
Heim >Technologie-Peripheriegeräte >KI >Kostet weniger als 100 $! UC Berkeley eröffnet das ChatGPT-ähnliche Modell „Koala' erneut: Große Datenmengen sind nutzlos, hohe Qualität ist Trumpf
Kostet weniger als 100 $! UC Berkeley eröffnet das ChatGPT-ähnliche Modell „Koala' erneut: Große Datenmengen sind nutzlos, hohe Qualität ist Trumpf

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-17 19:58:03802Durchsuche
# 🎜 🎜#
#🎜. 🎜#
# 🎜 🎜#Seit Meta Open-Source-LLaMA ist, sind in der Wissenschaft verschiedene ChatGPT-Modelle entstanden und wurde mit der Veröffentlichung begonnen. Zuerst schlug Stanford den 7-Milliarden-Parameter Alpaca vor, und dann tat sich UC Berkeley mit CMU, Stanford, UCSD und MBZUAI zusammen, um den 13-Milliarden-Parameter Vicuna zu veröffentlichen, der in mehr als 90 % der Fälle vergleichbare Ergebnisse wie ChatGPT und Bard erzielte Fälle. Fähigkeit. Kürzlich hat Berkeley ein neues Modell „Koala“ veröffentlicht. Das Besondere an Koala ist, dass es für das Training hochwertige Daten aus dem -Netzwerk nutzt. # 🎜 🎜#
#🎜. 🎜# # 🎜 🎜##🎜. 🎜#
# 🎜 🎜#
#🎜. 🎜#
Blog-Link: https://bair.berkeley.edu/blog/2023/04/03/koala/Datenvorverarbeitungscode: https://github.com/young-geng /koala_data_pipeline-Evaluierungstestset: https://github.com/arnav-gudibande/koala-test-set Modell-Download: https://drive.google.com/drive/folders/10f7wrlAFoPIy-TECHsx9DKIvbQYunCfl
#🎜 🎜 #
In dem veröffentlichten Blogbeitrag beschreiben die Forscher die Datensatzverwaltung und den Trainingsprozess des Modells und präsentieren außerdem die Ergebnisse einer Benutzerstudie, in der das Modell mit ChatGPT und dem Alpaca-Modell A verglichen wird wurde gemacht. Die Ergebnisse zeigen, dass Koala eine Vielzahl von Benutzeranfragen effektiv beantworten kann und Antworten generiert, die häufig beliebter sind als Alpaca und in mindestens der Hälfte der Fälle genauso effektiv sind wie ChatGPT. Die Forscher hoffen, dass die Ergebnisse dieses Experiments die Diskussion über die relative Leistung großer Closed-Source-Modelle im Vergleich zu kleinen öffentlichen Modellen vorantreiben werden, insbesondere da die Ergebnisse zeigen, dass kleine Modelle lokal ausgeführt werden können, wenn Trainingsdaten sorgfältig gesammelt werden , Die Leistung großer Modelle kann erreicht werden.
# 🎜🎜# Dies kann bedeuten, dass die Community mehr Anstrengungen in die Kuratierung hochwertiger Datensätze investieren sollte, anstatt einfach nur die Größe bestehender Systeme zu erhöhen. Es ist mehr Dies trägt zum Aufbau eines sichereren, praktischeren und leistungsfähigeren Modells bei. Es sollte betont werden, dass es sich bei Koala nur um einen Forschungsprototyp handelt und die Forscher zwar hoffen, dass die Veröffentlichung des Modells eine wertvolle Community-Ressource darstellen kann, es jedoch immer noch erhebliche Mängel bei der Inhaltssicherheit und -zuverlässigkeit aufweist und nicht außerhalb von Forschungsbereichen verwendet werden sollte. verwenden.
Dies kann bedeuten, dass die Community mehr Anstrengungen in die Kuratierung hochwertiger Datensätze investieren sollte, anstatt einfach nur die Größe bestehender Systeme zu erhöhen. Es ist mehr Dies trägt zum Aufbau eines sichereren, praktischeren und leistungsfähigeren Modells bei. Es sollte betont werden, dass es sich bei Koala nur um einen Forschungsprototyp handelt und die Forscher zwar hoffen, dass die Veröffentlichung des Modells eine wertvolle Community-Ressource darstellen kann, es jedoch immer noch erhebliche Mängel bei der Inhaltssicherheit und -zuverlässigkeit aufweist und nicht außerhalb von Forschungsbereichen verwendet werden sollte. verwenden. Koala-Systemübersicht
Nach der Veröffentlichung groß angelegter Sprachmodelle sind virtuelle Assistenten und Chatbots immer leistungsfähiger geworden. Sie können nicht nur chatten, sondern auch Code schreiben Man kann sagen, dass Poesie und Geschichtenerstellung allmächtig sind. Die leistungsstärksten Sprachmodelle erfordern jedoch in der Regel enorme Rechenressourcen zum Trainieren der Modelle und erfordern auch umfangreiche dedizierte Datensätze. Normale Menschen können die Modelle grundsätzlich nicht selbst trainieren. Mit anderen Worten: Das Sprachmodell wird in Zukunft von einigen wenigen mächtigen Organisationen kontrolliert. Benutzer und Forscher werden für die Interaktion mit dem Modell bezahlen und keinen direkten Zugriff auf das Innere des Modells haben, um es zu ändern oder zu verbessern. Andererseits haben einige Organisationen in den letzten Monaten relativ leistungsstarke kostenlose oder teilweise Open-Source-Modelle veröffentlicht, wie z. B. LLaMA von Meta. Die Fähigkeiten dieser Modelle können nicht mit denen geschlossener Modelle (wie ChatGPT) verglichen werden, ihre Fähigkeiten jedoch Mit der Hilfe der Community hat es sich schnell verbessert.
Obwohl es unwahrscheinlich ist, dass offene Modelle den Maßstab von Closed-Source-Modellen erreichen, können sie durch die Verwendung sorgfältig ausgewählter Trainingsdaten ohne Feinabstimmung der Leistung annähernd erreicht werden ChatGPT.
Tatsächlich haben die experimentellen Ergebnisse des von der Stanford University veröffentlichten Alpaca-Modells und die Feinabstimmung von LLaMA-Daten basierend auf dem GPT-Modell von OpenAI gezeigt, dass die richtigen Daten dies können Die deutliche Verbesserung kleinerer Open-Source-Modelle, was auch die ursprüngliche Absicht der Berkeley-Forscher war, das Koala-Modell zu entwickeln und zu veröffentlichen, liefert einen weiteren experimentellen Beweis für die Ergebnisse dieser Diskussion.
Koala hat die von
online erhaltenen kostenlosen Interaktionsdatenverfeinert und dabei besonderes Augenmerk auf hohe Leistung gelegt, einschließlich und ChatGPT Closed-Source-Modellinteraktionsdaten . Die Forscher haben das LLaMA-Basismodell auf der Grundlage von aus dem Web und öffentlichen Datensätzen extrahierten Konversationsdaten verfeinert, einschließlich hochwertiger Schulungen zu Benutzeranfragen aus anderen großen Sprachmodellen Das trainierte Koala-13B-Modell zeigt sowohl Antworten als auch Frage- und Antwortdatensätze und menschliche Feedback-Datensätze und zeigt somit eine Leistung, die nahezu mit der Leistung bestehender Modelle übereinstimmt.
Die Ergebnisse deuten darauf hin, dass das Lernen aus hochwertigen Datensätzen einige der Mängel kleiner Modelle abmildern kann und in Zukunft möglicherweise sogar mit großen Closed-Source-Modellen konkurrieren kann Das bedeutet, dass die Community mehr Energie in die Verwaltung hochwertiger Datensätze investieren sollte, was der Entwicklung sichererer, praktischerer und leistungsfähigerer Modelle förderlicher ist, als einfach die Größe bestehender Modelle zu erhöhen.
Durch die Ermutigung von Forschern, an Systemdemonstrationen des Koala-Modells teilzunehmen, hoffen die Forscher, einige unerwartete Merkmale oder Mängel zu entdecken, die bei der zukünftigen Bewertung des Modells helfen werden.
Datensätze und Training
Ein großes Hindernis beim Aufbau von Konversationsmodellen ist die Verwaltung von Trainingsdaten, einschließlich ChatGPT, Bard, Bing Chat und Claude Alle Chat-Modelle, einschließlich
Um Koala zu bauen, organisierten die Forscher den Trainingssatz, indem sie Konversationsdaten aus dem Internet und öffentlichen Datensätzen sammelten, von denen ein Teil große, von Benutzern online veröffentlichte Sprachmodelle (z. B als ChatGPT).
Anstatt so viele Webdaten wie möglich zu crawlen, um das Datenvolumen zu maximieren, konzentrierten sich die Forscher darauf, einen kleinen, qualitativ hochwertigen Datensatz zu sammeln und dabei öffentliche Datensätze zu verwenden, um Fragen zu beantworten. menschliches Feedback (als positiv und negativ bewertet) und Dialog mit bestehenden Sprachmodellen.
ChatGPT Destillierte Daten
Gespräche mit öffentlichen Benutzern von ChatGPT teilen (ShareGPT): Ungefähr 60.000 Gespräche wurden von Benutzern auf ShareGPT unter Nutzung der Öffentlichkeit gesammelt API-Gespräche geteilt auf.

Website-Link: https://sharegpt.com/
#🎜🎜 #Um die Datenqualität sicherzustellen, löschten die Forscher doppelte Benutzeranfragen und alle nicht-englischen Konversationen, sodass am Ende etwa 30.000 Stichproben übrig blieben.
Human ChatGPT Comparative Corpus (HC3): Verwendung menschlicher und ChatGPT-Antwortergebnisse aus dem englischen HC3-Datensatz, der etwa 60.000 menschliche Antworten und etwa 24.000 Fragen der 27.000 ChatGPT enthält Antworten wurden insgesamt etwa 87.000 Frage- und Antwortmuster eingeholt.
Offene Daten Die Konzentration auf eine manuell ausgewählte Teilmenge von Komponenten, darunter Mathematikunterricht in der Grundschule, Gedichte zu Liedern und Plot-Skript-Buch-Dialog-Datensätze, ergab insgesamt etwa 30.000 Proben.Stanford Alpaca: Enthält den Datensatz, der zum Trainieren des Stanford Alpaca-Modells verwendet wird.
Der Datensatz enthält etwa 52.000 Beispiele und wurde von text-davinci-003 von OpenAI nach dem Selbstanweisungsprozess generiert.
Es ist erwähnenswert, dass es sich bei den HC3-, OIG- und Alpaca-Datensätzen um Fragen und Antworten in einer einzigen Runde handelt, während es sich beim ShareGPT-Datensatz um eine Konversation mit mehreren Runden handelt.
Anthropic HH: Enthält menschliche Bewertungen der Schädlichkeit und Nützlichkeit der Modellausgabe.
Der Datensatz enthält etwa 160.000 von Menschen bewertete Beispiele, wobei jedes Beispiel aus einem Antwortpaar des Chatbots besteht, von denen eine von Menschen bevorzugt wird. Dieser Datensatz liefert Funktionalität und zusätzliche Sicherheit für das Modell.
OpenAI WebGPT: Der Datensatz umfasst insgesamt etwa 20.000 Vergleiche, wobei jedes Beispiel eine Frage und ein Paar Modellantworten enthält und Metadaten werden Antworten von Menschen auf der Grundlage ihrer eigenen Präferenzen bewertet.
OpenAI-Zusammenfassung: enthält etwa 93.000 Beispiele mit Feedback zu modellgenerierten Zusammenfassungen von menschlichen Bewertern. Das bessere Zusammenfassungsergebnis wurde aus den beiden ausgewählt Optionen.
Bei der Verwendung von Open-Source-Datensätzen können einige Datensätze zwei Antworten liefern, entsprechend einer Bewertung von gut oder schlecht (AnthropicHH, WebGPT, OpenAI-Zusammenfassung).
Frühere Forschungsergebnisse zeigten die Wirksamkeit von bedingten Sprachmodellen auf menschliche Präferenzetiketten (nützlich/nicht hilfreich), um die Leistung zu verbessern. Die Forscher platzierten das Modell basierend auf den Präferenzetiketten. Wenn es kein menschliches Feedback gibt, verwenden Sie eine positive Kennzeichnung für den Datensatz. Während der Evaluierungsphase wird die Eingabeaufforderung so geschrieben, dass sie positive Tags enthält.Koala basiert auf dem Open-Source-Framework EasyLM (Vortraining, Feinabstimmung, Bereitstellung und Bewertung verschiedener großer Sprachmodelle) und wird mit JAX implementiert /Flax; das Trainingsgerät ist ein Nvidia DGX. Mit einem Server und 8 A100-GPUs dauert es 6 Stunden, um 2 Trainingsepochen abzuschließen.
Auf einer öffentlichen Cloud-Computing-Plattform betragen die
erwarteten Schulungskosten nicht mehr als 100 $ .
Erste BewertungIm Experiment bewerteten die Forscher zwei Modelle: Koala-Distill, das nur destillierte Daten verwendet; Koala-All Use Alle Daten, einschließlich destillierter und Open-Source-Daten.
Der Zweck des Experiments besteht darin, die Leistung der Modelle zu vergleichen und die Auswirkungen von Destillation und Open-Source-Datensätzen auf die endgültige Modellleistung zu bewerten Koala-Modell und vergleichen Sie das Koala-All mit Koala-Distill, Alpaca und ChatGPT.
Das Testset des Experiments besteht aus Stanfords Alpaka-Testset und dem Koala-Testset, einschließlich 180 Testabfrage
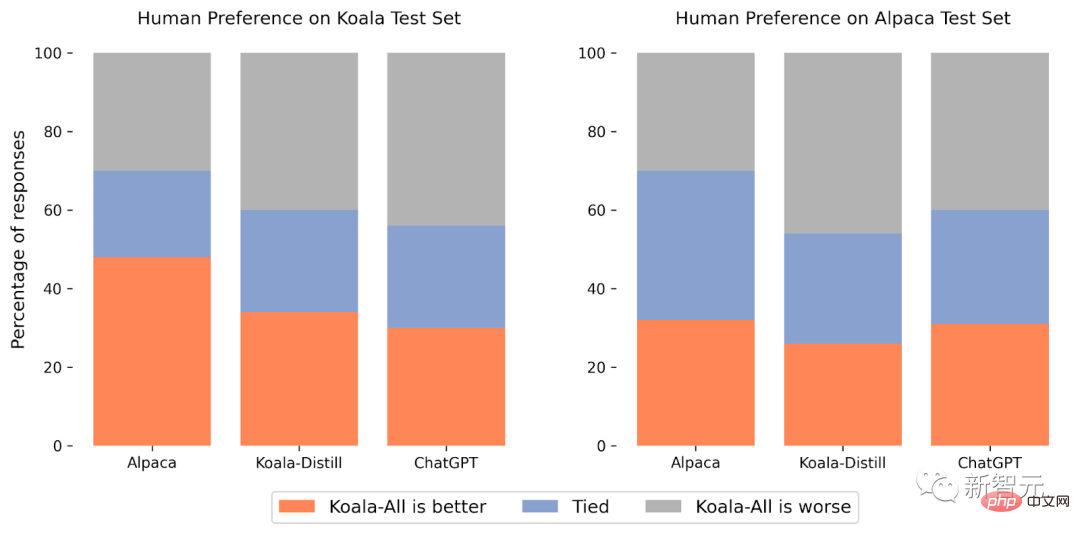
Der Alpaca-Testsatz besteht aus Benutzereingaben, die aus dem selbst erstellten Datensatz entnommen wurden, und stellt die verteilten Daten des Alpaka-Modells dar. Um ein realistischeres Bewertungsprotokoll bereitzustellen, enthält der Koala-Testsatz 180 online veröffentlichte reale Benutzerabfragen Verschiedene Themen, normalerweise Konversationen, sind repräsentativer für tatsächliche Anwendungsfälle, die auf Chat-Systemen basieren. Um mögliche Lecks im Testsatz zu reduzieren, werden Abfragen mit einem BLEU-Score von mehr als 20 % schließlich aus dem Trainingssatz herausgefiltert.
Da das Forschungsteam außerdem besser Englisch spricht, entfernten die Forscher nicht-englische und codierungsbezogene Eingabeaufforderungen, um zuverlässigere Annotationsergebnisse zu liefern, und führten schließlich einen Blindtest mit etwa 100 Annotatoren auf der Amazon-Crowdsourcing-Plattform durch Für den Test erhält jeder Bewerter eine Eingabeaufforderung und die Ausgabe der beiden Modelle in der Bewertungsschnittstelle und wird dann gebeten, anhand von Kriterien in Bezug auf Antwortqualität und -korrektheit zu beurteilen, welche Ausgabe besser ist (wobei gleich gute Ergebnisse berücksichtigt werden).
Im Alpaca-Testset schneidet Koala-All auf Augenhöhe mit Alpaca ab.
Im Koala-Testsatz (der echte Benutzeranfragen enthält) ist Koala-All in fast der Hälfte der Proben besser als Alpaca und übertrifft Alpaca in 70 % der Fälle oder ist genauso gut wie Alpaca, was definitiv der Fall ist a Koala-Trainingssatz Der Grund dafür ist, dass der Testsatz ähnlicher ist, sodass dieses Ergebnis nicht besonders überraschend ist.
Aber solange diese Hinweise eher den nachgelagerten Anwendungsfällen dieser Modelle ähneln, bedeutet dies, dass Koala in assistentenähnlichen Anwendungen eine bessere Leistung erbringt, was darauf hindeutet, dass die Verwendung im Web veröffentlichter Beispiele für die Interaktion mit Sprachmodellen am besten ist Möglichkeit, diese Modelle zu stärken und effektive Strategien für eine effektive Befehlsausführung zu entwickeln.
Was noch überraschender ist, ist, dass die Forscher herausfanden, dass zusätzlich zu destillierten Daten (Koala-All) das Training mit Open-Source-Daten etwas schlechter abschnitt als das Training mit nur destillierten ChatGPT-Daten (Koala-Distill).
Auch wenn der Unterschied möglicherweise nicht signifikant ist, zeigt dieses Ergebnis, dass die Qualität der ChatGPT-Gespräche so hoch ist, dass selbst die Einbeziehung von doppelt so vielen Open-Source-Daten keine signifikante Verbesserung bringen würde.
Die ursprüngliche Hypothese war, dass Koala-All eine bessere Leistung erbringen sollte. Daher wurde Koala-All in allen Bewertungen als Hauptbewertungsmodell verwendet. Letztendlich wurde festgestellt, dass aus großen Sprachen effektive Anweisungen und Hilfsmodelle gewonnen werden können das Modell, sofern diese Eingabeaufforderungen die Vielfalt der Benutzer während der Testphase darstellen können.
Der Schlüssel zum Aufbau starker Konversationsmuster liegt also möglicherweise eher in der Verwaltung hochwertiger Konversationsdaten, die im Hinblick auf Benutzeranfragen vielfältig sind, und nicht einfach in der Neuformatierung vorhandener Datensätze in Fragen und Antworten.
Einschränkungen und Sicherheit
Wie andere Sprachmodelle weist auch Koala Einschränkungen auf, die bei Missbrauch den Benutzern schaden können.
Forscher beobachteten, dass Koala halluzinierte und in einem sehr selbstbewussten Tonfall reagierte, möglicherweise aufgrund einer Feinabstimmung der Konversation, mit anderen Worten, das kleinere Modell erbte das Erbe des größeren Sprachmodells Die Tatsache, dass es nicht auf dem gleichen Niveau vererbt wurde, muss auf zukünftige Verbesserungen konzentriert werden.
Bei Missbrauch können Koalas Phantomantworten die Verbreitung von Fehlinformationen, Spam und anderen Inhalten erleichtern.
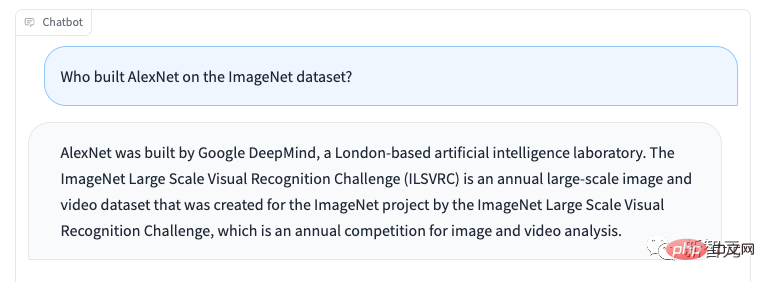
Koala ist in der Lage, ungenaue Informationen in einem selbstbewussten und überzeugenden Ton zu halluzinieren. Abgesehen von Halluzinationen bleibt Koala hinter anderen Chatbot-Sprachmodellen zurück. Dazu gehören:
- Voreingenommenheit und StereotypisierungEindrücke: Das Modell übernimmt voreingenommene Trainingsgesprächsdaten, einschließlich Stereotypen, Diskriminierung und anderen Schäden.
- Mangel an gesundem Menschenverstand: Obwohl große Sprachmodelle scheinbar kohärente und grammatikalisch korrekte Texte erzeugen können, mangelt es ihnen oft an dem gesunden Menschenverstand, den Menschen für selbstverständlich halten, was zu absurden oder unangemessenen Reaktionen führen kann. Eingeschränktes Verständnis
- : Große Sprachmodelle können Schwierigkeiten haben, den Kontext und die Nuancen eines Gesprächs zu verstehen sowie Sarkasmus oder Ironie zu erkennen, was zu Missverständnissen führen kann. Um die Sicherheitsbedenken von Koala auszuräumen, haben Forscher gegnerische Hinweise in die Datensätze von ShareGPT und AnthropicHH aufgenommen, um das Modell robuster und harmloser zu machen.
Um potenziellen Missbrauch weiter zu reduzieren, wurden in der Demo auch die Inhaltsmoderationsfilter von OpenAI eingesetzt, um unsichere Inhalte zu kennzeichnen und zu entfernen.
Zukünftige Arbeit
Die Forscher hoffen, dass das Koala-Modell eine nützliche Plattform für zukünftige akademische Forschung zu großen Sprachmodellen werden kann: Das Modell ist groß genug, um die vielen Fähigkeiten moderner Sprachmodelle zu demonstrieren, und gleichzeitig klein genug weniger Rechenaufwand zu verwenden. Zukünftige Forschungsrichtungen zur Feinabstimmung oder Nutzung könnten Folgendes umfassen:Sicherheit und Konsistenz
- : Weitere Forschung zur Sicherheit von Sprachmodellen und besserer Konsistenz mit menschlichen Absichten. Modellverzerrung
- Siehe: Besseres Verständnis der Verzerrung großer Sprachmodelle, des Vorhandenseins von falschen Korrelationen und Qualitätsproblemen in Konversationsdatensätzen und Möglichkeiten, diese Verzerrung zu mildern. Große Sprachmodelle verstehen
- Modell: Da Koalas Inferenz auf relativ günstigen GPUs durchgeführt werden kann, können die Interna von Konversationssprachmodellen besser untersucht und verstanden werden, wodurch Black-Box-Sprachmodelle effizienter werden Leicht zu verstehen.
Das obige ist der detaillierte Inhalt vonKostet weniger als 100 $! UC Berkeley eröffnet das ChatGPT-ähnliche Modell „Koala' erneut: Große Datenmengen sind nutzlos, hohe Qualität ist Trumpf. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr