
Heim >Technologie-Peripheriegeräte >KI >Neue DeepMind-Forschung: Transformator kann sich ohne menschliches Eingreifen selbst verbessern
Neue DeepMind-Forschung: Transformator kann sich ohne menschliches Eingreifen selbst verbessern

- 王林nach vorne
- 2023-04-20 19:07:071245Durchsuche
Derzeit sind Transformer zu einer leistungsstarken neuronalen Netzwerkarchitektur für die Sequenzmodellierung geworden. Eine bemerkenswerte Eigenschaft vortrainierter Transformatoren ist ihre Fähigkeit, sich durch Cue-Konditionierung oder kontextbezogenes Lernen an nachgelagerte Aufgaben anzupassen. Nach einem Vortraining an großen Offline-Datensätzen hat sich gezeigt, dass große Transformatoren eine effiziente Verallgemeinerung auf nachgelagerte Aufgaben bei der Textvervollständigung, dem Sprachverständnis und der Bilderzeugung ermöglichen.
Neuere Arbeiten haben gezeigt, dass Transformatoren auch Richtlinien aus Offline-Daten lernen können, indem sie Offline-Reinforcement Learning (RL) als sequentielles Vorhersageproblem behandeln. Arbeiten von Chen et al. (2021) zeigten, dass Transformer durch Nachahmungslernen Einzeltask-Richtlinien aus Offline-RL-Daten lernen können, und nachfolgende Arbeiten zeigten, dass Transformer sowohl in derselben Domäne als auch in domänenübergreifenden Umgebungen Richtlinien für mehrere Aufgaben extrahieren können. Diese Arbeiten zeigen alle ein Paradigma für die Extraktion allgemeiner Multitasking-Richtlinien, d. h. zunächst das Sammeln großer und vielfältiger Datensätze zu Umweltinteraktionen und das anschließende Extrahieren von Richtlinien aus den Daten durch sequentielle Modellierung. Diese Methode zum Erlernen von Richtlinien aus Offline-RL-Daten durch Nachahmungslernen wird als Offline-Richtliniendestillation (Offline Policy Distillation) oder Richtliniendestillation (Policy Distillation, PD) bezeichnet.
PD bietet Einfachheit und Skalierbarkeit, aber einer seiner großen Nachteile besteht darin, dass sich die generierten Richtlinien durch zusätzliche Interaktionen mit der Umgebung nicht schrittweise verbessern. Beispielsweise lernte Googles Generalist-Agent Multi-Game Decision Transformers eine rückgabebedingte Richtlinie, mit der viele Atari-Spiele gespielt werden können, während DeepMinds Generalist-Agent Gato eine Lösung für verschiedene Probleme durch kontextbezogene Aufgabenbegründungsstrategien für Aufgaben in der Umgebung erlernte. Leider kann keiner der Agenten die Richtlinie im Kontext durch Versuch und Irrtum verbessern. Daher lernt die PD-Methode eher Richtlinien als verstärkende Lernalgorithmen.
In einem aktuellen DeepMind-Artikel stellten Forscher die Hypothese auf, dass der Grund dafür, dass sich PD durch Versuch und Irrtum nicht verbesserte, darin lag, dass die für das Training verwendeten Daten keinen Lernfortschritt anzeigen konnten. Aktuelle Methoden lernen entweder eine Richtlinie aus Daten, die kein Lernen enthalten (z. B. feste Expertenrichtlinie über Destillation) oder lernen eine Richtlinie aus Daten, die zwar Lernen enthalten (z. B. der Wiedergabepuffer eines RL-Agenten), aber die Kontextgröße des letzteren ( zu klein) Fehler bei der Erfassung politischer Verbesserungen.

Papieradresse: https://arxiv.org/pdf/2210.14215.pdf#🎜 Die wichtigste Beobachtung der Forscher ist, dass die sequentielle Natur des Lernens beim Training von RL-Algorithmen im Prinzip das verstärkende Lernen selbst als ein Problem der kausalen Sequenzvorhersage modellieren kann. Insbesondere wenn der Kontext eines Transformators lang genug ist, um die durch Lernaktualisierungen hervorgerufenen Richtlinienverbesserungen einzubeziehen, sollte er nicht nur in der Lage sein, eine feste Richtlinie darzustellen, sondern auch in der Lage sein, einen Richtlinienverbesserungsalgorithmus darzustellen, indem er sich auf die Zustände konzentriert , Aktionen und Belohnungen früherer Episoden, Sohn.
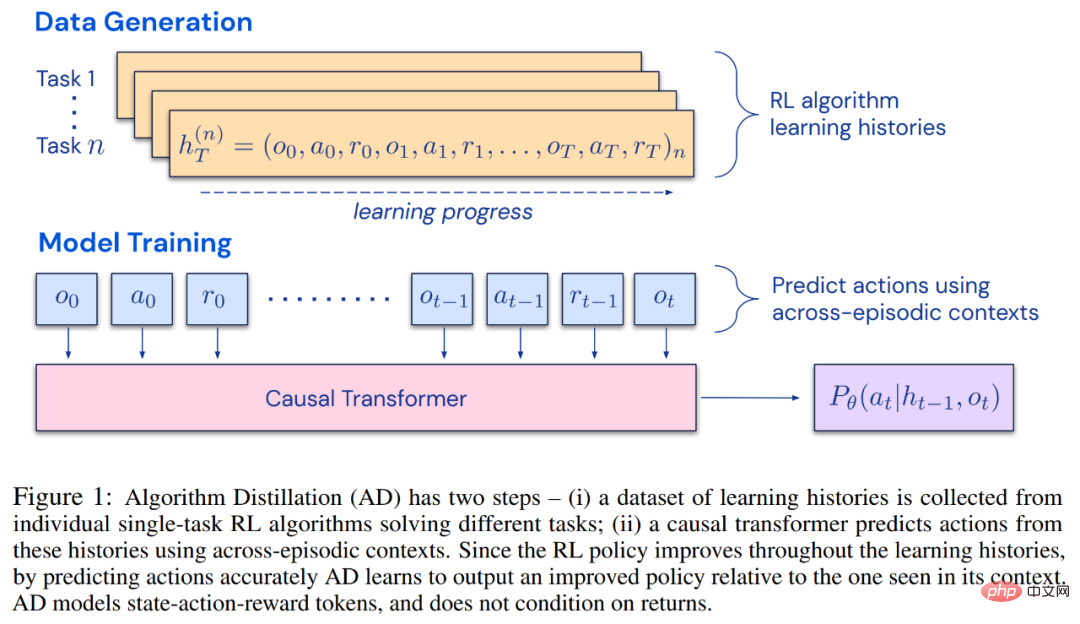
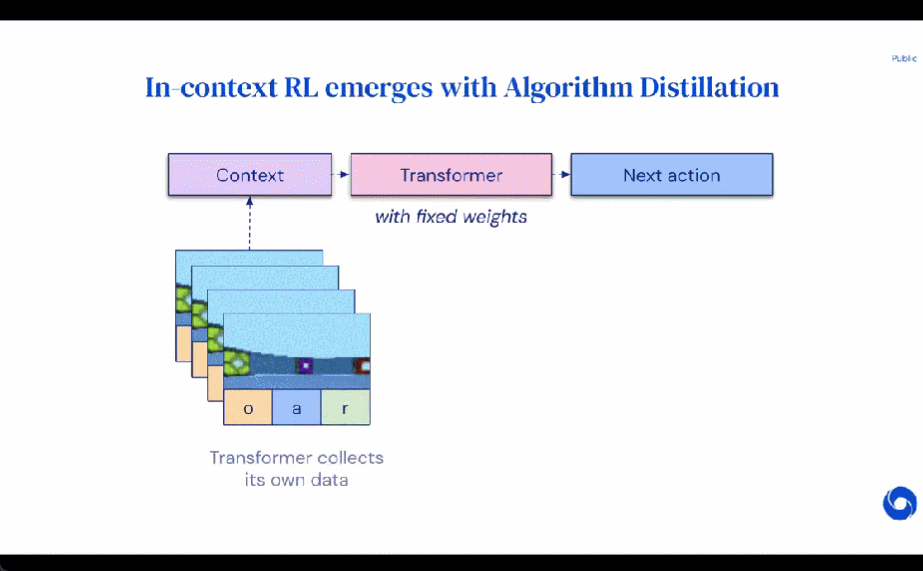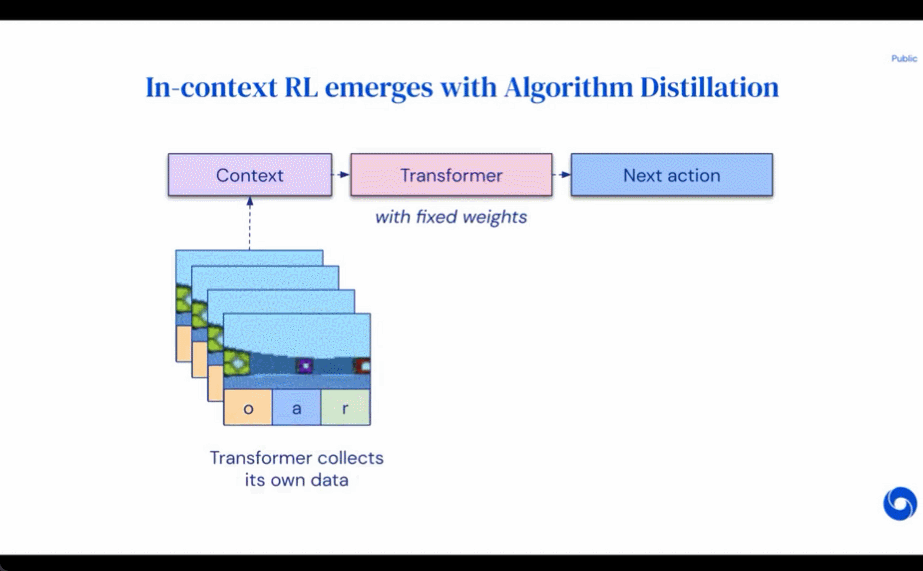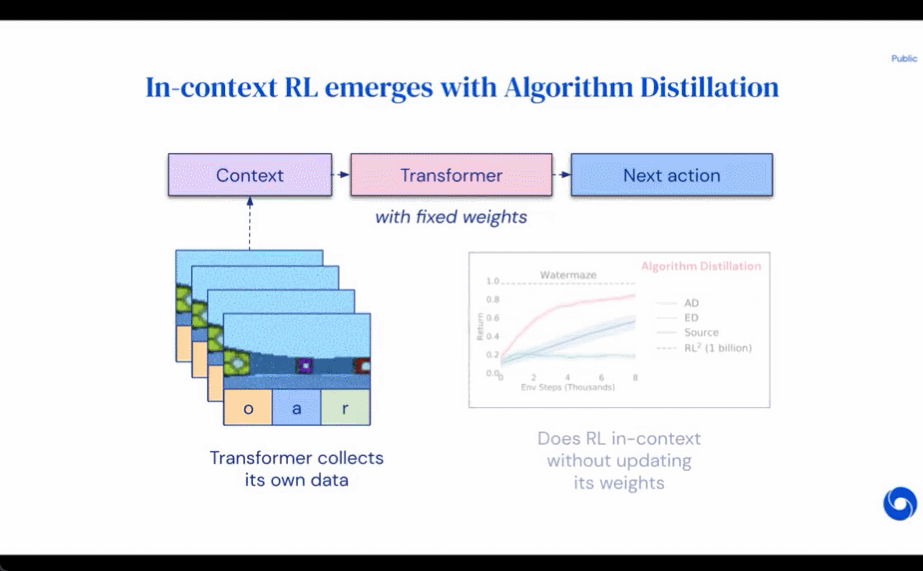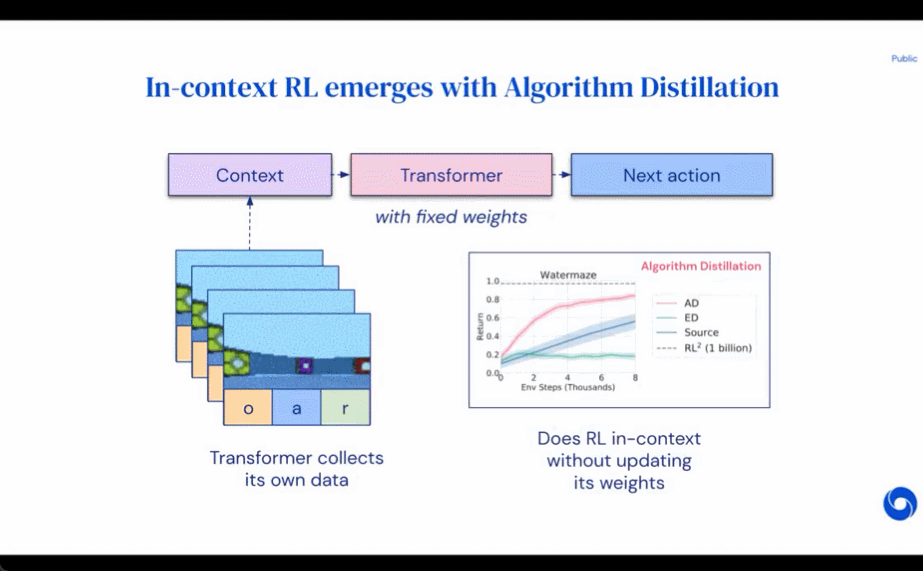
Dies eröffnet die Möglichkeit, dass jeder RL-Algorithmus durch Nachahmungslernen in ausreichend leistungsstarke Sequenzmodelle wie Transformatoren destilliert werden kann und diese Modelle in kontextbezogene RL-Algorithmen umgewandelt werden können.Der Forscher schlug die Algorithmusdestillation (AD) vor, eine Methode zum Lernen durch Optimierung des kausalen Sequenzvorhersageverlusts im Lernverlauf des RL-Algorithmus kontextbezogene Richtlinienverbesserungsoperatoren. Wie in Abbildung 1 unten dargestellt, besteht AD aus zwei Teilen. Ein großer Multitask-Datensatz wird zunächst generiert, indem der Trainingsverlauf eines RL-Algorithmus für eine große Anzahl einzelner Aufgaben gespeichert wird. Anschließend modelliert das Transformatormodell Aktionen kausal, indem es den vorherigen Lernverlauf als Kontext verwendet. Da sich die Richtlinie während des Trainings des Quell-RL-Algorithmus weiter verbessert, muss AD verbesserte Operatoren erlernen, um die Aktionen an jedem beliebigen Punkt im Trainingsverlauf genau zu modellieren. Entscheidend ist, dass der Transformatorkontext groß genug (d. h. episodisch) sein muss, um Verbesserungen in den Trainingsdaten zu erfassen.
Die Forscher gaben an, dass durch die Verwendung eines Kausaltransformators mit einem ausreichend großen Kontext der Gradienten-basierte RL-Algorithmus nachgeahmt werden könne , AD ist völlig neues Aufgabenlernen und kann im Kontext verstärkt werden. Wir haben AD in einer Reihe teilweise beobachtbarer Umgebungen untersucht, die erkundet werden müssen, darunter das pixelbasierte Watermaze von DMLab, und gezeigt, dass AD zur Kontexterkundung, zeitlichen Konfidenzzuweisung und Verallgemeinerung fähig ist. Darüber hinaus ist der von AD erlernte Algorithmus effizienter als der Algorithmus, der die Quelldaten des Transformatortrainings generiert hat.
Abschließend ist es erwähnenswert, dass AD die erste Methode ist, um kontextuelles Verstärkungslernen durch sequentielle Modellierung von Offline-Daten mit Imitationsverlust zu demonstrieren. #? gute Leistung bei der Ausführung komplexer Bewegungen. Für einen intelligenten Agenten kann er unabhängig von seiner Umgebung, internen Struktur und Ausführung auf der Grundlage vergangener Erfahrungen als abgeschlossen angesehen werden. Es kann in der folgenden Form ausgedrückt werden:
Forscher betrachten die „lange geschichtsbedingte“ Strategie auch als An Algorithmus, der Folgendes ergibt:
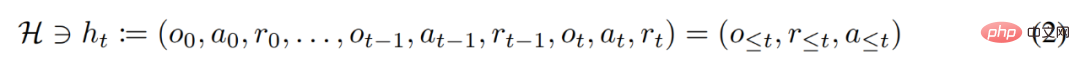 wobei Δ(A) den Wahrscheinlichkeitsverteilungsraum auf dem Aktionsraum A darstellt. Gleichung (3) zeigt, dass der Algorithmus in der Umgebung entfaltet werden kann, um Sequenzen von Beobachtungen, Belohnungen und Aktionen zu generieren. Der Einfachheit halber stellt diese Studie den Algorithmus als P und die Umgebung (d. h. Aufgabe) als
wobei Δ(A) den Wahrscheinlichkeitsverteilungsraum auf dem Aktionsraum A darstellt. Gleichung (3) zeigt, dass der Algorithmus in der Umgebung entfaltet werden kann, um Sequenzen von Beobachtungen, Belohnungen und Aktionen zu generieren. Der Einfachheit halber stellt diese Studie den Algorithmus als P und die Umgebung (d. h. Aufgabe) als
dar. Die Lernhistorie wird durch den Algorithmus dargestellt, sodass für jede gegebene Aufgabe
 Generiert. Sie können
Generiert. Sie können
 erhalten. Forscher verwenden lateinische Großbuchstaben, um Zufallsvariablen wie O, A, R und ihre darzustellen entsprechende Kleinbuchstabenformen o, α, r. Indem sie Algorithmen als langfristige, geschichtsbedingte Richtlinien betrachteten, stellten sie die Hypothese auf, dass jeder Algorithmus, der eine Lernhistorie generiert, durch Verhaltensklonen von Aktionen in ein neuronales Netzwerk umgewandelt werden kann. Als nächstes schlägt die Studie einen Ansatz vor, der Agenten das lebenslange Lernen von Sequenzmodellen mit Verhaltensklonen ermöglicht, um den Langzeitverlauf auf Aktionsverteilungen abzubilden.
erhalten. Forscher verwenden lateinische Großbuchstaben, um Zufallsvariablen wie O, A, R und ihre darzustellen entsprechende Kleinbuchstabenformen o, α, r. Indem sie Algorithmen als langfristige, geschichtsbedingte Richtlinien betrachteten, stellten sie die Hypothese auf, dass jeder Algorithmus, der eine Lernhistorie generiert, durch Verhaltensklonen von Aktionen in ein neuronales Netzwerk umgewandelt werden kann. Als nächstes schlägt die Studie einen Ansatz vor, der Agenten das lebenslange Lernen von Sequenzmodellen mit Verhaltensklonen ermöglicht, um den Langzeitverlauf auf Aktionsverteilungen abzubilden.  Tatsächliche Ausführung
Tatsächliche Ausführung
In der Praxis implementiert diese Forschung den Algorithmusdestillationsprozess (Algorithmusdestillation, AD) als zweistufigen Prozess. Zunächst wird ein Lernverlaufsdatensatz erfasst, indem einzelne, auf Gradienten basierende RL-Algorithmen für viele verschiedene Aufgaben ausgeführt werden. Als nächstes wird ein Sequenzmodell mit Kontext aus mehreren Episoden trainiert, um Aktionen im Verlauf vorherzusagen. Der spezifische Algorithmus lautet wie folgt: 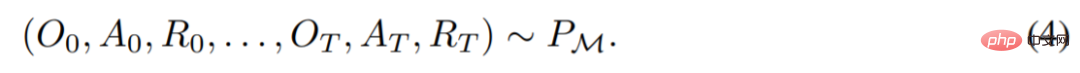
Experiment
Die für das Experiment erforderliche Umgebung Es unterstützt viele Aufgaben, die nicht einfach aus Beobachtungen abgeleitet werden können, und die Episoden sind kurz genug, um episodenübergreifende kausale Transformatoren effizient zu trainieren. Das Hauptziel dieser Arbeit bestand darin, zu untersuchen, inwieweit AD-Verstärkung im Vergleich zu früheren Arbeiten im Kontext gelernt wird. Das Experiment verglich AD, ED (Expert Distillation), RL^2 usw.
Die Ergebnisse der Auswertung von AD, ED und RL^2 sind in Abbildung 3 dargestellt. Die Studie ergab, dass sowohl AD als auch RL^2 kontextbezogen anhand von Aufgaben aus der Trainingsverteilung lernen können, während ED dies nicht kann, obwohl ED bei der Auswertung innerhalb einer Verteilung besser abschneidet als zufälliges Raten. 
Bezüglich Abbildung 4 unten beantwortete der Forscher eine Reihe von Fragen. Zeigt AD kontextuelles Verstärkungslernen? Die Ergebnisse zeigen, dass AD kontextuelles Verstärkungslernen in allen Umgebungen lernen kann, ED dagegen in den meisten Situationen nicht im Kontext erforschen und lernen kann. Kann AD aus pixelbasierten Beobachtungen lernen? Die Ergebnisse zeigen, dass AD die episodische Regression durch kontextuelles RL maximiert, während ED nicht lernt.
AD Ist es möglich, einen RL-Algorithmus zu lernen, der effizienter ist als der Algorithmus, der die Quelldaten generiert hat? Die Ergebnisse zeigen, dass die Dateneffizienz von AD deutlich höher ist als die der Quellalgorithmen (A3C und DQN). Ist es möglich, AD mit einer Demo zu beschleunigen? Um diese Frage zu beantworten, behält diese Studie die Stichprobenstrategie an verschiedenen Punkten im Verlauf des Quellalgorithmus in den Testsatzdaten bei, verwendet dann diese Strategiedaten, um den Kontext von AD und ED vorab zu füllen, und führt beide Methoden im aus Kontext von Dark Room. Die Ergebnisse sind in Abbildung 5 dargestellt. Während ED die Leistung der Eingaberichtlinien beibehält, verbessert AD jede Richtlinie im Kontext, bis sie nahezu optimal ist. Wichtig ist: Je optimierter die Eingabestrategie ist, desto schneller verbessert AD sie, bis sie das Optimum erreicht.
Weitere Einzelheiten finden Sie im Originalpapier. 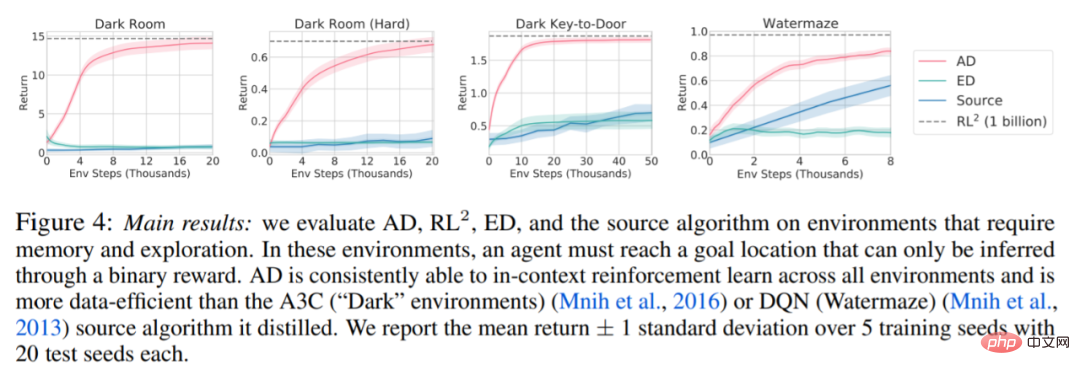
Das obige ist der detaillierte Inhalt vonNeue DeepMind-Forschung: Transformator kann sich ohne menschliches Eingreifen selbst verbessern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr