
Heim >Technologie-Peripheriegeräte >KI >Verwendung mehrerer ChatGPT-APIs zur Implementierung von Tsinghua UltraChat-Mehrrundengesprächen
Verwendung mehrerer ChatGPT-APIs zur Implementierung von Tsinghua UltraChat-Mehrrundengesprächen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-22 20:37:061127Durchsuche
Seit der Veröffentlichung von ChatGPT hat die Beliebtheit von Konversationsmodellen in diesem Zeitraum nur zugenommen. Während wir die erstaunliche Leistung dieser Modelle bewundern, sollten wir auch die enorme Rechenleistung und die massive Datenunterstützung hinter ihnen erraten.
Was die Daten betrifft, sind qualitativ hochwertige Daten von entscheidender Bedeutung. Aus diesem Grund hat OpenAI viel Mühe in die Daten- und Annotationsarbeit gesteckt. Mehrere Studien haben gezeigt, dass ChatGPT ein zuverlässigerer Datenannotator ist als Menschen. Wenn die Open-Source-Community große Mengen an Dialogdaten von leistungsstarken Sprachmodellen wie ChatGPT erhalten kann, kann sie Dialogmodelle mit besserer Leistung trainieren. Das beweist die Modellfamilie Alpaca – Alpaca, Vicuna, Koala. Beispielsweise hat Vicuna den neunstufigen Erfolg von ChatGPT nachgeahmt, indem es die Anweisungen für das LLaMA-Modell mithilfe der von ShareGPT gesammelten Benutzerfreigabedaten verfeinerte. Zunehmende Beweise zeigen, dass Daten die primäre Produktivität für das Training leistungsstarker Sprachmodelle sind.
ShareGPT ist eine ChatGPT-Datenaustausch-Website, auf der Benutzer ChatGPT-Antworten hochladen, die sie interessant finden. Die Daten auf ShareGPT sind offen, aber trivial und müssen von den Forschern selbst gesammelt und organisiert werden. Wenn ein qualitativ hochwertiger, umfassender Datensatz vorliegt, wird die Open-Source-Community mit halbem Aufwand für die Entwicklung von Konversationsmodellen das doppelte Ergebnis erzielen.
Auf dieser Grundlage hat ein aktuelles Projekt namens UltraChat systematisch einen Konversationsdatensatz von höchster Qualität erstellt. Die Projektautoren versuchten, zwei unabhängige ChatGPT-Turbo-APIs zur Durchführung von Gesprächen zu verwenden, um mehrere Runden von Gesprächsdaten zu generieren.
- Projektadresse: https://github.com/thunlp/UltraChat
- Datensatzadresse: http://39.101.77.220/
- Datensatz-Interaktionsadresse: https://atlas.nomic.ai/map/0ce65783-c3a9-40b5-895d-384933f50081/a7b46301-022f-45d8-bbf4-98107eabdbac
Konkret zielt dieses Projekt darauf ab, eine Open-Source-, Skalierbare, mehrrunde Dialogdaten basierend auf Turbo-APIs, praktisch für Forscher, um leistungsstarke Sprachmodelle mit universellen Dialogfunktionen zu entwickeln. Darüber hinaus wird das Projekt unter Berücksichtigung des Datenschutzes und anderer Faktoren Daten im Internet nicht direkt als Eingabeaufforderungen verwenden. Um die Qualität der generierten Daten sicherzustellen, verwendeten die Forscher im Generierungsprozess zwei unabhängige ChatGPT Turbo APIs, bei denen ein Modell die Rolle des Benutzers übernimmt, um Fragen oder Anweisungen zu generieren, und das andere Modell Feedback generiert.

Wenn Sie ChatGPT direkt verwenden, um es basierend auf einigen Startgesprächen und Fragen frei zu generieren, treten leicht Probleme wie einzelne Themen und wiederholte Inhalte auf, was es schwierig macht, die Vielfalt der Daten selbst sicherzustellen. Zu diesem Zweck hat UltraChat die von den Konversationsdaten abgedeckten Themen und Aufgabentypen systematisch klassifiziert und entworfen und außerdem ein detailliertes Prompt-Engineering für das Benutzermodell und das Antwortmodell durchgeführt. Es enthält drei Teile:
- Fragen zur Welt ( Fragen zur Welt): Dieser Teil des Gesprächs basiert auf umfassenden Fragen zu Konzepten, Entitäten und Objekten in der realen Welt. Die behandelten Themen umfassen Technologie, Kunst, Finanzen und andere Bereiche.
- Schreiben und Erstellen: Dieser Teil der Konversationsdaten konzentriert sich darauf, die KI anzuweisen, ein vollständiges Textmaterial von Grund auf zu erstellen, und auf dieser Grundlage Folgefragen oder weitere Anleitungen zur Verbesserung des Schreibens und Inhalts des Textes zu stellen Zu den schriftlichen Materialtypen gehören Artikel, Blogs, Gedichte, Geschichten, Theaterstücke, E-Mails und mehr.
- Unterstütztes Umschreiben (Schreiben und Erstellen) vorhandener Daten: Diese Dialogdaten werden auf der Grundlage vorhandener Daten generiert. Die Anweisungen umfassen unter anderem Umschreiben, Fortsetzung, Übersetzung, Einführung, Begründung usw. Die behandelten Themen sind ebenfalls sehr vielfältig.
Diese drei Datenteile decken die Anforderungen der meisten Benutzer an KI-Modelle ab. Gleichzeitig stehen diese drei Datentypen auch vor unterschiedlichen Herausforderungen und erfordern unterschiedliche Konstruktionsmethoden.
Die größte Herausforderung des ersten Teils der Daten besteht beispielsweise darin, das allgemeine Wissen in der menschlichen Gesellschaft in insgesamt Hunderttausenden Gesprächen möglichst umfassend abzudecken. Dazu gingen die Forscher von automatisch generierten Themen aus und Aus Wikidata abgeleitete Entitäten.
Die Herausforderungen im zweiten und dritten Teil bestehen hauptsächlich darin, Benutzeranweisungen zu simulieren und die Generierung von Benutzermodellen in nachfolgenden Gesprächen so vielfältig wie möglich zu gestalten, ohne vom ultimativen Ziel des Gesprächs (Materialerstellung oder Umschreibung von Materialien wie folgt) abzuweichen erforderlich) Aus diesem Grund haben die Forscher die Eingabeaufforderungen des Benutzermodells vollständig entworfen und damit experimentiert. Nach Abschluss der Konstruktion haben die Autoren die Daten auch nachbearbeitet, um das Halluzinationsproblem abzuschwächen.
Derzeit hat das Projekt die ersten beiden Datenteile mit einem Datenvolumen von 1,24 Millionen veröffentlicht, was der größte verwandte Datensatz in der Open-Source-Community sein dürfte. Der Inhalt enthält reichhaltige und farbenfrohe Gespräche in der realen Welt, und der letzte Teil der Daten wird in Zukunft veröffentlicht.
Weltproblemdaten stammen aus 30 repräsentativen und vielfältigen Metathemen, wie in der folgenden Abbildung dargestellt:

- Basierend auf den oben genannten Metathemen generierte das Projekt über 1100 Unterthemen. Themen Für die Datenkonstruktion;
- Generieren Sie für jedes Unterthema bis zu 10 spezifische Fragen.
- Verwenden Sie dann die Turbo-API, um für jede der 10 Fragen neue verwandte Fragen zu generieren Wie oben beschrieben, werden zwei Modelle iterativ verwendet, um 3 bis 7 Dialogrunden zu generieren.
- Darüber hinaus sammelte dieses Projekt die 10.000 am häufigsten verwendeten benannten Entitäten aus Wikidata; verwendete die ChatGPT-API, um 5 Metafragen für jede Entität zu generieren, und generierte 10 spezifischere Fragen und 20 verwandte, aber allgemeine Es wurden 200.000 spezifische Fragen, 250.000 allgemeine Fragen und 50.000 Metafragen befragt und für jede Frage wurden 3–7 Dialogrunden erstellt.
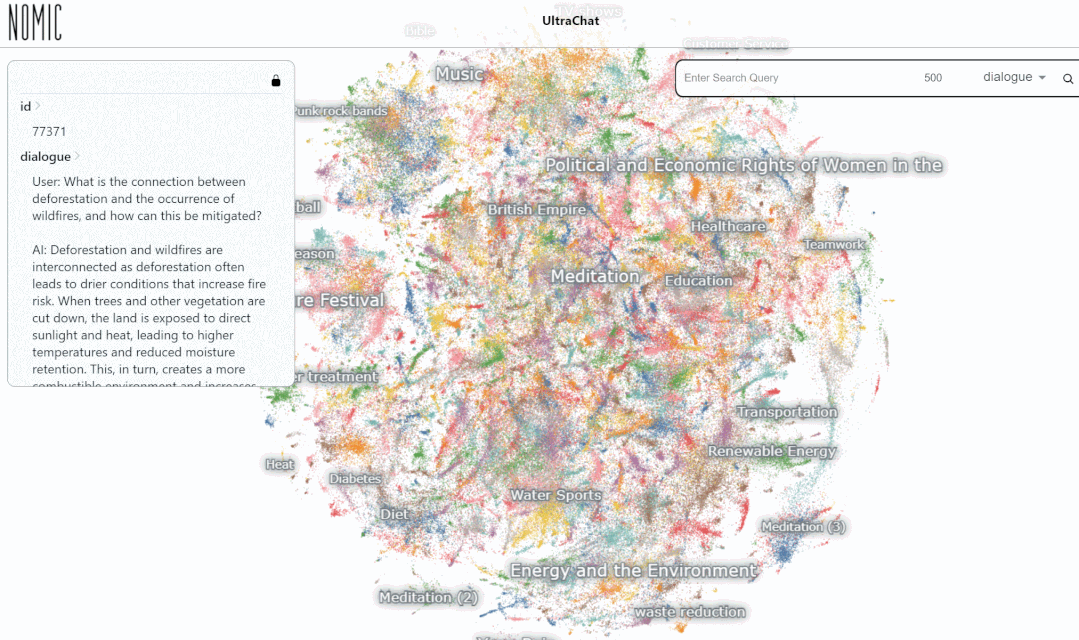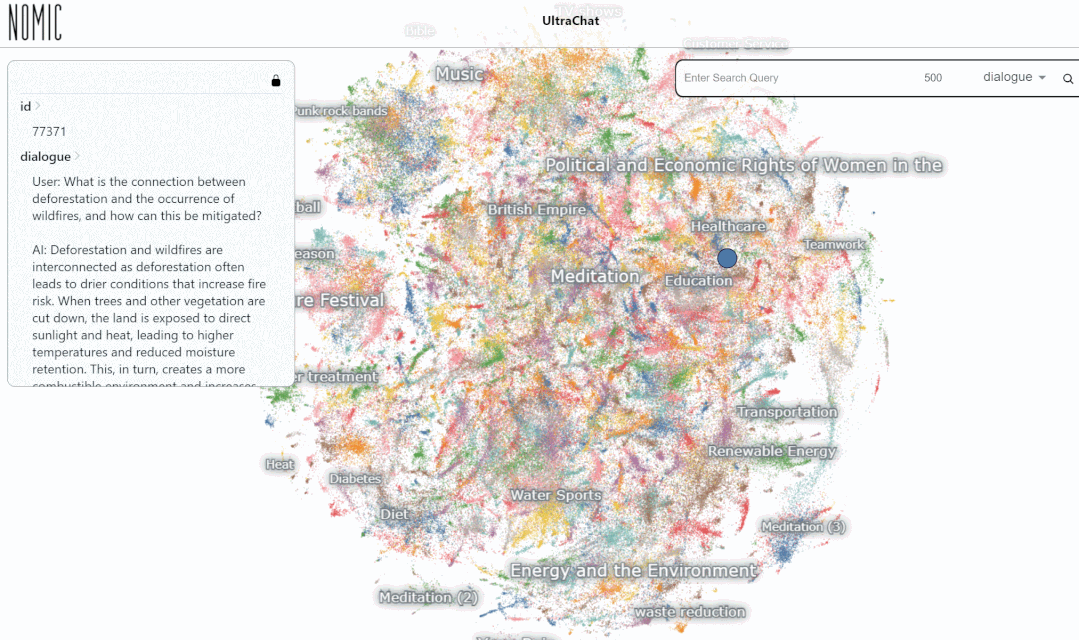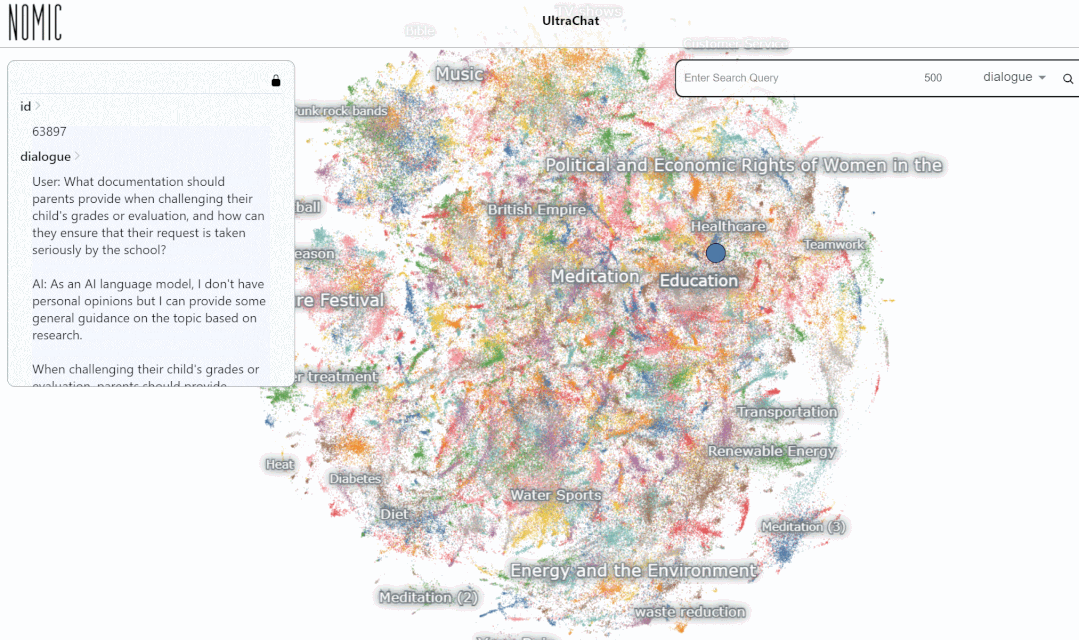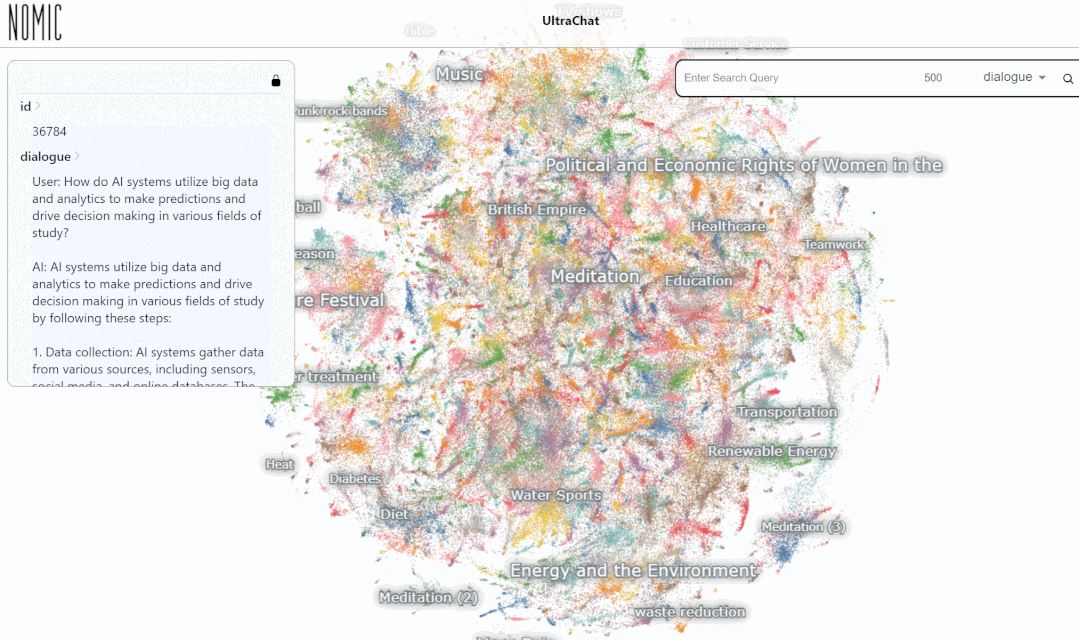
Als nächstes schauen wir uns ein konkretes Beispiel an:
Wir haben den Datensucheffekt auf der UltraChat-Plattform getestet. Wenn Sie beispielsweise „Musik“ eingeben, sucht das System automatisch nach 10.000 ChatGPT-Konversationsdatensätzen im Zusammenhang mit Musik, und jeder Satz ist eine mehrrunde Konversation 
Geben Sie das Schlüsselwort „Mathe“ ein. Die Suche Die Ergebnisse zeigen 3346 Gruppen von Mehrrundengesprächen: 
Derzeit deckt UltraChat viele Informationsbereiche ab, darunter Medizin, Bildung, Sport, Umweltschutz und andere Themen. Gleichzeitig versuchte der Autor, das Open-Source-Modell LLaMa-7B zu verwenden, um eine Feinabstimmung der überwachten Anweisungen auf UltraChat durchzuführen, und stellte fest, dass nach nur 10.000 Trainingsschritten ein sehr beeindruckender Effekt erzielt wurde. Einige Beispiele sind wie folgt: 
 Weltwissen: separat aufgeführt Hier sind 10 gute chinesische und amerikanische Universitäten
Weltwissen: separat aufgeführt Hier sind 10 gute chinesische und amerikanische Universitäten
 Stellen Sie sich die Frage vor: Was sind die möglichen Konsequenzen, wenn Raumfahrt möglich wird?
Stellen Sie sich die Frage vor: Was sind die möglichen Konsequenzen, wenn Raumfahrt möglich wird?
Syllogismus: Ist ein Wal ein Fisch?

Hypothetische Frage: Beweisen Sie, dass Jackie Chan besser ist als Bruce Lee
Insgesamt ist UltraChat ein hochwertiger, umfassender ChatGPT-Konversationsdatensatz, der mit anderen kombiniert werden kann Datensätze, wodurch die Qualität von Open-Source-Dialogmodellen erheblich verbessert wird. Derzeit veröffentlicht UltraChat nur die englische Version, wird aber in Zukunft auch die chinesische Version der Daten veröffentlichen. Interessierte Leser sind herzlich eingeladen, sich damit auseinanderzusetzen.
Das obige ist der detaillierte Inhalt vonVerwendung mehrerer ChatGPT-APIs zur Implementierung von Tsinghua UltraChat-Mehrrundengesprächen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr