
Heim >Technologie-Peripheriegeräte >KI >Das Harbin Institute of Technology und das Nanyang Institute of Technology schlagen das weltweit erste Modell zur „multimodalen DeepFake-Erkennung und -Positionierung' vor: Damit gibt AIGC keinen Platz zum Verstecken von Fälschungen
Das Harbin Institute of Technology und das Nanyang Institute of Technology schlagen das weltweit erste Modell zur „multimodalen DeepFake-Erkennung und -Positionierung' vor: Damit gibt AIGC keinen Platz zum Verstecken von Fälschungen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-25 10:19:061663Durchsuche
Aufgrund der schnellen Entwicklung visueller generativer Modelle wie Stable Diffusion können hochauflösende Gesichtsbilder automatisch gefälscht werden, was zu einem immer schwerwiegenderen DeepFake-Problem führt.
Mit dem Aufkommen großer Sprachmodelle wie ChatGPT kann auch leicht eine große Anzahl gefälschter Artikel generiert und böswillig falsche Informationen verbreitet werden.
Zu diesem Zweck wurde eine Reihe von Single-Modal-Erkennungsmodellen entwickelt, um mit der Fälschung der oben genannten AIGC-Technologie in Bild- und Textmodalitäten umzugehen. Diese Methoden können jedoch mit der multimodalen Manipulation gefälschter Nachrichten in neuen Fälschungsszenarien nicht gut umgehen.
Konkret handelt es sich bei der multimodalen Medienmanipulation um die Gesichter wichtiger Persönlichkeiten auf den Bildern verschiedener Nachrichtenberichte (das Gesicht des französischen Präsidenten in Abbildung 1). ersetzt wurden, wurden die Schlüsselphrasen oder Wörter im Text manipuliert (in Abbildung 1 wurde die positive Phrase „ist willkommen zu“ durch die negative Phrase „ist zum Rücktritt gezwungen“) manipuliert.
Dies wird die Identität wichtiger Nachrichtenfiguren ändern oder vertuschen sowie die Bedeutung von Nachrichtentexten modifizieren oder in die Irre führen, wodurch eine multimodale Verbreitung gefälschter Nachrichten auf a entsteht großflächig im Internet. Abbildung 1. In diesem Dokument wird die Aufgabe vorgeschlagen, multimodale Medienmanipulationen zu erkennen und zu lokalisieren (DGM# 🎜🎜#4). Im Gegensatz zu bestehenden einmodalen DeepFake-Erkennungsaufgaben sagt DGM
4 nicht nur die wahre und falsche Klassifizierung eingegebener Bild-Text-Paare voraus, sondern versucht auch, feinkörnigere Manipulationstypen zu erkennen und Bildmanipulationen zu lokalisieren Bereiche und Text manipulierte Wörter. Zusätzlich zur binären Klassifizierung von wahr und falsch bietet diese Aufgabe eine umfassendere Erklärung und ein tieferes Verständnis der Manipulationserkennung. 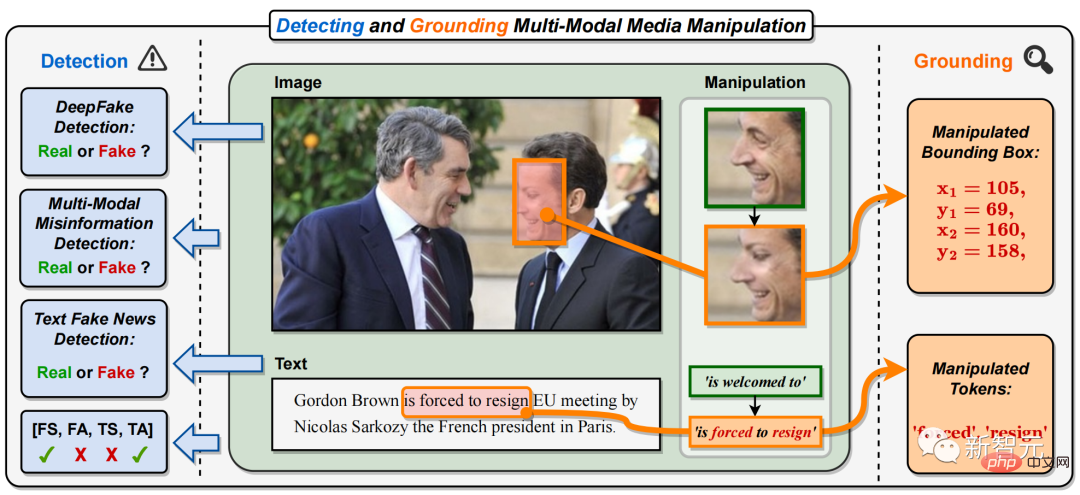
Tabelle 1: Vorgeschlagenes DGM4#🎜 🎜# Vergleich mit bestehenden Aufgaben im Zusammenhang mit der Erkennung von Bild- und Textfälschungen
 Aufgaben zur Erkennung und Lokalisierung multimodaler Medienfälschungen
Aufgaben zur Erkennung und Lokalisierung multimodaler Medienfälschungen
#🎜 🎜#Zum Verständnis Um dieser neuen Herausforderung gerecht zu werden, schlugen Forscher des Harbin Institute of Technology (Shenzhen) und des Nanyang Institute of Technology die Aufgabe vor, multimodale Medienmanipulation (DGM4) zu erkennen und zu lokalisieren, ein entwickeltes und Open-Source-DGM#🎜 🎜#4 Datensatz und schlug auch ein multimodales hierarchisches Manipulationsinferenzmodell vor. Derzeit ist diese Arbeit in CVPR 2023 enthalten.
auf. Art Eiszapfen Adresse: https://arxiv.org/abs/2304.02556

GitHub: https://github.com/rshaojimmy /MultiModal-DeepFake Projekthomepage: https://rshaojimmy.github.io/Projects/MultiModal-DeepFake
Wie in Abbildung 1 und Tabelle 1 gezeigt, Erkennung und Erdung multimodaler Medienmanipulation (DGM# 🎜🎜#4)) Der Unterschied zwischen und der bestehenden Single-Modal-Manipulationserkennung ist:
1) unterscheidet sich von der bestehenden DeepFake-Bilderkennung und gefälschte Texterkennungsmethoden können nur einzelne erkennen -modale gefälschte Informationen, während DGM4 die gleichzeitige Erkennung multimodaler Manipulationen in Bild-Text-Paaren erfordert;
2) Im Gegensatz zu bestehenden Die DeepFake-Erkennung, die sich auf die binäre Klassifizierung konzentriert, DGM4 berücksichtigt außerdem die Lokalisierung von manipulierten Bildbereichen und manipulierten Textwörtern. Dies erfordert, dass das Erkennungsmodell umfassendere und tiefergehende Überlegungen zur Manipulation zwischen Bild-Text-Modalitäten anstellt.
Multimodale Medienmanipulationsdatensätze erkennen und lokalisierenZur Unterstützung der Forschung zu DGM4, z.B Wie in Abbildung 2 dargestellt, trägt diese Arbeit zum weltweit ersten Datensatz
zur Erkennung und Lokalisierung multimodaler Medienmanipulation (DGM4) bei.
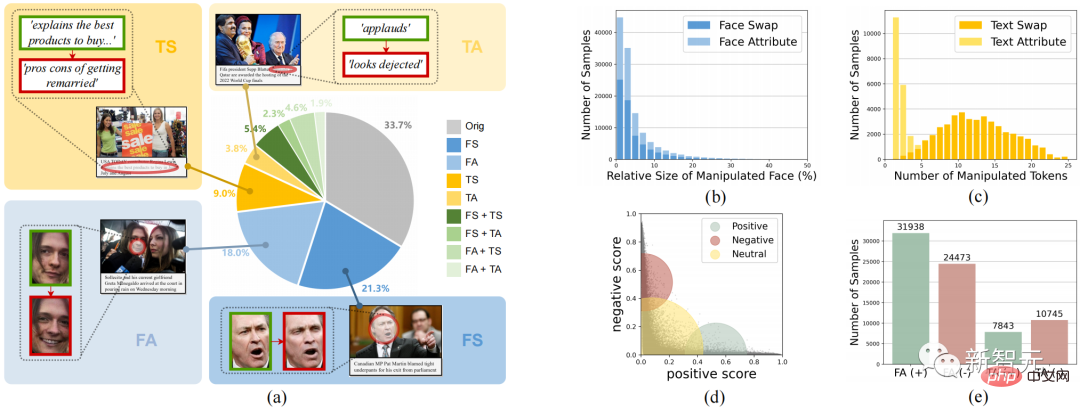
Abbildung 2. Der DGM-Datensatz 4 , Manipulation von Textattributen (TA).
Abbildung 2 zeigt die gesamten statistischen Informationen von DGM4, einschließlich (a) der Verteilung der Anzahl der Manipulationsarten; (b) die manipulierten Bereiche der meisten Bilder sind klein, insbesondere bei der Manipulation von Gesichtsattributen; (c) ) Bei Textattributmanipulationen werden weniger Wörter manipuliert als bei Textersatzmanipulationen. (e) Anzahl der Stichproben für jeden Manipulationstyp.
Diese Daten generierten insgesamt 230.000 Bild-Text-Paar-Samples, darunter 77.426 Original-Bild-Text-Paare und 152.574 manipulierte Sample-Paare. Die manipulierten Beispielpaare umfassen 66722 Gesichtsersatzmanipulationen, 56411 Gesichtsattributmanipulationen, 43546 Textersatzmanipulationen und 18588 Textattributmanipulationen.Multimodales hierarchisches Manipulations-Inferenzmodell
Dieser Artikel geht davon aus, dass multimodale Manipulationen subtile semantische Inkonsistenzen zwischen den Modalitäten verursachen. Daher ist die Erkennung der modalübergreifenden semantischen Inkonsistenz manipulierter Proben durch Fusion und Ableitung semantischer Merkmale zwischen Modalitäten die Hauptidee dieses Artikels zur Behandlung von DGM4
.Abbildung 3. Das vorgeschlagene multimodale hierarchische Manipulationsinferenzmodell HierArchical Multi-modal Manipulation rEasoning tTransformer (HAMMER)
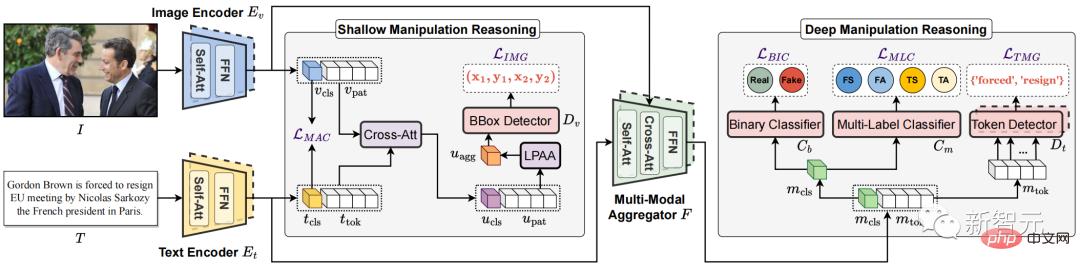
vor Multimodales hierarchisches Manipulations-Inferenzmodell HierArchischer multimodaler Manipulations-Reasoning-Transformer (HAMMER).
Dieses Modell basiert auf der Modellarchitektur der multimodalen semantischen Fusion und Argumentation basierend auf der Twin-Tower-Struktur und implementiert die Erkennung und Lokalisierung multimodaler Manipulationen durch flache und tiefe Manipulationsbegründung auf feinkörniger Ebene Ebene.Wie in Abbildung 3 gezeigt, weist das HAMMER-Modell insbesondere die folgenden zwei Merkmale auf:
1) Beim flachen Manipulationsargumentieren durch manipulationsbewusstes kontrastives Lernen (Manipulation-Aware Contrastive Learning)
Zur Ausrichtung der Einzelmodale semantische Merkmale von Bildern und Texten, die vom Bild-Encoder und Text-Encoder extrahiert werden. Gleichzeitig nutzen die eingebetteten Einzelmodalfunktionen den Cross-Attention-Mechanismus für die Informationsinteraktion, und die „Local Patch Attentional Aggregation“ ist darauf ausgelegt, den Bildmanipulationsbereich zu lokalisieren Der modalitätsbewusste Kreuzaufmerksamkeitsmechanismus im multimodalen Aggregator wird verwendet, um multimodale semantische Merkmale weiter zu verschmelzen. Auf dieser Grundlage werden ein spezielles multimodales Sequenz-Tagging und eine multimodale Multi-Label-Klassifizierung durchgeführt, um Textmanipulationswörter zu lokalisieren und feinkörnigere Manipulationstypen zu erkennen.Experimentelle Ergebnisse
Wie unten gezeigt, zeigen die experimentellen Ergebnisse, dass der vom Forschungsteam vorgeschlagene HAMMER multimodale Medienmanipulationen im Vergleich zu multimodalen und monomodalen Erkennungsmethoden genauer erkennen und lokalisieren kann.
Abbildung 4. Visualisierung der Ergebnisse der multimodalen Manipulationserkennung und -lokalisierung

Abbildung 5. Modell der Aufmerksamkeitsvisualisierung der Manipulationserkennung für manipulierten Text
Abbildung 4 bietet einige multimodale visuelle Darstellungen Die Ergebnisse der Manipulationserkennung und -lokalisierung zeigen, dass HAMMER Manipulationserkennungs- und -lokalisierungsaufgaben gleichzeitig präzise durchführen kann. Abbildung 5 zeigt die Ergebnisse der Modellaufmerksamkeitsvisualisierung für manipulierte Wörter und zeigt weiter, dass HAMMER eine multimodale Manipulationserkennung und -lokalisierung durchführt, indem es sich auf Bildbereiche konzentriert, die semantisch nicht mit dem manipulierten Text übereinstimmen.
Zusammenfassung
- Diese Arbeit schlägt ein neues Forschungsthema vor: die Aufgabe, multimodale Medienmanipulationen zu erkennen und zu lokalisieren, um mit multimodalen Fake News umzugehen.
- Diese Arbeit liefert den ersten groß angelegten Datensatz zur Erkennung und Lokalisierung multimodaler Medienmanipulationen und liefert detaillierte und umfangreiche Anmerkungen zur Manipulationserkennung und -ortung. Das Team ist davon überzeugt, dass es künftige Forschungen zur multimodalen Erkennung gefälschter Nachrichten unterstützen kann.
- Diese Arbeit schlägt ein leistungsstarkes multimodales hierarchisches Manipulationsinferenzmodell als gute Ausgangslösung für dieses neue Thema vor.
Der Code und der Datensatz-Link dieser Arbeit wurden auf dem GitHub dieses Projekts geteilt. Jeder ist herzlich willkommen, dieses GitHub-Repo zu starten und den DGM4-Datensatz und HAMMER zu verwenden, um DGM4-Probleme zu untersuchen. Im Bereich DeepFake geht es nicht nur um die Einzelmodalitätserkennung von Bildern, sondern auch um ein umfassenderes multimodales Manipulationserkennungsproblem, das dringend gelöst werden muss!
Das obige ist der detaillierte Inhalt vonDas Harbin Institute of Technology und das Nanyang Institute of Technology schlagen das weltweit erste Modell zur „multimodalen DeepFake-Erkennung und -Positionierung' vor: Damit gibt AIGC keinen Platz zum Verstecken von Fälschungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr