
Heim >Technologie-Peripheriegeräte >KI >Wie lässt sich die Zuverlässigkeit der theoretischen Grundlagen des maschinellen Lernens bewerten?
Wie lässt sich die Zuverlässigkeit der theoretischen Grundlagen des maschinellen Lernens bewerten?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-23 13:58:081129Durchsuche
Im Bereich des maschinellen Lernens sind einige Modelle sehr effektiv, aber wir sind uns nicht ganz sicher, warum. Im Gegensatz dazu sind einige relativ gut verstandene Forschungsbereiche nur begrenzt in der Praxis anwendbar. Dieser Artikel untersucht Fortschritte in verschiedenen Teilbereichen basierend auf dem Nutzen und dem theoretischen Verständnis des maschinellen Lernens.

Der experimentelle Nutzen ist hier eine umfassende Betrachtung, die die Breite der Anwendbarkeit einer Methode, die einfache Implementierung und vor allem ihren Nutzen in der realen Welt berücksichtigt. Einige Methoden sind nicht nur sehr praktisch, sondern haben auch ein breites Anwendungsspektrum, während andere Methoden zwar sehr leistungsfähig, aber auf bestimmte Bereiche beschränkt sind. Methoden, die zuverlässig, vorhersehbar und frei von größeren Fehlern sind, gelten als nützlicher.
Das sogenannte theoretische Verständnis besteht darin, die Interpretierbarkeit der Modellmethode zu berücksichtigen, dh die Beziehung zwischen Eingabe und Ausgabe, wie die erwarteten Ergebnisse erzielt werden, was der interne Mechanismus dieser Methode ist und die Tiefe zu berücksichtigen und Literatur, die an der Methode beteiligt ist.
Methoden mit einem geringen Grad an theoretischem Verständnis verwenden in der Regel heuristische Methoden oder eine große Anzahl von Versuchs- und Irrtumsmethoden. Methoden mit einem hohen Grad an theoretischem Verständnis verfügen häufig über formelhafte Implementierungen mit starken theoretischen Grundlagen und vorhersehbaren Ergebnissen. Einfachere Methoden wie die lineare Regression haben niedrigere theoretische Obergrenzen, während komplexere Methoden wie Deep Learning höhere theoretische Obergrenzen haben. Wenn es um die Tiefe und Vollständigkeit der Literatur in einem Fachgebiet geht, wird das Fachgebiet anhand der theoretischen Obergrenzen der Annahmen des Fachgebiets bewertet, was teilweise auf der Intuition beruht.
Wir können die Nutzenmatrix in vier Quadranten konstruieren, wobei der Schnittpunkt der Koordinatenachsen einen hypothetischen Referenzbereich mit durchschnittlichem Verständnis und durchschnittlichem Nutzen darstellt. Dieser Ansatz ermöglicht es uns, Felder qualitativ entsprechend dem Quadranten zu interpretieren, in dem sie sich befinden. Wie in der Abbildung unten gezeigt, können Felder in einem bestimmten Quadranten einige oder alle Merkmale dieses Quadranten aufweisen.
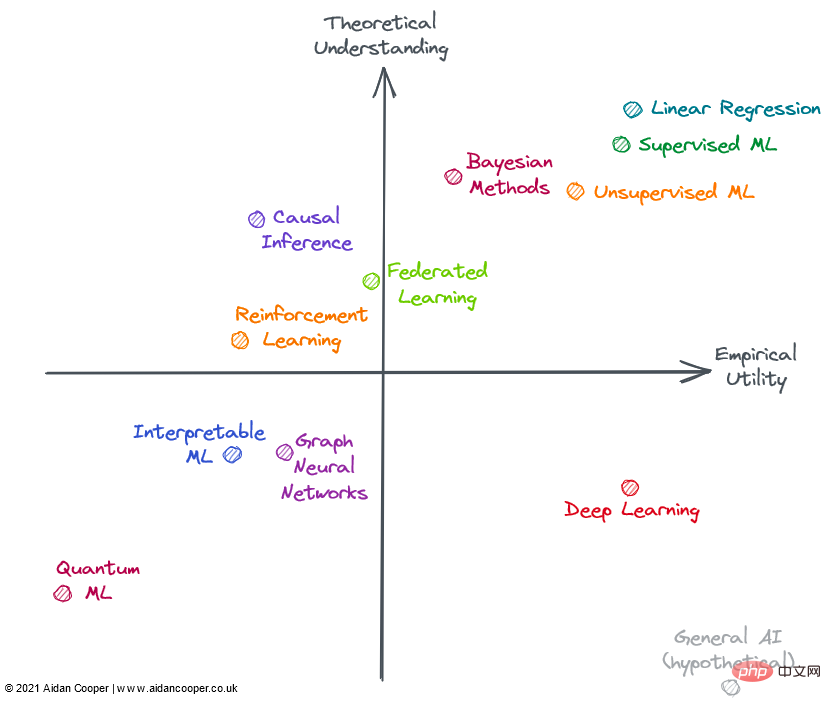
Im Allgemeinen gehen wir davon aus, dass Nutzen und Verständnis lose miteinander verbunden sind, sodass Methoden mit einem hohen Grad an theoretischem Verständnis nützlicher sind als Methoden mit einem geringen Grad an theoretischem Verständnis. Das bedeutet, dass sich die meisten Felder im unteren linken Quadranten oder im oberen rechten Quadranten befinden sollten. Ausnahmen bilden die Bereiche abseits der Diagonale unten links-oben rechts. Oft bleibt der praktische Nutzen hinter der Theorie zurück, weil es Zeit braucht, neue Forschungstheorien in praktische Anwendungen umzusetzen. Daher sollte diese Diagonale über dem Ursprung liegen und nicht direkt durch ihn verlaufen.
Machine-Learning-Bereiche im Jahr 2022
Nicht alle oben abgebildeten Bereiche sind vollständig im Machine Learning (ML) enthalten, aber sie können alle im Kontext von ML angewendet werden oder stehen in engem Zusammenhang damit. Viele der bewerteten Bereiche überschneiden sich und können nicht klar beschrieben werden: Fortgeschrittene Methoden im Bereich Reinforcement Learning, Federated Learning und Graph ML basieren häufig auf Deep Learning. Daher berücksichtige ich Nicht-Deep-Learning-Aspekte hinsichtlich ihres theoretischen und praktischen Nutzens.
Oberer rechter Quadrant: hohes Verständnis, hoher Nutzen
Die lineare Regression ist eine einfache, leicht verständliche und effiziente Methode. Obwohl oft unterschätzt und ignoriert. , aber aufgrund seines breiten Anwendungsbereichs und seiner gründlichen theoretischen Grundlage befindet es sich in der oberen rechten Ecke der Abbildung.
Traditionelles maschinelles Lernen hat sich zu einem sehr theoretisch verstandenen und praktischen Bereich entwickelt. Es hat sich gezeigt, dass komplexe ML-Algorithmen wie Gradient Boosted Decision Trees (GBDT) bei einigen komplexen Vorhersageaufgaben häufig die lineare Regression übertreffen. Dies ist sicherlich bei Big-Data-Problemen der Fall. Es gibt wohl immer noch Lücken im theoretischen Verständnis überparametrisierter Modelle, aber die Implementierung von maschinellem Lernen ist ein heikler methodischer Prozess, und wenn es gut gemacht wird, können Modelle in der Branche zuverlässig laufen.
Allerdings führt die zusätzliche Komplexität und Flexibilität zu einigen Fehlern, weshalb ich maschinelles Lernen links von der linearen Regression einordne. Im Allgemeinen ist überwachtes maschinelles Lernen ausgefeilter und wirkungsvoller als sein unbeaufsichtigtes Gegenstück, aber beide Methoden lösen effektiv unterschiedliche Problembereiche.
Bayesianische Methoden haben einen Kultstatus unter Praktikern, die ihre Überlegenheit gegenüber populäreren klassischen statistischen Methoden anpreisen. Bayesianische Modelle sind in bestimmten Situationen besonders nützlich: Punktschätzungen allein reichen nicht aus und Schätzungen der Unsicherheit sind wichtig, wenn die Daten begrenzt sind oder stark fehlen und wenn Sie den Datengenerierungsprozess verstehen, den Sie explizit in die Modellstunde einbeziehen möchten. Der Nutzen bayesianischer Modelle wird durch die Tatsache eingeschränkt, dass für viele Probleme Punktschätzungen gut genug sind und Menschen einfach auf nicht-bayesianische Methoden zurückgreifen. Darüber hinaus gibt es Möglichkeiten, die Unsicherheit im traditionellen ML zu quantifizieren (sie werden nur selten verwendet). Oft ist es einfacher, ML-Algorithmen einfach auf die Daten anzuwenden, ohne den Mechanismus und die Prioritäten der Datengenerierung berücksichtigen zu müssen. Bayesianische Modelle sind außerdem rechenintensiv und hätten einen größeren Nutzen, wenn theoretische Fortschritte zu besseren Stichproben- und Approximationsmethoden führen würden.
Unterer rechter Quadrant: Geringes Verständnis, hoher Nutzen
Im Gegensatz zu den Fortschritten in den meisten Bereichen hat Deep Learning einige erstaunliche Erfolge erzielt, auch wenn es sich als grundsätzlich schwierig erwiesen hat, bei theoretischen Aspekten voranzukommen. Deep Learning verkörpert viele Merkmale eines wenig bekannten Ansatzes: Modelle sind instabil, schwer zuverlässig zu erstellen, basieren auf schwachen Heuristiken und liefern unvorhersehbare Ergebnisse. Fragwürdige Praktiken wie das zufällige „Anpassen“ von Startwerten sind weit verbreitet und die Mechanismen des Arbeitsmodells sind schwer zu erklären. Allerdings schreitet Deep Learning immer weiter voran und erreicht übermenschliche Leistungsniveaus in Bereichen wie Computer Vision und Verarbeitung natürlicher Sprache, wodurch eine Welt ansonsten unverständlicher Aufgaben, wie etwa autonomes Fahren, eröffnet wird.
Hypothetisch wird die allgemeine KI die untere rechte Ecke einnehmen, da Superintelligenz per Definition außerhalb des menschlichen Verständnisses liegt und zur Lösung jedes Problems eingesetzt werden kann. Derzeit ist es nur als Gedankenexperiment enthalten.
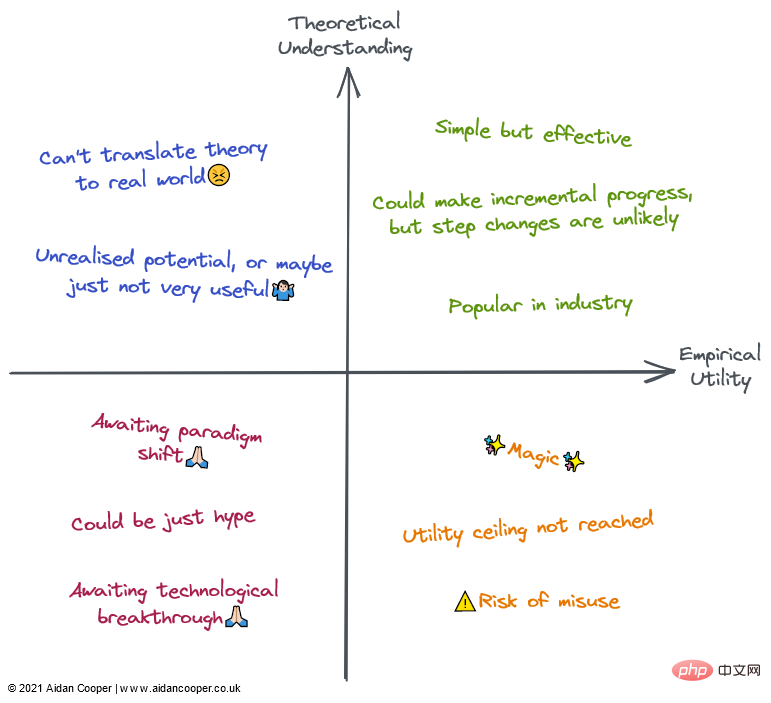
Qualitative Beschreibung jedes Quadranten. Felder können durch einige oder alle ihrer Beschreibungen in den entsprechenden Regionen beschrieben werden
Oberer linker Quadrant: hohes Verständnis, geringer Nutzen
Die meisten Formen der kausalen Schlussfolgerung sind kein maschinelles Lernen, aber manchmal sind sie es und sind immer für die Vorhersage von Interesse Modelle. Kausalität kann in randomisierte kontrollierte Studien (RCTs) und ausgefeiltere Methoden der kausalen Schlussfolgerung unterteilt werden, die versuchen, kausale Zusammenhänge anhand von Beobachtungsdaten zu messen. RCTs sind in der Theorie einfach und liefern präzise Ergebnisse, sind jedoch oft teuer und unpraktisch – wenn nicht sogar unmöglich – in der realen Welt durchzuführen und haben daher nur einen begrenzten Nutzen. Kausalinferenzmethoden imitieren im Wesentlichen RCTs, ohne etwas zu tun, was ihre Durchführung wesentlich erleichtert, es gibt jedoch eine Reihe von Einschränkungen und Fallstricken, die die Ergebnisse ungültig machen können. Insgesamt bleibt die Kausalität ein frustrierendes Unterfangen, bei dem die aktuellen Methoden für die von uns gestellten Fragen oft unzureichend sind, es sei denn, diese Fragen können durch randomisierte kontrollierte Studien untersucht werden oder sie passen genau in einen Rahmen (z. B. als zufälliges Ergebnis einer „ natürliches Experiment").
Federated Learning (FL) ist ein cooles Konzept, das sehr wenig Beachtung findet – wahrscheinlich, weil seine überzeugendsten Anwendungen die Verteilung auf eine große Anzahl von Smartphone-Geräten erfordern, sodass FL nur von zwei Akteuren wirklich untersucht werden kann: Apple und Google. Es gibt noch andere Anwendungsfälle für FL, wie beispielsweise die Bündelung proprietärer Datensätze. Bei der Koordinierung dieser Initiativen bestehen jedoch politische und logistische Herausforderungen, die ihren Nutzen in der Praxis einschränken. Dennoch, was nach einem ausgefallenen Konzept klingt (grob zusammengefasst: „Setzen Sie das Modell in die Daten ein, nicht die Daten in das Modell“), funktioniert FL und bietet Anwendungen in Bereichen wie Tastaturtextvorhersage und personalisierten Nachrichtenempfehlungen Erfolgsgeschichten Die grundlegende Theorie und Technologie hinter FL scheint für eine breitere Anwendung von FL ausreichend zu sein.
Reinforcement Learning (RL) hat in Spielen wie Schach, Go, Poker und DotA ein beispielloses Leistungsniveau erreicht. Aber außerhalb von Videospielen und Simulationsumgebungen muss Reinforcement Learning noch überzeugend in reale Anwendungen umgesetzt werden. Robotik sollte die nächste Grenze in RL sein, aber das geschah nicht – die Realität schien anspruchsvoller zu sein als die stark eingeschränkte Spielzeugumgebung. Allerdings sind die bisherigen Erfolge von RL ermutigend, und jemand, der Schach wirklich mag, könnte argumentieren, dass sein Nutzen noch größer sein sollte. Ich würde mir wünschen, dass RL einige seiner potenziellen praktischen Anwendungen erkennt, bevor es auf die rechte Seite der Matrix gesetzt wird.
Unterer linker Quadrant: geringes Verständnis, geringer Nutzen
Graph Neural Network (GNN) ist heute ein sehr beliebtes Feld im maschinellen Lernen und hat in vielen Bereichen vielversprechende Ergebnisse erzielt. Bei vielen dieser Beispiele ist jedoch unklar, ob GNNs besser sind als Alternativen, die traditionellere strukturierte Daten gepaart mit Deep-Learning-Architekturen verwenden. Probleme, bei denen die Daten von Natur aus graphenstrukturiert sind, wie etwa Moleküle in der Cheminformatik, scheinen überzeugendere GNN-Ergebnisse zu liefern (obwohl diese im Allgemeinen den nicht graphbezogenen Methoden unterlegen sind). Mehr als in den meisten Bereichen scheint es eine große Lücke zwischen Open-Source-Tools für das Training von GNNs in großem Maßstab und internen Tools zu geben, die in der Industrie verwendet werden, was die Machbarkeit großer GNNs außerhalb dieser ummauerten Gärten einschränkt. Die Komplexität und Breite des Fachgebiets legen eine hohe theoretische Obergrenze nahe, daher sollte es Raum geben, damit GNNs reifen und Vorteile für bestimmte Aufgaben überzeugend demonstrieren können, was zu einem größeren Nutzen führen wird. GNNs könnten auch von technologischen Fortschritten profitieren, da Graphen derzeit nicht auf natürliche Weise auf vorhandene Computerhardware passen.
Interpretable Machine Learning (IML) ist ein wichtiges und vielversprechendes Feld, das weiterhin Aufmerksamkeit erhält. Technologien wie SHAP und LIME sind zu wirklich nützlichen Werkzeugen für die Abfrage von ML-Modellen geworden. Aufgrund der begrenzten Akzeptanz ist der Nutzen vorhandener Ansätze jedoch noch nicht vollständig ausgeschöpft – robuste Best Practices und Implementierungsrichtlinien müssen noch festgelegt werden. Die derzeitige Hauptschwäche von IML besteht jedoch darin, dass es nicht die kausale Frage beantwortet, an der wir wirklich interessiert sind. IML erklärt, wie Modelle Vorhersagen treffen, erklärt jedoch nicht, wie die zugrunde liegenden Daten kausal mit ihnen zusammenhängen (obwohl dies häufig auf diese Weise falsch interpretiert wird). Vor großen theoretischen Fortschritten beschränkten sich die legitimen Einsatzmöglichkeiten von IML meist auf die Fehlersuche/Überwachung von Modellen und die Hypothesengenerierung.
Quantum Machine Learning (QML) liegt weit außerhalb meiner Möglichkeiten, scheint aber derzeit eine hypothetische Übung zu sein, die geduldig darauf wartet, dass brauchbare Quantencomputer verfügbar werden. Bis dahin saß QML unbedeutend in der unteren linken Ecke.
Inkrementeller Fortschritt, Technologiesprünge und Paradigmenwechsel
Es gibt drei Hauptmechanismen auf diesem Gebiet, um das theoretische Verständnis und die empirische Nutzenmatrix zu durchlaufen (Abbildung 2).
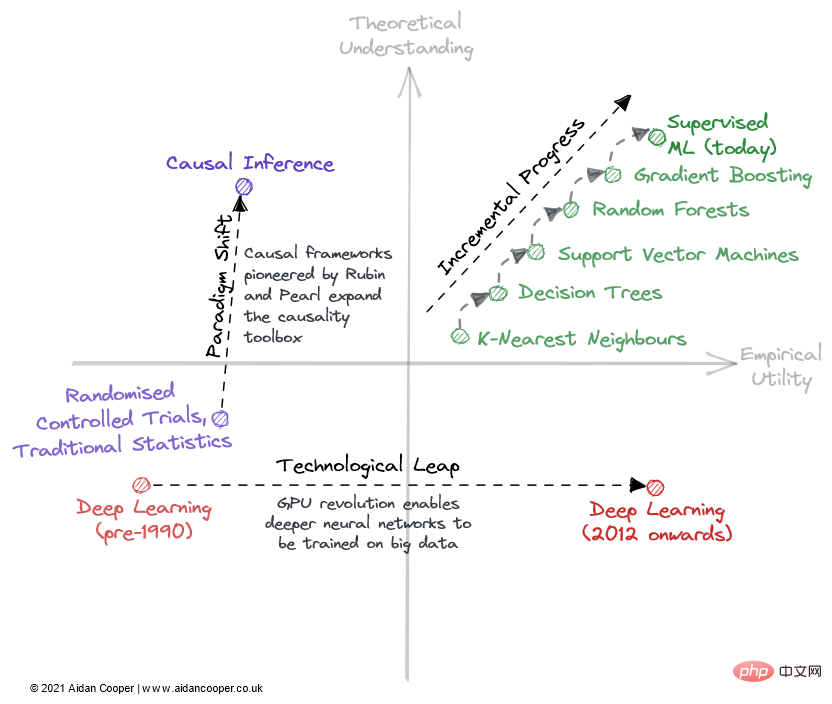
Anschauliches Beispiel dafür, wie Felder durch eine Matrix durchlaufen werden können.
Progressive Progression ist eine langsame und stetige Progression, die sich im Zollfeld auf der rechten Seite der Matrix nach oben bewegt. Ein gutes Beispiel hierfür ist das überwachte maschinelle Lernen der letzten Jahrzehnte. In dieser Zeit wurden immer effektivere Vorhersagealgorithmen verfeinert und übernommen, was uns zu dem leistungsstarken Werkzeugkasten verhalf, über den wir heute verfügen. In allen ausgereiften Bereichen ist schrittweiser Fortschritt der Status quo, außer in Zeiten dramatischerer Bewegungen aufgrund von Technologiesprüngen und Paradigmenwechseln.
Aufgrund von Technologiesprüngen kam es in einigen Bereichen zu sprunghaften Veränderungen im wissenschaftlichen Fortschritt. Das Gebiet des *Deep Learning* wurde nicht durch seine theoretischen Grundlagen enträtselt, die mehr als 20 Jahre vor dem Deep-Learning-Boom der 2010er Jahre entdeckt wurden – es war die durch Consumer-GPUs ermöglichte Parallelverarbeitung, die seine Renaissance befeuerte. Technologiesprünge erscheinen meist als Sprünge nach rechts entlang der empirischen Nutzenachse. Allerdings sind nicht alle technologiegestützten Fortschritte sprunghaft. Das heutige Deep Learning zeichnet sich durch schrittweise Fortschritte aus, die durch das Training immer größerer Modelle mit mehr Rechenleistung und zunehmend spezialisierter Hardware erzielt werden.
Der ultimative Mechanismus des wissenschaftlichen Fortschritts in diesem Rahmen ist der Paradigmenwechsel. Wie Thomas Kuhn in seinem Buch „The Structure of Scientific Revolutions“ feststellte, stellen Paradigmenwechsel wichtige Veränderungen in den Grundkonzepten und experimentellen Praktiken wissenschaftlicher Disziplinen dar. Der von Donald Rubin und Judea Pearl entwickelte Kausalrahmen ist ein Beispiel dafür und erhebt den Bereich der Kausalität von randomisierten kontrollierten Studien und der traditionellen statistischen Analyse zu einer leistungsfähigeren mathematischen Disziplin in Form der kausalen Schlussfolgerung. Paradigmenwechsel äußern sich häufig in einer Aufwärtsbewegung des Verständnisses, die mit einer Steigerung des Nutzens einhergehen kann.
Allerdings kann ein Paradigmenwechsel die Matrix in jede Richtung durchqueren. Als sich neuronale Netze (und später tiefe neuronale Netze) als vom traditionellen ML getrenntes Paradigma etablierten, ging dies zunächst mit einem Rückgang der Praktikabilität und des Verständnisses einher. Viele aufstrebende Gebiete gehen auf diese Weise von etablierteren Forschungsgebieten aus.
Die wissenschaftliche Revolution der Vorhersage und des Deep Learning
Zusammenfassend sind hier einige spekulative Vorhersagen darüber, was meiner Meinung nach in der Zukunft passieren könnte (Tabelle 1). Felder im oberen rechten Quadranten werden weggelassen, da sie zu ausgereift sind, um einen signifikanten Fortschritt zu erkennen.
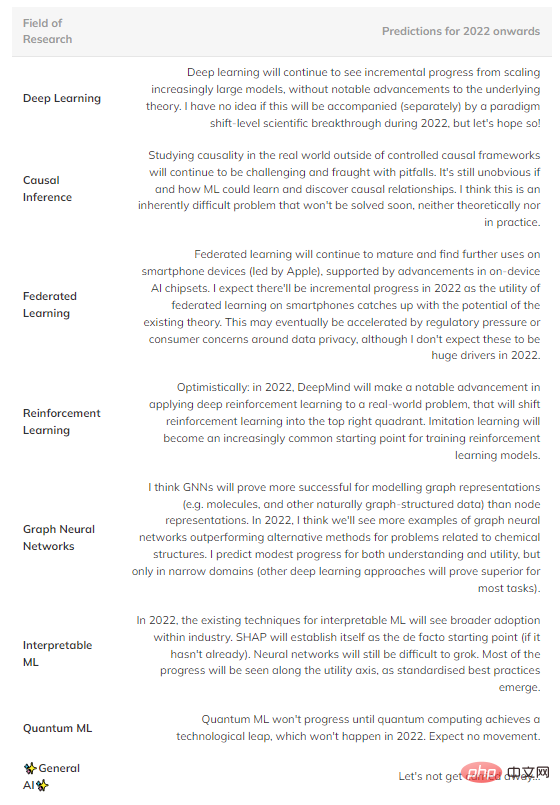
Tabelle 1: Prognose zukünftiger Fortschritte in mehreren wichtigen Bereichen des maschinellen Lernens.
Eine wichtigere Beobachtung als die Entwicklung einzelner Bereiche ist jedoch der allgemeine Trend zum Empirismus und die zunehmende Bereitschaft, umfassendes theoretisches Verständnis anzuerkennen.
Aus historischer Erfahrung tauchen im Allgemeinen zuerst Theorien (Hypothesen) auf und dann werden Ideen formuliert. Aber Deep Learning hat einen neuen wissenschaftlichen Prozess eingeleitet, der dies untergräbt. Das heißt, von den Methoden wird erwartet, dass sie ihre Leistung auf dem neuesten Stand der Technik demonstrieren, bevor sich jemand auf die Theorie konzentriert. Empirische Ergebnisse sind entscheidend, Theorie ist optional.
Dies hat zu einem systematischen und weit verbreiteten Einsatz der maschinellen Lernforschung geführt, um die neuesten Ergebnisse auf dem neuesten Stand der Technik zu erzielen, indem einfach bestehende Methoden modifiziert und auf Zufälligkeiten gesetzt werden, um die Basislinie zu übertreffen, anstatt die Theorie auf diesem Gebiet sinnvoll voranzutreiben. Aber vielleicht ist das der Preis, den wir für diese neue Welle des maschinellen Lernbooms zahlen.
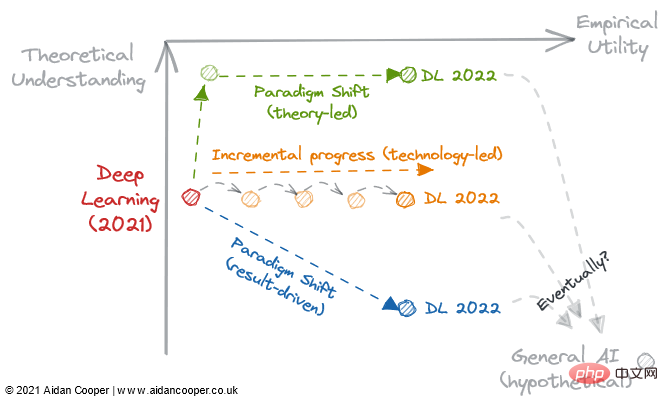
Abbildung 3: 3 mögliche Entwicklungspfade für Deep Learning im Jahr 2022.
2022 könnte der Wendepunkt sein, wenn Deep Learning unwiderruflich zu einem ergebnisorientierten Prozess wird und theoretisches Verständnis auf optional verbannt. Wir sollten über die folgenden Fragen nachdenken:
Werden theoretische Durchbrüche es unserem Verständnis ermöglichen, mit der Praxis gleichzuziehen und Deep Learning in eine strukturiertere Disziplin wie traditionelles maschinelles Lernen umzuwandeln?
Ist die vorhandene Deep-Learning-Literatur ausreichend, um eine unbegrenzte Steigerung des Nutzens zu ermöglichen, indem einfach auf immer größere Modelle skaliert wird?
Oder führt uns ein empirischer Durchbruch weiter in den Kaninchenbau, in ein neues Paradigma, das den Nutzen steigert, obwohl wir weniger darüber wissen?
Führt einer dieser Wege zur allgemeinen künstlichen Intelligenz? Nur die Zeit wird es zeigen.
Das obige ist der detaillierte Inhalt vonWie lässt sich die Zuverlässigkeit der theoretischen Grundlagen des maschinellen Lernens bewerten?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr