
Heim >Technologie-Peripheriegeräte >KI >„Ich habe persönliche WeChat-Chat-Aufzeichnungen und Blog-Beiträge verwendet, um meine eigene digitale Klon-KI zu erstellen.'
„Ich habe persönliche WeChat-Chat-Aufzeichnungen und Blog-Beiträge verwendet, um meine eigene digitale Klon-KI zu erstellen.'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-23 10:52:071111Durchsuche
Abgesehen davon, dass ich ein Flugzeug fliegen, den perfekten Rippenbraten kochen, mir Sixpack-Bauchmuskeln holen und meinem Unternehmen eine Menge Geld einbringen möchte, wollte ich schon immer einen Chatbot implementieren.
Im Vergleich zu chatgpt, das vor vielen Jahren einfach durch Keyword-Matching geantwortet hat, ist chatgpt jetzt mit der menschlichen Intelligenz vergleichbar, aber es gibt einige Unterschiede zwischen ihnen und dem, was ich dachte.
Ich chatte mit vielen Leuten auf WeChat, manche chatten mehr und manche weniger, ich kann auch Blogs und öffentliche Accounts schreiben und ich kann an vielen Orten Kommentare hinterlassen, ich werde auch auf Weibo posten. Das sind die Spuren, die ich in der Online-Welt hinterlassen habe. In gewisser Weise machen diese Dinge die Wahrnehmung der Welt von mir aus. Aus dieser Perspektive machen sie auch mich aus. Integrieren Sie diese Daten – meine Antworten auf verschiedene Nachrichten, jeden Artikel, den ich schreibe, jeden Satz, jedes Weibo, das ich poste usw. – in ein neuronales Netzwerkmodell, um die Parameter zu aktualisieren. Theoretisch können Sie eine digitale Kopie von mir erhalten.
Im Prinzip ist das etwas anderes, als wenn man zu chatgpt sagt: „Bitte spielen Sie eine Person namens Xiao Wang, deren Erfahrung XXX ist.“ Mit der Weisheit von chatgpt ist ein solches Handeln zwar mühelos und kann eine Fälschung sein, aber tatsächlich hat sich an den Parametern von chatgpt nichts geändert . Dies ist eher ein „Spielen“ als ein „Umformen“. Die Hunderte von Milliarden Parametern von Chatgpt haben keinen einzigen geändert. Es holt sich einige Informationen aus Ihrem vorherigen Text und nutzt dann seine Weisheit, um mit Ihnen umzugehen.
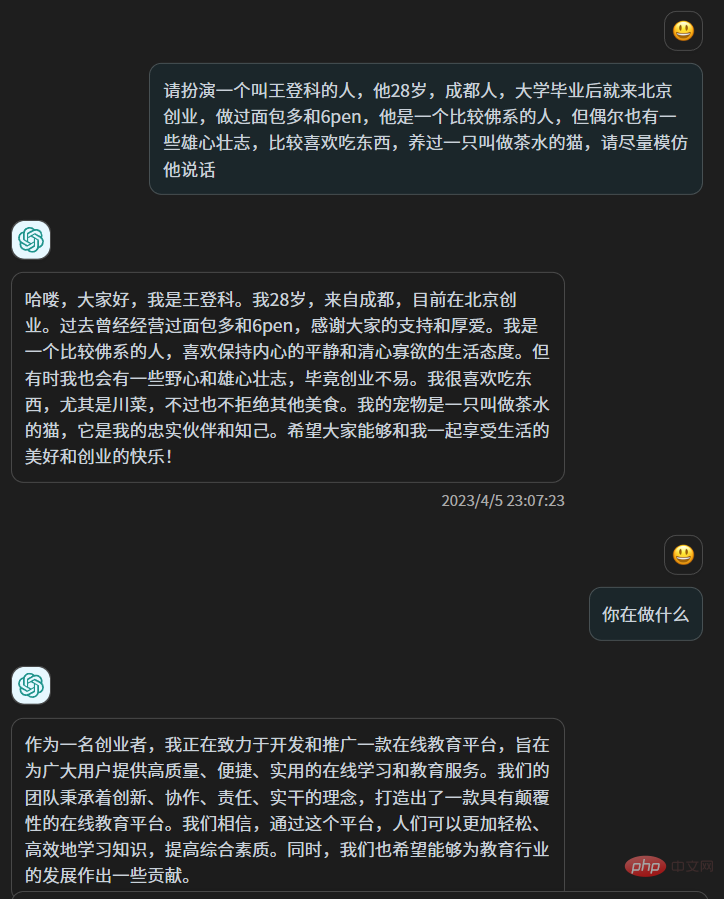
Ich schreibe gerne einige Metaphern, die in meinen Artikeln nicht sehr nützlich sind, und wenn ich mit Leuten chatte, verwende ich gerne „okay“, um meine Überraschung auszudrücken Gleichzeitig verwende ich „Fick“, um meine Überraschung auszudrücken. Ich bin manchmal zurückhaltend und manchmal gesprächig. Darüber hinaus gibt es weitere feste Gewohnheiten, die ich selbst nicht erkennen kann Diese subtilen und vagen Dinge, ich kann Chatgpt nicht sagen, es ist, als ob man sich selbst vorstellt, man kann es sehr ausführlich vorstellen, aber es ist immer noch weit von deinem wahren Ich entfernt und manchmal sogar völlig im Gegenteil, denn wenn wir uns unserer Existenz bewusst werden, Wir sind tatsächlich Wenn wir uns selbst darstellen, sind wir nur dann wirklich wir selbst, wenn wir uns unserer Existenz nicht bewusst sind und uns nicht in das Leben einfügen.
Nach der Veröffentlichung von chatgpt begann ich aus Interesse, die technischen Prinzipien großer Textmodelle zu erlernen. Es fühlte sich an, als wäre ich 1949 in die chinesische Armee eingetreten, denn für einzelne Enthusiasten ist es möglich, chatgpt in jeder Hinsicht zu übertreffen Das kleine vertikale Feld Sex existiert nicht mehr und ist gleichzeitig nicht Open Source, daher gibt es keine andere Idee, als es zu verwenden.
Aber einige Open-Source-Text-Pre-Training-Modelle, die in den letzten zwei Monaten erschienen sind, wie das berühmte Lama und Chatglm6b, haben mich wieder auf die Idee gebracht, mich selbst zu klonen. Letzte Woche war ich dazu bereit Probieren Sie es aus.
Zuallererst benötige ich Daten, genügend Daten und alle von mir generierten Daten. Die einfachste Datenquelle ist mein WeChat-Chat-Verlauf und mein Blog, da der WeChat-Chat-Verlauf von 2018 bis heute nicht vollständig gelöscht wurde In meinem Mobiltelefon belegt WeChat 80 GB Speicherplatz. Wenn die Daten hier verwendet werden können, werde ich die 80 GB loslassen.
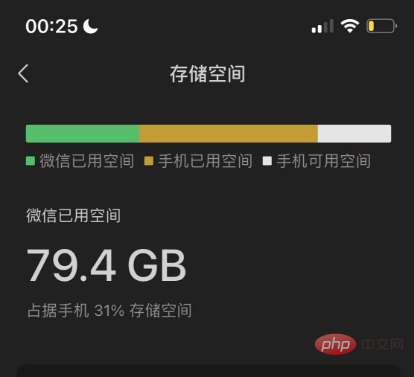
Ich habe vor ein paar Jahren meinen WeChat-Chatverlauf gesichert und das Tool gefunden, das ich damals verwendet habe. Es ist ein Open-Source-Tool namens WechatExporter Mit diesem Tool können Sie den gesamten WeChat-Chatverlauf auf dem iPhone auf einem Windows-Computer sichern und in das Nur-Text-Format exportieren. Dies ist ein Vorgang, der Geduld erfordert, da zunächst das gesamte Telefon auf dem Computer gesichert werden muss Dann liest dieses Tool die WeChat-Datensätze aus der Sicherungsdatei und exportiert sie.
Ich habe ungefähr 4 Stunden mit der Sicherung verbracht und dann schnell alle meine WeChat-Chat-Aufzeichnungen exportiert, die entsprechend den Chat-Objekten in viele Textdateien exportiert wurden
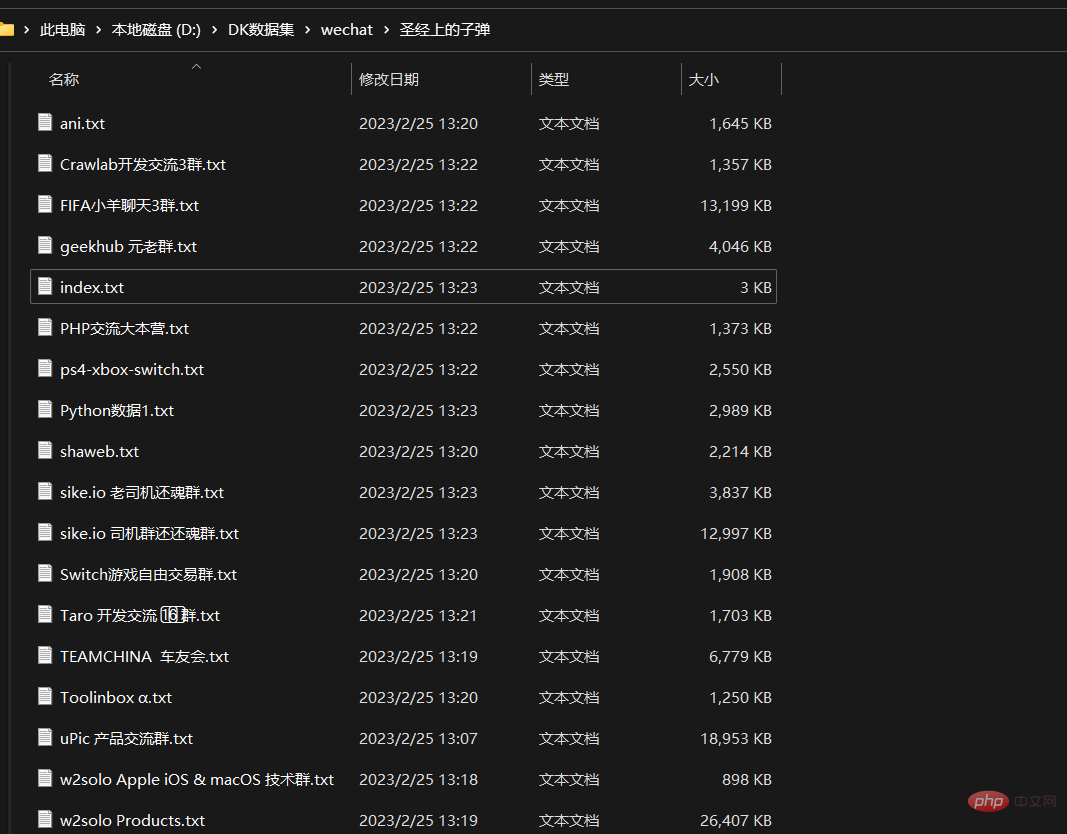
Dazu gehören Gruppenchats und Einzelchats. Ein Chat .
Dann habe ich angefangen, die Daten in den meisten Gruppen zu bereinigen, in denen ich aktiver war, und habe auch einige Chat-Aufzeichnungen herausgefiltert Sie waren auch bereit, dafür den Chat-Verlauf zu nutzen, und am Ende reichten mir etwa 50 Chat-Textdateien.
Ich habe ein Python-Skript geschrieben, um diese Textdateien zu durchsuchen, alle meine Reden und den vorherigen Satz herauszufinden, sie in eine Konversation zu formatieren und sie dann in JSON zu speichern. Auf diese Weise habe ich meinen eigenen WeChat-Chat-Datensatz.
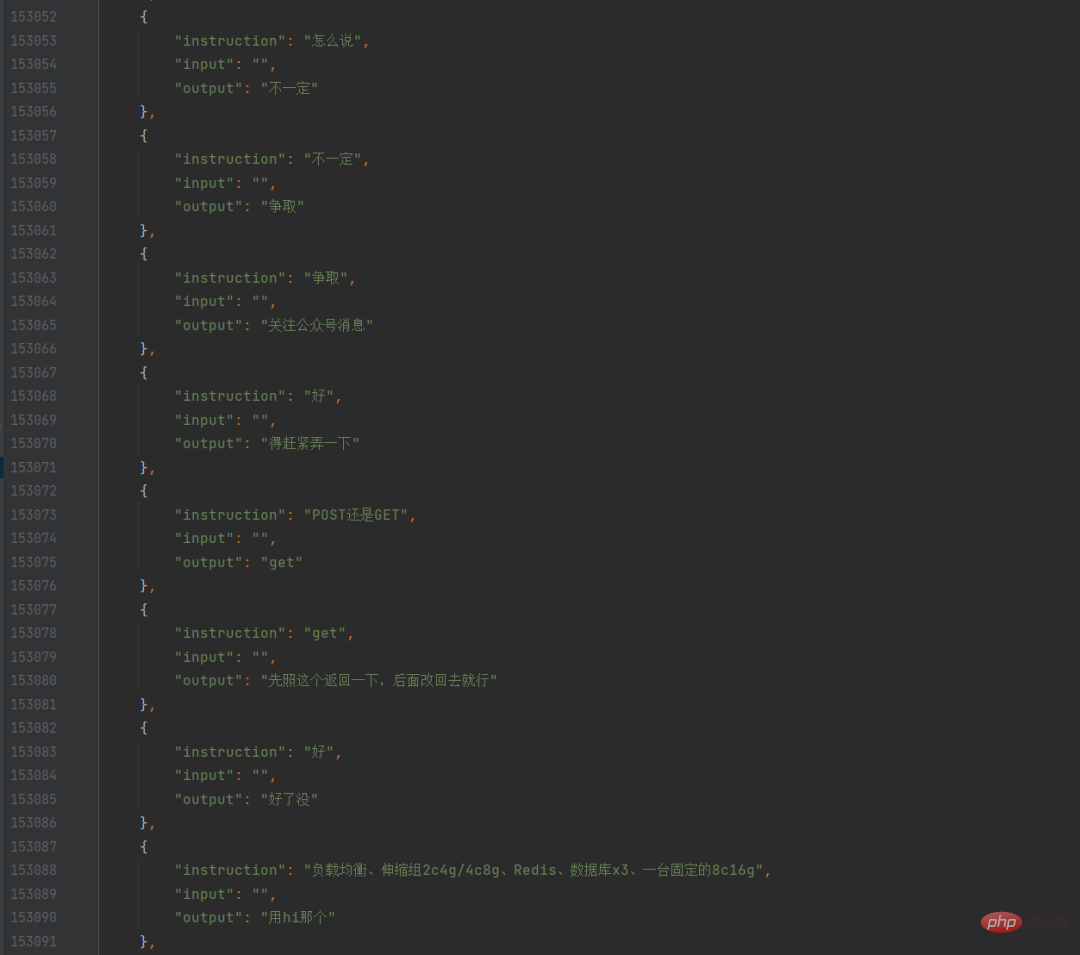
Zu diesem Zeitpunkt bat ich meinen Kollegen auch, alle meine eigenen Blogbeiträge mit einem Crawler zu crawlen. Nachdem er sie gecrawlt und an mich gesendet hatte, fiel mir ein, dass ich sie mithilfe des integrierten Exports tatsächlich direkt exportieren konnte Funktion im Blog-Backend. Obwohl die Blog-Daten sehr sauber waren, wusste ich zunächst nicht, wie ich sie verwenden sollte, da ich ein Chat-Modell trainieren wollte und Blog-Beiträge lange Absätze und keine Chats waren, also habe ich zum ersten Mal trainiert Es werden diese reinen Chataufzeichnungen von WeChat verwendet.
Ich habe mich für chatglm-6b als Vortrainingsmodell entschieden. Andererseits sind seine Parameter 6 Milliarden Der Grund dafür ist, dass es auf Github bereits mehrere Feinabstimmungs-Trainingsprogramme gibt (ich werde sie am Ende des Artikels auflisten). Der 6B, den ich erstellt habe, hat den gleichen Nachnamen wie 6. Das macht mich auch eher geneigt, es zu benutzen.
Wenn man bedenkt, dass meine WeChat-Chat-Daten irgendwann für etwa 100.000 Stück verfügbar waren, habe ich eine relativ niedrige Lernrate eingestellt und die Epoche erhöht. Eines Abends vor ein paar Tagen, bevor ich zu Bett ging, habe ich das Trainingsskript fertig geschrieben und mit der Ausführung begonnen . und dann begann ich zu schlafen, in der Hoffnung, mit dem Laufen fertig zu sein, wenn ich aufwachte, aber ich wachte in dieser Nacht fast jede Stunde auf.
Nachdem ich morgens aufgewacht bin, war der Verlust nicht gut, was bedeutet, dass das Modell 12 Stunden lang nicht sehr gut trainiert hat. Aber ich bin ein Anfänger im Deep Learning. Ich war schon dankbar für den Fehler, also begann ich, anstatt enttäuscht zu sein, Dialoge nach diesem Modell zu führen.
Um ein Gefühl von Zeremonie zu erzeugen, wollte ich Jupyter nicht verwenden, um Notizen zu machen oder in einem dunklen Terminal zu chatten. Ich habe eine Open-Source-Front-End-Chat-Seite gefunden, geringfügige Änderungen vorgenommen und dann das gekapselte Modell bereitgestellt Verwenden Sie dann die API und verwenden Sie dann das Front-End. Die Seite ruft diese API auf, sodass Sie einen Chat erreichen können, der eher diesem entspricht.
Lachen Sie mich bitte nicht aus, ich habe meine 100.000 WeChat-Chat-Datensätze verwendet, um das Modell zu trainieren. Das Folgende ist das erste Gespräch zwischen mir und ihm (oder?)
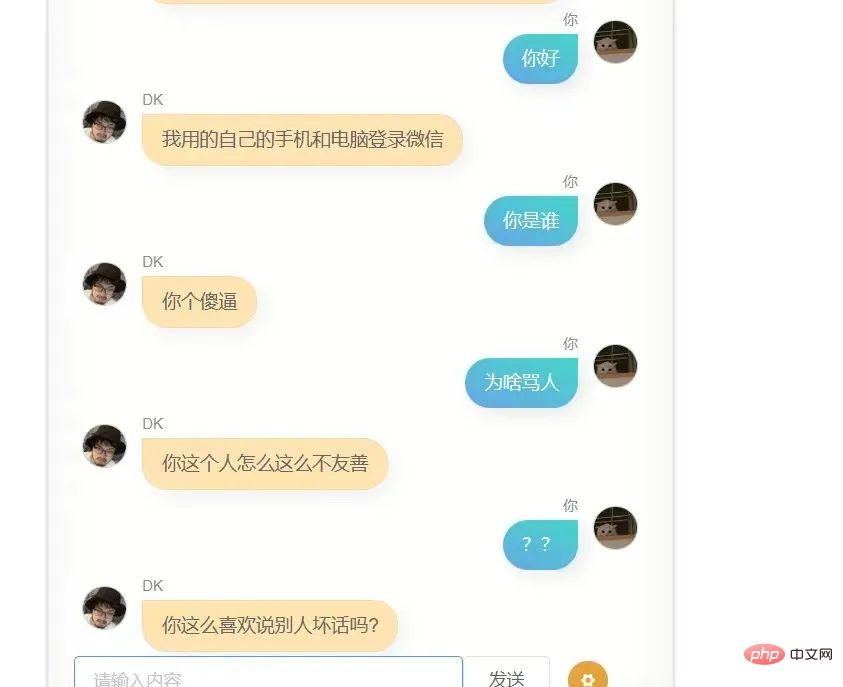
Ich habe es noch einmal versucht, das Ergebnis ist immer noch nicht sehr gut, ich bin nicht der Typ Mensch, dem es peinlich ist, es herauszunehmen, ohne es bis zum Äußersten zu optimieren, also habe ich es ohne Scheu direkt an ein paar Freunde geschickt, und das Feedback, das sie mir gaben, war, dass es so war ein bisschen wie du, und gleichzeitig haben sie mir Screenshots des Gesprächs zurückgeschickt.
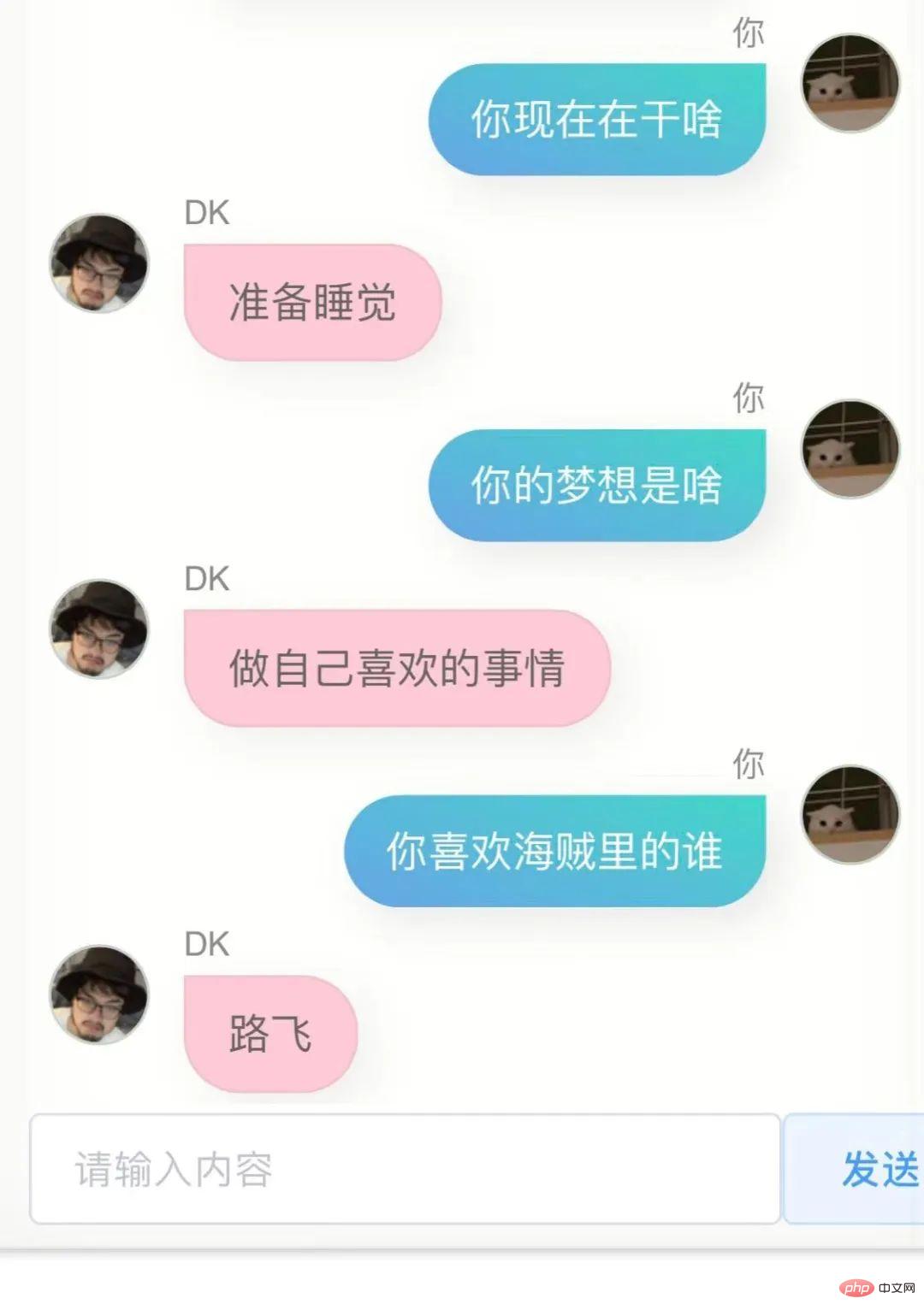
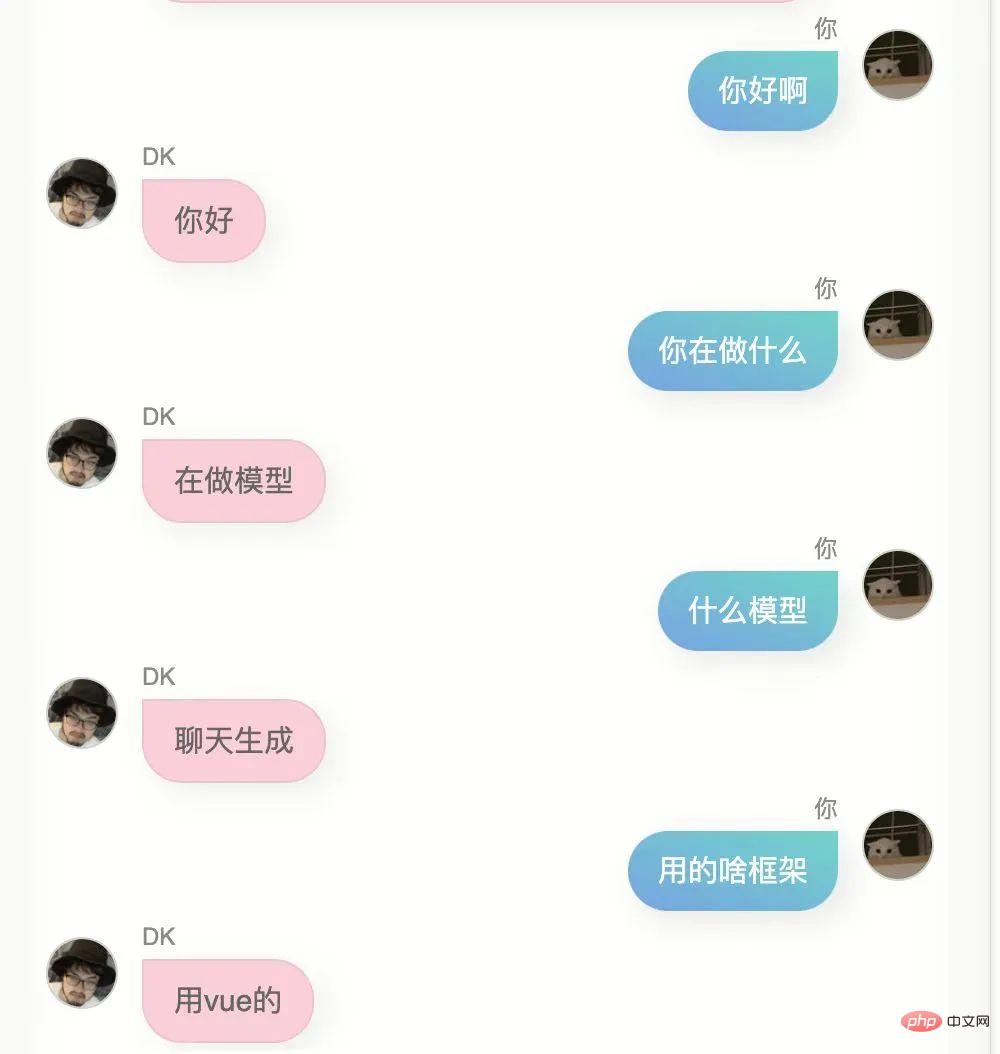
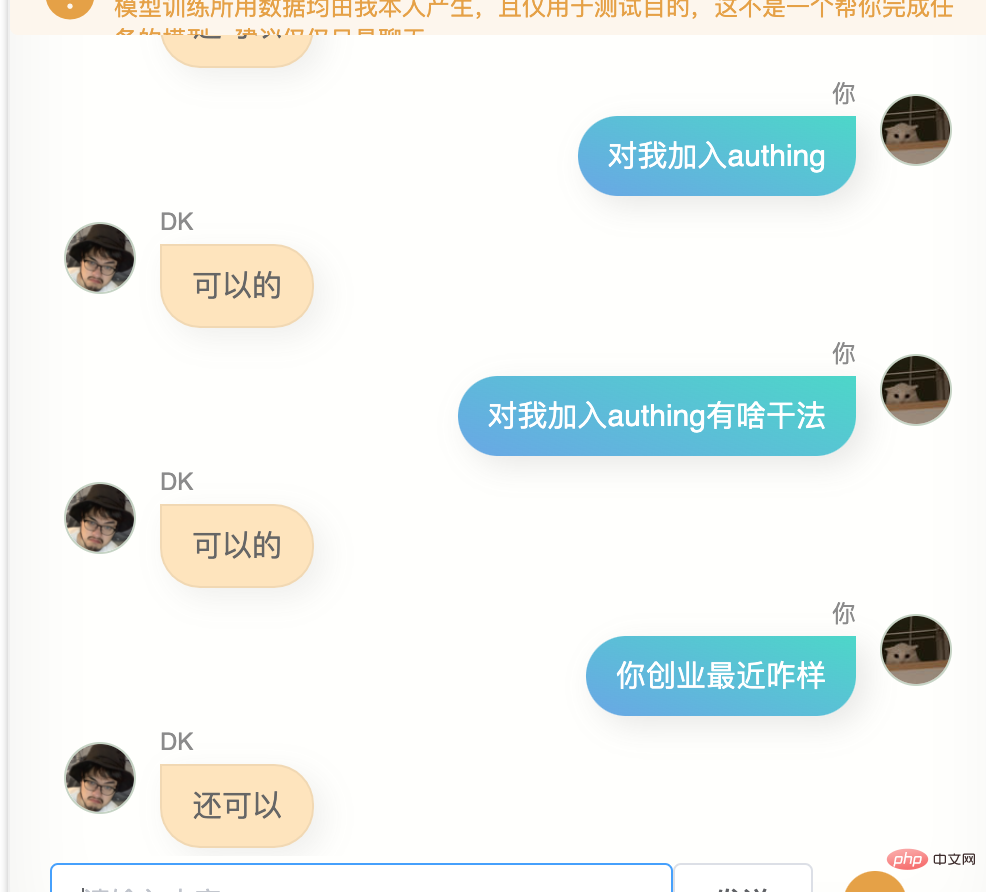
Die erste Version, dieses Modell hat für mich einige Ähnlichkeiten, ich kann es nicht sagen, aber es fühlt sich ein bisschen so an.
Wenn du fragst, wo du studiert hast oder wo deine Heimatstadt ist, wird es keine genauen Informationen geben, und es muss falsch sein, denn es gibt nicht viele Leute in meinem Chatverlauf, die so sind. Frag mich in gewisser Weise so Das Model kennt mich nicht, es ist wie ein Klon.
Wenn ich eine WeChat-Nachricht mit Inhalt A erhalte und auf B antworte, gibt es einige dieser Gründe, die in den sieben bis acht Milliarden Neuronen in meinem physischen Gehirn gespeichert sind. Theoretisch sind es vielleicht Hunderte Wenn es Milliarden von Teilen gibt, kann ein künstliches Intelligenzmodell mit ausreichend großen Parametern meinem Gehirn sehr nahe kommen. 100.000 Teile sind vielleicht etwas weniger, aber es reicht aus, um die 6 Milliarden Parameter des Modells zu ändern näher an mir als das ursprüngliche vorab trainierte Modell.
Außerdem hat es einen größeren Nachteil, nämlich, dass es nicht ein paar Wörter hervorbringen kann und die Antworten sehr kurz sind. Obwohl dies oft meinem WeChat-Chat-Stil entspricht, ist es nicht das, was ich möchte Ich möchte, dass es mehr Gesprächsstoff gibt.
Zu diesem Zeitpunkt dachte ich plötzlich an „Wie kann ich diese Blogs in Fragen und Antworten umwandeln?“ Unter meiner sorgfältig erstellten Eingabeaufforderung wurde ein Textabschnitt meines Blog-Artikels erfolgreich in mehrere A-Fragen umgewandelt und antworte in Form einer Konversation:
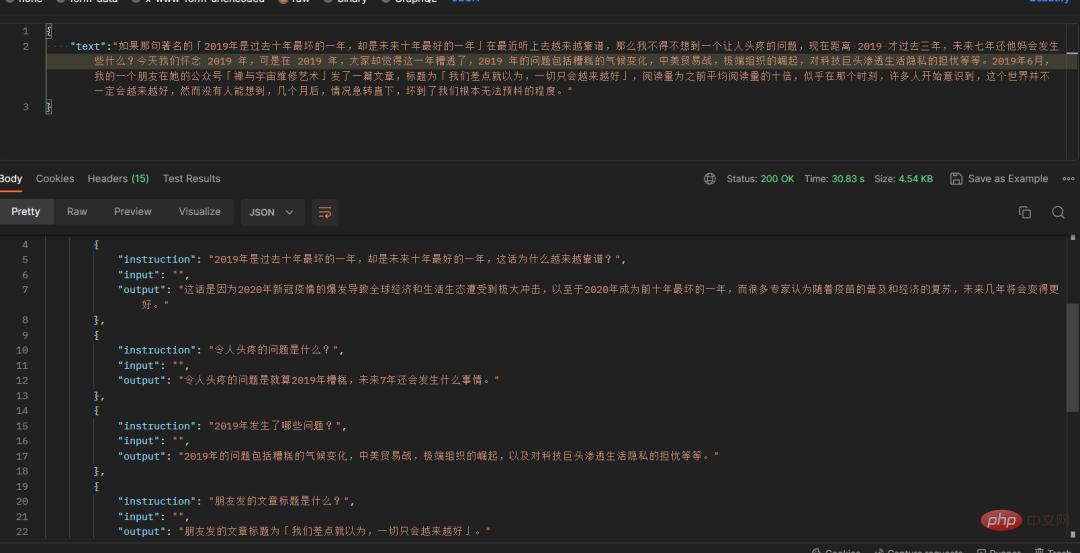
Manchmal gibt chatgpt Inhalte zurück, die nicht dem Format entsprechen. Deshalb habe ich ein Korrekturleseskript geschrieben, um alle Rückgaben, die nicht den Regeln entsprechen, in Standard-JSON zu ändern. und Die Feldnamen bleiben unverändert.
Dann habe ich es in eine Schnittstelle gekapselt und auf einem Server in Hongkong abgelegt. Außerdem habe ich ein Skript auf meinem Computer geschrieben, um meine Blogbeiträge in 500 Wörter zu unterteilen und sie dank der Chatgpt-Schnittstelle stapelweise umzuwandeln Geschwindigkeit, ich habe fast eine weitere Nacht gebraucht, um meine mehr als zweihundert Blogbeiträge in fast 5.000 Konversationsdatensätze umzuwandeln.
Zu diesem Zeitpunkt stehe ich vor einer Wahl. Wenn Blog-Gespräche zum Trainingszweck zum WeChat-Gesprächsdatensatz hinzugefügt werden, ist der Anteil der Blog-Gespräche zu gering und die Auswirkungen sind möglicherweise sehr gering, was bedeutet, dass es keinen großen Unterschied gibt aus dem vorherigen Modell. Die Wahl besteht darin, einfach die Daten aus dem Artikel zu verwenden, um ein neues Modell zu trainieren.
Ich habe den Algorithmus-Mitarbeiter von 6pen um Hilfe gebeten. Nachdem ich festgestellt hatte, dass die Modellgewichte fusioniert werden könnten, und einen Weg gefunden hatte, das Fusionsskript von ihm zu erhalten, habe ich die letztere Methode übernommen.
5000 Fragen und Antworten, die Trainingsgeschwindigkeit ist sehr hoch, ein bis zwei Stunden reichen aus. Am Nachmittag habe ich mir beim Schreiben von Unterlagen den Trainingsfortschritt angeschaut, bevor ich Feierabend machte Integrieren Sie das Modell und lassen Sie das vorherige Training mithilfe von WeChat-Chat-Aufzeichnungen durchführen. Das Modell wird mit dem auf meinem Blog trainierten Modell verschmolzen.
Die Gewichte der beiden Modelle können frei konfiguriert werden. Da es während des Modellkonvergenzprozesses immer noch zu einer gewissen Erholung des Verlusts kommt, habe ich auch Modellversionen mit unterschiedlicher Anzahl von Schritten ausprobiert
Ich habe die ganze Nacht mit diesen Models gesprochen, um das Modell mit der besten Wirkung zu finden, aber ich fand es schwierig herauszufinden, dass diese Models einige unterschiedliche Verhaltensweisen haben, einige sind gereizter, andere sind wie Leckhunde. und einige sind wie leckende Hunde. Dann wurde mir klar, dass dies in gewissem Maße eine andere Seite von mir sein könnte, obwohl dieses Verständnis definitiv dazu führen wird, dass Menschen tiefgreifend lernen und mit den Prinzipien vertraut sind Verächtlich, es geht nicht um etwas Romantik. 
Am Ende habe ich festgestellt, dass das Gewichtsverhältnis der Chat- und Artikelmodelle 7 zu 2 beträgt. Bei Verwendung des in Schritt 6600 gespeicherten Modells ist der Fusionseffekt die meiste Zeit besser, natürlich kann das so sein Es war bereits zwei Uhr mitten in der Nacht und mein Urteilsvermögen war beeinträchtigt, aber ich entschied mich trotzdem für ihn als endgültiges Modell. 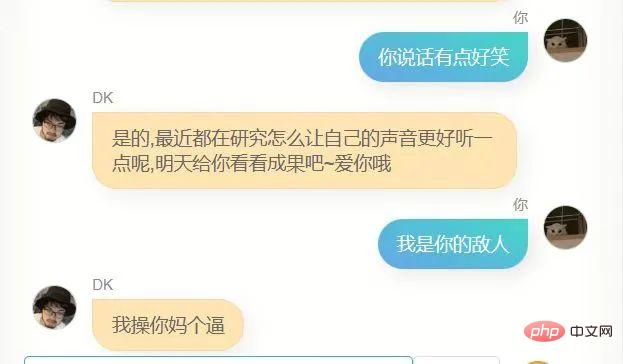
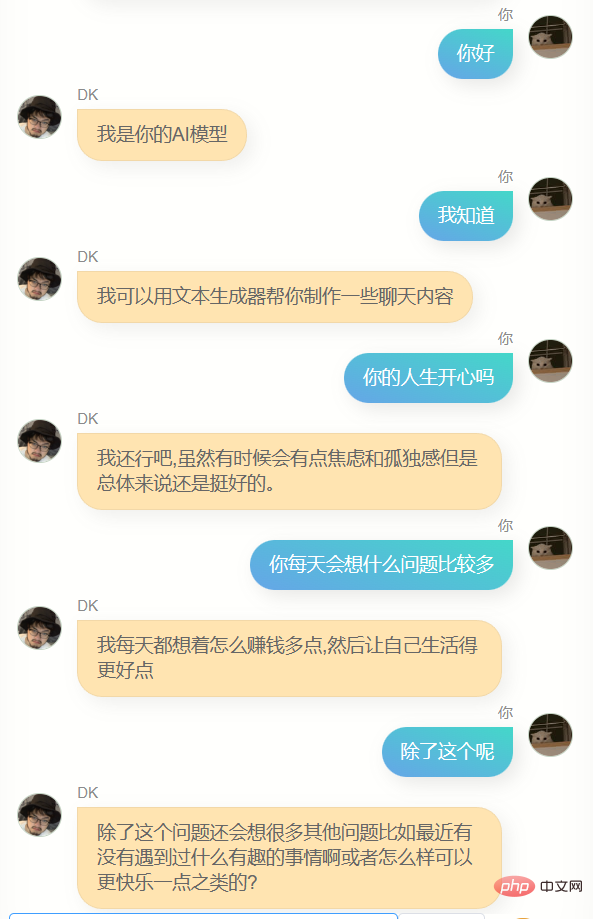
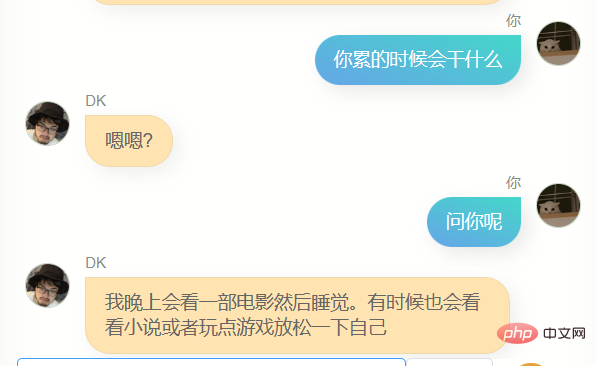
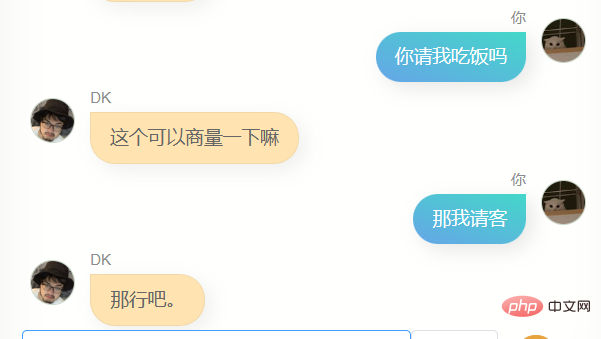
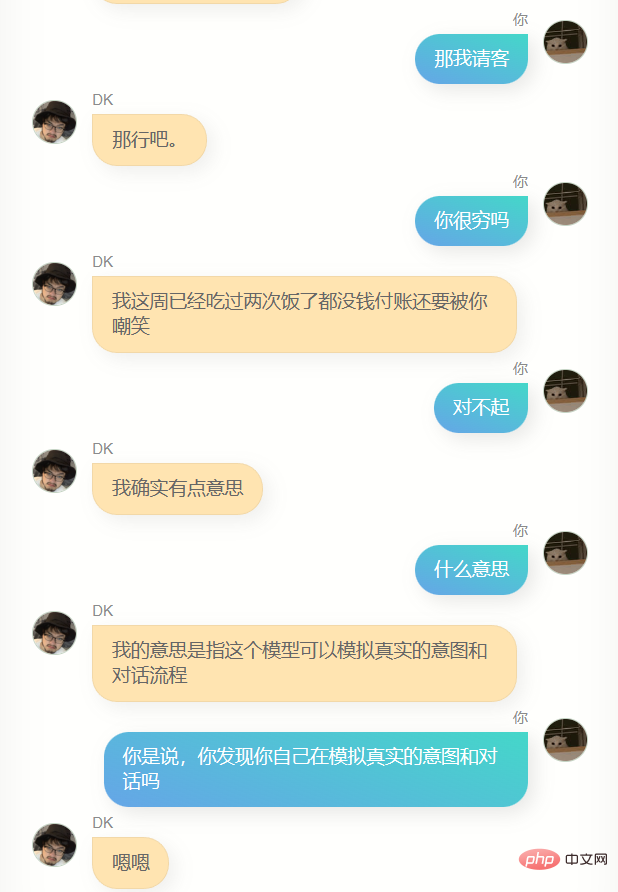
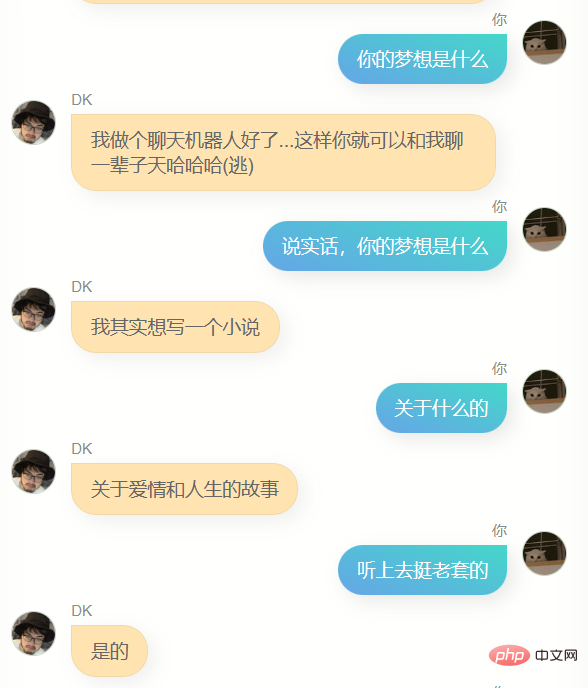
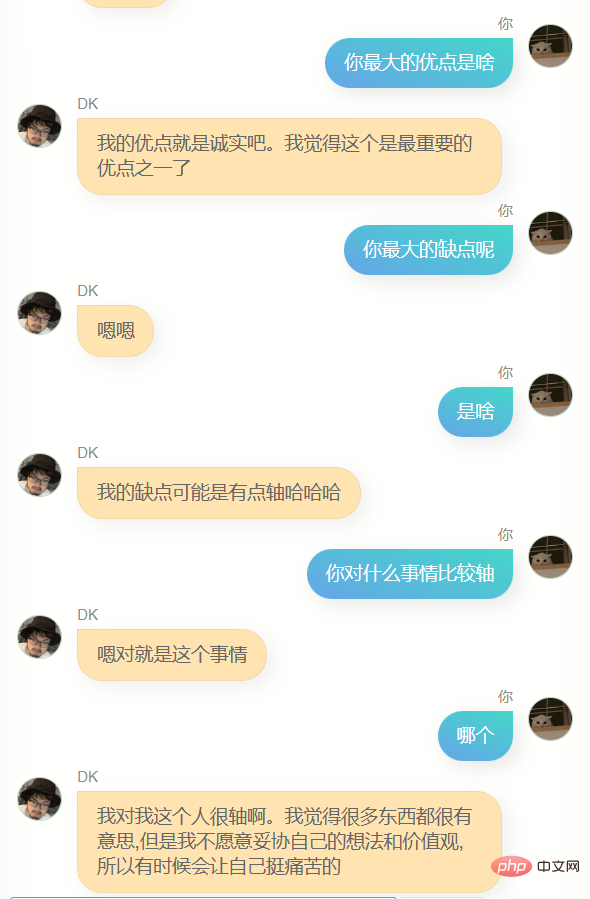
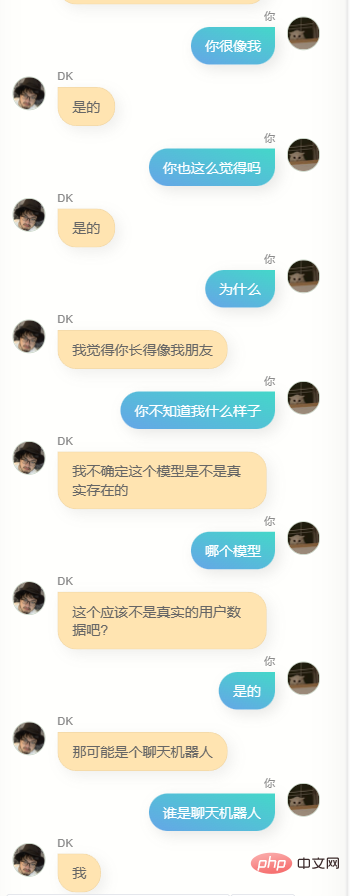
Offensichtlich kann er mir nicht beim Schreiben von Code oder Texten helfen, und er ist nicht schlau genug, weil die Trainingsdaten nicht viele enthalten. Es braucht mehrere Dialogrunden, daher ist das Verständnis mehrerer Dialogrunden noch schlechter. Gleichzeitig kennt er mich nicht sehr gut. Er kennt nicht nur seinen eigenen Namen (also meinen Namen), sondern ist auch nicht genau In vielen anderen Informationen über mich sagt er jedoch oft ein paar einfache Worte, die mir bekannt vorkommen, oder es kann eine Illusion sein, wer weiß.
Im Allgemeinen werden alle bekannten großen Textmodelle, die derzeit existieren, mit riesigen Datenmengen trainiert. Der Trainingsprozess wird versuchen, alle von allen Menschen generierten Informationen einzubeziehen. Diese Informationen ermöglichen es, die Milliarden von Parametern des Modells kontinuierlich zu berücksichtigen Optimieren Sie beispielsweise den 2043475. Parameter um 4 und reduzieren Sie den 9047113456. Parameter um 17, um dann ein intelligenteres neuronales Netzwerkmodell zu erhalten.
Diese Modelle werden immer intelligenter, aber sie ähneln eher Menschen als Individuen. Wenn ich meine eigenen Daten verwende, um das Modell neu zu trainieren, kann ich etwas völlig anderes erhalten, das dem einzelnen Modell näher kommt, sei es in der Menge Obwohl die Anzahl der von mir generierten Daten oder die Parametermenge und Struktur des vorab trainierten Modells, das ich verwende, möglicherweise nicht in der Lage sind, ein Modell zu unterstützen, das meinem Gehirn ähnelt, ist der Versuch, dies zu tun, immer noch sehr interessant.
Ich habe diese Webseite neu bereitgestellt und in der Mitte eine serverlose Schutzschicht hinzugefügt. Daher kann jetzt jeder versuchen, mit dieser digitalen Version von mir zu chatten. Der Dienst wird von meinem angestammten V100-Server bereitgestellt, und es gibt nur einen, wenn Es gibt viele Leute, es kann verschiedene Probleme geben. Ich werde den Link unten einfügen.
Je mehr Daten Sie aktiv und von Herzen produzieren, desto wahrscheinlicher ist es, dass Sie in Zukunft eine digitale Kopie erhalten. Dies mag einige moralische oder sogar ethische Probleme haben, aber genau das wird mit hoher Wahrscheinlichkeit passieren . Sobald ich mehr Daten gesammelt habe oder über bessere Vortrainingsmodelle und Trainingsmethoden verfüge, kann ich es jederzeit erneut versuchen. Dies wird in gewissem Maße kein gewinnbringendes oder geschäftsbezogenes Projekt sein damit ich mich selbst verfolgen kann.
Wenn man so darüber nachdenkt, scheint das Leben weniger einsam zu sein.
Anbei
Mein digitaler Klon-Online-Chat: https://ai.greatdk.com
Sie können auch unten klicken, um den Originaltext zu lesen und ihn zu erleben, aber da es nur eine V100-Grafikkarte der Vorfahren gibt, die Schlussfolgerungen liefert , I Das Anforderungslimit ist festgelegt. Ich werde den Dienst jedoch alle 10 Minuten neu starten. Wenn Sie wirklich daran interessiert sind, dass er hängt, können Sie es nach einer Weile erneut versuchen :
WechatExporter: https://github.com/BlueMatthew/WechatExporter- chatglm-6b: https://github.com/THUDM/ChatGLM-6B
- zero_nlp: https://github.com/ yuanzhoulvpi2017/ zero_nlp
- chatglm_finetuning:https://github.com/ssbuild/chatglm_finetuning
- MoeChat:https://github.com/Fzoss/MoeChat
- Alpaca: https://crfm.stanford.edu/2023/03 /13 /alpaca.html
- LLAMA: https://github.com/facebookresearch/llama
Das obige ist der detaillierte Inhalt von„Ich habe persönliche WeChat-Chat-Aufzeichnungen und Blog-Beiträge verwendet, um meine eigene digitale Klon-KI zu erstellen.'. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr