
Heim >Technologie-Peripheriegeräte >KI >„Von GAN zu ChatGPT: Die Lehigh University beschreibt die Entwicklung von KI-generierten Inhalten'
„Von GAN zu ChatGPT: Die Lehigh University beschreibt die Entwicklung von KI-generierten Inhalten'

- 王林nach vorne
- 2023-04-20 17:55:081209Durchsuche
ChatGPT und andere generative KI (GAI)-Technologien fallen in die Kategorie der durch künstliche Intelligenz generierten Inhalte (AIGC), bei der digitale Inhalte wie Bilder, Musik und natürliche Sprache durch KI-Modelle erstellt werden. Ziel von AIGC ist es, den Content-Erstellungsprozess effizienter und zugänglicher zu gestalten und so die Produktion hochwertiger Inhalte schneller zu ermöglichen. AIGC wird erreicht, indem Absichtsinformationen aus Anweisungen von Menschen extrahiert und verstanden werden und Inhalte basierend auf ihrem Wissen und ihren Absichtsinformationen generiert werden.
In den letzten Jahren sind groß angelegte Modelle in AIGC immer wichtiger geworden, da sie eine bessere Absichtsextraktion ermöglichen und dadurch die Generierungsergebnisse verbessern. Mit zunehmender Daten- und Modellgröße werden die Verteilungen, die Modelle lernen können, umfassender und näher an der Realität, was zu realistischeren und qualitativ hochwertigeren Inhalten führt.
Dieser Artikel bietet einen umfassenden Überblick über die Geschichte, die Grundkomponenten und die jüngsten Fortschritte von AIGC, von der einmodalen Interaktion bis zur multimodalen Interaktion. Aus einer Single-Modal-Perspektive werden in diesem Artikel Text- und Bildgenerierungsaufgaben und zugehörige Modelle vorgestellt. Aus einer multimodalen Perspektive werden die übergreifenden Anwendungen zwischen den oben genannten Modalitäten vorgestellt. Abschließend werden die offenen Fragen und zukünftigen Herausforderungen der AIGC diskutiert.

Papieradresse: https://arxiv.org /abs/2303.04226
Einführung
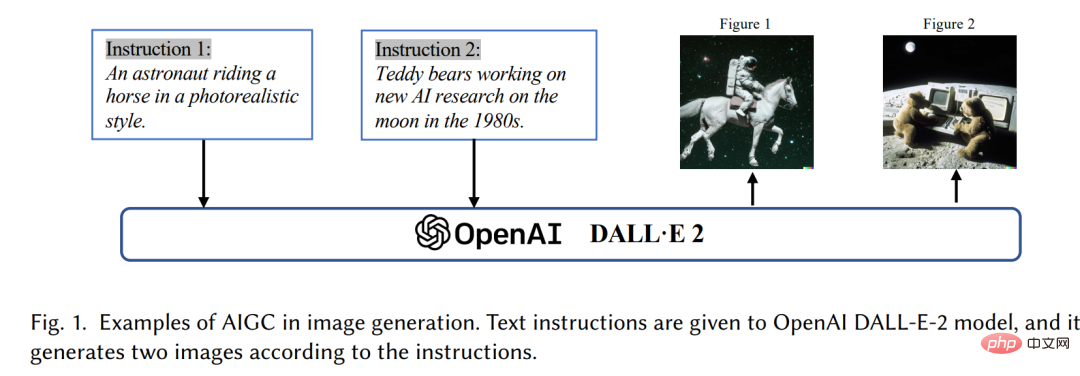
In den letzten Jahren haben durch künstliche Intelligenz generierte Inhalte (AIGC) große Beachtung gefunden In der Informatik-Community hat die Gesellschaft im Allgemeinen begonnen, verschiedenen Produkten zur Inhaltsgenerierung große Aufmerksamkeit zu schenken, die von großen Technologieunternehmen [3] entwickelt wurden, wie z. B. ChatGPT [4] und DALL-E2 [5]. AIGC bezieht sich auf Inhalte, die mithilfe fortschrittlicher generativer KI (GAI)-Technologie erstellt wurden, und nicht auf Inhalte, die von menschlichen Autoren erstellt wurden. AIGC kann automatisch große Mengen an Inhalten in kurzer Zeit erstellen. ChatGPT ist beispielsweise ein von OpenAI entwickeltes Sprachmodell zum Aufbau von Konversationssystemen mit künstlicher Intelligenz, die menschliche Spracheingaben effektiv verstehen und auf sinnvolle Weise reagieren können. Darüber hinaus ist DALL-E-2 ein weiteres hochmodernes GAI-Modell, das ebenfalls von OpenAI entwickelt wurde und in der Lage ist, innerhalb von Minuten einzigartige, hochwertige Bilder aus Textbeschreibungen zu erstellen, wie in Abbildung 1 „Ein Astronaut mit“ dargestellt ein Reiten im realistischen Stil". Angesichts der herausragenden Leistungen von AIGC glauben viele Menschen, dass dies eine neue Ära der künstlichen Intelligenz sein wird und erhebliche Auswirkungen auf die ganze Welt haben wird.
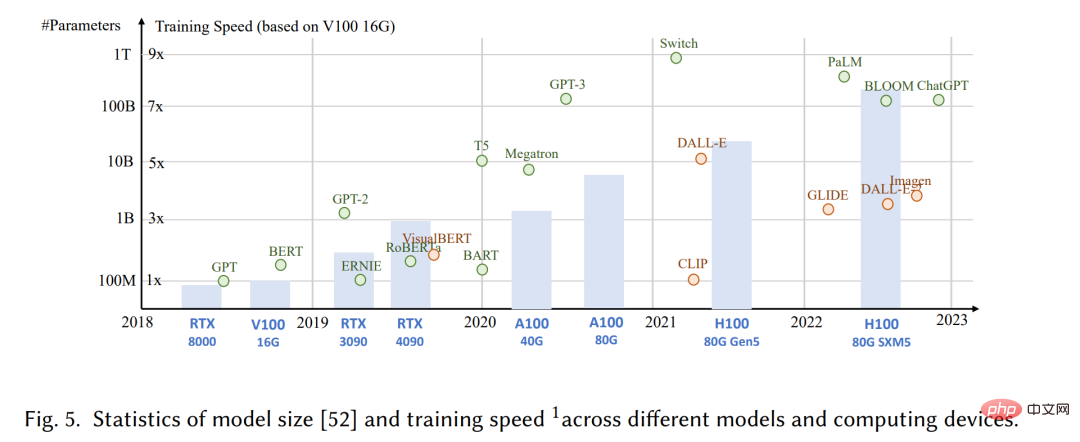
Technisch gesehen bezieht sich AIGC auf die gegebenen manuellen Anweisungen kann dabei helfen, das Modell zu lehren und bei der Erledigung von Aufgaben anzuleiten, und den GAI-Algorithmus verwenden, um Inhalte zu generieren, die den Anweisungen entsprechen. Der Generierungsprozess umfasst normalerweise zwei Schritte: Extrahieren von Absichtsinformationen aus menschlichen Anweisungen und Generieren von Inhalten basierend auf der extrahierten Absicht. Wie jedoch in früheren Studien gezeigt wurde [6,7], ist das Paradigma des GAI-Modells, das die beiden oben genannten Schritte enthält, nicht völlig neu. Im Vergleich zu früheren Arbeiten besteht der Kernfortschritt der jüngsten AIGC darin, komplexere generative Modelle auf größeren Datensätzen zu trainieren, größere Basismodellarchitekturen zu verwenden und Zugriff auf eine breite Palette von Rechenressourcen zu haben. Beispielsweise bleibt das Hauptframework von GPT-3 das gleiche wie bei GPT-2, aber die Datengröße vor dem Training erhöht sich von WebText [8] (38 GB) auf CommonCrawl [9] (570 GB nach dem Filtern) und die Größe des Basismodells steigt von 1,5B auf 175B. Daher verfügt GPT-3 über eine bessere Generalisierungsfähigkeit als GPT-2 bei Aufgaben wie der Extraktion menschlicher Absichten.
Zusätzlich zu den Vorteilen eines erhöhten Datenvolumens und einer höheren Rechenleistung erforschen Forscher auch Möglichkeiten, neue Technologien in GAI-Algorithmen zu integrieren. ChatGPT nutzt beispielsweise Reinforcement Learning aus menschlichem Feedback (RLHF) [10–12], um die am besten geeignete Reaktion auf eine bestimmte Anweisung zu ermitteln und so die Zuverlässigkeit und Genauigkeit des Modells im Laufe der Zeit zu verbessern. Dieser Ansatz ermöglicht es ChatGPT, menschliche Vorlieben in langen Gesprächen besser zu verstehen. Gleichzeitig wurde im Bereich Computer Vision von Stability [13] eine stabile Diffusion vorgeschlagen. Auch bei der Bildgenerierung hat KI im Jahr 2022 große Erfolge erzielt. Im Gegensatz zu früheren Methoden können generative Diffusionsmodelle dabei helfen, hochauflösende Bilder zu erzeugen, indem sie den Kompromiss zwischen Erkundung und Nutzung steuern und so die Vielfalt der generierten Bilder und ihre Ähnlichkeit mit den Trainingsdaten harmonisch kombinieren.
Durch die Kombination dieser Fortschritte hat das Modell erhebliche Fortschritte bei AIGC-Aufgaben gemacht und wurde in verschiedenen Branchen angewendet, darunter Kunst [14], Werbung [15], Bildung [16] usw. In naher Zukunft wird AIGC weiterhin ein wichtiger Forschungsbereich im maschinellen Lernen werden. Daher ist es von entscheidender Bedeutung, eine umfassende Übersicht über die bisherige Forschung durchzuführen und offene Fragen auf diesem Gebiet zu identifizieren. Die Kerntechnologien und Anwendungen im Bereich AIGC werden besprochen.
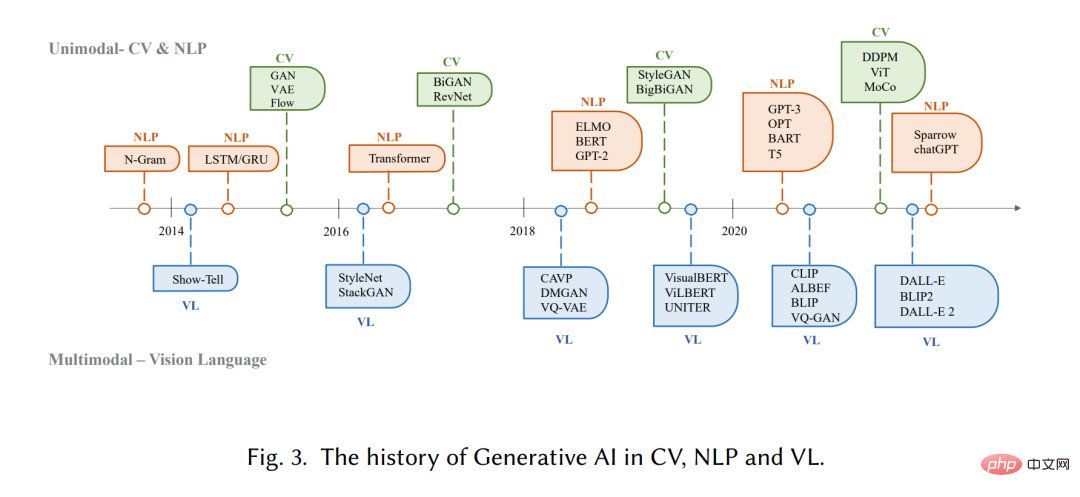
Dies ist die erste umfassende Übersicht über AIGC, die GAI sowohl unter technischen als auch unter Anwendungsaspekten zusammenfasst. Frühere Forschungen haben sich auf GAI aus verschiedenen Perspektiven konzentriert, einschließlich der Erzeugung natürlicher Sprache [17], der Bilderzeugung [18] und der Erzeugung im multimodalen maschinellen Lernen [7, 19]. Bisherige Arbeiten konzentrierten sich jedoch nur auf bestimmte Teile von AIGC. In diesem Artikel werden zunächst die grundlegenden Techniken besprochen, die üblicherweise bei AIGC verwendet werden. Darüber hinaus wird eine umfassende Zusammenfassung des erweiterten GAI-Algorithmus bereitgestellt, einschließlich der Erzeugung einzelner und mehrerer Spitzen, wie in Abbildung 2 dargestellt. Darüber hinaus werden die Anwendungen und potenziellen Herausforderungen von AIGC diskutiert. Abschließend werden bestehende Probleme und zukünftige Forschungsrichtungen in diesem Bereich aufgezeigt. Zusammenfassend sind die Hauptbeiträge dieses Artikels wie folgt:
- Soweit wir wissen, sind wir die ersten, die AIGC verbessern und KI Der generative Prozess bietet der Person formale Definitionen und gründliche Forschung.
- Bespricht die Geschichte und grundlegende Technologie von AIGC und führt eine umfassende Analyse der neuesten Fortschritte von GAI-Aufgaben und -Modellen aus der Perspektive der Single-Modal-Generierung und der Multi-Modal-Generierung durch.
- diskutierte die wichtigsten Herausforderungen für AIGC und die zukünftigen Forschungstrends von AIGC.
Der Rest der Umfrage ist wie folgt organisiert. Abschnitt 2 befasst sich hauptsächlich mit der Geschichte von AIGC unter zwei Gesichtspunkten: der visuellen Modalität und der sprachlichen Modalität. Abschnitt 3 stellt die Grundkomponenten vor, die derzeit häufig im GAI-Modelltraining verwendet werden. Abschnitt 4 fasst die jüngsten Fortschritte bei GAI-Modellen zusammen, wobei Abschnitt 4.1 den Fortschritt aus einer monomodalen Perspektive und Abschnitt 4.2 den Fortschritt aus einer multimodalen Generierungsperspektive bespricht. Bei der multimodalen Generierung werden visuelle Sprachmodelle, Text-Audio-Modelle, Textgraph-Modelle und Textcode-Modelle eingeführt. Die Abschnitte 5 und 6 stellen die Anwendung des GAI-Modells in der AIGC und einige wichtige Forschungsarbeiten in diesem Bereich vor. Die Abschnitte 7 und 8 zeigen die Risiken, bestehenden Probleme und zukünftigen Entwicklungsrichtungen der AIGC-Technologie auf. Abschließend fassen wir unsere Studie in 9 zusammen.
Die Geschichte der generativen künstlichen Intelligenz
Generative Modelle haben eine lange Geschichte im Bereich der künstlichen Intelligenz, die bis in die 1950er Jahre zurückreicht Entwicklung von Markov-Modellen (HMM) [20] und Gaußschen Mischungsmodellen (GMMs) [21]. Diese Modelle generieren sequentielle Daten wie Sprache und Zeitreihen. Allerdings kam es erst mit dem Aufkommen von Deep Learning zu deutlichen Leistungsverbesserungen bei generativen Modellen.
In frühen tiefen generativen Modellen hatten verschiedene Domänen normalerweise nicht viele Lots der Überlappung. Bei der Verarbeitung natürlicher Sprache (NLP) besteht die traditionelle Methode zur Satzgenerierung darin, mithilfe der N-Gramm-Sprachmodellierung [22] die Wortverteilung zu lernen und dann nach der besten Reihenfolge zu suchen. Diese Methode kann sich jedoch nicht effektiv an lange Sätze anpassen. Um dieses Problem zu lösen, wurden später wiederkehrende neuronale Netze (RNN) [23] in Sprachmodellierungsaufgaben eingeführt, die die Modellierung relativ langer Abhängigkeiten ermöglichen. Anschließend erfolgte die Entwicklung des Langzeitgedächtnisses (LSTM) [24] und der Gated Recurrent Units (GRU) [25], die Gating-Mechanismen nutzen, um das Gedächtnis während des Trainings zu steuern. Diese Methoden sind in der Lage, etwa 200 Token in der Stichprobe zu verarbeiten [26], was eine deutliche Verbesserung im Vergleich zu N-Gramm-Sprachmodellen darstellt.
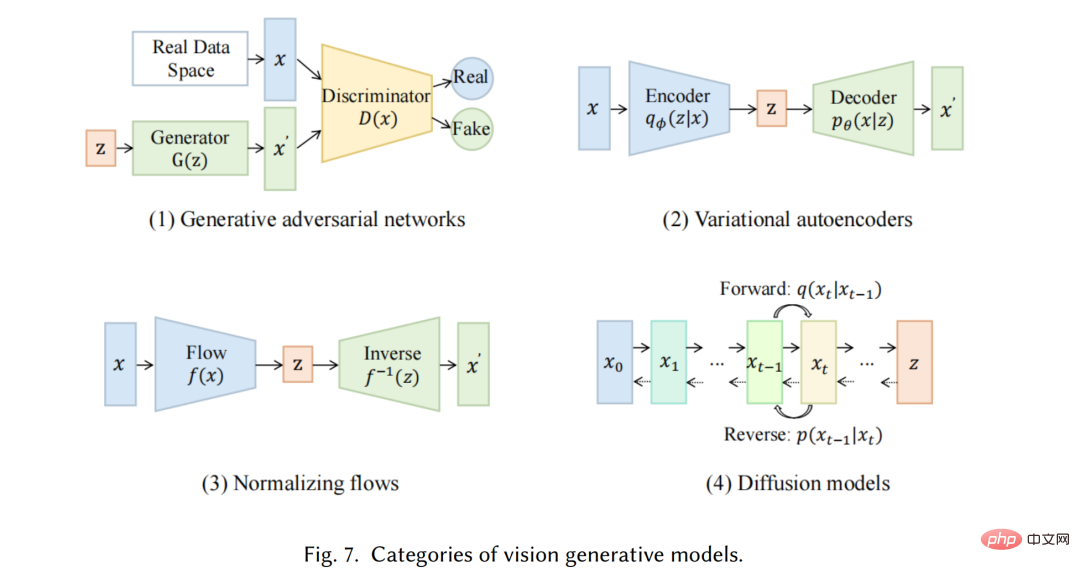
Vor dem Aufkommen von Deep-Learning-basierten Methoden verwendeten traditionelle Bilderzeugungsalgorithmen im Bereich Computer Vision (CV) Textursynthese [27] und Textur Kartierung [28] und andere Technologien. Diese Algorithmen basieren auf manuell entwickelten Funktionen und verfügen nur über begrenzte Möglichkeiten zur Generierung komplexer und vielfältiger Bilder. Im Jahr 2014 wurden Generative Adversarial Networks (GANs) [29] erstmals vorgeschlagen und erzielten beeindruckende Ergebnisse in verschiedenen Anwendungen, was einen wichtigen Meilenstein auf diesem Gebiet darstellt. Variations-Autoencoder (VAE) [30] und andere Methoden, wie z. B. generative Diffusionsmodelle [31], wurden ebenfalls entwickelt, um den Bilderzeugungsprozess feiner zu steuern und qualitativ hochwertige Bilder zu erzeugen# 🎜 🎜#
Die Entwicklung generativer Modelle in verschiedenen Bereichen verläuft auf unterschiedlichen Wegen, aber letztendlich entsteht ein übergreifendes Problem: die Transformatorarchitektur [32]. Vaswani et al. führten 2017 die NLP-Aufgabe ein, und Transformer wurde später auf CV angewendet und wurde dann zum Hauptrückgrat vieler generativer Modelle in verschiedenen Bereichen [9, 33, 34]. Im Bereich NLP übernehmen viele bekannte groß angelegte Sprachmodelle wie BERT und GPT die Transformatorarchitektur als Hauptbaustein, was Vorteile gegenüber früheren Bausteinen wie LSTM und GRU bietet. In CV entwickelten Vision Transformer (ViT) [35] und Swin Transformer [36] dieses Konzept später weiter, indem sie die Transformer-Architektur mit einer Vision-Komponente kombinierten, sodass es auf bildbasierte Downstream-Anwendungen angewendet werden kann. Zusätzlich zu den Verbesserungen, die Transformatoren für einzelne Modalitäten mit sich bringen, ermöglicht dieser Crossover auch die Zusammenführung von Modellen aus verschiedenen Domänen, um multimodale Aufgaben zu erfüllen. Ein Beispiel für ein multimodales Modell ist CLIP [37]. CLIP ist ein gemeinsames Vision-Sprachmodell, das eine Transformatorarchitektur mit einer Vision-Komponente kombiniert und so das Training auf großen Mengen an Text- und Bilddaten ermöglicht. Da es während des Vortrainings visuelles und sprachliches Wissen kombiniert, kann es auch als Bildencoder bei der multimodalen Cue-Generierung verwendet werden. Alles in allem hat das Aufkommen transformatorbasierter Modelle die Produktion künstlicher Intelligenz revolutioniert und die Möglichkeit groß angelegter Schulungen eröffnet.
In den letzten Jahren haben Forscher auch damit begonnen, neue Technologien auf Basis dieser Modelle einzuführen. Im NLP beispielsweise bevorzugen Menschen manchmal Hinweise mit wenigen Schüssen [38] gegenüber der Feinabstimmung. Dabei geht es darum, einige aus dem Datensatz ausgewählte Beispiele in den Hinweis aufzunehmen, um dem Modell zu helfen, die Aufgabenanforderungen besser zu verstehen. In visuellen Sprachen kombinieren Forscher häufig modalitätsspezifische Modelle mit selbstüberwachten kontrastiven Lernzielen, um robustere Darstellungen bereitzustellen. Da AIGC in Zukunft immer wichtiger wird, werden immer mehr Technologien eingeführt, wodurch dieser Bereich voller Vitalität wird.
Generative Künstliche Intelligenz
Wir stellen vor modernste unimodale generative Modelle. Diese Modelle sind so konzipiert, dass sie eine bestimmte Rohdatenmodalität wie Text oder Bilder als Eingabe akzeptieren und dann Vorhersagen in derselben Modalität wie die Eingabe generieren. Wir werden einige der vielversprechendsten Methoden und Techniken diskutieren, die in diesen Modellen verwendet werden, darunter generative Sprachmodelle wie GPT3 [9], BART [34], T5 [56] und generative Vision-Modelle wie GAN [29], VAE [30]. ] und normalisierter Fluss [57].
Multimodales Modell
#🎜 🎜#Multimodale Generierung ist ein wichtiger Teil der heutigen AIGC. Das Ziel der multimodalen Generierung besteht darin, zu lernen, Modelle ursprünglicher Modalitäten zu generieren, indem multimodale Verbindungen und Interaktionen von Daten gelernt werden [7]. Solche Verbindungen und Interaktionen zwischen Modalitäten sind teilweise sehr komplex, was das Erlernen multimodaler Repräsentationsräume im Vergleich zu monomodalen Repräsentationsräumen erschwert. Mit dem Aufkommen der bereits erwähnten leistungsstarken musterspezifischen Infrastruktur werden jedoch immer mehr Methoden vorgeschlagen, um dieser Herausforderung zu begegnen. In diesem Abschnitt stellen wir modernste multimodale Modelle in den Bereichen visuelle Sprachgenerierung, textuelle Audiogenerierung, textuelle Grafikgenerierung und textuelle Codegenerierung vor. Da die meisten multimodalen generativen Modelle immer eine hohe Relevanz für praktische Anwendungen haben, werden sie in diesem Abschnitt hauptsächlich aus der Perspektive nachgelagerter Aufgaben vorgestellt.
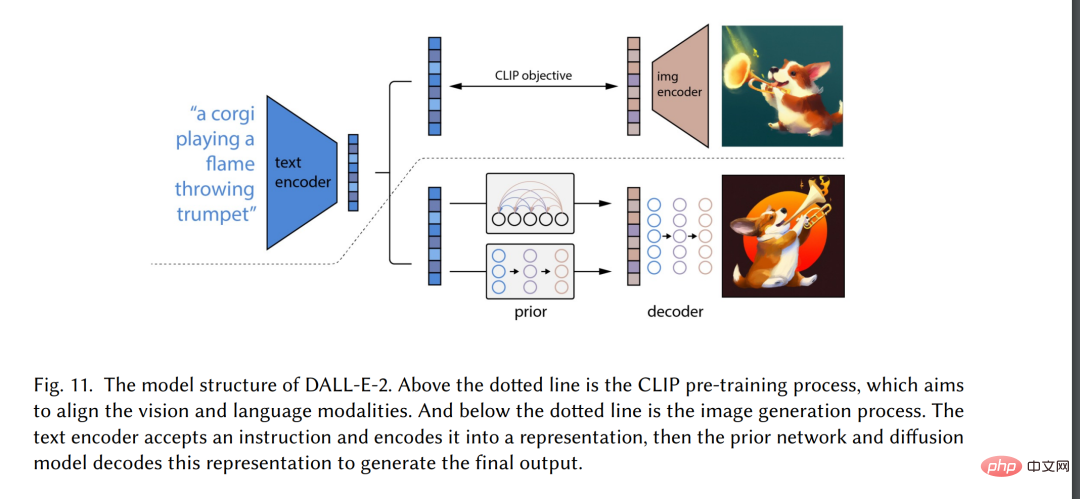
# 🎜🎜#
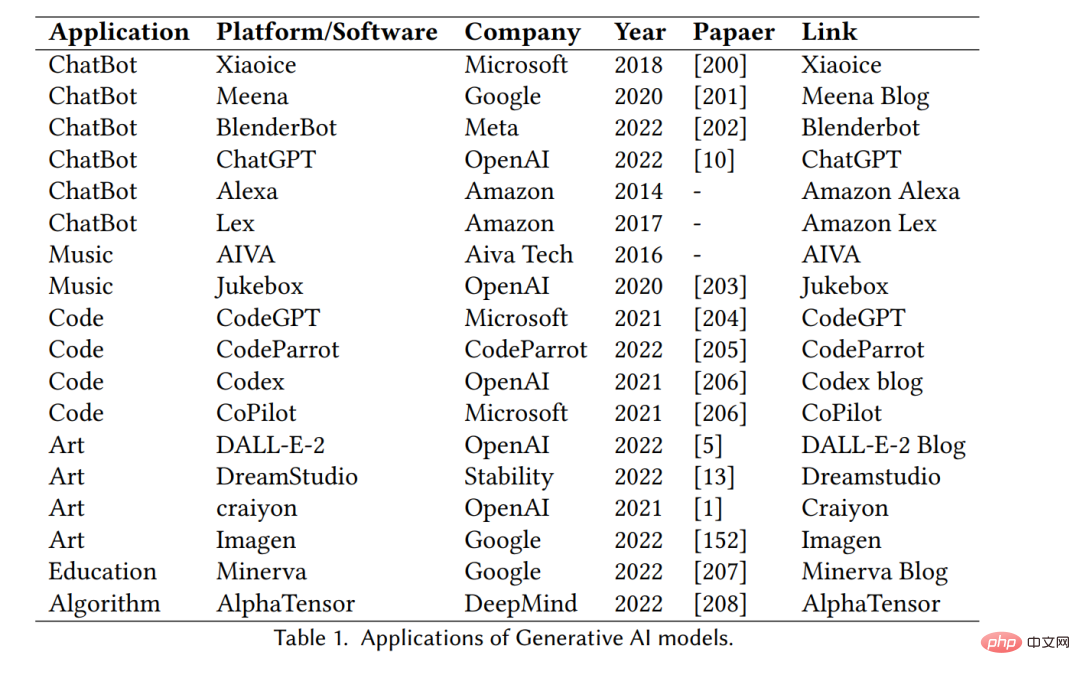
Das obige ist der detaillierte Inhalt von„Von GAN zu ChatGPT: Die Lehigh University beschreibt die Entwicklung von KI-generierten Inhalten'. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr