
Heim >Technologie-Peripheriegeräte >KI >Backdoor-Verteidigungsmethode des segmentierten Backdoor-Trainings: DBD
Backdoor-Verteidigungsmethode des segmentierten Backdoor-Trainings: DBD

- 王林nach vorne
- 2023-04-25 23:16:14856Durchsuche
Die Forschungsgruppe von Professor Wu Baoyuan von der Chinesischen Universität Hongkong (Shenzhen) und die Forschungsgruppe von Professor Qin Zhan von der Zhejiang-Universität haben gemeinsam einen Artikel im Bereich Backdoor-Verteidigung veröffentlicht, der von ICLR2022 erfolgreich angenommen wurde.
In den letzten Jahren hat das Backdoor-Problem große Aufmerksamkeit erregt. Da weiterhin Hintertürangriffe vorgeschlagen werden, wird es immer schwieriger, Abwehrmethoden gegen allgemeine Hintertürangriffe vorzuschlagen. In diesem Artikel wird eine Backdoor-Verteidigungsmethode vorgeschlagen, die auf einem segmentierten Backdoor-Trainingsprozess basiert.
Dieser Artikel enthüllt, dass der Backdoor-Angriff eine durchgängig überwachte Trainingsmethode ist, die die Backdoor in den Funktionsraum projiziert. Auf dieser Grundlage unterteilt dieser Artikel den Trainingsprozess zur Vermeidung von Backdoor-Angriffen. Es wurden Vergleichsexperimente zwischen dieser Methode und anderen Backdoor-Abwehrmethoden durchgeführt, um die Wirksamkeit dieser Methode zu beweisen.
Inklusionskonferenz: ICLR2022
Artikellink: https://arxiv.org/pdf/2202.03423.pdf
Codelink: https://github.com/SCLBD/ DBD
1 Einführung in den Hintergrund
Das Ziel eines Hintertürangriffs besteht darin, das Modell durch Ändern der Trainingsdaten oder Steuern des Trainingsprozesses dazu zu bringen, korrekte und saubere Proben vorherzusagen. Proben mit Hintertüren werden jedoch als Zielbezeichnungen beurteilt. Beispielsweise fügt ein Backdoor-Angreifer einem Bild (d. h. einem vergifteten Bild) einen weißen Block mit fester Position hinzu und ändert die Bezeichnung des Bildes in die Zielbezeichnung. Nachdem das Modell mit diesen vergifteten Daten trainiert wurde, stellt das Modell fest, dass das Bild mit einem bestimmten weißen Block die Zielbezeichnung ist (wie in der Abbildung unten dargestellt).
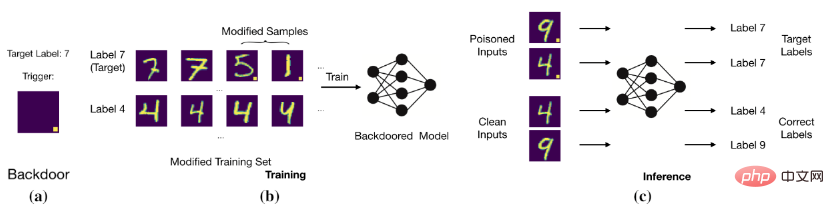 Grundlegender Hintertürangriff
Grundlegender Hintertürangriff
Das Modell stellt die Beziehung zwischen dem Auslöser und der Zielbezeichnung her.
2 Backdoor-Angriff), Clean-Label-Backdoor-Angriff, der das ursprüngliche Label des vergifteten Bildes beibehält.
1. Vergiftungsetikettenangriff: BadNets (Gu et al., 2019) ist der erste und repräsentativste Vergiftungsetikettenangriff. Später (Chen et al., 2017) schlugen vor, dass die Unsichtbarkeit vergifteter Bilder der ihrer harmlosen Versionen ähneln sollte, und auf dieser Grundlage wurde ein gemischter Angriff vorgeschlagen. Kürzlich (Xue et al., 2020; Li et al., 2020; 2021) wurde weiter untersucht, wie Poisoning-Tag-Backdoor-Angriffe verdeckter durchgeführt werden können. Kürzlich wurde ein heimlicherer und effektiverer Angriff, WaNet (Nguyen & Tran, 2021), vorgeschlagen. WaNet nutzt Bildverzerrungen als Backdoor-Trigger, der den Bildinhalt beibehält und ihn gleichzeitig verformt.
2. Clean-Label-Angriff: Um das Problem zu lösen, dass Benutzer Backdoor-Angriffe durch die Untersuchung von Bild-Label-Beziehungen erkennen können, schlugen Turner et al. das Clean-Label-Angriffsparadigma vor, bei dem das Ziellabel mit dem identisch ist Originaletikett der vergifteten Probe konsistent. Diese Idee wurde erweitert, um die Videoklassifizierung anzugreifen (Zhao et al., 2020b), die eine Ziel-allgemeine gegnerische Störung (Moosavi-Dezfooli et al., 2017) als Auslöser annahm. Obwohl Clean-Tag-Backdoor-Angriffe subtiler sind als Poisoned-Tag-Backdoor-Angriffe, ist ihre Leistung in der Regel relativ schlecht und es kann sein, dass die Hintertür nicht einmal erstellt wird (Li et al., 2020c).
2.2 Backdoor-Abwehr
Die meisten der vorhandenen Backdoor-Abwehrmaßnahmen sind empirisch und können in fünf Kategorien unterteilt werden, darunter
1. Erkennungsbasierte Verteidigung (Xu et al, 2021; Zeng et al, 2011 ; Xiang et al, 2022) prüft, ob das verdächtige Modell oder Muster angegriffen wird, und lehnt die Verwendung schädlicher Objekte ab.
2. Vorverarbeitungsbasierte Abwehrmaßnahmen (Doan et al., 2020; Li et al., 2021; Zeng et al., 2021) zielen darauf ab, die in Angriffsmustern enthaltenen auslösenden Muster zu zerstören, indem vor der Eingabe des Bildes in das Modell eine Vorverarbeitung eingeführt wird. Verarbeitungsmodul zur Verhinderung der Aktivierung einer Hintertür.
3. Die auf der Modellrekonstruktion basierende Verteidigung (Zhao et al., 2020a; Li et al., 2021;) besteht darin, versteckte Hintertüren im Modell durch direkte Modifikation des Modells zu beseitigen.
4. Die Auslösung einer umfassenden Verteidigung (Guo et al., 2020; Dong et al., 2021; Shen et al., 2021) besteht darin, zunächst die Hintertür zu erkennen und zweitens die verborgene Hintertür zu beseitigen, indem ihre Auswirkungen unterdrückt werden.
5. Verteidigung basierend auf Vergiftungsunterdrückung (Du et al, 2020; Borgnia et al, 2021) reduziert die Wirksamkeit vergifteter Proben während des Trainingsprozesses, um die Entstehung versteckter Hintertüren zu verhindern
2.3 Halbüberwachtes Lernen und selbstüberwachtes Lernen
1. Halbüberwachtes Lernen: In vielen realen Anwendungen beruht die Erfassung gekennzeichneter Daten häufig auf manueller Kennzeichnung, was sehr teuer ist. Im Vergleich dazu ist es viel einfacher, unbeschriftete Proben zu erhalten. Um die Leistungsfähigkeit sowohl unbeschrifteter als auch gekennzeichneter Proben zu nutzen, wurde eine große Anzahl halbüberwachter Lernmethoden vorgeschlagen (Gao et al., 2017; Berthelot et al., 2019; Van Engelen & Hoos, 2020). In jüngster Zeit wurde auch halbüberwachtes Lernen zur Verbesserung der Modellsicherheit eingesetzt (Stanforth et al., 2019; Carmon et al., 2019), die im gegnerischen Training unbeschriftete Proben verwenden. Kürzlich (Yan et al., 2021) diskutierten, wie man halbüberwachtes Lernen durch eine Hintertür öffnen kann. Zusätzlich zur Änderung der Trainingsbeispiele muss diese Methode jedoch auch andere Trainingskomponenten (z. B. Trainingsverluste) steuern.
2. Selbstüberwachtes Lernen: Das selbstüberwachte Lernparadigma ist eine Teilmenge des unüberwachten Lernens, und das Modell wird mithilfe von Signalen trainiert, die von den Daten selbst generiert werden (Chen et al, 2020a; Grill et al, 2020; Liu et al., 2021). Es wird verwendet, um die Widerstandsfähigkeit des Gegners zu erhöhen (Hendrycks et al, 2019; Wu et al, 2021; Shi et al, 2021). Kürzlich wurde in einigen Artikeln (Saha et al., 2021; Carlini & Terzis, 2021; Jia et al., 2021) untersucht, wie man Hintertüren in selbstüberwachtes Lernen einbauen kann. Allerdings erfordern diese Angriffe neben der Modifizierung von Trainingsbeispielen auch die Kontrolle anderer Trainingskomponenten (z. B. Trainingsverlust).
3 Backdoor-Funktionen
Wir führten BadNets- und Clean-Label-Angriffe auf den CIFAR-10-Datensatz durch (Krizhevsky, 2009). Überwachtes Lernen mit toxischen Datensätzen und selbstüberwachtes Lernen mit SimCLR mit unbeschrifteten Datensätzen (Chen et al., 2020a).
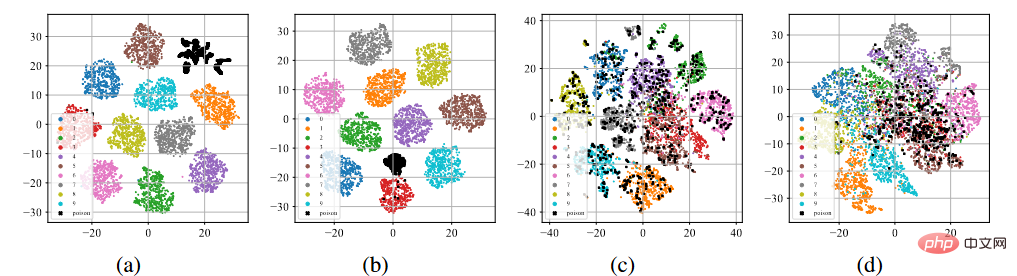
T-sne-Anzeige von Backdoor-Funktionen
Wie in der Abbildung (a)-(b) oben gezeigt, nach dem standardmäßigen überwachten Trainingsprozess, unabhängig davon, ob es sich um einen Vergiftungsetikettenangriff handelt oder um Clean-Label-Angriff Unten neigen alle vergifteten Proben (angezeigt durch schwarze Punkte) dazu, sich zu separaten Clustern zusammenzuballen. Dieses Phänomen weist auf den Erfolg bestehender, auf Poisoning basierender Backdoor-Angriffe hin. Durch übermäßiges Lernen kann das Modell die Eigenschaften von Backdoor-Triggern lernen. In Kombination mit einem durchgängig überwachten Trainingsparadigma kann das Modell den Abstand zwischen vergifteten Proben im Merkmalsraum verringern und die erlernten auslöserbezogenen Merkmale mit Zielbezeichnungen verbinden. Im Gegenteil, wie in den Abbildungen (c) bis (d) oben gezeigt, liegen die vergifteten Proben im unbeschrifteten Vergiftungsdatensatz nach dem selbstüberwachten Trainingsprozess sehr nahe an den Proben mit Originaletiketten. Dies zeigt, dass wir durch selbstüberwachtes Lernen Hintertüren verhindern können.
4 Hintertür-Verteidigung basierend auf Segmentierung
Basierend auf der Analyse von Hintertür-Eigenschaften schlagen wir eine Hintertür-Verteidigung in der Segmentierungstrainingsphase vor. Wie in der folgenden Abbildung dargestellt, besteht es aus drei Hauptphasen: (1) Erlernen eines bereinigten Merkmalsextraktors durch selbstüberwachtes Lernen, (2) Filtern hochzuverlässiger Proben durch Label-Noise-Lernen und (3) halbüberwachtes Fein- Tuning.
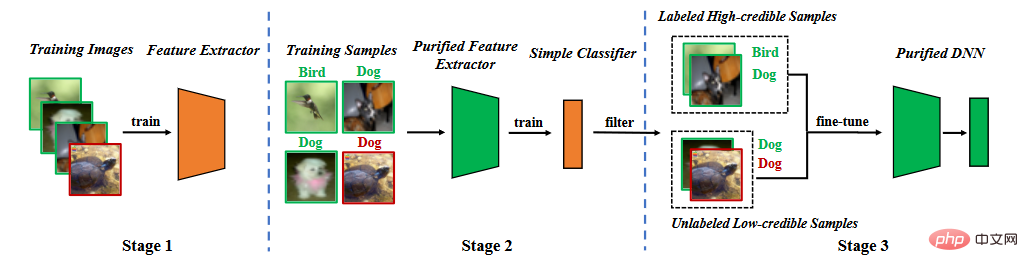 Methodenflussdiagramm
Methodenflussdiagramm
4.1 Lernmerkmalsextraktor
Wir verwenden den Trainingsdatensatz, um das Modell zu lernen. Die Parameter des Modells bestehen aus zwei Teilen, einem sind die Parameter des Backbone-Modells und der andere sind die Parameter der vollständig verbundenen Schicht. Wir nutzen selbstüberwachtes Lernen, um die Parameter des Backbone-Modells zu optimieren.
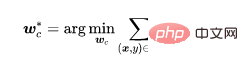
Wo ist der selbstüberwachte Verlust (zum Beispiel NT-Xent in SimCLR (Chen et al., 2020))? Backdoor-Funktionen.
4.2 Label-Noise-Lernen zum Filtern von Proben
Sobald der Feature-Extraktor trainiert ist, legen wir die Parameter des Feature-Extraktors fest und verwenden den Trainingsdatensatz, um die Parameter der vollständig verbundenen Schicht weiter zu lernen,
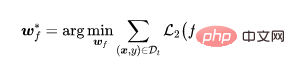
Wo ist der überwachte Lernverlust (z. B. Kreuzentropieverlust)?
Obwohl dieser Segmentierungsprozess es dem Modell erschwert, Hintertüren zu lernen, gibt es zwei Probleme. Erstens kommt es im Vergleich zu Methoden, die durch überwachtes Lernen trainiert werden, zu einem gewissen Rückgang der Genauigkeit der Vorhersage sauberer Proben, da der erlernte Merkmalsextraktor in der zweiten Stufe eingefroren wird. Zweitens dienen bei Angriffen mit vergifteten Etiketten vergiftete Proben als „Ausreißer“, was die zweite Lernstufe weiter behindert. Diese beiden Probleme weisen darauf hin, dass wir vergiftete Proben entfernen und das gesamte Modell neu trainieren oder optimieren müssen.
Wir müssen feststellen, ob die Probe eine Hintertür hat. Wir glauben, dass es für das Modell schwierig ist, aus Backdoor-Proben zu lernen, daher verwenden wir Vertrauen als Unterscheidungsindikator. Proben mit hohem Vertrauen sind saubere Proben, während Proben mit niedrigem Vertrauen vergiftete Proben sind. Durch Experimente wurde festgestellt, dass das mit symmetrischem Kreuzentropieverlust trainierte Modell eine große Verlustlücke zwischen den beiden Proben aufweist, sodass der Grad der Diskriminierung hoch ist, wie in der folgenden Abbildung dargestellt.
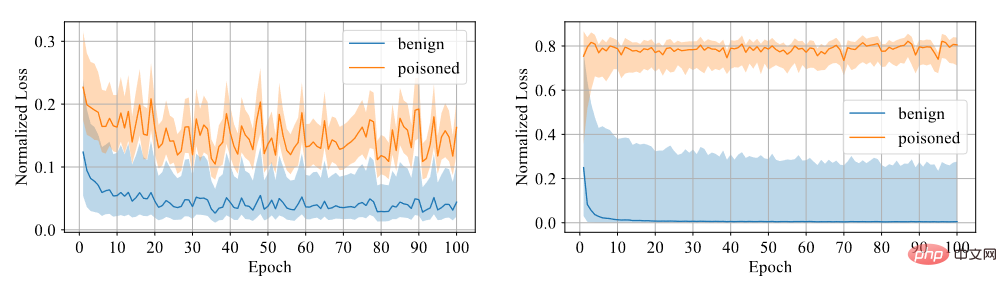
Vergleich zwischen symmetrischem Kreuzentropieverlust und Kreuzentropieverlust
Daher haben wir den Feature-Extraktor korrigiert, um die vollständig verbundene Schicht mithilfe des symmetrischen Kreuzentropieverlusts zu trainieren, und den Datensatz so gefiltert, dass er hoch ist nach der Größe des Konfidenzniveaus. Konfidenzdaten und Daten mit niedrigem Konfidenzniveau.
4.3 Halbüberwachte Feinabstimmung
Zuerst entfernen wir Etiketten von Daten mit geringem Vertrauen. Wir verwenden halbüberwachtes Lernen, um das gesamte Modell zu verfeinern.

Wo ist der halbüberwachte Verlust (z. B. die Verlustfunktion in MixMatch (Berthelot et al, 2019)).
Halbüberwachte Feinabstimmung kann nicht nur verhindern, dass das Modell Backdoor-Trigger lernt, sondern auch dafür sorgen, dass das Modell bei sauberen Datensätzen gut funktioniert.
5 (eine Teilmenge). Der Artikel verwendet das ResNet18-Modell (He et al., 2016). Der Artikel untersucht alle Verteidigungsmethoden zur Abwehr von vier typischen Angriffen, nämlich Badnets (Gu et al., 2019), Backdoor-Angriffe mit gemischten Strategien (Chen et al.). . al, 2017), WaNet (Nguyen & Tran, 2021) und Clean-Label-konsistente Angriffe mit gegnerischen Störungen (Turner et al, 2019).
Beispielbild für einen Backdoor-Angriff
5.2 Experimentelle Ergebnisse
 Die Beurteilungskriterien des Experiments sind die Beurteilungsgenauigkeit von BA als saubere Probe und die Beurteilungsgenauigkeit von ASR als vergifteter Probe .
Die Beurteilungskriterien des Experiments sind die Beurteilungsgenauigkeit von BA als saubere Probe und die Beurteilungsgenauigkeit von ASR als vergifteter Probe .
Ergebnisse des Backdoor-Verteidigungsvergleichs
Wie in der Tabelle oben gezeigt, ist DBD bei der Abwehr aller Angriffe deutlich besser als Verteidigungen mit den gleichen Anforderungen (d. h. DPSGD und ShrinkPad). In allen Fällen hat DBD mehr als 20 % BA und 5 % niedrigere ASR als DPSGD. Der ASR des DBD-Modells beträgt in allen Fällen weniger als 2 % (in den meisten Fällen weniger als 0,5 %), was bestätigt, dass DBD die Erstellung versteckter Hintertüren erfolgreich verhindern kann. DBD wird mit zwei anderen Methoden verglichen, nämlich NC und NAD, die beide erfordern, dass der Verteidiger über einen sauberen lokalen Datensatz verfügt.
Wie in der Tabelle oben gezeigt, übertreffen NC und NAD DPSGD und ShrinkPad, weil sie zusätzliche Informationen aus lokalen sauberen Datensätzen nutzen. Obwohl NAD und NC zusätzliche Informationen verwenden, ist DBD insbesondere besser als diese. Insbesondere im ImageNet-Datensatz hat NC nur begrenzte Auswirkungen auf die Reduzierung der ASR. Im Vergleich dazu erreicht DBD den kleinsten ASR, während DBDs BA in fast allen Fällen am höchsten oder zweithöchsten ist. Darüber hinaus sank der BA im Vergleich zum Modell ohne jegliches Verteidigungstraining bei der Abwehr von Poisoning-Tag-Angriffen um weniger als 2 %. Bei relativ größeren Datensätzen ist DBD sogar noch besser, da alle Basismethoden weniger effektiv sind. Diese Ergebnisse bestätigen die Wirksamkeit von DBD.
5.3 Ablationsexperimente
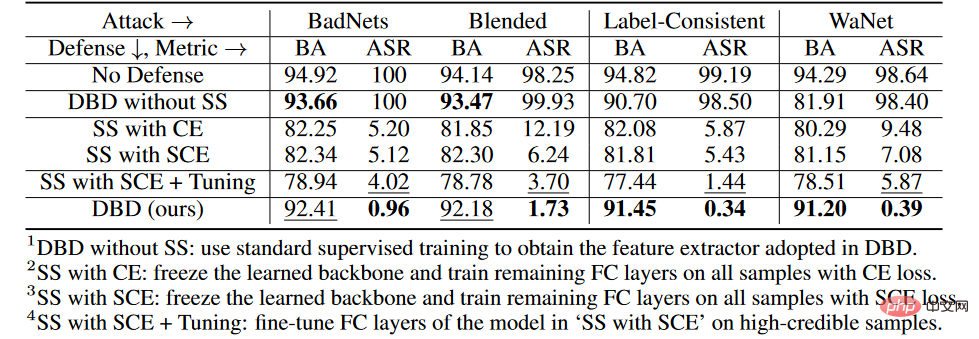
ablierungsexperimente in jeder Stufe
on im CIFAR-10-Datensatz verglichen wir die vorgeschlagene DBD und seine vier Varianten, einschließlich
1 , ersetzt das durch selbstüberwachtes Lernen erzeugte Rückgrat durch das auf überwachte Weise trainierte Rückgrat und behält andere Teile unverändert
2 mit SS, friert das durch selbstüberwachtes Lernen erlernte Rückgrat ein und Kreuzentropieverlust Die verbleibenden vollständig verbundenen Schichten wurden auf allen Trainingsmustern trainiert
3.SS mit SCE, ähnlich der zweiten Variante, jedoch unter Verwendung eines symmetrischen Kreuzentropieverlusts trainiert.
4.SS mit SCE + Tuning, weitere Feinabstimmung der vollständig verbundenen Schicht auf Proben mit hoher Zuverlässigkeit, gefiltert durch die dritte Variante.
Wie in der Tabelle oben gezeigt, ist die Entkopplung des ursprünglichen End-to-End-überwachten Trainingsprozesses wirksam, um die Entstehung versteckter Hintertüren zu verhindern. Darüber hinaus werden die zweite und dritte DBD-Variante verglichen, um die Wirksamkeit des SCE-Verlusts bei der Abwehr von Poison-Tag-Backdoor-Angriffen zu überprüfen. Darüber hinaus sind ASR und BA der vierten DBD-Mutation niedriger als die der dritten DBD-Mutation. Dieses Phänomen ist auf die Entfernung von Stichproben mit geringer Konfidenz zurückzuführen. Dies legt nahe, dass es für die Verteidigung wichtig ist, nützliche Informationen aus Stichproben mit geringem Vertrauen zu nutzen und gleichzeitig deren Nebenwirkungen zu reduzieren.
5.4 Widerstand gegen potenzielle adaptive Angriffe
Wenn Angreifer die Existenz von DBD kennen, können sie adaptive Angriffe entwerfen. Wenn der Angreifer die vom Verteidiger verwendete Modellstruktur kennt, kann er einen adaptiven Angriff entwerfen, indem er das Auslösemuster so optimiert, dass die vergiftete Probe nach dem selbstüberwachten Lernen in einem neuen Cluster verbleibt, wie unten gezeigt:
Angriffseinstellungen
Lassen Sie bei einem Klassifizierungsproblem die sauberen Proben darstellen, die vergiftet werden müssen, stellen Sie die Proben mit dem Originaletikett dar und seien Sie ein geschultes Rückgrat. Angesichts des vom Angreifer vorgegebenen vergifteten Bildgenerators zielt der adaptive Angriff darauf ab, das Auslösemuster zu optimieren, indem der Abstand zwischen vergifteten Bildern minimiert und gleichzeitig der Abstand zwischen der Mitte des vergifteten Bildes und der Mitte der Gruppe harmloser Bilder mit unterschiedlichen Etikettenabständen maximiert wird. das heißt.
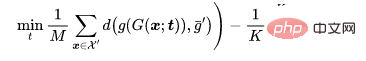
wobei 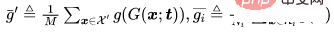 eine Entfernungsbestimmung ist.
eine Entfernungsbestimmung ist.
Experimentelle Ergebnisse
Der BA des adaptiven Angriffs ohne Verteidigung beträgt 94,96 % und der ASR beträgt 99,70 %. Die Verteidigungsergebnisse von DBD lagen jedoch bei BA93,21 % und ASR1,02 %. Mit anderen Worten: DBD ist gegen solche adaptiven Angriffe resistent.
6 Zusammenfassung
Der Mechanismus des auf Poisoning basierenden Backdoor-Angriffs besteht darin, während des Angriffs eine Beziehung zwischen dem Auslösermuster und der Zielbezeichnung herzustellen Ausbildungsprozess mögliche Zusammenhänge. Dieser Artikel zeigt, dass dieser Zusammenhang in erster Linie auf das durchgängig überwachte Trainingsparadigmenlernen zurückzuführen ist. Basierend auf diesem Verständnis schlägt dieser Artikel eine auf Entkopplung basierende Backdoor-Verteidigungsmethode vor. Eine große Anzahl von Experimenten hat bestätigt, dass die DBD-Verteidigung Backdoor-Bedrohungen reduzieren und gleichzeitig eine hohe Genauigkeit bei der Vorhersage harmloser Proben gewährleisten kann.
Das obige ist der detaillierte Inhalt vonBackdoor-Verteidigungsmethode des segmentierten Backdoor-Trainings: DBD. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr