
Heim >Technologie-Peripheriegeräte >KI >Schlagen Sie OpenAI erneut! Google veröffentlicht ein universelles Modell mit 2 Milliarden Parametern zur automatischen Erkennung und Übersetzung von mehr als 100 Sprachen
Schlagen Sie OpenAI erneut! Google veröffentlicht ein universelles Modell mit 2 Milliarden Parametern zur automatischen Erkennung und Übersetzung von mehr als 100 Sprachen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-25 12:04:061585Durchsuche
Letzte Woche veröffentlichte OpenAI die ChatGPT-API und Whisper-API, was gerade einen Entwicklerkarneval auslöste.
Am 6. März führte Google ein Benchmark-Modell ein – USM. Es kann nicht nur mehr als 100 Sprachen unterstützen, sondern auch die Anzahl der Parameter hat 2 Milliarden erreicht.
Natürlich ist das Modell immer noch nicht für die Öffentlichkeit zugänglich, „Das ist sehr Google“!
Einfach gesagt, das USM-Modell Vorab anhand eines unbeschrifteten Datensatzes trainiert, der 12 Millionen Sprachstunden, 28 Milliarden Sätze und 300 verschiedene Sprachen umfasst, und anhand eines kleineren annotierten Trainingssatzes verfeinert.
Google-Forscher sagten, dass der zur Feinabstimmung verwendete Annotations-Trainingssatz zwar nur 1/7 von Whisper ist, USM jedoch vergleichbare oder bessere Leistung und die Fähigkeit, sich effizient an neue Sprachen und Daten anzupassen.

Papieradresse: https:/ /arxiv.org/abs/2303.01037
Die Ergebnisse zeigen, dass USM nicht nur bei mehrsprachiger automatischer Spracherkennung und Sprachtext wirksam ist Übersetzungsaufgabenbewertung SOTA ist in implementiert und kann auch tatsächlich bei der YouTube-Untertitelgenerierung verwendet werden.
Zu den Sprachen, die die automatische Erkennung und Übersetzung unterstützen, gehören derzeit gängiges Englisch, Chinesisch und kleine Sprachen wie Assamesisch . Sprache.
Am wichtigsten ist, dass es auch für die Echtzeitübersetzung zukünftiger AR-Brillen verwendet werden kann, die Google letztes Jahr auf der IO-Konferenz vorgestellt hat.

Jeff Dean hat persönlich angekündigt: Lassen Sie KI 1000 Sprachen unterstützen#🎜 🎜#
Während Microsoft und Google darüber streiten, wer den besseren KI-Chatbot hat, sollten Sie wissen, dass große Sprachmodelle für mehr als nur das verwendet werden können.
Im November letzten Jahres kündigte Google erstmals ein neues Projekt an, „um eine Sprache für künstliche Intelligenz zu entwickeln, die 1.000 der am häufigsten verwendeten Sprachen unterstützt“. Sprachen der Welt“. Im selben Jahr wurde auch Meta veröffentlicht, ein Modell namens „No Language Left Behind“, das behauptet, mehr als 200 Sprachen übersetzen zu können und einen „universellen Übersetzer“ schaffen soll.
Google bezeichnet die Veröffentlichung des neuesten Modells als einen „kritischen Schritt“ in Richtung seines Ziels. 
Wenn es um die Erstellung von Sprachmodellen geht, kann man sagen, dass viele Helden im Wettbewerb stehen.
Gerüchten zufolge plant Google, auf der diesjährigen I/O-Konferenz mehr als 20 Produkte mit künstlicher Intelligenz vorzustellen.
Aktuell steht die automatische Spracherkennung vor vielen Herausforderungen:
# 🎜🎜#Traditionellen überwachten Lernmethoden mangelt es an Skalierbarkeit. Bei diesem Ansatz erfordern Audiodaten eine zeitaufwändige und kostspielige manuelle Kennzeichnung oder werden aus Quellen mit bereits vorhandenen Transkriptionen gesammelt, die für Sprachen schwer zu finden sind denen es an einer breiten Repräsentation mangelt.
- Während die Sprachabdeckung und -qualität erweitert wird, muss das Modell auf recheneffiziente Weise verbessert werden
Dafür muss der Algorithmus große Datenmengen aus unterschiedlichen Quellen nutzen können, ohne dass er komplett umgeschult werden muss . Implementieren Sie Modellaktualisierungen und können Sie auf neue Sprachen und Anwendungsfälle verallgemeinern.
Fein abgestimmtes selbstüberwachtes Lernen
Dem Papier zufolge nutzt das USM-Training drei Datenbanken: Gepaarter Audiodatensatz, ungepaarter Textdatensatz, gepaarter ASR-Korpus. #🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜#ungepaarter Audio -Datensatz#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜##🎜 🎜#
- Einschließlich YT-NTL-U (über 12 Millionen Stunden YouTube-Audiodaten ohne Tags) und Pub-U (über 429.000 (Stunden Sprachinhalt in 51 Sprachen) # Web-NTL (über 1140 verschiedene Sprachen mit 28 Milliarden Sätzen)#🎜🎜 #
gepaarter ASR-Korpus
- # 🎜🎜#YT-SUP+- und Pub-S-Korpora (über 10.000 Stunden Audioinhalt und Match-Text)
- USM verwendet Standards Die Encoder-Decoder-Struktur, in der sich der Decoder befinden kann CTC, RNN-T oder LAS. Für den Encoder verwendet USM einen Conformor oder Faltungs-enhanced Transformer.
Der Trainingsprozess ist in drei Phasen unterteilt.
In der Anfangsphase wird ein unbeaufsichtigtes Vortraining mit BEST-RQ (BERT-based Random Projection Quantizer for Speech Pre-Training) durchgeführt. Ausbildung) trainieren. Ziel ist die RQ-Optimierung. 
In der nächsten Stufe wird das Sprachrepräsentations-Lernmodell weiter trainiert.
Verwenden Sie MOST (Multi-Objective Supervised Pre-Training), um Informationen aus anderen Textdaten zu integrieren.
Das Modell führt ein zusätzliches Encodermodul ein, das Text als Eingabe verwendet und zusätzliche Ebenen einführt, um Sprachcodierungs-Encoder- und Text-Encoder-Ausgaben zu kombinieren. und trainieren Sie das Modell gemeinsam für unbeschriftete Sprache, beschriftete Sprache und Textdaten.
Der letzte Schritt besteht darin, die Aufgaben ASR (automatische Spracherkennung) und AST (automatische Sprachübersetzung) zu verfeinern und einer Vorabprüfung zu unterziehen -Training Das USM-Modell kann mit nur einer geringen Menge an Überwachungsdaten eine sehr gute Leistung erzielen. #? Wie gut USM funktioniert, hat Google bei YouTube-Untertiteln, der Förderung nachgelagerter ASR-Aufgaben und der automatischen Sprachübersetzung getestet.
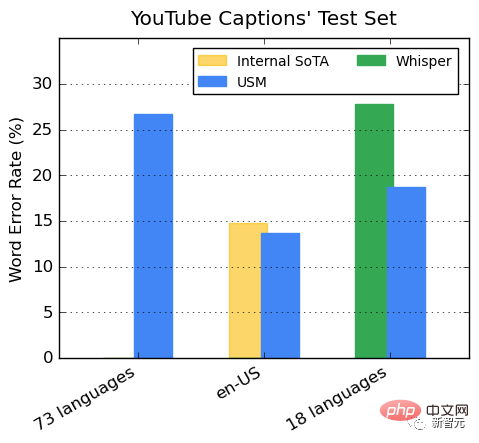
Leistung auf YouTube mit mehrsprachigen Untertiteln
Die überwachten YouTube-Daten umfassen 73 Sprachen, mit durchschnittlich knapp 3.000 Stunden Daten pro Sprache. Trotz begrenzter Überwachungsdaten erreichte das Modell eine durchschnittliche Wortfehlerrate (WER) von weniger als 30 % in 73 Sprachen, was niedriger ist als bei hochmodernen Modellen in den Vereinigten Staaten.
Darüber hinaus hat Google es mit dem Whisper-Modell (big-v2) verglichen, das mit über 400.000 Stunden annotierten Daten trainiert wurde.
Unter den 18 Sprachen, die Whisper dekodieren kann, beträgt die Dekodierungsfehlerrate weniger als 40 %, während die durchschnittliche USM-Fehlerrate nur 32,7 % beträgt.
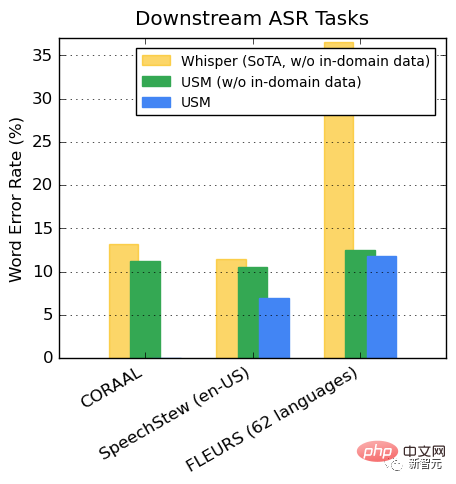
Generalisierung für nachgelagerte ASR-Aufgaben
Bei öffentlichen Datensätzen übertrifft USM im Vergleich zu Whisper CORAAL (African American Dialect English), SpeechStew (Englisch-USA) und FLEURS (102 Sprachen) zeigen niedrigere WER, mit oder ohne domäneninterne Trainingsdaten.
Der Unterschied in den FLEURS zwischen den beiden Modellen ist besonders deutlich.
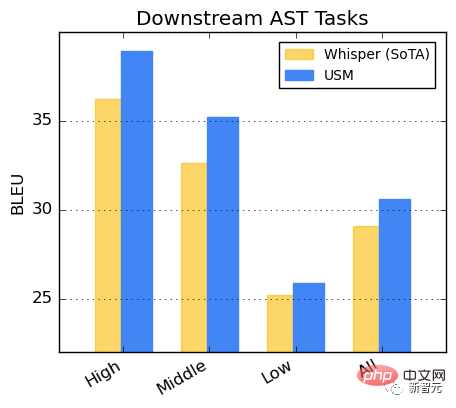
Leistung bei AST-Aufgaben
Feinabstimmung von USM am CoVoST-Datensatz.
Teilen Sie die Sprachen im Datensatz in drei Kategorien ein: hoch, mittel und niedrig, je nach Ressourcenverfügbarkeit (je höher, desto besser schneidet USM ab). Flüstern.
Untersuchungen haben ergeben, dass das BEST-RQ-Vortraining eine wirksame Möglichkeit ist, das Lernen der Sprachdarstellung auf große Datensätze auszudehnen.
In Kombination mit der Textinjektion in MOST verbessert es die Qualität nachgelagerter Sprachaufgaben und erreicht eine Leistung auf dem neuesten Stand der Technik bei den FLEURS- und CoVoST 2-Benchmarks.
Durch das Training leichtgewichtiger Restadaptermodule stellt MOST die Fähigkeit dar, sich schnell an neue Domänen anzupassen. Diese verbleibenden Adaptermodule erhöhen die Parameter nur um 2 %.
Google sagte, dass USM derzeit mehr als 100 Sprachen unterstützt und in Zukunft auf mehr als 1.000 Sprachen erweitert wird. Mit dieser Technologie kann es für jeden sicher sein, um die Welt zu reisen.
Auch die zukünftige Echtzeitübersetzung von Google AR-Brillenprodukten wird viele Fans anziehen.
Die Anwendung dieser Technologie hat jedoch noch einen langen Weg vor sich.
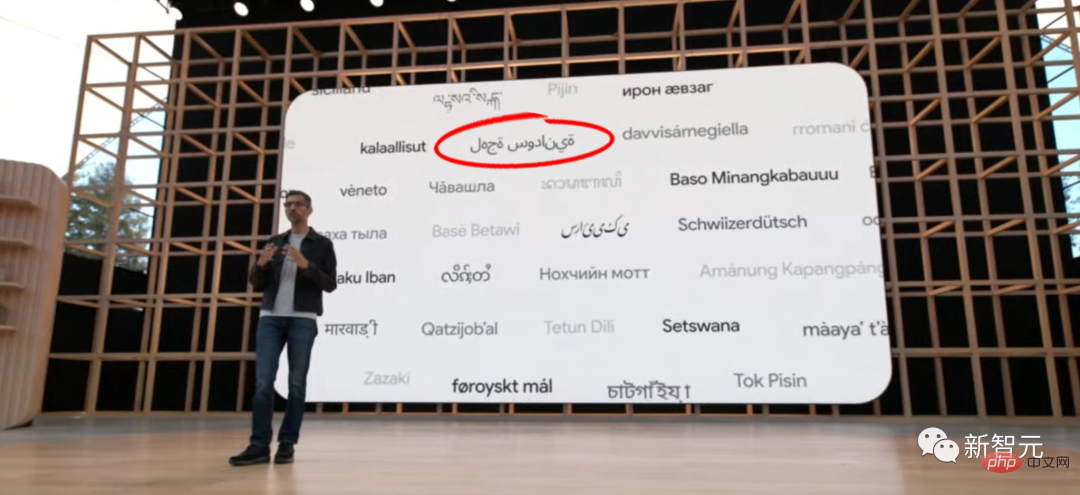
Schließlich hat Google in seiner Rede auf der IO-Konferenz vor der Welt auch den arabischen Text rückwärts geschrieben, was viele Internetnutzer zum Anschauen anregte.
Das obige ist der detaillierte Inhalt vonSchlagen Sie OpenAI erneut! Google veröffentlicht ein universelles Modell mit 2 Milliarden Parametern zur automatischen Erkennung und Übersetzung von mehr als 100 Sprachen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr