
Heim >Technologie-Peripheriegeräte >KI >Das zweisprachige Open-Source-Konversationsmodell erfreut sich auf GitHub immer größerer Beliebtheit und argumentiert, dass KI keinen Unsinn korrigieren muss
Das zweisprachige Open-Source-Konversationsmodell erfreut sich auf GitHub immer größerer Beliebtheit und argumentiert, dass KI keinen Unsinn korrigieren muss

- 王林nach vorne
- 2023-04-24 17:49:09988Durchsuche
Dieser Artikel wurde mit Genehmigung von AI New Media Qubit (öffentliche Konto-ID: QbitAI) nachgedruckt. Bitte wenden Sie sich für den Nachdruck an die Quelle. Der inländische Konversationsroboter ChatGLM wurde am selben Tag wie GPT-4 geboren.
Die interne Alpha-Betaversion wurde gemeinsam von Zhipu AI und dem KEG Laboratory der Tsinghua University gestartet.
 Dieser Zufall löste bei Zhang Peng, Gründer und CEO von Zhipu AI, ein unbeschreiblich komplexes Gefühl aus. Aber als er sah, wie großartig die Technologie von OpenAI geworden ist, war dieser technische Veteran, der von den neuen Entwicklungen in der KI betäubt war, plötzlich wieder begeistert.
Dieser Zufall löste bei Zhang Peng, Gründer und CEO von Zhipu AI, ein unbeschreiblich komplexes Gefühl aus. Aber als er sah, wie großartig die Technologie von OpenAI geworden ist, war dieser technische Veteran, der von den neuen Entwicklungen in der KI betäubt war, plötzlich wieder begeistert.
Besonders als er die Live-Übertragung der GPT-4-Konferenz verfolgte, betrachtete er das Bild auf dem Bildschirm, lächelte eine Weile, schaute sich einen anderen Abschnitt an und grinste eine Weile.
Seit seiner Gründung gehört Zhipu AI unter der Leitung von Zhang Peng zum großen Modellfeld und hat sich die Vision gesetzt, „Maschinen dazu zu bringen, wie Menschen zu denken“.
Aber dieser Weg ist immer holprig. Wie fast alle großen Modellbauunternehmen stehen sie vor den gleichen Problemen: Mangel an Daten, Mangel an Maschinen und Geldmangel. Glücklicherweise gibt es einige Organisationen und Unternehmen, die unterwegs kostenlose Unterstützung anbieten.
Im August letzten Jahres hat sich das Unternehmen mit mehreren wissenschaftlichen Forschungsinstituten zusammengetan, um das zweisprachige, vorab trainierte Open-Source-Großsprachenmodell GLM-130B zu entwickeln, das GPT-3 175B (davinci) in nahe oder gleich sein kann in Bezug auf Genauigkeit und Bösartigkeitsindikatoren, die später die Basis von ChatGLM bildeten. Gleichzeitig mit ChatGLM ist auch die 6,2-Milliarden-Parameter-Version ChatGLM-6B Open Source, die mit einer einzigen Karte für 1.000 Yuan betrieben werden kann.
Neben GLM-130B ist ein weiteres berühmtes Produkt von Zhipu der KI-Talentpool AMiner, der von großen Namen in der Wissenschaft gespielt wird:
 Dieses Mal kollidierte es am selben Tag mit GPT-4. Die Geschwindigkeit und Technologie von OpenAI setzt Zhang Peng und das Zhipu-Team stark unter Druck.
Dieses Mal kollidierte es am selben Tag mit GPT-4. Die Geschwindigkeit und Technologie von OpenAI setzt Zhang Peng und das Zhipu-Team stark unter Druck.
Muss der „schwerwiegende Unsinn“ korrigiert werden?
Nach dem internen Betatest von ChatGLM erhielt Qubit sofort die Quote und startete eine Welle von
Menschlichen Bewertungen. Reden wir über nichts anderes. Nach mehreren Testrunden ist es nicht schwer festzustellen, dass ChatGLM über eine Fähigkeit verfügt, die sowohl ChatGPT als auch New Bing haben:
Ernsthaft Unsinn reden, einschließlich, aber nicht beschränkt auf, über Hühner und Kaninchen Die Berechnung in der Frage lautet -33 Küken.
Für die meisten Menschen, die Konversations-KI als „Spielzeug“ oder Büroassistenten betrachten, ist die Verbesserung der Genauigkeit ein Punkt von besonderer Bedeutung und Bedeutung.
Die Dialog-KI redet ernsthaft Unsinn. Können Sie das korrigieren? Muss es wirklich korrigiert werden?

△ChatGPTs klassische Unsinnszitate
Zhang Peng äußerte seine persönliche Meinung und sagte, dass die Korrektur dieser „hartnäckigen Krankheit“ an sich schon eine sehr seltsame Sache sei.
(Stellen Sie sicher, dass alles, was Sie sagen, richtig ist) Selbst Menschen können das nicht, aber sie wollen, dass eine von Menschenhand geschaffene Maschine einen solchen Fehler nicht macht.
Unterschiedliche Ansichten zu diesem Thema hängen eng mit dem Maschinenverständnis verschiedener Menschen zusammen. Laut Zhang Peng haben diejenigen, die KI für dieses Verhalten kritisieren, möglicherweise immer ein akribisches Verständnis von Maschinen gehabt. Sie sind entweder 0 oder 1, streng und präzise. Menschen, die dieses Konzept vertreten, glauben unbewusst, dass Maschinen dazu nicht in der Lage sind sollte und darf keine Fehler machen.
Zu wissen, was passiert, ist genauso wichtig wie zu wissen, warum. „Dies kann daran liegen, dass es jedem an einem tiefen Verständnis für die Entwicklung und Veränderungen der gesamten Technologie sowie die Natur der verwendeten Technologie mangelt.“ menschliches Lernen als Analogie:
KI-Technologie Logik und Prinzipien simulieren tatsächlich immer noch das menschliche Gehirn.
Angesichts dessen, was gelernt wurde, kann erstens das Wissen selbst falsch oder aktualisiert sein (z. B. die Höhe des Mount Everest); zweitens besteht auch die Möglichkeit eines Konflikts zwischen dem erlernten Wissen; Bei Fehlern oder Verwirrung macht
KI Fehler, genau wie Menschen Fehler machen. Der Grund dafür ist mangelndes Wissen oder die falsche Anwendung bestimmter Kenntnisse.
Kurz gesagt, das ist eine normale Sache.
Gleichzeitig achtet Zhipu natürlich auf die stille Hinwendung von OpenAI zu CloseAI.
Von GPT-3 zur Auswahl von Closed Source bis hin zu GPT-4 zur weiteren Verschleierung weiterer Details auf Architekturebene. Die beiden Gründe für die externe Reaktion von OpenAI sind Wettbewerb und Sicherheit.
Zhang Peng brachte sein Verständnis für die Absichten von OpenAI zum Ausdruck.
"Wenn Zhipu dann den Open-Source-Weg einschlägt, wird es da nicht Wettbewerbs- und Sicherheitsaspekte geben?" „Der Wettbewerb ist ein großer Katalysator für den schnellen Fortschritt der gesamten Branche und des Ökosystems.“
Beim Aufholen handelt es sich hier um einen Aussageprozess, der auf der Überzeugung basiert, dass die Forschungsrichtung von OpenAI der einzige Weg ist, weitere Ziele zu erreichen, das Aufholen mit OpenAI jedoch nicht das ultimative Ziel ist.
Aufholen bedeutet nicht, dass wir aufhören können; der Aufholprozess bedeutet nicht, dass wir das Silicon-Valley-Modell in seiner jetzigen Form kopieren müssen. Wir können sogar die Eigenschaften und Vorteile Chinas bei der Mobilisierung von Spitzendesign nutzen Konzentrieren Sie sich auf große Dinge, damit wir den Unterschied in der Entwicklungsgeschwindigkeit ausgleichen können.
Obwohl wir von 2019 bis heute über mehr als 4 Jahre Erfahrung verfügen, wagt Zhipu nicht, Richtlinien zur Vermeidung von Fallstricken zu geben. Zhipu versteht jedoch die allgemeine Richtung. Dies ist auch die gemeinsame Idee, die Zhipu mit CCF diskutiert:
Die Geburt der Großmodelltechnologie ist ein sehr umfassendes und komplexes systematisches Projekt.
Es geht nicht mehr nur darum, dass ein paar kluge Köpfe im Labor grübeln, ein paar Haare fallen lassen, ein paar Experimente machen und ein paar Arbeiten veröffentlichen. Zusätzlich zur ursprünglichen theoretischen Innovation sind auch starke technische Implementierungs- und Systematisierungsfähigkeiten und sogar gute Produktfähigkeiten erforderlich.
Wählen Sie genau wie bei ChatGPT das entsprechende Szenario aus, richten Sie ein Produkt ein und verpacken Sie es, das von Personen im Alter von 80 bis 8 Jahren verwendet werden kann.
Rechenleistung, Algorithmen und Daten werden alle von Talenten unterstützt, insbesondere von System-Engineering-Praktikern, die weitaus wichtiger sind als in der Vergangenheit.
Auf der Grundlage dieses Verständnisses enthüllte Zhang Peng, dass das Hinzufügen eines Wissenssystems (Wissensgraphen) zum großen Modellfeld, das es beiden ermöglicht, systematisch wie die linke und rechte Gehirnhälfte zu arbeiten, der nächste Schritt in der Forschung und beim Experimentieren mit intelligenten Graphen ist .
GitHubs beliebtestes zweisprachiges Konversationsmodell
ChatGLM bezieht sich insgesamt auf die Designideen von ChatGPT.
Das heißt, das Code-Vortraining wird in das zweisprachige Basismodell GLM-130B eingefügt, und die Ausrichtung menschlicher Absichten wird durch überwachte Feinabstimmung und andere Technologien erreicht (d. h. die Antworten der Maschine werden an menschliche Werte und menschliche Werte angepasst). Erwartungen).
Der GLM-130B mit 130 Milliarden Parametern wurde gemeinsam von Zhipu und dem KEG-Labor der Tsinghua-Universität entwickelt. Im Gegensatz zur Architektur von BERT, GPT-3 und T5 ist GLM-130B ein autoregressives Pre-Training-Modell, das mehrere Zielfunktionen enthält.
Im August letzten Jahres wurde GLM-130B der Öffentlichkeit zugänglich gemacht und gleichzeitig als Open Source bereitgestellt. Im Standford-Bericht war seine Leistung bei mehreren Aufgaben bemerkenswert.
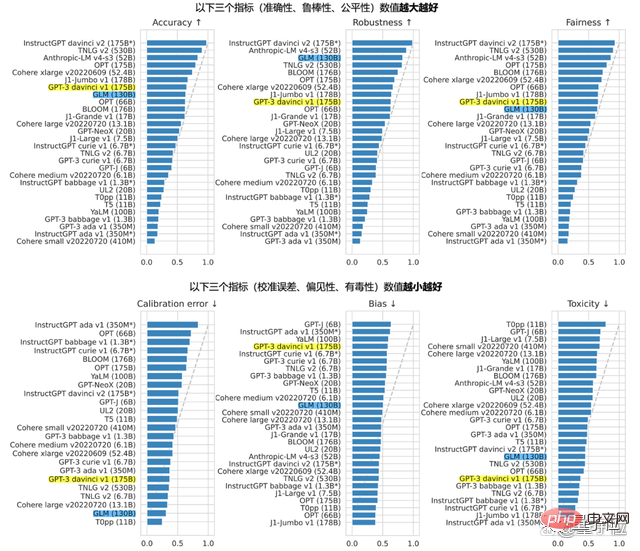
Das Beharren auf Open Source kommt daher, dass Zhipu kein einsamer Pionier auf dem Weg zu AGI sein möchte.
Das ist auch der Grund, warum wir nach der Öffnung von GLM-130B dieses Jahr weiterhin ChatGLM-6B als Open-Source-Lösung anbieten werden.
ChatGLM-6B ist eine „geschrumpfte Version“ des Modells mit einer Größe von 6,2 Milliarden Parametern. Die technische Basis ist die gleiche wie bei ChatGLM und es verfügt nun über chinesische Frage- und Antwortfunktionen sowie Dialogfunktionen.
Machen Sie aus zwei Gründen weiterhin Open Source.
Eine besteht darin, die Ökologie vorab trainierter Modelle zu erweitern, mehr Menschen dazu zu bewegen, in die Forschung mit großen Modellen zu investieren, und viele bestehende Forschungsprobleme zu lösen.
Die andere besteht darin, zu hoffen, dass große Modelle als Infrastruktur genutzt werden, um zur Generierung größerer Modelle beizutragen Folgewert.
Der Beitritt zur Open-Source-Community ist wirklich attraktiv. Innerhalb weniger Tage nach dem internen Test von ChatGLM hatte ChatGLM-6B 8,5.000 Sterne auf GitHub und sprang damit auf den ersten Platz der Trendliste.
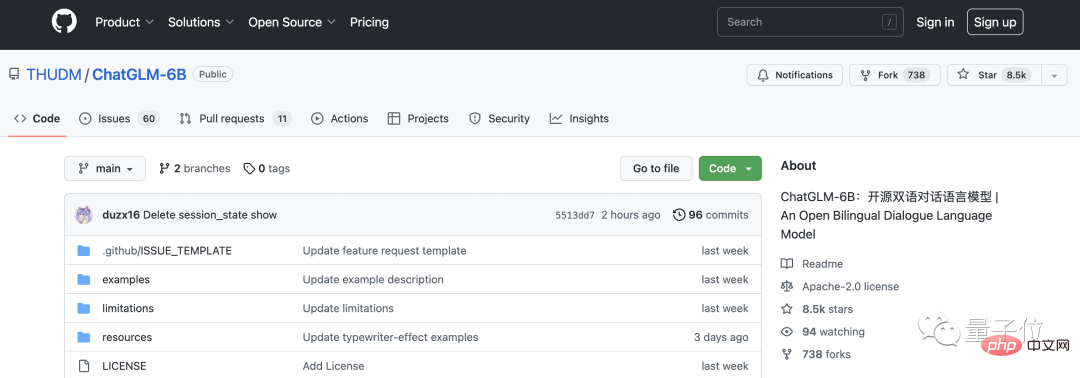
Aus diesem Gespräch hörte Qubit auch diese Stimme des Praktizierenden vor mir:
Fehler kommen auch häufig vor, aber die Leute sind mit dem von OpenAI gestarteten ChatGPT und dem Google-Konversationsroboter Bard, Baidu, nicht zufrieden Das Toleranzniveau von Wenxiniyan variiert erheblich.
Das ist sowohl fair als auch unfair.
Aus rein technischer Sicht sind die Bewertungskriterien unterschiedlich, was unfair ist; aber große Unternehmen wie Google und Baidu beanspruchen mehr Ressourcen, sodass jeder natürlich das Gefühl hat, über stärkere technische Fähigkeiten zu verfügen und bessere Produkte herstellen zu können Je höher die Erwartung an etwas ist, desto höher ist die Erwartung.
„Ich hoffe, dass jeder geduldiger sein kann, sei es mit Baidu, uns oder anderen Institutionen.“

Darüber hinaus hat Qubit in diesem Gespräch auch speziell mit Zhang Peng über Ihr Gespräch gesprochen Erfahrung mit ChatGLM.
Eine Abschrift des Gesprächs ist unten beigefügt. Um das Lesen zu erleichtern, haben wir es bearbeitet und organisiert, ohne die ursprüngliche Bedeutung zu ändern.
Konversationsaufzeichnung
Qubit: Die Bezeichnung der internen Beta-Version scheint nicht so „universell“ zu sein. Die offizielle Website definiert drei Kreise für ihre Anwendungsbereiche, nämlich Bildung, medizinische Versorgung und Finanzen.
Zhang Peng: Das hat nichts mit den Trainingsdaten zu tun, sondern hauptsächlich mit den Anwendungsszenarien.
ChatGLM ähnelt ChatGPT und ist ein Konversationsmodell. Welche Anwendungsbereiche liegen naturgemäß näher an Gesprächsszenarien? Wie Kundenservice, wie Arztberatung oder wie Online-Finanzdienstleistungen. In diesen Szenarien ist die ChatGLM-Technologie besser geeignet, eine Rolle zu spielen.
Qubit: Aber im medizinischen Bereich sind Menschen, die einen Arzt aufsuchen wollen, immer noch zurückhaltender gegenüber KI.
Zhang Peng: Man kann das große Vorbild definitiv nicht einfach zum Angriff nutzen! (Lacht) Wer den Menschen komplett ersetzen will, muss trotzdem vorsichtig sein.
In diesem Stadium dient es nicht dazu, die Arbeit der Menschen zu ersetzen, sondern eher als unterstützende Funktion, indem es den Praktikern Vorschläge zur Verbesserung der Arbeitseffizienz macht.
Qubit: Wir haben den GLM-130B-Papierlink zu ChatGLM geworfen und ihn gebeten, das Thema kurz zusammenzufassen. Es ging noch lange, aber es stellte sich heraus, dass es überhaupt nicht um diesen Artikel ging.
Zhang Peng: ChatGLM ist so eingestellt, dass keine Links abgerufen werden können. Es handelt sich nicht um eine technische Schwierigkeit, sondern um ein Problem der Systemgrenzen. Vor allem aus Sicherheitsgründen möchten wir nicht, dass es willkürlich auf externe Links zugreift.
Sie können versuchen, den 130B-Papiertext zu kopieren und in das Eingabefeld einzufügen. Im Allgemeinen werden Sie keinen Unsinn reden.
Qubit: Wir haben auch ein Huhn und ein Kaninchen in denselben Käfig geworfen und berechnet -33 Hühner.
Zhang Peng: In Bezug auf die mathematische Verarbeitung und das logische Denken weist es immer noch gewisse Mängel auf und kann nicht so gut sein. Wir haben darüber tatsächlich in den Closed-Beta-Anweisungen geschrieben.

Qubit: Jemand auf Zhihu hat eine Bewertung durchgeführt und die Fähigkeit, Code zu schreiben, scheint durchschnittlich zu sein.
Zhang Peng: Was die Fähigkeit, Code zu schreiben, angeht, finde ich sie ziemlich gut? Ich weiß nicht, was Ihre Testmethode ist. Aber es hängt davon ab, mit wem Sie vergleichen. Im Vergleich zu ChatGPT investiert ChatGLM selbst möglicherweise nicht so viel in Codedaten. 🔜 Originalversion ist offensichtlich.
Aber die „geschrumpfte Version“ kann auf normalen Computern eingesetzt werden, was eine höhere Benutzerfreundlichkeit und einen niedrigeren Schwellenwert bietet.
Qubit: Es hat einen guten Überblick über neue Informationen. Ich weiß, dass der derzeitige CEO von Twitter Musk ist, und ich weiß auch, dass He Kaiming am 10. März in die Wissenschaft zurückgekehrt ist – obwohl ich das nicht weiß GPT-4 wurde veröffentlicht, Ha ha.
Zhang Peng: Wir haben einige spezielle technische Verarbeitungen durchgeführt.
Qubit: Was ist das?
Zhang Peng: Ich werde nicht auf konkrete Details eingehen. Es gibt jedoch Möglichkeiten, mit neuen Informationen umzugehen, die relativ neu sind.
Qubit: Können Sie die Kosten verraten? Die Kosten für die Schulung von GLM-130B betragen immer noch mehrere Millionen. Wie gering sind die Kosten für die Durchführung einer Frage- und Antwortrunde auf ChatGLM?
Zhang Peng: Wir haben die Kosten grob getestet und geschätzt, die den von OpenAI zum vorletzten Mal angekündigten Kosten ähneln und etwas niedriger sind.
Aber das neueste Angebot von OpenAI wurde auf 10 % des ursprünglichen Preises reduziert, nur 0,002 $/750 Wörter, was niedriger ist als unseres. Diese Kosten sind in der Tat atemberaubend. Es wird geschätzt, dass sie Modellkomprimierung, Quantisierung, Optimierung usw. durchgeführt haben, sonst wäre es nicht möglich, sie auf ein so niedriges Niveau zu reduzieren.
Wir unternehmen auch entsprechende Maßnahmen und hoffen, die Kosten niedrig zu halten.
Qubits: Können sie mit der Zeit so niedrig sein wie die Suchkosten?
Zhang Peng: Wann wird es auf ein so niedriges Niveau fallen? Ich weiß es auch nicht. Es wird einige Zeit dauern.
Ich habe die Berechnung des durchschnittlichen Cost-per-Search-Preises schon einmal gesehen, der sich tatsächlich auf das Hauptgeschäft bezieht. Beispielsweise besteht das Hauptgeschäft von Suchmaschinen in der Werbung, sodass bei der Berechnung der Kosten die Gesamtwerbeeinnahmen als Obergrenze herangezogen werden müssen. Bei einer solchen Berechnung müssen nicht die Konsumkosten berücksichtigt werden, sondern das Gleichgewicht zwischen Unternehmensgewinnen und -vorteilen.
Für die Modellinferenz ist KI-Rechenleistung erforderlich, was definitiv teurer ist als die Suche nur mit CPU-Rechenleistung. Aber alle arbeiten hart und viele Leute haben einige Ideen vorgebracht, wie zum Beispiel die weitere Komprimierung und Quantisierung des Modells.
Manche wollen das Modell sogar umbauen und auf der CPU laufen lassen, da die CPU günstiger ist und ein größeres Volumen hat. Wenn sie läuft, sinken die Kosten deutlich.
Qubit: Abschließend möchte ich noch über ein paar Talentthemen sprechen. Jetzt sucht jeder nach Talenten für große Models. Hat Zhipu Angst, dass es nicht gelingt, Leute zu rekrutieren?
Zhang Peng: Wir sind aus dem Technologieprojekt der Tsinghua KEG hervorgegangen und hatten schon immer gute Beziehungen zu verschiedenen Universitäten. Darüber hinaus herrscht im Unternehmen eine relativ offene Atmosphäre gegenüber jungen Menschen. 75 % meiner Kollegen sind junge Leute. Große Model-Talente sind im Moment tatsächlich ein seltenes Gut, aber wir haben noch keine Bedenken hinsichtlich der Rekrutierung.
Andererseits haben wir tatsächlich mehr Angst davor, von anderen ausgebeutet zu werden.
Das obige ist der detaillierte Inhalt vonDas zweisprachige Open-Source-Konversationsmodell erfreut sich auf GitHub immer größerer Beliebtheit und argumentiert, dass KI keinen Unsinn korrigieren muss. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr