer (ViT). Seitdem hat es floriert und war bisher ein großer Erfolg , und es wird weiterhin auf weitere Bereiche ausgeweitet. Die Expansionsdynamik wird immer schneller.Zweitens ist das Forschungs- und Entwicklungsmodell in den meisten NLP-Teilbereichen auf ein zweistufiges Modell umgestiegen: Modellvorschulungsphase + Anwendungsfeinabstimmung (Feinabstimmung). ) oder den Zero/Wenige-Aufnahme-Aufforderungsmodus verwenden. Genauer gesagt sind verschiedene NLP-Aufgaben tatsächlich in zwei verschiedene Pre-Training-Modell-Frameworks konvergiert: Für Aufgaben zum Verstehen natürlicher Sprache wurde das technische System in der Darstellung „Zwei-Wege-Sprachmodell Pre-Training + Anwendungsfeinabstimmung“ vereinheitlicht von Bert. "-Modus; für Aufgaben zur Generierung natürlicher Sprache ist das technische System auf den durch GPT 2.0 repräsentierten Modus "autoregressives Sprachmodell (d. h. einseitiges Sprachmodell von links nach rechts) + Zero/Few Shot Prompt" vereinheitlicht. Warum es in zwei technische Routen unterteilt ist, ist unvermeidlich. Wir werden dies später erklären.
Diese beiden Modelle mögen ähnlich erscheinen, sie enthalten jedoch sehr unterschiedliche Entwicklungsideen und werden zu unterschiedlichen zukünftigen Entwicklungsrichtungen führen. Leider haben die meisten von uns damals das Potenzial von GPT als Entwicklungsroute unterschätzt und unsere Vision auf Modelle wie Bert konzentriert. ( 20 Jahre (ca. Juni) sollten wir uns bisher mitten in diesem Paradigmenwechsel befinden . Übergangszeit: Das durch GPT 3.0 dargestellte Modell „autoregressives Sprachmodell + Eingabeaufforderung“ nimmt eine dominierende Stellung ein Wie bereits erwähnt, konvergierte der technische Rahmen in den frühen Tagen der Entwicklung von Pre-Training-Modellen Das Bert-Modell und das GPT-Modell Dies sind zwei unterschiedliche technische Paradigmen, und die Menschen stehen dem Bert-Modell im Allgemeinen optimistischer gegenüber. Eine ganze Reihe späterer technischer Verbesserungen verlaufen auf dem Weg von Bert. Mit der Weiterentwicklung der Technologie werden Sie jedoch feststellen, dass die derzeit größten LLM-Modelle fast alle auf dem „autoregressiven Sprachmodell + Prompting“-Modell basieren, das GPT 3.0 ähnelt, wie z. B. GPT 3, PaLM, GLaM, Gopher, Chinchilla, MT -NLG, LaMDA usw., keine Ausnahmen. Warum passiert das? Dahinter muss eine gewisse Unvermeidlichkeit stecken, und ich denke, dass dies hauptsächlich auf zwei Gründe zurückzuführen ist.
Zuallererst Googles T5-Modell vereinheitlicht formal die externen Ausdrücke des Verstehens natürlicher Sprache und der Aufgaben zur Generierung natürlicher Sprache. Wie in der Abbildung oben gezeigt, handelt es sich bei dem rot markierten Problem um ein Textklassifizierungsproblem und bei dem gelb markierten um ein Regressions- oder Klassifizierungsproblem, das die Ähnlichkeit von Sätzen bestimmt. Dies sind typische Probleme beim Verstehen natürlicher Sprache. Im T5-Modell stimmen diese Probleme des Verständnisses natürlicher Sprache mit den Generierungsproblemen in Form von Eingabe und Ausgabe überein. Mit anderen Worten, das Klassifizierungsproblem kann in das LLM-Modell umgewandelt werden, um Zeichenfolgen entsprechender Kategorien zu generieren, sodass das Verständnis und Generierungsaufgaben werden in der Form ausgedrückt, dass eine vollständige Einheit erreicht wird. Der zweite Grund: Wenn Sie mit null oder wenigen Schussaufforderungen gute Arbeit leisten möchten, müssen Sie den GPT-Modus übernehmen. Es gibt Studien (Referenz: Zur Rolle der Bidirektionalität beim Vortraining von Sprachmodellen), die bewiesen haben, dass der Bert-Modus besser ist als der GPT-Modus, wenn nachgelagerte Aufgaben fein abgestimmt werden Wird verwendet, wenn dieser Modus nachgelagerte Aufgaben löst, ist der Effekt des GPT-Modus besser als der des Bert-Modus. Dies zeigt, dass es für das generierte Modell einfacher ist, Aufgaben im Null-Schuss-/Wenige-Schuss-Aufforderungsmodus auszuführen, und dass der Bert-Modus natürliche Nachteile hat, wenn er Aufgaben auf diese Weise erledigt. Dies ist der zweite Grund. Aber hier stellt sich die Frage: Warum verfolgen wir die Null-Schuss-/Wenige-Schuss-Aufforderung, Aufgaben zu erledigen? Um dieses Problem klar zu erklären, müssen wir zunächst eine weitere Frage klären: Welche Art von LLM-Modell ist für uns am idealsten? Das Bild oben zeigt, wie ein idealer LLM aussehen sollte. Erstens sollte LLM über starke unabhängige Lernfähigkeiten verfügen. Angenommen, wir füttern ihn mit allen verschiedenen Arten von Daten wie Text oder Bildern, die es auf der Welt gibt, dann sollte er in der Lage sein, alle darin enthaltenen Wissenspunkte automatisch zu lernen. Der Lernprozess erfordert kein menschliches Eingreifen und sollte dazu in der Lage sein das erlernte Wissen flexibel anwenden, um praktische Probleme zu lösen. Da es sich um umfangreiche Daten handelt, sind viele Modellparameter zum Speichern des Wissens erforderlich, um das gesamte Wissen aufzunehmen. Daher wird dieses Modell zwangsläufig ein riesiges Modell sein. Zweitens LLM sollte in der Lage sein, Probleme in jedem Teilbereich des NLP zu lösen, und nicht nur begrenzte Bereiche unterstützen. Es sollte sogar auf Probleme in anderen Bereichen außerhalb des NLP reagieren Na ja. Antwort . Wenn wir außerdem LLM verwenden, um Probleme in einem bestimmten Bereich zu lösen, sollten wir die Ausdrücke verwenden, an die wir als Menschen gewöhnt sind, das heißt, LLM sollte menschliche Befehle verstehen. Dies spiegelt wider, dass LLM sich an die Menschen anpassen kann und nicht umgekehrt, dass sich die Menschen an das LLM-Modell anpassen können. Typische Beispiele für Menschen, die sich an LLM gewöhnen, sind, dass sie sich den Kopf zerbrechen, verschiedene Eingabeaufforderungen auszuprobieren, um gute Eingabeaufforderungen zu finden, die das vorliegende Problem am besten lösen können. Zu diesem Punkt zeigt die obige Abbildung einige Beispiele auf der Schnittstellenebene, auf der Menschen mit LLM interagieren, um zu veranschaulichen, welche Schnittstellenform für Menschen zur Verwendung des LLM-Modells gut geeignet ist. Nachdem wir dieses ideale LLM gelesen haben, gehen wir zurück und erklären die verbleibenden Fragen oben: Warum sollten wir Null-Schuss-/Wenige-Schuss-Aufforderungen verfolgen, um Aufgaben zu erledigen? Es gibt zwei Gründe. Erstens muss der Umfang dieses LLM-Modells sehr groß sein, und es darf nur sehr wenige Institutionen geben, die in der Lage sind, dieses Modell zu erstellen oder die Parameter dieses Modells zu ändern. Die Aufgabensteller sind Tausende kleiner und mittlerer Organisationen oder sogar Einzelpersonen. Selbst wenn Sie das Modell als Open Source nutzen, können sie das Modell nicht bereitstellen, geschweige denn den Feinabstimmungsmodus verwenden, um die Modellparameter zu ändern. Daher sollten wir einen Weg verfolgen, der es dem Aufgabenanforderer ermöglicht, die Aufgabe abzuschließen, ohne die Modellparameter zu ändern, d die technische Ausrichtung des Soft Promptings widerspricht diesem Entwicklungstrend). Der Modellbauer verwandelt LLM in einen öffentlichen Dienst und führt ihn im LLM-as-Service-Modus aus. Als Service-Unterstützer müssen LLM-Modellhersteller unter Berücksichtigung der sich ständig ändernden Benutzeranforderungen das Ziel verfolgen, LLM in die Lage zu versetzen, möglichst viele Arten von Aufgaben zu erledigen. Dies ist ein Nebeneffekt und ein realistischer Faktor, warum Super Große Modelle werden auf jeden Fall AGI verfolgen. Zweitens, egal ob es sich um die Aufforderung „Null-Schuss“, „Wenige-Schuss-Aufforderung“ oder sogar um die Gedankenkettenaufforderung (CoT, Chain of Thought) handelt, die die LLM-Denkfähigkeit fördert, ist es die im Bild oben vorhandene Schnittstellenschicht. Technologie . Insbesondere ist die ursprüngliche Absicht der Zero-Shot-Eingabeaufforderung tatsächlich die ideale Schnittstelle zwischen Menschen und LLM. Sie verwendet direkt die von Menschen gewohnte Aufgabenausdrucksmethode, um LLM Dinge erledigen zu lassen Die Wirkung war nicht gut. Nach weiteren Recherchen haben wir herausgefunden, dass der Effekt besser ist als die Null-Schuss-Aufforderung, wenn wir LLM ein paar Beispiele nennen und diese Beispiele zur Darstellung der Aufgabenbeschreibung für eine bestimmte Aufgabe verwenden. Daher studiert jeder die bessere Wenig-Schuss-Aufforderungstechnologie. Es ist verständlich, dass wir ursprünglich gehofft hatten, dass LLM eine bestimmte Aufgabe mithilfe von Befehlen ausführen könnte, die üblicherweise von Menschen verwendet werden. Die aktuelle Technologie ist dazu jedoch nicht in der Lage. Deshalb haben wir uns für die nächstbeste Lösung entschieden und diese alternativen Technologien verwendet, um menschliche Aufgaben auszudrücken Anforderungen. Wenn Sie die obige Logik verstehen, können Sie leicht die folgende Schlussfolgerung ziehen: Wenige Schussaufforderungen (auch bekannt als In-Context-Learning) sind lediglich eine Übergangstechnologie. Wenn wir eine Aufgabe natürlicher beschreiben können und LLM sie verstehen kann, werden wir diese Übergangstechnologien ohne zu zögern aufgeben. Der Grund liegt auf der Hand, dass die Verwendung dieser Methoden zur Beschreibung von Aufgabenanforderungen nicht im Einklang mit der menschlichen Gewohnheit steht. Das ist auch der Grund, warum ich GPT 3.0+Prompting als Übergangstechnologie aufgeführt habe. Das Aufkommen von ChatGPT hat diesen Status quo verändert und Prompting durch Instruct ersetzt, was einen neuen technologischen Paradigmenwechsel mit sich gebracht und mehrere Folgetechnologien hervorgebracht hat. ups. Einfluss. Auswirkung 1: LLM an eine neue interaktive Benutzeroberfläche für Menschen anpassen Im Kontext des idealen LLM schauen wir uns ChatGPT an, um seinen technischen Beitrag besser zu verstehen. ChatGPT sollte unter allen vorhandenen Technologien die technische Methode sein, die dem idealen LLM am nächsten kommt. Wenn ich die herausragendsten Funktionen von ChatGPT zusammenfassen könnte, würde ich die folgenden acht Wörter verwenden: „Leistungsstark und rücksichtsvoll“. „Leistungsstark“ Dies sollte meiner Meinung nach hauptsächlich auf das Grundlagen-LLM GPT3.5 zurückzuführen sein, auf dem ChatGPT basiert. Denn obwohl ChatGPT manuell gekennzeichnete Daten hinzugefügt hat, sind es nur Zehntausende von Daten auf Token-Ebene, die zum Trainieren des GPT 3.5-Modells verwendet werden. Diese Datenmenge enthält weniger Weltwissen (Fakten in der Daten und gesunder Menschenverstand) können als ein Tropfen auf den heißen Stein bezeichnet werden, sind nahezu vernachlässigbar und werden im Grunde keine Rolle bei der Verbesserung der Grundfunktionen von GPT 3.5 spielen. Daher sollten seine leistungsstarken Funktionen hauptsächlich aus dem dahinter verborgenen GPT 3.5 stammen. GPT 3.5 bewertet das Riesenmodell unter den idealen LLM-Modellen. Fügt ChatGPT also neues Wissen in das GPT 3.5-Modell ein? Es sollte in Zehntausende manuell gekennzeichneter Daten eingefügt werden, aber was eingefügt wird, ist kein Weltwissen, sondern menschliches Präferenzwissen. Die sogenannte „menschliche Präferenz“ hat mehrere Bedeutungen: Erstens handelt es sich um eine für Menschen übliche Art und Weise, eine Aufgabe auszudrücken. Beispielsweise ist es üblich, dass Menschen sagen: „Übersetzen Sie den folgenden Satz aus dem Chinesischen ins Englische“, um den Bedarf an „maschineller Übersetzung“ auszudrücken. LLM ist jedoch kein Mensch. Wie kann es also verstehen, was dieser Satz bedeutet? Sie müssen einen Weg finden, LLM die Bedeutung dieses Befehls verständlich zu machen und ihn korrekt auszuführen. Daher fügt ChatGPT diese Art von Wissen durch manuelle Annotation von Daten in GPT 3.5 ein, wodurch es für LLM einfacher wird, menschliche Befehle zu verstehen. Dies ist der Schlüssel zu seiner „Empathie“. Zweitens haben Menschen ihre eigenen Standards dafür, was eine gute und was eine schlechte Antwort ist. Beispielsweise ist eine detailliertere Antwort gut, eine Antwort mit diskriminierendem Inhalt ist schlecht und so weiter. Dies ist die menschliche Präferenz für die Qualität der Antworten. Die Daten, die Menschen über das Belohnungsmodell an LLM zurückmelden, enthalten diese Art von Informationen. Insgesamt fügt ChatGPT menschliches Präferenzwissen in GPT 3.5 ein, um ein LLM zu erhalten, das menschliche Sprache versteht und höflicher ist. Es ist ersichtlich, dass der größte Beitrag von ChatGPT darin besteht, dass es im Grunde die Schnittstellenschicht des idealen LLM realisiert und es LLM ermöglicht, sich an die gewohnheitsmäßigen Befehlsausdrücke der Menschen anzupassen, anstatt die Menschen umgekehrt dazu zu bringen, sich an LLM anzupassen und sich den Kopf zu zerbrechen. Erstellen Sie einen Befehl, der funktionieren kann (das war es, was die Prompt-Technologie tat, bevor die Instruct-Technologie auf den Markt kam), und dies erhöht die Benutzerfreundlichkeit und Benutzererfahrung von LLM. Es war InstructGPT/ChatGPT, das dieses Problem zuerst erkannte und eine gute Lösung bereitstellte, was auch seinen größten technischen Beitrag darstellt. Im Vergleich zu den vorherigen Schussaufforderungen handelt es sich um eine Mensch-Computer-Schnittstellentechnologie, die den menschlichen Ausdrucksgewohnheiten für die Interaktion mit LLM besser entspricht. Und dies wird sicherlich zukünftige LLM-Modelle inspirieren und weiterhin an benutzerfreundlichen Mensch-Maschine-Schnittstellen arbeiten, um LLM gehorsamer zu machen. Auswirkung 2: Viele NLP-Unterbereiche haben keinen unabhängigen Forschungswert mehr Was den NLP-Bereich betrifft, bedeutet dieser Paradigmenwechsel, dass viele NLP-Forschungsbereiche, die derzeit unabhängig existieren, einbezogen werden Das technische System von LLM existiert nicht mehr unabhängig und verschwindet nach und nach. Nach dem ersten Paradigmenwechsel sind zwar viele „Zwischenaufgaben“ im NLP nicht mehr notwendig, um als eigenständige Forschungsfelder weiterzubestehen, die meisten „Endaufgaben“ bestehen jedoch immer noch als eigenständige Forschungsfelder, werden aber auf „Vorschulung“ umgestellt. . + Feinabstimmung“-Rahmen, angesichts einzigartiger Probleme in diesem Bereich wurden nacheinander neue Verbesserungspläne vorgeschlagen. Aktuelle Untersuchungen zeigen, dass bei vielen NLP-Aufgaben die Leistung mit zunehmender Größe des LLM-Modells erheblich verbessert wird. Daraus lässt sich meiner Meinung nach die folgende Schlussfolgerung ziehen: Die meisten sogenannten „einzigartigen“ Probleme in einem bestimmten Bereich sind höchstwahrscheinlich nur eine äußere Erscheinung, die durch mangelndes Domänenwissen verursacht wird, solange genügend Domänenwissen vorhanden ist Dieses sogenannte fachspezifische Problem lässt sich sehr gut lösen. Tatsächlich besteht keine Notwendigkeit, sich auf ein bestimmtes Fachgebietsproblem zu konzentrieren und hart daran zu arbeiten, eine spezielle Lösung zu finden. Vielleicht ist die Wahrheit über AGI überraschend einfach: Man gibt LLM einfach mehr Daten vor Ort und lässt es selbstständig mehr lernen. In diesem Zusammenhang beweist ChatGPT gleichzeitig, dass wir jetzt direkt das ideale LLM-Modell verfolgen können. Dann sollte der zukünftige Technologieentwicklungstrend lauten: Verfolgung immer größerer LLM-Modelle durch Erhöhung der Datenvielfalt vor dem Training. Um immer mehr Bereiche abzudecken, lernt LLM durch den Vortrainingsprozess autonom Domänenwissen aus Domänendaten. Da die Modellgröße weiter zunimmt, werden viele Probleme gelöst. Der Forschungsschwerpunkt liegt auf der Frage, wie dieses ideale LLM-Modell aufgebaut werden kann, und nicht auf der Lösung spezifischer Probleme in einem bestimmten Bereich. Auf diese Weise werden immer mehr Teilgebiete des NLP in das technische System des LLM aufgenommen und verschwinden nach und nach. Um zu beurteilen, ob unabhängige Forschung in einem bestimmten Bereich sofort gestoppt werden sollte, kann der Beurteilungsmaßstab eine der beiden folgenden Methoden sein: Erstens wird beurteilt, ob der Forschungseffekt von LLM auf eine bestimmte Aufgabe den des Menschen übersteigt Leistung: Für diejenigen Forschungsbereiche, in denen die Wirkung von LLM die des Menschen übersteigt, besteht kein Bedarf für unabhängige Forschung. Beispielsweise übersteigt der LLM-Effekt bei vielen Aufgaben in den GLUE- und SuperGLUE-Testsätzen derzeit die menschliche Leistungsfähigkeit. Tatsächlich besteht keine Notwendigkeit, dass Forschungsfelder, die eng mit diesem Datensatz verbunden sind, weiterhin unabhängig voneinander existieren. Zweitens vergleichen Sie die Aufgabeneffekte zweier Modi. Der erste Modus ist die Feinabstimmung mit größeren domänenspezifischen Daten, und der zweite Modus besteht aus wenigen Eingabeaufforderungen oder befehlsbasierten Methoden. Wenn die Wirkung der zweiten Methode die Wirkung der ersten Methode erreicht oder übertrifft, bedeutet dies, dass dieses Feld nicht weiterhin unabhängig existieren muss. Wenn dieser Standard tatsächlich in vielen Forschungsbereichen verwendet wird, ist der Effekt der Feinabstimmung immer noch dominant (aufgrund der großen Menge an Trainingsdaten in diesem Modusbereich), und es scheint, dass er unabhängig existieren kann. Wenn man jedoch bedenkt, dass bei vielen Aufgaben mit zunehmender Modellgröße die Wirkung weniger Schussaufforderungen weiter zunimmt. Mit dem Aufkommen größerer Modelle wird dieser Wendepunkt wahrscheinlich kurzfristig erreicht. Wenn die obige Spekulation wahr ist, bedeutet dies die folgende grausame Tatsache: Für viele Forscher im NLP-Bereich stehen sie vor der Wahl, wohin sie sich weiter mit Problemen befassen sollen, die für diesen Bereich einzigartig sind ? Oder sollten wir diesen scheinbar aussichtslosen Ansatz aufgeben und stattdessen ein besseres LLM aufbauen? Wenn wir uns für den Aufbau von LLM entscheiden, welche Institutionen haben die Fähigkeit und die Voraussetzungen dafür? Was würden Sie auf diese Frage antworten? Auswirkung 3: Weitere Forschungsfelder außer NLP werden in das LLM-Technologiesystem einbezogen. Wenn Sie aus der Perspektive von AGI stehen und sich auf das zuvor beschriebene ideale LLM-Modell und die Aufgaben beziehen, die es erfüllen kann Es sollte nicht auf den Bereich NLP oder einen oder zwei Fachbereiche beschränkt sein. Das ideale LLM sollte ein domänenunabhängiges allgemeines Modell der künstlichen Intelligenz sein. Es funktioniert in einem oder zwei Bereichen gut, aber das bedeutet nicht, dass es das kann Erledige nur diese Aufgaben. Das Aufkommen von ChatGPT beweist, dass es für uns in dieser Zeit möglich ist, AGI zu verfolgen, und jetzt ist es an der Zeit, die Fesseln des „Felddisziplin“-Denkens abzulegen. ChatGPT demonstriert nicht nur die Fähigkeit, verschiedene NLP-Aufgaben in einem fließenden Konversationsformat zu lösen, sondern verfügt auch über starke Programmierfähigkeiten. Es ist selbstverständlich, dass nach und nach immer mehr andere Forschungsbereiche in das LLM-System einbezogen werden und Teil der allgemeinen künstlichen Intelligenz werden. LLM erweitert sein Fachgebiet von NLP nach außen, und eine natürliche Wahl sind Bildverarbeitung und multimodale Aufgaben. Es gibt bereits einige Bemühungen, Multimodalität zu integrieren und LLM zu einer universellen Mensch-Computer-Schnittstelle zu machen, die multimodale Eingabe und Ausgabe unterstützt. Typische Beispiele sind DeepMinds Flamingo und Microsofts „Language Models are General-Purpose Interfaces“, wie oben gezeigt Vorgehensweise wird demonstriert. Mein Urteil ist, dass die zukünftige Integration in LLM, um nützliche Funktionen zu werden, langsamer sein könnte, als wir denken, egal ob es sich um Bilder oder um Multimodalität handelt. Der Hauptgrund dafür ist, dass das Bildfeld in den letzten zwei Jahren zwar Berts Pre-Training-Ansatz nachgeahmt hat, aber versucht, selbstüberwachtes Lernen einzuführen, um die Fähigkeit des Modells freizusetzen, selbstständig Wissen aus Bilddaten zu lernen. Typische Technologien sind „kontrastierend“. Lernen" und MAE. Dies sind zwei verschiedene technische Routen. Den aktuellen Ergebnissen zufolge scheint dieser Weg jedoch noch nicht abgeschlossen zu sein. Dies spiegelt sich in der Anwendung vorab trainierter Modelle im Bildbereich auf nachgelagerte Aufgaben wider, die weitaus weniger Vorteile bringen als Bert oder GPT. Es wird maßgeblich auf nachgelagerte NLP-Aufgaben angewendet. Daher müssen Bildvorverarbeitungsmodelle noch eingehend erforscht werden, um das Potenzial von Bilddaten auszuschöpfen, was ihre Vereinheitlichung in LLM-Großmodelle verzögern wird. Wenn dieser Weg eines Tages eröffnet wird, besteht natürlich eine hohe Wahrscheinlichkeit, dass sich die aktuelle Situation im Bereich NLP wiederholt, d. h. verschiedene Forschungsteilbereiche der Bildverarbeitung können nach und nach verschwinden und in groß angelegtes LLM integriert werden Terminalaufgaben direkt erledigen. Neben Bildern und Multimodalität ist es offensichtlich, dass nach und nach auch andere Bereiche in das ideale LLM einbezogen werden. Diese Richtung ist im Aufwind und ein hochwertiges Forschungsthema. Das Obige sind meine persönlichen Gedanken zum Paradigmenwechsel. Als nächstes wollen wir uns mit dem Mainstream-Technologiefortschritt der LLM-Modelle nach GPT 3.0 befassen. Wie das ideale LLM-Modell zeigt, können verwandte Technologien tatsächlich in zwei Hauptkategorien unterteilt werden. Die erste Kategorie befasst sich mit der Art und Weise, wie das LLM-Modell Wissen aus Daten absorbiert. In der zweiten Kategorie geht es auch um die Auswirkungen des Modellgrößenwachstums auf die Fähigkeit des LLM, Wissen zu absorbieren ist eine Mensch-Computer-Schnittstelle, die zeigt, wie Menschen die inhärenten Fähigkeiten von LLM nutzen, um Aufgaben zu lösen, einschließlich der Modi „In Context Learning“ und „Instruct“. Chain of Thought (CoT)-Prompting, eine LLM-Argumentationstechnologie, gehört im Wesentlichen zum In-Context-Lernen. Da sie wichtiger sind, werde ich gesondert darauf eingehen. Lernende: Von endlosen Daten zu massivem Wissen Weg des Wissens: Welches Wissen hat LLM gelernt? LLM hat viel Wissen aus massiven Freitexten gelernt. Wenn man dieses Wissen grob einteilt, kann man es in . . Es gibt eine lange Forschungsgeschichte darüber, ob LLM linguistisches Wissen erfassen kann. Seit der Entstehung von Bert wurde die entsprechende Forschung fortgesetzt, und verschiedene Experimente haben vollständig bewiesen, dass LLM unterschiedliche Ebenen von linguistischem Wissen erlernen kann Aus diesem Grund wird es nach dem Vortraining des Modells verwendet. Einer der wichtigsten Gründe ist, dass bei verschiedenen Sprachverständnisaufgaben in natürlicher Sprache erhebliche Leistungsverbesserungen erzielt wurden. Darüber hinaus haben verschiedene Studien auch gezeigt, dass flaches Sprachwissen wie Morphologie, Wortarten, Syntax und anderes Wissen in den Low-Level- und Middle-Level-Strukturen von Transformer gespeichert sind, während abstraktes Sprachwissen wie semantisches Wissen weit verbreitet ist in den mittleren und oberen Strukturen von Transformer. . Zum Beispiel „Biden ist der derzeitige Präsident der Vereinigten Staaten“, „Biden ist ein Amerikaner“, „Der ukrainische Präsident Selenskyj traf sich mit US-Präsident Biden“, das sind Faktenwissen im Zusammenhang mit Biden und „Menschen haben zwei Augen“ und „; „Die Sonne geht im Osten auf“ ist eine Erkenntnis des gesunden Menschenverstandes. Es gibt viele Studien darüber, ob das LLM-Modell Weltwissen lernen kann, und die Schlussfolgerungen sind relativ konsistent: LLM absorbiert tatsächlich eine große Menge Weltwissen aus den Trainingsdaten, und dieses Wissen ist hauptsächlich in der mittleren und oberen Schicht verteilt Transformator, besonders konzentriert in der Mittelschicht. Darüber hinaus nimmt mit zunehmender Tiefe des Transformer-Modells die Menge an Wissen, die erlernt werden kann, schrittweise exponentiell zu (siehe: BERTnesia: Untersuchung des Erfassens und Vergessens von Wissen in BERT). Tatsächlich betrachten Sie LLM als einen impliziten Wissensgraphen, der sich in Modellparametern widerspiegelt. Wenn Sie es so verstehen, gibt es meiner Meinung nach überhaupt kein Problem. „Wann benötigen Sie Milliarden von Wörtern an Pre-Training-Daten?“ Dieser Artikel untersucht die Beziehung zwischen der Menge des durch das Pre-Training-Modell erlernten Wissens und der Menge der Trainingsdaten. Seine Schlussfolgerung lautet: für Bert-Typ-Sprache Mithilfe von Modellen können Sie linguistisches Wissen wie Syntax und Semantik gut mit nur 10 bis 100 Millionen Korpuswörtern erlernen, aber um Faktenwissen zu erlernen, benötigen Sie mehr Trainingsdaten. Diese Schlussfolgerung ist tatsächlich zu erwarten, schließlich ist das sprachliche Wissen relativ begrenzt und statisch, während das Faktenwissen riesig ist und sich ständig verändert. Aktuelle Untersuchungen haben gezeigt, dass das vorab trainierte Modell mit zunehmender Menge an Trainingsdaten bei verschiedenen nachgelagerten Aufgaben eine bessere Leistung erbringt, was zeigt, dass es sich bei dem, was aus den inkrementellen Trainingsdaten gelernt wird, hauptsächlich um Weltwissen handelt. Speicherort: Wie LLM Wissen speichert und abruft Aus dem oben Gesagten ist ersichtlich, dass LLM tatsächlich viel Sprach- und Weltwissen aus den Daten gelernt hat. Wo speichert LLM ein bestimmtes Wissen? Wie wird es extrahiert? Das ist auch eine interessante Frage. Natürlich muss das Wissen in den Modellparametern von Transformer gespeichert werden. Der Struktur von Transformer nach zu urteilen, bestehen die Modellparameter aus zwei Teilen: Der MHA-Teil (Multi-Head Attention) macht etwa ein Drittel der Gesamtparameter aus, und zwei Drittel der Parameter sind in der FFN-Struktur konzentriert. MHA wird hauptsächlich zur Berechnung der Korrelationsstärke zwischen Wörtern oder Wissen und zur Integration globaler Informationen verwendet. Es ist wahrscheinlicher, dass bestimmte Wissenspunkte nicht gespeichert werden, sodass der Wissenskörper leicht abgeleitet werden kann des LLM-Modells ist in der FFN-Struktur von Transformer gespeichert. Die Granularität dieser Positionierung ist jedoch immer noch zu grob und es ist unmöglich, genau zu beantworten, wie ein bestimmtes Wissen gespeichert und abgerufen wird Ein Teil des Wissens wird in Tripeln ausgedrückt, wobei „is-capital-of“ die Beziehung zwischen Entitäten darstellt. Wo ist dieses Wissen im LLM gespeichert? „Transformer Feed-Forward Layers Are Key-Value Memories“ bietet eine relativ neue Perspektive, die Transformers FFN als einen Schlüsselwertspeicher betrachtet, der eine große Menge an spezifischem Wissen speichert. Wie in der Abbildung oben gezeigt (die linke Seite der Abbildung ist die ursprüngliche Papierfigur, die eigentlich nicht leicht zu verstehen ist, können Sie sich zum besseren Verständnis die mit Anmerkungen versehene rechte Abbildung ansehen), ist die erste Schicht von FFN eine MLP-Breite Die verborgene Schicht ist die Schlüsselschicht. Die zweite Schicht ist die schmale verborgene Schicht von MLP und die Wertschicht. Die Eingabeschicht von FFN ist eigentlich die Ausgabeeinbettung des MHA, die einem bestimmten Wort entspricht. Dies ist die Einbettung, die den Eingabekontext in Bezug auf den gesamten Satz durch Selbstaufmerksamkeit integriert, was die Gesamtinformationen des gesamten Eingabesatzes darstellt. Key-Schicht zeichnet ein Paar -Informationen auf. Beispielsweise zeichnet er für den Es mag immer noch kompliziert klingen, also lassen Sie uns zur Veranschaulichung ein extremes Beispiel verwenden. Wir gehen davon aus, dass der Knoten In diesem Artikel wurde auch darauf hingewiesen, dass der Low-Level-Transformer auf das Oberflächenmuster des Satzes und der High-Level-Transformer auf das semantische Muster reagiert. Das heißt, der Low-Level-FFN speichert Oberflächenwissen wie z B. Lexikon und Syntax, und die mittlere und obere Ebene speichern semantisches und sachliches Konzeptwissen. Dies steht im Einklang mit anderen Forschungsergebnissen. Ich würde vermuten, dass die Behandlung von FFN als Schlüsselwertspeicher wahrscheinlich nicht die endgültige richtige Antwort ist, aber es ist wahrscheinlich nicht allzu weit von der endgültigen richtigen Antwort entfernt. Wissenskorrekturflüssigkeit: So korrigieren Sie das in LLM gespeicherte Wissen Da wir wissen, dass ein bestimmtes Stück Weltwissen in den Parametern eines oder mehrerer FFN-Knoten gespeichert ist, stellt sich natürlich eine weitere Frage: Können wir im LLM-Modell gespeicherte Fehler oder veraltetes Wissen korrigieren? Zum Beispiel bezüglich der Frage: „Wer ist der derzeitige Premierminister des Vereinigten Königreichs?“ Glauben Sie, dass LLM angesichts der häufigen Wechsel der britischen Premierminister in den letzten Jahren eher dazu neigt, „Boris“ oder „Sunak“ zu exportieren? Offensichtlich wird es in den Trainingsdaten mehr Daten geben, die „Boris“ enthalten. In diesem Fall ist es sehr wahrscheinlich, dass LLM eine falsche Antwort gibt, sodass wir das veraltete Wissen, das in LLM gespeichert ist, korrigieren müssen. Zusammengefasst gibt es derzeit drei verschiedene Methoden, um das im LLM enthaltene Wissen zu korrigieren: Der erste Methodentyp korrigiert das Wissen aus der Quelle der Trainingsdaten. „Auf dem Weg zur Rückverfolgung von Faktenwissen in Sprachmodellen auf die Trainingsdaten“ Das Forschungsziel dieses Artikels ist: Können wir für ein bestimmtes Wissen feststellen, welche Trainingsdaten dazu geführt haben, dass LLM dieses Wissen gelernt hat? Die Antwort lautet „Ja“, was bedeutet, dass wir die Quelle der Trainingsdaten, die einem bestimmten Wissen entsprechen, rückwärts verfolgen können. Wenn wir diese Technologie verwenden und davon ausgehen, dass wir ein bestimmtes Wissen löschen möchten, können wir zunächst die entsprechende Datenquelle lokalisieren, die Datenquelle löschen und dann das gesamte LLM-Modell erneut trainieren. Dadurch kann der Zweck erreicht werden, relevantes Wissen zu löschen im LLM. Hier gibt es jedoch ein Problem. Wenn wir einen kleinen Teil des Wissens korrigieren, müssen wir das Modell neu trainieren, was offensichtlich zu kostspielig ist. Daher bietet diese Methode keine großen Entwicklungschancen. Sie eignet sich möglicherweise besser für die einmalige Löschung einer bestimmten Datenkategorie. Für eine kleine Anzahl regelmäßiger Wissenskorrekturszenarien ist sie möglicherweise nicht geeignet besser zum Entfernen von Vorurteilen geeignet sein. Warten Sie, bis der giftige Inhalt entfernt ist. Die zweite Art von Methode besteht darin, eine Feinabstimmung am LLM-Modell vorzunehmen, um das Wissen zu korrigieren . Eine intuitive Methode, die man sich vorstellen kann, ist: Wir können Trainingsdaten basierend auf dem neuen Wissen erstellen, das geändert werden soll, und dann das LLM-Modell eine Feinabstimmung dieser Trainingsdaten durchführen lassen, um so das LLM dazu zu bringen, sich an das neue Wissen zu erinnern und es zu vergessen das alte Wissen. Diese Methode ist einfach und intuitiv, bringt aber auch einige Probleme mit sich. Erstens führt sie zum Problem des Katastrophenvergessens, was bedeutet, dass nicht nur das Wissen vergessen wird, das vergessen werden sollte, sondern auch das Wissen, das nicht vergessen werden sollte vergessen werden, was dazu führt, dass die Effektivität einiger nachgelagerter Aufgaben danach abnimmt. Da das aktuelle LLM-Modell außerdem sehr umfangreich ist, sind die Kosten selbst bei häufiger Feinabstimmung tatsächlich recht hoch. Wer sich für diese Methode interessiert, kann sich auf „Modifying Memories in Transformer Models“ beziehen. Eine andere Art von Methode modifiziert direkt die Modellparameter, die bestimmten Kenntnissen in LLM entsprechen, um das Wissen zu korrigieren . Angenommen, wir möchten das alte Wissen zu überarbeiten. Zuerst finden wir eine Möglichkeit, den FFN-Knoten zu lokalisieren, der altes Wissen in den LLM-Modellparametern speichert, und dann können wir die entsprechenden Modellparameter in FFN zwangsweise anpassen und ändern, um das alte Wissen durch neues Wissen zu ersetzen. Es ist ersichtlich, dass diese Methode zwei Schlüsseltechnologien umfasst: Erstens, wie der spezifische Speicherort eines bestimmten Wissens im LLM-Parameterraum lokalisiert wird, und zweitens, wie die Modellparameter korrigiert werden, um die Korrektur von altem Wissen durch neues zu erreichen Wissen. Einzelheiten zu dieser Art von Technologie finden Sie unter „Suchen und Bearbeiten von Sachzusammenhängen in GPT“ und „Massenbearbeitung von Speicher in einem Transformer“. Das Verständnis dieses Prozesses der Wiederholung von LLM-Wissen ist tatsächlich sehr hilfreich für ein tieferes Verständnis der inneren Funktionsweise von LLM. Wir wissen, dass der Umfang der LLM-Modelle in den letzten Jahren schnell zugenommen hat und die meisten der derzeit leistungsstärksten LLM-Modelle Parametergrößen von mehr als 100 Milliarden (100 Milliarden) haben ) Parameter. Beispielsweise beträgt die Größe von GPT 3 von OpenAI 175 B, die Größe von Googles LaMDA beträgt 137 B, die Größe von PaLM beträgt 540 B, die Größe von DeepMinds Gogher beträgt 280 B und so weiter. Es gibt auch chinesische Riesenmodelle in China, wie Zhiyuan GLM mit einem Maßstab von 130B, Huawei „Pangu“ mit einem Maßstab von 200B, Baidu „Wenxin“ mit einem Maßstab von 260B und Inspur „Yuan 1.0“ mit einem Maßstab von 245B . Daher stellt sich natürlich die Frage: Was passiert, wenn die Größe der LLM-Modelle weiter zunimmt? Die Anwendung vorab trainierter Modelle wird häufig in zwei Phasen unterteilt: die Phase vor dem Training und die Phase der spezifischen Szenarioanwendung. In der Vortrainingsphase ist das Optimierungsziel die Kreuzentropie. Bei autoregressiven Sprachmodellen wie GPT kommt es darauf an, ob das LLM das nächste Wort korrekt vorhersagt, während es in der Szenarioanwendungsphase im Allgemeinen von den Bewertungsindikatoren abhängt spezifisches Szenario. Im Allgemeinen ist unsere Intuition: Wenn das LLM-Modell in der Vortrainingsphase bessere Indikatoren aufweist, ist seine Fähigkeit, nachgelagerte Aufgaben zu lösen, natürlich stärker. Dies ist jedoch nicht ganz richtig. Vorhandene Untersuchungen haben gezeigt, dass der Optimierungsindex in der Vortrainingsphase zwar eine positive Korrelation mit nachgelagerten Aufgaben aufweist, diese ist jedoch nicht vollständig positiv. Mit anderen Worten: Es reicht nicht aus, nur die Indikatoren in der Phase vor dem Training zu betrachten, um zu beurteilen, ob ein LLM-Modell gut genug ist. Auf dieser Grundlage werden wir diese beiden verschiedenen Phasen getrennt betrachten, um zu sehen, welche Auswirkungen die Weiterentwicklung des LLM-Modells haben wird. Schauen wir uns zunächst an, was passiert, wenn die Modellgröße in der Vortrainingsphase allmählich zunimmt. OpenAI untersuchte dieses Problem speziell in „Skalierungsgesetze für neuronale Sprachmodelle“ und schlug das „Skalierungsgesetz“ vor, dem das LLM-Modell folgt. Wie in der Abbildung oben gezeigt, beweist diese Studie: Wenn wir die Menge an Trainingsdaten, die Modellparametergröße unabhängig erhöhen oder die Modelltrainingszeit verlängern (z. B. von 1 Epoche auf 2 Epoche), geht der Verlust der Vor- Das trainierte Modell auf dem Testsatz wird monoton reduziert, das heißt, der Modelleffekt wird immer besser. Da alle drei Faktoren wichtig sind, haben wir bei der eigentlichen Vorschulung ein Entscheidungsproblem bei der Zuteilung der Rechenleistung: Nehmen wir das gesamte Rechenleistungsbudget an, das zum Trainieren von LLM verwendet wird (z. B. wie viele GPU-Stunden). Sollten wir angesichts der gegebenen Anzahl an GPU-Tagen die Datenmenge erhöhen und die Modellparameter reduzieren? Oder sollten gleichzeitig die Datenmenge und die Modellgröße zunehmen und die Anzahl der Trainingsschritte sinken? Wenn die Größe eines Faktors zunimmt, muss die Größe anderer Faktoren verringert werden, um die Gesamtrechenleistung unverändert zu lassen. Daher gibt es verschiedene mögliche Pläne für die Zuteilung der Rechenleistung. Am Ende entschied sich OpenAI dafür, die Menge an Trainingsdaten und Modellparametern gleichzeitig zu erhöhen, nutzte jedoch eine frühe Stoppstrategie, um die Anzahl der Trainingsschritte zu reduzieren. Denn es beweist: Für die beiden Elemente Trainingsdatenvolumen und Modellparameter ist es nicht die beste Wahl, beide gleichzeitig entsprechend einem bestimmten Verhältnis zu erhöhen Die Schlussfolgerung besteht darin, der Erhöhung der Modellparameter und dann der Menge der Trainingsdaten Vorrang einzuräumen. Unter der Annahme, dass sich das gesamte Rechenleistungsbudget für das Training von LLM um das Zehnfache erhöht, sollte die Menge an Modellparametern um das 5,5-fache und die Menge an Trainingsdaten um das 1,8-fache erhöht werden. Zu diesem Zeitpunkt ist der Modelleffekt am besten. Eine Studie von DeepMind (Referenz: Training Compute-Optimal Large Language Models) untersuchte dieses Thema eingehender. Ihre grundlegenden Schlussfolgerungen ähneln denen von OpenAI. Beispielsweise ist es tatsächlich notwendig, die Menge an Trainingsdaten zu erhöhen Modellparameter gleichzeitig Der Modelleffekt wird besser sein. Viele große Modelle berücksichtigen dies beim Vortraining nicht. Viele große LLM-Modelle erhöhen lediglich monoton die Modellparameter und legen gleichzeitig die Menge der Trainingsdaten fest. Dieser Ansatz ist tatsächlich falsch und schränkt das Potenzial des LLM-Modells ein. Es korrigiert jedoch die proportionale Beziehung zwischen den beiden und geht davon aus, dass die Menge an Trainingsdaten und Modellparametern gleichermaßen wichtig ist. Mit anderen Worten: Unter der Annahme, dass das gesamte Rechenleistungsbudget, das zum Trainieren von LLM verwendet wird, um das Zehnfache zunimmt, erhöht sich die Menge an Modellparametern Damit das Modell den besten Effekt erzielt, sollte es um das 3,3-fache erhöht werden. Das bedeutet: Die Bedeutung der Erhöhung der Menge an Trainingsdaten ist wichtiger, als wir bisher dachten . Basierend auf diesem Verständnis wählte DeepMind beim Entwurf des Chinchilla-Modells eine andere Konfiguration hinsichtlich der Rechenleistungszuteilung: Im Vergleich zum Gopher-Modell mit einem Datenvolumen von 300 B und einem Modellparametervolumen von 280 B entschied sich Chinchilla dafür, die Trainingsdaten um das Vierfache zu erhöhen , aber das Modell reduziert Die Parameter werden auf ein Viertel der von Gopher reduziert, was etwa 70B entspricht. Unabhängig von Indikatoren vor dem Training oder vielen Indikatoren für nachgelagerte Aufgaben ist Chinchilla jedoch besser als der größere Gopher. Das bringt uns zu folgender Erleuchtung: Wir können uns dafür entscheiden, die Trainingsdaten zu vergrößern und die LLM-Modellparameter im gleichen Verhältnis zu reduzieren zu erreichen Der Zweck besteht darin, die Größe des Modells erheblich zu reduzieren, ohne den Modelleffekt zu verringern. Die Reduzierung der Modellgröße hat viele Vorteile, beispielsweise ist die Inferenzgeschwindigkeit bei der Anwendung viel schneller. Dies ist zweifellos ein vielversprechender LLM-Entwicklungsweg.
Der erste Aufgabentyp spiegelt perfekt das Skalierungsgesetz des LLM-Modells wider Dies bedeutet, dass mit zunehmender Vergrößerung des Modellmaßstabs die Leistung der Aufgabe immer besser wird, wie in (a) oben gezeigt. Solche Aufgaben erfüllen in der Regel die folgenden gemeinsamen Merkmale: Es handelt sich häufig um wissensintensive Aufgaben, was bedeutet, dass die Leistung solcher Aufgaben umso besser ist, je mehr Wissen das LLM-Modell enthält. Viele Studien haben gezeigt, dass die Lerneffizienz umso höher ist, je größer das Modell ist. Dies zeigt, dass die Wirkung der Aufgabe umso besser ist Bei einem Batch von Trainingsdaten ist ein größeres LLM-Modell relativ effizienter. Ein kleineres Modell, aus dem mehr Wissen gelernt wird. Darüber hinaus nimmt unter normalen Umständen bei einer Erhöhung der LLM-Modellparameter häufig gleichzeitig die Menge der Trainingsdaten zu, was bedeutet, dass große Modelle mehr Wissenspunkte aus mehr Daten lernen können. Diese Studien können die obige Abbildung gut erklären, warum diese wissensintensiven Aufgaben mit zunehmender Modellgröße immer besser werden. Die meisten traditionellen Aufgaben zum Verstehen natürlicher Sprache sind tatsächlich solche wissensintensiven Aufgaben, und bei vielen Aufgaben wurden in den letzten zwei Jahren große Verbesserungen erzielt, die sogar die menschliche Leistung übertreffen. Offensichtlich liegt dies höchstwahrscheinlich an der Vergrößerung des Maßstabs des LLM-Modells und nicht an einer spezifischen technischen Verbesserung. Der zweite Aufgabentyp zeigt, dass LLM über eine Art „Emergent Ability“ verfügt, wie in (b) oben gezeigt „Jenseits des Imitationsspiels: Quantifizierung und Extrapolation der Fähigkeiten von Sprachmodellen“ In diesem Artikel wird darauf hingewiesen, dass diese Art von Aufgaben, die „aufkommende Fähigkeiten“ widerspiegeln, auch einige Gemeinsamkeiten aufweisen : Diese Aufgaben bestehen im Allgemeinen aus mehreren Schritten. Um diese Aufgaben zu lösen, müssen häufig zunächst mehrere Zwischenschritte gelöst werden. Bei der endgültigen Lösung solcher Aufgaben spielt die Fähigkeit zum logischen Denken eine wichtige Rolle. Chain of Thought Prompting ist eine typische Technologie, die die LLM-Denkfähigkeiten verbessert und die Leistung solcher Aufgaben erheblich verbessern kann. Die CoT-Technologie wird in den folgenden Abschnitten erläutert und hier nicht besprochen. Die Frage ist, warum es in LLM dieses Phänomen der „emergenten Fähigkeit“ gibt? Der obige Artikel und „Emergent Abilities of Large Language Models“ geben mehrere mögliche Erklärungen: Eine mögliche Erklärung ist, dass die Bewertungsindikatoren einiger Aufgaben nicht glatt genug sind. Einige Beurteilungsstandards für Generierungsaufgaben erfordern beispielsweise, dass die vom Modell ausgegebene Zeichenfolge vollständig mit der Standardantwort übereinstimmen muss, um als richtig zu gelten. Andernfalls wird sie mit 0 Punkten bewertet. Selbst wenn das Modell zunimmt, wird seine Wirkung allmählich besser, was sich in der Ausgabe korrekterer Zeichenfragmente widerspiegelt. Da es jedoch nicht vollständig korrekt ist, werden nur dann 0 Punkte vergeben, wenn das Modell korrekt ist Wenn der Wert groß genug ist, werden die Ausgabewerte bewertet, wenn alle Segmente korrekt sind. Mit anderen Worten: Da der Indikator nicht glatt genug ist, kann er nicht die Realität widerspiegeln, dass LLM die Aufgabenleistung tatsächlich schrittweise verbessert. Es scheint die äußere Manifestation einer „aufkommenden Fähigkeit“ zu sein. Eine andere mögliche Erklärung ist: Mit zunehmender Modellgröße steigt die Fähigkeit, jeden Schritt zu lösen, aber solange ein Zwischenschritt falsch ist, ist die endgültige Antwort falsch es wird auch zu diesem oberflächlichen Phänomen der „emergenten Fähigkeit“ führen. Natürlich handelt es sich bei den oben genannten Erklärungen immer noch um Vermutungen, weshalb es bei LLM zu diesem Phänomen kommt. Weitere und eingehendere Untersuchungen sind erforderlich. Es gibt auch eine kleine Anzahl von Aufgaben. Mit zunehmendem Modellmaßstab zeigt die Wirkungskurve der Aufgabe eine U-förmige Charakteristik: Mit zunehmendem Modellmaßstab nimmt die Aufgabe zu Der Effekt wird allmählich schlechter, aber wenn die Modellskala weiter zunimmt, wird der Effekt immer besser und zeigt einen U-förmigen Wachstumstrend, wie in der Abbildung oben gezeigt, dem Indikatortrend des rosa PaLM-Modells für die beiden Aufgaben. Warum erscheinen diese Aufgaben so besonders? „Inverse Skalierung kann U-förmig werden“ Dieser Artikel gibt eine Erklärung: Diese Aufgaben enthalten tatsächlich zwei verschiedene Arten von Unteraufgaben, eine ist die eigentliche Aufgabe und die andere ist die „Interferenzaufgabe (Distraktoraufgabe)“. Wenn das Modell klein ist, kann es keine Unteraufgabe identifizieren, daher ähnelt die Leistung des Modells der zufälligen Auswahl von Antworten. Wenn das Modell auf eine mittlere Größe anwächst, führt es hauptsächlich Interferenzaufgaben aus, was sich negativ auf die Größe auswirkt Die tatsächliche Aufgabenleistung spiegelt sich in der Abnahme des tatsächlichen Aufgabeneffekts wider. Wenn die Modellgröße weiter erhöht wird, kann LLM die störenden Aufgaben ignorieren und die tatsächliche Aufgabe ausführen, was sich darin widerspiegelt, dass der Effekt zunimmt. Mensch-Computer-Schnittstelle: Vom kontextbezogenen Lernen zum Unterrichtsverständnis Unter anderem ist Instruct die Schnittstellenmethode von ChatGPT, was bedeutet, dass Menschen eine Beschreibung der Aufgabe in natürlicher Sprache geben, wie zum Beispiel „Übersetze diesen Satz vom Chinesischen ins Englische“, etwa so. Ich verstehe, dass Zero-Shot-Eingabeaufforderung tatsächlich der frühe Name des aktuellen Instruct ist. Früher nannten die Leute es Zero-Shot, aber jetzt nennen es viele Leute Instruct. Obwohl es die gleiche Konnotation hat, gibt es zwei spezifische Methoden. In den frühen Tagen, als die Leute Null-Schuss-Aufforderungen durchführten, wussten sie eigentlich nicht, wie sie eine Aufgabe ausdrücken sollten, also änderten sie verschiedene Wörter oder Sätze und versuchten wiederholt, die Aufgabe gut auszudrücken. Dieser Ansatz hat sich als gut geeignet erwiesen Die Verteilung von Trainingsdaten ist eigentlich bedeutungslos. Der aktuelle Ansatz von Instruct besteht darin, eine Befehlsanweisung zu geben und zu versuchen, LLM diese verständlich zu machen. Obwohl sie alle oberflächlich betrachtet Ausdruck von Aufgaben sind, sind die Ideen doch unterschiedlich. Und „In Context Learning“ hat eine ähnliche Bedeutung wie „Fewly Shot Prompting“, das heißt, LLM ein paar Beispiele als Vorlage zu geben und LLM dann neue Probleme lösen zu lassen. Ich persönlich denke, dass In Context Learning auch als Beschreibung einer bestimmten Aufgabe verstanden werden kann, Instruct ist jedoch eine abstrakte Beschreibungsmethode und In Context Learning ist eine Beispielmethode zur Veranschaulichung. Da diese Begriffe derzeit etwas verwirrend verwendet werden, spiegelt das obige Verständnis natürlich nur meine persönliche Meinung wider. Daher führen wir hier nur das Lernen im Kontext und das Unterweisen ein und erwähnen nicht mehr „Zero Shot“ und „Wenig Shot“. Mysteriöses Lernen im Kontext Wenn Sie sorgfältig darüber nachdenken, werden Sie feststellen, dass In-Context-Lernen eine sehr magische Technologie ist. Was ist daran so magisch? Der Zauber besteht darin, dass, wenn Sie LLM mehrere Beispielbeispiele Fine-Tuning und In-Context-Learning scheinen beide einige Beispiele für LLM zu liefern, unterscheiden sich jedoch qualitativ (siehe Bild oben): Fine-Tuning verwendet diese Beispiele als Trainingsdaten Ändern Sie die Modellparameter von LLM mithilfe von Backpropagation, und die Aktion zum Ändern der Modellparameter spiegelt tatsächlich den Prozess des LLM-Lernens aus diesen Beispielen wider. Allerdings hat In Context Learning nur Beispiele für LLM zum Anschauen herausgenommen und die Parameter des LLM-Modells nicht mithilfe von Backpropagation auf der Grundlage der Beispiele geändert, sondern es gebeten, neue Beispiele vorherzusagen. Da die Modellparameter nicht geändert werden, bedeutet dies, dass LLM anscheinend keinen Lernprozess durchlaufen hat. Wenn es keinen Lernprozess durchlaufen hat, warum kann es dann neue Beispiele allein durch Betrachten vorhersagen? Das ist die Magie des kontextbezogenen Lernens. Erinnert Sie das an einen Text: „Nur weil ich dich noch einmal in der Menge angesehen habe, kann ich dein Gesicht nie wieder vergessen.“ Der Song heißt „Legend“. Sagen Sie, dass es legendär ist oder nicht? Es scheint, dass In-Context-Learning nicht Wissen aus Beispielen lernt. Lernt LLM tatsächlich auf seltsame Weise? Oder stimmt es, dass es nichts gelernt hat? Die Antwort auf diese Frage ist immer noch ein ungelöstes Rätsel. Einige bestehende Studien vertreten unterschiedliche Meinungen und sind so unterschiedlich, dass es schwierig ist zu beurteilen, welche davon die Wahrheit sagt. Einige Forschungsergebnisse sind sogar widersprüchlich. Hier sind einige aktuelle Meinungen darüber, wer Recht hat und wer Unrecht hat. Das können Sie nur selbst entscheiden. Natürlich denke ich, dass die Suche nach der Wahrheit hinter diesem magischen Phänomen ein gutes Forschungsthema ist. Ein Versuch zu beweisen, dass In-Context Learning nicht aus Beispielen lernt, ist „Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?“. Es wurde festgestellt: In dem Beispielbeispiel Was wirklich einen größeren Einfluss auf das In-Context-Lernen hat, ist: die Verteilung von Kurz gesagt, diese Arbeit beweist, dass In Context Learning nicht die Zuordnungsfunktion lernt, sondern die Verteilung von Eingabe und Ausgabe sehr wichtig ist und diese beiden nicht zufällig geändert werden können. Einige Arbeiten gehen davon aus, dass LLM diese Zuordnungsfunktion immer noch aus den angegebenen Beispielen lernt Alles in allem ist dies immer noch ein ungelöstes Rätsel. Magisches Instruct Understanding Wir können Instruct als eine Aufgabenstellung betrachten, die für Menschen leicht zu verstehen ist. Unter dieser Prämisse kann die aktuelle Forschung zu Instruct in zwei Arten unterteilt werden: Instruct, was mehr ist akademische Forschung und eine Anleitung zur Beschreibung realer menschlicher Bedürfnisse. Werfen wir zunächst einen Blick auf den ersten Typ: Derjenige, bei dem es sich eher um akademische Forschung handelt Unterweisen. Sein zentrales Forschungsthema ist die Verallgemeinerungsfähigkeit des LLM-Modells, um Instruct in Multitasking-Szenarien zu verstehen. Wie im FLAN-Modell in der Abbildung oben gezeigt, gibt es viele NLP-Aufgaben. Für jede Aufgabe erstellen die Forscher eine oder mehrere Eingabeaufforderungsvorlagen als Anweisung der Aufgabe und verwenden dann Trainingsbeispiele zur Feinabstimmung das LLM-Modell, sodass LLM mehrere Aufgaben gleichzeitig erlernen kann. Geben Sie dem LLM-Modell nach dem Training eine Anweisung für eine brandneue Aufgabe, die es noch nie zuvor gesehen hat, und lassen Sie LLM dann die Null-Schuss-Aufgabe lösen. Ob die Aufgabe gut genug gelöst ist, kann verwendet werden, um zu beurteilen, ob das LLM-Modell funktioniert verfügt über die Verallgemeinerungsfähigkeit, um die Anweisung zu verstehen. Wenn Sie die aktuellen Forschungsergebnisse zusammenfassen (siehe „Skalierungsanweisungen – fein abgestimmte Sprachmodelle“/„Super-NaturalInstructions: Generalisierung über deklarative Anweisungen für über 1600 NLP-Aufgaben“), können Sie die Generalisierung effektiv steigern Zu den Fähigkeitsfaktoren des LLM-Modells Instruct gehören: Erhöhung der Anzahl von Multitasking-Aufgaben, Erhöhung der Größe des LLM-Modells, Bereitstellung von CoT-Eingabeaufforderung und Erhöhung der Aufgabenvielfalt. Wenn eine dieser Maßnahmen ergriffen wird, kann das Lehrverständnis des LLM-Modells verbessert werden. Der zweite Typ ist Auf der Grundlage echter menschlicher Bedürfnisse unterrichten. Diese Art der Forschung wird durch InstructGPT und ChatGPT repräsentiert. Auch diese Art der Arbeit basiert auf Multitasking, der größte Unterschied zur akademischen forschungsorientierten Arbeit besteht jedoch darin, dass sie sich an den realen Bedürfnissen menschlicher Nutzer orientiert. Warum sagst du das? Weil die Eingabeaufforderungen zur Aufgabenbeschreibung, die sie für das LLM-Multitasking-Training verwenden, aus echten Anfragen einer großen Anzahl von Benutzern stammen, anstatt den Umfang der Forschungsaufgabe festzulegen und die Forscher dann die Eingabeaufforderungen zur Aufgabenbeschreibung schreiben zu lassen. Die sogenannten „echten Bedürfnisse“ spiegeln sich hier in zwei Aspekten wider: Erstens sind die abgedeckten Aufgabentypen vielfältiger und entsprechen zweitens eher den tatsächlichen Bedürfnissen der Benutzer, da sie zufällig aus den von den Benutzern eingereichten Aufgabenbeschreibungen ausgewählt werden , Eine bestimmte Beschreibung einer Aufgabe wird vom Benutzer übermittelt und spiegelt wider, was der durchschnittliche Benutzer sagen würde, wenn er Aufgabenanforderungen äußert, und nicht das, was der Benutzer Ihrer Meinung nach sagen würde. Offensichtlich wird die Benutzererfahrung des LLM-Modells, die durch diese Art von Arbeit verbessert wird, besser sein. InstructGPT In der Arbeit wurde diese Methode auch mit der Instruct-basierten Methode von FLAN verglichen. Verwenden Sie zunächst die in FLAN erwähnten Aufgaben, Daten und Eingabeaufforderungsvorlagen, um die FLAN-Methode auf GPT 3 zu reproduzieren, und vergleichen Sie sie dann mit InstructGPT. Da das Grundmodell von InstructGPT ebenfalls GPT3 ist, gibt es nur Unterschiede Daten und Methoden sind vergleichbar und es zeigt sich, dass die Wirkung der FLAN-Methode weit hinter InstructGPT zurückbleibt. Was ist also der Grund dafür? Nach der Analyse der Daten geht das Papier davon aus, dass die FLAN-Methode relativ wenige Aufgabenfelder umfasst und eine Teilmenge der in InstructGPT beteiligten Felder darstellt, sodass der Effekt nicht gut ist. Mit anderen Worten: Die im FLAN-Papier enthaltenen Aufgaben stimmen nicht mit den tatsächlichen Bedürfnissen der Benutzer überein, was zu unzureichenden Ergebnissen in realen Szenarien führt. Für uns bedeutet dies, dass es wichtig ist, echte Bedürfnisse aus Benutzerdaten zu erfassen. #? Context Learning verwendet einige Beispiele, um Aufgabenbefehle konkret auszudrücken, während Instruct eine abstrakte Aufgabenbeschreibung ist, die eher den menschlichen Gewohnheiten entspricht. Eine natürliche Frage ist also: Gibt es einen Zusammenhang zwischen ihnen? Können wir LLM beispielsweise mehrere spezifische Beispiele für die Erledigung einer bestimmten Aufgabe bereitstellen und LLM den entsprechenden Instruct-Befehl finden lassen, der in natürlicher Sprache beschrieben ist? Derzeit gibt es vereinzelte Arbeiten, die sich mit diesem Thema befassen. Ich denke, dass diese Richtung von großem Forschungswert ist. Lassen Sie uns zunächst über die Antwort sprechen. Die Antwort lautet: Ja, LLM Can. „Große Sprachmodelle sind schnelle Ingenieure auf menschlicher Ebene“ ist eine sehr interessante Arbeit in dieser Richtung. Geben Sie LLM für eine bestimmte Aufgabe einige Beispiele und lassen Sie LLM automatisch Befehle in natürlicher Sprache generieren, die die Aufgabe beschreiben können. Anschließend wird die von LLM generierte Aufgabenbeschreibung verwendet, um den Aufgabeneffekt zu testen. Die verwendeten Grundmodelle sind GPT 3 und InstructGPT. Nach dem Segen dieser Technologie ist die Wirkung von Instruct, die von LLM generiert wird, im Vergleich zu GPT 3 und InstructGPT, die diese Technologie nicht verwenden, erheblich verbessert und bei einigen Aufgaben übermenschliche Leistung. Licht der Weisheit: So verbessern Sie die Denkfähigkeit von LLM Viele Studien haben bewiesen, dass LLM über ein starkes Wissensgedächtnis verfügt. Im Allgemeinen sagen wir nicht, dass ein Mensch klug ist, nur weil er ein starkes Gedächtnis hat. Ob er über ein starkes Denkvermögen verfügt, ist für uns oft ein wichtiges Kriterium, um zu beurteilen, ob ein Mensch klug ist. Ebenso ist ein starkes Denkvermögen erforderlich, wenn die Wirkung von LLM erstaunlich sein soll. Im Wesentlichen ist die Denkfähigkeit die umfassende Nutzung vieler relevanter Wissenspunkte, um neues Wissen oder neue Schlussfolgerungen abzuleiten. Die Denkfähigkeit des LLM war im vergangenen Jahr einer der wichtigsten und beliebtesten Forschungsbereiche im LLM. Daher ist die Frage, die uns beschäftigt, folgende: ? Wenn der Modellmaßstab groß genug ist, verfügt LLM selbst über Inferenzfähigkeiten, LLM hat bei einfachen Denkproblemen sehr gute Fähigkeiten erreicht, bei komplexen Denkproblemen sind jedoch noch eingehendere Untersuchungen erforderlich. Tatsächlich sind die allgemeinen Richtungen dieser beiden Ideen sehr unterschiedlich: Verwendung von Code zur Verbesserung der LLM-Folgefähigkeiten, was eine Idee der direkten Verbesserung der LLM-Folgefähigkeiten durch Erhöhung der Vielfalt der Trainingsdaten widerspiegelt, während die auf Eingabeaufforderungen basierenden Die Methode fördert nicht die Denkfähigkeit von LLM selbst, sondern ist lediglich eine technische Methode, die es LLM ermöglicht, diese Fähigkeit im Problemlösungsprozess besser zu demonstrieren. Es ist ersichtlich, dass erstere (Code-Methode) die Grundursache behandelt, während letztere die Symptome behandelt. Natürlich ergänzen sich die beiden tatsächlich, aber auf lange Sicht ist die Ursache wichtiger. Promptbasierte Methode In diesem Bereich gibt es eine Menge Arbeit. Zusammenfassend kann man sie grob in drei technische Routen einteilen. Die erste Idee besteht darin, dem Problem direkt eine Hilfsbegründungsaufforderung hinzuzufügen. Diese Methode ist einfach und unkompliziert, aber in vielen Bereichen effektiv. Dieser Ansatz wurde von „Large Language Models Are Zero-Shot Reasoner“ vorgeschlagen und wird auch Zero-Shot CoT genannt. Konkret ist es in zwei Phasen unterteilt (wie in der Abbildung oben gezeigt). In der ersten Phase wird der Frage die Aufforderung „Lass uns Schritt für Schritt denken“ hinzugefügt, und in der zweiten Phase gibt LLM den spezifischen Argumentationsprozess aus , Fügen Sie nach den Fragen in der ersten Stufe den von LLM ausgegebenen spezifischen Argumentationsprozess zusammen und fügen Sie Prompt="Daher lautet die Antwort (arabische Ziffern)" hinzu. Zu diesem Zeitpunkt gibt LLM die Antwort. Eine solch einfache Operation kann die Effektivität von LLM bei verschiedenen Argumentationsaufgaben erheblich steigern. Beim Testsatz für mathematisches Denken GSM8K stieg die Argumentationsgenauigkeit direkt von ursprünglich 10,4 % auf 40,4 %, was ein Wunder ist. Warum hat LLM die Möglichkeit, detaillierte Argumentationsschritte aufzulisten und die Antwort zu berechnen, indem es die Aufforderung „Lass uns Schritt für Schritt denken“ gibt? Der Grund ist noch nicht schlüssig: Es liegt wahrscheinlich daran, dass die Daten vor dem Training eine große Menge dieser Art von Daten enthalten, die mit „Lass uns Schritt für Schritt denken“ beginnen, gefolgt von detaillierten Argumentationsschritten gibt schließlich die Antwort. LLM merkt sich diese Muster während des Vortrainings. Wenn wir diese Eingabeaufforderung eingeben, wird LLM dazu angeregt, sich vage an die Ableitungsschritte bestimmter Beispiele zu „erinnern“, sodass wir diese Beispiele nachahmen können, um Schrittfolgerungen durchzuführen und Antworten zu geben. Natürlich ist dies nur meine unbegründete Schlussfolgerung. Wenn Sie die später eingeführte Standard-CoT-Praxis lesen, werden Sie feststellen, dass sich Zero-Shot-CoT im Wesentlichen nicht vom Standard-CoT unterscheidet, außer dass es beim Standard-CoT der Fall ist Beispiele für Schritte, und Zero-shot CoT aktiviert höchstwahrscheinlich einige Beispiele im Gedächtnis, die Argumentationsschritte durch Eingabeaufforderungen enthalten, was wahrscheinlich so unterschiedlich ist. Es ist völlig verständlich, dass der Standard-CoT-Effekt besser ist als der Zero-Shot-CoT-Effekt, denn wenn man sich beim Abrufen von Beispielen auf LLM verlässt, wird die Genauigkeit nicht als zu hoch eingeschätzt und die Genauigkeit künstlich gegebener Beispiele ist garantiert. Daher ist der natürliche Standard-CoT-Effekt besser. Dies zeigt die Wahrheit, dass LLM selbst die Fähigkeit zur Vernunft besitzt, aber wir haben keine Möglichkeit, diese Fähigkeit zu stimulieren. Durch die Bereitstellung zweistufiger Eingabeaufforderungen kann dieses Potenzial bis zu einem gewissen Grad freigesetzt werden. Darüber hinaus gibt es für Chinesisch wahrscheinlich eine weitere goldene Erinnerung, wie zum Beispiel „Die detaillierten Problemlösungsideen lauten wie folgt“, ähnlich wie hier, denn wenn das chinesische Korpus die Argumentationsschritte, einleitenden Sätze und „Lass uns Schritt denken“ erklärt „durch Schritt“ werden oft verwendet „Es sollte anders sein.“ Dies ist eine offensichtliche westliche Aussage, und es ist tatsächlich notwendig, diese goldene Erinnerung auf Chinesisch zu untersuchen. Die zweite Idee wird allgemein als beispielbasierte Gedankenkette (few-shot CoT, Chain of Thought) Prompting bezeichnet. Diese Richtung ist derzeit die Hauptrichtung der LLM-Inferenzforschung, und es wird viel an dieser Idee gearbeitet. Wir stellen kurz einige repräsentative Arbeiten mit signifikanten Ergebnissen vor, die im Grunde die technische Entwicklungsrichtung von CoT darstellen können. Die Grundidee von CoT ist eigentlich sehr einfach. Um dem LLM-Modell das Erlernen des Denkens beizubringen, werden einige manuell geschriebene Argumentationsbeispiele Schritt für Schritt erläutert Die endgültige Antwort und diese künstlichen Argumente sind in der Denkkette Prompting aufgeführt. Konkrete Beispiele finden Sie im blauen Text im Bild oben. CoT bedeutet, das LLM-Modell eine Wahrheit verstehen zu lassen; das heißt, während des Denkprozesses keine zu großen Schritte zu unternehmen, sonst ist es leicht, Fehler zu machen und große Probleme Schritt für Schritt in kleine Probleme zu verwandeln , akkumulieren Sie kleine Gewinne zu großen Gewinnen. Der früheste Artikel, der das Konzept von CoT eindeutig vorschlägt, ist „Chain of Thought Prompting elicits Reasoning in Large Language Models“. Der Artikel wurde im Januar 2022 veröffentlicht. Obwohl die Methode sehr einfach ist, wurde die Argumentationsfähigkeit des LLM-Modells erheblich verbessert nach der Anwendung von CoT. GSM8K Die Genauigkeit des Testsatzes für mathematisches Denken ist auf etwa 60,1 % gestiegen. Natürlich wurde diese Idee, detaillierte Argumentationsschritte und Zwischenprozesse anzugeben, nicht zuerst von CoT vorgeschlagen. Die frühere „Scratchpad“-Technologie (siehe: Zeigen Sie Ihre Arbeit: Scratchpads für Zwischenberechnungen mit Sprachmodellen) übernahm zuerst eine ähnliche Idee. Nicht lange nachdem CoT es vorgeschlagen hatte, erhöhte eine verbesserte Technologie namens „Selbstkonsistenz“ die Genauigkeit des GSM8K-Testsatzes auf 74,4 %. Dieser Vorschlag ist „Selbstkonsistenz“. Verbessert die Gedankenkette in Sprachmodellen. Die Idee der „Selbstkonsistenz“ ist ebenfalls sehr intuitiv (siehe Abbildung oben): Zuerst können Sie CoT verwenden, um mehrere Beispiele für schriftliche Argumentationsprozesse anzugeben, und dann LLM bitten, über das gegebene Problem nachzudenken Ist CoT, gibt es direkt einen Inferenzprozess aus und antwortet, der gesamte Prozess ist beendet. „Selbstkonsistenz“ ist nicht der Fall. LLM muss mehrere unterschiedliche Argumentationsprozesse und Antworten ausgeben und dann die beste Antwort auswählen. Die Idee ist sehr einfach und direkt, aber der Effekt ist wirklich gut. „Selbstkonsistenz“ lehrt LLM tatsächlich, diese Wahrheit zu lernen: Kong Yiji sagte einmal, dass es vier Möglichkeiten gibt, das Wort „Fenchel“ für Fenchelbohnen zu schreiben. Ebenso kann es viele richtige Lösungen für ein mathematisches Problem geben, jede mit einer anderen Der Prozess führt zur endgültigen Antwort. Alle Wege führen nach Rom. Obwohl es einige Menschen gibt, die sich verirren und nach Peking gelangen, gibt es nur wenige, die sich verirren. Schauen Sie sich an, wohin die meisten Menschen gehen, und dort ist die richtige Antwort. Einfache Methoden enthalten oft tiefgreifende philosophische Bedeutungen, nicht wahr? In Zukunft basiert die Arbeit „On the Advance of Making Language Models Better Reasoners“ auf „Selbstkonsistenz“ und integriert darüber hinaus „die Erweiterung von einer Aufforderungsfrage auf mehrere Aufforderungsfragen und die Überprüfung der Zwischenschritte der Argumentation“ auf Richtigkeit und gewichtete Abstimmung der Antworten auf mehrere Ausgaben.“ Diese drei Verbesserungen verbesserten die Genauigkeit des GSM8K-Testsatzes auf etwa 83 %.
. Natürlich ist dieses sogenannte „Teile und herrsche“ meine Verallgemeinerung, andere haben das nicht gesagt. Die Kernidee dieser Idee ist: Für ein komplexes Argumentationsproblem zerlegen wir es in eine Reihe von Teilproblemen, die leicht zu lösen sind. Nachdem wir die Teilprobleme einzeln gelöst haben, leiten wir dann die Antwort auf das komplexe Problem ab Problem aus den Antworten auf die Teilprobleme. Sie sehen, das ähnelt tatsächlich der Idee des Divide-and-Conquer-Algorithmus. Ich persönlich bin der Meinung, dass diese Art des Denkens der authentische Weg sein könnte, den Kern des Problems aufzudecken und letztendlich das komplexe Argumentationsproblem des LLM zu lösen. Wir nehmen die „Least-to-Most-Prompting“-Technologie als Beispiel, um eine spezifische Umsetzung dieser Idee zu veranschaulichen, wie in der Abbildung oben gezeigt: Sie ist in zwei Phasen unterteilt. In der ersten Phase können wir das ursprüngliche Problem erkennen die letzte Frage: Nehmen wir an, dass das letzte Problem Final Q ist, und füllen Sie dann die Eingabeaufforderungsvorlage des ursprünglichen Problems aus: „Wenn ich das Final Q-Problem lösen möchte, muss ich es lösen.“ Zuerst“ und übergeben Sie dann das ursprüngliche Problem und diese Eingabeaufforderung an LLM. Lassen Sie das LLM-Modell die Antwort geben, was gleichbedeutend damit ist, dass LLM der letzten Frage das Präfix Unterfrage Sub Q geben soll. Dann treten wir in die zweite Stufe ein. Lassen Sie den LLM die soeben erhaltene Unterfrage Sub Q beantworten und erhalten Sie die entsprechende Antwort. Anschließend wird die ursprüngliche Frage in die Unterfrage Sub Q und die entsprechende Antwort gespleißt, und dann wird dem LLM die letzte Frage Final Q gestellt. Zu diesem Zeitpunkt wird der LLM die endgültige Antwort geben. Auf diese Weise spiegelt es die Idee wider, Unterfragen zu zerlegen und aus den Antworten auf die Unterfragen nach und nach die endgültige Antwort zu finden. #? Fähigkeiten von LLM-Modellen In Bezug auf die Argumentationsfähigkeit von LLM wurde ein interessantes und rätselhaftes Phänomen beobachtet: Zusätzlich zum Text können Sie Programmcode hinzufügen, um an der Modellvorbereitung teilzunehmen -Training kann die Denkfähigkeit des LLM-Modells erheblich verbessert werden. Diese Schlussfolgerung kann aus den experimentellen Abschnitten vieler Arbeiten gezogen werden (siehe: AUTOMATIC CHAIN OF THOOGHT PROMPTING IN LARGE LANGUAGE MODELS/Challenging BIG-Bench-Aufgaben und ob Chain-of-Thought diese und andere experimentelle Abschnitte von Arbeiten lösen kann). ). Die obige Abbildung zeigt experimentelle Daten aus dem Artikel „ „On the Advance of Making Language Models Better Reasoners“, darunter GPT3 davinci, das Standardmodell von GPT 3, basierend auf Klartexttraining; code-davinci-002 (in OpenAI intern Codex genannt) ist ein Modell, das sowohl auf Code- als auch auf NLP-Daten trainiert wird. Wenn Sie die Auswirkungen der beiden vergleichen, können Sie sehen, dass unabhängig von der verwendeten Inferenzmethode allein durch den Wechsel von einem reinen Text-Pre-Training-Modell zu einem gemischten Text- und Code-Pre-Training-Modell die Modellinferenzfähigkeit verbessert wurde Bei fast allen Testdatensätzen nehmen wir als Beispiel die Leistungsverbesserung, die 20 bis 50 Prozentpunkte übersteigt Auf der Ebene spezifischer Inferenzmodelle haben wir während des Vortrainings lediglich zusätzlichen Programmcode zusätzlich zum Text hinzugefügt. Zusätzlich zu diesem Phänomen können wir aus den Daten in der obigen Abbildung auch einige andere Schlussfolgerungen ziehen, zum Beispiel das reine Text-Pre-Training-Modell von GPT 3 hat tatsächlich eine beträchtliche Leistung. Neben der schlechten Leistung bei mathematischen Argumenten wie GSM8K ist auch die Leistung anderer Argumentationsdatensätze akzeptabel -davinci-002, das ist das Modell nach dem Hinzufügen der Instruct-Feinabstimmung auf der Grundlage von code-davinci-002 (was der erste Schritt zum Hinzufügen des InstructGPT- oder ChatGPT-Modells ist), hat eine schwächere Argumentationsfähigkeit als Codex, aber es gibt andere Forschung zeigt, dass es bei der Verarbeitung natürlicher Sprache stärker als Codex ist. Dies scheint darauf hinzudeuten, dass das Hinzufügen einer Anweisungsfeinabstimmung die Argumentationsfähigkeit des LLM-Modells beeinträchtigt, aber die Fähigkeit zum Verstehen natürlicher Sprache bis zu einem gewissen Grad verbessert. Diese Schlussfolgerungen sind tatsächlich sehr interessant und können zu weiteren Überlegungen und Untersuchungen anregen. Warum können vorab trainierte Modelle durch das Vortraining von Code zusätzliche Argumentationsfähigkeiten erlangen? Die genaue Ursache ist derzeit unbekannt und verdient weitere Erforschung multimodale Ausrichtungsarbeiten für die beiden Datentypen durch. Die Daten müssen einen beträchtlichen Anteil an Codes, Beschreibungen und Anmerkungen zu mathematischen oder logischen Problemen enthalten. Es ist offensichtlich, dass diese mathematischen oder logischen Argumentationsdaten bei der Lösung nachgelagerter mathematischer Argumentationsprobleme hilfreich sind. #? Sprechen Sie über die gängigen technischen Ideen des Denkens und einige bestehende Schlussfolgerungen. Als nächstes werde ich über meine Gedanken zur LLM-Modell-Schlussfolgerungstechnologie sprechen. Der folgende Inhalt ist eine rein persönliche Schlussfolgerung ohne viele Beweise, also lesen Sie ihn bitte mit Vorsicht. Mein Urteil ist: Obwohl die Technologie im vergangenen Jahr schnelle Fortschritte bei der Stimulierung der Denkfähigkeit von LLM gemacht hat und große technische Fortschritte erzielt wurden, ist das allgemeine Gefühl, dass wir möglicherweise auf dem richtigen Weg sind Richtung, aber es ist noch ein langer Weg, bis wir zur wahren Natur des Problems gelangen. Wir müssen tiefer nachdenken und dies erforschen. Zuallererst stimme ich der Hauptidee des oben genannten Divide-and-Conquer-Algorithmus zu. Bei komplexen Argumentationsproblemen sollten wir es in eine Reihe einfacher Unterprobleme aufteilen, da die Wahrscheinlichkeit der Beantwortung des Unterproblems zunimmt -Probleme richtig ist für LLM viel höher. Nachdem LLM die Unterfragen einzeln beantwortet hat, leitet es nach und nach die endgültige Antwort ab. Inspiriert durch die „Least-to-most-Prompting“-Technologie denke ich, wenn ich weiter darüber nachdenke, dass LLM-Argumentation wahrscheinlich eine der folgenden zwei Möglichkeiten ist: ein Graph-Argumentationsproblem, das kontinuierlich mit LLM interagiert, oder ein Graph-Argumentationsproblem, das kontinuierlich interagiert Interagiert mit LLM. Probleme bei der Ausführung des Programmflussdiagramms für die Interaktion mit LLM. Lassen Sie uns zunächst über das Problem des Diagrammdenkens sprechen. Nehmen wir an, wir haben eine Möglichkeit, ein komplexes Problem in eine Diagrammstruktur zu zerlegen, die aus Unterproblemen oder Unterschritten besteht Im Diagramm handelt es sich um Unterprobleme oder Unterschritte. Die Kanten im Diagramm stellen die Abhängigkeiten zwischen Unterfragen dar. Das heißt, Sie können Unterfrage B nur beantworten, indem Sie sie beantworten Es besteht eine hohe Wahrscheinlichkeit, dass im Diagramm eine Schleifenstruktur vorliegt, d. h. bestimmte Unterschritte werden wiederholt ausgeführt. Unter der Annahme, dass wir das oben erwähnte Teilproblem-Demontagediagramm erhalten können, können wir LLM Schritt für Schritt entsprechend der Diagrammstruktur entsprechend der Abhängigkeitsbeziehung führen und die Teilfragen beantworten, die zuerst beantwortet werden müssen, bis die endgültige Antwort abgeleitet ist . Lassen Sie uns noch einmal über das Problem des Programmflussdiagramms sprechen. Nehmen wir an, wir haben eine Möglichkeit, ein komplexes Problem in Unterprobleme oder Unterschritte zu zerlegen und ein Programmflussdiagramm zu erstellen Struktur, die aus Unterschritten besteht. In dieser Struktur werden einige Schritte mehrmals wiederholt ausgeführt (Schleifenstruktur), und die Ausführung einiger Schritte erfordert eine bedingte Beurteilung (bedingte Verzweigung). Kurz gesagt: Interagieren Sie bei der Ausführung jedes Unterschritts mit LLM, erhalten Sie die Antwort auf den Unterschritt und fahren Sie dann entsprechend dem Prozess mit der Ausführung fort, bis die endgültige Antwort ausgegeben wird. Ähnlich diesem Modell. Unter der Annahme, dass diese Idee ungefähr richtig ist, kann aus dieser Perspektive möglicherweise erklärt werden, warum das Hinzufügen von Code die Argumentationsfähigkeit des vorab trainierten Modells verbessert: Es besteht eine hohe Wahrscheinlichkeit, dass das multimodale vorab trainierte Modell von ein verwendet Implizites Programm wie dieses im Modell Als Brücke zwischen den beiden Modalitäten verbindet das Flussdiagramm die beiden, dh von der Textbeschreibung zum impliziten Flussdiagramm und dann zum spezifischen Code, der vom Flussdiagramm generiert wird. Mit anderen Worten, diese Art des multimodalen Vortrainings kann die Fähigkeit des LLM-Modells verbessern, aus Text ein implizites Flussdiagramm zu erstellen und es gemäß dem Flussdiagramm auszuführen, dh es stärkt seine Argumentationsfähigkeit. Natürlich besteht das größte Problem bei der obigen Idee darin, wie wir uns auf das LLM-Modell oder andere Modelle verlassen können, um die Diagrammstruktur oder Flussdiagrammstruktur basierend auf dem im Text beschriebenen Problem zu erhalten? Das könnte die Schwierigkeit sein. Eine mögliche Idee besteht darin, das Vortraining von Text und höherwertigem Code weiter zu verbessern und die Methode des impliziten Lernens der internen impliziten Struktur zu übernehmen. Wenn Sie über die aktuelle CoT-Technologie nachdenken, die auf den oben genannten Ideen basiert, können Sie sie folgendermaßen verstehen: Standard-CoT basiert tatsächlich auf Text in natürlicher Sprache, um die Diagrammstruktur oder das Programmflussdiagramm zu beschreiben, während die „Least-to-most-Prompting“-Technologie verwendet wird Es wird versucht, die Graphstruktur basierend auf dem letzten Graphknoten abzuleiten und sich auf die Rückwärtsinferenz zu verlassen. Es ist jedoch offensichtlich, dass die aktuelle Methode die Tiefe ihrer Rückwärtsinferenz begrenzt, was bedeutet, dass nur eine sehr einfache Graphstruktur abgeleitet werden kann. Das ist es, was seine Möglichkeiten einschränkt. Hier sind einige LLM-Forschungsbereiche, die ich persönlich für wichtig halte, oder Forschungsrichtungen, die einer eingehenden Untersuchung wert sind. Erkundung der Skalenobergrenze des LLM-Modells Obwohl es den Anschein hat, dass die weitere Vergrößerung des Maßstabs des LLM-Modells keinen technischen Inhalt hat, ist dies tatsächlich äußerst wichtig. Meiner persönlichen Einschätzung nach besteht seit der Entstehung von Bert über GPT 3 und dann ChatGPT eine hohe Wahrscheinlichkeit, dass die Kernbeiträge dieser beeindruckenden wichtigen technologischen Durchbrüche auf dem Wachstum der LLM-Modellgröße und nicht auf einer bestimmten Technologie beruhen . Vielleicht der wahre Schlüssel zur Erschließung von AGI ist: extrem große und ausreichend vielfältige Daten, extrem große Modelle und ausreichende Trainingsprozesse. Darüber hinaus erfordert die Erstellung sehr umfangreicher LLM-Modelle sehr hohe technische Umsetzungsfähigkeiten des technischen Teams, und es kann nicht davon ausgegangen werden, dass es dieser Angelegenheit an technischem Inhalt mangelt. Welche Forschungsbedeutung hat es also, den Umfang des LLM-Modells weiter zu vergrößern? Ich denke, es gibt zwei Aspekte des Wertes. Erstens wissen wir, wie oben erwähnt, dass bei wissensintensiven Aufgaben die Leistung verschiedener Aufgaben mit zunehmender Modellgröße immer besser wird, und bei vielen Arten von Überlegungen und schwierigen Aufgaben wird CoT hinzugefügt Prompting Schließlich zeigt seine Wirkung auch die Tendenz, dem Skalierungsgesetz zu folgen. Eine natürliche Frage lautet also: Inwieweit kann der Skaleneffekt von LLM diese Aufgaben lösen? Diese Frage beschäftigt viele Menschen, auch mich. Zweitens, angesichts der magischen „emergenten Fähigkeit“ von LLM: Welche neuen Fähigkeiten werden dadurch freigeschaltet, wenn wir die Modellgröße weiter erhöhen, die wir nicht erwartet hatten? Das ist auch eine sehr interessante Frage. In Anbetracht der beiden oben genannten Punkte müssen wir die Modellgröße noch weiter erhöhen, um zu sehen, wo die Obergrenze der Modellgröße für die Lösung verschiedener Aufgaben liegt. Über so etwas kann man natürlich nur reden. Für 99,99 % der Praktizierenden gibt es keine Möglichkeit oder Fähigkeit dazu. Dafür sind die Anforderungen an die finanzielle Ausstattung und Investitionsbereitschaft, die Ingenieursleistung und die technische Begeisterungsfähigkeit der Forschungseinrichtungen äußerst hoch und unabdingbar. Eine grobe Schätzung der Zahl der Institutionen, die dies leisten können, liegt bei maximal 5 im Ausland und maximal 3 im Inland. In Anbetracht der Kostenfrage könnte es in Zukunft natürlich zu einem „großen Aktienmodell“ kommen, bei dem mehrere fähige Institutionen zusammenarbeiten und zusammenarbeiten, um ein supergroßes Modell aufzubauen. Verbesserung der komplexen Denkfähigkeit von LLM Wie bereits über die Denkfähigkeit von LLM beschrieben, obwohl die Denkfähigkeit von LLM im vergangenen Jahr in vielen Studien stark verbessert wurde (Referenz: Limitations of Language Modelle in der arithmetischen und symbolischen Induktion (Modelle in großen Sprachen können immer noch nicht geplant werden) zeigen, dass LLM derzeit bessere Argumentationsprobleme lösen kann, die oft noch relativ einfach sind. Die Fähigkeit von LLM zum komplexen Denken ist noch schwach, wie beispielsweise das einfache Kopieren von Zeichen oder Darüber hinaus , Subtraktions-, Multiplikations- und Divisionsoperationen: Wenn Zeichenfolgen oder Zahlen sehr lang sind, nimmt die Denkfähigkeit von LLM schnell ab und komplexe Denkfähigkeiten wie die Fähigkeit zur Verhaltensplanung sind sehr schwach. Alles in allem sollte die Stärkung der komplexen Denkfähigkeiten des LLM einer der wichtigsten Aspekte der zukünftigen Forschung zum LLM sein. Wie oben erwähnt, ist das Hinzufügen von Code und Vorschulung eine Richtung, die die LLM-Argumentationsfähigkeiten direkt verbessert. Derzeit gibt es nicht genügend Forschung in dieser Richtung. Es handelt sich eher um eine Zusammenfassung praktischer Erfahrungen, die Erforschung der dahinter stehenden Prinzipien und die anschließende Einführung weiterer Arten neuer Daten als des Codes, um die Argumentationsfähigkeit von LLM zu verbessern die Denkfähigkeit wesentlich verbessern. LLM umfasst neben NLP noch weitere Forschungsfelder Das aktuelle ChatGPT eignet sich gut für NLP- und Code-Aufgaben und kombiniert Bilder, Videos, Audio und andere Bilder mit mehreren -modale Integration in LLM und sogar andere Bereiche mit offensichtlicheren Unterschieden wie KI für die Wissenschaft und Robotersteuerung werden nach und nach in LLM integriert, was für LLM der einzige Weg ist, zu AGI zu führen. Diese Richtung hat gerade erst begonnen und hat daher einen hohen Forschungswert. Einfacher zu verwendende interaktive Schnittstelle für Menschen und LLM Wie bereits erwähnt, ist hier der größte technische Beitrag von ChatGPT. Aber offensichtlich ist die aktuelle Technologie nicht perfekt und es muss viele Befehle geben, die LLM nicht verstehen kann. Daher suchen wir in dieser Richtung nach einer besseren Technologie, die es Menschen ermöglicht, ihre eigenen gewohnten Befehlsausdrücke zu verwenden, und LLM kann diese verstehen. Dies ist eine neue und sehr vielversprechende technische Richtung. Erstellung eines schwierigen, umfassenden Aufgabenbewertungsdatensatzes Ein guter Bewertungsdatensatz ist der Grundstein für den kontinuierlichen Fortschritt der Technologie. Mit der schrittweisen Erweiterung des LLM-Modells verbessert sich die Aufgabenleistung rasch, was dazu führt, dass viele Standardtestsätze schnell veraltet sind. Mit anderen Worten, diese Datensätze sind im Vergleich zu bestehenden Technologien zu einfach. Bei einem Testsatz ohne Schwierigkeiten wissen wir nicht, wo die Mängel und blinden Flecken der aktuellen Technologie liegen. Daher ist der Aufbau eines schwierigen Testsatzes der Schlüssel zur Förderung des Fortschritts der LLM-Technologie. Derzeit sollten einige neue Testsätze in der Branche erscheinen, repräsentative sind BIGBench, OPT-IML usw. Diese Testsätze spiegeln einige Merkmale wider, z. B. dass sie schwieriger als bestehende LLM-Technologien sind und eine Vielzahl von Aufgaben integrieren. Inspiriert durch ChatGPT denke ich, dass zusätzlich eine weitere Überlegung einbezogen werden sollte: die Widerspiegelung echter Benutzerbedürfnisse. Das heißt, der Ausdruck dieser Aufgaben wird tatsächlich von den Benutzern initiiert. Nur das auf diese Weise konstruierte LLM-Modell kann die tatsächlichen Bedürfnisse der Benutzer lösen. Darüber hinaus glaube ich, dass LLM seine Fähigkeiten schnell auf andere Bereiche als NLP übertragen wird, und es muss auch im Voraus darüber nachgedacht werden, wie mehr Bewertungsdaten aus anderen Bereichen integriert werden können. Hochwertiges Data Engineering Für das Pre-Training-Modell sind Daten die Grundlage, und der Pre-Training-Prozess kann als der Prozess der Aufnahme des in den Daten enthaltenen Wissens verstanden werden. Daher müssen wir die Gewinnung, Sammlung und Bereinigung hochwertiger Daten weiter stärken. In Bezug auf Daten sind zwei Aspekte zu berücksichtigen: die Qualität und Quantität der Daten . Basierend auf den Vergleichsexperimenten von T5 können wir den Schluss ziehen, dass zwischen den beiden Faktoren Quantität und Qualität die Qualität Vorrang hat und der richtige Weg darin bestehen sollte, die Datengröße zu erhöhen und gleichzeitig die Datenqualität sicherzustellen. Datenqualität umfasst mehrere Maßnahmen wie den Informationsgehalt der Daten und die Vielfalt der Daten. Beispielsweise handelt es sich bei Wiki um offensichtlich qualitativ hochwertige Daten mit einer extrem hohen Wissensdichte in der Welt Erhöhung der Daten Die Artenvielfalt ist zweifellos die Grundlage für die Anregung verschiedener neuer Funktionen von LLM. Beispielsweise ist das Hinzufügen von Daten von Q&A-Websites direkt hilfreich für die Verbesserung der QA-Funktionen von LLM. Vielfältige Daten geben LLM die Möglichkeit, mehr unterschiedliche Arten von Aufgaben besser zu lösen, sodass dies möglicherweise das wichtigste Kriterium für die Datenqualität ist. Bezüglich der Datenmenge können grundsätzlich alle im Internet öffentlich veröffentlichten Daten in den Pre-Training-Prozess des LLM-Modells einbezogen werden. Wo liegen also seine Grenzen? „Werden uns die Daten ausgehen? Eine Analyse der Grenzen der Skalierung von Datensätzen beim maschinellen Lernen“ schätzte dies und kam zu dem Schluss, dass bis etwa 2026 hochwertige NLP-Daten aufgebraucht sein werden und bis 2030 minderwertige NLP-Daten erschöpft sein werden . Es wird bis 2050 aufgebraucht sein, während Bilddaten mit geringer Qualität zwischen 2030 und 2060 aufgebraucht sein werden. Und das bedeutet: Entweder haben wir bis dahin neue Arten von Datenquellen, oder wir müssen die Effizienz des LLM-Modells bei der Nutzung der Daten steigern. Andernfalls kommt der derzeitige datengesteuerte Ansatz zur Modelloptimierung nicht weiter voran oder die Vorteile werden geringer. Sparsifizierung des sehr großen LLM-Modells Transformer Unter den derzeit größten LLMs verwenden viele Modelle eine spärliche (sparse) Struktur, wie GPT 3, PaLM, GLaM usw., GPT 4 hat eine hohe Wahrscheinlichkeit. Wir werden auch den Weg des spärlichen Modells wählen. Der Hauptvorteil der Verwendung eines Sparse-basierten Modells besteht darin, dass es die Trainingszeit und die Online-Inferenzzeit von LLM erheblich reduzieren kann. Das Switch Transformer-Papier weist darauf hin, dass unter der Voraussetzung des gleichen Rechenleistungsbudgets mit dem Sparse Transformer die Trainingsgeschwindigkeit des LLM-Modells im Vergleich zum Dense Transformer um das Vier- bis Siebenfache erhöht werden kann. Warum beschleunigen Sparse-Modelle die Trainings- und Inferenzzeiten? Dies liegt daran, dass das Sparse-Modell für eine bestimmte Trainingsinstanz nur einen kleinen Teil der gesamten Parameter über den Routing-Mechanismus verwendet. Die Anzahl der aktiven Parameter, die am Training und an der Inferenz beteiligt sind, ist daher relativ gering schnell. Ich denke, dass sehr große LLM-Modelle in Zukunft höchstwahrscheinlich zu spärlichen Modellen konvergieren werden. Dafür gibt es zwei Hauptgründe: Einerseits zeigen bestehende Forschungsergebnisse (Referenz: Große Modelle sind sparsame Lernende: Aktivierungssparsität in trainierten Transformatoren), dass der standardmäßige dichte Transformator selbst während des Trainings und der Inferenz nur spärlich aktiviert wird, d. h. nur ein Teil der Parameter wird aktiviert und die meisten Parameter nehmen nicht am Trainings- und Inferenzprozess teil. In diesem Fall könnten wir genauso gut direkt zum Sparse-Modell migrieren. Darüber hinaus besteht kein Zweifel daran, dass der Umfang des LLM-Modells weiter zunehmen wird und die hohen Schulungskosten ein wichtiges Hindernis für die weitere Erweiterung des Modells darstellen Sparse-Modelle können die Trainingskosten für sehr große Modelle erheblich senken. Je größer das Modell, desto deutlicher werden die Vorteile des Sparse-Modells. Unter Berücksichtigung dieser beiden Aspekte besteht eine hohe Wahrscheinlichkeit, dass größere LLM-Modelle in Zukunft eine spärliche Modelllösung übernehmen werden. Warum gehen andere Großmodelle derzeit nicht den Weg spärlicher Modelle? Da das Sparse-Modell Probleme wie instabiles Training und leichte Überanpassung aufweist, ist es nicht einfach, gut zu trainieren. Daher ist es eine wichtige zukünftige Forschungsrichtung, die Probleme zu beheben, mit denen spärliche Modelle konfrontiert sind, und spärliche Modelle zu entwerfen, die einfacher zu trainieren sind. Wenn Sie ein LLM-Modell mit erstaunlichen Effekten wie ChatGPT auf der Grundlage verschiedener aktueller Forschungsergebnisse replizieren möchten, müssen Sie bei der Entwicklung der Technologie wichtige Kompromisse eingehen Auswahl Die folgenden Fragen: Zunächst Im Vortrainingsmodus haben wir drei Optionen: autoregressives Sprachmodell wie GPT, bidirektionales Sprachmodell wie Bert und Hybridmodus wie T5 (Encoder-Decoder In der Architektur verwendet der Encoder ein bidirektionales Sprachmodell und der Decoder ein autoregressives Sprachmodell, sodass es sich um eine Hybridstruktur handelt, deren Essenz jedoch immer noch zum Bert-Modus gehört. Wir sollten ein autoregressives Sprachmodell wie GPT wählen. Die Gründe werden im Abschnitt zum Paradigmenwechsel dieses Artikels analysiert. Wenn inländische LLM derzeit die Technologieauswahl in diesem Bereich treffen, scheinen viele von ihnen den technischen Weg des bidirektionalen Bert-Sprachmodells oder des T5-Hybrid-Sprachmodells einzuschlagen. Es ist sehr wahrscheinlich, dass die Richtung in die Irre gegangen ist. Zweitens starkes Denkvermögen ist eine wichtige psychologische Grundlage für Benutzer, um LLM zu erkennen. Wenn Sie möchten, dass LLM auf der Grundlage aktueller Erfahrungen über ein starkes Denkvermögen verfügt, ist es am besten, ein Vortraining durchzuführen Dabei muss eine große Menge Code und Text für das LLM-Training eingeführt werden. Zur Begründung gibt es eine entsprechende Analyse an den entsprechenden Stellen dieses Artikels. Drittens: Wenn Sie möchten, dass die Modellparameterskala nicht so groß ist, der Effekt aber dennoch gut genug sein soll, stehen Ihnen zwei technische Optionen für die Konfiguration zur Verfügung: entweder die hochwertige Datenerfassung verbessern, das Mining verbessern oder Reinigung usw. Arbeit, was bedeutet, dass meine Modellparameter halb so groß sein können wie die des ChatGPT/GPT 4-Modells, aber um ähnliche Effekte zu erzielen, muss die Menge an hochwertigen Trainingsdaten doppelt so hoch sein wie die des ChatGPT/GPT 4-Modells (Chinchillas Ansatz); Eine weitere Möglichkeit, die Größe des Modells effektiv zu reduzieren, besteht darin, das Textabrufmodell (Retrieval-basiert) + LLM zu übernehmen. Dadurch kann auch die Parameterskala des LLM-Modells erheblich reduziert werden der gleiche Effekt. Diese beiden Technologieoptionen schließen sich nicht gegenseitig aus, sondern ergänzen sich. Mit anderen Worten: Diese beiden Technologien können gleichzeitig verwendet werden, um ähnliche Effekte wie bei supergroßen Modellen zu erzielen, sofern der Modellmaßstab relativ klein ist. wie man die Ausbildungskosten von LLM durch technische Mittel senken kann. Die Sparseisierung des Merkmalsextraktors von LLM ist eine technische Wahl, die die Kosten für Modelltraining und Inferenz effektiv reduzieren kann. Daraus folgt, dass mit zunehmender Modellgröße die Sparseisierung von LLM-Modellen eine Option ist, die in Betracht gezogen werden sollte. der Idee Aufmerksamkeit geschenkt werden, durch die Erhöhung der Datenvielfalt neue LLM-Funktionen hinzuzufügen. Die größte Inspiration für mich von ChatGPT ist eigentlich die Frage, ob man Verstärkungslernen verwenden sollte. Andere alternative Technologien sollten in der Lage sein, ähnliche Dinge zu tun. ChatGPT: Warum OpenAI Zu Beginn dieses Artikels haben wir die LLM-Philosophie von OpenAI erwähnt. Was hält OpenAI von LLM? Wenn wir auf die kontinuierlich eingeführten Technologien zurückblicken, können wir sehen, dass LLM seit GPT 1.0 grundsätzlich als einziger Weg zu AGI angesehen wird. Konkret sollte die zukünftige AGI in den Augen von OpenAI so aussehen: Es gibt einen aufgabenunabhängigen, supergroßen LLM, der dazu dient, verschiedenes Wissen aus massiven Daten zu erlernen. Dieses LLM generiert alles, um verschiedene Probleme zu lösen, und das sollte auch so sein in der Lage sein, menschliche Befehle so zu verstehen, dass sie von Menschen genutzt werden können. Tatsächlich besteht das Verständnis des LLM-Entwicklungskonzepts in der ersten Hälfte darin, „ein aufgabenunabhängiges, sehr großes LLM aufzubauen und es verschiedenes Wissen aus massiven Daten lernen zu lassen“. Dies ist fast jeder Konsens und kann die tatsächliche Vision von OpenAI widerspiegeln . Es ist die zweite Hälfte. Wir können einige der wichtigsten Schritte Revue passieren lassen: GPT 1.0 folgt der autoregressiven Sprachmodellroute zur Generierung von Mustern, die früher als Bert veröffentlicht wurde. Bert hat bewiesen, dass bidirektionale Sprachmodelle bei vielen NLP-Verständnisaufgaben eine bessere Leistung erbringen als autoregressive einseitige Sprachmodelle. Trotzdem ist GPT 2.0 nicht auf den Weg bidirektionaler Sprachmodelle umgestiegen, sondern folgte weiterhin dem Weg der Textgenerierung und begann, Zero-Shot-Eingabeaufforderungen und Wenige-Eingabeaufforderungen auszuprobieren. Tatsächlich beginnt zu diesem Zeitpunkt die AGI im Kopf von OpenAI an die Oberfläche zu kommen und zeigt allmählich ihre Umrisse. Nur weil der Effekt von Null-Schuss/wenigen Schüssen weitaus schlimmer ist als die Feinabstimmung von Bert+, nehmen es nicht alle zu ernst und verstehen nicht einmal, warum es immer auf der Route des einseitigen Sprachmodells besteht. Zum jetzigen Zeitpunkt schätze ich, dass nicht einmal OpenAI selbst sicherstellen kann, dass dieser Weg definitiv funktioniert. Das hindert es jedoch nicht daran, diesen Weg weiterzugehen. GPT 3.0 hat relativ leistungsstarke Zero-Shot-/Wenige-Shot-Prompt-Fähigkeiten gezeigt. Zu diesem Zeitpunkt ist die AGI in OpenAIs Gedanken völlig aus dem Wasser gesickert, mit einem klaren Umriss, und ihre Wirkung beweist auch, dass dieser Weg eher beschritten wird . Bestanden. GPT 3.0 ist ein Scheideweg und Wendepunkt, der die Entwicklungsrichtung von LLM bestimmt. Ein weiterer entsprechender Weg ist das „Bert+Fine-Tuning“-Modell. An dieser Weggabelung entschieden sich verschiedene Praktiker für unterschiedliche Wege, und von da an begann sich die technische Kluft zu vergrößern. Leider entscheiden sich viele inländische Praktiker dafür, auf dem Weg der „Bert+Feinabstimmung“ weiterhin Rückschritte zu machen, was auch ein entscheidender Zeitpunkt ist, der die heutige rückständige Situation verursacht hat. Für die Zukunft gibt es InstructGPT und ChatGPT. 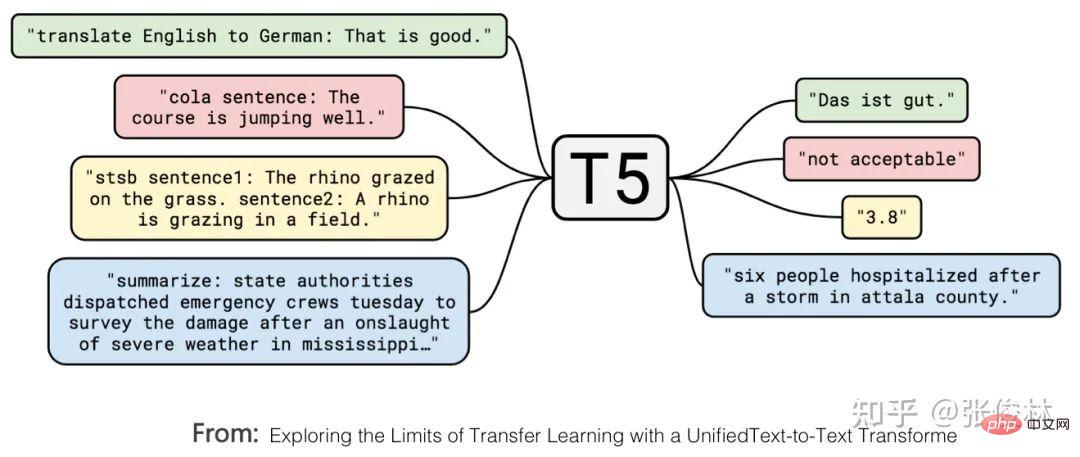 Dies zeigt, dass die Aufgabe der Erzeugung natürlicher Sprache mit der Aufgabe des Verstehens natürlicher Sprache in Bezug auf den Ausdruck kompatibel sein kann. Wenn es umgekehrt ist, wird es schwierig sein, dies zu erreichen. Dies hat den Vorteil, dass das gleiche LLM-Generierungsmodell fast alle NLP-Probleme lösen kann. Wenn weiterhin der Bert-Modus verwendet wird, kann dieses LLM-Modell die Generierungsaufgabe nicht gut bewältigen. Es gibt also einen Grund, warum wir durchaus dazu neigen, generative Modelle zu verwenden.
Dies zeigt, dass die Aufgabe der Erzeugung natürlicher Sprache mit der Aufgabe des Verstehens natürlicher Sprache in Bezug auf den Ausdruck kompatibel sein kann. Wenn es umgekehrt ist, wird es schwierig sein, dies zu erreichen. Dies hat den Vorteil, dass das gleiche LLM-Generierungsmodell fast alle NLP-Probleme lösen kann. Wenn weiterhin der Bert-Modus verwendet wird, kann dieses LLM-Modell die Generierungsaufgabe nicht gut bewältigen. Es gibt also einen Grund, warum wir durchaus dazu neigen, generative Modelle zu verwenden. 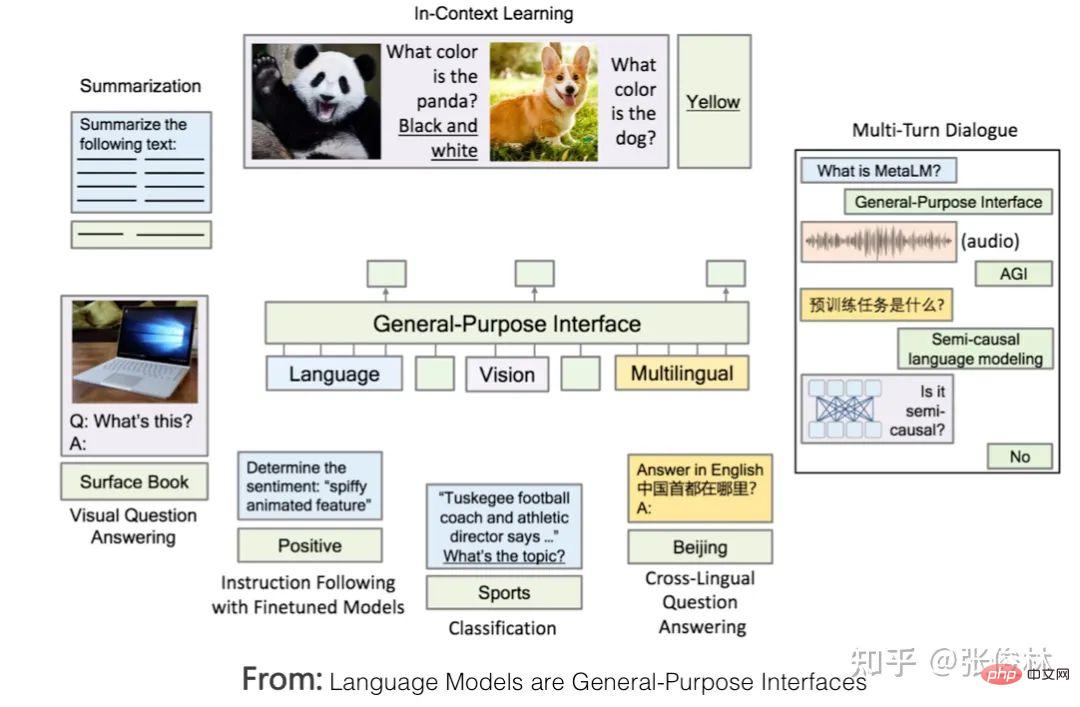
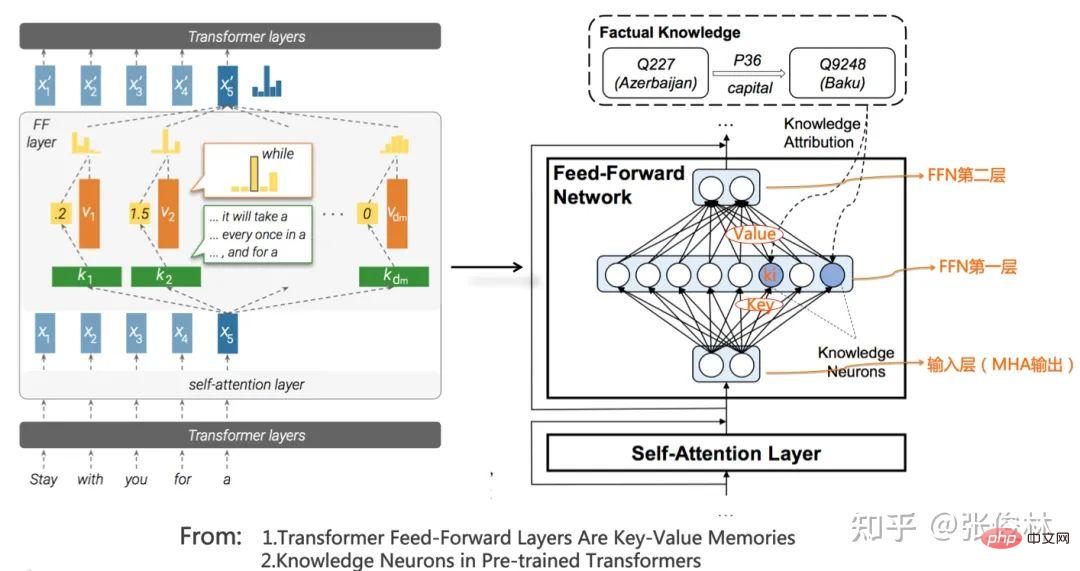
 . Knoten
. Knoten  in der ersten verborgenen Schicht von FFN im Bild oben möglicherweise das Wissen auf . Der dem
in der ersten verborgenen Schicht von FFN im Bild oben möglicherweise das Wissen auf . Der dem  -Knoten entsprechende Schlüsselvektor bezieht sich tatsächlich auf den Gewichtsvektor des Knotens
-Knoten entsprechende Schlüsselvektor bezieht sich tatsächlich auf den Gewichtsvektor des Knotens  und jedes Knotens der Eingabeschicht, und der entsprechende Wertvektor bezieht sich auf die Verbindung zwischen dem Knoten
und jedes Knotens der Eingabeschicht, und der entsprechende Wertvektor bezieht sich auf die Verbindung zwischen dem Knoten  und jedem Knoten der Wertschicht des zweiten Schicht des FFN-Gewichtsvektors. Der Schlüsselvektor jedes Neurons wird verwendet, um eine bestimmte Sprache oder ein bestimmtes Wissensmuster in der Eingabe zu identifizieren. Es handelt sich um einen Musterdetektor. Wenn die Eingabe ein bestimmtes Muster enthält, das erkannt werden soll, werden der Eingabevektor und das Schlüsselgewicht des Knotens
und jedem Knoten der Wertschicht des zweiten Schicht des FFN-Gewichtsvektors. Der Schlüsselvektor jedes Neurons wird verwendet, um eine bestimmte Sprache oder ein bestimmtes Wissensmuster in der Eingabe zu identifizieren. Es handelt sich um einen Musterdetektor. Wenn die Eingabe ein bestimmtes Muster enthält, das erkannt werden soll, werden der Eingabevektor und das Schlüsselgewicht des Knotens  als innere Vektorprodukte berechnet und Relu hinzugefügt, um eine große numerische Antwort von
als innere Vektorprodukte berechnet und Relu hinzugefügt, um eine große numerische Antwort von  zu bilden, was bedeutet, dass
zu bilden, was bedeutet, dass  vorhanden ist Dieses Muster wurde erkannt, daher wird der Antwortwert über den Wertgewichtungsvektor des
vorhanden ist Dieses Muster wurde erkannt, daher wird der Antwortwert über den Wertgewichtungsvektor des  -Knotens an die zweite Schicht von FFN weitergegeben. Dies entspricht der Gewichtung des Werts des Wertvektors mit dem Antwortwert und der anschließenden Übergabe und Wiedergabe an die Ausgabe jedes Knotens der zweiten Wertschicht. Auf diese Weise sieht der Vorwärtsausbreitungsberechnungsprozess von FFN so aus, als würde man ein bestimmtes Wissensmuster über Key erkennen, dann den entsprechenden Wert herausnehmen und den Wert auf der zweiten Schichtausgabe von FFN wiedergeben. Natürlich sammelt jeder Knoten in der zweiten Schicht von FFN alle Knoteninformationen in der Schlüsselschicht von FFN, es handelt sich also um eine gemischte Antwort, und die gemischte Antwort aller Knoten in der Wertschicht kann als Wahrscheinlichkeitsverteilungsinformation interpretiert werden, die die darstellt Ausgabewort.
-Knotens an die zweite Schicht von FFN weitergegeben. Dies entspricht der Gewichtung des Werts des Wertvektors mit dem Antwortwert und der anschließenden Übergabe und Wiedergabe an die Ausgabe jedes Knotens der zweiten Wertschicht. Auf diese Weise sieht der Vorwärtsausbreitungsberechnungsprozess von FFN so aus, als würde man ein bestimmtes Wissensmuster über Key erkennen, dann den entsprechenden Wert herausnehmen und den Wert auf der zweiten Schichtausgabe von FFN wiedergeben. Natürlich sammelt jeder Knoten in der zweiten Schicht von FFN alle Knoteninformationen in der Schlüsselschicht von FFN, es handelt sich also um eine gemischte Antwort, und die gemischte Antwort aller Knoten in der Wertschicht kann als Wahrscheinlichkeitsverteilungsinformation interpretiert werden, die die darstellt Ausgabewort.  in der obigen Abbildung der Schlüsselwertspeicher ist, der dieses Wissen aufzeichnet. Sein Schlüsselvektor wird verwendet, um das Wissensmodell „Die Hauptstadt von China ist …“ zu erkennen und seinen Wertvektor im Wesentlichen zu speichern die gleichen Wörter wie „Peking“ „Einbettung ist ein relativ ähnlicher Vektor. Wenn die Eingabe von Transformer „Die Hauptstadt von China ist [Maske]“ lautet, erkennt der -Knoten dieses Wissensmuster aus der Eingabeebene und generiert daher eine größere Antwortausgabe. Wir gehen davon aus, dass andere Neuronen in der Schlüsselschicht keine Antwort auf diese Eingabe haben. Dann empfängt der entsprechende Knoten in der Werteschicht tatsächlich nur die Worteinbettung, die dem Wert „Beijing“ entspricht, und führt die weitere Verarbeitung über den großen Antwortwert durch von
in der obigen Abbildung der Schlüsselwertspeicher ist, der dieses Wissen aufzeichnet. Sein Schlüsselvektor wird verwendet, um das Wissensmodell „Die Hauptstadt von China ist …“ zu erkennen und seinen Wertvektor im Wesentlichen zu speichern die gleichen Wörter wie „Peking“ „Einbettung ist ein relativ ähnlicher Vektor. Wenn die Eingabe von Transformer „Die Hauptstadt von China ist [Maske]“ lautet, erkennt der -Knoten dieses Wissensmuster aus der Eingabeebene und generiert daher eine größere Antwortausgabe. Wir gehen davon aus, dass andere Neuronen in der Schlüsselschicht keine Antwort auf diese Eingabe haben. Dann empfängt der entsprechende Knoten in der Werteschicht tatsächlich nur die Worteinbettung, die dem Wert „Beijing“ entspricht, und führt die weitere Verarbeitung über den großen Antwortwert durch von  Numerische Verstärkung. Daher gibt die Ausgabe, die der Maskenposition entspricht, natürlich das Wort „Peking“ aus. Es ist im Grunde dieser Prozess. Er sieht kompliziert aus, ist aber eigentlich sehr einfach.
Numerische Verstärkung. Daher gibt die Ausgabe, die der Maskenposition entspricht, natürlich das Wort „Peking“ aus. Es ist im Grunde dieser Prozess. Er sieht kompliziert aus, ist aber eigentlich sehr einfach. 
Skaleneffekt: Was passiert, wenn LLM immer größer wird?
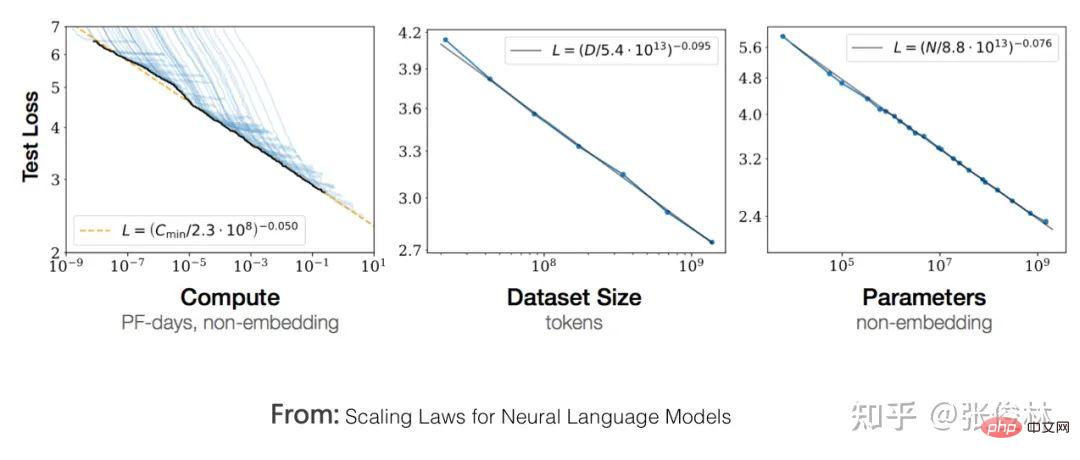
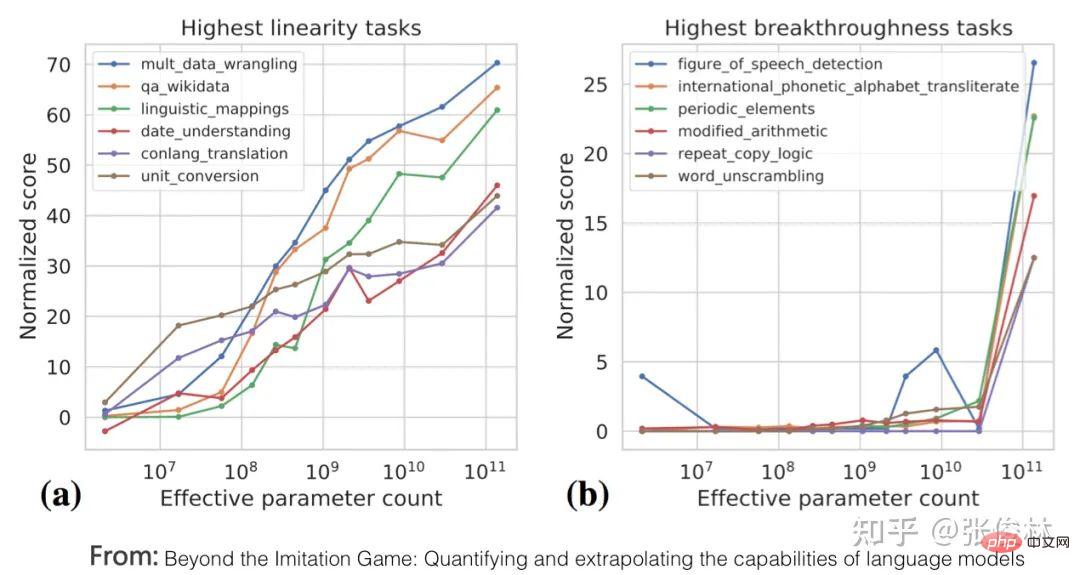
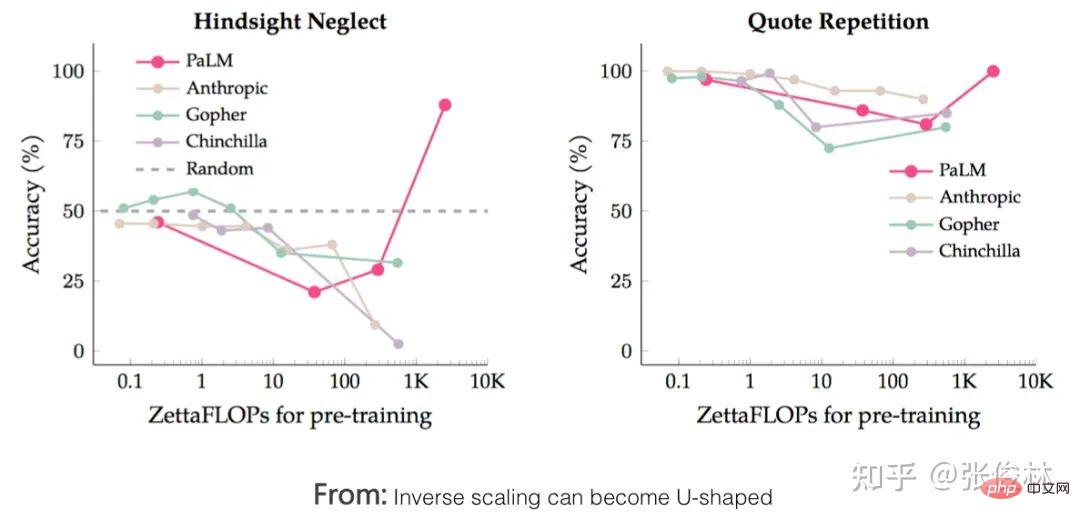
 zur Verfügung stellen und diese dann angeben
zur Verfügung stellen und diese dann angeben  , LLM das entsprechende
, LLM das entsprechende  erfolgreich vorhersagen kann. Wenn Sie das hören, fragen Sie sich vielleicht: Was ist daran so magisch? Funktioniert Feinabstimmung nicht so? Wenn Sie diese Frage stellen, bedeutet das, dass Sie nicht gründlich genug über dieses Thema nachgedacht haben.
erfolgreich vorhersagen kann. Wenn Sie das hören, fragen Sie sich vielleicht: Was ist daran so magisch? Funktioniert Feinabstimmung nicht so? Wenn Sie diese Frage stellen, bedeutet das, dass Sie nicht gründlich genug über dieses Thema nachgedacht haben. 
 , das LLM zur Verfügung gestellt wurde, spielt es eigentlich keine Rolle, ob
, das LLM zur Verfügung gestellt wurde, spielt es eigentlich keine Rolle, ob  die richtige Antwort auf
die richtige Antwort auf  ist. Wenn wir die richtige Antwort
ist. Wenn wir die richtige Antwort  durch eine andere zufällige Antwort
durch eine andere zufällige Antwort  ersetzen, ist dies der Fall haben keinen Einfluss auf die Wirksamkeit des In-Context-Lernens. Dies verdeutlicht zumindest eines: In Context Learning stellt LLM nicht die Zuordnungsfunktionsinformationen von
ersetzen, ist dies der Fall haben keinen Einfluss auf die Wirksamkeit des In-Context-Lernens. Dies verdeutlicht zumindest eines: In Context Learning stellt LLM nicht die Zuordnungsfunktionsinformationen von  zu
zu  zur Verfügung:
zur Verfügung: 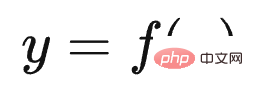 Andernfalls wird diese
Andernfalls wird diese 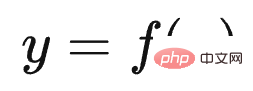 -Zuordnungsfunktion definitiv gestört, wenn Sie zufällig die richtige Bezeichnung ändern . Mit anderen Worten: Beim In-Context-Learning wird der Mapping-Prozess vom Eingaberaum zum Ausgaberaum nicht erlernt.
-Zuordnungsfunktion definitiv gestört, wenn Sie zufällig die richtige Bezeichnung ändern . Mit anderen Worten: Beim In-Context-Learning wird der Mapping-Prozess vom Eingaberaum zum Ausgaberaum nicht erlernt.  und
und  , also die Verteilung des Eingabetextes
, also die Verteilung des Eingabetextes  und was die Kandidatenantworten
und was die Kandidatenantworten  sind, wenn man zum Beispiel diese beiden Verteilungen ändert , ersetzen Sie
sind, wenn man zum Beispiel diese beiden Verteilungen ändert , ersetzen Sie  durch Kandidatenantworten. Bei Inhalten außerhalb des Kontexts nimmt die Wirkung von In-Context-Lernen stark ab.
durch Kandidatenantworten. Bei Inhalten außerhalb des Kontexts nimmt die Wirkung von In-Context-Lernen stark ab. 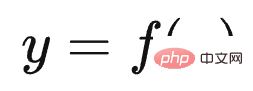 , sie wird jedoch implizit gelernt. „Welcher Lernalgorithmus ist In-Context-Lernen? Untersuchungen mit linearen Modellen“ geht beispielsweise davon aus, dass Transformer den Mapping-Prozess implizit von
, sie wird jedoch implizit gelernt. „Welcher Lernalgorithmus ist In-Context-Lernen? Untersuchungen mit linearen Modellen“ geht beispielsweise davon aus, dass Transformer den Mapping-Prozess implizit von  nach
nach  aus Beispielen lernen kann. Seine Aktivierungsfunktion enthält einige einfache Mapping-Funktionen, während LLM den Mapping-Prozess lernen kann von Beispielen bis Fire das entsprechende. Der Artikel „Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers“ behandelt ICL als implizite Feinabstimmung.
aus Beispielen lernen kann. Seine Aktivierungsfunktion enthält einige einfache Mapping-Funktionen, während LLM den Mapping-Prozess lernen kann von Beispielen bis Fire das entsprechende. Der Artikel „Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers“ behandelt ICL als implizite Feinabstimmung. 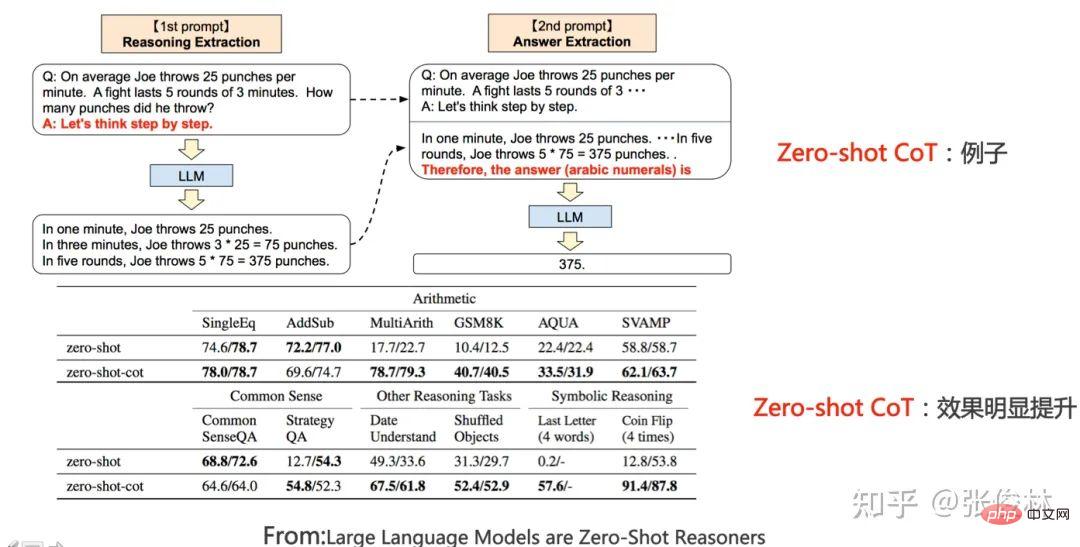
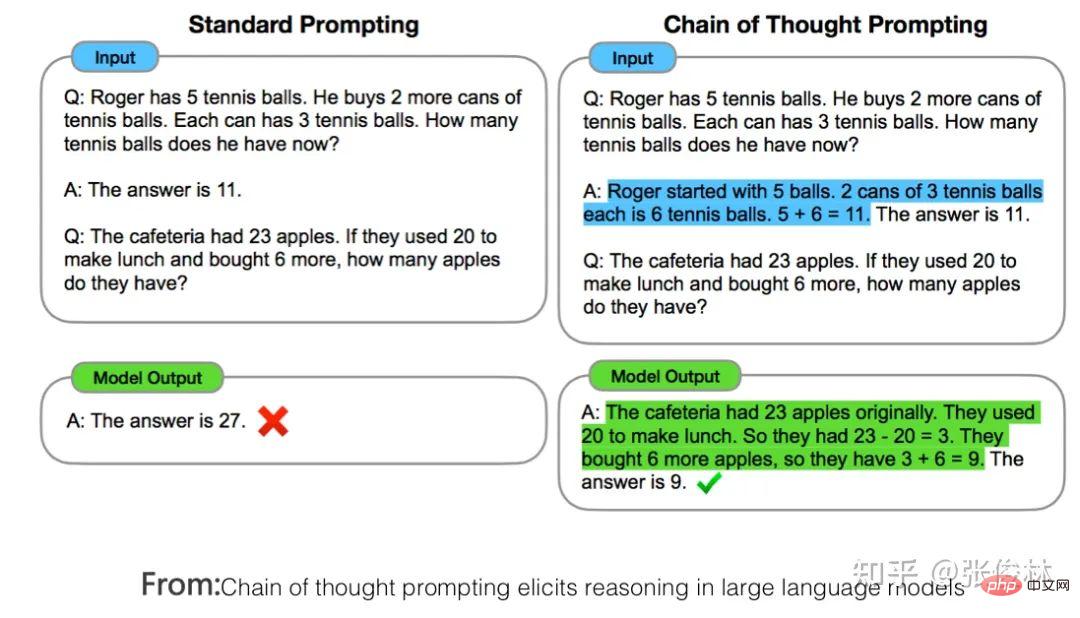
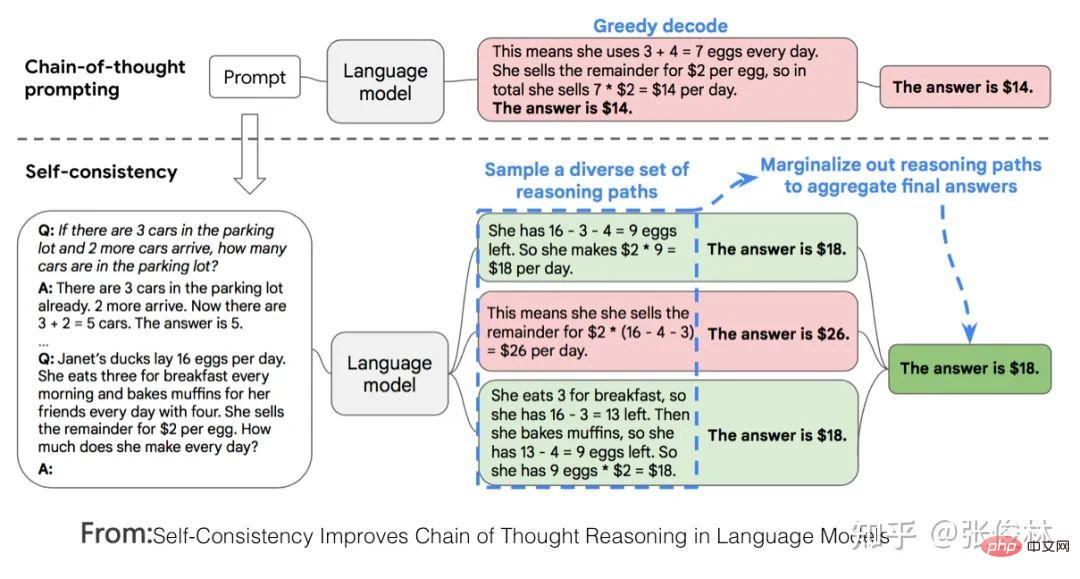
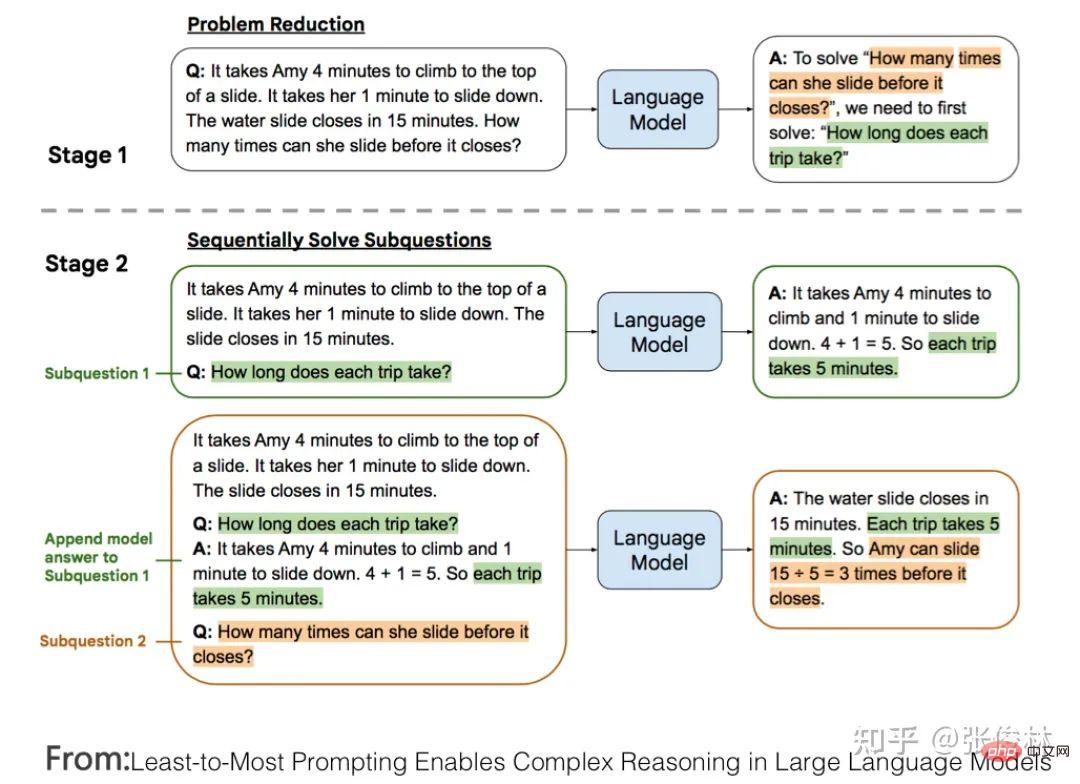
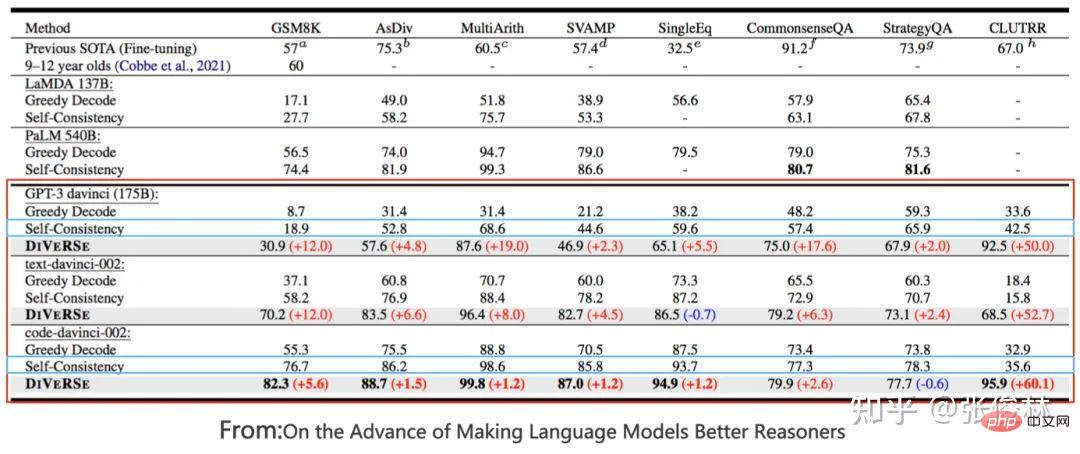
Der Weg in die Zukunft: LLM-Forschungstrends und Schlüsselrichtungen, die es wert sind, erforscht zu werden
Der Weg zum Lernen: Worauf sollten Sie bei der Replikation von ChatGPT achten?
Das obige ist der detaillierte Inhalt vonEntdecken Sie die Großmodelltechnologie in der Post-GPT 3.0-Ära und machen Sie sich auf den Weg, die Zukunft von AGI zu verwirklichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr