
Heim >Technologie-Peripheriegeräte >KI >Erweiterung der TensorFlow-Anwendungstechnologie – Bildklassifizierung
Erweiterung der TensorFlow-Anwendungstechnologie – Bildklassifizierung

- 王林nach vorne
- 2023-04-18 16:07:031820Durchsuche
1. Erweiterung des Bereitstellungsbetriebs der wissenschaftlichen Forschungsplattform
Für Modellschulungen im maschinellen Lernen empfehle ich Ihnen, weitere offizielle TensorFlow-Kurse oder -Ressourcen zu lernen, wie z. B. die beiden Kurse auf dem MOOC der chinesischen Universität 《TensorFlow-Einführung in die Praxis Betriebskurs》und《TensorFlow-Einführungskurs – Bereitstellung》. Für das verteilte Training von Modellen, die an wissenschaftlicher Forschung oder Arbeit beteiligt sind, kann eine Ressourcenplattform oft sehr zeitaufwendig sein und nicht in der Lage sein, individuelle Bedürfnisse zeitnah zu erfüllen. Hier werde ich die im vorherigen Artikel erwähnte Verwendung der Jiutian Bisheng-Plattform „Vorläufiges Verständnis des TensorFlow Framework-Lernens“ spezifisch erweitern, um Schülern und Benutzern die schnellere Durchführung von Modellschulungen zu erleichtern. Diese Plattform kann Aufgaben wie Datenmanagement und Modelltraining übernehmen und ist eine praktische und schnelle Übungsplattform für wissenschaftliche Forschungsaufgaben. Die spezifischen Schritte beim Modelltraining sind:
(1) Registrieren Sie sich und melden Sie sich bei der Jiutian Bisheng-Plattform an. Da nachfolgende Trainingsaufgaben den Verbrauch von Rechenleistungs-Beans erfordern, ist die Anzahl der Rechenleistungs-Beans für neue Benutzer begrenzt, dies ist jedoch möglich durch Aufgaben wie das Teilen mit Freunden erhalten werden. Der Erwerb von Rechenleistungsbohnen wurde abgeschlossen. Gleichzeitig können Sie sich bei umfangreichen Modelltrainingsaufgaben per E-Mail an die Mitarbeiter der Plattform wenden, um mehr Speicherplatz für das Modelltraining zu erhalten, um die Konsole zu aktualisieren und so den in Zukunft erforderlichen Trainingsspeicherbedarf zu decken. Die Details zu Speicher- und Rechenleistungs-Beans lauten wie folgt:


https://www.php.cn/link/b977b532403e14d6681a00f78f95506e
Der Hauptzweck dieses Kapitels besteht darin, Benutzern ein tieferes Verständnis der Bildklassifizierung durch Erweiterung der Bildklassifizierungstechnologie zu vermitteln. 2.1 Wozu dient die Faltungsoperation? Wenn es um die Verarbeitung oder Klassifizierung von Bildern geht, gibt es einen Vorgang, der nicht vermieden werden kann, und dieser Vorgang ist die Faltung. Spezifische Faltungsoperationen können grundsätzlich durch Lernvideos verstanden werden, aber mehr Leser bleiben möglicherweise nur auf der Ebene, wie Faltungsoperationen durchgeführt werden und warum Faltungen durchgeführt werden und wozu Faltungsoperationen dienen. Ein wenig Wissen ist noch unklar. Hier finden Sie einige Erweiterungen für alle, die Ihnen helfen sollen, die Faltung besser zu verstehen. Der grundlegende Faltungsprozess ist in der folgenden Abbildung dargestellt. Am Beispiel eines Bildes wird eine Matrix verwendet, um das Bild darzustellen. Die Faltungsoperation besteht darin, die Eigenwerte dieser kleinen Bereiche durch Multiplikation des Faltungskerns mit der entsprechenden Matrix zu erhalten. Die extrahierten Merkmale unterscheiden sich aufgrund unterschiedlicher Faltungskerne. Aus diesem Grund führt jemand Faltungsoperationen auf verschiedenen Kanälen des Bildes durch, um die Merkmale verschiedener Kanäle des Bildes zu erhalten und nachfolgende Klassifizierungsaufgaben besser durchführen zu können.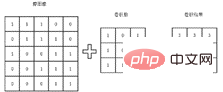
Beim täglichen Modelltraining muss der spezifische Faltungskern nicht manuell entworfen werden, sondern wird automatisch mithilfe des Netzwerks trainiert, indem die tatsächliche Bezeichnung des gegebenen Bildes verwendet wird. Dieser Prozess ist jedoch nicht förderlich für das Verständnis des Faltungskerns. Und der Faltungsprozess ist nicht intuitiv. Um jedem zu helfen, die Bedeutung der Faltungsoperation besser zu verstehen, finden Sie hier ein Beispiel für eine Faltungsoperation. Wie in der folgenden Matrix dargestellt, stellen die numerischen Werte die Pixel der Grafik dar. Der Einfachheit halber werden hier nur 0 und 1 verwendet. Es ist nicht schwer zu erkennen, dass die Merkmale dieser Matrixgrafik die oberen sind Die Hälfte der Grafik ist hell und die untere Hälfte der Grafik ist schwarz, sodass das Bild eine sehr klare Trennlinie aufweist, das heißt, es weist offensichtliche horizontale Eigenschaften auf.

Um die horizontalen Merkmale der obigen Matrix gut zu extrahieren, sollte der entworfene Faltungskern daher auch über die Attribute der horizontalen Merkmalsextraktion verfügen. Der Faltungskern, der vertikale Merkmalsextraktionsattribute verwendet, ist hinsichtlich der Offensichtlichkeit der Merkmalsextraktion relativ unzureichend. Wie unten gezeigt, wird für die Faltung der Faltungskern verwendet, der horizontale Merkmale extrahiert:
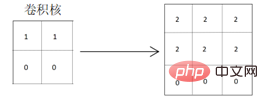
Aus der erhaltenen Faltungsergebnismatrix ist ersichtlich, dass die horizontalen Merkmale der Originalgrafiken und die Trennlinien der Grafiken gut extrahiert wurden wird deutlicher, da die Pixelwerte der farbigen Teile der Grafik vertieft werden, wodurch die horizontalen Merkmale der Grafik gut hervorgehoben werden. Bei Verwendung eines Faltungskerns, der vertikale Merkmale für die Faltung extrahiert:
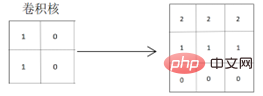
Aus der erhaltenen Faltungsergebnismatrix ist ersichtlich, dass auch die horizontalen Merkmale der Originalgrafik extrahiert werden können, es werden jedoch zwei Trennlinien erzeugt Grafikänderungen sind: Von besonders hell zu hell und dann zu Schwarz ändert sich auch die auf der realen Grafik reflektierte Situation von hell zu dunkel zu schwarz, was sich von den horizontalen Eigenschaften der echten Originalgrafiken unterscheidet.
Aus den obigen Beispielen lässt sich leicht erkennen, dass unterschiedliche Faltungskerne die Qualität der endgültigen extrahierten Grafikmerkmale beeinflussen. Gleichzeitig sind auch die von verschiedenen Grafiken reflektierten Merkmale unterschiedlich Unterschiedliche grafische Feature-Attribute? Es ist auch besonders wichtig, Faltungskerne besser zu lernen und zu entwerfen. In tatsächlichen Kartenklassifizierungsprojekten ist es notwendig, geeignete Merkmale basierend auf Bildunterschieden auszuwählen und zu extrahieren, und häufig sind Kompromisse zu berücksichtigen.
2.2 Wie kann Faltung für eine bessere Bildklassifizierung berücksichtigt werden?
Wie Sie aus der Rolle von Faltungsoperationen im vorherigen Abschnitt ersehen können, ist es besonders wichtig, ein Netzwerkmodell zu entwerfen, um den Faltungskern, der sich an das Bild anpasst, besser zu lernen. In praktischen Anwendungen werden jedoch automatisches Lernen und Training durchgeführt, indem die realen Beschriftungen der gegebenen Bildkategorien in Vektordaten umgewandelt werden, die die Maschine verstehen kann. Natürlich ist eine Verbesserung durch manuelle Einstellungen nicht völlig unmöglich. Obwohl die Bezeichnungen des Datensatzes festgelegt sind, können wir basierend auf den Bildtypen des Datensatzes unterschiedliche Netzwerkmodelle auswählen. Unter Berücksichtigung der Vor- und Nachteile verschiedener Netzwerkmodelle werden häufig gute Trainingsergebnisse erzielt.
Gleichzeitig können Sie beim Extrahieren von Bildmerkmalen auch die Verwendung der Multitasking-Lernmethode in Betracht ziehen. In den vorhandenen Bilddaten können Sie die Bilddaten erneut verwenden, um einige zusätzliche Bildmerkmale (z. B. Kanalmerkmale und räumliche Merkmale) zu extrahieren das Bild usw.) und ergänzen oder füllen Sie dann die zuvor extrahierten Merkmale, um die endgültigen extrahierten Bildmerkmale zu verbessern. Natürlich führt dieser Vorgang manchmal dazu, dass die extrahierten Merkmale redundant sind und der erzielte Klassifizierungseffekt häufig kontraproduktiv ist. Daher muss er auf der Grundlage der tatsächlichen Trainingsklassifizierungsergebnisse berücksichtigt werden.
2.3 Einige Vorschläge zur Auswahl des Netzwerkmodells
Der Bereich der Bildklassifizierung hat sich in den letzten Jahren vom ursprünglichen klassischen AlexNet-Netzwerkmodell zum beliebten ResNet-Netzwerkmodell relativ vollständig entwickelt. Die Klassifizierungsgenauigkeit einiger häufig verwendeter Bilddatensätze lag tendenziell bei 100 %. Derzeit verwenden die meisten Menschen in diesem Bereich die neuesten Netzwerkmodelle, und bei den meisten Bildklassifizierungsaufgaben kann die Verwendung der neuesten Netzwerkmodelle tatsächlich offensichtliche Klassifizierungseffekte mit sich bringen. Daher ignorieren viele Menschen in diesem Bereich häufig frühere Netzwerkmodelle und gehen direkt vor um die neuesten und beliebtesten Netzwerkmodelle kennenzulernen.
Hier empfehle ich den Lesern immer noch, sich mit einigen klassischen Netzwerkmodellen im Bereich der Diagrammklassifizierung vertraut zu machen, da Technologieaktualisierungen und -iterationen sehr schnell erfolgen und selbst die neuesten Netzwerkmodelle in Zukunft möglicherweise eliminiert werden, aber die Funktionsprinzipien Die grundlegenden Netzwerkmodelle sind in etwa gleich. Durch die Beherrschung der klassischen Netzwerkmodelle können Sie nicht nur die Grundprinzipien beherrschen, sondern auch die Unterschiede zwischen verschiedenen Netzwerkmodellen und die Vor- und Nachteile der Bearbeitung verschiedener Aufgaben verstehen. Wenn Ihr Bilddatensatz beispielsweise relativ klein ist, kann das Training mit dem neuesten Netzwerkmodell sehr komplex und zeitaufwändig sein, aber der Verbesserungseffekt ist minimal, sodass es sich nicht lohnt, Ihre eigenen Trainingszeitkosten für einen vernachlässigbaren Effekt zu opfern . Um das Bildklassifizierungsnetzwerkmodell zu beherrschen, müssen Sie daher wissen, was es ist und warum es so ist, damit Sie in Zukunft bei der Auswahl eines Bildklassifizierungsmodells wirklich gezielt vorgehen können.
Vorstellung des Autors:
Porridge, 51CTO-Community-Redakteur, arbeitete einst in der Big-Data-Technologieabteilung eines E-Commerce-Forschungs- und Entwicklungszentrums für künstliche Intelligenz und arbeitete an Empfehlungsalgorithmen. Derzeit beschäftigt er sich mit der Forschung in Richtung natürlicher Sprachverarbeitung. Zu seinen Hauptfachgebieten gehören Empfehlungsalgorithmen, NLP und CV. Zu den verwendeten Codierungssprachen gehören Java, Python und Scala. Veröffentlichung eines ICCC-Konferenzpapiers.
Das obige ist der detaillierte Inhalt vonErweiterung der TensorFlow-Anwendungstechnologie – Bildklassifizierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr