
Heim >Technologie-Peripheriegeräte >KI >Maschinelles Lernen ist ein Segen des Himmels! Datenwissenschaftler und Kaggle-Master veröffentlicht „Leitfaden zur Vermeidung von ML-Fallstricken'
Maschinelles Lernen ist ein Segen des Himmels! Datenwissenschaftler und Kaggle-Master veröffentlicht „Leitfaden zur Vermeidung von ML-Fallstricken'

- PHPznach vorne
- 2023-04-12 20:40:011377Durchsuche
Datenwissenschaft und maschinelles Lernen erfreuen sich immer größerer Beliebtheit.
Die Zahl der Menschen, die diesen Bereich betreten, wächst täglich.
Das bedeutet, dass viele Datenwissenschaftler nicht über umfangreiche Erfahrung beim Aufbau ihres ersten Modells für maschinelles Lernen verfügen, sodass leicht Fehler passieren können.
Hier sind einige der häufigsten Anfängerfehler bei Lösungen für maschinelles Lernen.

Datennormalisierung nicht dort verwenden, wo es nötig ist
Für Anfänger mag es wie eine Selbstverständlichkeit erscheinen, Funktionen in ein Modell einzubauen und darauf zu warten, dass es Vorhersagen liefert.
Aber in manchen Fällen können die Ergebnisse enttäuschend sein, weil Sie einen sehr wichtigen Schritt verpasst haben.

Bestimmte Modelltypen erfordern eine Datennormalisierung, einschließlich linearer Regression, klassischer neuronaler Netze usw. Diese Modelltypen verwenden Merkmalswerte multipliziert mit trainierten Gewichten. Wenn Merkmale nicht normalisiert werden, kann es vorkommen, dass der Bereich möglicher Werte für ein Merkmal stark vom Bereich möglicher Werte für ein anderes Merkmal abweicht.
Angenommen, der Wert eines Merkmals liegt im Bereich [0, 0,001] und der Wert des anderen Merkmals liegt im Bereich [100000, 200000]. Bei einem Modell, bei dem zwei Merkmale gleich wichtig sind, beträgt das Gewicht des ersten Merkmals das 100.000.000-fache des Gewichts des zweiten Merkmals. Große Gewichte können dem Modell ernsthafte Probleme bereiten. Beispielsweise gibt es einige Ausreißer.
Darüber hinaus kann es sehr schwierig sein, die Wichtigkeit verschiedener Merkmale abzuschätzen, da ein großes Gewicht bedeuten kann, dass das Merkmal wichtig ist, oder einfach nur bedeuten kann, dass es einen kleinen Wert hat.
Und nach der Normalisierung liegen alle Merkmale im gleichen Wertebereich, normalerweise [0, 1] oder [-1, 1]. In diesem Fall liegen die Gewichte in einem ähnlichen Bereich und entsprechen weitgehend der wahren Bedeutung jedes Merkmals.
Insgesamt führt die Verwendung der Datennormalisierung bei Bedarf zu besseren und genaueren Vorhersagen.
Ich denke, je mehr Funktionen, desto besser
Manche Leute denken vielleicht, je mehr Funktionen Sie hinzufügen, desto besser, sodass das Modell automatisch die besten Funktionen auswählt und verwendet.
In der Praxis ist dies nicht der Fall. In den meisten Fällen übertrifft ein Modell mit sorgfältig entworfenen und ausgewählten Funktionen ein ähnliches Modell mit zehnmal mehr Funktionen deutlich.
Je mehr Features das Modell hat, desto größer ist das Risiko einer Überanpassung. Selbst in völlig zufälligen Daten ist das Modell in der Lage, einige Signale zu finden – manchmal schwächere, manchmal stärkere.

Natürlich gibt es im Zufallsrauschen kein wirkliches Signal. Wenn wir jedoch über genügend Rauschspalten verfügen, ist es für das Modell möglich, einige davon basierend auf dem erkannten Fehlersignal zu verwenden. In diesem Fall nimmt die Qualität der Modellvorhersagen ab, da sie teilweise auf zufälligem Rauschen basieren.
Es stimmt, dass es verschiedene Techniken zur Funktionsauswahl gibt, die in diesem Fall helfen können. In diesem Artikel werden sie jedoch nicht besprochen.
Denken Sie vor allem daran: Sie sollten in der Lage sein, jede Ihrer Funktionen zu erklären und zu verstehen, warum diese Funktion Ihrem Modell hilft.
Verwenden Sie baumbasierte Modelle, wenn eine Extrapolation erforderlich ist
Der Hauptgrund für die Beliebtheit von Baummodellen liegt nicht nur in ihrer Stärke, sondern auch in ihrer einfachen Handhabung.

Allerdings ist es nicht immer bewährt. In manchen Fällen kann die Verwendung eines baumbasierten Modells durchaus ein Fehler sein.
Das Baummodell verfügt über keine Inferenzfunktionen. Diese Modelle liefern niemals einen vorhergesagten Wert, der größer ist als der in den Trainingsdaten gesehene Maximalwert. Sie geben auch niemals Vorhersagen aus, die kleiner als das Minimum im Training sind.
Aber bei manchen Aufgaben kann die Extrapolationsfähigkeit eine große Rolle spielen. Wenn dieses Modell beispielsweise zur Vorhersage von Aktienkursen verwendet wird, ist es möglich, dass zukünftige Aktienkurse höher sein werden als je zuvor. In diesem Fall sind baumbasierte Modelle daher nicht mehr geeignet, da ihre Vorhersagen auf Niveaus in der Nähe von Allzeithochpreisen beschränkt sind.
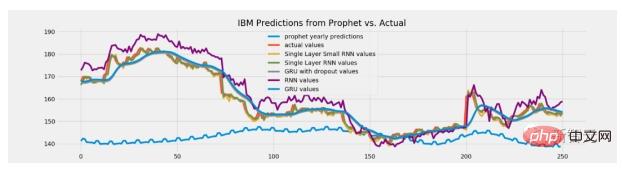

Wie kann man dieses Problem lösen?
Tatsächlich führen alle Wege nach Rom!
Eine Möglichkeit besteht darin, Veränderungen oder Unterschiede vorherzusagen, anstatt Werte direkt vorherzusagen. Eine andere Lösung besteht darin, für solche Aufgaben einen anderen Modelltyp zu verwenden, beispielsweise eine lineare Regression oder extrapolationsfähige neuronale Netze.
Überflüssige Normalisierung
Sie müssen mit Daten vertraut sein. Die Bedeutung der Normalisierung. Allerdings erfordern unterschiedliche Aufgaben unterschiedliche Normalisierungsmethoden. Wenn Sie den falschen Typ drücken, verlieren Sie mehr als Sie gewinnen!
 Baumbasierte Modelle erfordern keine Datennormalisierung, da die Funktionen primitiv sind Werte werden nicht als Multiplikatoren verwendet und Ausreißer haben keinen Einfluss auf sie.
Baumbasierte Modelle erfordern keine Datennormalisierung, da die Funktionen primitiv sind Werte werden nicht als Multiplikatoren verwendet und Ausreißer haben keinen Einfluss auf sie.
Neuronale Netzwerke benötigen möglicherweise auch keine Normalisierung – zum Beispiel, wenn das Netzwerk bereits Schichten enthält, die die Normalisierung intern durchführen (wie die BatchNormalization der Keras-Bibliothek).
 In einigen Fällen erfordert die lineare Regression möglicherweise auch keine Datenregression. Eine Transformation . Das bedeutet, dass alle Merkmale in einem ähnlichen Wertebereich liegen und die gleiche Bedeutung haben. Wenn das Modell beispielsweise auf Zeitreihendaten angewendet wird und alle Merkmale historische Werte desselben Parameters sind.
In einigen Fällen erfordert die lineare Regression möglicherweise auch keine Datenregression. Eine Transformation . Das bedeutet, dass alle Merkmale in einem ähnlichen Wertebereich liegen und die gleiche Bedeutung haben. Wenn das Modell beispielsweise auf Zeitreihendaten angewendet wird und alle Merkmale historische Werte desselben Parameters sind.
In der Praxis schadet die Anwendung unnötiger Datennormalisierung nicht unbedingt dem Modell. Meistens sind die Ergebnisse in diesen Fällen einer übersprungenen Normalisierung sehr ähnlich. Allerdings verkompliziert die Durchführung zusätzlicher unnötiger Datentransformationen die Lösung und erhöht das Risiko, dass einige Fehler entstehen.
Ob Sie es also verwenden oder nicht, die Übung wird Ihnen die Wahrheit sagen!
Datenverletzung
Datenverletzung ist einfacher als wir denken.
Bitte sehen Sie sich den folgenden Codeausschnitt an:
#🎜🎜 #
Eigentlich sind beide Features „sum_feature“ und „diff_feature“ falsch. 
Sie lassen Informationen „durchsickern“, da der Teil mit den Trainingsdaten nach der Aufteilung in Zug-/Testsätze einige der Informationen aus den Testzeilen enthält. Obwohl dies zu besseren Validierungsergebnissen führt, wird die Leistung bei der Anwendung auf reale Datenmodelle sinken.
Der richtige Ansatz besteht darin, zuerst einen Trainings-/Testsplit durchzuführen. Erst dann wird die Feature-Generierungsfunktion angewendet. Im Allgemeinen ist es ein gutes Feature-Engineering-Muster, den Trainingssatz und den Testsatz getrennt zu verarbeiten.
In einigen Fällen müssen einige Informationen zwischen den beiden weitergegeben werden. Beispielsweise möchten wir möglicherweise, dass der Testsatz denselben StandardScaler verwendet, der für den Trainingssatz verwendet und darauf trainiert wurde. Da es sich hierbei jedoch nur um einen Einzelfall handelt, müssen wir die einzelnen Sachverhalte noch im Detail analysieren!

Es ist gut, aus seinen Fehlern zu lernen. Aber am besten lernt man aus den Fehlern anderer – ich hoffe, die Fehlerbeispiele in diesem Artikel helfen Ihnen weiter.
Das obige ist der detaillierte Inhalt vonMaschinelles Lernen ist ein Segen des Himmels! Datenwissenschaftler und Kaggle-Master veröffentlicht „Leitfaden zur Vermeidung von ML-Fallstricken'. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr