
Heim >Technologie-Peripheriegeräte >KI >Illustration der zehn am häufigsten verwendeten Algorithmen für maschinelles Lernen!
Illustration der zehn am häufigsten verwendeten Algorithmen für maschinelles Lernen!

- 王林nach vorne
- 2023-04-12 13:34:051656Durchsuche
Im Bereich des maschinellen Lernens gibt es ein Sprichwort mit dem Titel „Es gibt kein kostenloses Mittagessen auf der Welt“. Kurz gesagt bedeutet dies, dass kein Algorithmus bei jedem Problem die beste Wirkung erzielen kann wichtig.
Zum Beispiel kann man nicht sagen, dass neuronale Netze immer besser sind als Entscheidungsbäume oder umgekehrt. Die Modellausführung wird von vielen Faktoren beeinflusst, beispielsweise der Größe und Struktur des Datensatzes.
Daher sollten Sie viele verschiedene Algorithmen basierend auf Ihrem Problem ausprobieren und gleichzeitig einen Testdatensatz verwenden, um die Leistung zu bewerten und den besten auszuwählen.
Natürlich muss der Algorithmus, den Sie ausprobieren, für Ihr Problem relevant sein, und der Schlüssel liegt in der Hauptaufgabe des maschinellen Lernens. Wenn Sie beispielsweise Ihr Haus reinigen möchten, können Sie einen Staubsauger, einen Besen oder einen Mopp verwenden, aber Sie würden nicht eine Schaufel nehmen und anfangen, ein Loch zu graben.
Für Neulinge im maschinellen Lernen, die die Grundlagen des maschinellen Lernens verstehen möchten, finden Sie hier die zehn wichtigsten Algorithmen für maschinelles Lernen, die von Datenwissenschaftlern verwendet werden. Wir stellen Ihnen die Eigenschaften dieser zehn besten Algorithmen vor, damit jeder sie besser verstehen und anwenden kann . Komm, schau mal rein.
01 Lineare Regression
Die lineare Regression ist wahrscheinlich einer der bekanntesten und am einfachsten zu verstehenden Algorithmen in der Statistik und im maschinellen Lernen.
Da es bei der prädiktiven Modellierung hauptsächlich darum geht, den Fehler des Modells zu minimieren oder möglichst genaue Vorhersagen auf Kosten der Interpretierbarkeit zu treffen. Wir leihen, verwenden und stehlen Algorithmen aus vielen verschiedenen Bereichen, und dazu sind einige statistische Kenntnisse erforderlich.
Die lineare Regression wird durch eine Gleichung dargestellt, die die lineare Beziehung zwischen der Eingabevariablen (x) und der Ausgabevariablen (y) beschreibt, indem das spezifische Gewicht (B) der Eingabevariablen ermittelt wird.
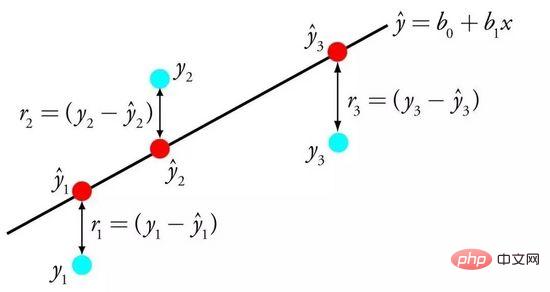
Lineare Regression
Beispiel: y = B0 + B1 * x
Angesichts der Eingabe x werden wir y vorhersagen. Das Ziel des linearen Regressionslernalgorithmus besteht darin, die Werte der Koeffizienten B0 und zu finden B1.
Lineare Regressionsmodelle können mithilfe verschiedener Techniken aus Daten erlernt werden, z. B. lineare Algebra-Lösungen für gewöhnliche kleinste Quadrate und Gradientenabstiegsoptimierung.
Die lineare Regression gibt es seit über 200 Jahren und sie wurde umfassend erforscht. Einige Faustregeln bei der Verwendung dieser Technik bestehen darin, sehr ähnliche (korrelierte) Variablen zu entfernen und nach Möglichkeit Rauschen aus den Daten zu entfernen. Dies ist eine schnelle und einfache Technik und ein guter erster Algorithmus.
02 Logistische Regression
Die logistische Regression ist eine weitere Technik, die maschinelles Lernen aus dem Bereich der Statistik übernimmt. Dies ist eine spezielle Methode für binäre Klassifikationsprobleme (Probleme mit zwei Klassenwerten).
Die logistische Regression ähnelt der linearen Regression darin, dass das Ziel beider darin besteht, den Gewichtungswert jeder Eingabevariablen zu ermitteln. Im Gegensatz zur linearen Regression wird der vorhergesagte Wert der Ausgabe mithilfe einer nichtlinearen Funktion namens Logistikfunktion transformiert.
Logistische Funktionen sehen aus wie ein großes S und wandeln jeden Wert in den Bereich von 0 bis 1 um. Dies ist nützlich, da wir die entsprechenden Regeln auf die Ausgabe der Logistikfunktion anwenden, die Werte in 0 und 1 klassifizieren können (z. B. wenn IF kleiner als 0,5 ist, dann Ausgabe 1) und den Klassenwert vorhersagen können.
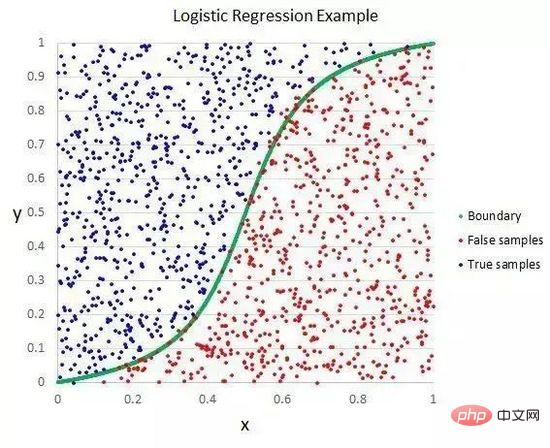
Logistische Regression
Aufgrund der einzigartigen Lernmethode des Modells können Vorhersagen durch logistische Regression auch zur Berechnung der Wahrscheinlichkeit der Zugehörigkeit zu Klasse 0 oder Klasse 1 verwendet werden. Dies ist nützlich bei Problemen, die viele Begründungen erfordern.
Wie die lineare Regression funktioniert auch die logistische Regression besser, wenn Sie Attribute entfernen, die nicht mit der Ausgabevariablen in Zusammenhang stehen, und Attribute, die einander sehr ähnlich (korreliert) sind. Dies ist ein Modell, das schnell lernt und binäre Klassifizierungsprobleme effektiv bewältigt.
03 Lineare Diskriminanzanalyse
Die traditionelle logistische Regression ist auf binäre Klassifizierungsprobleme beschränkt. Wenn Sie mehr als zwei Klassen haben, ist die lineare Diskriminanzanalyse (LDA) die bevorzugte lineare Klassifizierungstechnik.
Die Darstellung von LDA ist sehr einfach. Es besteht aus statistischen Eigenschaften Ihrer Daten, die auf Grundlage jeder Kategorie berechnet werden. Für eine einzelne Eingabevariable umfasst dies:
Der Durchschnittswert für jede Kategorie.
Varianz über alle Kategorien hinweg berechnet.
Lineare Diskriminanzanalyse
LDA wird durchgeführt, indem der Diskriminanzwert jeder Klasse berechnet und eine Vorhersage für die Klasse mit dem Maximalwert erstellt wird. Bei dieser Technik wird davon ausgegangen, dass die Daten eine Gaußsche Verteilung (Glockenkurve) aufweisen. Daher ist es am besten, Ausreißer zuerst manuell aus den Daten zu entfernen. Dies ist ein einfacher, aber leistungsstarker Ansatz für Probleme der Klassifizierungsvorhersagemodellierung.
04 Klassifizierungs- und Regressionsbaum
Der Entscheidungsbaum ist ein wichtiger Algorithmus für maschinelles Lernen.
Das Entscheidungsbaummodell kann durch einen Binärbaum dargestellt werden. Ja, es ist ein Binärbaum aus Algorithmen und Datenstrukturen, nichts Besonderes. Jeder Knoten stellt eine einzelne Eingabevariable (x) und die linken und rechten untergeordneten Elemente dieser Variablen dar (vorausgesetzt, die Variablen sind Zahlen). Die Blattknoten des Baums enthalten die Ausgabevariablen (y), die zur Erstellung von Vorhersagen verwendet werden. Die Vorhersage erfolgt durch Durchlaufen des Baums, Stoppen beim Erreichen eines bestimmten Blattknotens und Ausgeben des Klassenwerts des Blattknotens.
Entscheidungsbäume haben eine schnelle Lerngeschwindigkeit und eine schnelle Vorhersagegeschwindigkeit. Vorhersagen sind für viele Probleme oft genau und Sie müssen keine besondere Vorbereitung für die Daten durchführen. 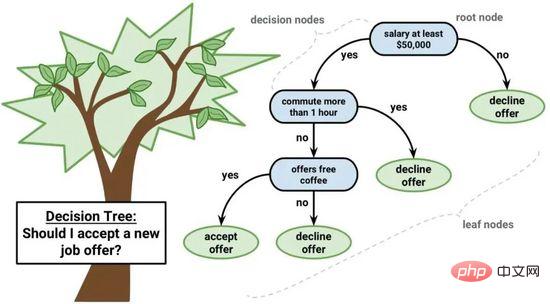
Bayes-Theorem
Der Grund, warum Naive Bayes als naiv bezeichnet wird, liegt darin, dass davon ausgegangen wird, dass jede Eingabevariable unabhängig von ist. Dies ist eine starke Annahme, die für reale Daten unrealistisch ist, aber die Technik ist bei komplexen Problemen im großen Maßstab immer noch sehr effektiv.
06 K Nächster Nachbar
K-Nächste Nachbarn
KNN benötigt möglicherweise viel Speicher oder Platz, um alle Daten zu speichern, aber nur, wenn Die erforderliche Berechnung (oder das Lernen) wird nur durchgeführt, wenn Vorhersagen getroffen werden. Sie können Ihren Trainingssatz auch jederzeit aktualisieren und verwalten, um die Vorhersagegenauigkeit aufrechtzuerhalten.
Das Konzept der Distanz oder Nähe kann in einer hochdimensionalen Umgebung (große Anzahl von Eingabevariablen) zusammenbrechen, was sich negativ auf den Algorithmus auswirken kann. Solche Ereignisse werden als Dimensionsflüche bezeichnet. Dies bedeutet auch, dass Sie nur die Eingabevariablen verwenden sollten, die für die Vorhersage der Ausgabevariablen am relevantesten sind. 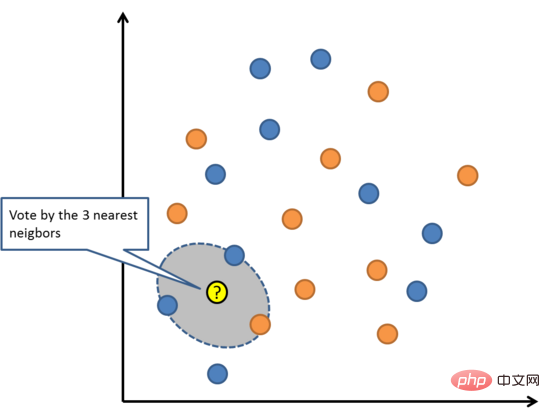
Lernen der Vektorquantisierung
LVQ wird durch eine Sammlung von Codebuchvektoren dargestellt. Beginnen Sie mit der zufälligen Auswahl von Vektoren und iterieren Sie dann mehrmals, um sie an den Trainingsdatensatz anzupassen. Nach dem Lernen kann der Codebuchvektor zur Vorhersage wie K-nächste Nachbarn verwendet werden. Finden Sie den ähnlichsten Nachbarn (beste Übereinstimmung), indem Sie den Abstand zwischen jedem Codebuchvektor und der neuen Dateninstanz berechnen, und geben Sie dann den Klassenwert der Einheit mit der besten Übereinstimmung oder den tatsächlichen Wert im Fall einer Regression als Vorhersage zurück. Die besten Ergebnisse werden erzielt, wenn Sie die Daten auf denselben Bereich beschränken (z. B. zwischen 0 und 1).
Wenn Sie feststellen, dass KNN gute Ergebnisse für Ihren Datensatz liefert, versuchen Sie, LVQ zu verwenden, um den Speicherbedarf für die Speicherung des gesamten Trainingsdatensatzes zu reduzieren. 
Support Vector Machine
Der Abstand zwischen der Hyperebene und dem nächstgelegenen Datenpunkt wird als Grenze bezeichnet, und die Hyperebene mit der größten Grenze ist die beste Wahl. Gleichzeitig beziehen sich nur diese nahe beieinander liegenden Datenpunkte auf die Definition der Hyperebene und die Konstruktion des Klassifikators. Diese Punkte werden als Stützvektoren bezeichnet und unterstützen oder definieren die Hyperebene. In der konkreten Praxis werden wir Optimierungsalgorithmen verwenden, um Koeffizientenwerte zu finden, die die Grenze maximieren.
SVM ist wahrscheinlich einer der leistungsfähigsten sofort einsatzbereiten Klassifikatoren und es lohnt sich, ihn in Ihrem Datensatz auszuprobieren.
09 Bagging und Random Forest
Random Forest ist einer der beliebtesten und leistungsstärksten Algorithmen für maschinelles Lernen. Es handelt sich um einen integrierten Algorithmus für maschinelles Lernen namens Bootstrap Aggregation oder Bagging.
bootstrap ist eine leistungsstarke statistische Methode, mit der eine Menge, beispielsweise der Mittelwert, aus einer Datenstichprobe geschätzt wird. Es nimmt eine große Anzahl von Beispieldaten, berechnet den Durchschnitt und mittelt dann alle Durchschnittswerte, um eine genauere Schätzung des wahren Durchschnitts zu erhalten.
Beim Absacken wird die gleiche Methode verwendet, am häufigsten wird jedoch der Entscheidungsbaum anstelle der Schätzung des gesamten statistischen Modells verwendet. Es führt eine Mehrfachabtastung der Trainingsdaten durch und erstellt dann ein Modell für jede Datenprobe. Wenn Sie eine Vorhersage für neue Daten treffen müssen, erstellt jedes Modell eine Vorhersage und mittelt die Vorhersagen, um eine bessere Schätzung des tatsächlichen Ausgabewerts zu erhalten.
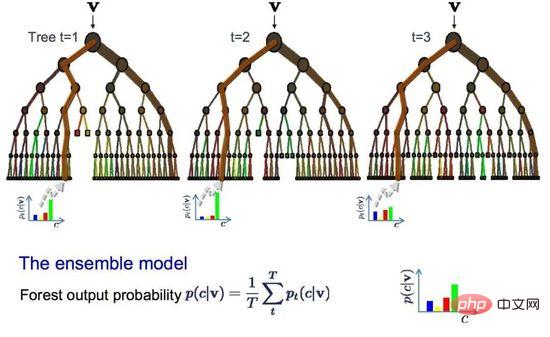
Random Forest
Random Forest ist eine Anpassung des Entscheidungsbaums im Vergleich zur Auswahl des besten Teilungspunkts, Random Forest Wälder erreichen eine suboptimale Segmentierung durch die Einführung von Zufälligkeit.
Daher unterscheiden sich die für jede Datenprobe erstellten Modelle stärker voneinander, sind aber in ihrem eigenen Sinne immer noch genau. Die Kombination von Vorhersageergebnissen ermöglicht eine bessere Schätzung des korrekten potenziellen Ausgabewerts.
Wenn Sie mit Algorithmen mit hoher Varianz (z. B. Entscheidungsbäumen) gute Ergebnisse erzielen, führt das Hinzufügen dieses Algorithmus zu noch besseren Ergebnissen.
10 Boosting und AdaBoost
Boosting ist eine Ensemble-Technik, die aus einigen schwachen Klassifikatoren einen starken Klassifikator erstellt. Es erstellt zunächst ein Modell aus den Trainingsdaten und erstellt dann ein zweites Modell, um zu versuchen, die Fehler des ersten Modells zu korrigieren. Fügen Sie kontinuierlich Modelle hinzu, bis der Trainingssatz eine perfekte Vorhersage liefert oder bis zur Obergrenze hinzugefügt wurde.
AdaBoost ist der erste wirklich erfolgreiche Boosting-Algorithmus, der für die binäre Klassifizierung entwickelt wurde, und es ist auch der beste Ausgangspunkt für das Verständnis von Boosting. Der bekannteste Algorithmus, der derzeit auf AdaBoost basiert, ist das stochastische Gradienten-Boosting. AdaBoost wird häufig bei kurzen Entscheidungsbäumen verwendet. Nachdem der erste Baum erstellt wurde, bestimmt die Leistung jeder Trainingsinstanz im Baum, wie viel Aufmerksamkeit der nächste Baum dieser Trainingsinstanz widmen muss. Schwierig vorhersehbare Trainingsdaten erhalten mehr Gewicht, während leicht vorhersehbare Instanzen weniger gewichtet werden. Modelle werden nacheinander erstellt und jede Modellaktualisierung wirkt sich auf den Lerneffekt des nächsten Baums in der Sequenz aus. Nachdem alle Bäume erstellt wurden, trifft der Algorithmus Vorhersagen zu neuen Daten und gewichtet die Leistung jedes Baums danach, wie genau er bei den Trainingsdaten war.
Da der Algorithmus großen Wert auf die Fehlerkorrektur legt, sind saubere Daten ohne Ausreißer sehr wichtig. 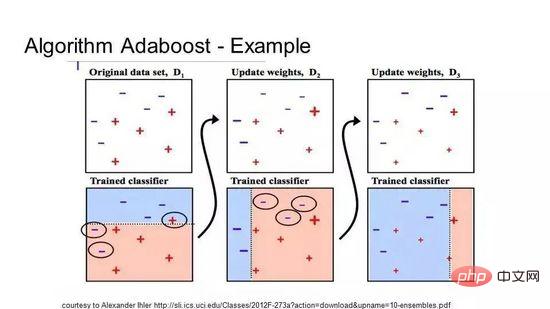
Größe, Qualität und Beschaffenheit der Daten;
Verfügbare Rechenzeit;
Dringlichkeit der Aufgabe;
#🎜 🎜#Was Was möchten Sie mit den Daten tun?- Selbst ein erfahrener Datenwissenschaftler kann nicht wissen, welcher Algorithmus am besten funktioniert, bevor er verschiedene Algorithmen ausprobiert. Obwohl es viele andere Algorithmen für maschinelles Lernen gibt, sind diese Algorithmen die beliebtesten. Wenn Sie neu im Bereich maschinelles Lernen sind, ist dies ein guter Ausgangspunkt.
Das obige ist der detaillierte Inhalt vonIllustration der zehn am häufigsten verwendeten Algorithmen für maschinelles Lernen!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr