
Heim >Technologie-Peripheriegeräte >KI >Fünf vielversprechende KI-Modelle für die Bildübersetzung
Fünf vielversprechende KI-Modelle für die Bildübersetzung

- 王林nach vorne
- 2023-04-23 10:55:071934Durchsuche
Bild-zu-Bild-Übersetzung
Gemäß der Definition von Solanki, Nayyar und Naved im Artikel ist die Bild-zu-Bild-Übersetzung der Prozess der Konvertierung eines Bildes von einer Domäne in eine Ein weiteres Ziel besteht darin, die Zuordnung zwischen Eingabebildern und Ausgabebildern zu lernen.
Mit anderen Worten, wir hoffen, dass das Modell ein Bild a in ein anderes Bild b umwandeln kann, indem es die Zuordnungsfunktion f lernt.

Jemand fragt sich vielleicht, welchen Nutzen diese Modelle haben und welche Relevanz sie in der Welt der künstlichen Intelligenz haben. Es gibt in der Regel viele Anwendungen, und sie beschränken sich nicht nur auf Kunst oder Grafikdesign. Beispielsweise ist die Möglichkeit, ein Bild aufzunehmen und es in ein anderes Bild umzuwandeln, um synthetische Daten (z. B. ein segmentiertes Bild) zu erstellen, für das Training selbstfahrender Automodelle sehr nützlich. Eine weitere getestete Anwendung ist das Kartendesign, bei dem das Modell beide Transformationen durchführen kann (Satellitenansicht in Karte und umgekehrt). Image-Flip-Transformationen können auch auf die Architektur angewendet werden, wobei Modelle Empfehlungen zum Abschließen unvollendeter Projekte geben.
Eine der überzeugendsten Anwendungen der Bildkonvertierung besteht darin, eine einfache Zeichnung in eine wunderschöne Landschaft oder ein Gemälde umzuwandeln.
5 Die vielversprechendsten KI-Modelle für die Bildübersetzung
In den letzten Jahren wurden mehrere Methoden entwickelt, um das Problem der Bildübersetzung durch die Nutzung generativer Modelle zu lösen . Die am häufigsten verwendeten Methoden basieren auf der folgenden Architektur: Generative Adversarial Network (GAN) #Diffusion Model (DVAE)
- Transformers
- Pix2Pix
- Pix2Pix ist ein Modell, das auf bedingtem GAN basiert. Das bedeutet, dass seine Architektur aus einem Generatornetzwerk (G) und einem Diskriminator (D) besteht. Beide Netzwerke werden in einem kontradiktorischen Spiel trainiert, bei dem Gs Ziel darin besteht, neue Bilder zu generieren, die dem Datensatz ähneln, und D entscheiden muss, ob das Bild generiert wird (gefälscht) oder aus dem Datensatz stammt (wahr).
- Die Hauptunterschiede zwischen Pix2Pix und anderen GAN-Modellen sind: (1) Der erste Generator verwendet ein Bild als Eingabe, um den Generierungsprozess zu starten, während normales GAN zufälliges Rauschen verwendet. (2) Pix2Pix ist ein vollständig überwachtes Modell, was bedeutet, dass der Datensatz aus Bildpaaren aus zwei Domänen besteht.
U-Net : besteht aus zwei Modulen (Downsampling und Upsampling). Das Eingabebild wird mithilfe von Faltungsschichten auf eine Reihe kleinerer Bilder (sogenannte Feature-Maps) reduziert, die dann über transponierte Faltungen hochgesampelt werden, bis die ursprünglichen Eingabeabmessungen erreicht sind. Es gibt Sprungverbindungen zwischen Downsampling und Upsampling.
Patch-Diskriminator: Faltungsnetzwerk, seine Ausgabe ist eine Matrix, wobei jedes Element das Bewertungsergebnis eines Teils (Patches) des Bildes ist. Es umfasst den L1-Abstand zwischen dem generierten und dem realen Bild, um sicherzustellen, dass der Generator lernt, anhand des Eingabebilds die richtige Funktion abzubilden. Wird auch Markov genannt, da es auf der Annahme beruht, dass Pixel aus verschiedenen Patches unabhängig sind.
- Pix2Pix-Ergebnisse
- Unüberwachte Bild-zu-Bild-Übersetzung (EINHEIT)
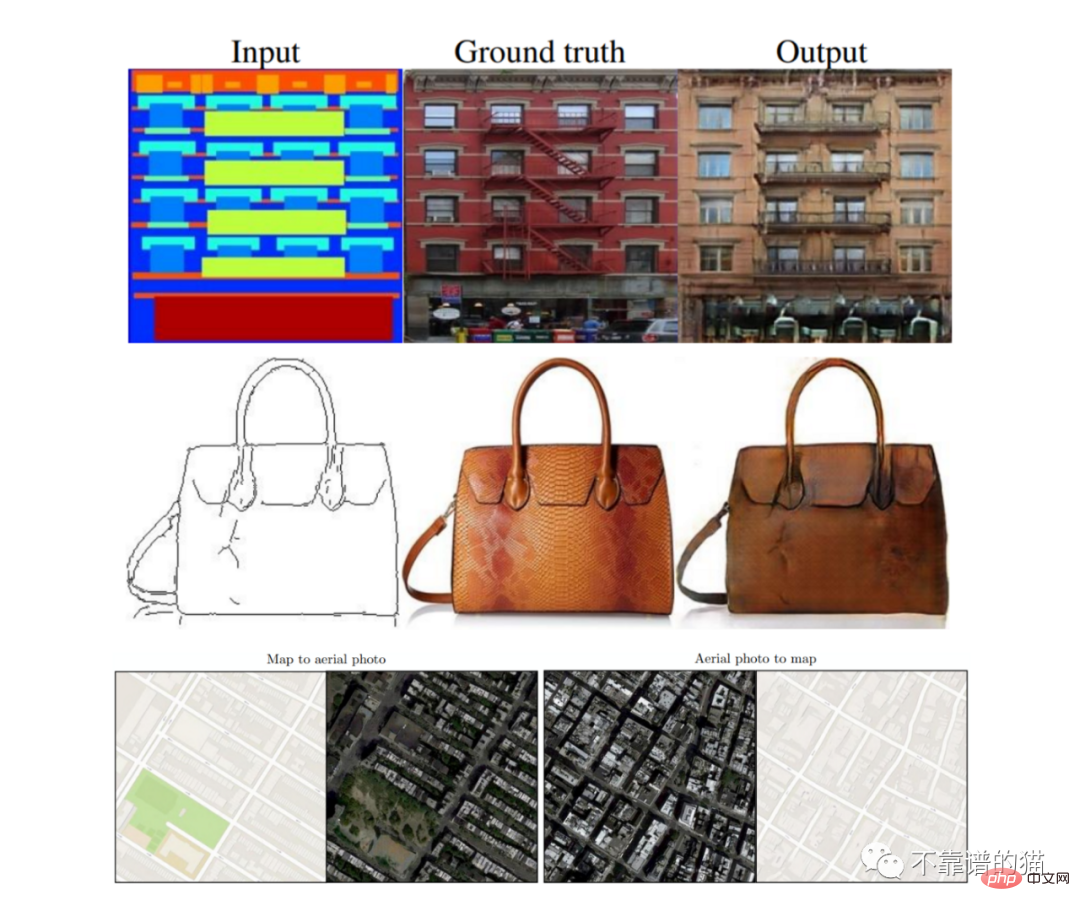 Das Modell geht zunächst davon aus, dass zwei Domänen (A und B) einen gemeinsamen latenten Raum (Z) teilen. Intuitiv können wir uns diesen latenten Raum als eine Zwischenstufe zwischen den Bildbereichen A und B vorstellen. Wenn wir also das Beispiel „Malen-zu-Bild“ verwenden, können wir denselben latenten Raum nutzen, um ein Gemäldebild rückwärts zu erzeugen oder um ein atemberaubendes Bild vorwärts zu sehen (siehe Abbildung X).
Das Modell geht zunächst davon aus, dass zwei Domänen (A und B) einen gemeinsamen latenten Raum (Z) teilen. Intuitiv können wir uns diesen latenten Raum als eine Zwischenstufe zwischen den Bildbereichen A und B vorstellen. Wenn wir also das Beispiel „Malen-zu-Bild“ verwenden, können wir denselben latenten Raum nutzen, um ein Gemäldebild rückwärts zu erzeugen oder um ein atemberaubendes Bild vorwärts zu sehen (siehe Abbildung X).
In der Abbildung: (a) gemeinsamer latenter Raum. (b) UNIT-Architektur: G2-Generator, D1-, D2-Diskriminator. Gestrichelte Linien stellen gemeinsame Schichten zwischen Netzwerken dar.
UNIT-Modell wird unter einem Paar VAE-GAN-Architekturen (siehe oben) entwickelt, wobei die letzte Schicht des Encoders (E1, E2) und die erste Schicht des Generators (G1, G2) ist geteilt.
UNIT-ErgebnissePalettePalette ist ein bedingtes Diffusionsmodell, das von Google Research entwickelt wurde Gruppe in Kanada. Das Modell ist darauf trainiert, vier verschiedene Aufgaben im Zusammenhang mit der Bildkonvertierung auszuführen, was zu qualitativ hochwertigen Ergebnissen führt: (i) Kolorierung: Hinzufügen von Farbe zu Graustufenbildern
(i) Kolorierung: Hinzufügen von Farbe zu Graustufenbildern
In dem Artikel untersuchen die Autoren den Unterschied zwischen einem allgemeinen Multitasking-Modell und mehreren spezialisierten Modellen, die beide für eine Million Iterationen trainiert wurden. Die Architektur des Modells basiert auf dem klassenbedingten U-Net-Modell von Dhariwal und Nichol 2021 und verwendet eine Stapelgröße von 1024 Bildern für 1 Mio. Trainingsschritte. Lärmpläne als Hyperparameter vorverarbeiten und abstimmen, unterschiedliche Pläne für Training und Vorhersage verwenden.

Palette-Ergebnisse
Vision Transformers (ViT)
Bitte beachten Sie, dass die folgenden beiden Modelle zwar nicht speziell für die Bildtransformation entwickelt wurden, aber einen Fortschritt darstellen, leistungsstarke Modelle wie Transformer in den Bereich der Computer Vision zu bringen . Ein offensichtlicher Schritt wurde getan.
Vision Transformers (ViT) ist eine Modifikation der Transformers-Architektur (Vaswani et al., 2017) und wurde für die Bildklassifizierung entwickelt. Das Modell verwendet Bilder als Eingabe und gibt die Wahrscheinlichkeit der Zugehörigkeit zu jeder definierten Klasse aus.
Das Hauptproblem besteht darin, dass Transformer so konzipiert sind, dass sie eindimensionale Sequenzen als Eingabe verwenden, keine zweidimensionalen Matrizen. Zum Sortieren empfehlen die Autoren, das Bild in kleine Teile aufzuteilen und sich das Bild als Sequenz (oder Satz im NLP) und die Teile als Token (oder Wörter) vorzustellen.
Um es kurz zusammenzufassen: Wir können den gesamten Prozess in drei Phasen unterteilen:
1) Einbetten: Kleine Teile teilen und glätten → lineare Transformation anwenden → Klassen-Tag hinzufügen (dieses Tag dient als Bildzusammenfassung, die bei der Klassifizierung berücksichtigt wird) →Positionseinbettung
2) Transformer-Encoder-Block: Platzieren Sie die eingebetteten Patches in einer Reihe von Transformer-Encoder-Blöcken. Der Aufmerksamkeitsmechanismus lernt, auf welche Teile des Bildes er sich konzentrieren soll.
3) Klassifizierungs-MLP-Header: Leiten Sie die Klassentoken durch den MLP-Header, der die endgültige Wahrscheinlichkeit ausgibt, dass das Bild zu jeder Klasse gehört.
Vorteile der Nutzung von ViT: Die Regelung bleibt unverändert. Im Vergleich zu CNN wird Transformer nicht durch die Übersetzung (Änderung der Position von Elementen) im Bild beeinflusst.
Nachteile: Für das Training ist eine große Menge an beschrifteten Daten erforderlich (mindestens 14 Millionen Bilder).
TransGAN
TransGAN ist ein transformbasiertes GAN-Modell, das für die Bilderzeugung ohne Verwendung von Faltungsschichten entwickelt wurde. Stattdessen bestehen der Generator und der Diskriminator aus einer Reihe von Transformatoren, die durch Upsampling- und Downsampling-Blöcke verbunden sind.
Der Vorwärtsdurchlauf des Generators nimmt ein 1D-Array zufälliger Rauschproben und leitet sie durch den MLP. Intuitiv können wir uns das Array als Satz und die Pixelwerte als Wörter vorstellen (beachten Sie, dass ein Array mit 64 Elementen in ein 8✕8-Bild mit einem Kanal umgeformt werden kann. Als nächstes wendet der Autor eine Reihe von Transformatoren an). Blöcke, auf die jeweils eine Upsampling-Ebene folgt, die die Größe des Arrays (Bildes) verdoppelt.
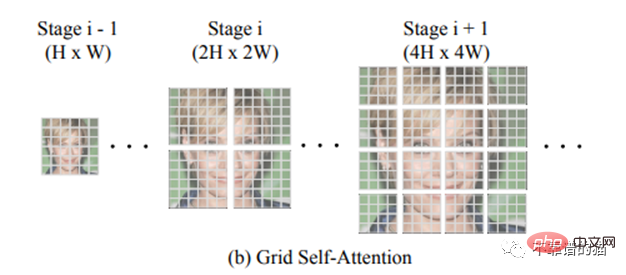
Ein Schlüsselmerkmal von TransGAN ist die Grid-Selbstaufmerksamkeit. Bei hochdimensionalen Bildern (d. h. sehr langen Arrays 32✕32 = 1024) kann die Anwendung des Transformators zu explosiven Kosten des Selbstaufmerksamkeitsmechanismus führen, da Sie jedes Pixel des 1024-Arrays mit allen 255 möglichen Pixeln vergleichen müssen ( RGB-Dimension). Anstatt also die Korrespondenz zwischen einem bestimmten Token und allen anderen Token zu berechnen, unterteilt die Gitter-Selbstaufmerksamkeit die volldimensionale Feature-Map in mehrere nicht überlappende Gitter und berechnet die Token-Interaktionen in jedem lokalen Gitter.
Die Diskriminatorarchitektur ist dem zuvor zitierten ViT sehr ähnlich.

TransGAN-Ergebnisse für verschiedene Datensätze
Das obige ist der detaillierte Inhalt vonFünf vielversprechende KI-Modelle für die Bildübersetzung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr