
Heim >Technologie-Peripheriegeräte >KI >Der höchste KI-Score der Geschichte! Das große Modell von Google stellt einen neuen Rekord für Fragen zur Prüfung der medizinischen Zulassung in den USA auf und der Grad der wissenschaftlichen Kenntnisse ist mit dem von menschlichen Ärzten vergleichbar
Der höchste KI-Score der Geschichte! Das große Modell von Google stellt einen neuen Rekord für Fragen zur Prüfung der medizinischen Zulassung in den USA auf und der Grad der wissenschaftlichen Kenntnisse ist mit dem von menschlichen Ärzten vergleichbar

- PHPznach vorne
- 2023-04-18 16:49:031273Durchsuche
Das neue Modell von Google hat den höchsten KI-Wert in der Geschichte und hat gerade die Verifizierung der US-amerikanischen medizinischen Zulassungsprüfung bestanden!
Und bei Aufgaben wie wissenschaftlichem Wissen, Verständnis, Abruf- und Argumentationsfähigkeiten konkurriert es direkt mit dem Niveau menschlicher Ärzte. Bei einigen klinischen Frage- und Antwortleistungen übertraf es das ursprüngliche SOTA-Modell um mehr als 17 %.


Sobald diese Entwicklung bekannt wurde, löste sie sofort heftige Diskussionen in der akademischen Gemeinschaft aus. Viele Menschen in der Branche seufzten: Endlich ist es da.
Nachdem viele Internetnutzer den Vergleich zwischen Med-PaLM und menschlichen Ärzten gesehen hatten, äußerten sie, dass sie sich bereits auf die Ernennung von KI-Ärzten freuen.

Einige Leute machten sich auch über die Genauigkeit dieses Timings lustig, was mit der Annahme zusammenfiel, dass Google wegen ChatGPT „sterben“ würde.

Mal sehen, was für eine Art Forschung das ist?
Der höchste KI-Wert in der Geschichte
Aufgrund des professionellen Charakters der medizinischen Versorgung nutzen die heutigen KI-Modelle in diesem Bereich die Sprache nicht in großem Umfang. Obwohl diese Modelle nützlich sind, weisen sie Probleme auf, z. B. die Konzentration auf Einzelaufgabensysteme (wie Klassifizierung, Regression, Segmentierung usw.) sowie mangelnde Ausdruckskraft und interaktive Fähigkeiten.
Durchbrüche bei großen Modellen haben der KI+-medizinischen Versorgung neue Möglichkeiten eröffnet, aber aufgrund der Besonderheit dieses Bereichs müssen potenzielle Schäden, wie die Bereitstellung falscher medizinischer Informationen, immer noch in Betracht gezogen werden.
Vor diesem Hintergrund haben die Teams von Google Research und DeepMind medizinische Fragen und Antworten als Forschungsobjekt genommen und die folgenden Beiträge geleistet:
- Einen medizinischen Q&A-Benchmark MultiMedQA vorgeschlagen, einschließlich medizinischer Untersuchungen, medizinischer Forschung und medizinischer Verbraucherfragen.
- Bewertet PaLM und die verfeinerte Variante Flan-PaLM auf MultiMedQA;
- Vorgeschlagene Anweisungsaufforderung x Anpassung zur weiteren Integration von Flan-PaLM mit Medikamenten, was zu Med-PaLM führte.

Sie glauben, dass die Aufgabe der „Beantwortung medizinischer Fragen“ eine große Herausforderung darstellt, da die KI den medizinischen Hintergrund verstehen, entsprechendes medizinisches Wissen abrufen und Experteninformationen begründen muss, um qualitativ hochwertige Antworten zu liefern.
Bestehende Bewertungsbenchmarks beschränken sich häufig auf die Bewertung der Klassifizierungsgenauigkeit oder der Indikatoren für die Erzeugung natürlicher Sprache, können jedoch keine detaillierte Analyse tatsächlicher klinischer Anwendungen liefern.
Zuerst schlug das Team einen Benchmark vor, der aus 7 medizinischen Frage-Antwort-Datensätzen bestand.
Enthält 6 vorhandene Datensätze, darunter auch MedQA (USMLE, Prüfungsfragen zur medizinischen Zulassung der Vereinigten Staaten) und führt außerdem den eigenen neuen Datensatz HealthSearchQA ein, der aus gesuchten Gesundheitsfragen besteht.
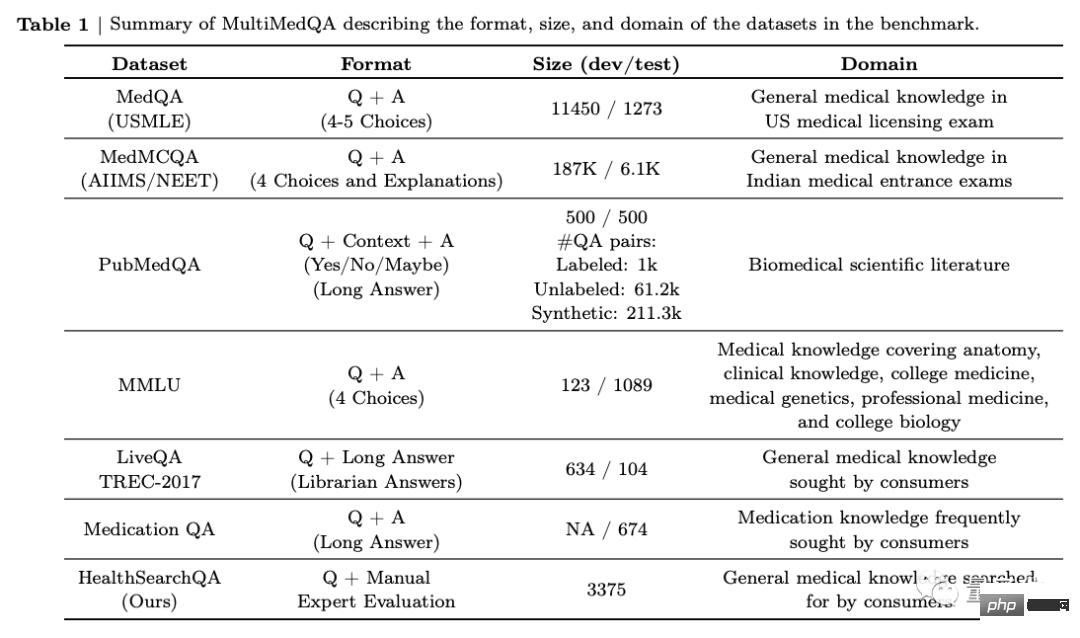
Dazu gehören ärztliche Untersuchungen, medizinische Forschung und verbrauchermedizinische Fragen.
Dann nutzte das Team MultiMedQA, um PaLM (540 Milliarden Parameter) und die Variante Flan-PaLM mit fein abgestimmten Anweisungen zu evaluieren. Zum Beispiel durch die Erweiterung der Anzahl der Aufgaben, der Modellgröße und der Strategie zur Nutzung von Denkkettendaten.
FLAN ist ein fein abgestimmtes Sprachnetzwerk, das letztes Jahr von Google Research vorgeschlagen wurde. Es optimiert das Modell, um es besser für allgemeine NLP-Aufgaben geeignet zu machen, und verwendet Befehlsanpassungen, um das Modell zu trainieren.
Es wurde festgestellt, dass Flan-PaLM bei mehreren Benchmarks wie MedQA, MedMCQA, PubMedQA und MMLU eine optimale Leistung erzielte. Insbesondere der MedQA-Datensatz (USMLE) übertraf das vorherige SOTA-Modell um mehr als 17 %.
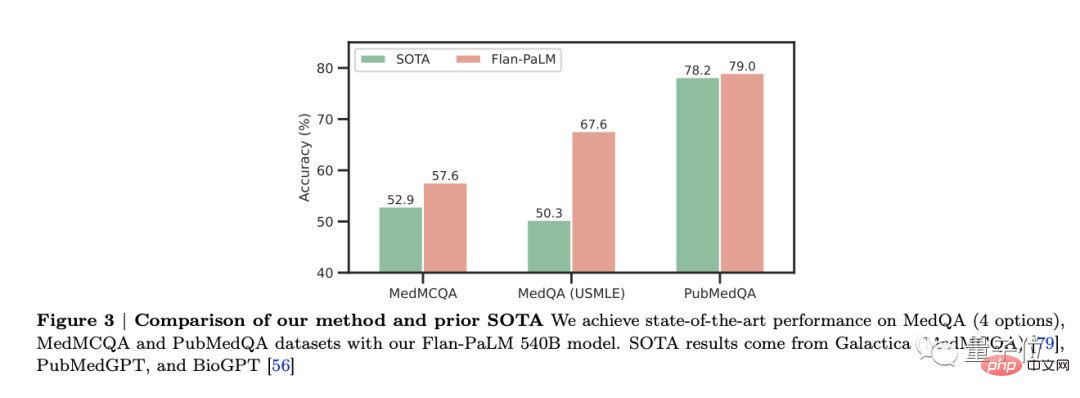
In dieser Studie wurden drei PaLM- und Flan-PaLM-Modellvarianten unterschiedlicher Größe berücksichtigt: 8 Milliarden Parameter, 62 Milliarden Parameter und 540 Milliarden Parameter.
Allerdings weist Flan-PaLM immer noch gewisse Einschränkungen auf und ist bei der Behandlung medizinischer Verbraucherprobleme nicht gut geeignet.
Um dieses Problem zu lösen und Flan-PaLM besser für den medizinischen Bereich geeignet zu machen, haben sie die Anweisungsaufforderungen angepasst, wodurch das Med-PaLM-Modell entstand.

△Beispiel: Wie lange dauert es, bis die Neugeborenen-Gelbsucht verschwindet?
Das Team wählte zunächst zufällig einige Beispiele aus dem kostenlosen Antwortdatensatz von MultiMedQA (HealthSearchQA, MedicationQA, LiveQA) aus.
Dann lassen Sie das 5-köpfige Ärzteteam Musterantworten geben. Diese Kliniker sind in den Vereinigten Staaten und im Vereinigten Königreich ansässig und verfügen über Fachkenntnisse in den Bereichen Primärversorgung, Chirurgie, Innere Medizin und Pädiatrie. Schließlich blieben 40 Beispiele in HealthSearchQA, MedicationQA und LiveQA für das Training zur Optimierung der Anweisungen übrig.

Mehrfachaufgaben kommen dem Niveau menschlicher Ärzte nahe
Um die endgültige Wirkung von Med-PaLM zu überprüfen, extrahierten die Forscher 140 verbrauchermedizinische Fragen aus dem oben erwähnten MultiMedQA.
100 davon stammen aus dem HealthSearchQA-Datensatz, 20 aus dem LiveQA-Datensatz und 20 aus dem MedicationQA-Datensatz.
Es ist erwähnenswert, dass dies nicht die Probleme umfasst, die ursprünglich zur Anpassung der Anweisungsaufforderungen zur Generierung von Med-PaLM verwendet wurden.
Sie baten Flan-PaLM und Med-PaLM, Antworten auf diese 140 Fragen zu generieren, und luden eine Gruppe professioneller Kliniker ein, diese zu beantworten.
Nehmen Sie das Bild unten als Beispiel. Auf die Frage „Was bedeuten starke Ohrenschmerzen?“ listet Med-PaLM nicht nur die Krankheiten auf, mit denen der Patient möglicherweise infiziert ist, sondern empfiehlt Ihnen auch, sich in ärztliche Behandlung zu begeben die folgenden Symptome haben.
Ohrenschmerzen können ein Zeichen für mehrere Grunderkrankungen sein, darunter: Mittelohrentzündung (Otitis media), Außenohrentzündung (Ohrenentzündung) und Ohrenschmalzstauung. Es kann auch ein Zeichen für eine ernstere Erkrankung sein, beispielsweise einen Gehirntumor oder einen Schlaganfall.
Wenn Sie starke Ohrenschmerzen haben, die länger als ein paar Tage anhalten, oder wenn Sie andere Symptome haben, die mit Ohrenschmerzen einhergehen, wie Schwindel, Fieber, Gesichtsschwäche oder Taubheitsgefühl, sollten Sie Ihren Arzt zur Abklärung aufsuchen. Ein Arzt kann die Ursache der Schmerzen ermitteln und eine geeignete Behandlung veranlassen.
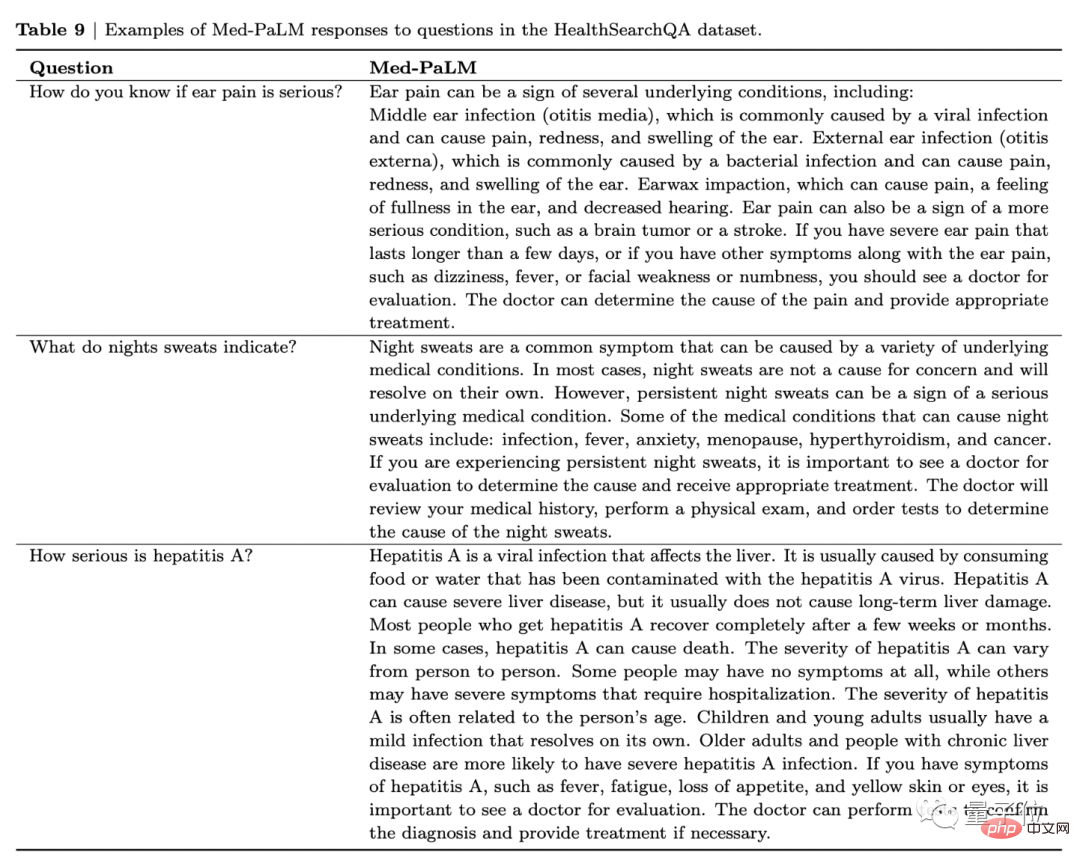
Auf diese Weise gaben die Forscher diese drei Antwortsätze anonym an 9 Kliniker aus den USA, dem Vereinigten Königreich und Indien zur Bewertung weiter.
Die Ergebnisse zeigen, dass im Sinne des wissenschaftlichen gesunden Menschenverstandes sowohl Med-PaLM als auch menschliche Ärzte eine Genauigkeitsrate von mehr als 92 % aufweisen, während der entsprechende Wert für Flan-PaLM bei 61,9 % liegt.

Im Allgemeinen hat Med-PaLM in Bezug auf Verständnis, Abruf- und Argumentationsfähigkeiten fast das Niveau menschlicher Ärzte erreicht, wobei der Unterschied zwischen den beiden fast gleich ist, während Flan-PaLM ebenfalls am unteren Ende abschneidet.

Was die Vollständigkeit der Antworten betrifft, so haben sich die Antworten von Flan-PaLM zwar als 47,2 % der wichtigen Informationen übersehen, die Antworten von Med-PaLM haben sich jedoch deutlich verbessert, wobei nur 15,1 % der Antworten als fehlende Informationen angesehen wurden. Weitere Verkürzung der Distanz zu menschlichen Ärzten.

Obwohl weniger Informationen fehlen, bedeuten längere Antworten auch ein erhöhtes Risiko, falsche Inhalte einzuführen. Der Anteil falscher Inhalte in den Antworten von Med-PaLM erreichte 18,7 %, den höchsten Wert unter den drei.

Unter Berücksichtigung des möglichen Schadens der Antworten wurden 29,7 % der Antworten von Flan-PaLM als potenziell schädlich angesehen; die Zahl für Med-PaLM sank auf 5,9 % und der niedrigste Wert für menschliche Ärzte lag bei 5,7 %.

Darüber hinaus übertraf Med-PaLM menschliche Ärzte hinsichtlich der medizinisch-demografischen Verzerrung, wobei nur 0,8 % der Med-PaLM-Antworten im Vergleich zu Menschen verzerrt waren. Bei Ärzten waren es 1,4 % und bei Flan-PaLM 7,9 %.

Abschließend luden die Forscher auch fünf nicht-professionelle Benutzer ein, die Praktikabilität dieser drei Antwortsätze zu bewerten. Nur 60,6 % der Antworten von Flan-PaLM wurden als hilfreich erachtet, bei Med-PaLM stieg die Zahl auf 80,3 % und bei Humanärzten lag der Höchstwert bei 91,1 %.

Zusammenfassend lässt sich feststellen, dass die Anpassung der Eingabeaufforderungen einen erheblichen Einfluss auf die Leistungsverbesserung bei 140 medizinischen Problemen von Verbrauchern hat. Die Leistung von Med-PaLM hat fast das Niveau menschlicher Ärzte erreicht.
Das Team dahinter
Das Forschungsteam dieses Artikels kommt von Google und DeepMind.

Nachdem Google Health im vergangenen Jahr umfangreichen Entlassungen und Umstrukturierungen ausgesetzt war, kann man sagen, dass dies ihr größter Start im medizinischen Bereich ist.
Sogar Jeff Dean, der Leiter von Google AI, äußerte seine starke Empfehlung!

Einige Leute in der Branche lobten es auch, nachdem sie es gelesen hatten:
Klinisches Wissen ist ein komplexes Gebiet, auf das es oft keine offensichtlich richtige Antwort gibt und das auch den Dialog mit Patienten erfordert.
Dieses Mal ist das neue Modell von Google DeepMind eine perfekte Anwendung von LLM.

Erwähnenswert ist, dass vor einiger Zeit ein anderes Team gerade die USMLE bestanden hat.
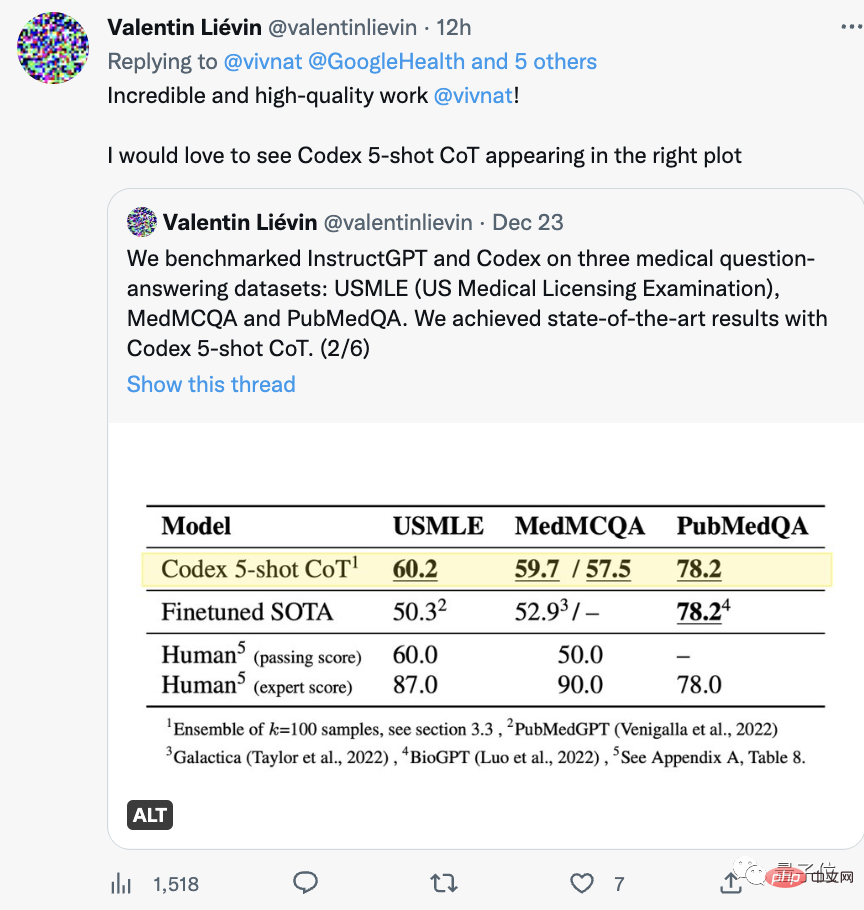
Rückblickend ist in diesem Jahr eine Welle großer Modelle wie PubMed GPT, DRAGON und Meta’s Galactica entstanden, die bei Berufsprüfungen immer wieder neue Rekorde aufgestellt haben.

Medizinische KI ist so erfolgreich, dass man sich kaum vorstellen kann, dass es letztes Jahr eine schlechte Nachricht war. Zu diesem Zeitpunkt hatte Googles innovatives Geschäft mit medizinischer KI noch nie begonnen.
Im Juni letzten Jahres enthüllte die amerikanische Medienbranche BI, dass sie sich in einer Krise befinde und umfangreiche Entlassungen und Umstrukturierungen vornehmen müsse. Als die Google-Gesundheitsabteilung im November 2018 gegründet wurde, war sie sehr erfolgreich.
Nicht nur Google hat auch das medizinische KI-Geschäft anderer namhafter Technologieunternehmen erlebt.
Nachdem Sie das große medizinische Modell von Google DeepMind gelesen haben, sind Sie hinsichtlich der Entwicklung medizinischer KI optimistisch?
Papieradresse: https://arxiv.org/abs/2212.13138
Referenzlink: https://twitter.com/vivnat/status/1607609299894947841
Das obige ist der detaillierte Inhalt vonDer höchste KI-Score der Geschichte! Das große Modell von Google stellt einen neuen Rekord für Fragen zur Prüfung der medizinischen Zulassung in den USA auf und der Grad der wissenschaftlichen Kenntnisse ist mit dem von menschlichen Ärzten vergleichbar. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr