
Heim >Technologie-Peripheriegeräte >KI >11 gängige Techniken zur Kodierung von Klassifizierungsmerkmalen
11 gängige Techniken zur Kodierung von Klassifizierungsmerkmalen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-12 12:16:091900Durchsuche
Maschinelle Lernalgorithmen akzeptieren nur numerische Eingaben. Wenn wir also auf kategoriale Merkmale stoßen, werden wir die kategorialen Merkmale kodieren. Dieser Artikel fasst 11 gängige Kodierungsmethoden für kategoriale Variablen zusammen.

1. ONE HOT ENCODING
Die beliebteste und am häufigsten verwendete Codierungsmethode ist One Hot Enoding. Eine einzelne Variable mit n Beobachtungen und d unterschiedlichen Werten wird in d binäre Variablen mit n Beobachtungen umgewandelt, wobei jede binäre Variable durch ein Bit (0, 1) identifiziert wird.
Zum Beispiel:
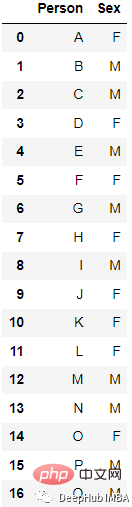
Nach der Codierung

Die einfachste Implementierung ist die Verwendung von get_dummies von pandas
new_df=pd.get_dummies(columns=[‘Sex’], data=df)
2, Label-Codierung
Weisen Sie der kategorialen Datenvariablen eine eindeutig identifizierte Ganzzahl zu. Diese Methode ist sehr einfach, kann jedoch bei kategorialen Variablen, die ungeordnete Daten darstellen, Probleme verursachen. Beispiel: Tags mit hohen Werten können eine höhere Priorität haben als Tags mit niedrigen Werten.
Zum Beispiel haben wir in den obigen Daten nach der Codierung die folgenden Ergebnisse erhalten:

Der LabelEncoder von sklearn kann direkt konvertiert werden:
from sklearn.preprocessing import LabelEncoder le=LabelEncoder() df[‘Sex’]=le.fit_transform(df[‘Sex’])
3. Label Binarizer
LabelBinarizer ist ein Tool zum Erstellen einer Etikettenmatrix Eine Utility-Klasse mit mehreren Kategorien, die eine Liste in eine Matrix mit genau der gleichen Anzahl von Spalten wie die eindeutigen Werte im Eingabesatz umwandelt.
Zum Beispiel diese Daten
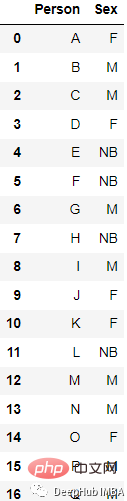
Das konvertierte Ergebnis ist

from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() new_df[‘Sex’]=lb.fit_transform(df[‘Sex’])
4. Lassen Sie eine Codierung weg
Wenn Sie eine Codierung weglassen, werden alle Datensätze mit demselben Wert für die kategoriale Zielmerkmalsvariable angezeigt gemittelt, um den Mittelwert der Zielvariablen zu bestimmen. Der Kodierungsalgorithmus unterscheidet sich geringfügig zwischen den Trainings- und Testdatensätzen. Da die für die Klassifizierung berücksichtigten Merkmalsdatensätze aus dem Trainingsdatensatz ausgeschlossen sind, spricht man von „Leave One Out“.
Die Codierung spezifischer Werte spezifischer kategorialer Variablen ist wie folgt.
ci = (Σj != i tj / (n — 1 + R)) x (1 + εi) where ci = encoded value for ith record tj = target variable value for jth record n = number of records with the same categorical variable value R = regularization factor εi = zero mean random variable with normal distribution N(0, s)
Zum Beispiel die folgenden Daten:

Nach der Kodierung:

Um diesen Kodierungsprozess zu demonstrieren, erstellen wir den Datensatz:
import pandas as pd; data = [[‘1’, 120], [‘2’, 120], [‘3’, 140], [‘2’, 100], [‘3’, 70], [‘1’, 100],[‘2’, 60], [‘3’, 110], [‘1’, 100],[‘3’, 70] ] df = pd.DataFrame(data, columns = [‘Dept’,’Yearly Salary’])
und kodieren ihn dann:
import category_encoders as ce
tenc=ce.TargetEncoder()
df_dep=tenc.fit_transform(df[‘Dept’],df[‘Yearly Salary’])
df_dep=df_dep.rename({‘Dept’:’Value’}, axis=1)
df_new = df.join(df_dep)Auf diese Weise wir erhalten das obige Ergebnis.
5. Hashing
Bei Verwendung der Hash-Funktion wird die Zeichenfolge in einen eindeutigen Hash-Wert umgewandelt. Weil es sehr wenig Speicher benötigt und mehr kategoriale Daten verarbeiten kann. Feature-Hashing ist eine effektive Methode zur Verwaltung spärlicher hochdimensionaler Features beim maschinellen Lernen. Es eignet sich für Online-Lernszenarien und zeichnet sich durch schnelle, einfache, effiziente und schnelle Eigenschaften aus.
Zum Beispiel die folgenden Daten:
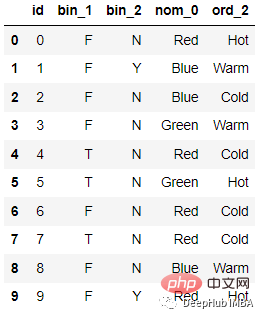
Nach der Kodierung
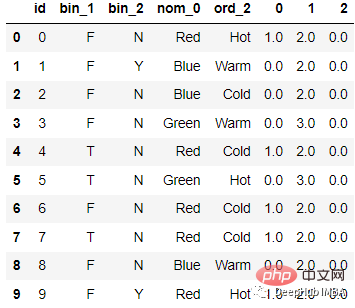
lautet der Code wie folgt:
from sklearn.feature_extraction import FeatureHasher # n_features contains the number of bits you want in your hash value. h = FeatureHasher(n_features = 3, input_type =’string’) # transforming the column after fitting hashed_Feature = h.fit_transform(df[‘nom_0’]) hashed_Feature = hashed_Feature.toarray() df = pd.concat([df, pd.DataFrame(hashed_Feature)], axis = 1) df.head(10)
6. Weight of Evidence Encoding
(WoE) Das Hauptziel der Entwicklung ist die Erstellung eines Vorhersagemodell zur Bewertung des Kredit- und Kreditausfallrisikos in der Finanzbranche. Das Ausmaß, in dem Beweise eine Theorie stützen oder widerlegen, hängt von ihrer Beweiskraft oder WOE ab.
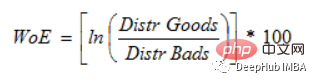
Wenn P(Goods) / P(Bads) = 1, dann ist WoE 0. Wenn das Ergebnis für diese Gruppe zufällig ist, dann ist P(Schlecht) > P(Gut), das Chancenverhältnis ist 1 und die Beweiskraft (WoE) ist 0. Wenn P(Goods) > P(schlecht) in einer Gruppe, dann ist WoE größer als 0.
因为Logit转换只是概率的对数,或ln(P(Goods)/P(bad)),所以WoE非常适合于逻辑回归。当在逻辑回归中使用wo编码的预测因子时,预测因子被处理成与编码到相同的尺度,这样可以直接比较线性逻辑回归方程中的变量。
例如下面的数据

会被编码为:

代码如下:
from category_encoders import WOEEncoder
df = pd.DataFrame({‘cat’: [‘a’, ‘b’, ‘a’, ‘b’, ‘a’, ‘a’, ‘b’, ‘c’, ‘c’], ‘target’: [1, 0, 0, 1, 0, 0, 1, 1, 0]})
woe = WOEEncoder(cols=[‘cat’], random_state=42)
X = df[‘cat’]
y = df.target
encoded_df = woe.fit_transform(X, y)7、Helmert Encoding
Helmert Encoding将一个级别的因变量的平均值与该编码中所有先前水平的因变量的平均值进行比较。
反向 Helmert 编码是类别编码器中变体的另一个名称。它将因变量的特定水平平均值与其所有先前水平的水平的平均值进行比较。

会被编码为

代码如下:
import category_encoders as ce encoder=ce.HelmertEncoder(cols=’Dept’) new_df=encoder.fit_transform(df[‘Dept’]) new_hdf=pd.concat([df,new_df], axis=1) new_hdf
8、Cat Boost Encoding
是CatBoost编码器试图解决的是目标泄漏问题,除了目标编码外,还使用了一个排序概念。它的工作原理与时间序列数据验证类似。当前特征的目标概率仅从它之前的行(观测值)计算,这意味着目标统计值依赖于观测历史。

TargetCount:某个类别特性的目标值的总和(到当前为止)。
Prior:它的值是恒定的,用(数据集中的观察总数(即行))/(整个数据集中的目标值之和)表示。
featucalculate:到目前为止已经看到的、具有与此相同值的分类特征的总数。

编码后的结果如下:

代码:
import category_encoders category_encoders.cat_boost.CatBoostEncoder(verbose=0, cols=None, drop_invariant=False, return_df=True, handle_unknown=’value’, handle_missing=’value’, random_state=None, sigma=None, a=1) target = df[[‘target’]] train = df.drop(‘target’, axis = 1) # Define catboost encoder cbe_encoder = ce.cat_boost.CatBoostEncoder() # Fit encoder and transform the features cbe_encoder.fit(train, target) train_cbe = cbe_encoder.transform(train)
9、James Stein Encoding
James-Stein 为特征值提供以下加权平均值:
- 观察到的特征值的平均目标值。
- 平均期望值(与特征值无关)。
James-Stein 编码器将平均值缩小到全局的平均值。该编码器是基于目标的。但是James-Stein 估计器有缺点:它只支持正态分布。
它只能在给定正态分布的情况下定义(实时情况并非如此)。为了防止这种情况,我们可以使用 beta 分布或使用对数-比值比转换二元目标,就像在 WOE 编码器中所做的那样(默认使用它,因为它很简单)。
10、M Estimator Encoding:
Target Encoder的一个更直接的变体是M Estimator Encoding。它只包含一个超参数m,它代表正则化幂。m值越大收缩越强。建议m的取值范围为1 ~ 100。
11、 Sum Encoder
Sum Encoder将类别列的特定级别的因变量(目标)的平均值与目标的总体平均值进行比较。在线性回归(LR)的模型中,Sum Encoder和ONE HOT ENCODING都是常用的方法。两种模型对LR系数的解释是不同的,Sum Encoder模型的截距代表了总体平均值(在所有条件下),而系数很容易被理解为主要效应。在OHE模型中,截距代表基线条件的平均值,系数代表简单效应(一个特定条件与基线之间的差)。
最后,在编码中我们用到了一个非常好用的Python包 “category-encoders”它还提供了其他的编码方法,如果你对他感兴趣,请查看它的官方文档:
http://contrib.scikit-learn.org/category_encoders/
Das obige ist der detaillierte Inhalt von11 gängige Techniken zur Kodierung von Klassifizierungsmerkmalen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Technologietrends, die Sie im Jahr 2023 im Auge behalten sollten
- Wie künstliche Intelligenz Rechenzentrumsteams neue Alltagsaufgaben beschert
- Können künstliche Intelligenz oder Automatisierung das Problem der geringen Energieeffizienz in Gebäuden lösen?
- OpenAI-Mitbegründer im Interview mit Huang Renxun: Die Argumentationsfähigkeiten von GPT-4 haben noch nicht die Erwartungen erfüllt
- Dank der OpenAI-Technologie übertrifft Bing von Microsoft Google im Suchverkehr