
Heim >Technologie-Peripheriegeräte >KI >Ein Überblick über den Forschungsfortschritt von Deep Learning bei der Vorhersage und Klassifizierung von Zeitreihen im Jahr 2022
Ein Überblick über den Forschungsfortschritt von Deep Learning bei der Vorhersage und Klassifizierung von Zeitreihen im Jahr 2022

- PHPznach vorne
- 2023-04-13 12:25:021159Durchsuche
Der Rückgang von Transformatoren bei der Vorhersage von Zeitreihen und der Aufstieg von Methoden zur Einbettung von Zeitreihen sowie bei der Erkennung und Klassifizierung von Anomalien haben ebenfalls Fortschritte gemacht
Der gesamte Bereich hat im Jahr 2022 in mehreren verschiedenen Aspekten Fortschritte gemacht. Dieser Artikel wird versuchen, eine Einführung zu geben einige der Entwicklungen im vergangenen Jahr. Die vielversprechenderen und kritischeren Papiere, die im letzten Jahr oder so erschienen sind, und das Prognoserahmenwerk Flow Forecast [FF].

Zeitreihenvorhersage
1. Sind Transformer für die Zeitreihenvorhersage wirklich effektiv?
https://www.php.cn/link/bf4d73f316737b26f1e860da0ea63ec8
Transformerbezogene Forschung Vergleichen Sie Autoformer, Pyraformer, Fedformer usw., ihre Auswirkungen und Probleme ) und anderen Modellen wächst die Transformer-Reihe der Zeitreihenvorhersagearchitektur weiter). Die Fähigkeit dieser Modelle, Daten genau vorherzusagen und bestehende Methoden zu übertreffen, bleibt jedoch fraglich, insbesondere im Lichte neuer Forschungsergebnisse (auf die wir später noch eingehen werden).
Autoformer: Erweiterte und verbesserte Leistung des Informer-Modells. Autoformer verfügt über einen automatischen Korrelationsmechanismus, der es dem Modell ermöglicht, zeitliche Abhängigkeiten besser zu lernen als mit der Standardaufmerksamkeit. Ziel ist es, die Trend- und Saisonkomponenten zeitlicher Daten genau zu zerlegen. 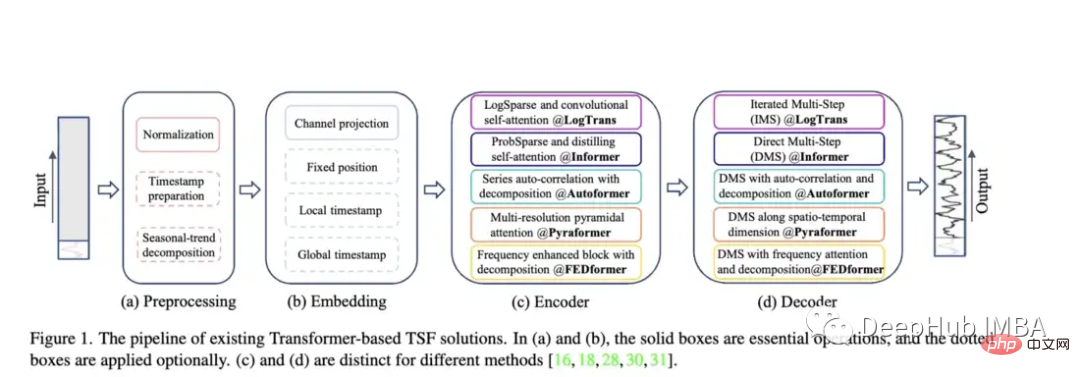
Pyraformer: Der Autor stellt das „Pyramid Attention Module (PAM)“ vor, in dem die skalenübergreifende Baumstruktur die Merkmale in verschiedenen Auflösungen zusammenfasst und die skaleninternen Nachbarverbindungen die zeitliche Abhängigkeit verschiedener Bereiche modellieren
Fedformer: Dieses Modell konzentriert sich auf die Erfassung globaler Trends in Zeitreihendaten. Die Autoren schlagen ein Modul zur Zerlegung saisonaler Trends vor, das die globalen Merkmale von Zeitreihen erfassen soll.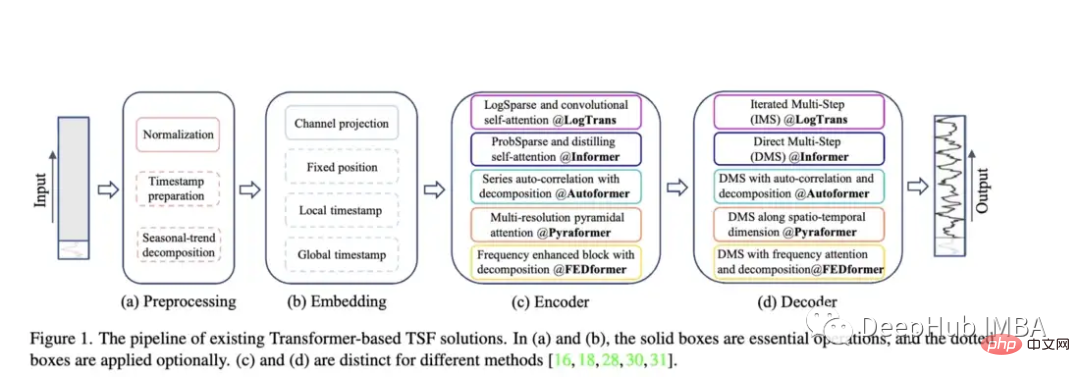 Earthformer: Wahrscheinlich die einzigartigste dieser Arbeiten, sie konzentriert sich speziell auf die Vorhersage von Erdsystemen wie Wetter, Klima und Landwirtschaft. Eine neue quaderförmige Aufmerksamkeitsarchitektur wird eingeführt. Dieses Papier sollte großes Potenzial haben, da viele klassische Transformer in der Forschung zur Vorhersage von Fluss- und Sturzfluten gescheitert sind.
Earthformer: Wahrscheinlich die einzigartigste dieser Arbeiten, sie konzentriert sich speziell auf die Vorhersage von Erdsystemen wie Wetter, Klima und Landwirtschaft. Eine neue quaderförmige Aufmerksamkeitsarchitektur wird eingeführt. Dieses Papier sollte großes Potenzial haben, da viele klassische Transformer in der Forschung zur Vorhersage von Fluss- und Sturzfluten gescheitert sind.
Nichtstationärer Transformator: Dies ist die neueste Arbeit, die Transformatoren zur Vorhersage verwendet. Ziel der Autoren ist es, den Transformer besser auf die Verarbeitung instationärer Zeitreihen abzustimmen. Sie nutzen zwei Mechanismen: destabilisierende Aufmerksamkeit und eine Reihe stabilisierender Mechanismen. Diese Mechanismen können in jedes vorhandene Transformer-Modell eingebunden werden, und der Autor hat das Einbinden in Informer, Autoformer und den herkömmlichen Transformer getestet, um die Leistung zu verbessern (im Anhang wird auch gezeigt, dass dadurch die Leistung von Fedformer verbessert werden kann).
Bewertungsmethodik des Papiers: Ähnlich wie bei Informer werden alle diese Modelle (außer Earthformer) anhand von Elektrizitäts-, Transport-, Finanz- und Wetterdatensätzen bewertet. Hauptsächlich anhand der Indikatoren für den mittleren quadratischen Fehler (MSE) und den mittleren absoluten Fehler (MAE) bewertet:
Dieses Papier ist sehr gut, vergleicht jedoch nur Papiere im Zusammenhang mit Transformer. Tatsächlich sollte es mit einfacheren Methoden verglichen werden . Zum Beispiel einfache lineare Regression, LSTM/GRU oder sogar Baummodelle wie XGB. Eine andere Sache ist, dass sie nicht auf einige Standarddatensätze beschränkt sein sollten, da ich bei anderen zeitreihenbezogenen Datensätzen keine gute Leistung gesehen habe. Beispielsweise haben Informanten große Probleme damit, den Flussfluss genau vorherzusagen, und ihre Leistung ist im Vergleich zu LSTM oder sogar gewöhnlichen Transformern oft schlecht. Da außerdem die Bildabmessungen im Gegensatz zur Computer Vision zumindest konstant bleiben, können Zeitreihendaten in Länge, Periodizität, Trend und Saisonalität stark variieren, sodass eine größere Auswahl an Datensätzen erforderlich ist. In der Rezension von OpenReviews Non-Stationary Transformer hat ein Kommentator diese Probleme ebenfalls geäußert, sie wurde jedoch in der abschließenden Meta-Rezension abgelehnt:
In der Rezension von OpenReviews Non-Stationary Transformer hat ein Kommentator diese Probleme ebenfalls geäußert, sie wurde jedoch in der abschließenden Meta-Rezension abgelehnt:
„Da dieses Modell zur Transformer-Domäne gehört und Transformer sich vor dem Anzeigen im Status befand.“ „Ich glaube nicht, dass Vergleiche mit anderen Methodenfamilien notwendig sind.“
Dies ist ein sehr problematisches Argument und führt zu einer mangelnden Anwendbarkeit der Forschung auf die reale Welt . Wie wir alle wissen: Der überwältigende Vorteil von XGB bei Tabellendaten hat sich nicht geändert. Welchen Sinn hat es also, wenn Transformer hinter verschlossenen Türen arbeitet? Jedes Mal übertroffen und jedes Mal geschlagen.
Als jemand, der Wert auf modernste Methoden und innovative Modelle in der Praxis legt, musste ich am Ende feststellen, dass dies nicht der Fall war, als ich monatelang versuchte, ein sogenanntes „gutes“ Modell zum Laufen zu bringen So gut wie eine einfache lineare Regression durchführen, was ist der Sinn dieser Monate? Was ist der Sinn dieses sogenannten „guten“ Modells? besser als einfache Modelle, aber dies muss im Papier explizit erwähnt werden, anstatt es zu beschönigen oder einfach anzunehmen, dass dies nicht der Fall ist
Aber das Papier ist immer noch gut, wie Earthformer zum MovingMNIST-Datensatz und N- Die Bewertung war Es wurde am Körper-MNIST-Datensatz durchgeführt, und die Autoren haben es verwendet, um die Wirksamkeit der Quaderaufmerksamkeit zu überprüfen und ihre momentane Niederschlagsvorhersage und El-Niño-Zyklusvorhersage zu bewerten. Ich denke, dass dies ein gutes Beispiel für die Integration physikalischen Wissens in die Aufmerksamkeitsmodellarchitektur ist Entwerfen Sie dann gute Tests.
2. Sind Transformatoren für die Zeitreihenprognose wirksam (2022)? Fähigkeit von Transformers, Daten im Vergleich zu Basismethoden vorherzusagen, bestätigen in gewissem Maße, dass Transformers im Allgemeinen eine schlechtere Leistung erbringen als einfachere Modelle und schwierig abzustimmen sind:
Ersetzte die Selbstaufmerksamkeit durch einfache lineare Schichten und stellte fest: „Die Leistung.“ von Informer wächst mit der schrittweisen Vereinfachung, was darauf hindeutet, dass zumindest für bestehende LTSF-Benchmarks Selbstaufmerksamkeitsschemata und andere komplexe Module unnötig sind Die SOTA-Transformatoren sind leicht zurückgegangen, was darauf hindeutet, dass diese Modelle nur ähnliche Daten aus benachbarten Zeitreihensequenzen erfassen. „In den vergangenen Jahren waren die Ergebnisse unzähliger Zeitreihenexperimente des Transformer-Modells in den allermeisten Fällen nicht optimal, oder wir dachten, es sei etwas falsch gemacht worden Details zur Implementierung wurden alle als Ideen für das nächste SOTA-Modell angesehen, aber dieses Papier hat eine konsistente Idee: Wenn ein einfaches Modell Transformer übertrifft, sollten wir sie weiterhin verwenden, oder ist es nur das Aktueller Mechanismus? Sollten wir zu Architekturen wie lstm, gru oder einfachen Feedforward-Modellen zurückkehren? Ich kenne die Antworten auf keine dieser Fragen, aber die Gesamtauswirkungen dieses Artikels bleiben meiner Meinung nach abzuwarten Möglicherweise besteht die Möglichkeit, einen Schritt zurückzutreten und sich auf das Erlernen effizienter Zeitreihendarstellungen zu konzentrieren. 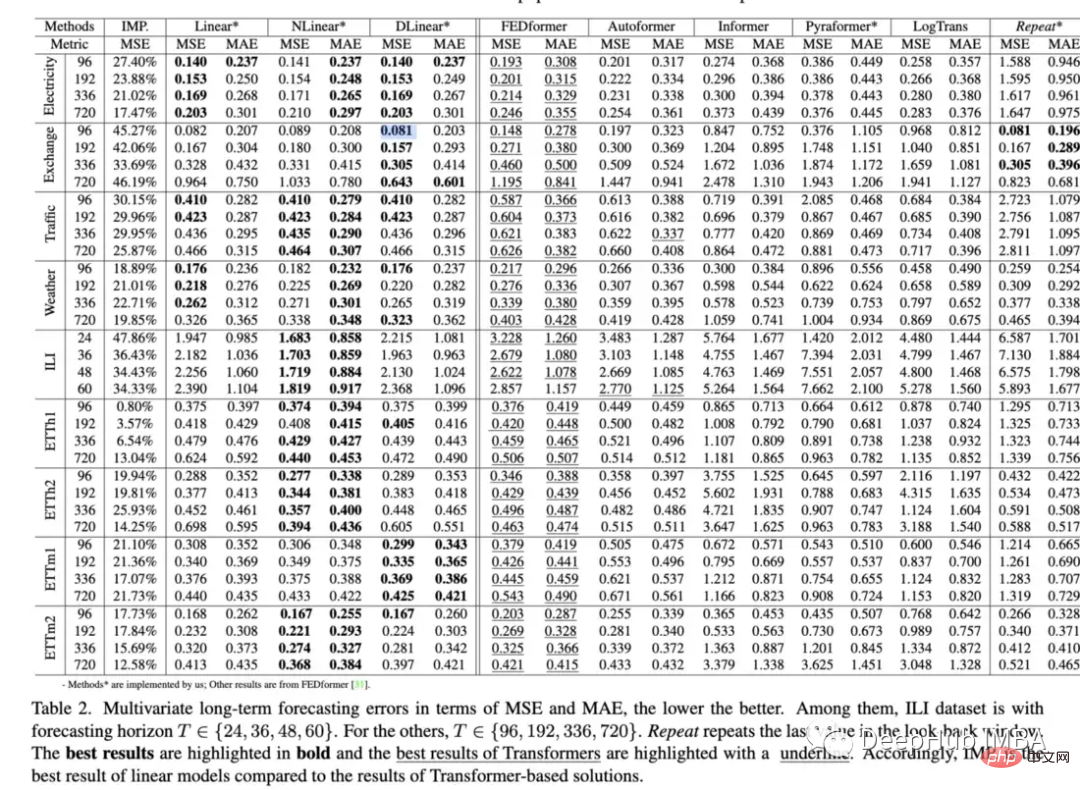
- Umfangreiche Forschung hat sich auf die Anwendung von Transformatoren auf Vorhersagen konzentriert, es wurde jedoch relativ wenig Forschung zur Anomalieerkennung durchgeführt. In diesem Artikel wird ein (unüberwachter) Transformator zur Erkennung von Anomalien mithilfe eines speziell konstruierten Modells vorgestellt die Mechanik und Minmax-Strategie
- .
Dieses Papier bewertet die Leistung des Modells anhand von fünf realen Datensätzen, darunter Server-Maschinendatensatz, gepoolte Servermetriken, Bodenfeuchtigkeit aktiv passiv und NeurIPS-TS (das selbst aus fünf verschiedenen Datensätzen besteht). Während man diesem Modell gegenüber skeptisch sein könnte, insbesondere im Hinblick auf den Standpunkt des zweiten Artikels, ist diese Einschätzung recht streng. Neurips-TS ist ein kürzlich erstellter Datensatz, der speziell für eine genauere Bewertung von Anomalieerkennungsmodellen entwickelt wurde. Dieses Modell scheint die Leistung im Vergleich zu einfacheren Anomalieerkennungsmodellen zu verbessern.
Die Autoren schlagen einen einzigartigen unbeaufsichtigten Transformer vor, der bei einer Vielzahl von Datensätzen zur Anomalieerkennung gut funktioniert. Dies ist eine der vielversprechendsten Arbeiten im Bereich Zeitreihentransformatoren der letzten Jahre. Denn die Vorhersage ist anspruchsvoller als die Klassifizierung oder sogar die Erkennung von Anomalien, da Sie versuchen, eine große Bandbreite möglicher Werte mehrere Zeitschritte in die Zukunft vorherzusagen. So viel Forschung hat sich auf Vorhersagen konzentriert, während Klassifizierung oder Anomalieerkennung ignoriert wurden. Sollten wir bei Transformer einfach anfangen?
4. WaveBound: Dynamische Fehlergrenzen für die Vorhersage stabiler Zeitreihen (Neurips 2022):
Die Autoren bewerten, indem sie es in ein vorhandenes Transformator + LSTNet-Modell einbinden. Sie fanden heraus, dass es in den meisten Fällen die Leistung deutlich verbesserte. Obwohl sie nur das Autoformer-Modell getestet haben und nicht neuere Modelle wie Fedformer. Neue Formen der Regularisierung oder Verlustfunktionen sind immer nützlich, da sie normalerweise in jedes vorhandene Zeitreihenmodell eingefügt werden können. Wenn Sie Fedformer + instationären Mechanismus + Wavebound kombinieren, können Sie wahrscheinlich die einfache lineare Regression in der Leistung schlagen :). ZeitreihendarstellungObwohl Transformer in der Vorhersagerichtung nicht gut abschneidet, hat Transformer große Fortschritte bei der Erstellung nützlicher Zeitreihendarstellungen gemacht. Ich denke, dass dies ein beeindruckender neuer Bereich im Bereich des Zeitreihen-Deep-Learnings ist, der eingehender erforscht werden sollte. 5、TS2Vec: Auf dem Weg zur universellen Darstellung von Zeitreihen (AAAI 2022)https://www.php.cn/link/7690dd4db7a92524c684e3191919eb6b
Das Modell wird mithilfe von Darstellungen zur Vorhersage und Anomalieerkennung bewertet und übertrifft viele Modelle wie Informer und Log Transformer. 6、Lernen latenter saisonaler Trenddarstellungen für Zeitreihenprognosen (Neurips 2022)https://www.php.cn/link/ Die Autoren haben ein Modell (LAST) erstellt, das Variationsinferenz verwendet, um eine getrennte Darstellung von Saisonalität und Trend zu erstellen.
Die Autoren bewerten ihr Modell anhand der nachgelagerten Vorhersageaufgabe, was sie tun, indem sie der Darstellung einen Prädiktor hinzufügen (siehe B in der Abbildung oben). Sie bieten auch interessante Diagramme, um die Visualisierung der Darstellung zu zeigen. Das Modell übertrifft Autoformer bei mehreren Vorhersageaufgaben sowie TS2Vec und Kosten. Es sieht auch so aus, als ob es bei einigen Vorhersageaufgaben eine bessere Leistung als die oben erwähnte einfache lineare Regression erbringen könnte.
 Obwohl ich Modellen, die nur Standardvorhersageaufgaben bewerten, weiterhin skeptisch gegenüberstehe, glänzt dieses Modell wirklich, weil es sich auf die Darstellung und nicht auf die Vorhersageaufgabe selbst konzentriert. Wenn wir uns einige der in der Arbeit gezeigten Grafiken ansehen, können wir erkennen, dass das Modell offenbar lernt, zwischen Saisonalität und Trends zu unterscheiden. Visuelle Darstellungen verschiedener Datensätze sind ebenfalls im selben Raum eingebettet, und es wäre interessant, wenn sie erhebliche Unterschiede aufweisen würden.
Obwohl ich Modellen, die nur Standardvorhersageaufgaben bewerten, weiterhin skeptisch gegenüberstehe, glänzt dieses Modell wirklich, weil es sich auf die Darstellung und nicht auf die Vorhersageaufgabe selbst konzentriert. Wenn wir uns einige der in der Arbeit gezeigten Grafiken ansehen, können wir erkennen, dass das Modell offenbar lernt, zwischen Saisonalität und Trends zu unterscheiden. Visuelle Darstellungen verschiedener Datensätze sind ebenfalls im selben Raum eingebettet, und es wäre interessant, wenn sie erhebliche Unterschiede aufweisen würden. 7、CoST: Kontrastives Lernen entwirrter saisonaler Trenddarstellungen für Zeitreihenprognosen (ICLR 2022)
https://www.php. cn/link/791d3a0048b9c200dceca07f99ddd178
Dies ist ein Artikel, der Anfang 2022 bei ICLR veröffentlicht wurde und LaST in Bezug auf Lernsaison und Trenddarstellung sehr ähnlich ist. Da LaST seine Leistung weitgehend ersetzt hat, wird es hier nicht zu ausführlich beschrieben. Aber der Link ist oben für diejenigen, die ihn lesen möchten.Andere interessante Artikel
8、Domain Adaptation for Time Series Forecasting via Attention Sharing (ICML 2022)
https://www . php.cn/link/d4ea5dacfff2d8a35c0952291779290d
Vorhersage ist eine Herausforderung für DNN, wenn es an Trainingsdaten mangelt. In diesem Artikel wird eine gemeinsame Aufmerksamkeitsschicht für Domänen mit umfangreichen Daten verwendet und anschließend separate Module für Zieldomänen.
Das vorgeschlagene Modell wird anhand synthetischer und realer Datensätze evaluiert. In einer synthetischen Umgebung wurden Kaltstart-Lernen und Wenig-Schuss-Lernen getestet und es wurde festgestellt, dass ihre Modelle einfache Transformer- und DeepAR-Modelle übertrafen. Für den realen Datensatz wurde der Einzelhandelsdatensatz von Kaggle übernommen und das Modell übertraf die Basislinie in diesen Experimenten deutlich.
Kaltstart, wenige Stichproben und endliches Lernen sind äußerst wichtige Themen, aber nur wenige Artikel befassen sich mit Zeitreihen. Dieses Modell stellt einen wichtigen Schritt zur Lösung einiger dieser Probleme dar. Dies bedeutet, dass sie anhand vielfältigerer, begrenzter realer Datensätze ausgewertet und mit mehr Basismodellen verglichen werden können. Der Vorteil der Feinabstimmung oder Regularisierung besteht darin, dass sie für jede Architektur angepasst werden kann.
9、Wann man eingreifen sollte: Erlernen optimaler Interventionsrichtlinien für kritische Ereignisse (Neurips 2022)
https://www.php.cn/link /f38fef4c0e4988792723c29a0bd3ca98
Obwohl dies kein „typischer“ Zeitreihenaufsatz ist, habe ich mich entschieden, ihn in diese Liste aufzunehmen, da der Schwerpunkt des Aufsatzes darauf liegt, Maschinen zu finden, bevor sie ausfallen. Der beste Zeitpunkt zum Eingreifen. Dies nennt man OTI oder Optimal Time Intervention
Eines der Probleme bei der Bewertung von OTI ist die Genauigkeit der zugrunde liegenden Überlebensanalyse (wenn sie falsch ist, ist die Bewertung falsch). Die Autoren bewerteten ihr Modell anhand zweier statischer Schwellenwerte, stellten fest, dass es gut funktionierte, und zeichneten die erwartete Leistung und das Hit-to-Fail-Verhältnis für verschiedene Richtlinien auf.
Dies ist ein interessantes Problem und die Autoren schlagen eine neuartige Lösung vor: „Wenn es eine Grafik gäbe, die den Kompromiss zwischen Ausfallwahrscheinlichkeit und erwarteter Interventionszeit zeigt, dann könnten Experimente sein.“ überzeugender, sodass man die Form dieser Kompromisskurve visuell erkennen kann.“ Getestete Benchmarks
Monash Time Series Forecasting Archive (Neurips 2021): Dieses Archiv soll eine „Masterliste“ von erstellen verschiedene Zeitreihendatensätze und bieten einen aussagekräftigeren Benchmark. Das Repository enthält über 20 verschiedene Datensätze aus mehreren Branchen, darunter Gesundheit, Einzelhandel, Mitfahrgelegenheiten, Demografie und mehr.
https://www.php.cn/link/5d7009220a974e94404889274d3a9553
Subseasonal Forecasting Microsoft (2021): Das ist Ein öffentlich veröffentlichter Datensatz von Microsoft zur Förderung des Einsatzes von maschinellem Lernen zur Verbesserung subsaisonaler Prognosen (z. B. zwei bis sechs Wochen in die Zukunft). Subsaisonale Vorhersagen helfen Regierungsbehörden, sich besser auf Wetterereignisse und Entscheidungen der Landwirte vorzubereiten. Microsoft hat für diese Aufgabe mehrere Benchmark-Modelle eingebunden, und im Allgemeinen schneiden Deep-Learning-Modelle im Vergleich zu anderen Methoden recht schlecht ab. Das beste DL-Modell ist ein einfaches Feedforward-Modell, und Informer schneidet sehr schlecht ab.
https://www.php.cn/link/c3cbd51329ff1a0169174e9a78126ee1
Revisiting Time Series Outlier Detection: Dieser Artikel bespricht Für das Benchmarking werden viele vorhandene Datensätze zur Erkennung von Anomalien/Ausreißern sowie 35 neue synthetische Datensätze und 4 Datensätze aus der realen Welt vorgeschlagen.
https://www.php.cn/link/03793ef7d06ffd63d34ade9d091f1ced
Open-Source-Timing-Prediction-Framework FF#🎜🎜 # Flow Forecast ist ein Open-Source-Zeitreihenvorhersage-Framework, das die folgenden Modelle umfasst:
Vanilla LSTM (LSTM), SimpleTransformer, Multi-Head Attention, Transformer mit linearem Decoder, DARNN, Transformer XL, Informer, DeepAR, DSANet, SimpleLinearModel usw. Dies ist eine gute Quelle für Modellcode zum Erlernen der Verwendung von Deep Learning zur Zeitvorhersage. Wenn Sie interessiert sind, können Sie einen Blick darauf werfen. https://www.php.cn/link/fea33a31df7d05a276193d32621ecbe4
Zusammenfassung#🎜 🎜# In den letzten zwei Jahren haben wir den Aufstieg und möglichen Rückgang von Transformern bei der Zeitreihenvorhersage und den Aufstieg von Methoden zur Einbettung von Zeitreihen erlebt, mit weiteren Durchbrüchen bei der Erkennung und Klassifizierung von Anomalien.
Aber für Deep-Learning-Zeitreihen: Interpretierbarkeit, Visualisierung und Benchmarking-Methoden fehlen noch, da es sehr wichtig ist, wo das Modell ausgeführt wird und wo Leistungsausfälle auftreten. Darüber hinaus könnten in Zukunft weitere Formen der Regularisierung, Vorverarbeitung und des Transferlernens zur Verbesserung der Leistung entstehen.
Vielleicht ist Transformer gut für die Zeitreihenvorhersage (vielleicht auch nicht). Ohne das Aufkommen von Patch wird Transformer weiterhin als nutzlos angesehen.
 Obwohl ich Modellen, die nur Standardvorhersageaufgaben bewerten, weiterhin skeptisch gegenüberstehe, glänzt dieses Modell wirklich, weil es sich auf die Darstellung und nicht auf die Vorhersageaufgabe selbst konzentriert. Wenn wir uns einige der in der Arbeit gezeigten Grafiken ansehen, können wir erkennen, dass das Modell offenbar lernt, zwischen Saisonalität und Trends zu unterscheiden. Visuelle Darstellungen verschiedener Datensätze sind ebenfalls im selben Raum eingebettet, und es wäre interessant, wenn sie erhebliche Unterschiede aufweisen würden.
Obwohl ich Modellen, die nur Standardvorhersageaufgaben bewerten, weiterhin skeptisch gegenüberstehe, glänzt dieses Modell wirklich, weil es sich auf die Darstellung und nicht auf die Vorhersageaufgabe selbst konzentriert. Wenn wir uns einige der in der Arbeit gezeigten Grafiken ansehen, können wir erkennen, dass das Modell offenbar lernt, zwischen Saisonalität und Trends zu unterscheiden. Visuelle Darstellungen verschiedener Datensätze sind ebenfalls im selben Raum eingebettet, und es wäre interessant, wenn sie erhebliche Unterschiede aufweisen würden. 

Das obige ist der detaillierte Inhalt vonEin Überblick über den Forschungsfortschritt von Deep Learning bei der Vorhersage und Klassifizierung von Zeitreihen im Jahr 2022. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr