
Heim >Technologie-Peripheriegeräte >KI >Ein Überblick über die NLP-Modelltechnologie der automatischen Programmierung
Ein Überblick über die NLP-Modelltechnologie der automatischen Programmierung

- PHPznach vorne
- 2023-04-13 09:52:051794Durchsuche
Copilot, Codex und AlphaCode: Der aktuelle Stand automatisch programmierter Computerprogramme
In den letzten Jahren haben wir aufgrund des Aufstiegs von Transformatoren im Bereich der Verarbeitung natürlicher Sprache eine erstaunliche Vielfalt an Code-geschriebenen Deep-Learning-Modellen gesehen. Die Fähigkeit, Computerprogramme zu schreiben, oft als Programmsyntheseproblem bezeichnet, wird mindestens seit den späten 1960er und frühen 1970er Jahren untersucht.
In den 2010er und 20er Jahren inspirierte der Erfolg aufmerksamkeitsbasierter Modelle in anderen Bereichen erneut die Forschung zur prozeduralen Synthese, d. basierend auf neuronalen Modellen (Transformatoren).
Die vorab trainierten Modelle zeigten dank ihres Aufmerksamkeitsmechanismus beeindruckende Fähigkeiten beim Meta-Lernen und scheinen praktische Anwendung bei der Entwicklung von Textaufgaben zu haben – indem sie im Eingabeaufforderungsinhalt nur ein paar Beispiele (genannt „Zero-Shot oder Wenige“) bereitstellen -shot learning“ in der Forschungsliteratur).
Moderne Programmsynthese basierend auf tiefen NLP-Modellen
NLP-Modelle können mithilfe spezieller Datensätze weiter trainiert werden, um die Leistung für bestimmte Aufgaben zu optimieren. Das Schreiben von Code ist ein besonders interessanter Anwendungsfall für diese Anwendung.
Das als „Your AI Pair Programmer“ beworbene Copilot-Projekt auf GitHub löste bei seinem Start im Jahr 2021 eine ziemliche Kontroverse aus. Dies ist zum großen Teil auf die Verwendung des gesamten öffentlichen GitHub-Codes im Trainingsdatensatz zurückzuführen. Den Anweisungen zufolge umfassen diese Codebasen Projekte mit Copyleft-Lizenzen, die die Verwendung von Code in Projekten wie Copilot möglicherweise nicht zulassen, es sei denn, Copilot selbst ist Open Source.
Copilot ist das Produkt einer Beziehung zwischen der OpenAI-Organisation und der Microsoft Corporation und basiert auf einer Code-trainierten Version von GPT-3. Die von OpenAI demonstrierte und über seine API verfügbare Version heißt Codex. Die formale experimentelle Beschreibung mit Copex ist in dem von Herrn Chen et al. im Jahr 2021 veröffentlichten Artikel detailliert beschrieben.
Anfang 2022 ließ sich DeepMind nicht übertreffen und entwickelte sein eigenes prozedural synthetisiertes Deep-NLP-System: AlphaCode.
Neuer Herausforderer: AlphaCode
AlphaCode ist wie Codex und Copilot zuvor ein groß angelegtes NLP-Modell, das zum Schreiben von Code entwickelt und trainiert wurde. Wie Copilot wurde AlphaCode nicht entwickelt, um AlphaCode als Produktivitätstool für Softwareentwickler zu nutzen, sondern um die menschliche Programmierleistung bei wettbewerbsorientierten Programmieraufgaben herauszufordern.
Die Wettbewerbs-Codierungsherausforderungen, die zum Trainieren und Bewerten von AlphaCode (die den neuen CodeContests-Datensatz bilden) verwendet werden, liegen im Schwierigkeitsgrad zwischen dem Schwierigkeitsgrad früherer Datensätze und dem Schwierigkeitsgrad realer Softwareentwicklung.
Für diejenigen, die mit kompetitiven Programmier-Challenge-Sites nicht vertraut sind: Diese Aufgabe ist ein bisschen wie eine vereinfachte Version der testgetriebenen Entwicklung. Angesichts einiger Textbeschreibungen und einiger Beispiele besteht der Kern dieser Herausforderung darin, ein Programm zu schreiben, das eine Reihe von Tests besteht – von denen die meisten dem Programmierer verborgen bleiben.
Idealerweise sollten versteckte Tests umfassend sein und das Bestehen aller Tests bedeutet, dass ein bestimmtes Problem erfolgreich gelöst wurde. Allerdings ist es ein schwieriges Problem, jeden Randfall mit Unit-Tests abzudecken. Ein wichtiger Beitrag auf dem Gebiet der Programmsynthese ist tatsächlich der CodeContests-Datensatz selbst, da das DeepMind-Team erhebliche Anstrengungen unternommen hat, um durch einen Mutationsprozess zusätzliche Tests zu generieren, mit dem Ziel, die Falsch-Positiv-Rate zu reduzieren (Tests bestanden, aber das Problem besteht). nicht gelöst) und langsame Positivitätsrate (der Test besteht, aber die Lösung ist zu langsam).
Die Leistung von AlphaCode wird anhand des Inhalts einer wettbewerbsfähigen Programmierherausforderung auf der Wettbewerbswebsite CodeForces bewertet. Insgesamt gehörte AlphaCode im Durchschnitt zu den „Top 54,3 %“ der konkurrierenden (und vermutlich menschlichen) Programmierer.
Bitte beachten Sie, dass diese Kennzahl etwas irreführend sein kann, da sie tatsächlich einer Leistung von 45,7 % entspricht. Unglaublicherweise ist das AlphaCode-System in der Lage, jeden Algorithmus zu schreiben, der alle versteckten Tests besteht. Seien Sie jedoch gewarnt: AlphaCode verwendet eine ganz andere Strategie als Menschen, um Programmierprobleme zu lösen.
Während ein menschlicher Konkurrent möglicherweise einen Algorithmus schreibt, um die meisten Routinen zu lösen, indem er Erkenntnisse aus der Ausführung früherer Versionen der Lösung einbezieht und diese kontinuierlich verbessert, bis alle Tests bestanden sind, verfolgt AlphaCode einen breiter angelegten Ansatz, der für jede Routine mehrere Beispiele generiert Frage und wählen Sie 10 Proben aus, die Sie einreichen möchten.
Ein großer Beitrag zur Leistung von AlphaCode im CodeContests-Datensatz sind die Ergebnisse der Filterung und Clusterung nach der Generierung: Nachdem etwa 1.000.000 Kandidatenlösungen generiert wurden, beginnt es mit der Filterung der Kandidaten, um fehlgeschlagene Beispieltests in den Problembeschreibungskandidaten zu entfernen, wodurch etwa 99 eliminiert werden % des Kandidatenpools.
Der Autor erwähnte, dass etwa 10 % der Probleme zu diesem Zeitpunkt keine Kandidatenlösungen haben, die alle Beispieltests bestehen.
Die verbleibenden Kandidaten werden dann durch Clustering auf 10 oder weniger Einreichungen gefiltert. Kurz gesagt, sie trainierten ein anderes Modell, um basierend auf der Problembeschreibung zusätzliche Testeingaben zu generieren (beachten Sie jedoch, dass sie für diese Tests keine gültigen Ausgaben hatten).
Die verbleibenden Kandidatenlösungen (die Anzahl nach dem Filtern kann weniger als 1000 betragen) werden basierend auf ihrer Ausgabe auf der generierten Testeingabe geclustert. Ein Kandidat aus jedem Cluster wird in der Reihenfolge vom größten zum kleinsten zur Einreichung ausgewählt. Wenn weniger als 10 Cluster vorhanden sind, werden die Cluster mehrmals abgetastet.
Während die Filter-/Clustering-Schritte einzigartig sind und AlphaCode auf den neuen CodeContests-Datensatz abgestimmt ist, wird es zunächst auf die gleiche Weise trainiert wie Codex oder Copilot. AlphaCode wurde zunächst anhand eines großen, öffentlich verfügbaren Codedatensatzes von GitHub vorab trainiert (abgerufen am 14. Juli 2021). Sie trainierten 5 Varianten und die Anzahl der Parameter stieg von 284 Millionen auf 41 Milliarden.
Im gleichen Sinne wie die AlphaGo-Serie oder der AlphaStar-Roboter, der das Spiel StarCraft II spielt, ist AlphaCode auch ein Forschungsprojekt, das darauf abzielt, ein System zu entwickeln, das menschliche Fähigkeiten in speziellen Aufgabenbereichen annähert Prozess der Programmsynthese Die Eintrittsbarrieren für Versorgungsunternehmen entwickelten sich in .
Aus der Perspektive der Entwicklung praktischer Werkzeuge zur Lösung von Problemen sind Codex- und Copilot-Werkzeuge auf Basis von GPT-3 Vertreter von Robotern in diesem Bereich. Codex ist eine OpenAI-Variante von GPT-3, die auf einem Korpus öffentlich verfügbaren Codes trainiert wird. Basierend auf dem mit dem Papier veröffentlichten HumanEval-Datensatz berichtet OpenAI, dass Codex mehr als 70 % der Probleme lösen kann, indem es 100 Beispiele in Aufgaben im „Docstring to Code“-Format generiert.
Als nächstes werden wir diese schnelle Programmiertechnik untersuchen, die mithilfe von Codex automatisch Code generiert. Wir werden gleichzeitig das unten angegebene Modell verwenden, um John Conways Spiel des Lebens zu entwickeln.
GitHub Copilot übernimmt die Methode der automatischen Code-Vervollständigung. Die aktuelle Verpackungsform ist eine Erweiterung integrierter Entwicklungsumgebungen wie Visual Studio, VSCode, Neovim und JetBrains. Laut der Beschreibung auf der Copilot-Webseite ist es Copilot gelungen, eine Reihe gut getesteter Python-Funktionen gemäß der angegebenen Beschreibung erfolgreich neu zu schreiben, von denen 57 % dem HumanEval-Datensatz ähneln.
Wir werden uns einige praktische Anwendungsfälle für Copilot ansehen, beispielsweise die Automatisierung des Testschreibens mithilfe einer speziellen Betaversion der Copilot-Erweiterung für VSCode.
Prompt-Programmierung: Conways „Spiel des Lebens“ mit Codex schreiben
In diesem Abschnitt stellen wir das Schreiben von Zellen basierend auf John Conways „Spiel des Lebens“-Automatensimulatoraufgaben vor. Mit ein paar Modifikationen und ohne feste Kodierung der Regeln sollte unser Programm in der Lage sein, jeden Satz lebensechter Regeln für zelluläre Automaten zu simulieren.
Anstatt 100 Beispiele zu generieren und das beste auszuwählen (entweder manuell oder durch Ausführen von Tests), verfolgen wir einen interaktiven Ansatz. Wenn Codex eine schlechte Lösung liefert, nehmen wir Anpassungen vor, um eine bessere Antwort zu finden. Selbstverständlich können wir bei absoluter Notwendigkeit den Code weiter modifizieren, um ein funktionierendes Beispiel zu erhalten, für den Fall, dass Codex komplett ausfällt.
Schreiben Sie eine realistische CA (Zellularautomaten). Es handelt sich um eine Gitterdynamik, in der Zeit, Raum und Zustand alle diskret sind und räumliche Interaktion und zeitliche Kausalität lokal sind eine Funktion vorschlagen, die Nachbarn berechnet. Wir haben die folgende Docstring-Eingabeaufforderung geschrieben und sie code-davinci-001 bereitgestellt, dem größten Codex-Modell in der OpenAI-API-Bibliothek:
# PROMPT<br>import numpy as np<br>def compute_neighborhood(grid: np.array) -> np.array:<br>"""<br>Compute the sum of cell states in the Moore neighborhood<br>for each cell in the input grid.<br>A Moore neighborhood includes 8 cells,<br>diagonally and orthogonally adjacent to, but not including, the center cell.<br>The cells denoted by '1' correspond to the Moore neighborhood for cell a:<br>1 1 1<br>1 a 1<br>1 1 1<br>If cell 'a' is on the edge of the grid,<br>the Moore neighborhood wraps around to the cells on the opposite edge,<br>i.e. grid is on a toroid.<br><br>args:<br>grid, a numpy array with binary values 0 or 1. grid contains the current cell state values<br>Returns:<br><br>neighorhood_grid, a numpy array with integer values from 0 to 8.<br>For each cell (element in grid) in grid, neighborhood_grid should<br>contain the sum of states in that cell's Moore neighborhood<br>"""
Fügen Sie im obigen Code die Kommentarzeile „# PROMPT“ hinzu. und „#GENERATED“, um klarer zu machen, wo die Eingabeaufforderung endet.
Haben Sie die ziemlich ausführliche Docstring-Eingabeaufforderung oben sorgfältig analysiert? Wie funktioniert Codex? Tatsächlich sah der erste Versuch mit Codex so aus:
# GENERATED<br># TODO: implement this function<br>pass
Das verheißt wahrscheinlich nichts Gutes für unser kleines Experiment. Selbst nach der Optimierung des P-Wert-Hyperparameters, um eine lockerere Kernel-Abtastung (und hoffentlich eine bessere Diversität) zu erreichen, scheint Codex immer noch keine Antwort auf die obige Frage zu haben.
Glücklicherweise können wir der Docstring-Eingabeaufforderung einfach etwas wie das Folgende hinzufügen und Codex wird eine vielversprechendere Ausgabe erzeugen.
# PROMPT (appended to previous prompt)<br><br>this function is completed and does not include any TODOs<br>"""<br><br># GENERATED<br><br># get the dimensions of the grid<br>n_rows, n_cols = grid.shape<br><br># initialize the output array<br>neighborhood_grid = np.zeros((n_rows, n_cols), dtype=int)<br><br># loop over the grid<br>for i in range(n_rows):<br>for j in range(n_cols):<br><br># get the current cell value<br>cell_val = grid[i, j]<br><br># get the Moore neighborhood of the current cell<br># using the get_neighborhood function<br>neighborhood = get_neighborhood(grid, i, j)<br><br># sum the cell values in the neighborhood<br>neighborhood_sum = np.sum(neighborhood)<br><br># store the sum in the neighborhood grid<br>neighborhood_grid[i, j] = neighborhood_sum<br><br>return neighborhood_grid
Natürlich ist das noch keine wirkliche Lösung, da es eine unbenutzte Variable cell_val einführt und den Großteil seiner Arbeit an eine andere Funktion delegiert, die es gerade hinzugefügt hat, get_neighborhood. Aber insgesamt scheint dies ein machbarer Anfang zu sein.
Als nächstes haben wir einen einfachen Dokumentstring für die oben erwähnte Funktion get_neighborhood geschrieben:
def get_neighborhood(grid: np.array, i: int, j: int) -> np.array:<br>"""<br>get_neighborhood is used by compute_neighborhood <br>to return the 3x3 Moore neighborhood for the cell <br>located at coordinates i,j If i,j coordinates are <br>on the edge of the grid (i.e. i or j equal 0, or i == <br>grid.shape[0]-1 or j == grid.shape[1]), the Moore<br>Neighborhood should wrap around to include cells on the<br>opposite edge. In other words the grid can be considered to <br>be the surface of a toroid, like 'Pac-Man'<br><br>args:<br>grid, np.array, this is the current state of<br>the cellular automata grid<br>i, int, this coordinate corresponds to the row<br>j, int, coordinate corresponding to column<br><br>returns:<br>moore_neighborhood - np.array, should always have<br>dimensions 3x3 and<br>contain the Moore neighborhood for the cell at i,j <br>in grid.Because the center cell is not part of the<br>neighborhood, moore_neighborhood[1,1] should always <br>be 0<br>"""<br><br># GENERATED<br><br># get the dimensions of the grid<br>n_rows, n_cols = grid.shape<br><br># initialize the output array<br>moore_neighborhood = np.zeros((3, 3), dtype=int)<br><br># get the coordinates of the Moore neighborhood<br># using the get_neighborhood_coordinates function<br>neighborhood_coords = <br>get_neighborhood_coordinates(i, j, n_rows, n_cols)<br><br># loop over the coordinates<br>for coord in neighborhood_coords:<br># get the cell value at the coordinate<br>cell_val = grid[coord[0], coord[1]]<br><br># store the cell value in the output array<br>moore_neighborhood[coord[0], coord[1]] = cell_val<br><br>return moore_neighborhood
Die Ausgabe des obigen Programms scheint machbar; aber nach der Prüfung enthält sie tatsächlich einen wichtigen Fehler .
In der Schleife über die Nachbarkoordinaten wird der Wert der Moore-Nachbarschaft zugewiesen, wobei dieselben Koordinaten verwendet werden, die zum Abrufen des Werts aus dem Raster verwendet wurden.
Wir haben keine klare Möglichkeit gefunden, Codex aufzufordern, Fehler zu vermeiden; daher mussten wir den Code manuell ändern:
# FIXED loop over the coordinates <br>for index, coord in enumerate(neighborhood_coords): <br># get the cell value at the coordinate<br>cell_val = grid[coord[0], coord[1]] <br><br># FIXED store the cell value in the output array<br>moore_neighborhood[index // 3, index % 3] = cell_val<br><br>return moore_neighborhood
Außerdem wurde eine weitere Funktion get_neighborhood_coordinates eingeführt Behandeln Sie die „schwierigen“ Teile mit dem vorherigen Code.
Als nächstes müssen wir einen Prompt für die Funktion get_neighborhood_coordinates schreiben.
# PROMPT <br>def get_neighborhood_coordinates(<br>i: int, j: int, n_rows: int, n_cols: int) -> list:<br>"""<br>get_neighborhood_coordinates is used by get_neighborhood <br>to return the coordinates of the 3x3 Moore neighborhood for<br>the cell located at coordinates i,j If i,j coordinates are on<br>the edge of the grid (i.e. i or j equal 0, or i ==<br>grid.shape[0]-1 or j == grid.shape[1]), the Moore<br>Neighborhood should wrap around to include cells on the<br>opposite edge. In other words the grid can be considered to <br>be the surface of a toroid, like 'Pac-Man'<br><br>args:<br>i, int, this coordinate corresponds to the row<br>j, int, coordinate corresponding to column<br>n_rows, int, number of rows in the grid<br>n_cols, int, number of columns in the grid<br><br>returns:<br>neighborhood_coords - list of tuples, <br>each tuple contains the coordinates<br>of a cell in the Moore neighborhood<br>"""<br><br># GENERATED<br><br># initialize the output list<br>neighborhood_coords = []<br><br># get the coordinates of the Moore neighborhood<br># using the get_neighborhood_coordinates function<br>for row in range(i-1, i+2):<br>for col in range(j-1, j+2):<br># skip the center cell<br>if row == i and col == j:<br>continue<br><br># check if the cell is on the edge of the grid<br># if so, wrap around to the opposite edge<br>if row row = n_rows - 1<br>elif row == n_rows:<br>row = 0<br><br>if col col = n_cols - 1<br>elif col == n_cols:<br>col = 0<br><br># store the cell coordinates<br>neighborhood_coords.append((row, col))<br><br>return neighborhood_coords
这比我们预期的函数式编程深度要深一点(compute_neighborhood调用get_neighborhood,反过来get_neighborhood又调用get_neighborhood_coordinates),但看起来我们终于有了一组函数,可以返回一个邻居和的网格。
还剩下update函数,它对应的docstring提示如下所示:
# PROMPT<br><br>def update_grid(grid: np.array, rules: list) -> np.array:<br>"""<br>update input arg grid according the the Life-like rules<br>contained in input arg rules. rules is a list of lists, <br>with the first element containing a list of 'birth'<br>conditions (cells go from 0 -> 1) and the second element<br>containing a list of 'survival' conditions (cells are<br>unchanged).<br>Cells which have a neighborhood sum that is not in the<br>'birth' (B) or 'survival' (S) rules go to 0. <br><br>This functions uses function compute_neighborhood to compute <br>the neighborhood value for each cell in grid.<br><br>args:<br>grid, np.array. grid contains the cell values (0 or 1)<br> rules, list of lists. rules contains the B/S rules <br> for Life-like cellular automatafor example, to<br> simulate Conway's Life CA, `rules = [[3], [2,3]]`,<br> i.e. B3/S23 Life Without Death has rules<br> B3/S012345678, so `rules = [[3],<br> [0,1,2,3,4,5,6,7,8]]`<br><br>update_grid should raise an Exception if rules contains <br>values greater than 8 (maximum number of live cells in a<br>Moore neighborhood) or less than 0. <br>"""<br><br># GENERATED<br><br># get the dimensions of the grid<br>n_rows, n_cols = grid.shape<br><br># get the neighborhood grid<br>neighborhood_grid = compute_neighborhood(grid)<br><br># loop over the grid<br>for i in range(n_rows):<br>for j in range(n_cols):<br># get the current cell value<br>cell_val = grid[i, j]<br><br># get the neighborhood value for the current cell<br>neighborhood_val = neighborhood_grid[i, j]<br><br># check if the cell is alive<br>if cell_val == 1:<br># check if the cell should die<br>if neighborhood_val not in rules[1]:<br>grid[i, j] = 0<br>else:<br># check if the cell should be born<br>if neighborhood_val in rules[0]:<br>grid[i, j] = 1<br><br>return grid
这看起来是解决上面问题的一种非常合理的方法;尽管我们确实明确建议,如果邻居网格包含错误的值并且在生成的输出中找不到,就会引发异常。
只需进行一些修复:在函数get_neighborhood中进行手动干预,并且尝试给出一些提示,我们就可以成功地设计出一个完全可行的类似生命的细胞自动机模拟器。
上面的代码不是一个特别快的实现方案,但它的质量与程序员在开始使用一种新语言时可能做出的那种“Hello World”尝试相似。值得注意的是,在训练数据集中包含了许多示例,供研究者参考。
在康威的《生命游戏》中,我们可以想象这段程序在微型滑翔机的发展过程中取得的成功。

虽然我们确实通过一组函数完成了CA模拟器的编写,但这种方法对于日常软件工程来说并不是非常有用或现实的开发方式。但另一方面,这并不能阻止像SourceAI这样的初创公司(本质上是OpenAI Codex API的包装商)将其服务宣传为“给每个人创造有价值的定制软件的机会”。
“我们构建了一个独立的系统,可以开发出世界上最熟练的工程师级别的软件。”不过,与Codex交互的确是学习或实践编程的一种潜在有用的方式,尤其是针对CodeSignal、CodeForces或HackerRank等网站的编程问题方面。
接下来,我们将尝试评估Codex/Copilot,以获得自动编写测试和docstring的更现实的使用情形。
任务2:编写测试
对于本例来说,我们选择使用VSCode开发工具的GitHub Copilot扩展来编写测试。
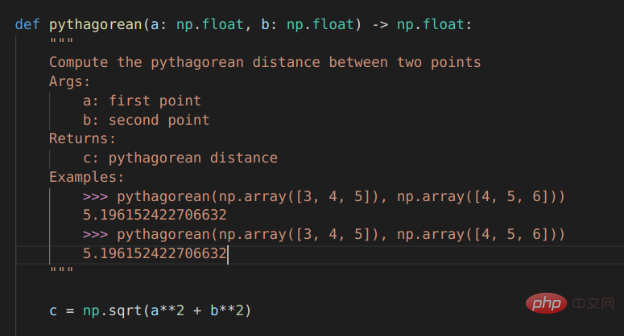
# PROMPT (in VSCode)<br>import numpy as np<br>def pythagorean(a: np.float, b: np.float) -> np.float:<br>"""<br>Use the Pythagorean theorem to comput the hypotenuse for<br>a triangle with side lengths a and b<br><br>args:<br>a, np.float, side of the triangle<br>b, np.float, the other side of the triangle<br><br>returns:<br>c, np.float, the length of the hypotenuse<br>"""<br>c = np.sqrt(a**2 + b**2)<br>return c<br><br>def test_pythagorean():<br><br># GENERATED (Copilot autocomplete)<br>"""<br>Test the pythagorean function<br>"""<br>a = np.array([3, 4, 5])<br>b = np.array([4, 5, 6])<br>c = pythagorean(a, b)<br><br>assert np.allclose(c, np.sqrt(a**2 + b**2))
虽然毕达哥拉斯定理函数可能过于简单,但Copilot建议进行一次合理的测试。如果您运行它,它就会通过。你会注意到,自动完成建议能够正确地获得测试的结构和数字内容。
如果我们想使用自己喜欢的框架以更系统的方式编写测试,该怎么办?不用太担心,因为我们已经使用numpy库和自动微分技术编写了大量的低级学习模型,供给测试者使用。因此,虽然接下来的这个示例不是100%真实地来自真实世界,但效果还是比较贴近真实情况的。
在本例中,我们将使用autograd和numpy以及unittest中的TestCase类设置一个简单的多层感知器前向传递、损失函数和梯度函数进行测试。
#PROMPT<br>import unittest<br>from autograd import numpy as np<br>from autograd import grad<br><br>def forward_mlp(input_x: np.array, <br>weights: list, biases: list) -> np.array:<br>"""<br>compute the forward pass of a multilayer perceptron. <br>The number of layers is equal to the length of the list of<br>weights, which must be the same as the list of biases,<br>biases. <br><br>args:<br>input_x, np.array, input data<br>weights, list of np.arrays, a list of np.array matrices,<br> representing the weights<br>biases: list of np.arrays, a list of biases for each<br> layer<br><br>returns:<br>result, np.array, the output of the network<br>"""<br><br>assert len(weights) == len(biases)<br><br>for layer_index in range(len(weights) - 1):<br>input_x = np.tanh(np.matmul(input_x,<br>weights[layer_index]) + biases[layer_index])<br><br>output = np.matmul(input_x, weights[-1]) + biases[-1]<br>return output<br>def get_loss(input_x: np.array, weights: list, <br>biases: list, target: np.array) -> np.float:<br>"""<br>compute the mean squared error loss for an mlp with weights<br>and biases, with respect to the input data input_x and the<br>target array target.<br><br>args:<br>input_x, np.array, input data<br>weights, list of np.arrays, a list of np.array matrices,<br>representing the weights<br>biases: list of np.arrays, a list of biases for each<br>layer<br>target: np.array, the target values<br><br>returns:<br>loss, np.float, the loss<br>"""<br><br>output = forward_mlp(input_x, weights, biases)<br><br>return np.mean((output - target)**2)<br><br>get_loss_grad = grad(get_loss, argnum=(1,2))<br><br><br>class TestMLP(unittest.TestCase):<br>"""<br>tests for MLP, get_loss, and get_grad_loss<br>"""<br># GENERATED (chosen from Copilot suggestions)<br>def setUp(self):<br>pass<br><br>def test_forward_mlp(self):<br>"""<br>test forward_mlp<br>"""<br><br>input_x = np.array([[1, 2, 3], [4, 5, 6]])<br>weights = [np.array([[1, 2], [3, 4]]), <br>np.array([[5, 6], [7, 8]]), <br>np.array([[9, 10], [11, 12]])]<br>biases = [np.array([[1, 2]]), np.array([[3, 4]]),<br>np.array([[5, 6]])]<br><br>output = forward_mlp(input_x, weights, biases)<br>self.assertTrue(np.allclose(output, <br>np.array([[-0.9, -0.9], [-0.9, -0.9]])))<br><br>def test_get_loss(self):<br>"""<br>test get_loss<br>"""<br>input_x = np.array([[1, 2, 3], [4, 5, 6]])<br>weights = [np.array([[1, 2], [3, 4]]), <br>np.array([[5, 6], [7, 8]]), <br>np.array([[9, 10], [11, 12]])]<br>biases = [np.array([[1, 2]]), np.array([[3, 4]]),<br>np.array([[5, 6]])]<br>target = np.array([[1, 1], [1, 1]])<br><br>loss = get_loss(input_x, weights, biases, target)<br><br>self.assertTrue(np.allclose(loss, 0.5))<br><br>def test_get_loss_grad(self):<br>"""<br>test get_loss_grad<br>"""<br><br>input_x = np.array([[1, 2, 3], [4, 5, 6]])<br>weights = [np.array([[1, 2], [3, 4]]), <br>np.array([[5, 6], [7, 8]]), <br>np.array([[9, 10], [11, 12]])]<br>biases = [np.array([[1, 2]]), np.array([[3, 4]]), <br>np.array([[5, 6]])]<br>target = np.array([[1, 1], [1, 1]])<br><br>loss_grad = get_loss_grad(<br>input_x, weights, biases, target)<br><br>self.assertTrue(<br>np.allclose(loss_grad[0], <br>np.array([[-0.9, -0.9], [-0.9, -0.9]])))<br>self.assertTrue(<br>np.allclose(loss_grad[1], <br>np.array([[-0.9, -0.9], [-0.9, -0.9]])))<br>self.assertTrue(<br>np.allclose(loss_grad[2],<br>np.array([[-0.9, -0.9], [-0.9, -0.9]])))<br><br># END GENERATED (the final two lines are part of the prompt)<br>if __name__ == "__main__":<br>unittest.main(verbosity=1)
Copilot的建议虽然并不完美,但确实为测试类提供了合理的思路。不过,如果您尝试原封不动地运行代码的话,则不会执行任何测试,更不用说通过测试了。
输入数据和第一个权重矩阵之间存在维度不匹配,数据类型也是错误的(所有数组都是整数数据类型),而且无法使用Autograd梯度函数。
当然,上面这些问题并不是很难解决,如果用3x2矩阵替换权重矩阵列表中的第一个条目,那么前向传播应该可以运行。要使得梯度计算测试顺利进行,或者需要在np.array定义的数字上添加小数点,或者显式定义数组数据类型。
有了这些更改后,测试即可成功执行并失败,但预期值在数字表现方面还不正确。
任务3:自动文档字符串
Copilot有很大潜力的一项任务是自动编写文档,特别是为已经编写的函数填写docstring内容。这方面几乎是比较实用了。
对于毕达哥拉斯定理的示例程序,Copilot运行结果已经非常接近,但它将问题描述为查找两点a和b之间的距离,而不是查找边长c到边长a和边长b的距离。不出所料,随同Copilot一同发行的docstring中的示例也与函数的实际内容不匹配:返回的是一个标量,而不是c的值数组。
Copilot对前向MLP函数的docstrings的建议也很接近,但并不完全正确。
Copilot支持的自动Docstring建议
机器能取代我的工作吗?
对于软件工程师来说,程序合成方面的每一项新进展都可能引发一次经济恐慌。
Wenn Computerprogramme Computer genauso programmieren können wie Programmierer, heißt das dann nicht, dass Maschinen „unsere Jobs wegnehmen“ sollten? Wird dies in naher Zukunft der Fall sein?
Oberflächlich betrachtet scheint die Antwort „noch nicht“ zu lauten. Das bedeutet jedoch nicht, dass die Natur der Softwareentwicklung wahrscheinlich dieselbe bleiben wird, wenn diese Tools ausgereifter werden. In Zukunft könnte die Verwendung ausgefeilter Autovervollständigungstools für erfolgreiches Denken genauso wichtig sein wie die Verwendung von Codeformatierungstools.
Copilot befindet sich derzeit in der Betaphase und bietet nur eine begrenzte Anzahl von Optionen für die Verwendung. Ebenso verfügt Codex auch über eine API, die in der Betaversion über OpenAI verfügbar ist. Die Nutzungsbedingungen und Datenschutzaspekte des Pilotprogramms schränken die potenziellen Anwendungsfälle der Technologie ein.
Gemäß der aktuellen Datenschutzrichtlinie kann jeder in diese Systeme eingegebene Code zur Feinabstimmung von Modellen verwendet und von Mitarbeitern von GitHub/Microsoft oder OpenAI überprüft werden. Damit ist der Einsatz von Codex oder Copilot in sensiblen Projekten ausgeschlossen.
Copilot fügt dem Codex-Modell, auf dem es basiert, viele Dienstprogramme hinzu. Sie können ein Grundgerüst oder eine Gliederung für den gewünschten Code schreiben (z. B. ein Beispiel für einen Test des Unittest-Frameworks schreiben) und den Cursor in die Mitte der Gliederung bewegen, um sinnvolle OK-Vorschläge zur automatischen Vervollständigung zu erhalten.
Derzeit ist es unwahrscheinlich, dass Copilot den korrekten vollständigen Code für komplexere Probleme als einfache Codierungspraktiken vorschlägt. Allerdings kann es in der Regel eine vernünftige Gliederung erstellen und manuelles Eintippen ersparen.
Zu beachten ist außerdem, dass Copilot in der Cloud läuft. Das bedeutet, dass es offline nicht funktioniert und die Vorschläge zur automatischen Vervollständigung etwas langsam sind. An dieser Stelle können Sie durch die Vorschläge blättern, indem Sie Alt+] drücken, aber manchmal gibt es nur wenige Vorschläge zur Auswahl oder sogar nur einen Vorschlag zur Auswahl.
Wenn Copilot gut funktioniert, ist es tatsächlich gut genug, um ein wenig gefährlich zu sein. Die vorgeschlagenen Tests im Unittest-Beispiel und der vorgeschlagene Dokumentstring für die Pythagoras-Funktion scheinen auf den ersten Blick korrekt zu sein und werden wahrscheinlich die Prüfung eines abgestumpften Softwareentwicklers bestehen. Aber wenn sie mysteriöse Fehler enthalten, führt das später nur zu Schmerzen!
Zusammenfassend lässt sich sagen, dass Copilot/Codex in seinem aktuellen Zustand eher wie ein Spielzeug oder ein Lernwerkzeug ist, es aber unglaublich ist, dass es tatsächlich funktionieren kann. Wenn Sie einen tanzenden Bären treffen würden, würde Sie wahrscheinlich nicht die Art und Weise beeindrucken, wie gut er tanzt. Auch wenn Sie auf ein intelligentes Code-Vervollständigungstool stoßen, sollte Sie nicht die Perfektion des Codes beeindrucken, den es schreibt.
Kurz gesagt, mit der Weiterentwicklung der NLP-Modelltechnologie für die automatische Programmierung und der großen Anzahl von Anpassungen, die menschliche Programmierer an die Verwendung von NLP-Tools zur automatischen Vervollständigung vorgenommen haben, ist es wahrscheinlich, dass es einen großen Killer geben wird prozedurale Synthesemodelle in naher Zukunft.
Übersetzer-Einführung
Zhu Xianzhong, 51CTO-Community-Redakteur, 51CTO-Expertenblogger, Dozent, Computerlehrer an einer Universität in Weifang und ein Veteran in der freiberuflichen Programmierbranche. In den Anfängen konzentrierte er sich auf verschiedene Microsoft-Technologien (stellte drei technische Bücher zu ASP.NET AJX und Cocos 2d-X zusammen). In den letzten zehn Jahren widmete er sich der Open-Source-Welt (vertraut mit beliebten Vollversionen). Stack-Webentwicklungstechnologie) und lernte OneNet/AliOS+Arduino/ESP32/Raspberry Pi und andere IoT-Entwicklungstechnologien sowie Scala+Hadoop+Spark+Flink und andere Big-Data-Entwicklungstechnologien kennen.
Originaltitel: NLP-Modelle zum Schreiben von Code: Programmsynthese#🎜 🎜#, Autor: Kevin Vu
Das obige ist der detaillierte Inhalt vonEin Überblick über die NLP-Modelltechnologie der automatischen Programmierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr