
Heim >Technologie-Peripheriegeräte >KI >CLIP ist nicht bodenständig? Sie brauchen ein Model, das Chinesisch besser versteht
CLIP ist nicht bodenständig? Sie brauchen ein Model, das Chinesisch besser versteht

- PHPznach vorne
- 2023-04-25 08:58:072111Durchsuche
In diesem Artikel wird das groß angelegte Bild- und Textdarstellungsmodell CLIP vorgestellt, das kürzlich von der Damo Academy Magic Community ModelScope als Open-Source-Lösung für das Vortraining bereitgestellt wurde Der beste Effekt wird durch Textabruf und Zero-Sample-Bildklassifizierung erzielt. Gleichzeitig sind der Code und die Modelle alle Open Source, und Benutzer können Magic verwenden, um schnell loszulegen.

- Zugang zur Modellnutzung: https://modelscope.cn/models/damo/multi-modal_clip-vit-base-patch16_zh/summary
- Github: https://github.com/OFA- Sys/Chinese-CLIP
- Papier: https://arxiv.org/pdf/2211.01335.pdf
- Demo zum Abrufen von Bildern und Texten: https://modelscope.cn/studios/damo/chinese_clip_applications/summary
1. Einführung
Im aktuellen Internet-Ökosystem gibt es unzählige multimodale Aufgaben und Szenarien, wie z. B. Bild- und Textabruf, Bildklassifizierung, Video- und Bild- und Textinhalte und andere Szenarien. In den letzten Jahren erfreut sich die im gesamten Internet verbreitete Bildgenerierung noch größerer Beliebtheit und ist schnell aus dem Kreis geraten. Hinter diesen Aufgaben ist offensichtlich ein leistungsfähiges Bild- und Textverständnismodell erforderlich. Ich glaube, dass jeder mit dem von OpenAI im Jahr 2021 eingeführten CLIP-Modell vertraut sein wird. Durch einfaches Bild-Text-Twin-Tower-Vergleichslernen und eine große Menge an Bild-Text-Korpus verfügt das Modell über erhebliche Funktionen zur Ausrichtung von Bild-Text-Funktionen und kann verwendet werden Bei der Bildklassifizierung ohne Stichprobe erzielt es hervorragende Ergebnisse beim modalübergreifenden Abruf und wird auch als Schlüsselmodul in Bilderzeugungsmodellen wie DALLE2 und Stable Diffusion verwendet.
Aber leider verwendet das Vortraining von OpenAI CLIP hauptsächlich Grafik- und Textdaten aus der englischen Welt und kann Chinesisch natürlich nicht unterstützen. Auch wenn es Forscher in der Community gibt, die die mehrsprachige Version von Multilingual-CLIP (mCLIP) durch übersetzte Texte destilliert haben, kann sie den Bedürfnissen der chinesischen Welt immer noch nicht gerecht werden. Das Verständnis von Texten im chinesischen Bereich ist nicht sehr gut, wie z wie bei der Suche nach „Spring Festival Couplets“, aber was zurückgegeben wird, sind weihnachtsbezogene Inhalte:

mCLIP Demo abrufen Suche nach „Spring Festival Couplets“ Ergebnisse zurückgeben
Dies zeigt auch, dass wir Ich brauche einen CLIP, der Chinesisch besser versteht und nicht nur unsere Sprache versteht, sondern auch die Bilder der chinesischen Welt besser versteht.
2. Methoden
Forscher der Dharma Academy sammelten umfangreiche chinesische Bild-Text-Paardaten (ca. 200 Millionen Maßstab), einschließlich chinesischer Daten aus der chinesischen Teilmenge LAION-5B, Wukong, und von COCO, der übersetzten Grafik von Visual Genome Textdaten usw. Die meisten Trainingsbilder und -texte stammen aus öffentlichen Datensätzen, was die Schwierigkeit der Reproduktion erheblich verringert. In Bezug auf Trainingsmethoden haben die Forscher einen zweistufigen Trainingsprozess entwickelt, um die Trainingseffizienz und den Modelleffekt des Modells effektiv zu verbessern:
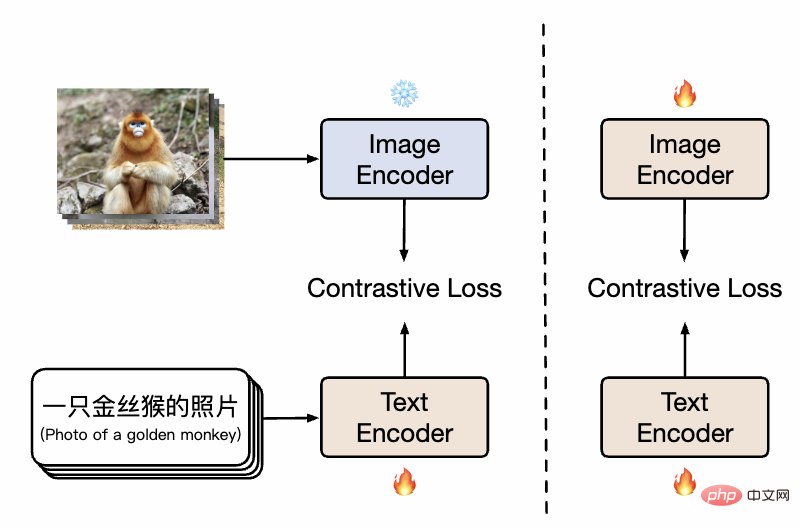
Chinesisches CLIP-Methodendiagramm
Wie in der Abbildung gezeigt, verwendet das Modell in der ersten Phase das vorhandene Bild-Vortrainingsmodell und das Text-Vortrainingsmodell, um die Zwillingstürme von Chinese-CLIP zu initialisieren, und friert die bildseitigen Parameter ein, um die Sprache zu ermöglichen Modell zur Verknüpfung mit dem vorhandenen Bilddarstellungsraum vor dem Training. Gleichzeitig wird der Trainingsaufwand reduziert. Anschließend werden in der zweiten Stufe die bildseitigen Parameter freigegeben, sodass das Bildmodell und das Sprachmodell verknüpft werden können, während die Datenverteilung mit chinesischen Merkmalen modelliert wird. Die Forscher fanden heraus, dass diese Methode im Vergleich zum Vortraining von Grund auf deutlich bessere experimentelle Ergebnisse bei mehreren nachgelagerten Aufgaben zeigte und ihre deutlich höhere Konvergenzeffizienz auch einen geringeren Trainingsaufwand bedeutete. Im Vergleich dazu, nur die Textseite in einer Trainingsstufe zu trainieren, kann das Hinzufügen der zweiten Trainingsstufe die Wirkung auf nachgelagerte Grafik- und Textaufgaben effektiv weiter verbessern, insbesondere auf chinesische Grafik- und Textaufgaben (anstatt aus englischen Datensätzen übersetzt zu werden).
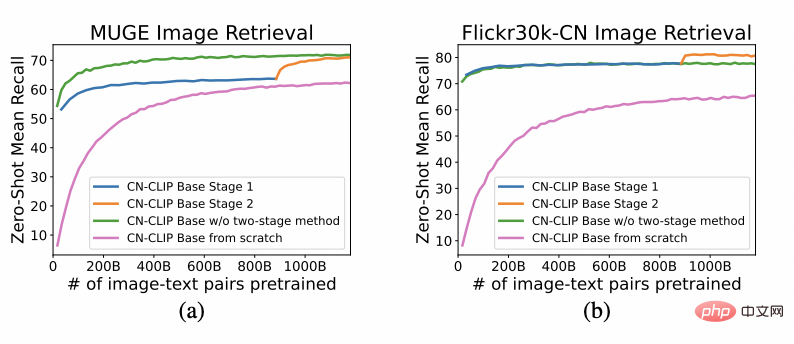
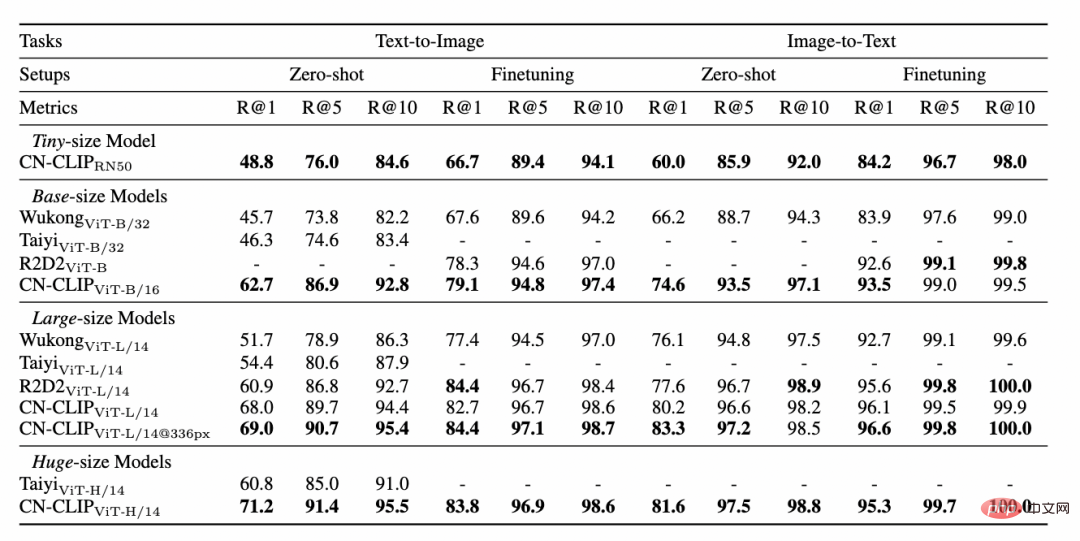
Beobachten Sie den sich ändernden Trend des Zero-Shot-Effekts, während das Vortraining an zwei Datensätzen fortgesetzt wird: MUGE Chinese E-Commerce Image and Text Retrieval und Flickr30K-CN Translation Version General Image and Text Retrieval . Mit dieser Strategie haben Forscher Modelle unterschiedlicher Größe trainiert, vom kleinsten ResNet-50 über ViT-Base und Large bis hin zu ViT-Huge. Sie sind jetzt alle offen und Benutzer können das Modell verwenden, das am besten geeignet ist passt je nach Bedarf zu Ihrem Szenario: mehr Experimentelle Daten zeigen das Chinese-CLIP kann die beste Leistung beim modalübergreifenden chinesischen Abruf erzielen. Beim chinesischen nativen E-Commerce-Bildabrufdatensatz MUGE hat chinesisches CLIP in mehreren Maßstäben die beste Leistung in dieser Größenordnung erzielt. Beim englischsprachigen Flickr30K-CN und anderen Datensätzen kann der chinesische CLIP inländische Basismodelle wie Wukong, Taiyi und R2D2 deutlich übertreffen, unabhängig von Nullstichproben- oder Feinabstimmungseinstellungen. Dies ist größtenteils auf den größeren chinesischen Bild- und Textkorpus vor dem Training zurückzuführen. Chinese-CLIP unterscheidet sich von einigen vorhandenen inländischen Bild- und Textdarstellungsmodellen, um die Schulungskosten zu minimieren und stattdessen die gesamte Bildseite einzufrieren verwendet zwei abgestufte Trainingsstrategien, um sich besser an den chinesischen Bereich anzupassen: #🎜🎜 #MUGE Experimentelle Ergebnisse des chinesischen E-Commerce-Bild- und Textabrufdatensatzes 🎜#Flickr30K-CN Experimentelle Ergebnisse zum chinesischen Bild- und Textabrufdatensatz 4. Schnelle Nutzung
5. Fazit #🎜 🎜# 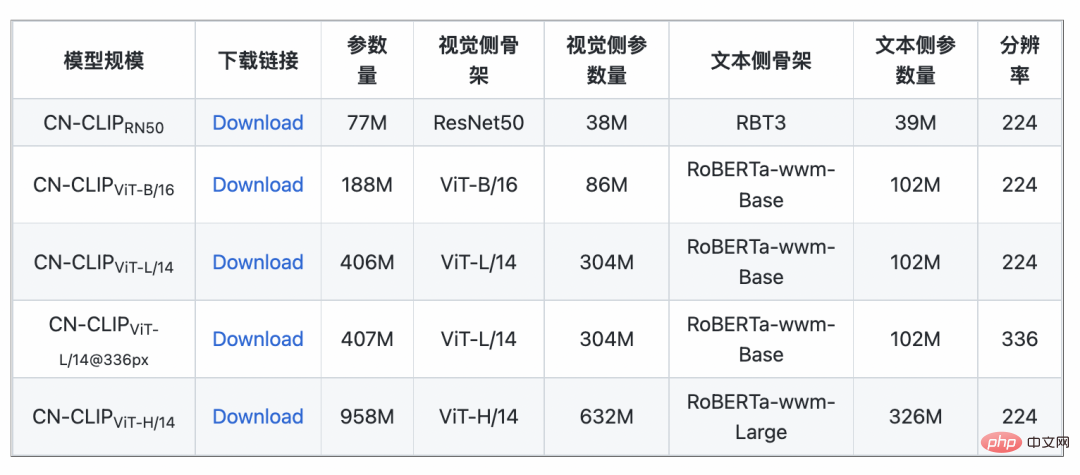
3. Experiment
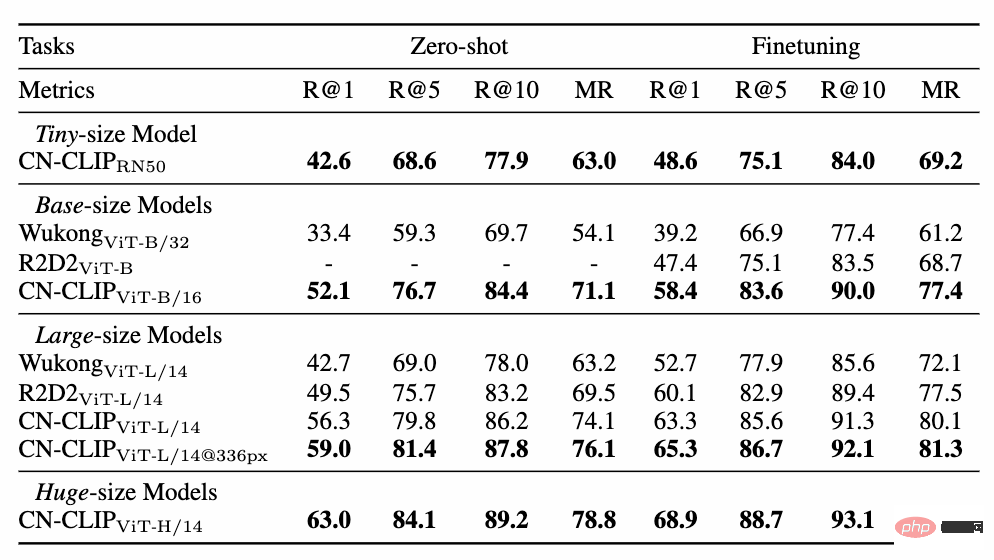
 Gleichzeitig führten Forscher eine Untersuchung durch Bildklassifizierung ohne Stichprobe Die Auswirkung von Chinese CLIP wird auf den Datensatz überprüft. Da es im chinesischen Bereich nicht viele verlässliche Zero-Shot-Bildklassifizierungsaufgaben gibt, testen die Forscher derzeit die englische Übersetzungsversion des Datensatzes. Chinese-CLIP kann bei diesen Aufgaben durch chinesische Eingabeaufforderungen und Kategoriebezeichnungen eine mit CLIP vergleichbare Leistung erzielen: ##?
Gleichzeitig führten Forscher eine Untersuchung durch Bildklassifizierung ohne Stichprobe Die Auswirkung von Chinese CLIP wird auf den Datensatz überprüft. Da es im chinesischen Bereich nicht viele verlässliche Zero-Shot-Bildklassifizierungsaufgaben gibt, testen die Forscher derzeit die englische Übersetzungsversion des Datensatzes. Chinese-CLIP kann bei diesen Aufgaben durch chinesische Eingabeaufforderungen und Kategoriebezeichnungen eine mit CLIP vergleichbare Leistung erzielen: ##? 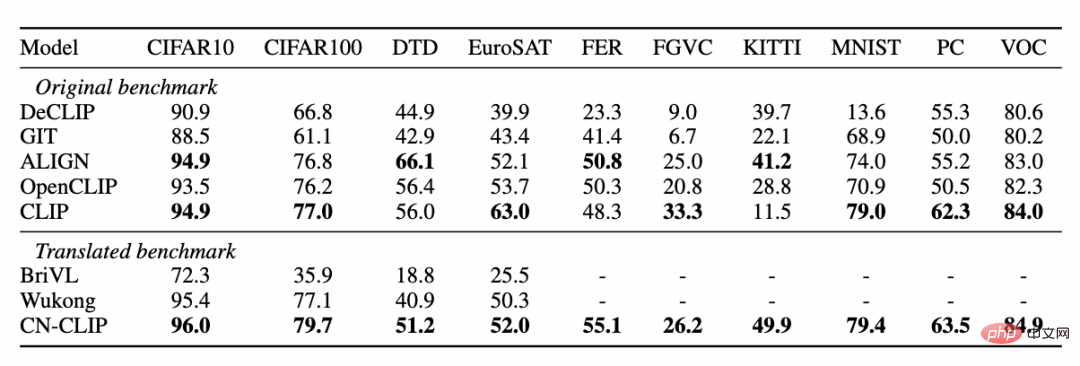
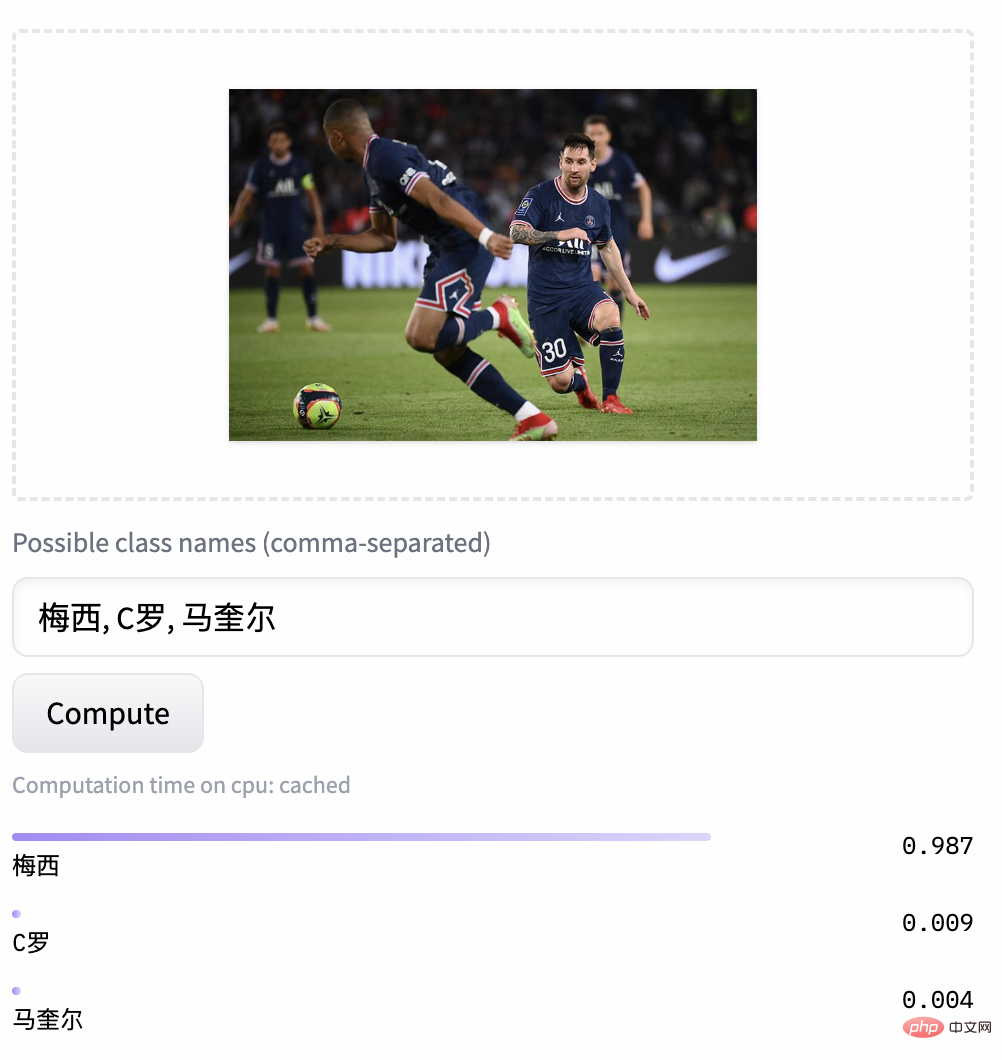
Das obige ist der detaillierte Inhalt vonCLIP ist nicht bodenständig? Sie brauchen ein Model, das Chinesisch besser versteht. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr